EMNLP'23 京东:深度语义召回中的超参自适应调整

作者 | 李国趸
整理 | NewBeeNLP
https://zhuanlan.zhihu.com/p/675751178
后台留言『交流』,加入 NewBee讨论组
大家好,这里是 NewBeeNLP。京东搞了一种在召回阶段简单的自适应调整温度系数和 margin 的方法。
参考论文:Adaptive Hyper-parameter Learning for Deep Semantic Retrieval
公司:京东
链接:https://aclanthology.org/2023.emnlp-industry.72.pdf
会议:EMNLP2023

省流版
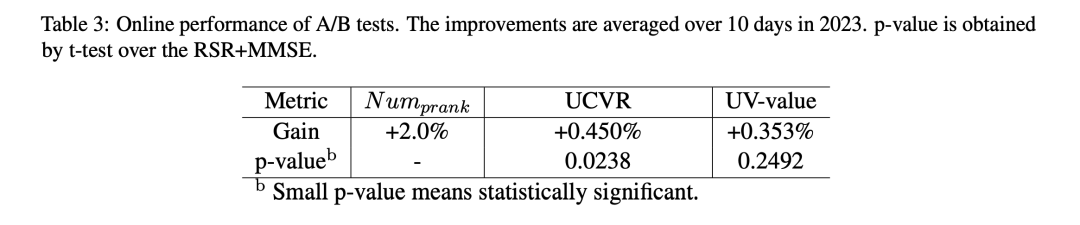
京东搜索搞了一种在召回阶段简单的自适应调整温度系数和margin的方法,比WWW那篇论文更简单。主要看两个大盘指标:UV值(每个独立访客的收入)和UCVR(订单数/UV)和一个中间指标:过了相关性模块后参与排名阶段(prank)的item数量(笔者注:怀疑prank是粗排)。2023年的10天的线上AB实验显示,效果还是蛮好的,p值也比较低。
动机
召回或者说检索中,最常用的就是sampled softmax loss或者margin loss,其中利用margin和温度系数来去显式控制正负例之间的“分辨率“。
之前的工作都是手拍的超参,很明显,更合理的方式是针对不同query,不同user实现一个自适应的温度或者margin。最近也有一篇www论文(Adap-τ : Adaptively modulating embedding magnitude for recommendation)在探讨温度系数怎么自适应调整,但是作者认为该论文方法比较复杂,且在搜索系统中是不可用的。文中提到的原因是因为现实中query是不可知的,而不像推荐系统中user是给定的。
作者也通过一系列实验表明两种loss的超参对batch recall@k的结果是比较敏感的: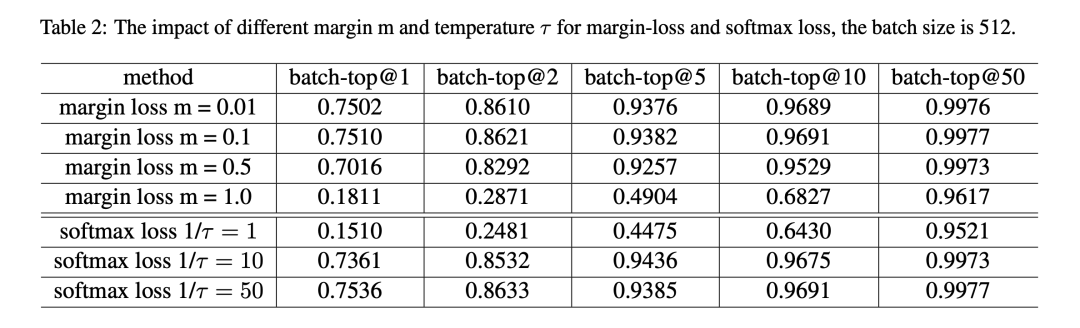
因此,作者就设计了一种更简单而且可以自适应调整温度系数和margin的方法,并且在京东线上AB实验上取得了收益。
双塔模型上常用的两个loss
双塔召回模型主要是通过负采样或batch内负样本进行训练。给定一个样本列表,其中包含一个正样本和n个负样本,即。目标是将负样本表征远离query并将正样本表征靠近query,即:
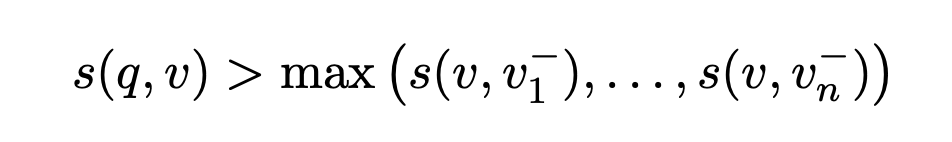
为了达到上述目标,有两种loss可以用来优化:
margin loss :旨在通过固定的超参数margin来区分正负例,控制度量空间中的决策边界。
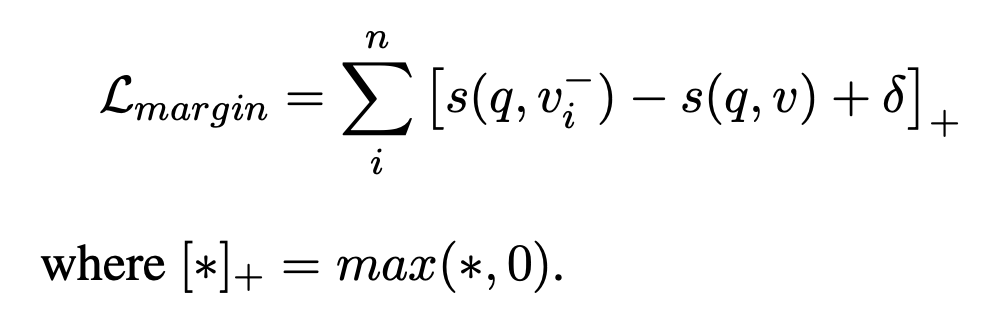
softmax loss :softmax损失函数能够实现良好的训练稳定性,并与ranking metric相匹配。通常比其他方法表现更好,因此在检索中受到广泛关注。其中温度系数用于平滑训练数据的整体拟合分布。更小值意味模型完全适应监督信号并更专注难负例,反之亦然。
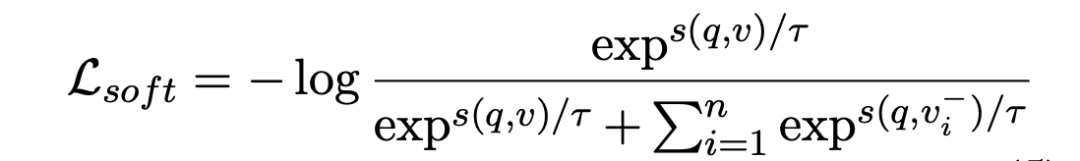
原文翻译,看看就好:上述损失函数取决于超参数,这在性能方面起着重要作用。具体实验将在下一节中讨论。不幸的是,传统方法在自适应选择超参数方面存在问题。此外,在个性化场景中,每对需要特定的边界和温度值,使得学习或选择适当的值更加具有挑战性。虽然其他领域,如推荐系统,已通过双层或统计学习解决了这个问题,但我们认为这些方法不适用于检索场景。检索场景涉及到来自在线系统的不同于推荐的输入查询,因为输入查询是丰富和不可知的。因此,需要一种无参数的方法来生成特定的值。为此,我们首先提出了一种通过内积计算值的启发式方法,然后提出了一种对称度量学习方法来缓解训练过程中的崩溃问题。
方法
在度量空间中,最难的负样本的位置非常接近正样本,而容易或随机的负样本则远离正样本。我们需要细分负样本。给定一对,如果是最难的负样本,则查询和正样本v的相似度应该更高,换句话说,边缘损失应该更小。同样,对于最难的负样本,温度在softmax损失中也应该更小。
所以,给定一个pair对,作者针对这个pair对定义了一个动态的,即:
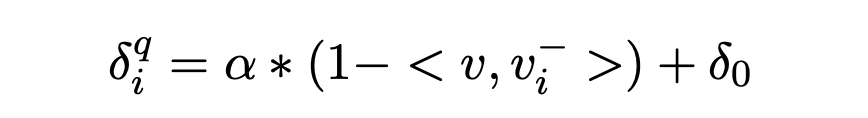
其实呢,这个动态,是指的根据正负item之间的内积来动态决定,依然需要一个全局的参数和。这两个参数可以是trainable的。
虽然启发式方法很简单,但作者觉得它在训练过程中会遭受模型崩溃的问题,导致所有item在度量空间中聚集在一起。从梯度的角度来看,可以知道自适应的margin将影响正负item的更新方向。
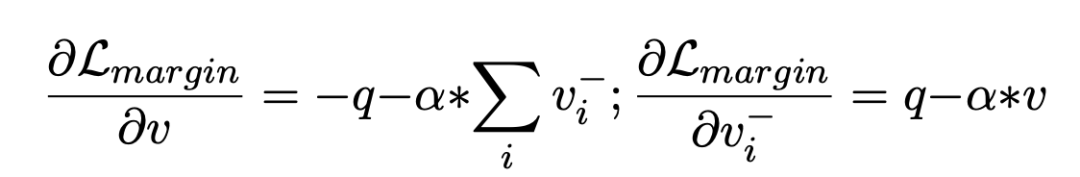
为了避免表征崩塌,最简单的方法就是停梯度:
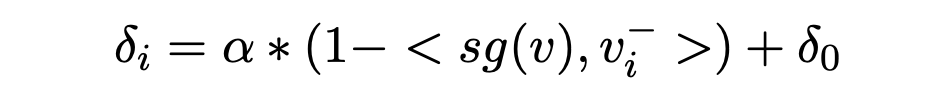
所以最后的loss就变成:
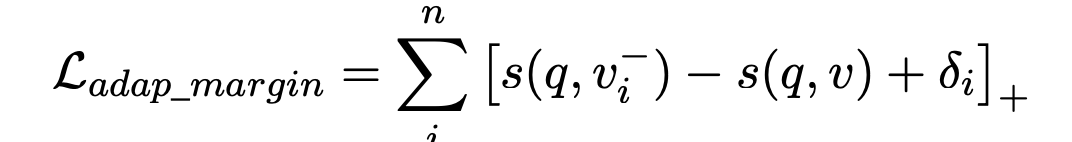
除此以外,作者还觉得,糟糕的初始化方式还是有崩溃风险,比如。这种情况下,q和v的距离会大于v和的距离。为了避免这种情况,搞了一个对称的loss来约束,即将v作为锚点,q作为正样本项,旨在将负样本项远离正样本项:
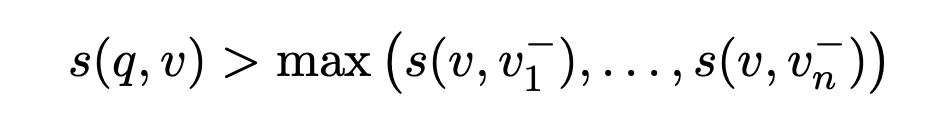
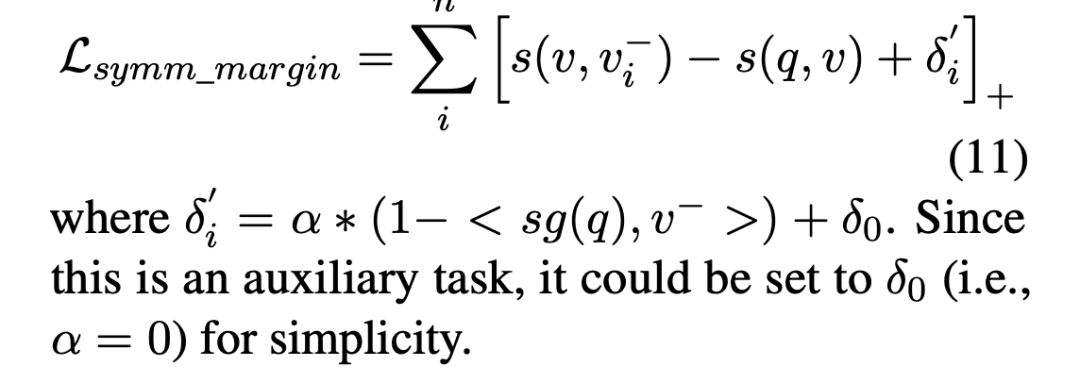
总的loss就是:
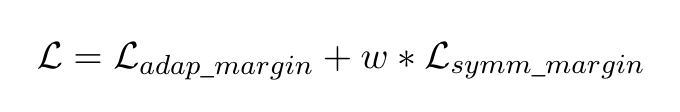
softmax loss也是一样:
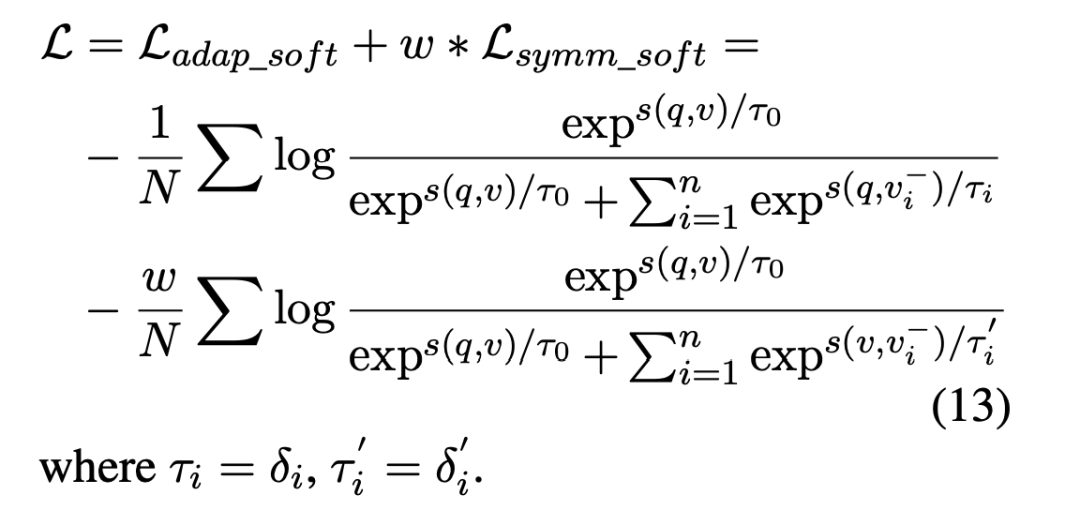
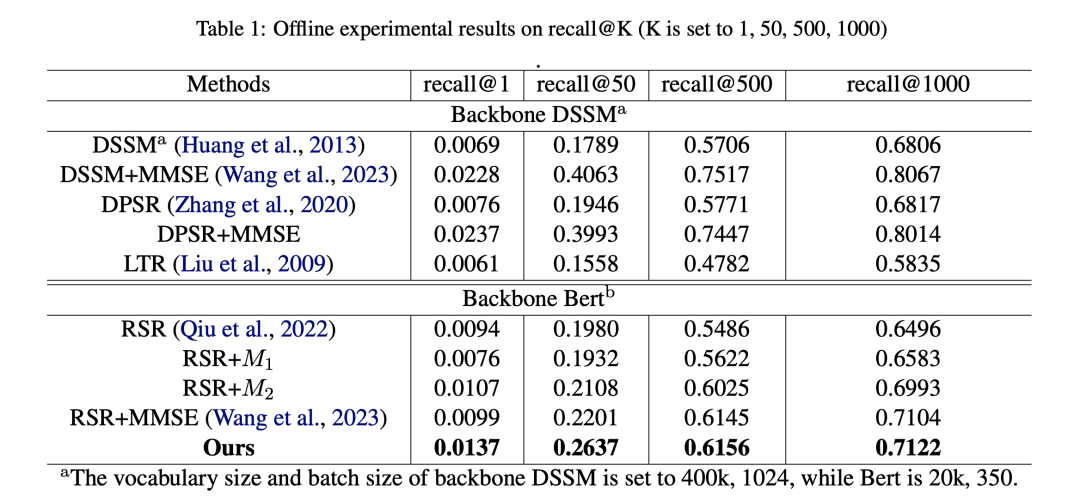
效果
batch recall@k作为指标
列一下牛逼的基线:
DSSM:经典的不说了,Learning deep structured semantic models for web search using clickthrough data
MMSE:京东23年出的一篇多目标EBR召回论文:Learning multi-stage multigrained semantic embeddings for e-commerce search
DPSR:京东20年出的一篇EBR召回论文:Towards personalized and semantic retrieval: An end-to-end solution for e-commerce search via embedding learning
LTR:经典的不说了,Learning to rank for information retrieval
RSR:京东22年出的一篇EBR召回论文,backbone是bert,Pre-training tasks for user intent detection and embedding retrieval in e-commerce search
作者也提到了这个方法可以用到淘宝的MGDSPR中。
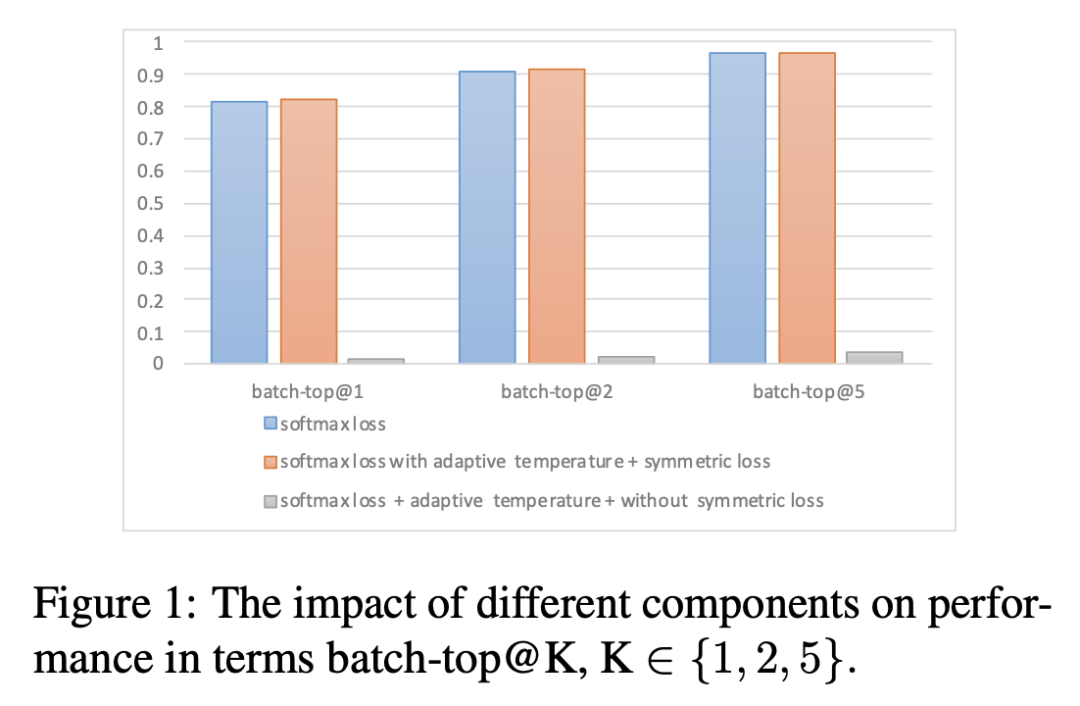
维度设置为128,批量大小设置为350,IVF-PQ的n-list设置为32768,并在Faiss ANNS库1中使用索引构建。softmax的默认温度为1/30,边距设置为0.1。设置为0.5,设置为0.01,设置为1/30。w的默认值设置为0.05。采用Adam优化器,初始学习率为5e-5。查询和序列的最大长度分别为30和100。
此外消融了下这些loss的效果,看起来确实涨了一些。同时对称loss是很必要的。
总结
可以试试。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

