大数据之Hadoop
Hadoop的简介

Apache Hadoop是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架,有助于使用许多电脑组成的网络来解决数据、计算密集型的问题。基于MapReduce计算模型,它为大数据的分布式存储与处理提供了一个软件框架。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。
Apache Hadoop的核心模块分为存储和计算模块,前者被称为Hadoop分布式文件系统(HDFS),后者即MapReduce计算模型。Hadoop框架先将文件分成数据块并分布式地存储在集群的计算节点中,接着将负责计算任务的代码传送给各节点,让其能够并行地处理数据。这种方法有效利用了数据局部性,令各节点分别处理其能够访问的数据。与传统的超级电脑架构相比,这使得数据集的处理速度更快、效率更高。
Hadoop组件
HDFS
HDFS分布式存储框架,适合海量数据的存储
HDFS的原理:是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间
通透性;让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
容错;即使系统中有某些节点宕机,整体来说系统仍然可以持续运作而不会有数据损失【通过副本机制实现】。
分布式文件管理系统很多,hdfs只是其中一种,不合适小文件。
HDFS的节点
一、管理节点NameNode
NameNode是整个文件系统的管理节点,它维护着整个文件系统的目录树,文件目录的元信息和每个文件对应的数据块列表,接收用户的操作请求。
①维护每个DataNode的心跳,用于查看数据节点是否存活
②用于管理HDFS中所有的文件信息,包括文件的路径、文件的block块信息、文件的大小及其权限
③响应客户端的请求,根据上传或下载返回请求的结果
二、数据节点DataNode
DataNode节点提供真实文件数据的存储服务
①用于存储客户端上传的具体文件,文件上传过程会进行数据的切分,根据block块大小会将文件切分成多块,并且block块会存储在多个DataNode中
②响应客户端的上传请求和下载请求
③检测和管理存储在本节点上的block块信息
Block块为HDFS中基本的存储单位,但并不是最小的存储单位
一个文件的长度大小是size,那么从文件的偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称为一个block。
BLock块大小:
1.在Hadoop1.X中大小默认为64M
2.在Hadoop2.X中大小默认为128M
为什么BLock块大小为128M?
问题:
1. 如果一个文件不进行做拆分,对应一个DataNode中存储一个完整的文件,对导致DataNode存取压力过大,由于计算本地化,所以计算压力也会很大,由此需要拆分
2. 如果拆分过大? 会导致1问题,同时下载速度也会很慢
3. 如果拆分过小? 对应一个拆分过的文件会特别多,那么对应的元数据信息也会很多,会导致NameNode压力过大,检索数据信息时间会很长
基于以上问题如何设计?
规定:一个数据的检索时间最长不超过10ms,规定检索时间为BLock数据下载时间的1%为1秒
数据下载时间由网络及磁盘决定,由于磁盘和网络传输时间在100M/s,基于这个理论值得到 block块大小是在128M
设置BLock块大小
hdfs-site.xml中dfs.blocksize属性
副本数
Replication。多副本。默认是三个
设置hdfs-site.xml的dfs.replication属性
副本机制与机架?
如果当前集群设置副本数为3 那么对应存放位置为在同一个机架中会存放两个份,其他机架中保存一份,可以保证数据的安全。
为什么block块不每个机架存放一份?
由于后续做数据计算时,会将计算结果进行汇总,如果数据过于分散,那么后续网络传输压力会很大。
三、Secondary NameNode
Secondary NameNode是NameNode的备份节点
①由于NameNode需要保存元数据信息,并且元数据信息是放在内存中的
②数据存放在内存中会有安全性问题,需要持久化
③由于NameNode对外请求压力大,并不适合做持久化工作,所以交由Secondary NameNode
HDFS的读写
一、HDFS的读流程

1.首先调用FileSystem对象的open方法,其实是一个DistributedFileSystem的实例
2.DistributedFileSystem通过rpc获得文件的第一个block的locations,同一block按照副本数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面.
3.前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream最会找出离客户端最近的datanode并连接。
4.数据从datanode源源不断的流向客户端。
5.如果第一块的数据读完了,就会关闭指向第一块的datanode连接,接着读取下一块。这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流。
6.如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的块都读完,这时就会关闭掉所有的流
如果在读数据的时候,DFSInputStream和datanode的通讯发生异常,就会尝试正在读的block的排第二近的datanode,并且会记录哪个datanode发生错误,剩余的blocks读的时候就会直接跳过该datanode。DFSInputStream也会检查block数据校验和,如果发现一个坏的block,就会先报告到namenode节点,然后DFSInputStream在其他的datanode上读该block的镜像
该设计的方向就是客户端直接连接datanode来检索数据并且namenode来负责为每一个block提供最优的datanode,namenode仅仅处理block location的请求,这些信息都加载在namenode的内存中,hdfs通过datanode集群可以承受大量客户端的并发访问。
二、HDFS的写流程

1.客户端通过调用DistributedFileSystem的create方法创建新文件,并向NameNode发送请求,namenode接收到请求后会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,namenode就会记录下新文件,否则就会抛出IO异常
2.NameNode在客户端中创建DFSOutputStream对象,DFSOutputStream可以协调namenode和datanode并会把数据切成一个个小packet,每个Packet大小为64K,packet会由多个chunks组成,每个chunk大小为512字节,并伴随一个4字节的校验码,然后将packet存放至dataQuene中
3.当dataQuene中存在数据时,会向NameNode请求上传第一个BLock块
4.NameNode接收到请求后,返回BLock块存储位置列表
5.客户端接收到列表后,根据机架感知(拓扑结构),以及负载均衡,寻找最优的一个DataNode节点进行连接
6.客户端会与最近的DataNode创建通道(pipeline),之后该DataNode会与其他的DataNode创建通道
7.开始上传第一个packet数据,dataQuene会将packet数据发送到本地的ackQueue
8.本地的ackQueue会将packet上传至DataNode的ackQueue
9.当第一个DataNode接收到packet,会将packet从ackQueue中分发至其他DataNode的ackQueue
10.当pipeline中的所有datanode都表示已经收到的时候,这时本地akc queue才会把对应的packet包移除掉。
11.当第一个BLock块中所有的packet数据上传完成,会重新向NameNode申请上传下一个BLock块所在的Locations位置,按之前的顺序再次提交,直到所有的BLock上传完成后通知namenode把文件标示为已完成
问题:如果上传过程中出现问题?
如果在写的过程中某个datanode发生错误,会采取以下几步:
1) pipeline被关闭掉;
2)为了防止丢包ack queue里的packet会同步到data queue里;
3)把产生错误的datanode上当前在写但未完成的block删掉;
4)block剩下的部分被写到剩下的两个正常的datanode中;
5)namenode找到另外的datanode去创建这个块的复制
MapReduce
MapReduce作用
将用户的业务逻辑和Hadoop中的组件结合起来形成一个分布式程序
JAVA类型与Hadoop类型对应
Java中的数据类型通过序列化以后,会产生大量的描述数据信息,在网络传输过程中,会占用大量资源,所以Hadoop实现了自己的一套数据结构,并且能够和Java中的数据类型进行对应
Hadoop text 对应 JAVA中的 String
| Java类型 | Writable |
|---|---|
| 字符串(String) | Text |
| 布尔型(boolean) | BooleanWritable |
| 字节型(byte) | ByteWritable |
| 整型(int) | IntWritable |
| VIntWritable | IntWritable |
| 浮点型(float) | FloatWritable |
| 长整型(long) | LongWritable |
| VLongWritable | LongWritable |
| 双精度浮点型(double) | DoubleWritable |
| 空值NULL | NullWritable |
MapReduce代码解析
1.Map端
① 输入数据为KV数据对,其中K为其数据读取的偏移量,Value为当前输入源的一行数据
②输出为KV数据对
③所有的业务逻辑都是在Map方法中实现的
④执行过程中每一行数据都会调用一次map方法
⑤一个切片数产生一个MapTask任务
2.Reduce端
①输入数据为Map端输出的数据
②所有的业务逻辑都在Reduce方法中实现
③如果ReduceTask数量为n个,那么对应输出文件也为n个
④Reduce中会将Map端输出的相同的Key放置一起,对应其Value是一个Iterable迭代器
3.Driver端
Driver的作用是将当前的程序打包提交给yarn集群(如果是在集群中运行),并通过Yarn中的ResourceManager创建当前程序的ApplicationMaster
具体代码步骤:
① 创建job,并设置Job中的配置,包括类,当前Job名称
②通过job设置Mapper和 Reducer(Reducer并不是必须的)
③设置Mapper输出的KV类以及最终输出的KV类
④设置输入输出的数据路径
⑤提交job
切片

切片源码
1、
public List<InputSplit> getSplits(JobContext job) throws IOException {
// 设置一个时间管理器,用于统计切片所花费的时间
StopWatch sw = new StopWatch().start();
// getFormatMinSplitSize=1L getMinSplitSize =1L => minSize = 1
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
// maxSize=9223372036854775807L
long maxSize = getMaxSplitSize(job);
// generate splits
// 创建List用来存储split
List<InputSplit> splits = new ArrayList<InputSplit>();
// 通过listStatus获取输入路径下所有的文件
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
// 获取文件所在路径
Path path = file.getPath();
// 获取文件长度
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
// 判断file对象类型
if (file instanceof LocatedFileStatus) {
// 本地文件系统
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
// HDFS上的文件系统
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
// 判断文件是否可以切分,有的文件会是压缩格式
if (isSplitable(job, path)) {
// blockSize值为当前文件大小,如果当文件大小超过128M时,大小为128M
long blockSize = file.getBlockSize();
// 经过对比后 blockSize=splitSize
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
// 当前文件长度赋予 bytesRemaining表示剩余长度
long bytesRemaining = length;
// SPLIT_SLOP=1.1
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
// 当前文件大小超过切片大小的1.1倍,开始切分数据
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
// 创建切片 length-bytesRemaining表示开始位置 splitSize表示切片长度
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
// 将剩余长度减去所切去的切片长度
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
// 如果剩余字节数小于 128M * 1.1 之后作为一个切片保存
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
// 如果不能切片,那么会创建一个切片用于处理数据
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
// 如果文件为空,那么也会创建一个切片
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}
总结:
① 切片大小并不总是为128M
②一个文件小于128M也会产生一个切片
③ 一个切片对应一个MapTask任务
2、
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}
序列化
为什么要做序列化?
在网络传输过程中,对象需要转换成二进制形式才能在网络中传输,将对象转成二进制形式的过程叫做序列化,将二进制结果转换成对象过程叫做反序列化
Map端读取文件过程
在MR代码中选择FileInputFormat进入,再去进入父类InputFormat,发现父类中定义了两个抽象方法
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
)
然后通过createRecordReader查看其子实现类中的方法,由于TextInputFormat继承与FileInputFormat,而MR程序中调用的是FileInputFormat,所以可以查看其子类TextInputFormat中的createRecordReader方法
@Override
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
...
return new LineRecordReader(recordDelimiterBytes);
}
进入LineRecordReader类中,查看initialize方法
public void initialize(InputSplit genericSplit,
TaskAttemptContext context) throws IOException {
// 获取FileSplit可以获取到切片的路径以及开始位置和长度
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.MAX_VALUE);
// 路径以及开始位置和长度
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
// open the file and seek to the start of the split
// 获取FileSystem读取文件
final FileSystem fs = file.getFileSystem(job);
fileIn = fs.open(file);
CompressionCodec codec = new CompressionCodecFactory(job).getCodec(file);
//判断切片是否为压缩格式
if (null!=codec) {
isCompressedInput = true;
decompressor = CodecPool.getDecompressor(codec);
if (codec instanceof SplittableCompressionCodec) {
final SplitCompressionInputStream cIn =
((SplittableCompressionCodec)codec).createInputStream(
fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
in = new CompressedSplitLineReader(cIn, job,
this.recordDelimiterBytes);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn;
} else {
in = new SplitLineReader(codec.createInputStream(fileIn,
decompressor), job, this.recordDelimiterBytes);
filePosition = fileIn;
}
} else {
fileIn.seek(start);
// 创建一个SplitLineReader对象,用于读取一行数据
in = new UncompressedSplitLineReader(
fileIn, job, this.recordDelimiterBytes, split.getLength());
filePosition = fileIn;
}
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
// 开始读取数据
if (start != 0) {
// new Text() 可以解释Map端Value输入总是用Text类型
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
// 将读取长度赋予给偏移量,可以解释Map端输入Key为LongWritable类型
this.pos = start;
}
小文件合并
读取数据过程中,如果小文件过多会导致什么问题?
根据切片逻辑,一个小文件对应一个切片,一个切片又对应一个MapTask
1. 当小文件过多时,导致ApplicationMaster向ResourceManager申请资源过多,会导致资源浪费。同时如果ResourceManager本身资源不充足情况下,申请过多的MapTask会导致当前程序一直处于接收状态,无法运行 2. 申请MapTask本身也需要消耗时间,当小文件数据量过少时,反而导致运行时间过长
解决方法:
在读取文件时,可以对小文件进行合并操作
修改切片大小方式:切片大小可以通过computeSplitSize方法进行查看,通过修改"mapreduce.input.fileinputformat.split.maxsize" 和"mapreduce.input.fileinputformat.split.minsize"可以解决

源码
public List<InputSplit> getSplits(JobContext job)
throws IOException {
long minSizeNode = 0;
long minSizeRack = 0;
long maxSize = 0;
Configuration conf = job.getConfiguration();
。。。
if (maxSplitSize != 0) {
maxSize = maxSplitSize;
} else {
// 可以获取到我们逻辑中设置的参数
maxSize = conf.getLong("mapreduce.input.fileinputformat.split.maxsize", 0);
// If maxSize is not configured, a single split will be generated per
// node.
}
。。。
// all the files in input set
List<FileStatus> stats = listStatus(job);
List<InputSplit> splits = new ArrayList<InputSplit>();
if (stats.size() == 0) {
return splits;
}
// In one single iteration, process all the paths in a single pool.
// Processing one pool at a time ensures that a split contains paths
// from a single pool only.
for (MultiPathFilter onepool : pools) {
ArrayList<FileStatus> myPaths = new ArrayList<FileStatus>();
。。。
// 通过getMoreSplits方法获取切片
// create splits for all files in this pool.
getMoreSplits(job, myPaths, maxSize, minSizeNode, minSizeRack, splits);
}
// create splits for all files that are not in any pool.
getMoreSplits(job, stats, maxSize, minSizeNode, minSizeRack, splits);
}
getMoreSplits 方法
private void getMoreSplits(JobContext job, List<FileStatus> stats,
long maxSize, long minSizeNode, long minSizeRack,
List<InputSplit> splits){
...
// populate all the blocks for all files
long totLength = 0;
int i = 0;
for (FileStatus stat : stats) {
// 创建一个OneFileInfo对象,所以查看OneFileInfo对象的构造方法
files[i] = new OneFileInfo(stat, conf, isSplitable(job, stat.getPath()),
rackToBlocks, blockToNodes, nodeToBlocks,
rackToNodes, maxSize);
totLength += files[i].getLength();
}
...
}
OneFileInfo对象的构造方法
OneFileInfo(FileStatus stat, Configuration conf,
boolean isSplitable,
HashMap<String, List<OneBlockInfo>> rackToBlocks,
HashMap<OneBlockInfo, String[]> blockToNodes,
HashMap<String, Set<OneBlockInfo>> nodeToBlocks,
HashMap<String, Set<String>> rackToNodes,
long maxSize)
throws IOException {
this.fileSize = 0;
// get block locations from file system
BlockLocation[] locations;
if (stat instanceof LocatedFileStatus) {
locations = ((LocatedFileStatus) stat).getBlockLocations();
} else {
FileSystem fs = stat.getPath().getFileSystem(conf);
locations = fs.getFileBlockLocations(stat, 0, stat.getLen());
}
。。。
// 如果文件可切分,那么再进行切分
else {
ArrayList<OneBlockInfo> blocksList = new ArrayList<OneBlockInfo>(
locations.length);
for (int i = 0; i < locatio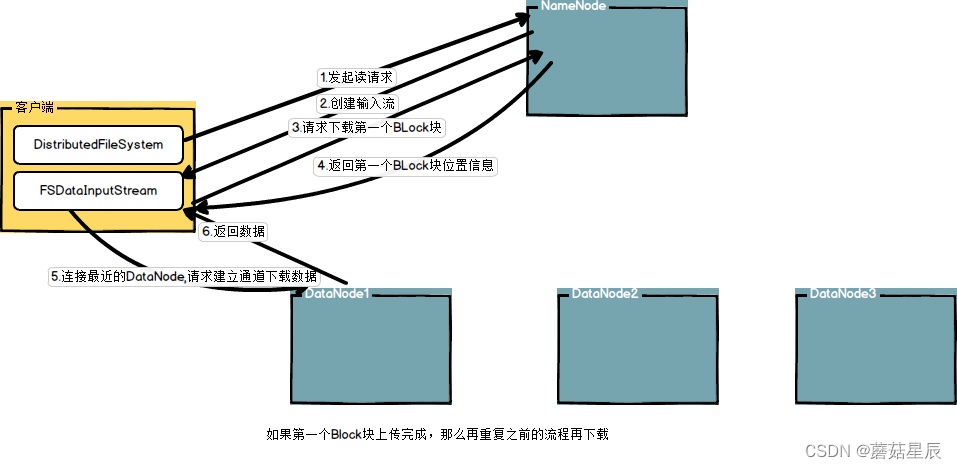
ns.length; i++) {
fileSize += locations[i].getLength();
// each split can be a maximum of maxSize
// 获取文件长度
long left = locations[i].getLength();
long myOffset = locations[i].getOffset();
long myLength = 0;
do {
// 如果当切片大小没有设置情况下,等于整个文件长度
if (maxSize == 0) {
myLength = left;
} else {
// 如果当文件大小在切片的 1到2倍之间 文件一分为二
if (left > maxSize && left < 2 * maxSize) {
// if remainder is between max and 2*max - then
// instead of creating splits of size max, left-max we
// create splits of size left/2 and left/2. This is
// a heuristic to avoid creating really really small
// splits.
myLength = left / 2;
} else {
// 取文件和切片的最小值,如果文件是大于切片数的两倍取切片大小,小于取文件大小
myLength = Math.min(maxSize, left);
}
}
。。。。
}
}
输入类为什么为FileInputFormat
从job.waitForCompletion提交开始进入,进入方法内后有submit方法,再进入该方法内
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
ensureState(JobState.DEFINE);
// 设置当前API为最新的API
setUseNewAPI();
// 创建连接
connect();
// 获取提交对象 submitter
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
// 做具体的提交工作,运行之前的配置步骤都会在该方法中
return submitter.submitJobInternal(Job.this, cluster);
}
});
// 改变状态为运行状态
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
进入submitJobInternal方法
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
// 用于检查输出空间,如果文件已存在,那么会抛出异常
checkSpecs(job);
。。。
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
// 用于创建具体的切片数
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
进入writeSplits方法内
private int writeSplits(org.apache.hadoop.mapreduce.JobContext job,
Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
JobConf jConf = (JobConf)job.getConfiguration();
int maps;
// 由于之前已设置当前API为最新所以对应结果为TRUE
if (jConf.getUseNewMapper()) {
maps = writeNewSplits(job, jobSubmitDir);
} else {
maps = writeOldSplits(jConf, jobSubmitDir);
}
return maps;
}
进入writeNewSplits方法内
private <T extends InputSplit>
int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
Configuration conf = job.getConfiguration();
// job.getInputFormatClass() 获取对应配置信息为 JobContextImpl类中的 conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class);结果
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
// 获取到其对象后调用getSplits方法获取最后的切片列表
List<InputSplit> splits = input.getSplits(job);
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
return array.length;
}
Shuffle过程
shuffle过程上:

shuffle过程下:

代码断点:
①跑代码时,对应查看Reduce方法中Key的顺序,需要将ReduceTask数量设置为1个
②通过查看结果,可以知道Key为有序,并且是按照字典顺序进行排序,字典排序是根据ASC码表进行比较,并且比较是是按对应位置进行比较大小,例如如下顺序:
1 11 2 3
Combiner预聚合
作用:将Reduce端的逻辑提前到Map端进行处理,可以在很大程度上降低网络IO,但是注意,并不是所有的reduce函数处理逻辑都可以提前
具体执行效果如下:
Map input records=1098250
Map output records=2280970
Map output bytes=25597490
Map output materialized bytes=232
Input split bytes=468
Combine input records=2280970
Combine output records=16
Reduce input groups=4
Reduce shuffle bytes=232
Reduce input records=16
Reduce output records=4
MapTask
查看MapTask源码步骤
由于Driver端主要是用于数据提交,所以入口在Mapper端,而Mapper端中通常数据写出是由Writer方法调用,所以通过该方法进入源码
通过点击context.write进入后是一个抽象类,需要查看其子实现,由于其子实现类有多个,如果一时间无法判断,那么可以通过在多个类中打断点来查看具体执行,为哪个子实现类的方法。
TaskInputOutputContext.write -> WrappedMapper->TaskInputOutputContextImpl -> RecordWriter-> MapTask(NewOutputCollector)
NewOutputCollector类中方法:
public void write(K key, V value) throws IOException, InterruptedException {
// 该collector为MapOutputCollector的实现类MapOutputBuffer对象
collector.collect(key, value,
// 通过HashPartitioner类中的getPartition实现具体分区逻辑
partitioner.getPartition(key, value, partitions));
}
分区逻辑
public int getPartition(K key, V value,
int numReduceTasks) {
// 可以从此看出ReduceTask与分区的关系
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
进入 MapOutputCollector类中查看方法
public void init(Context context
) throws IOException, ClassNotFoundException;
public void collect(K key, V value, int partition
) throws IOException, InterruptedException;
// 会调用flush方法
public void close() throws IOException, InterruptedException;
// 用于当整个MapTask关闭时,将缓存中的数据刷写到磁盘中,并做merge
public void flush() throws IOException, InterruptedException,
ClassNotFoundException;
首先进入MapOutputBuffer中的collect方法
public synchronized void collect(K key, V value, final int partition
) throws IOException {
reporter.progress();
// 判断Map端输入的类型与Driver端设置的类型是否一致
if (key.getClass() != keyClass) {
throw new IOException("Type mismatch in key from map: expected "
+ keyClass.getName() + ", received "
+ key.getClass().getName());
}
// 判断Map端输入的类型与Driver端设置的类型是否一致
if (value.getClass() != valClass) {
throw new IOException("Type mismatch in value from map: expected "
+ valClass.getName() + ", received "
+ value.getClass().getName());
}
// 用来判断分区数是否正常
if (partition < 0 || partition >= partitions) {
throw new IOException("Illegal partition for " + key + " (" +
partition + ")");
}
checkSpillException();
// 查看当前类的init方法 知道 bufferRemaining为当前缓存大小(100M)的80%(阈值)
bufferRemaining -= METASIZE;
if (bufferRemaining <= 0) {
// start spill if the thread is not running and the soft limit has been
// reached
spillLock.lock();
try {
do {
// 如果溢写操作已执行
if (!spillInProgress) {
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
// serialized, unspilled bytes always lie between kvindex and
// bufindex, crossing the equator. Note that any void space
// created by a reset must be included in "used" bytes
final int bUsed = distanceTo(kvbidx, bufindex);
final boolean bufsoftlimit = bUsed >= softLimit;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished, reclaim space
// 当执行完成以后,开启重置操作
resetSpill();
bufferRemaining = Math.min(
distanceTo(bufindex, kvbidx) - 2 * METASIZE,
softLimit - bUsed) - METASIZE;
continue;
} else if (bufsoftlimit && kvindex != kvend) {
// spill records, if any collected; check latter, as it may
// be possible for metadata alignment to hit spill pcnt
// 开始溢写
startSpill();
final int avgRec = (int)
(mapOutputByteCounter.getCounter() /
mapOutputRecordCounter.getCounter());
。。。
}
}
public void init(MapOutputCollector.Context context
) throws IOException, ClassNotFoundException {
job = context.getJobConf();
reporter = context.getReporter();
mapTask = context.getMapTask();
mapOutputFile = mapTask.getMapOutputFile();
sortPhase = mapTask.getSortPhase();
spilledRecordsCounter = reporter.getCounter(TaskCounter.SPILLED_RECORDS);
partitions = job.getNumReduceTasks();
rfs = ((LocalFileSystem)FileSystem.getLocal(job)).getRaw();
//sanity checks
final float spillper =
// 阈值0.8
job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float)0.8);
final int sortmb = job.getInt(JobContext.IO_SORT_MB, 100);
// 1024 * 1024
indexCacheMemoryLimit = job.getInt(JobContext.INDEX_CACHE_MEMORY_LIMIT,
INDEX_CACHE_MEMORY_LIMIT_DEFAULT);
if (spillper > (float)1.0 || spillper <= (float)0.0) {
throw new IOException("Invalid \"" + JobContext.MAP_SORT_SPILL_PERCENT +
"\": " + spillper);
}
// 0x7FF为2047 当sortmb=100和2047做位运算,如果不等于sortmb那么抛出异常,限定sortmb最大只能为2G
if ((sortmb & 0x7FF) != sortmb) {
throw new IOException(
"Invalid \"" + JobContext.IO_SORT_MB + "\": " + sortmb);
}
// 定义当前类为QuickSort.class,快排
sorter = ReflectionUtils.newInstance(job.getClass("map.sort.class",
QuickSort.class, IndexedSorter.class), job);
// buffers and accounting
// 创建了sortmb=100M的字节数值 100M * 2的10次方
int maxMemUsage = sortmb << 20;
maxMemUsage -= maxMemUsage % METASIZE;
// 创建内存缓冲区的大小
kvbuffer = new byte[maxMemUsage];
bufvoid = kvbuffer.length;
kvmeta = ByteBuffer.wrap(kvbuffer)
.order(ByteOrder.nativeOrder())
.asIntBuffer();
setEquator(0);
bufstart = bufend = bufindex = equator;
kvstart = kvend = kvindex;
maxRec = kvmeta.capacity() / NMETA;
// 阈值内的内存大小 softLimit
softLimit = (int)(kvbuffer.length * spillper);
// 当前缓存剩余量,一开始为100M * 80%
bufferRemaining = softLimit;
LOG.info(JobContext.IO_SORT_MB + ": " + sortmb);
LOG.info("soft limit at " + softLimit);
LOG.info("bufstart = " + bufstart + "; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "; length = " + maxRec);
// k/v serialization
comparator = job.getOutputKeyComparator();
keyClass = (Class<K>)job.getMapOutputKeyClass();
valClass = (Class<V>)job.getMapOutputValueClass();
serializationFactory = new SerializationFactory(job);
keySerializer = serializationFactory.getSerializer(keyClass);
keySerializer.open(bb);
valSerializer = serializationFactory.getSerializer(valClass);
valSerializer.open(bb);
// 记录输出的数据量
// output counters
mapOutputByteCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_BYTES);
mapOutputRecordCounter =
reporter.getCounter(TaskCounter.MAP_OUTPUT_RECORDS);
fileOutputByteCounter = reporter
.getCounter(TaskCounter.MAP_OUTPUT_MATERIALIZED_BYTES);
// 如果有预聚合功能,那么会提前创建一个combinerRunner 有这个类再去创建一个combineCollector
// combiner
final Counters.Counter combineInputCounter =
reporter.getCounter(TaskCounter.COMBINE_INPUT_RECORDS);
combinerRunner = CombinerRunner.create(job, getTaskID(),
combineInputCounter,
reporter, null);
if (combinerRunner != null) {
final Counters.Counter combineOutputCounter =
reporter.getCounter(TaskCounter.COMBINE_OUTPUT_RECORDS);
combineCollector= new CombineOutputCollector<K,V>(combineOutputCounter, reporter, job);
} else {
combineCollector = null;
}
// 溢写执行标记
spillInProgress = false;
minSpillsForCombine = job.getInt(JobContext.MAP_COMBINE_MIN_SPILLS, 3);
spillThread.setDaemon(true);
spillThread.setName("SpillThread");
spillLock.lock();
try {
// 执行了溢写进程
spillThread.start();
while (!spillThreadRunning) {
spillDone.await();
}
} catch (InterruptedException e) {
throw new IOException("Spill thread failed to initialize", e);
} finally {
spillLock.unlock();
}
if (sortSpillException != null) {
throw new IOException("Spill thread failed to initialize",
sortSpillException);
}
}
startSpill()
private void startSpill() {
assert !spillInProgress;
kvend = (kvindex + NMETA) % kvmeta.capacity();
bufend = bufmark;
// 设置溢写标记
spillInProgress = true;
LOG.info("Spilling map output");
LOG.info("bufstart = " + bufstart + "; bufend = " + bufmark +
"; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "(" + (kvstart * 4) +
"); kvend = " + kvend + "(" + (kvend * 4) +
"); length = " + (distanceTo(kvend, kvstart,
kvmeta.capacity()) + 1) + "/" + maxRec);
// 开启溢写进程 ,进入 run()方法
spillReady.signal();
}
SpillThread的run()
protected class SpillThread extends Thread {
@Override
public void run() {
。。。
// 该方法在溢写时,会对数据进行做排序操作,并生成溢写文件
sortAndSpill();
。。。
}
}
获取分区类代码
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
通过partitioner对象查看其创建过程
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job);
通过查看jobContext.getPartitionerClass()方法
JobContextImpl类中:
public Class<? extends Partitioner<?,?>> getPartitionerClass()
throws ClassNotFoundException {
return (Class<? extends Partitioner<?,?>>)
// PARTITIONER_CLASS_ATTR = "mapreduce.job.partitioner.class" 默认为 HashPartitioner.class
conf.getClass(PARTITIONER_CLASS_ATTR, HashPartitioner.class);
}
排序
sorter = ReflectionUtils.newInstance(job.getClass("map.sort.class",
QuickSort.class, IndexedSorter.class), job);
public <U> Class<? extends U> getClass(String name,
Class<? extends U> defaultValue,
Class<U> xface) {
try {
Class<?> theClass = getClass(name, defaultValue);
if (theClass != null && !xface.isAssignableFrom(theClass))
throw new RuntimeException(theClass+" not "+xface.getName());
else if (theClass != null)
return theClass.asSubclass(xface);
Outputformat
TextOutputFormat
public synchronized void write(K key, V value)
throws IOException {
boolean nullKey = key == null || key instanceof NullWritable;
boolean nullValue = value == null || value instanceof NullWritable;
if (nullKey && nullValue) {
return;
}
if (!nullKey) {
writeObject(key);
}
if (!(nullKey || nullValue)) {
out.write(keyValueSeparator);
}
if (!nullValue) {
writeObject(value);
}
out.write(newline);
}
总结

Mapreduce的计算流程
map阶段 —> shuffle阶段 —> reduce阶段
1、map阶段
在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,默认一个block对应一个切片。一个切片对应一个MapTask, 切片完成后开始执行自定义map代码逻辑
2、shuffle阶段

- Mapper任务结束后产生<K2,V2>的输出,这些输出先存放在缓存中,每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spil l.percent),一个后台线程就把内容写到(spill)Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
- 写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。
3、Reduce阶段
当MapTask执行完成之后开始执行ReduceTask
- 执行ReduceTask之前会先从Map端拉取
- 从map端复制来的数据首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、combine、排序等过程。如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中。
- 最后将合并后的结果作为输入传入Reduce任务中。
- 最后就是Reduce过程了,在这个过程中产生了最终的输出结果,并将其写到HDFS上。
MR优化
MapReduce优化方法主要从六个方面考虑:数据输入、Map阶段、Reduce阶段、IO传输、数据倾斜问题和常用的调优参数
一、数据输入
1、合并小文件:因为大量小文件会产生大量的Map任务,而任务的装载比较耗
时,从而导致MR运行较慢
2、采用CombineTextInputFormat来作为输入框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理
二、Map阶段
1、减少溢写(Spill)次数,通过调整参数
- io.sort.mb:环形缓存区大小
- sort.spill.percent:达到多少表示满,百分比(80%)增大触发spill的内存上限,减少spill次数,从而减少磁盘IO
2、减少合并(Merge)次数,调节参数
- io.sort.factor:增大每次合并文件的个数,这样减少merge次数
3、在map之后,不影响业务逻辑前提下,先进行Combine处理,减少I/O
三、Reduce阶段
1、合理设置Map和Reduce数
- 通过设置切片大小改变Map数量
- 当Reduce中处理的数据量过大时,可以通过改变ReduceTask数量来增加ReduceTask个数从而分散数据量
2、设置Map、Reduce共存
调整slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的
等待时间
3、规避使用Reduce
在不需要使用Reduce时,就不要使用,这样减少shuffle
四、I/O传输
1、采用数据压缩的方式,减少网络IO的时间
安装Snappy和LZO压缩编码器
2、使用SequenceFile二进制文件
五、数据倾斜
1、数据倾斜现象
数据倾斜通常是发生在Reduce阶段,当Reduce端执行过程中,少量ReduceTask执行缓慢,可以判断为产生的数据倾斜,原因是部分Reduce接收到的相同Key对应的数据量过多,整体数据向少量Reduce倾斜
2、减少数据倾斜的方法
方法1:抽样和范围分区
可以通过对原始数据进行抽样得到的结果集来预设分区边界值方法2:自定义分区
基于输出键的背景知识进行自定义分区。例如,如果Map输出键的单词来源于一本书。且其中某几个专
业词汇较多。那么就可以自定义分区将这这些专业词汇发送给固定的一部分Reduce实例。而将其他的都
发送给剩余的Reduce实例方法3:Combine
使用Combine可以大量地减小数据倾斜。在可能的情况下,Combine的目的就是聚合并精简数据方法4:Key值过滤
通过在Map端对结果中不需要的并产生数据倾斜的Key值进行过滤,从而减少Reduce端处理的压力
其他
开启JVM重用
对于大量小文件Job,可以开启JVM重用会减少45%运行时间。
JVM重用原理:一个Map运行在一个JVM上,开启重用的话,该Map在JVM上运行完毕后,JVM继续运行
其他Map,减少开启时间
具体设置:mapreduce.job.jvm.numtasks值在10-20之间。
Shuffle优化
- 配置方面:
- 增大map阶段的缓冲区大小。
- map阶段输出结果使压缩;压缩算法使用lzo。
- 增加reduce阶段copy数据线程数。
- 增加副本数,从而提高计算时的数据本地化。
- 程序方面:
- 在不影响计算结果的情况下建议使用combiner。
- 输出结果的序列化类型尽量选择占用字节少的类型。
- 架构方面:
- 将http改为udp,因为http还要进行3次握手操作。
Yarn
Yarn工作流程

阶段描述
任务提交阶段
- 1.客户端请求执行应用程序
- 2.ResourceManager返回客户端应用程序提交路径,以及JobID
- 3.客户端接收到请求后,将当前应用程序jar包 以及切片数及其配置信息发送至HDFS指定路径
- 4.客户端发送请求,启动ApplicationManager
- 5.ApplicationManager启动后将job添加至资源队列ResourceSchedule中
任务初始化阶段
- 6.当资源队列中有空闲资源,通知Manager启动应用程序
- 7.Application Manager将任务进行初始化成Task
- 8.NodeManager接收到ApplicationManager指令后,创建Container,并在Container中启动ApplicationMaster
- 9.ApplicationMaster去HDFS中获取当前应用程序的配置信息及程序jar包
任务分配阶段及任务执行阶段
- 10.ApplicationMaster根据切片信息,向ResourceManager请求资源,启动MapTask,ApplicationMaster接收请求后通知NodeManager启动Container指令
- 11.AppMaster向对应的NodeManager中启动MapTask
- 12.MapTask启动后会向HDFS读取数据
- 13.MapTask执行完成会产生一个临时文件
- 14.MapTask结束后,AppMaster会向ResourceManager申请启动ReduceTask
- 15.ResourceManager通知NodeManager启动Container指令
- 16.AppMaster向对应的NodeManager中启动ReduceTask
- 17.拉取对应MapTask输出的数据
- 18.根据输出路径将结果数据写入HDFS
任务结束
- 19.当ReduceTask执行完,AppMaster会向ResourceManager申请关闭资源
Yarn常用命令
yarn application -list 查看yarn中的应用程序(job)
yarn application -kill applicationID 强制退出applicationID
Yarn资源调度
调度器种类
有三种调度器可以选择: FIFO Scheduler , Capacity Scheduler , FairScheduler
FIFO Scheduler
最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集
群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞

Capacity Scheduler
capacity scheduler(容量调度器,apache版本默认使用的调度器)通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略

FairScheduler
Fair Scheduler(公平调度器,CDH版本的hadoop默认使用的调度器)
Fair调度器的设计目标是为所有的应用分配公平的资源(对公平的定义可以通过参数来设置)。公平调度在也可以在多个队列间工作。举个例子,假设有两个用户A和B,他们分别拥有一个队列。当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会用于四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。

Fair Scheduler 不需要保留集群的资源,因为它会动态在所有正在运行的作业之间平衡资源
调度器区别
-
FIFO调度器:支持单队列 、先进先出 生产环境不会用。
-
容量调度器:支持多队列,保证先进入的任务优先执行。
-
公平调度器:支持多队列,保证每个任务公平享有队列资源。