mysql学习笔记
记录不经常使用容易忘记,和不知道的MYSQL知识
MYSQL基础相关
官方文档位置
https://dev.mysql.com/doc/refman/8.0/en/server-system-variables.html
MYSQL原理图

- 查看表的创建和库的创建信息
show create [table or database ] name ; - 查看编码命令
show variables like 'character_%'; show variables like 'collation_%'; - 插入数据时乱码

原因是访问的客户端与mysql编码不一致,解决方案,设置当前连接的客户端字符集 “SET NAMES GBK;” - 修改表和数据库的编码
1.更改表的编码
alter table [tablename] charset utf8;
2.更改表中字段的编码
alter table [表名] modify [字段名] varchar(20) charset utf8;
3.修改数据库的编码
alter database [数据库名] charset utf8;
查询语句
SQL执行顺序

以下面这个SQL为例

- From 子句执行顺序为从后往前、从右到左,从最后一张表到第一张,最后一张表最为驱动表,所以表应该从大到小的写。
比如:select * from students,user;那么顺序就是从user开始到student的数据生成一张笛卡儿积的虚拟表1,user表是驱动表,如果是小表的话效率比较高。
SELECT 是先执行 FROM 这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
- 首先先通过 CROSS JOIN 求笛卡尔积,相当于得到虚拟表 vt(virtual table)1-1;
- 通过 ON 进行筛选,在虚拟表 vt1-1 的基础上进行筛选,得到虚拟表 vt1-2;
- 添加外部行。如果我们使用的是左连接、右链接或者全连接,就会涉及到外部行,也就是在虚拟表 vt1-2 的基础上增加外部行,得到虚拟表 vt1-3。
- On 在生成虚拟表后,会用On对数据进行筛选,把筛选出来的保存成虚拟表2
- Join添加外部表,如果有外连接查询中保留表会追加到虚拟表2,形成虚拟表3,如果from包含多个表,第三张表会和前两张表的结果,重复From-On-Join的步骤,直到处理完所有的表。
左外连接保留左表,右外连接保留右表,全外连接保存左右表 - Where 对于Join完后生成的虚拟表3,根据制定的条件进行筛选,把满足的数据保存成虚拟表4
- Group By 对虚拟表4的某一列相同的组合成一组,生成虚拟表5,group by 完成之后,只能得到虚拟表5的行和列
- 聚合函数 (AVG,COUNT,FIRST,LAST,MAX,MIN,SUM等)
- Cube,RollUp生成数据集的聚合,生成虚拟表6
- Having 根据制定条件过滤聚合的数据,聚合结果进行筛选,生成虚拟表7
- SELECT ,把要展示的列筛选出来,根据生成虚拟表8
- DISTINCT 把重复和行删除,生成虚拟表9
- ORDER BY 对结果进行排序,生成虚拟表10
- LIMIT/OFFSET 指定返回行,生成虚拟表11
SQL分类
按照功能可以分为三类:
1.DDL(Data Definition Languages、数据定义语言):定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。例如:alter ,create ,drop等。
2.DML(Data Manipulation Language、数据操作语言),用于添加、删除、更新和查询数据库记录,并检查数据完整性, INSERT 、 DELETE 、 UPDATE 、 SELECT。
3.DCL(Data Control Language、数据控制语言),用于定义数据库、表、字段、用户的访问权限和安全级别。GRANT 、 REVOKE 、 COMMIT 、 ROLLBACK 、 SAVEPOINT 等。
1.起别名的时候as可以省略,如果别名中没有空格,可以省略“”
2.数据导入指令
source XXX.sql 可以导入某一个sql文件
3.除非使用所有列,否则不要用select * ,虽然可以降低输入时间,但是会降低查询效率。
4.关键字大写,表,列,库小写。
5.DISTINCT 是对后面跟的所有列去重
6.在Mysql里空值是占用空间的
7.如果表名,字段名和保留字有冲突,需要用着重号``包裹。
8.desc 全拼describe
9.show table status like ‘employees’ 查看表或视图的信息,存储引擎,版本,行数,大小等
10.SHOW CREATE VIEW 视图名称;查看视图的详细定义

算术运算符:+ - * /

比较运算符: = <=> (等于) <> != (不等于) < <= > >=(小于等于,大于等于)

使用<=>比较两个null值的时候,返回的是1,如果用=比较返回的还是null
非符号比较符

LEAST(值1,值2,…,值n)当参数是整数或者浮点数时,LEAST将返回其中最小的值;当参数为字符串时,返回字
母表中顺序最靠前的字符;当比较值列表中有NULL时,不能判断大小,返回值为NULL。
LIKE 运算符,用于模糊匹配,“%”匹配0或者多个字符,“_”只能匹配一个字符。
REGEXP 正则匹配

逻辑运算符

1.SELECT NOT NULL;返回结果是null
2.
3.Or和And 的优先级不一样,And的优先级高于Or,因此先执行And,然后再Or
位运算符
在二进制的基础上进行运算,先把操作数变成二进制数,按位进行计算,结果再转为十进制

一个数字如何快速的*2,使用<<位移
运算符优先级

正则匹配实用

- 查询以特定字符或字符串开头的记录 字符‘^’匹配以特定字符或者字符串开头的文本
select * from test where name regexp ‘^a’查询以a开头的 - 查询以特定字符或字符串结尾的记录 字符‘ ’ 匹 配 以 特 定 字 符 或 者 字 符 串 结 尾 的 文 本 。 ‘ s e l e c t ∗ f r o m t e s t w h e r e n a m e r e g e x p ′ a ’匹配以特定字符或者字符串结尾的文本。 `select * from test where name regexp 'a ’匹配以特定字符或者字符串结尾的文本。‘select∗fromtestwherenameregexp′a’;`
- 知道两边字符,忘记中间查询
select * from test where name regexp 'a.c' - *号匹配0-n次,+至少匹配1次
select * from test where name regexp 'ab+' - 匹配指定字符to
select * from test where name regexp 'to' - 匹配指定多个字符串
select * from test where name regexp 'to|ti' - 匹配指定的字符
select * from test where name regexp '[oi]' - 匹配指定字符之外的字符
select * from test where name regexp "[^a-e1-2]"匹配a-e和数字1-2以外的所有 - 指定字符串连续出现的次数
select * from test where name regexp 'm{2,}'
排序和分页
ASC (ascend) 升序
DESC(descend)降序
单列排序:select * from test order by id
多列排序:select * from test order by id,name desc
LIMIE 【位置偏移,】行数
set @myrnum = 0; select (@myrnum := @myrnum + 1) as ROWNUM,name from students;
使用变量,使用:=赋值,生成行号
多表联查
连接多个表至少需要n-1个连接条件
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行(交集)
外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。(左集)
如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表 。(右集)
关键字Join ,Inner Join,Cross join都表示内连接。
Mysql不支持满外连接,但是可以使用LEFT JOIN UNION RIGHT JOIN 代替
Union用来合并多条select语句的结果,列数和数据类型必须一致
Union all对两个结果集的交集不去重,Union会对交集去重。

自然连接:自动查询表中相同名字的字段,等值连接
Using的用法:
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
USING (department_id);
等于
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
on e.department_id=d.department_id;
using只能在join的时候使用,而且字段名要一致,where适用所有关联
函数
Mysql中函数分为内置函数和自定义函数,操作对象的多少分为单行和多行
单行函数:对一行进行转换返回一个结果,可以嵌套,参数是一列和一个值。
单行函数
单行函数
select abs(-12),sign(-12),PI(),CEIL(-12.5),FLOOR(-12.5),LEAST(1,5,7,9),greatest(9,4,3,7,1),MOD(12,8) ,RAND(),RAND(4),ROUND(4.12),ROUND(4.15144,2),TRUNCATE(3.14159166,3),sqrt(9);
角度弧度转换
select RADIANS(30),DEGREES(1.2);
三角函数
select sin(30);
幂运算
SELECT POW(3,2);
进制转换
SELECT BIN(12);
字符串函数
字符串编码转换
CONVERT(value USING char_code)
查看字符串编码
CHARSET(value)
SELECT CHARSET('mysql'), CHARSET(CONVERT('mysql' USING 'utf8'));
select CHAR_LENGTH('ABCDE'),LENGTH('你'),concat('你','好'),CONCAT_WS('-','你','好','啊');

select insert('abcdefg',2,1,'C'),replace('defg','d','e'),UPPER('pou'),LOWER('POU')

select LEFT('FEDCBA',1),RIGHT('abcdef',1),lpad('iii',5,'H'),rpad('H',5,'i'),LTRIM(' 1'),RTRIM('1 ');

select TRIM(' a '),TRIM('-' FROM '-ABCDE-'),TRIM(leading '-' from '-1999-03-'),trim(trailing '-' from '-1999-03-')

select field('i','o','d','c','d','q','i') as field,find_in_set('b','a,b,c,d') as find_in_set,reverse('abcd')

日期函数
获取日期
select curdate(),current_date,current_time,now(),UTC_TIME;

select unix_timestamp(),unix_timestamp(current_time),from_unixtime(unix_timestamp(current_time)) as from_unixtime;



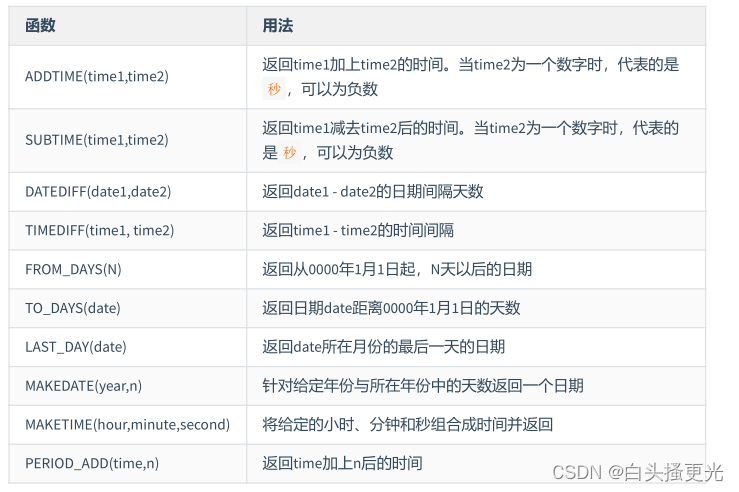
计算日期加减函数
select date_add(CURRENT_DATE,interval 1 DAY ),ADDDATE(CURRENT_DATE,interval 1 day );
```
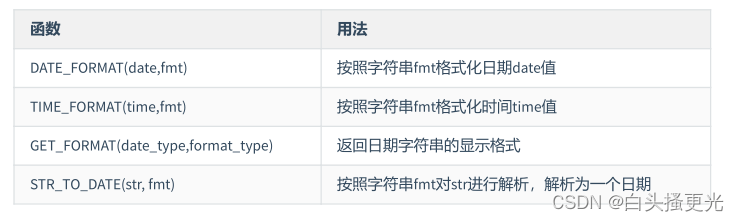
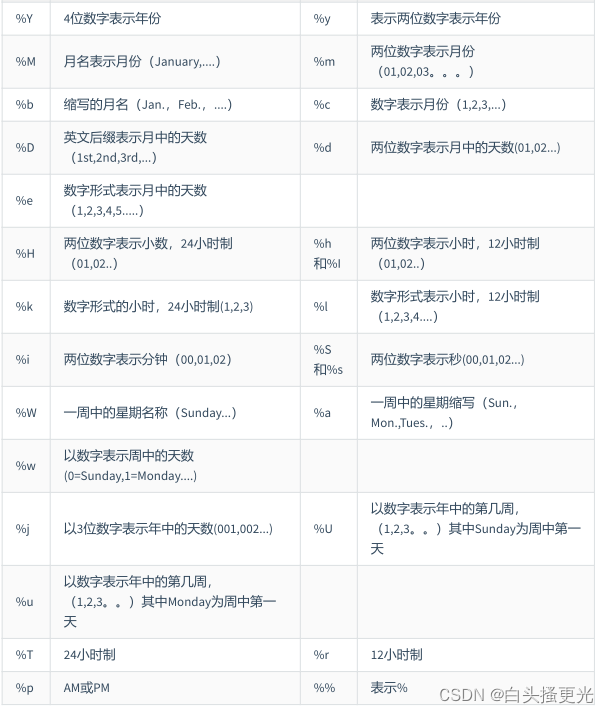
##### 日期格式化
#### 流程处理函数
查询部门为10,20,30的,10部门工资1.1倍,20部门工资1.2倍,30部门工资1.3倍
```sql
select last_name,case when department_id = 10 then salary*1.1
when department_id = 20 then salary*1.2
when department_id = 30 then salary*1.3
else salary end as salary_add
from employees where department_id in(10,20,30)
select ifnull(null,"hello world!");
select if(1>0,'true','false');
加密函数
select PASSWORD('roo!Dt444564CD'),MD5('root'),SHA('root'),decode(encode('rootD4s','root'),'root');


信息函数

聚合函数
聚合函数应用于一组数据,对一组数据返回一个值。
主要有:AVG,SUM,MAX,MIN,COUNT
-
count()和count(1),count(列)的区别?
MylSAM没有区别,因为内部有一个计数器维护行数,但是InnoDB中count()和count(1)直接读取行数,复杂度是O(n),innoDB会遍历一遍。count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。 -
ROLLUP,在groupby分组之后对分组的内容进行统计,会在所有分组记录后增加一条记录,该记录查询出的所有记录总和。
-
HAVING 子句,不能单独使用,只能跟group by一起使用,不能在where子句中使用聚合函数
select department_id from employees where department_id is not null group by department_id having max(salary) >10000;
select max(salary) as maxsalary,department_id from employees where department_id is not null group by department_id having maxsalary >10000;
WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成的。另外,WHERE排除的记录不再包括在分组中。如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。 这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用
的资源就比较多,执行效率也较低。
子查询
单行子查询
查询最低工资大于50号部门最低工资的部门id和其最低工资
select min(salary) as minsal,department_id from employees group by department_id having minsal >(select min(salary) from employees where department_id=50) ;
多行子查询
集合比较子查询,内查询返回多行,需要使用多行比较操作符
IN 比较任意一值
ANY 和某一个值比较
ALL 所有值比较
SOME ANY的别名
相关更新
#增加列
alter table employees add(department_name varchar(36));
# 根据查询更新列
update employees e SET department_name =(select department_name from departments where e.department_id=departments.department_id);
# 删除列
alter table employees drop department_name;
delete from employees where employee_id in (select employee_id from employees where salary >=9000);
自联接和子查询那个效率高?
自连接查询是对自己的数据进行判断,但是子查询是对未知表的结果进行判断。
加载数据
数据格式如下,列之间使用\t间隔(LOAD DATA默认的列间隔符),\N表示NULL
histler Gwen bird \N 1997-12-09 \N
加载文件pet.txt中的数据到表pet中,使用以下命令
create table userinfo(id int,name varchar(36),height double);
LOAD DATA LOCAL INFILE '/path/pet.txt' INTO TABLE pet LINES TERMINATED BY '\n';
- load data infile '/var/lib/mysql-files/test.text' into table userinfo;
要想使用load_file()函数加载,必须满足用户有操作目标文件的权限,并且是在制定的目录下
show global variables like '%secure%';
select load_file('/var/lib/mysql-files/test.text');

数据类型
存储引擎
约束
视图
一个或者多个数据表里的数据的逻辑表示,视图不存储数据。
为什么使用视图?
可以使用表的一部分,而不是所有的表,可以针对不同的用户制定不同的视图。视图是一种 虚拟表 ,本身是 不具有数据 的,占用很少的内存空间,它是 SQL 中的一个重要概念。视图建立在已有表的基础上, 视图赖以建立的这些表称为基表。
视图的创建和删除只影响视图本身,不影响对应的基表。但是当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化,反之亦然。可以帮助我们把经常查询的结果集放到虚拟表中,提升使用效率。
创建视图
- 在创建视图时,没有在视图名后面指定字段列表,则视图中字段列表默认和SELECT语句中的字段列表一致。如果SELECT语句中给字段取了别名,那么视图中的字段名和别名相同。
create view emp_tmp_2(emp_num,sal_tmp) as select employee_id,salary from employees;
2.可以在视图的基础上进一步创建视图
3.支持通过insert ,delete,update等对视图进行更新,视图中数据变化,表中数据也会变化。
要使视图可更新,视图中的行和底层基本表中的行之间必须存在 一对一 的关系。
不可更新视图的情况:
- 在定义视图的时候指定了“ALGORITHM = TEMPTABLE”,视图将不支持INSERT和DELETE操作;
- 视图中不包含基表中所有被定义为非空又未指定默认值的列,视图将不支持INSERT操作;
- 在定义视图的SELECT语句中使用了 JOIN联合查询 ,视图将不支持INSERT和DELETE操作;
- 在定义视图的SELECT语句后的字段列表中使用了 数学表达式 或 子查询 ,视图将不支持INSERT,也不支持UPDATE使用了数学表达式、子查询的字段值;
- 在定义视图的SELECT语句后的字段列表中使用 DISTINCT 、 聚合函数 、 GROUP BY 、 HAVING 、UNION,函数 等,视图将不支持INSERT、UPDATE、DELETE;
- 在定义视图的SELECT语句中包含了子查询,而子查询中引用了FROM后面的表,视图将不支持INSERT、UPDATE、DELETE;
视图定义基于一个 不可更新视图 ;
7.常量视图。
修改删除视图
方式1:
create or replace view view_name() as select * from 。。。。
方式2:
alter view 视图名称 as 查询语句
DROP VIEW IF EXISTS 视图名称;
**注意:**基于视图a、b创建了新的视图c,如果将视图a或者视图b删除,会导致视图c的查询失败。这样的视图c需要手动删除或修改,否则影响使用。



存储过程与函数
存储过程
含义:存储过程的英文是 Stored Procedure 。它的思想很简单,就是一组经过 预先编译 的 SQL 语句的封装。
调用过程:存储过程预先存储在 MySQL 服务器上,需要执行的时候,客户端只需要向服务器端发出调用存储过程的命令,服务器端就可以把预先存储好的这一系列 SQL 语句全部执行。
优点:
1、简化操作,提高了sql语句的重用性,减少了开发程序员的压力
2、减少操作过程中的失误,提高效率
3、减少网络传输量(客户端不需要把所有的 SQL 语句通过网络发给服务器)
4、减少了 SQL 语句暴露在网上的风险,也提高了数据查询的安全性
5.一旦存储过程被创建出来,使用它就像使用函数一样简单,我们直接通过调用存储过程名即可。相较于函数,存储过程是 没有返回值的。
DELIMITER $
CREATE PROCEDURE CountPro(in deparid int,out num int)
begin
select count(*) into num from employees where department_id=deparid;
end $
DELIMITER ;
set @num=0;
call CountPro('80',@num);
select @num;
DELIMITER $
CREATE PROCEDURE `add_num2`(IN n INT)
BEGIN
DECLARE i INT;
DECLARE sum INT;
SET i = 1;
SET sum = 0;
WHILE i <= n DO
SET sum = sum + i;
SET i = i +1;
END WHILE;
SELECT sum;
END $
DELIMITER ;
- DELIMITER 指定结束符
- create procedure 名称
- IN 类型参数只能作为输入,OUT 类型参数只能作为输出,INOUT是参数既当输入也当输出。
- begin end 结束符为结构体
- 要将结果放入变量需要用into 设置一个OUT或INOUT类型的参数进行返回。
- 最后将结束符恢复成默认的;
- 调用的时候使用call 名称调用
- 需要返回的参数要进行初始化,用select @参数名展示
- DECLARE用于在存储过程中定义变量
函数
create function 函数名(参数名 参数类型)
returns 返回值类型
【约束】
begin
end
# 调用SELECT 函数名(实参列表)

存储函数可以放在查询语句中使用,存储过程不行。
查看修改删除存储过程和函数
1.SHOW CREATE [FUNCTION,PROCEDURE] 过程名或函数名;
2.SHOW [FUNCTION,PROCEDURE] STATUS LIKE ‘SELECT%’;
直接查看information_schema库中的ROUTINES,根据类型筛选
select * from ROUTINES WHERE ROUTINE_TYPE=[FUNCTION,PROCEDURE];
DROP {PROCEDURE | FUNCTION} [IF EXISTS] 存储过程或函数的名
自定义UDF
变量,流程控制和游标
变量由系统定义,不是用户定义,属于服务器层面。
启动MySQL服务,生成MySQL服务实例期间,MySQL将为MySQL服务器内存中的系统变量赋值,这些系统变量定义了当前MySQL服务实例的属性、特征。这些系统变量的值要么是编译MySQL时参数的默认值,要么是配置文件(例如my.ini等)中的参数值。大家可以通过网址查看MySQL文档的系统变量。
每一个MySQL客户机成功连接MySQL服务器后,都会产生与之对应的会话。会话期间,MySQL服务实例会在MySQL服务器内存中生成与该会话对应的会话系统变量,这些会话系统变量的初始值是全局系统变量值的复制。
变量有:全局系统变量,会话系统变量,默认是会话级别的。静态变量(在 MySQL 服务实例运行期间它们的值不能使用 set 动态修改)属于特殊的全局系统变量。
全局变量对所有的连接有效,但是不能在mysql重启的时候共用。会话1对某个全局变量的修改会导致其他会话的这个变量的更新。
系统变量查询
#查看所有全局变量
SHOW GLOBAL VARIABLES [LIKE '%标识符%'];
#查看所有会话变量
SHOW SESSION VARIABLES;
SHOW VARIABLES;
# 查看某个变量
#查看指定的系统变量的值
SELECT @@global.变量名;
#查看指定的会话变量的值
SELECT @@session.变量名;
#或者
SELECT @@变量名;
系统变量修改
- 直接修改mysql的启动文件
- 通过set设置
SET @@global[session].变量名=变量值;
SET GLOBAL[session] 变量名=变量值;
用户变量
用户变量和会话变量一样,只对当前连接的会话有效,局部变量只在当前的begin - end语句块中有效。局部变量只能在存储过程和函数中使用。
触发器
主要针对有必然关联的两件事情之间进行绑定的需求,由某个事件来触发,所谓事件就是指
用户的动作或者触发某项行为。如果定义了触发程序,当数据库执行这些语句时候,就相当于事件发生了,就会自动激发触发器执行相应的操作。当对数据表中的数据执行插入、更新和删除操作,需要自动执行一些数据库逻辑时,可以使用触发器来实现。
实例:插入一张表的同时,根据判断去更新另一张表
DROP TRIGGER IF EXISTS insert_before_check;
delimiter $
create trigger insert_before_check
before insert on hello_log for each row
begin
IF LENGTH(NEW.log) != 0 THEN
insert into length_log values(10 * LENGTH(NEW.log));
end if ;
end $
delimiter ;
查看触发器
show triggers;
show create triggers 触发器名;
show * from infomation_schema.TRIGGERS;
drop trigger if exists 触发器名称;
优点:
1.触发器可以确保数据的完整性。每当一张表输入,修改更新操作的时候,自动触发对应的业务处理。
2.触发器可以帮我们记录操作日志。什么时间发生了什么事情,方便定位问题。
3.对数据进行合法性检查等逻辑。
缺点:
1.可读性差,如果触发器有异常会出现应用方面的错误,不了解触发器很难解决问题。
2.数据表结构的变更会影响触发器的错误,比较隐蔽影响排查效率。
外键的修改不会引起字表的触发器

事件
MySQL 事件是根据计划运行的任务。因此,我们有时将它们称为 预定事件。当创建一个事件时,SQL 语句将在一个或多个固定时间间隔执行,在特定日期和时间开始和结束。从概念上讲,这类似于 Unix crontab (也称为“ cron 作业”)或 Windows 任务计划程序的想法。计划任务有时也被称为 “时间触发器”,意味着这些是随着时间的推移而触发的对象。
触发器是响应特定类型的事件而执行,但是事件是通过预先指定的时间间隔来执行的。
实例:创建一个时间每一分钟插入一条数据到log表中
# 1.创建存储过程,插入数据
drop procedure if exists printhello;
delimiter $
create procedure printhello()
begin
create table if not exists hello_log(log varchar(36));
insert into hello_log values('hello world,schduler!');
end$
delimiter ;
# 2.创建事件,定时调用
# 创建定时任务,定时打印helloworld
DROP EVENT IF EXISTS print_hello_sche;
delimiter $$
create event print_hello_sche
on schedule every 1 minute starts timestamp '2022-04-24 15:30:30'
on completion preserve
# 当事件运行完毕,不对事件删除,on completion not preserve则删除
do
begin call printhello;
end$$
delimiter ;;
定义条件
定义条件就是给MySQL中的错误码命名,这有助于存储的程序代码更清晰。它将一个 错误名字 和 指定的错误条件 关联起来。这个名字可以随后被用在定义处理程序的 DECLARE HANDLER 语句中。
DECLARE 错误名称 CONDITION FOR 错误码(错误条件)
#错误码可以参考mysql官方错误码MYSQL——error——code,sqlstate_value是字符类型的错误代码
delimiter $
create procedure InsertDataWithCondition()
begin
declare duplicate_entry condition for sqlstate '23000';
# 定义错误条件duplicate_entry为23000
declare exit handler for duplicate_entry set @pro_value =-1;
#定义duplicate_entry 的exit处理程序,可以是复合语句
set @x =-1;
select * from depat_tmp;
end $
delimiter ;
流程控制
IF
drop procedure if exists update_salary_5yarn;
DELIMITER $
CREATE PROCEDURE update_salary_5yarn(in emp_id INT)
begin
DECLARE emp_salary DOUBLE;
DECLARE emp_year DOUBLE;
# 定义两个变量进行接收
select **employees.salary,DATEDIFF(current_date(),hire_date)/365 into emp_salary,emp_year** from employees where employee_id=emp_id;
#查询出对应的变量值,多个变量复制方法
IF emp_salary < 8000 and emp_year > 5
then update employees set salary=salary+500 where employee_id=emp_id;
elseif emp_year > 5
then update employees set salary=salary+200 where employee_id=emp_id;
else update employees set salary=salary+100 where employee_id=emp_id;
end if;
end $
DELIMITER ;
case when
# 创建存储过程update_salary_by_eid5
#声明存储过程update_salary_by_eid5,定义IN参数emp_id,输入员工编号。判断该员工的
#入职年限,如果是0年,薪资涨50;如果是1年,薪资涨100;如果是2年,薪资涨200;如果是3年,
#薪资涨300;如果是4年,薪资涨400;其他的涨薪
show create table employees;
delimiter $
create procedure update_salary_by_eid5(in emp_id int,out upsalary double)
begin
declare year_num double;
declare upsalary_bum double;
select round(datediff(current_date(),hire_date)/365) into year_num from employees where employee_id=emp_id;
case year_num
when 0 then set @upsalary_bum:=50;update employees set salary=salary+50 where employee_id=emp_id;
when 1 then set @upsalary_bum:=100;update employees set salary=salary+100 where employee_id=emp_id;
when 2 then set @upsalary_bum:=200;update employees set salary=salary+200 where employee_id=emp_id;
when 4 then set @upsalary_bum:=300;update employees set salary=salary+300 where employee_id=emp_id;
when 5 then set @upsalary_bum:=400;update employees set salary=salary+400 where employee_id=emp_id;
else set @upsalary_bum:=500;update employees set salary=salary+500 where employee_id=emp_id;
end case;
end;
delimiter ;
loop (while true)
LOOP循环语句用来重复执行某些语句。LOOP内的语句一直重复执行直到循环被退出(使用LEAVE子句),跳出循环过程
# loop,重复执行,直到循环推出,while true
# 循环涨薪,直到公司平均工资为12000位置,并且统计循环次数
delimiter $
create procedure loop_upsalary(out num int)
begin
declare up_num int default 0;
# 定义默认值
declare avg_sal double;
add_loop:LOOP
# 定义loop,命名
select avg(salary) into avg_sal from employees;
if avg_sal >12000 then leave add_loop;
else
update employees set salary=salary+100;
set up_num=up_num+1;
end if ;
end loop add_loop;
# 退出指定的loop
set num=up_num;
end $
delimiter ;
set @num=0;
call loop_upsalary(@num);
select @num;
while
WHILE语句创建一个带条件判断的循环过程。WHILE在执行语句执行时,先对指定的表达式进行判断,如果为真,就执行循环内的语句,否则退出循环。WHILE语句的基本格式如下:
DELIMITER //
CREATE PROCEDURE update_salary_while(OUT num INT)
BEGIN
DECLARE avg_sal DOUBLE ;
DECLARE while_count INT DEFAULT 0;
SELECT AVG(salary) INTO avg_sal FROM employees;
WHILE avg_sal > 5000 DO
UPDATE employees SET salary = salary * 0.9;
SET while_count = while_count + 1;
SELECT AVG(salary) INTO avg_sal FROM employees;
END WHILE;
SET num = while_count;
END //
DELIMITER ;