(ICCV-2021)通过有效的全局-局部特征表示和局部时间聚合进行步态识别(三)
4. Experiments
4.1. Datasets
\quad \quad 在两个常用数据集上评估了所提出方法的性能,即CASIA-B和 OUMVLP数据集。
\quad \quad CASIA-B. CASIA-B数据集是最大的跨视角步态数据库。它包括124个受试者,每个受试者有10组视频。10组视频中,6组是正常行走(NM),2组是背着包行走(BG),2组是穿着外套行走(CL)。每组包含11个不同角度的步态序列(0°-180°,采样间隔为18°)。因此,CASIA-B 中有 124 (subject) × 10 (groups) × 11 (view angle) = 13 , 640 124\text{(subject)}\times10\text{(groups)}\times11\text{(view angle)} = 13,640 124(subject)×10(groups)×11(view angle)=13,640个步态序列。每个受试者的步态序列分为训练集和测试集。在训练阶段,根据不同的训练规模配置三种训练设置:小规模训练(ST)、中规模训练(MT)和大规模训练(LT)。对于这三种设置,分别选择 24、62 和 74 名受试者作为训练集,其余 100、62 和 50 名受试者分别用于测试。来自训练集的所有步态数据用于在训练阶段训练所提出的模型。在测试阶段,将序列NM#01-NM#04作为注册集,而考虑序列NM#05-NM#06、BG#01-BG#02和CL#01-CL#02作为验证集来评估性能。
\quad \quad OU-MVLP. OUMVLP 数据集是规模最大的步态识别数据库之一,共包含 10,307 个受试者。每个受试者包含两组视频,Seq#00 和 Seq#01。每组视频从 14 个角度捕获:0°-90° 和 180°-270°,采样间隔为 15°。采用的协议为:5,153名受试者作为训练数据,5,154名受试者作为测试数据来评估所提出方法的性能。在测试阶段,Seq#01中的序列作为注册集,Seq#00中的序列作为验证集进行评估。
4.2. Implementation Details
\quad \quad 采用与GaitSet相同的预处理方法来获得 CASIA-B 和 OUMVLP 数据集的步态轮廓。每帧的图像都归一化为 64 × 44 64\times44 64×44 的大小。网络参数如表1所示。三元组损失公式中的 m m m设置为 0.2。GeM公式中的 p p p被初始化为6.5。CASIA-B 数据集中的批大小参数 P P P和 K K K均设置为 8。由于OUMVLP数据集比CASIA-B大得多,因此批大小 P × K P\times K P×K设置为 32 × 8 = 256 32\times 8 = 256 32×8=256。在训练阶段,输入步态序列的长度设置为30。在测试阶段,将整个步态序列放入所提出的模型中以提取步态特征。在 ST、MT 和 LT 的设置中,epoch数分别设置为 60K、80K 和 80K。所有的实验都以 Adam 作为优化器。 CASIA-B 数据集的权重衰减设置为5e-4。对于ST的设置,学习率设置为1e-4。对于MT和LT的设置,学习率首先设置为1e-4,70K次迭代后重置为1e-5。对于 OUMVLP 数据集,epoch数设置为 210K。学习率首先设置为1e-4,在 150K 和 200K 迭代后分别重置为 1e-5 和 5e-6。特别的,因为OUMVLP的ID比CASIA数据集多100倍,所以将标签平滑操作加入交叉熵损失中。对于 OUMVLP 数据集,权重衰减首先设置为 0,然后在200K后重置为 5e-4。
表 1. 所提出方法的网络结构。

4.3. Comparison with State-of-the-Art Methods
Evaluation on CASIA-B. 在CASIA-B上,将所提出的方法与最新的步态识别方法进行比较,包括ViDP、CMCC、GaitSet、AE、MGAN、CNN-LB、CNN-3D、CNN-Ensemble、ACL和GaitPart。实验结果如表2所示。可以观察到,所提出的方法几乎在所有角度都达到了最佳识别精度。通过考虑不同的条件(NM、BG 和 CL)和不同的数据集规模进一步详细分析比较结果。
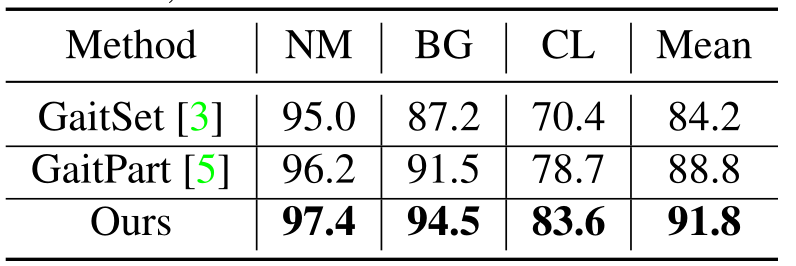
\quad \quad 首先探索不同条件(NM、BG 和 CL)的影响。从表2可以观察到,当外部环境发生变化时,准确率显著下降。例如,在设置为LT的情况下,GaitPart 在 NM、BG 和 CL 三个条件下的识别准确率分别为 96.2%、91.5% 和 78.7%。对于所提出的方法,在这些条件下的识别准确率为 97.4%、94.5% 和 83.6%,分别比 GaitPart 高 1.2%、3.0% 和 4.9%。实验结果表明,该方法在 BG 和 CL 条件下具有显著优势,表明该模型可以提取更鲁棒的步态特征。即使在 ST 和 MT 设置中,也可以看到相似的识别结果,该方法也获得了最佳性能。另一方面,可以从真实场景中的任意视角和条件收集人类步态。因此,可以着重研究在各种外部环境因素下步态识别的稳健性。基于表2,进一步计算三个条件的平均准确率。表3显示了所提出的方法与最先进的步态识别方法的比较结果,包括GaitSet和GaitPart。可以观察到,该方法的平均准确率为 91.8%,分别优于 GaitSet 和 GaitPart 7.6% 和 3.0%。
\quad \quad 还讨论了不同数据集规模设置的比较结果。Chao等人提供了一个评估协议,在CASIA-B上,方法的性能在三个不同的尺度上进行评估,即ST、MT和LT。本文展示了这三种设置的完整实验结果。实验结果如表2所示。可以观察到,在 NM 条件下,GaitSet对于三种设置的识别准确率分别为 79.5%、92.0% 和 95.0%。对于所提出的方法,相应的识别准确率分别为 86.0%、95.9% 和 97.4%,分别提高了 6.5%、3.9% 和 2.4%。具体来说,所提出的方法可以在小规模数据集的设置上取得较大的改进。
表 2. CASIA-B 在所有视角、不同设置和条件下的 Rank-1 准确度 (%),不包括相同视图的情况。

表 3. 在 NM、BG 和 CL 条件下与 GaitSet和 GaitPart的比较。
Evaluation on OUMVLP. 进一步评估了该方法在 OUMVLP 数据集上的性能。为了公平比较,采用与 GaitSet 和 GaitPart 方法相同的训练和测试协议。10307 名受试者分为两组,其中 5153 名受试者用于训练,其余受试者用于测试。在测试阶段,Seq#00被视为probe,Seq#01被当作gallery。表4展示了本文的方法与几种著名算法的比较结果,包括GEINet、GaitSet、GaitPart和GLN。可以看出,本文的方法在大多数情况下都能达到最好的识别性能。
表 4. OUMVLP 在 14 个probe视角下(不包括相同视角案例)的 Rank-1 准确度 (%)。

4.4. Ablation Study
\quad \quad 在本文中,所提出的识别框架包括几个关键模块,例如局部时间聚合、全局和局部特征提取器和广义均值池化层。因此,设计了不同的消融研究来分析每个关键模块的贡献。
Analysis of GLFE module. 与大多数仅提取全局或局部步态特征的步态识别方法不同,本文提出了一种新的全局和局部特征提取器来提取步态特征,其中包含更全面的步态信息。GLFE 模块由三个全局和局部卷积层组成,即GLconv层,每个层包括一个全局分支和一个局部分支。为了探索全局和局部分支的贡献,设计了消融研究来探索不同分支的作用。所有实验均在设置 LT 下进行。实验结果如表5所示。可以观察到,在 NM 条件下,使用全局或局部分支的准确率分别为 97.1% 和 96.2%,而同时使用两个分支的准确率分别为 97.4%,分别提高了 0.3% 和 1.2%。同时,全局和局部卷积层也提高了 BG 和 CL 条件下的性能。与仅使用全局或局部特征相比,GLconv 提取的步态特征可以更好地表示步态信息。此外,GLconv的局部分支可以产生不同的分区。为了探索 GLConv 层中的最佳分区,通过设置不同的分区来进一步设计消融研究。表5表明,分区的数量对准确性的影响很弱。例如,N=2、N=4、N=8的GLFE模块在NM条件下的准确率分别为97.3%、97.4%、97.4%。在本方法中,最终选择了N=8的GLFE模块来实现模型。
表5. 在CASIA-B上GLFE模块中不同组合的rank-1准确性(%)。"GLConvA-1 "和 "GLConvA-2 "是第一和第二个GLConvA模块。

空间特征映射分析。 传统的空间特征映射使用
F
Max
(
⋅
)
F_{\text {Max }}(\cdot)
FMax (⋅)或
F
A
v
g
(
⋅
)
F_{A v g}(\cdot)
FAvg(⋅)来聚合空间信息。然而,仅使用
F
Max
(
⋅
)
F_{\text {Max }}(\cdot)
FMax (⋅)、
F
A
v
g
(
⋅
)
F_{A v g}(\cdot)
FAvg(⋅)或它们的加权和,不能自适应地实现映射。在本文中,引入 GeM 池化来实现空间特征映射。为了验证 GeM 池化层的有效性,通过在 CASIA-B 数据集上实施具有不同空间特征映射策略的方法来设计比较实验。所有实验都是在LT设置下实现的。实验结果如表6所示。可以观察到,
G
e
M
(
⋅
)
G e M(\cdot)
GeM(⋅)的精度在所有条件下均达到最高的平均精度。具体来说,
F
Max
1
×
1
×
W
2
(
⋅
)
F_{\operatorname{Max}}^{1 \times 1 \times W_{2}}(\cdot)
FMax1×1×W2(⋅)和
G
e
M
(
⋅
)
G e M(\cdot)
GeM(⋅)的平均准确率分别为 91.3% 和 91.8%,这意味着 GeM pooling 可以获得更鲁棒的特征表示。此外,在BG和CL设置的条件下,GeM池化的表现比所有对比的的池化方法更好。例如,
G
e
M
(
⋅
)
G e M(\cdot)
GeM(⋅)在 BG 和 CL 设置上分别优于
F
Max
1
×
1
×
W
2
(
⋅
)
F_{\operatorname{Max}}^{1 \times 1 \times W_{2}}(\cdot)
FMax1×1×W2(⋅) 0.5% 和 1.1%。
表 6 不同空间特征映射的准确率(%)

局部时间聚合分析。 为了保持更多的空间信息,引入了局部时间聚合操作来代替传统步态识别方法中使用的第一个空间池化层。为了分析 LTA 操作的贡献,设计了具有不同下采样策略的方法。实验是在 CASIA-B 数据集上使用 LT 设置进行的。实验结果如表7所示。可以观察到使用两个空间池化层的准确率是96.3%,而“LTA+SP”的准确率是97.4%,说明使用LTA操作比只使用空间池化可以获得更好的性能。此外,还通过用 LTA 操作替换空间池化来构建模型。但是,此设置的准确性已大大降低。原因可能是两次 LTA 操作使更多的时间信息丢失。因此,采用“LTA+SP”模式作为本方法中的最终下采样策略。
表 7. 不同下采样组合的准确率(%)

5. Conclusion
\quad \quad 本文提出了一个新的步态识别框架,在三维卷积公式下产生判别性的特征表示。首先,为了提取更全面的步态信息,提出了一个全局和局部特征提取器来提取稳健的步态特征进行表示。其次,为了利用更多信息,还探索了不同下采样方法的效果,并引入了局部时间聚合来代替传统的空间池化层。此外,引入了广义均值池化层来自适应地聚合空间信息,从而提高特征映射性能。在公共数据集上的实验结果验证了所提方法的有效性。