IEnumerable类中的 Any方法,表示集合中有任何一元素满足条件,返回就true , 该方法有两个重载
1. 不带任何参数,表示集合中有元素
2. 参入一个 Func<TSource, bool> 委托 , 如果集合中有任何一个元素满足该条件就返回true int[] array = { 1, 2, 3 }; // See if any elements are divisible by two. bool b1 = array.Any(item => item % 2 == 0); // See if any elements are greater than three. bool b2 = array.Any(item => item >3); // See if any elements are 2. bool b3 = array.Any(item => item == 2); // Write results.
角度 a a/180 * pi 转化为弧度 pi = 2acos(0.0) ,可以求出π的值 在实际程序中一般都采用下面的方法 a *= acos(0.0)/90.0;
平时喜欢在电影天堂下载一些电影看,然后发现有一些电影是mkv格式的,然后什么爱奇艺、暴风影音之类的播放器都播放不了,各种百度结果是让我下载什么MXPlayer,记不住了,反正各种,但是各种用不了,各种不好使,让我一度很苦恼,mac到底怎么样才能看mkv格式的电影啊[抓狂]!!!!!!!!
吐槽完毕,进入正文
其实非常简单!!!!!!!!! 我们不都是用迅雷下载的嘛,下载过程中会有一个边下边播!点一下!就会弹出一个XLPlayer!!!!!就是他!然后你右键保留到Dock,从此你不需要再下载多余的播放器!一个字!爽!
分享给大家!
首先说明我是在JSP中使用ajaxSubmit()的,我的目的是在jsp页面提交表单到servlet,保证当前页面不刷新且不跳转。
遇到了好多问题,第一个问题就是百度了很多ajaxSubmit()用法,也是各种奇葩,种种坑爹的用法我就不一一列举了,避免看到我博客的人跟我一样遇到很多烦心的为题,直接贴上我的用法: 1.在html页面中引入以下两个.js文件,注意路径
<span style="font-family: Arial, Helvetica, sans-serif;"><script type="text/javascript" src="assets/js/jquery-2.0.3.min.js"></script></span> <script type="text/javascript" src="assets/js/jquery-form.js"></script> 备注:JQuery的版本要在1.5及1.5以上,原因可以看如下加大红色字体,官方解释如下:
<span style="font-size: 14px;">/*! * </span><strong><span style="font-size:24px;color:#cc0000;">jQuery Form Plugin</span></strong><span style="font-size: 14px;"> * version: 3.18 (28-SEP-2012) * @</span><span style="font-size:24px;color:#cc0000;"><strong>requires jQuery v1.5 or later</strong></span><span style="font-size: 14px;"> * * Examples and documentation at: http://malsup.com/jquery/form/ * Project repository: https://github.com/malsup/form * Dual licensed under the MIT and GPL licenses: * http://malsup.github.com/mit-license.txt * http://malsup.github.com/gpl-license-v2.txt */ /*global ActiveXObject alert */</span> 2.html中表单元元素如下:
<form id="surveyForm"> .
(1) 功能:判断m是否为素数,若是返回1,否则返回0。
#include <stdio.h>
/**********FOUND**********/
void fun( int n)
{
int i,k=1;
if(m<=1) k=0;
/**********FOUND**********/
for(i=1;i<m;i++)
/**********FOUND**********/
if(m%i=0) k=0;
/**********FOUND**********/
return m;
}
void main()
{
int m,k=0;
for(m=1;m<100;m++)
if(fun(m)==1)
{
printf("%4d",m);k++;
if(k%5==0) printf("\n");
}
}
(2)功能:在一个已按升序排列的数组中插入一个数,插入后,数组元素仍按升序排列。
#include <stdio.h>
#define N 11
main()
{ int i,number,a[N]={1,2,4,6,8,9,12,15,149,156};
printf("please enter an integer to insert in the array:\n");
/**********FOUND**********/
scanf("%d",&number) printf("The original array:\n");
for(i=0;i<N-1;i++)
printf("%5d",a[i]);
printf("\n");
/**********FOUND**********/
for(i=N-1;i>=0;i--)
if(number<=a[i])
/**********FOUND**********/
a[i]=a[i-1];
else
github上有很多弧形或者圆形的ProgressBar和SeekBar。前几天无意中发现一个弧形的ProgressBar觉得挺不错的,就下载来看看源码。ColorArcProgressBar 地址是这个:https://github.com/Shinelw/ColorArcProgressBar 运行他的Demo的时候发现几个问题,并且有些问题在issue里面也有人提出了,但是作者一直没有回复,我把问题修复之后加上了Seek的功能,让它能当做SeekBar用。
原作者的Demo效果图 存在的问题: 不能通过XML配置控件的大小,源码里面写死了,写成占屏幕的百分比。有几个属性的颜色值设置无效。比如默认的弧形背景色放大缩小控件之后对应的字体没有相应的调整大小 需要考虑的问题点: 我们从最下面带刻度带提示的效果图入手
####我们呢先分析原作者的代码:
package com.shinelw.colorarcprogressbar; import android.animation.ValueAnimator; import android.content.Context; import android.graphics.Canvas; import android.graphics.Color; import android.graphics.Matrix; import android.graphics.Paint; import android.graphics.PaintFlagsDrawFilter; import android.graphics.RectF; import android.graphics.SweepGradient; import android.util.AttributeSet; import android.util.DisplayMetrics; import android.view.View; import android.view.WindowManager; /** * colorful arc progress bar * Created by shinelw on 12/4/15. */ public class ColorArcProgressBar extends View{ private int mWidth; private int mHeight; //直径 private int diameter = 500; private RectF bgRect; //圆心 private float centerX; private float centerY; private Paint allArcPaint; private Paint progressPaint; private Paint vTextPaint; private Paint hintPaint; private Paint degreePaint; private Paint curSpeedPaint; private float startAngle = 135; private float sweepAngle = 270; private float currentAngle = 0; private float lastAngle; private int[] colors = {Color.
OLED一款小巧的显示屏,感觉可以做出很可爱的东西。
这次实验的这款是128X64的OLED屏幕 ,
芯片是SSD1306,请确认自家模块芯片型号,不然对不上号啊
使用IIC的方法,简单实验显示示例程序。
(请确认你手头上的模块可以IIC连接,若干不支持那只能SPI方式接线)
先实现连接与显示,之后再进行更深入的应用。
任意门:
Arduino Uno 驱动OLED进阶 显示中英文字
Arduino Uno 驱动OLED进阶 显示图片
Arduino Uno 驱动OLED进阶 显示几何动画
编译的过程,可能会遇到以下问题:
①提示错误
#error("Height incorrect, please fix Adafruit_SSD1306.h!"); 错误信息意思是指:
高度不正确,请修正Adafruit_SSD1306.h!
进入Arduino安装文件夹的libraries文件夹的Adfruit_SSD1306-master 找到Adafruit_SSD1306.h
打开此文件,找到第70行左右
默认是定义 SSD1306_128_32 ,由于我们使用的是128*64的OLED,所以,把原来的#define SSD1306_128_32,前面加上//
把#define SSD_128_64 前面的//去掉 最后就如上面图例一样
②模块的IIC 地址问题
模块的地址修改在这个位置,示例程序的61行
这个模块地址我用的是这个,但每个模块可能不一样,具体请咨询购买的商家,又或者可以参考下面链接的,IIC搜索地址程序。
任意门:Arduino 和LCD1602液晶屏 I2C接口实验
实验效果 BOM表 Arduino Uno *1
OLED 128*64 *1
跳线若干
针脚说明 VCC 接3.3v电源
GND 接地(GND)
SCL 时钟线
SDA 数据线
接线图 程序开源代码 在上代码之前,先下载两个库分别是
Adafruit SSD1306 Library:
初学tensorflow,如果写的不对的,请更正,谢谢!
tf.reshape(tensor, shape, name=None) 函数的作用是将tensor变换为参数shape的形式。 其中shape为一个列表形式,特殊的一点是列表中可以存在-1。-1代表的含义是不用我们自己指定这一维的大小,函数会自动计算,但列表中只能存在一个-1。(当然如果存在多个-1,就是一个存在多解的方程了)
好了我想说的重点还有一个就是根据shape如何变换矩阵。其实简单的想就是,
reshape(t, shape) => reshape(t, [-1]) => reshape(t, shape)
首先将矩阵t变为一维矩阵,然后再对矩阵的形式更改就可以了。
官方的例子:
# tensor 't' is [1, 2, 3, 4, 5, 6, 7, 8, 9] # tensor 't' has shape [9] reshape(t, [3, 3]) ==> [[1, 2, 3], [4, 5, 6], [7, 8, 9]] # tensor 't' is [[[1, 1], [2, 2]], # [[3, 3], [4, 4]]] # tensor 't' has shape [2, 2, 2] reshape(t, [2, 4]) ==> [[1, 1, 2, 2], [3, 3, 4, 4]] # tensor 't' is [[[1, 1, 1], # [2, 2, 2]], # [[3, 3, 3], # [4, 4, 4]], # [[5, 5, 5], # [6, 6, 6]]] # tensor 't' has shape [3, 2, 3] # pass '[-1]' to flatten 't' reshape(t, [-1]) ==> [1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 5, 5, 6, 6, 6] # -1 can also be used to infer the shape # -1 is inferred to be 9: reshape(t, [2, -1]) ==> [[1, 1, 1, 2, 2, 2, 3, 3, 3], [4, 4, 4, 5, 5, 5, 6, 6, 6]] # -1 is inferred to be 2: reshape(t, [-1, 9]) ==> [[1, 1, 1, 2, 2, 2, 3, 3, 3], [4, 4, 4, 5, 5, 5, 6, 6, 6]] # -1 is inferred to be 3: reshape(t, [ 2, -1, 3]) ==> [[[1, 1, 1], [2, 2, 2], [3, 3, 3]], [[4, 4, 4], [5, 5, 5], [6, 6, 6]]] # tensor 't' is [7] # shape `[]` reshapes to a scalar reshape(t, []) ==> 7
1.简单发送Get请求
/// <summary> /// 指定Url地址使用Get 方式获取全部字符串 /// </summary> /// <param name="url">请求链接地址</param> /// <returns></returns> public static string Get(string url) { string result = ""; HttpWebRequest req = (HttpWebRequest)WebRequest.Create(url); HttpWebResponse resp = (HttpWebResponse)req.GetResponse(); Stream stream = resp.GetResponseStream(); try { //获取内容 using (StreamReader reader = new StreamReader(stream)) { result = reader.ReadToEnd(); } } finally { stream.Close(); } return result; } 2.带请求参数的Get方法 /// <summary> /// 发送Get请求 /// </summary> /// <param name="url">地址</param> /// <param name="
据我所知到目前为止只有xilinx的FPGA支持动态局部重配置(DPR)。现在Altera的FPGA也支持部分重配置了。
FPGA的重配置(也叫重构)分为全重构和局部重构,全重构是将整体bitstream 文件download 到FPGA中。局部重构相对复杂,这项技术允许在FPGA内固定逻辑(fixed logic)正常运行时,对重构区域中的逻辑进行动态局部重配置。DPR可以使FPGA内的硬件资源实现分时复用,提高资源的使用率……(还有很多好处, 我在这里就不一一列举了,从现在对这项技术研究的人越来越多,就知道这项技术很好的)
动态局部重配置(DPR)基于FPGA的模块化设计,将整体设计划分为若干模块,这些模块中有些是不可重构的,有些是可重构的。DPR中各个模块所占的硬 件区域划分还有一些要求。由于Xilinx多数系列FPGA的配置bitstream的最小寻址单位是frame(1bit宽,以芯片高为长),所以配置 的最小单位必须是frame,这样就限制了重构区域的划分必须是纵向的一维划分(芯片的左下是坐标原点,纵向划分指划分X轴,不划分Y轴),因为如果横向 的划分,一个frame就会被分开,在配置时无法寻址。
各个模块实现在各自的区域中,那么各模块间的通信是怎样实现的那?在FPGA内信号的传递是通过布线资源实现的,两个模块A、B要实现通信既是将A的信号 线与相映的B的信号线相连,由于ise的自动布线无法指定某条信号线布在哪里,所以相邻两个模块的信号线不能保证相连。这样在DPR中就需要一个固定的结 构跨居在两个模块边界上,使各模块在各自的区域内分别与这个固定的结构相连,这样各个模块既可以在规定的区域内实现又可以与邻近模块进行通信。这个固定结 构就是“总线宏”(bus macro)。
9 bitstream中的“frame”
Xilinx FPGA bitstream中的配置数据是由帧(frame)组成的。帧是配置数据中的最小单元
很多时候,出于商业文件的保密性,Excel文件制作者会设置文件使用一定期限后,禁止再使用即让文件自行销毁,这在工作中是很重要的一项Excel技能,上一篇单独记录了 Excel文件自毁VBA指令,这里再结合实际,调用Excel工作簿的Workbook_Open()事件,使Excel工作簿达到使用天(30天)数后,只要用户打开文件它就会自动删除。 1.打开VBE代码编辑窗口,双击”ThisWorkbook”,输入如下代码:
Private Sub Workbook_Open() If DateDiff("d", DateSerial(2016, 11, 1), Date) = 30 Then MsgBox "此文件有效期为30天,目前使用期限已到,请下载最新版本!", 48, "温馨提醒您:" Call KillThisWorkbook Else Exit Sub End If End Sub 2.插入新的模块,输入以下代码:
Sub KillThisWorkbook() Application.DisplayAlerts = False With ThisWorkbook .Saved = True .ChangeFileAccess xlReadOnly Kill .FullName .Close End With Application.DisplayAlerts = True End Sub 3.保存,退出;
当时在代码中调用Dubbo服务时产生这个异常。
javax.servlet.ServletException: org.glassfish.jersey.server. ContainerException: java.lang.NoClassDefFoundError: Could not initialize class com.xxxx.report.api. ReportApiProvider$ReportApiProviderHolder dubbo消费端代码结构如下:
public abstract class AbstractApiProvider { //省略 ... protected ResourceBundle dubboConsumer = ResourceBundle.getBundle("consumer/dubbo-consumer"); // 省略 ... } public class ReportApiProvider extends AbstractApiProvider { private ReportApiProvider() { } private static class ReportApiProviderHolder { private static final ReportApiProvider singleton = new ReportApiProvider(); } static ReportApiProvider getInstance() { return ReportApiProviderHolder.singleton; } public static ReportService getReportService(){ return getInstance().getBean(ReportService.class); } } 调用getInstance()报错,但tomcat中却没有有效的日志,只有NoClassDefFoundError及调用栈信息。看到错误首先检查内部类相关的class是否成功编译,一切正常。
随后在排查过程中并未仔细检查父类AbstractApiProvider对资源的加载,导致排查多花了些时间。因为在父类中还完成了很多初始化工作,而且需要依赖很多其它的包。于是排查哪个包出现问题,通过每次替换一半的正常的依赖包并启动程序观察结果,于是很快定位到一个依赖包,替换了这个包后异常除。
APP上线前测试,无外乎
一:用数据线真机调试(以前需要下载真机调试证书)
二:打.ipa包给测试人员(上限100人)
2.1 打包APP的.ipa 包给测试人员之前,如果没有添加设备的UDID号, 先进入苹果开发者中心(添加了直接跳到2.6)
2.2点击 账户--登录(sing in )-- 配置文件
2.3然后点击 设备Devices-All ----点击右上方“+”号,出现下图所示:
(上边的添加账号是一个一个的添加,下边的添加账号是通过txt文件的方式添加多个,最多100个,点击蓝色字体下载文件夹如图
打开后
如果是手机,就选择ios.txt,在文件里边添加手机的UDID,并自定义设备名字,注意名字如果是中文的话,回事乱码的,建议英文名或拼音)
2.4 如何获取手机的UDID?我去···
2.4.1----iTunes------ 1:手机连接电脑
2:打开iTunes(会自动弹出),点击手机标示
3:点击 -摘要
4:点击右侧 序列号:后的数字,即出现UDID,
5:右键点击拷贝即可
2.4.2--------itools--------
1:点击打开(如果你安装了的话,会自动弹出窗口,也可以点击菜单栏图标打开),然后点击----摘要--更多
2:下边的设备标示就是UDID了,mac电脑双击拷贝就OK了:
2.5 单个添加:我们添加一个设备--名字和UDID
然后continue ,出现如图,点击register 成功界面
多个添加:
然后如图,点击continue
出现列表界面,和单个添加相似,只是多了几个而已
当然如果你已经添加过一些设备了,会弹出提示界面告诉你那个添加完了
2.6 配置文件即pp文件
1:点击配置文件 development 或者distribution
2:选取开发者 模式(注意:如果只是开发时给别人测试用,不急于上线,完全不用选Ad Hoc 的,一样可以打包发送到手机上(导出 Adhoc 的讲解 链接奉上:http://blog.csdn.net/yuanbohx/article/details/9213879 ))
2.1:选development(选第一个)
然后继续continue ,为配置文件命名一下,建议日期+项目名+用途(开发还是发布),选择你想添加的设备
(我全选了,没其他的设备了)
最后,下载文件,双击安装
2.7,下边打开Xcode
进入你的工程,点击 项目名--TARGETS--buildSetting 把滚动条拉倒大概中间的位置 找到 setting--检查刚才的配置文建是否安装成功
2.8 然后 项目名后 选择设备 --Generic iOS Device command+b ,编译一下,没有错误
Windows下bat脚本设置和获取环境变量
:: 设置环境变量 :: 关闭终端回显 @echo off set ENV_PATH=%PATH% @echo ====current environment: @echo %ENV_PATH% :: 添加环境变量,即在原来的环境变量后加上英文状态下的分号和路径 set MY_PATH=D:\test\ set ENV_PATH=%PATH%;%MY_PATH% @echo ====new environment: @echo %ENV_PATH% pause 运行效果:
在网上看到很多人都在问自定义View中,使用invalidate()方法并不会不调用onDraw(),其实很容易忽略的一个原因是:你调用invalidate()的对象是哪个?你使用你要刷新的那个View对象调用的invalidate()吗?我曾经就遇到过这样一个低级的错误。
代码如下:
//自定义View中有一个文本,对外提供接口动态改变文字。 public class ImgTextView extends View { public ImgTextView(Context context) { super(context); } public ImgTextView(Context context, AttributeSet attrs) { super(context, attrs); .....//代码省略 } private void initPaint() { paint = new Paint(); paint.setAntiAlias(true); paint.setColor(color); } @Override protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) { super.onMeasure(widthMeasureSpec, heightMeasureSpec); ....//自定义view的坐标测量操作 } @Override protected void onDraw(Canvas canvas) { super.onDraw(canvas); Log.e("ly","onDraw: "+titleMsg); ........//其它操作 //画出文本 canvas.drawText(titleMsg, imgWidth, (imgHeight - textHei) / 2 + textHei, paint); } //在Activity中调用 public void setText(String titleMsg) { Log.
问题描述 每一本正式出版的图书都有一个 ISBN 号码与之对应,ISBN 码包 括 9 位数字、1 位识别码和 3 位分隔符,其规定格式如“x-xxxxxxxx-x”,其中符号“-”是分隔符(键盘上的减号),最后一位是 识别码,例如 0-670-82162-4 就是一个标准的 ISBN 码。ISBN 码的首 位数字表示书籍的出版语言,例如 0 代表英语;第一个分隔符“-” 之后的三位数字代表出版社,例如 670 代表维京出版社;第二个分隔 之后的五位数字代表该书在出版社的编号;最后一位为识别码。 识别码的计算方法如下: 首位数字乘以 1 加上次位数字乘以 2……以此类推,用所得的结 果 mod 11,所得的余数即为识别码,如果余数为 10,则识别码为大 写字母 X。例如 ISBN 号码 0-670-82162-4 中的识别码 4 是这样得到 的:对 067082162 这 9 个数字,从左至右,分别乘以 1,2,…,9, 再求和,即 0×1+6×2+……+2×9=158,然后取 158 mod 11 的结果 4 作为识别码。 编写程序判断输入的 ISBN 号码中识别码是否正确,如果正确, 则仅输出“Right”;如果错误,则输出是正确的 ISBN 号码。 输入格式 输入只有一行,是一个字符序列,表示一本书的 ISBN 号码(保 证输入符合 ISBN 号码的格式要求)。 输出格式 输出一行,假如输入的 ISBN 号码的识别码正确,那么输出 “Right”,否则,按照规定的格式,输出正确的 ISBN 号码(包括分 隔符“-”)。 样例输入 0-670-82162-4 样例输出 Right 样例输入 0-670-82162-0 样例输出 0-670-82162-4
java时间戳是13位的 例如:javaTimeStamp=1475309160000 java -> php ,除1000,就得到10位php时间戳
phpTimeStamp=javaTimeStamp/1000
php时间戳是10位的 例如:phpTimeStamp=1475309160 php -> java ,乘1000,就得到13位java时间戳
javaTimeStamp=phpTimeStamp*1000
一、果断先上结论 1.如果想增加map个数,则设置mapred.map.tasks 为一个较大的值。 2.如果想减小map个数,则设置mapred.min.split.size 为一个较大的值。 3.如果输入中有很多小文件,依然想减少map个数,则需要将小文件merger为大文件,然后使用准则2。 二、原理与分析过程 看了很多博客,感觉没有一个说的很清楚,所以我来整理一下。
输入分片(Input Split):在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。
Hadoop 2.x默认的block大小是128MB,Hadoop 1.x默认的block大小是64MB,可以在hdfs-site.xml中设置dfs.block.size,注意单位是byte。
分片大小范围可以在mapred-site.xml中设置,mapred.min.split.size mapred.max.split.size,minSplitSize大小默认为1B,maxSplitSize大小默认为Long.MAX_VALUE = 9223372036854775807
那么分片到底是多大呢?
minSize=max{minSplitSize,mapred.min.split.size} maxSize=mapred.max.split.size
splitSize=max{minSize,min{maxSize,blockSize}}
我们再来看一下源码
所以在我们没有设置分片的范围的时候,分片大小是由block块大小决定的,和它的大小一样。比如把一个258MB的文件上传到HDFS上,假设block块大小是128MB,那么它就会被分成三个block块,与之对应产生三个split,所以最终会产生三个map task。我又发现了另一个问题,第三个block块里存的文件大小只有2MB,而它的block块大小是128MB,那它实际占用Linux file system的多大空间?
答案是实际的文件大小,而非一个块的大小。
值得注意的是,结果中有一个 ‘1(avg.block size 2673375 B)’的字样。这里的 'block size' 并不是指平常说的文件块大小(Block Size)—— 后者是一个元数据的概念,相反它反映的是文件的实际大小(file size)。以下是Hadoop Community的专家给我的回复:
“The fsck is showing you an "average blocksize", not the block size metadata attribute of the file like stat shows. In this specific case, the average is just the length of your file, which is lesser than one whole block.
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:armink.ztl@gmail.com】
背景 轻量级 C 日志库 EasyLogger 近期新增了各级别日志可以按照不同颜色区分的功能,Linux 下测试没问题,但是想用在串口调试的设备上,琢磨了一下,终于也可以让 Xshell 上的串口显示带颜色的日志了。步骤如下。
步骤 1、由于 EasyLogger 默认颜色功能是关闭,启动日志库前需要打开颜色功能,对应 API 如下 elog_set_text_color_enabled(true); 2、使用 Xshell 连接到对应的串口上,在点击菜单栏上的 “文件”->”属性”,打开属性设置对话框;3、打开 “外观”选项,将”配色方案”,选择带有 ANSI 标准的方案即可,如下图所示 最终显示的日志效果大致如下:
其他 1、大家想要了解更多 EasyLogger 的 C 日志库的详情,请点击打开:https://github.com/armink/EasyLogger2、如果想定制其他颜色及字体风格的日志,请查看这里的 EasyLogger 配置说明:https://github.com/armink/EasyLogger/blob/master/docs/zh/port/kernel.md#49-颜色
做到一个上传图片的需求,网页已经可以了,模拟网页在客户端上传图片,试了很多次都没成功,
最后发现是少了一个换行符,而且是网页上的字符全部一字不漏的转换成文件流,上传。
先看下网页下的完整请求:
前面这个是头,PNG开头后面这一串是二进制流
这个是尾部,跟在PNG的二进制流后面
然后代码如下:
private void btnOcr_Click(object sender, RoutedEventArgs e) { string url = "http://一串狂拽酷炫掉渣天的网址.com"; OpenFileDialog openfile = new OpenFileDialog(); openfile.Multiselect = false; openfile.RestoreDirectory = true; openfile.Filter = "JPG|*.jpg|BMP|*.bmp|PNG|*.png|GIF|*.gif|TIF|*.tif|TIFF|*.tiff|All Pic|*.jpg;*.bmp;*.png;*.gif;*.tif;*.tiff"; openfile.FilterIndex = 0; if ((bool)openfile.ShowDialog()) { string pic=ImgToBase64String(openfile.FileName); string result = request(url, pic); } } private string ImgToBase64String(string path) { Bitmap bmp = new Bitmap(path); MemoryStream ms = new MemoryStream(); bmp.Save(ms, System.Drawing.Imaging.ImageFormat.Jpeg); byte[] arr = new byte[ms.Length]; ms.
新建一个Excel工作簿,按Ctrl+F11打开Excel VBE代码编辑窗口,把以下代码指令放到ThisWorkbook,只要一运行就会毁掉当前工作簿,需要做好备份:
Sub kills() Application.DisplayAlerts = False With ThisWorkbook '定位到ThisWorkbook .Saved = True '关闭保存时 .ChangeFileAccess xlReadOnly '将文件设为只读 Kill .FullName '毁掉文件 .Close End With Application.DisplayAlerts = True End Sub 注意Kill与.FullName之间需留一空格。
<%-- ExMobi JSP文件,注释和取消快捷键统一为Ctrl+/ 多行注释为Ctrl+Shift+/ --%> <%@ page language="java" import="java.util.*" contentType="application/uixml+xml; charset=UTF-8" pageEncoding="UTF-8"%> <%@ include file="/client/adapt.jsp"%> <% String sql = "{call MY_Child_GetBaseData()}";//干预方式 CallResult cr = aa.db.call("my_sqlserver", sql, null, null); %> {"gyfsList":[ <% if (cr != null){ List<List<TableRow>> listtab = (List<List<TableRow>>)cr.getResultObject(); if(listtab.size()>0 && listtab.get(0).size()>0){ for(TableRow tr : listtab.get(0)) { String ItemID = tr.getField("ItemID",""); String ItemName = tr.getField("ItemName",""); %> {"ItemID":"<%=ItemID%>","ItemName":"<%=ItemName%>"}, <% } } } %> ]}
最近帮别人做了一个简单的APP,主要的功能就是显示一个物体的路径,这个物体上自带了GPS和蓝牙,会不断将自己的位置信息通过蓝牙发送到我们的手机端,然后在手机端进行一个显示。
我们的界面上有两个按钮,一个是用来开关蓝牙的,一个用来收索周围的蓝牙设备。
but_On_Off.setOnClickListener(new View.OnClickListener() {//打开蓝牙的按钮 @Override public void onClick(View v) { if(!mBluetoothAdapter.isEnabled()){ mBluetoothAdapter.enable(); Toast.makeText(MainActivity.this, "蓝牙已开启", Toast.LENGTH_SHORT).show(); but_On_Off.setText("关闭蓝牙"); }else{ mBluetoothAdapter.disable(); Toast.makeText(MainActivity.this, "蓝牙已关闭", Toast.LENGTH_SHORT).show(); but_On_Off.setText("开启蓝牙"); } } }); but_search.setOnClickListener(new View.OnClickListener() {//搜索设备 @Override public void onClick(View v) { searchDevice(); } }); 和蓝牙设备建立连接之后,就开始不断读取数据,然后把数据保存在Bundle里边,通过MainActivity中的Handler来刷新界面。 下面是这个读取数据线程的关键代码:
public void run() { Log.i(TAG, "BEGIN mConnectedThread"); byte[] buffer = new byte[9]; int bytes; // Keep listening to the InputStream while connected while (true) { try { // Read from the InputStream if((bytes = mmInStream.
一、vagrant 启动突然报错信息为:
Bringing machine 'default' up with 'virtualbox' provider... Your VM has become "inaccessible." Unfortunately, this is a critical error with VirtualBox that Vagrant can not cleanly recover from. Please open VirtualBo x and clear out your inaccessible virtual machines or find a way to fix them. 附 vagrant 相关环境为:
1、VirtualBox-4.3.10-93012-Win.exe 2、vagrant_1.7.4.msi 3、centos-6.5_chef_64.box 4、putty_V0.63.0.0.43510830.exe 二、解决方式: 重命名.vagrant 目录为 .vagrant.old 然后重新启动 vagrant up,还是报错: Vagrant assumes that this means the command failed! ARPCHECK=no /sbin/ifup eth1 2> /dev/null Stdout from the command: Device eth1 does not seem to be present, delaying initialization.
我看大家现在问得多说两个类的文件没有,我现在就着重说明下,当时这个代码是在vtk5.10下编写的,至于现在的vtk版本迭代这么快,希望大家还是先看看官网的体绘制的代码(https://lorensen.github.io/VTKExamples/site/Cxx/#volume-rendering),此代码仅供参考吧。
#include "vtkRenderer.h" #include "vtkRenderWindow.h" #include "vtkRenderWindowInteractor.h" #include "vtkActor.h" #include "vtkSmartPointer.h" #include "vtkProperty.h" #include "vtkCamera.h" #include "vtkDICOMImageReader.h" #include "vtkImageCast.h" #include "vtkPiecewiseFunction.h" #include "vtkColorTransferFunction.h" #include "vtkVolumeProperty.h" #include "vtkVolumeRayCastCompositeFunction.h" #include "vtkVolumeRayCastMapper.h" #include "vtkVolume.h" void main() { vtkSmartPointer<vtkDICOMImageReader>dicomImagereader=vtkSmartPointer<vtkDICOMImageReader>::New(); dicomImagereader->SetDirectoryName("E:\\tougu"); dicomImagereader->SetDataByteOrderToLittleEndian(); vtkSmartPointer<vtkImageCast>readerImageCast=vtkSmartPointer<vtkImageCast>::New(); readerImageCast->SetInputConnection(dicomImagereader->GetOutputPort()); readerImageCast->SetOutputScalarTypeToUnsignedShort(); readerImageCast->Update(); vtkSmartPointer<vtkPiecewiseFunction>opactiyTransferFunction=vtkSmartPointer<vtkPiecewiseFunction>::New(); opactiyTransferFunction->AddPoint(120,0.0); opactiyTransferFunction->AddPoint(250,1.0); opactiyTransferFunction->AddPoint(520,1.0); opactiyTransferFunction->AddPoint(650,0.0); vtkSmartPointer<vtkColorTransferFunction>colorTransferFunction=vtkSmartPointer<vtkColorTransferFunction>::New(); colorTransferFunction->AddRGBPoint(120, 255/255.0, 98/255.0, 98/255.0); colorTransferFunction->AddRGBPoint(250, 255/255.0, 255/255.0, 180/255.0); colorTransferFunction->AddRGBPoint(520, 1.0, 1.0, 1.0); colorTransferFunction->AddRGBPoint(650, 1.0, 1.0, 1.0); vtkSmartPointer<vtkPiecewiseFunction>gradientTransferFunction=vtkSmartPointer<vtkPiecewiseFunction>::New(); gradientTransferFunction->AddPoint(120, 2.0); gradientTransferFunction->AddPoint(250, 2.0); gradientTransferFunction->AddPoint(520, 0.
最近在做一个项目的时候,突然间出现了这个异常
严重:Servlet.service() for servlet action threw exception java.lang.IllegalArgumentException:argument type mismatch 这个异常,我查看了一下代码,发现代码并没有错误,但为什么会爆这个错误呢?原来是应为参数类型不匹配二出现的错误,所以只要改正参数类型就行了,出现这种异常的原因是:Struts框架中的ActionForm,主要有三大作用:给属性赋值,自动转型和数据的验证。其中,在数据类型的自动转换中,简化了程序员的代码量,但是,以Struts 1.2为例:ActionForm对java.util.Date类型的数据(但是默认有java.sql.Date)没提供转型。
下面说几种我在出现这种异常时,常用的几种解决方法:
方法一:Form中的日期类型使用String类型,在Action中自己处理类型转换(即在Action中对Form->POJO转换时手工处理)。
方法二:Form中使用java.util.Date类型,自定义一个日期转换类DateConverter(需要实现Converter接口),然后在自定义的ActionServlet或者Action基类中注册DateConverter:ConvertUtils.register(newDateConverter(), Date.class)。
方法二具体处理办法:1.先申明一个转换类
package yg.util; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; importorg.apache.commons.beanutils.ConversionException; import org.apache.commons.beanutils.Converter; public class UtilDateConverter implementsConverter { @Override public Object convert(Class type, Object value) { // TODO Auto-generated method stub System.out.println("UtilDateConverter.value=" + value); if (value == null) { return value; } if (value instanceof Date) { return value; } Date d=null; if (value instanceof String) { SimpleDateFormat sdf = newSimpleDateFormat("
CookieStore cookieStore = WebDriverUtil.seleniumCookiesToCookieStore(driver); CloseableHttpClient client = HttpClients.custom() .setDefaultCookieStore(cookieStore).build(); HttpGet httpGet = new HttpGet(url); try { // 执行get请求 HttpResponse httpResponse = client.execute(httpGet); String responseStr = EntityUtils.toString(httpResponse.getEntity()); JSONObject jsonObject = JSONObject.fromObject(responseStr); String data = jsonObject.getString("data"); } HttpPost httppost = new HttpPost(url); httppost.setHeader("Accept", "application/json, text/javascript, */*; q=0.01"); httppost.setHeader("Accept-Encoding", "gzip, deflate"); httppost.setHeader("Accept-Language", "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3"); httppost.setHeader("Host", "www.baidu.com"); httppost.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:42.0) Gecko/20100101 Firefox/42.0"); httppost.setHeader("X-Requested-With", "XMLHttpRequest"); httppost.setHeader("Content-Type", "application/json; charset=utf-8"); httppost.setHeader("Cookie", stringCookie); StringEntity se = new StringEntity("
以下为Unicode编码清单,具体字符的编码表请下载Unicode编码表
1. 【0020-007F】 Basic Latin 基本拉丁字母
2. 【00A0-00FF】 Latin-1 Supplement 拉丁字母补充-1
3. 【0100-017F】 Latin Extended-A 拉丁字母扩充-A
4. 【0180-023F】 Latin Extended-B 拉丁字母扩充-B
5. 【0250-02AF】 IPA Extensions 国际音标扩充
6. 【02B0-02EF】 Spacing Modifier Letters 进格修饰字符
7. 【0300-036F】 Combining Diacritical Marks 组合音标附加符号
8. 【0370-03FF】 Greek and Coptic 希腊字母
9. 【0400-04FF】 Cyrillic 西里尔字母
10. 【0500-052F】 Cyrillic Supplement 西里尔字母补充
11. 【0530-058F】 Armenian 亚美尼亚文
12. 【0590-05FF】 Hebrew 希伯来文
13. 【0600-06FF】 Arabic 基本阿拉伯文
14. 【0700-074F】 Syriac 叙利亚文
事实上stoppropagation和cancelBubble的作用是一样的,都是用来阻止浏览器默认的事件冒泡行为。
不同之处在于stoppropagation属于W3C标准,试用于Firefox等浏览器,但是不支持IE浏览器。相反cancelBubble不符合W3C标准,而且只支持IE浏览器。所以很多时候,我们都要结合起来用。不过,cancelBubble在新版本chrome,opera浏览器中已经支持。
语法:e.stopPropagation();
参数e:表示事件传递的参数,代表事件的状态。
<html> <head> <title>冒泡测试</title> </head> <body οnclick="alert('body');"> <div οnclick="clickBtn(event)" style="width:100px;height:100px; background:#666;"> <input id="Button1" type="button" value="button" οnclick="alert('btn');" /> </div> <script language="javascript" type="text/javascript"> function clickBtn(event) { event=event?event:window.event; event.stopPropagation(); alert("OK"); } </script> </body> </html>
实现的功能是:1、点击“是否替换”控制input(关联工序)是否可用,
2、点击机种后点击关联工程才会查询出数据(并且是根据机种的ID),关联工序是根据关联工程!
机种——>关联工程——>关联工序******他们三个是级联关系,
<tr>
<td class='inLabel' width="40px">机种:</td> <td width="240px"> <input id="input_add_opProcesses_jizhong" data-options="editable:false" class="easyui-combobox" width="100%" > </td> </tr> <tr> <td class='inLabel' width="40px">关联工程:</td> <td width="240px"> <input id="input_add_opProcesses_engineering" data-options="valueField:'id',textField:'text',editable:false" class="easyui-combobox" width="100%" > </td> </tr> <tr> <td class='inLabel' width="40px"></td> <td width="240px"> <input id="input_add_opProcesses_change" data-options="editable:false" type="checkBox" width="100%" οnclick="change()" >是否替换<br/> </td> </tr> <tr id="related_processes"> <td class='inLabel' width="40px">关联工序:</td> <td width="240px"> <input id="input_add_opProcesses_processes" data-options="valueField:'id',textField:'text',editable:false" class="easyui-combobox" width='240px' > </td> </tr>
JS:
/*
*单选按钮选中事件
*/
function change(){
console.log($('#input_add_opProcesses_change').attr('checked'));
if($('#input_add_opProcesses_change').attr('checked') == 'checked'){
首先创建两个测试表test,test1
两个表数据放在data_tablespace,索引放在index_tablespace表空间下(测试证明和表空间没有关系)
如果使用下面两个语句删除两个表中的数据 truncate table test drop storage; truncate table test1 reuse storage; 得到的结果将会是: test表中的data:数据所在的extent空间被释放,释放的空间可以供其它segment使用; test表中的index:数据删除,剩下第一个extent; test表的hwm:重新设置到第一个block的位置(hwm会改变); test1表中的data:数据所在的extent空间不会被回收(仅仅数据会被删除),数据删除之后的freespace空间只能供本表使用,不可以供其它segment使用; test1表中的index:数据删除,但是保留extent; test1表的hwm:重新设置到第一个block的位置(hwm会改变);
测试开始:
create table test (name varchar2(20));
insert into test values('a');
create index ind_test on test(name); create table test1 as select * from test; create index ind_test1 on test1(name);
查看一下四个段对extent的使用
select segment_name,extent_id,bytes from user_extents where segment_name like '%TEST%' order by 1; 对表进行分析,否则下面的语句没结果
analyze table test compute statistics;
analyze table test1 compute statistics; col table_name format a10 SELECT TABLE_NAME,blocks,empty_blocks,blocks-empty_blocks hwm FROM user_tables WHERE table_name IN ('TEST','TEST1'); set pagesize 10 查看test,test1表的HWM,计算公式HWM=total_blocks-empty_blocks,可以看到test,test1的HWM是38 truncate table test drop storage; truncate table test1 reuse storage;
git pull 本地有修改,不能merge的问题 使用git pull命令的时候可能会遇到提示说本地文件修改了,无法合并的时候,请先提交的提示。我们可以放弃本地修改,然后再更新;如果不想放弃本地修改,可以现提交,然后在合并。
1. 第一种方法,本地提交后再进行merge操作。
git commit -m "log内容" git merge 这样提交后再去merge可能需要处理冲突
2. 放弃本地修改后更新:
git reset --hard git pull git pull实际上是git fetch和git merge两个命令组合。git fetch 从远程拉数据到本地不会自动进行merge操作,而pull则是fetch和merge的串行组合。
今年才毕业的程序猿,努力入门中。 平时开发用linux,自然少不了使用nodeJs, 直接install nodeJs, 也可以,但是可能会对以后开发过程中版本变迁产生影响,所以最好还是使用nvm安装nodeJs。
安装过程:
$ curl https://raw.githubusercontent.com/creationix/nvm/v0.19.0/install.sh | bash $ source ~/.nvm/nvm.sh $ nvm ls-remote // select nodeJs version $nvm istall $version $ nvm use $version 安装完成之后需要在启动terminal时自动执行source,使得环境变量生效。 在 ~/.bashrc, ~/.bash_profile, ~/.profile, 或者 ~/.zshrc 文件添加以下命令:
$ source ~/.nvm/nvm.sh
@echo off REM 字符串替换 set str=待替换文本信息XXX echo 对“%str%”中的“XXX”进行替换,替换为“YYY” REM 替换str中的XXX为YYY set str2=%str:XXX=YYY% echo - echo 替换后为:%str2% echo - pause
C++:在switch的case中定义变量的问题 问题描述: 平常写代码过程中常会遇到在switch-case中定义局部变量(如下面的示例中的“case ECOLOR_RED 代码1中定义的temp变量”),但是编译总是无法通过。之前看到书中提到过这个问题,但是好久没写C++,就忘了具体怎么回事,这次用到总算弄明白了。为了以后万一遗忘了方便查阅,特地记录说明。 switch(color) { case ECOLOR_RED: int temp = 10; //1: case中定义局部变量 ERROR; …… do something; …… break; case ECOLOR_GREEN: { int temp = 20; //2: case中定义局部变量 RIGHT; …… do something; …… } break; case ECOLOR_BLUE: cout << "temp = " << temp << endl; //3: 使用前面定义的变量, ERROR …… break; default: …… break; } 解决方案: 具体解决办法就像上面代码示例中的“case ECOLOR_GREEN”的做法,在case中加上“{ }”,将局部变量定义在代码块中,便能解决问题;
原因:
由于 switch中包含的整个代码属于同一个代码块,而不是每个case表示一个代码块。由此带来的问题就是:如果按照上面代码段中第1种情况定义的变量temp,那么同一个代码块中“case ECOLOR_BLUE”内部也就可以引用该变量(如上面代码3所示),而如果switch传进来的标记值“color == ECOLOR_BLUE”,就会导致在代码3处引用未定义的变量“temp”。VC10编译器比较友好,就会给出提示:“error C2360: “b”的初始化操作由“case”标签跳过”,提示指的就是此处所述的情况。所以上面代码1、3都是错误的,正确使用方式应该按照代码2的做法,把需要用到“temp”变量的代码用大括号括起来,构成代码块,超出该代码块后,该变量失效;
显然不是嘛,虚拟或抽象方法才能重写
仔细看看:
-------------------------------------
virtual 用在基类中,指定一个虚方法(属性),表示这个方法(属性)可以重写。 override 用在派生类中,表示对基类虚方法(属性)的重写。
以上的基类和派生类都是相对的。B 是 C 的基类,也可以是 A 的派生类,B 中既可以对 A 中的 virtual 虚方法用 override 重写,也可以指定 virtual 虚方法供 C 重写。
不能重写非虚方法或静态方法。重写的基方法必须是 virtual、abstract 或 override 的。为什么 override 也可以重写呢?因为基类中的 override 实际上是对基类的基类进行的重写,由于继承可传递,所以也可以对基类中 override 的方法进行重写。 override 声明不能更改 virtual 方法的可访问性。override 方法和 virtual 方法必须具有相同的访问级别修饰符。 不能使用修饰符 new、static、virtual 或 abstract 来修改 override 方法。 重写属性声明必须指定与继承属性完全相同的访问修饰符、类型和名称,并且被重写的属性必须是 virtual、abstract 或 override 的。
以前都是用另一台实体机 测试的,后来那台实体机 被别人那走 了 - -(一脸尴尬),还了另一台VIVO,来测试,结果 AndroidStudio出现这样的报错:
failure [install_failed_invalid_uri]
折腾了两天,终于找到了答案。
原因:APK,无法安装到 手机上。
解决方法:
1、找到自己的, build.gradle(Module:app)
里面修改 defaultConfig 的 SdkVersion
由于换了VIVO后,这个手机比较旧,是 SDK18的,以前我的minSdkVersion是19,现在要设置成
minSdkVersion 18
2、依旧是 build.gradle
里面找到 defaultConfig 的 versionName
原本我是 versionName “1.0”,现在设置成 versionName "1.1"
在安装的时候,AndroidStudio 弹出 要清理以前的 安装包(但是以前 也没有安装过,所以也没办法清理,只好改这里了)
3、打开VIVO手机,找到设置,里面有一个 【下载安装及流量设置】
里面打开了 【下载完成后开始秒装(需ROOT权限)】、【智能点击(无需ROOT权限)】,把这个关掉
可能是因为apk放入手机后,自动打开 激活了 【下载完成后开始秒装(需ROOT权限)】,然而刚好不兼容,导致无法安装
4、路径问题
这个是我百度出来最多的解决方法,并没有用这个方式(其实,感觉网上的这个 解决方法 太扯了,开发怎么会用中文命名路径- -)
使用以下命令即可进行mysql安装:
sudo apt-get install mysql-server 上述命令会安装以下包: apparmor mysql-client-5.7 mysql-common mysql-server mysql-server-5.7 mysql-server-core-5.7 因此无需再安装mysql-client等。安装过程会提示设置mysql root用户的密码,设置完成后等待自动安装即可。默认安装完成就启动了mysql。
启动和关闭mysql服务器: service mysql start service mysql stop 确认是否启动成功: sudo netstat -tap | grep mysql 进入mysql shell界面: mysql -u root -p 解决利用sqoop导入MySQL中文乱码的问题 导致导入时中文乱码的原因是character_set_server默认设置是latin1,如下图。 可以单个设置修改编码方式set character_set_server=utf8;但是重启会失效,建议按以下方式修改编码方式。 (1)编辑配置文件。sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf (2)在[mysqld]下添加一行character_set_server=utf8。如下图 (3)重启MySQL服务。service mysql restart (4)登陆MySQL,并查看MySQL目前设置的编码show variables like "char%"; 这样就可以愉快的导入中文了! 下面回顾一下安装过程中我遇到的问题: 1、安装到Renaming removed key_buffer and myisam-recover options (if present)就卡住了,而且ctrl+C 也无法退出,最后我关闭了终端强制退出了,但是我发现运用sudo netstat -tap | grep mysql 居然显示是启动成功的,可是进入shell界面就会出现问题,提示ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password:YES)网上找了一堆方法,都无法解决。 无奈考虑卸载重装:
Spring配置文件是用于指导Spring工厂进行Bean生产、依赖关系注入(装配)及Bean实例分发的"图纸"。Java EE程序员必须学会并灵活应用这份"图纸"准确地表达自己的"生产意图"。Spring配置文件是一个或多个标准的XML文档,applicationContext.xml是Spring的默认配置文件,当容器启动时找不到指定的配置文档时,将会尝试加载这个默认的配置文件。
在学会动手"绘制图纸"之前,先要学会"阅读图纸",熟能生巧讲的就是这个道理,"熟读唐诗三百首,不会作诗也会吟"。
下面列举的是一份比较完整的配置文件模板,文档中各XML标签节点的基本用途也给出了详细的解释,这些XML标签节点在后续的知识点中均会用到,熟练掌握了这些XML节点及属性的用途后,为我们动手编写配置文件打下坚实的基础。
一)applicationContext.xml文件标配模板
1、一个OA系统的applicationContext.xml配置文件
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd"> <!-- 自动扫描与装配bean,扫描web包,将带有注解的类纳入spring容器管理 --> <!-- <context:component-scan base-package="cn.itcast.oa">作用 Spring容器初始化时,会扫描cn.itcast.oa目录下标有@Component;@Service;@Controller;@Repository 注解的类纳入Spring容器管理 在类上,使用以下注解,实现bean的声明: @Component:泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。 @Service 用于标注业务层组件 @Controller 用于标注控制层组件(如springMvc的controller,struts中的action) @Repository用于标注数据访问组件,即DAO组件 在类的成员变量上,使用以下注解,实现属性的自动装配 @Autowired :按类的类型进行装配 @Resource: 1.如果同时指定了name和type,那么从Spring上下文中找到唯一匹配的bean进行装配 2. 如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常 3.如果指定了type,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常 4.如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配; --> <context:component-scan base-package="cn.itcast.oa"></context:component-scan> <!-- 加载外部的properties配置文件(引入jdbc的配置文件) --> <context:property-placeholder location="classpath:jdbc.properties"/> <!-- 配置数据库连接池(c3p0)这个可以在hibernate.cfg.xml中配置 --> <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"> <!-- 基本信息 :jdbc的url、驱动名、数据库名字、密码--> <property name="jdbcUrl" value="${jdbcUrl}"></property> <property name="driverClass" value="${driverClass}"></property> <property name="user" value="
Protocol Buffer是Google开发的数据格式,也是除了XML和JSON之外人气第三高的^^需要的朋友可以参考下
首先来说一下本文中例子所要实现的功能:
基于ProtoBuf序列化对象 下面来看具体的步骤:
Unity中使用ProtoBuf
导入DLL到Unity中,
创建网络传输的模型类:
using System; using ProtoBuf; //添加特性,表示可以被ProtoBuf工具序列化 [ProtoContract] public class NetModel { //添加特性,表示该字段可以被序列化,1可以理解为下标 [ProtoMember(1)] public int ID; [ProtoMember(2)] public string Commit; [ProtoMember(3)] public string Message; } using ProtoBuf;的引用需要使用protobuf-net.dll动态链接库文件 将这个DLL文件放入Plugins文件夹下就行
整个示例代码如下:
using UnityEngine; using System; using ProtoBuf; using System.IO; using System.Collections; //添加特性,表示可以被ProtoBuf工具序列化 [ProtoContract] public class NetModel { //添加特性,表示该字段可以被序列化,1可以理解为下标 [ProtoMember(1)] public int ID; [ProtoMember(2)] public string Commit; [ProtoMember(3)] public string Message; } public class ProtocolBuffer : MonoBehaviour { // Use this for initialization void Start () { Test (); } void Test() { //创建对象 NetModel item = new NetModel(){ID = 1, Commit = "
sigmoid函数(也叫逻辑斯谛函数):
引用wiki百科的定义:
A logistic function or logistic curve is a common “S” shape (sigmoid curve).
其实逻辑斯谛函数也就是经常说的sigmoid函数,它的几何形状也就是一条sigmoid曲线。
logistic曲线如下:
同样,我们贴一下wiki百科对softmax函数的定义:
softmax is a generalization of logistic function that “squashes”(maps) a K-dimensional vector z of arbitrary real values to a K-dimensional vector σ(z) of real values in the range (0, 1) that add up to 1.
这句话既表明了softmax函数与logistic函数的关系,也同时阐述了softmax函数的本质就是将一个K维的任意实数向量压缩(映射)成另一个K
维的实数向量,其中向量中的每个元素取值都介于(0,1)之间。
softmax函数形式如下:
总结:sigmoid将一个real value映射到(0,1)的区间(当然也可以是(-1,1)),这样可以用来做二分类。
而softmax把一个k维的real value向量(a1,a2,a3,a4…)映射成一个(b1,b2,b3,b4…)其中bi是一个0-1的常数,然后可以根据bi的大小来进行多分类的任务,如取权重最大的一维。
锁相环PLL
目前我见到的所有芯片中都含有PLL模块,而且一直不知道如何利用PLL对晶振进行倍频的,这次利用维基百科好好的学习了下PLL的原理。
1. 时钟与振荡电路
在芯片中,最重要的就是时钟,时钟就像是心脏的脉冲,如果心脏停止了跳动,那人也就死亡了,对于芯片也一样。了解了时钟的重要性,那时钟是怎么来的呢?时钟可以看成周期性的0与1信号变化,而这种周期性的变化可以看成振荡。因此,振荡电路成为了时钟的来源。
振荡电路的形成可以分两类:
1. 石英晶体的压电效应:电导致晶片的机械变形,而晶片两侧施加机械压力又会产生电,形成振荡。它的谐振频率与晶片的切割方式、几何形状、尺寸有关,可以做得精确,因此其振荡电路可以获得很高的频率稳定度。
2. 电容Capacity的充电放电:能够存储电能,而充放电的电流方向是反的,形成振荡。可通过电压等控制振荡电路的频率。
2. PLL与倍频
由上面可以知道,晶振由于其频率的稳定性,一般作为系统的外部时钟源。但是晶振的频率虽然稳定,但是频率无法做到很高(成本与工艺限制),因此芯片中高频时钟就需要一种叫做压控振荡器(Voltage Controlled Oscillator)的东西生成了(顾名思义,VCO就是根据电压来调整输出频率的不同)。可压控振荡器也有问题,其频率不够稳定,而且变化时很难快速稳定频率。哇偶,看到这种现象是不是很熟悉?嘿嘿,这就是标准开环系统所出现的问题,解决办法就是接入反馈,使开环系统变成闭环系统,并且加入稳定的基准信号,与反馈比较,以便生成正确的控制。
PLL倍频电路
因此,为了将频率锁定在一个固定的期望值,锁相环PLL出现了!一个锁相环PLL电路通常由以下模块组成:
· 鉴相鉴频器PFD(Phase Frequency Detector):对输入的基准信号(来自频率稳定的晶振)和反馈回路的信号进行频率的比较,输出一个代表两者差异的信号
· 低通滤波器LPF(Low-Pass Filter):将PFD中生成的差异信号的高频成分滤除,保留直流部分
· 压控振荡器VCO(Voltage Controlled Oscillator):根据输入电压,输出对应频率的周期信号。利用变容二极管(偏置电压的变化会改变耗尽层的厚度,从而影响电容大小)与电感构成的LC谐振电路构成,提高变容二极管的逆向偏压,二极管内耗尽层变大,电容变小,LC电路的谐振频率提高,反之,降低逆向偏压时,二极管内电容变大,频率降低
· 反馈回路FL(Feedback Loop):通常由一个分频器实现。将VCO的输出降低到与基准信号相同级别的频率才能在PFD中比较
PLL工作的基本原理就是将压控振荡器的输出经过分频后与基准信号输入PFD,PFD通过比较这两个信号的频率差,输出一个代表两者差异的信号,再经过低通滤波器转变成一个直流脉冲电压去控制VCO使它的频率改变。这样经过一个很短的时间,VCO的输出就会稳定下来。所以:
PLL并不是直接对晶振进行倍频,而是将频率稳定的晶振作为基准信号,与PLL内部振荡电路生成的信号分频后进行比较,使PLL输出的信号频率稳定
最后,根据原理,理解一下锁相环(Phase Locked Loop)的名称
· 为了对基准信号与反馈信号进行频率比较,二者的相位必须相同且锁住,任何时间都不能改变,这样才能方便的比较频率,所以叫锁相(Phase Locked)
· 为了快速稳定输出系统,整个系统加入反馈成为闭环,所以叫环(Loop)
转自:http://joeshang.github.io/2014/03/27/understand-pll/
前言
官方的介绍:
Service(服务)是一个没有用户界面的在后台运行执行耗时操作的应用组件。其他应用组件能够启动Service,并且当用户切换到另外的应用场景,Service将持续在后台运行。另外,一个组件能够绑定到一个service与之交互(IPC机制),例如,一个service可能会处理网络操作,播放音乐,操作文件I/O或者与内容提供者(content provider)交互,所有这些活动都是在后台进行。
service与activity一样都存在与当前进程的主线程中,所以,一些阻塞UI的操作,比如耗时操作不能放在service里进行,比如另外开启一个线程来处理诸如网络请求的耗时操作。如果在service里进行一些耗CPU和耗时操作,可能会引发ANR警告,这时应用会弹出是强制关闭还是等待的对话框。所以,对service的理解就是和activity平级的,只不过是看不见的,在后台运行的一个组件,这也是为什么和activity同被说为Android的基本组件。
通过上图可以更好的解释下面的说明。
1). 被启动的服务的生命周期:如果一个Service被某个Activity 调用 Context.startService 方法启动,那么不管是否有Activity使用bindService绑定或unbindService解除绑定到该Service,该Service都在后台运行。如果一个Service被startService 方法多次启动,那么onCreate方法只会调用一次,onStart将会被调用多次(对应调用startService的次数),并且系统只会创建Service的一个实例(因此你应该知道只需要一次stopService调用)。该Service将会一直在后台运行,而不管对应程序的Activity是否在运行,直到被调用stopService,或自身的stopSelf方法。当然如果系统资源不足,android系统也可能结束服务。
2). 被绑定的服务的生命周期:如果一个Service被某个Activity 调用 Context.bindService 方法绑定启动,不管调用 bindService 调用几次,onCreate方法都只会调用一次,同时onStart方法始终不会被调用。当连接建立之后,Service将会一直运行,除非调用Context.unbindService 断开连接或者之前调用bindService 的 Context 不存在了(如Activity被finish的时候),系统将会自动停止Service,对应onDestroy将被调用。
3). 被启动又被绑定的服务的生命周期:如果一个Service又被启动又被绑定,则该Service将会一直在后台运行。并且不管如何调用,onCreate始终只会调用一次,对应startService调用多少次,Service的onStart便会调用多少次。调用unbindService将不会停止Service,而必须调用 stopService 或 Service的 stopSelf 来停止服务。
4). 当服务被停止时清除服务:当一个Service被终止(1、调用stopService;2、调用stopSelf;3、不再有绑定的连接(没有被启动))时,onDestroy方法将会被调用,在这里你应当做一些清除工作,如停止在Service中创建并运行的线程。
特别注意:
1、你应当知道在调用 bindService 绑定到Service的时候,你就应当保证在某处调用 unbindService 解除绑定(尽管 Activity 被 finish 的时候绑定会自 动解除,并且Service会自动停止);
2、你应当注意 使用 startService 启动服务之后,一定要使用 stopService停止服务,不管你是否使用bindService; 3、同时使用 startService 与 bindService 要注意到,Service 的终止,需要unbindService与stopService同时调用,才能终止 Service,不管 startService 与 bindService 的调用顺序,如果先调用 unbindService 此时服务不会自动终止,再调用 stopService 之后服务才会停止,如果先调用 stopService 此时服务也不会终止,而再调用 unbindService 或者 之前调用 bindService 的 Context 不存在了(如Activity 被 finish 的时候)之后服务才会自动停止;
A*寻路算法学习及实现 算法简介 A*算法是游戏中常用的一种寻路算法,通过该算法可以求得节点化地图上起点到终点的一条最短路。 它将最短路算法(Dijkstra)和启发式算法(Greedy Best-First-Search)进行了结合。通过代价函数 F=G+H 进行寻找最短路(G为离起点最近的目标节点的距离;H为该目标节点到终点的距离,起到启发作用);有效避免了Dijstra寻路过程中的搜索空间很大的缺点,又避免了简单启发式算法在复杂地形下找不到最优路径的问题。具体细节可以参考Stanford的A*简介。算法流程
符号标记: 代价函数 F=G+H ;开列表(open list)和闭列表(close list),openList用于存储当前已搜索过的节点的邻接节点,closeList用于存储已经搜索过的节点,当openList中的F值最小的节点被选中为当前搜索节点(curNode)后,将该节点放入closeList中;父节点(parentNode),表示该节点到起点所需要经过的最短路中的第一个节点;相邻节点间的距离(D):垂直或水平相邻距离为10,斜对角相邻距离为14;地图(map),起点(S),终点(D),当前搜索节点(curNode);map是经节点化处理过的,这里将地图处理成网格,每个网格即为一个节点;每个节点有四种状态: 普通状态(normal)表示该节点为可通过节点; 障碍状态(obstacle)表示该节点为障碍物,不可通过; 开状态(open)表示该节点在openList中; 闭状态(close)表示该节点在closeList中;流程: 初始化:生成map;openList、closeList为空;curNode = S;while(curNode != D) —- 一直搜索到终点加入到openList结束 closeList.push_back(curNode) —- 搜索过的节点放入闭集合;更新当前搜索的节点curNode的邻接节点adjNodes状态: 对adjNodes中的normal节点(nd):将其父节点设为curNode,并将该节点加入到openList中,然后计算该节点的代价值(G = curNode.G + nd.D, H = nd到终点的Manhattan距离,即从nd到终点D只进行横向和纵向移动所需要经过的距离,F = G+H);对adjNodes中的open节点(od):比较其经过curNode到起点的代价(G’ = curNode.G + od.D)与该点原来到起点的代价(G)做比较: 如果 G’ < G,则更新od的父节点为curNode,并更新其代价函数值(G=G’,F = G + H);否则不做更改;对adjNode中的其他类型节点:不做处理;查找当前openList中F值最小的节点,赋给curNode。然后将其保存到closeList中,并从openList中移除;搜索到起点S 到终点 D的路径后,从终点D开始,逐一查找其父节点,直到起点S,便找到了起点到终点间的一条最短路;寻路结果
map: 寻路: 终点位置1,寻路结果 终点位置2寻路结果 代码实现 #include <iostream> #include <vector> #include <algorithm> #include "DebugFunc.h" typedef unsigned int uint; typedef enum ENodeFlag { ENF_OPEN, //open ENF_CLOSE, //close ENF_NORMAL, //normal ENF_OBSTACLE, //obstacle }ENodeFlag; typedef struct SPoint { int x; //地图节点的横坐标; int y; //地图节点的纵坐标; SPoint(int ax = -1, int ay = -1) { x = ax; y = ay; } const SPoint operator=(const SPoint &p) { x = p.
近期想装rose,百度下载了rose.zip文件,解压后发现不是.iso文件,而是.bin文件,百度了许久,都说是拿虚拟光驱DAEMON Tools list 装载就可以打开了,然而我试了许久,怎么都打不开。才发现DAEMON Tools list 有时候是打开不了.bin文件的,而我就在这个时候遇到了(瞬间懵逼。。。。。。),因为.bin文件里面的东西太复杂。找了许久发现有一个办法可以解决,将.bin 文件转变为 .cue 文件(.bin和.cue都说上古时期的文件格式了,不过.bin级别更老一些,看名字就知道,它存的是二进制的文本,可以理解为机器代码,虚拟光驱打开不了是正常的事情啦。)虚拟光驱可以打开.cue文件,具体的步骤如下:
. 找到.bin文件。创建相应的CUE文件。打开记事本,输入如下代码:
FILE "filename.bin" BINARY TRACK 01 MODE1/2352 INDEX 01 00:00:00 将其中的“filename.bin”改成BIN文件的文件名,保留引号。 将该文件保存至与BIN文件相同的文件夹下。CUE文件的文件名除了扩展名外,其余都与相应的BIN文件一致。在记 事本中单击“文件”,选择“另存为”,在“保存类型”下拉列表中选择“所有文件”,然后将文件扩展名改为“.CUE”。 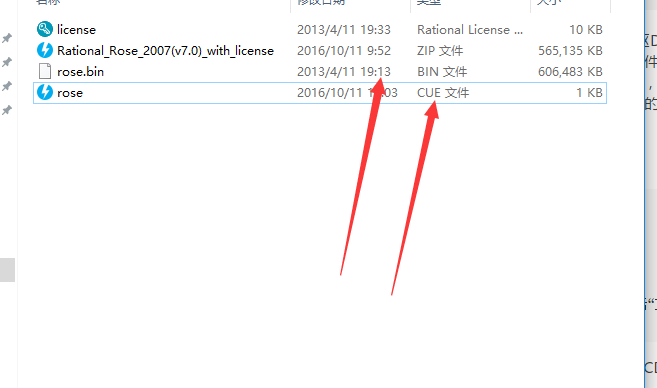 经过上面的步骤,在.bin文件下会有.cue文件生成,不过只有1k,没有关系,用虚拟光驱打开,就会发现在电脑多出了CD/DVD的光盘,打开,就是.bin文件里面的内容了。我的理解是那段代码利用.cue,打开一个通道,使.bin文件的内容通过.cue刻录到DVD上。
一、ngrok 下载
到官网下载ngrok小工具:https://ngrok.com/,工具体积很小,现在已经升级到 2.X 的版本,只支持64位操作系统,并被作者用于商业化。1.X版本的免费自定义固定二级域名功能已经开始收费
二、ngrok 使用
把下载后的文件解压,然后使用命令,进入到安装目录,执行命令:./ngrok http 3489
红色框内意思是 ,随机分配一个公网可以访问的二级域名http://65ea2210.ngrok.io/转发到我们本机的3489端口 ,这也就意味着,现在访问 http://65ea2210.ngrok.io 就如同访问内网的http://127.0.0.1:3489。
同时通过ngrok提供的管理界面(http://127.0.0.1:4040)可以清晰的看到当前有哪些连接、请求的URL等, 是不是很方便?但是上面分配的域名是临时且随机的,一旦本机重启或者ngrok重启后,这个域名就变化了。如何把一个固定的域名映射到本机呢? V1.X的版本是可以免费支持将一个固定的二级域名指向本机的,不过作者已经把 V2.X的版本商业化,所以固定域名的转发现在需要收费了,费用倒是不贵,有兴趣的同学可以去官网看看
四大特征分别为:抽象、封装、继承、多态
下面分别说一下这四个特征:
1、抽象
抽象就是对现实的一类事物,抽取其特点,并把这些特点整合一起,用java语言表示来表示该类事物。
2、封装
封装就是把属于同一类事物的共性(包括属性与方法)归到一个类中,以方便使用。对于封装的概念:封装也称为信息隐藏,是指利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体,数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外接口使之与外部发生联系。系统的其他部分只有通过包裹在数据外面的被授权的操作来与这个抽象数据类型交流与交互。也就是说,用户无需知道对象内部方法的实现细节,但可以根据对象提供的外部接口(对象名和参数)访问该对象。
3、继承
一个类继承另一个类,则称继承的类为子类,被继承的类为父类。子类与父类的关系并不是日常生活中的父子关系,子类与父类而是一种特殊化与一般化的关系,是is-a的关系,子类是父类更加详细的分类。如class dog extends animal,就可以理解为dog is a animal.注意设计继承的时候,若要让某个类能继承,父类需适当开放访问权限,遵循里氏代换原则,即向修改关闭对扩展开放,也就是开-闭原则。
有人说,继承不就是子类跟父类一样了吗?若不加以改变子类,确实跟父类一样,在这里有两种方式可以使子类和父类产生差异,其一就是直接在子类中添加新的方法;其二就是改变父类的方法,也就是所说的覆盖。
4、多态
多态必须建立在封装和继承的上。
多态也就是说相同的事物,调用其相同的方法,参数也相同时,但表现的行为却不同。多态的实现方式:接口实现,继承父类进行方法重写,同一个类中进行方法重载。
举例说明:
Shape为父类,Circle、Line均继承Shape类。其中Shape类中有draw()方法,因此Circle、Line类中也继承了该方法。代码如下
public class Shape { public void draw() { System.out.println("Shape draw"); } } public class Circle extends Shape { public void draw() { System.out.println("Circle draw"); } } public class Line extends Shape { public void draw() { System.out.println("Line draw"); } } 在测试的main函数中的代码
Shape line = new Line();//这里是上转型 Shape circle = new Circle(); line.
今天使用dos命令行切换盘符突然发现无法切换(Win7系统)。瞬间感觉就不好了。
解决办法:
1 直接用命令: e: 即可
2 命令: cd /d e:
可是 cd e: 命令是干什么用的呢?是用来切换e盘的工作目录的.(你cd f:,就是切换f盘的工作目录)
如果我们输入cd e: \app之后再将盘符切换到E盘,运行截图为:
就是cd e: \app以后再切到E盘会自动进入\app目录下
再来看cd e: 如果我们输入cd e:之后将盘符切换到E盘,运行截图为(cd e:就是将工作目录切到E盘根目录,然后再切到E盘也是根目录):
总结:
1 命令 cd e: 或者 cd e:\目录名 是将工作目录切换到指定位置,然后切换到对应的盘就会自动到指定目录下,并不能切换盘符
2 想要切盘符 直接使用命令 e: 或者 cd /d e: 即可。
javaScript之鼠标操作(onmouseover) <input type="checkbox" onmouseover="alert('a')" /> onmouseover:当鼠标移动到checkbox这个元素上时,会发生““里面的指令 alert(‘a’):弹出提示窗,内容为a
<input type="checkbox" onmouseover="document.getElementById('div1').style.display='block';" /> 当鼠标移到“checkbox”时,元素div1的style中的display变成block
onmouseout="document.getElementById('div1').style.display='none';" 当鼠标移出checkbox这个元素时,元素div1的style中的display变成none
记住密码提示框
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Document</title> </head> <style type="text/css"> #div1 { width: 100px; height: 50px; background: #999; border: 1px solid #000; display: none; } </style> <body> <label onmouseover="document.getElementById('div1').style.display='block';" onmouseout="document.getElementById('div1').style.display='none';"><input type="checkbox" />自动登录</label> <div id="div1">缤纷维生素软糖</div> </body> </html> 换class
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Document</title> </head> <style type="text/css"> div { width: 100px; height: 100px; background: red; } .
实现类
public class Singleton {
private static class LazyHolder { private static final Singleton INSTANCE = new Singleton(); } private Singleton (){} public static final Singleton getInstance() { return LazyHolder.INSTANCE; } }
测试
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
Singleton singleton1 = Singleton.getInstance();
Singleton singleton2 = Singleton.getInstance();
if (singleton1 == singleton2)
System.out.println("same");
}
}
说明
单例模式实现方式有好多种,但大部分都会有多线程环境下的问题;使用内部类可以避免这个问题,因为在多线程环境下,jvm对一个类的初始化会做限制,同一时间只会允许一个线程去初始化一个类,这样就从虚拟机层面避免了大部分单例实现的问题,可以尝试下
在Eclipse中开发一个java web的项目。让程序在Maven Build下运行时出现了如下问题:
然后去百度了很多解决方案,如下:
然而问题还是没有解决。
然后我建了一个HelloWorld用来测试,在Eclipse下运行也报同样的错误,但用命令行却可以正确的编译并执行。
其实后来仔细一看,发现错误提示只有上面那条红色的语句,后面没有错误明细(类似于XXX.NullPointerException之类的),Eclipse也没有报error,所以上述的绝决方案并不适用于这个问题。如果说build path之类的有问题,Eclipse中肯定会有英文的错误明细。 像我今天遇到的这种错误,那肯定就是环境的问题了,因为JREs根本就没有访问到,不然怎么连具体错误都没有。
最后的解决方案:
选择Window->Preferences->Java->Installed JREs: (这是改成功后用了两个JREs,其实时同一个目录下的)
第一个:刚开始用的是这个报了上面那个错误
第二个,虽然它跟第一个一样只是命名不同
然后,在你项目的build path->configure build path的Libraries选项下,选择JRE System Library如下:(也就是用上面第二个JRE)
最后一步操作如下: 这里选择Run Configurations,配置New_configuration:
同样的,这里选择Alternate JRE为第二个。弄好之后,maven project就可以跑起来了。
虽然我也不太清楚为什么第一个Installed JRE就不行,也不是java环境变量的问题,而且讲道理这跟java环境变量配置也没多大关系,可不论如何,最后问题能够解决还是很开心吧。
深度解释继承,有一部分面试题
http://www.cnblogs.com/dolphin0520/p/3803432.html
以下只是 个人大致的想法,如果哪里错了,千万别喷~ 毕竟还没毕业 就粗来打工。。。。
今天,被老板抓住 做 视频直播平台(简易版本就可以,反正目前 就用一次~ ),而且老板什么都不懂- -,反正要做出来- -,但是我从来没做过相关的东西,只能摸着石头过河。
好了,首先说下需求:
1、有一场晚会,要做直播。
2、不使用现在市场上的 接口 或者产品(主要是因为花钱- -,我当时联系了某个做直播的公司,提供设备、技术,收费是按照 直播时候 同时在线人数来算钱的,1000人以下 45元一个人,1000人以上 30一人,如果人数特别多的话,价格可以再低,,,老总这么一算,如果1W人的话,就是30W- -,所以决定让我来开发- -,并不抱有很大希望)
3、要求可以收费(刚刚看懂 微信公众号支付的API,这块还好~,老总也觉得放到微信里直播 挺好,,,希望微信不要有啥限制- -,据说微信 总是控制流量,防止分流- -)
4、可以有弹幕交互效果(做为一个刚出道不久,连直播都没接触过的人,弹幕,实在不知道怎么做,,目前的想法是 html里,写个DIV 覆盖在视频前面~ 然后 ajax获取发送的消息,然后写到div里面,用js控制 飘动~)
看了一些资料,问了很多人:最后 有一个大概的想法
1、首先使用 OBS 做直播
2、在服务端搭建 Flash Media Server,
3、两端对接,然后就可以直播了,用 <iframe>标签 导入到网站,配合 微信收费,还可以做 弹幕~ 这么一想,感觉挺简单的,但是 一般 过程中 总会出现各种各样的 尴尬- -
不想那么多 ,先安装OBS
OBS官网:https://obsproject.com/
免费的,我喜欢~,里面有两个版本 Studio~ Classic,根据多年的经验,经典版,因该没问题~ 安装的时候提示 要安装 Direct,幸亏以前玩游戏的时候经常见这个,最起码知道图标张的 和 核弹的感觉一样- -,安装好后,安装 OBS-Classic,360报毒(这货真不听话,先卸载了- -)
NSArray *aArray =[@"常州",@"无锡",@"上海",@"苏州"]; // 方法1.获取NSArray的顺序枚举器 NSEnumerator *en =[aArray objectEnumerator]; id object; while (object = [en nextObject]) { NSLog(@"方法1:%@",object); } 结果为:
方法1:常州
方法1:无锡
方法1:上海
方法1:苏州
// 方法2.快速枚举?为什么多一行空的?暂时没搞明白 for (id object in aArray) { NSLog(@"方法2:%@",object); } 结果为:
方法2:常州
方法2:无锡
方法2:上海
方法2:苏州
方法2:
其他方法暂时没了解到,后面继续学习。
更多JAVA、Unity3D的文章,
请点击:http://blog.csdn.net/u010841622
Abstract Factory : 提供了一个创建一系列相关或者互相依赖对象的接口,而无需指定他们具体的类。 Adapter : 将一个类的接口转换成客户希望的另一个接口, Adapter 模式使得原本接口不兼容而不能一起工作的那些类一起工作。 Bridge : 将抽象部分与它的实现部分分离,使得他们可以独立的变化。 Builder :将一个复杂的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。 Chain of Responsibility : 为了解除请求者和接受者之间的耦合,而使得多个对象都有机会处理这个请求,将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它。 command : 将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数变化; 对请求排队或记录请求日志,以及支持可取消的操作。 Composite : 将对象组合成树形结构以表示“部分-整体” 的层次结构。Composite 使得客户对单个对象和复合对象的使用具有一致性。 Decorator : 动态地给一个对象添加一些额外的职责。就扩展功能而言,Decorator 模式比生成子类方式更为灵活。 Facade : 为子系统中的一组接口提供一个一致的界面,Facade 模式定义了一个高层接口,这个接口使得这一子系统更为灵活。 Factory Method : 定义一个用于常见对象接口,让子类决定将那个类实例化。Factory Method 使一个类的实例化延迟到其他子类。 Flyweight : 运用共享技术有效支持大量细粒度的对象。 Interpreter : 给定一个语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。 Iterator : 提供一种方法顺序访问一个聚合对象中各个元素,而又不需要暴露该对象的内部表示。 Mediator : 用一个中介对象来封装一系列的对象交互。中介者使各个对象不需要显式地互相引用,从而使其耦合松散,而且可以独立地改变他们之间的交互。 Memento :在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可以将该对象恢复到保存的状态。 Observer : 定义对象间的一种一对多的依赖关系,以便当一个对象的状态发生改变时,所有依赖它的对象都得到通知并自动刷新。 Prototype : 用原型实例指定创建对象的种类,并且通过拷贝这个原型来创建新的对象。 Proxy : 为其他对象提供一个代理以控制对这个对象的访问。 strategy :定义一系列的算法,把它们一个个封装起来,并且使他们可互相替换。本模式使得算法的变化可独立于使用它的的客户。 Singleton : 保证一个类只有一个实例,并提供一个访问它的全局访问点。 state : 允许一个对象在其内部状态改变时改变他的行为。对象看起来似乎修改了它所属的类。 Template Method : 定义一个算法的骨架,而将一些步骤延迟到子类中。 template Method 使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。 Visitor : 表示一个作用于某对象结构中的各个元素的操作。它使你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
1. 添加引用:右击引用—添加引用—浏览—找到具体位置
2. 工具—常规—右击选项卡—浏览—找到具体位置(TreeListView.dll)
3. 将控件拖到界面上。
4. 设置属性这里主要设置一下Columns集合与SmallImageList
设置用来显示节点图标。如果不设置SmallImageList属性,无法正常显示。
如果不设置图标的话,图标显示的位置为空白。
5. CheckBoxs属性可以设置为Recursive可以显示成复选框。
6. 添加级别
//第一个参数是要显示的文本,第二个参数是要显示的图标索引。
TreeListViewItem itemA = new TreeListViewItem("A", 0);
itemA.Expand();//展开
itemA.SubItems.Add("AA");//SubItems相当于同一行的不同列值。
itemA.SubItems.Add("BB");//第三列
//二级
TreeListViewItem itemA0 = new TreeListViewItem("A0", 1);
itemA.Items.Add(itemA0);
//三级
TreeListViewItem itemA00 = new TreeListViewItem("A00", 3);
itemA0.Items.Add(itemA00);
treeListView1.Items.Add(itemA);
7. 编写BeforeExpand();BeforeCollapse();BeforeLabelEdit();三个事件的响应函数。就是展开或者折叠时显示哪个图标。
8. http://www.cnblogs.com/greatverve/archive/2010/10/21/winform-treelistview.html
类图关系中各个符号的表示意义: 从左向右 耦合度 不断的升高 (1)虚线 , 箭头 ,实线 , 空心右三角, 实心右三角, 空心菱形 , 实心菱形 1. 虚线 + 箭头 -- 代表依赖,即 代表 两个子类间存在 语义联系, 一个类的改变影响其中一个类中元素的改变 。 例如: 类 A -----> 类 B (这表示 类 A 依赖于 类B ,类 B 是个 独立的类,而类B对类 A 的影响在于,类 B 中某种改变将会导致类 A 中发生改变,就像连锁反应,当然,这里面存在上下级的关系 类 A 的改变不能影响到 类B, 所有 类 B 属于下层 )。 2.实线和箭头 -- 代表关联关系 : 可以理解为一种强依赖关系,例如: 活动者和用例之间的关系,就是关联关系, 两个类的关联关系,以学生和课程为例,不太能直接其中的关系描述清楚,但双方都 3. 虚线 + 空心右三角 : implements 4.实线 + 空心右三角 表示的泛化 -- 含义为继承或者是实现即(is a)。 5.
今天在项目中更新的时候,突然间爆了一个svn的这个错误,当时提示我去clean up操作,结果我执行clean up操作时候,还是报错,网上查找资料原来是使svn进入了死循环的状况,我把如何解决这个冲突的问题分享给大家,希望对遇到此问题的同学们有所帮助!
svn发生冲突时候,提示clean up ,执行clean up操作时报错 “Previous operation has not finished; run 'cleanup' if it was interrupted”。无论你到那个父层次的目录执行“clean up “,都是报一样的错。执行clean up时候,提示要clean up。可能是频繁做了一些改名,文件打开的时候更新或者提交操作,导致svn罢工了。这个也该算是svn的bug吧。类似的情况,其实之前也碰到过。之前都是图省事,把整个svn checkout的主目录都删掉,重新checkout来解决的。但是随着项目的深入开展,要更新的文件越来越多。这个问题迟早要解决的,试试看吧。问题的关键看来需要找到死锁的地方,解锁才行。网上查了下资料。Svn的operation是存放在“work queue’“里的。而“work queue’是在内嵌数据库wc.db的work_queue表中的。看看work_queue表中放了些什么,再做处理。
1.先去下载一个 sqlite3.exe ;
2.将下载好的 sqlite3.exe 文件放到 .svn 的同级目录下;
3.然后启动cmd命令执行找到你的 sqlite3.exe 接下来执行 sqlite3 .svn/wc.db "select * from work_queue"; 回车操作
4.然后会显示看到很多的记录,接下来执行 sqlite3 .svn/wc.db "delete from work_queue"; 【把队列清空】 回车操作
5. 执行 sqlite3 .svn/wc.db "select * from work_queue". 确认一下是否已经清空队列,发现已经没有记录显示,说明已经清空了。
6. 最后再试一下,看是否可以 clean up了。果然成功了。
[转]计算机视觉和模式识别的code
UIUC的Jia-Bin Huang同学收集了很多计算机视觉方面的代码,链接如下:
https://netfiles.uiuc.edu/jbhuang1/www/resources/vision/index.html
Type Topic Name Reference Link Code Structure from motion libmv http://code.google.com/p/libmv/ Code Dimension Reduction LLE http://www.cs.nyu.edu/~roweis/lle/code.html Code Clustering Spectral Clustering - UCSD Project http://vision.ucsd.edu/~sagarwal/spectral-0.2.tgz Code Clustering K-Means 323个Item- Oxford Code http://www.cs.ucf.edu/~vision/Code/vggkmeans.zip Code Image Deblurring Non-blind deblurring (and blind denoising) with integrated noise estimation U. Schmidt, K. Schelten, and S. Roth. Bayesian deblurring with integrated noise estimation, CVPR 2011 http://www.gris.tu-darmstadt.de/research/visinf/software/index.en.htm Code Structure from motion Structure from Motion toolbox for Matlab by Vincent Rabaud http://code.
跟老东家提出了离职,8月底正式走人,开启了休假模式。首先需要感谢的是老东家,虽然老东家整体状况不好,已经不太适合年轻人,但是在那里,我很庆幸遇到非常nice、技术超强的上司,让我受益匪浅。工作节奏虽然慢,但是也让我有时间将自己的私事都处理完,现在回想,选择老东家,在我的这个人生阶段还是一个很不错的选择。 空出来了大半个月的时间,出去天南海北的耍了一周,回来之后在某米和某为之间的offer犹豫了好久,最终选择了后者,工作兴趣还是更倾向于芯片底层,想在底层再沉淀几年,对自主处理器很感兴趣。这段时间也把驾照学了一段。 就这样,工作4年多来第一次有了一个大半个月的假期,工作日早晨看着上班族匆匆忙忙的身影,深切感受到了李涉“偷得浮生半日闲”的惬意,钓钓鱼,看看景,美好的时光总是过的很快。 入职新公司,全新的办公环境,全新的同事,自己也很兴奋,非常有幸加入。 接下来,不用多说,新的开始,全力以赴!
史上最详细最容易理解的HMM文章
http://www.52nlp.cn/hmm-learn-best-practices-four-hidden-markov-models
wiki上一个比较好的HMM例子
分类 隐马尔科夫模型 HMM(隐马尔科夫模型)是自然语言处理中的一个基本模型,用途比较广泛,如汉语分词、词性标注及语音识别等,在NLP中占有很重要的地位。网上关于HMM的介绍讲解文档很多,我自己当时开始看的时候也有点稀里糊涂。后来看到wiki上举得一个关于HMM的例子才如醍醐灌顶,忽然间明白HMM的三大问题是怎么回事了。例子我借助中文wiki重新翻译了一下,并对三大基本问题进行说明,希望对读者朋友有所帮助:
Alice 和Bob是好朋友,但是他们离得比较远,每天都是通过电话了解对方那天作了什么.Bob仅仅对三种活动感兴趣:公园散步,购物以及清理房间.他选择做什么事情只凭当天天气.Alice对于Bob所住的地方的天气情况并不了解,但是知道总的趋势.在Bob告诉Alice每天所做的事情基础上,Alice想要猜测Bob所在地的天气情况. Alice认为天气的运行就像一个马尔可夫链. 其有两个状态 “雨”和”晴”,但是无法直接观察它们,也就是说,它们对于Alice是隐藏的.每天,Bob有一定的概率进行下列活动:”散步”, “购物”, 或 “清理”. 因为Bob会告诉Alice他的活动,所以这些活动就是Alice的观察数据.这整个系统就是一个隐马尔可夫模型HMM. Alice知道这个地区的总的天气趋势,并且平时知道Bob会做的事情.也就是说这个隐马尔可夫模型的参数是已知的.可以用程序语言(Python)写下来: // 状态数目,两个状态:雨或晴 states = (‘Rainy’, ‘Sunny’) // 每个状态下可能的观察值 observations = (‘walk’, ’shop’, ‘clean’) //初始状态空间的概率分布 start_probability = {‘Rainy’: 0.6, ‘Sunny’: 0.4} // 与时间无关的状态转移概率矩阵 transition_probability = { ’Rainy’ : {‘Rainy’: 0.7, ‘Sunny’: 0.3}, ’Sunny’ : {‘Rainy’: 0.4, ‘Sunny’: 0.6}, } //给定状态下,观察值概率分布,发射概率 emission_probability = { ’Rainy’ : {‘walk’: 0.1, ’shop’: 0.4, ‘clean’: 0.5}, ’Sunny’ : {‘walk’: 0.
磁盘调度算法 一、实验内容 模拟电梯调度算法,实现对磁盘的驱动调度。 二、实验目的 磁盘是一种高速、大量旋转型、可直接存取的存储设备。它作为计算机系统的辅助存储器,负担着繁重的输入输出任务,在多道程序设计系统中,往往同时会有若干个要求访问磁盘的输入输出请示等待处理。系统可采用一种策略,尽可能按最佳次序执行要求访问磁盘的诸输入输出请求,这就叫驱动调度,使用的算法称驱动调度算法。驱动调度能降低为若干个输入输出请求服务所须的总时间,从而提高系统效率。本实验要求学生模拟设计一个驱动调度程序,观察驱动调度程序的动态运行过程。
三、实验原理 模拟电梯调度算法,对磁盘调度。
磁盘是要供多个进程共享的存储设备,但一个磁盘每个时刻只能为一个进程服务。
当有进程在访问某个磁盘时,其他想访问该磁盘的进程必须等待,直到磁盘一次工作结束。
当有多个进程提出输入输出请求处于等待状态,可用电梯调度算法从若干个等待访问者中选择一个进程,让它访问磁盘。当存取臂仅需移到一个方向最远的所请求的柱面后,如果没有访问请求了,存取臂就改变方向。
假设磁盘有200个磁道,用C语言随机函数随机生成一个磁道请求序列(不少于15个)放入模拟的磁盘请求队列中,假定当前磁头在100号磁道上,并向磁道号增加的方向上移动。请给出按电梯调度算法进行磁盘调度时满足请求的次序,并计算出它们的平均寻道长度。
实现代码
~~~~~~~~头文件~~~~~~~~~
#pragma once #include<stdio.h> #include<stdlib.h> #include<assert.h> #include<time.h> #define size 20 typedef struct Track { int present;//当前访问的磁道 int nextTrack;//被访问的下一个磁道数 int change;//移动距离 struct Track *next;//指针域 }Track,*pTrack; //初始化 void Init(pTrack* phead); //磁道选择插入 void Insert(pTrack* phead, int m); //磁盘的运行过程 void Action(pTrack* phead); //建立一个新的节点 pTrack SetLNode(int m); //磁道的排序 void Sort(int arr[], int len); //打印磁道调度信息 void Print(pTrack phead); ~~~~~~~~源代码~~~~~~~~
#include"Track.h" void Init(pTrack* phead) { assert(phead); (*phead) = NULL; } void Print(pTrack phead) { double count = 0; pTrack cur = phead; assert(phead); printf("
输入n个无重复0~9的数字,将其所有n位可能的排列组合列出来。
例如输入:123,则输出123,123,132,213,231,312,321
我的思路是使用递归的思想,将123先存放到List里面,每次从List拿出来一个数,把拿出来的数存放到一个save数组里,然后将其从List中删除,然后递归List。
注意:我这里用了一个int型变量mark,用来表示当前save数组的下标,比如说一开始123,我拿出1,然后存放到save数组里,所以当前的mark为0,每当递归一次,mark+=1;
Ps:为了输入方便,输入的数据类型为String型,然后我再把它转为char[];
public class Test{ /** * @param args */ private static List l; private static char[] save;//用于存放排列后的数字 public static void main(String[] args) { Scanner sc = new Scanner(System.in); String s = sc.next(); char[] c = s.toCharArray(); List ltt = new LinkedList(); save = new char[c.length]; for(int i = 0;i<c.length;i++) { ltt.add(c[i]); } l = new LinkedList(); permutation(ltt,0); } static public void permutation(List lt,int mark) { if(mark<save.
这次社会实践,首先带队老师带我们参观了国家级软件园、城市规划馆。让我更深入地了解到IT行业的飞速发展,以及庞大的市场前景和大公司对人才的迫切需求,这让我感觉自己选的专业没让我失望。同时,我也看到了如皋的潜力,和对高新技术发展的重视。
接着,经过丁老师这位行业内顶尖人才的点拨,我发现所谓程序员并不是只能吃青春饭的,是可以让自己在行业内一直发展下去的。我也了解到大学并不是仅仅混张毕业证就可以的,要有真才实学,要真懂技术,才有能力让自己过自己想过的生活。同时丁老师还为我们介绍了有效的学习方法,这也让我收获良多。
实训期间,老师还带我们品尝了日本 料理,并让我们以围绕日本而展开的议题进行讨论并发表自己的意见。进过讨论,和听他人发言,我越发感觉到祖国虽然潜力巨大,但还有待发展,只有真正强大起来才有能力为世界制定有利于自己的游戏规则。反观个人也是如此,一个人有了足够的能力很多问题将不是问题。 经过这次暑期社会实践,我对自己的职业生涯规划有了更清楚更系统的规划。同时,我也了解到IT行业的领域其实远比我想的要宽广,自己有很多可以选择的方向。也让自己明确了将来在IT行业的发展目标。在实训中,通过进一步的了解,我越发热爱自己的专业了,也对自己的职业生涯有了更好的规划,相信自己能有更好的发展。
最后,虽然实训并没有教会我软件方面的技能,却消除了我对自己的未来的迷惑,加深了我对能力的渴求,激励着我一步步走向自己的目标。
终端则
(一) 基础知识
1byte = 8bit
1byte = 2个16进制数
BCD码:用4位二进制数来表示1位十进制数中的0~9这10个数码,即1bcd码=4bit
(二) 报文结构
报文长度
TPDU头
报文头
应用数据
2字节16进制表示的报文长度(不包括本身)
5字节
12字节
交易数据(不定长度)
TPDU头 = ID(60H) + 目的地址(N4) + 源地址(N4),长度为10字节,压缩时用BCD码表示为5个字节长度的数值。
报文头 = 应用类别定义(N2 )+软件总版本号(N2) + 终端状态(N1) + 处理要求 (N1)+ 软件分版本号(N6),总长度为12字节,压缩时用BCD码表示为6个字节长度的数值。
上面的参数值大家只需知道有这回事就行了,具体开发时参见开发文档对号入座
(三) 报文域属性和数据格式(以消费报文为例)
================================
[F002]type=[ LLVAR] len=[016]value=[6225561620345170]
[F003]type=[NUMERIC] len=[006] value=[280000]
[F004]type=[ AMOUNT] len=[012] value=[0.02]
[F011]type=[NUMERIC] len=[006] value=[7]
[F022]type=[NUMERIC] len=[003] value=[22]
[F025]type=[NUMERIC] len=[002] value=[82]
[F035]type=[ LLVAR] len=[037]value=[6225561620345170=17061010000015500000]
[F036]type=[ LLLVAR] len=[104] value=[996225561620345170=1561562915590002
170013300000010101017061=000000000000=00000=0000000622556155000004000]
[F037]type=[ ALPHA] len=[012]value=[110153000006]
微信小程序框架提供的基础组件有八类
一:视图容器 view container
包括:
view 视图容器
scroll-view 可滚动视图容器
swiper 滑块视图容器
view:感觉跟html里的div对应,官方文档里给出的例子是:
<view class="section">
<view class="section_title">flex-direction:row</view>
<view class="flex-wrp" style="flex-direction:row;">
<view class="flex-item bc_green">1</view>
<view class="flex-item bc_red">2</view>
<view class="flex-item bc_blue">3</view>
</view>
</view>
<view class="section1">
<view class="section1_title">flex-direction:column</view>
<view class="flex-wrp" style="height:300px;flex-direction:column;">
<view class="flex-item1 bc_green">1</view>
<view class="flex-item1 bc_red">2</view>
<view class="flex-item1 bc_blue">3</view>
</view>
</view>
但实现效果跟它给出的效果图不一致,style里的flex-direction设置并没有实现
scroll-view:各项属性
scroll-x:允许横向滚动
scroll-y:允许纵向滚动
upper-threshold:距顶部/左边多远时(px),触发scrolltoupper事件
lower-threshold:距底部/右边多远时,触发scrolltolower事件
scroll-top:设置竖向滚动条位置
scroll-left:设置横向滚动条位置
scroll-into-view:值应为某子元素id,则滚动到该元素,元素顶部对齐滚动区域顶部
bindscrolltoupper:滚动到顶部/左边,会触发scrolltoupper事件
bindscrolltolower:滚动到底部/右边,会触发scrolltolower事件
bindsroll:滚动时触发
使用竖向滚动时,需要给scroll-view一个固定高度
=======================================================================================
.wxml代码
<view class="section">
<view>vertical scroll</view>
<scroll-view class="scroll-view" scroll-y="
java2提出了collection的概念,本文对collection框架进行分析,并对java2之前的容器进行回顾。
0x01 从Arraylist说起 什么是集合,简单地说,集合类似可以自适应、动态增长的数组,这也是提出集合概念的一个初衷。 最常见的Arraylist就是集合框架下的一员,准确的说它是一个实现了Collection接口的实现类,内部通过数组的形式存储数组,因此也是一个支持高效随机存储的集合,这里之所用使用高效两字是因为链式存储类型可能对外也提供随机存储操作,然而内部实现则需要多次遍历,因此从实现上并非随机存储。
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable 这里Arraylist是AbstractList的子类,而父类AbstractList是一个抽象类,继承自抽象类AbstractCollection,AbstractCollection实现了多数Collection interface中的方法。每一层抽象类都是对子类型的一个归类,对上一层部分接口方法进行实现或者增加新的方法。
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> public abstract class AbstractCollection<E> implements Collection<E> 0x02 Collection框架成员 collection中涉及成员繁多,从各个接口到中间抽象类再到具体实现类。 java中常用的两个概念collection和collections,都是集合框架下的重要概念,前者是集合类,后者是对集合进行的操作方法,Collections类中有很多静态方法,比如之前文章我们分析过的排序算法sort,或者从一个集合获得对应的同步版本集合的方法如synchronizedList之类,还有统计类的获取最大值最小值等等。本文重点分析Collection,从顶层到常用的实现类逐级介绍。
这里有三个概念,接口,抽象类,实现类。
interface Collection是集合的一个顶层接口,存储单独的元素。Map是一个顶层接口,存储键值对(Map.Entry)。 Collection接口下面有两个子类,接口List和Set,分别表示有序的collection和没有重复元素的Collection,其中Set有一个子接口SortedSet,表示有序的Set。
Map有一个子接口叫做SortedMap,是按照key的升序排列的Map。
Collection ->List (有序的collection) ->Set 不重复的collection ->sortedset有序的set Map(unique keys to values)[ map.entry] ->sortedmap(keys 升序的map) abstract class AbstractCollection 实现大多数的Collection接口方法 ->AbstractList 继承自AbstractCollection并实现多数List接口 ->AbstractSequentialList 继承自Abstractlist提供顺序访问而非随机访问 ->AbstractSet 继承自AbstractCollection并实现多数Set接口 AbstractMap 实现多数map接口 concrete implementation class Linkedlist是AbstractSequentialList 的实现类,抽象类的实现类。 Arraylist 是 AbstractList.
我们肯定都很熟悉商品购物车这一功能,每当我们在某宝某东上购买商品的时候,看中了哪件商品,就会加入购物车中,最后结算。购物车这一功能,方便消费者对商品进行管理,可以添加商品,删除商品,选中购物车中的某一项或几项商品,最后商品总价也会随着消费者的操作随着变化。 现在,笔者对购物车进行了简单实现,能够实现真实购物车当中的大部分功能。在本示例当中,用到了javascript中BOM操作,DOM操作,表格操作,cookie,json等知识点,同时,采用三层架构方式对购物车进行设计,对javascript的综合应用较强,对javascript初学者进阶有一定的益处。 请看主页效果图: 现在读者已经对主页的效果图进行了了解,我在这里附上主页的html代码,供读者参考,建议读者根据自己的思路写代码。请看html代码:
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title>商品列表页面</title> <!--商品列表样式表--> <link rel="stylesheet" type="text/css" href="../css/index.css" /> <!--cookie操作的js库--> <script src="../js/cookie.js" type="text/javascript" charset="utf-8"></script> </head> <body> <div class="container"> <h1>商品列表</h1> <div class="mycar"> <a href="cart.html">我的购物车</a><i id="ccount">0</i> </div> <div class="list"> <dl pid="1001"> <dt> <img src="../images/p1.jpg" /> </dt> <dd>智能手表</dd> <dd>酷黑,棒,棒,棒,棒</dd> <dd>¥<span>998</span></dd> <dd> <button>添加购物车</button> </dd> </dl> <dl pid="1002"> <dt> <img src="../images/p2.jpg" /> </dt> <dd>智能手机001</dd> <dd>金红色,酷酷酷酷</dd> <dd>¥<span>1998</span></dd> <dd> <button>添加购物车</button> </dd> </dl> <dl pid="1003"> <dt> <img src="../images/p3.jpg" /> </dt> <dd>华为手机002</dd> <dd>帅帅帅帅帅帅帅帅帅帅</dd> <dd>¥<span>998</span></dd> <dd> <button>添加购物车</button> </dd> </dl> <dl pid="
注:以下代码中默认 UINT8 a=‘3’,UINT8 b=‘F’,就不写函数调用了;
#include<stdio.h> typedef unsigned char UINT8; typedef unsigned short UINT16; UINT8 transform(UINT8 a,UINT8 b) { UINT8 c; if(a>='0' && a<='9') { a=a-'0'; } else if(a>='A' && a<='F') { a=a-'A'+10; } else if(a>='a' && a<='f') { a=a-'a'+10; } if(b>='0' && b<='9') { b=b-'0'; } else if(b>='A' && b<='F') { b=b-'A'+10; } else if(b>='a' && b<='f') { b=b-'a'+10; } return (a<<4)|b; }
环境:hive的远程模式 在客户端环境操作: 解决方案如下: 1.查看hive-site.xml配置,会看到配置值含有”system:java.io.tmpdir”的配置项 2.新建文件夹/home/grid/hive-0.14.0-bin/iotmp 3.将含有”system:java.io.tmpdir”的配置项的值修改为如上地址 启动hive,成功!
[hadoop@slave1 bin]$ hive 16/09/25 00:02:10 WARN conf.HiveConf: HiveConf of name hive.metastore.local does not exist
Logging initialized using configuration in jar:file:/software/hive/lib/hive-common-1.2.1.jar!/hive-log4j.properties hive>
使用PowerShell命令查询Active Directory中长时间没有登录计算机帐户。本文章以60天为例,大家可以根据需要修改。 下面给出脚本:
# This PowerShell Command will query Active Directory and return the computer accounts which have not logged for the past
# 60 days. You can easily change the number of days from 60 to any number of your choosing. lastLogonDate is a Human
# Readable conversion of the lastLogonTimeStamp (as far as I am able to discern. More details about the timestamp can
$then = (Get-Date).AddDays(-60) # The 60 is the number of days from today since the last logon.
boolean isOnPause; 在onPause里边
try { if (wb_webview != null) { wb_webview.onPause(); isOnPause = true; } } catch (Exception e) { e.printStackTrace(); } 在onResume里边 try { if (isOnPause) { if (wb_webview != null) { wb_webview.onResume(); } isOnPause = false; } } catch (Exception e) { e.printStackTrace(); } /** * 该处的处理尤为重要: * 应该在内置缩放控件消失以后,再执行mWebView.destroy() * 否则报错WindowLeaked */ @Override public void onDestroyView() { if (wb_webview != null) { wb_webview.clearCache(true); wb_webview.clearHistory(); layout_web.removeAllViews(); wb_webview.setVisibility(View.GONE); wb_webview.removeAllViews(); wb_webview.
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
下面直接来看实现:
/** * <p>先进先出队列</p> * * @author white * @version $Id: MyQueen, v 0.1 2016/9/21 0021 下午 8:32 white Exp $ */ public class MyQueen<T> { /** 队列第一个元素 */ private Node first; /** 队列最后元素 */ private Node last; /** 队列大小 */ private int size = 0; /** 队列结构 */ private class Node { T item; Node next; } /** * 队列是否为空 * @return */ public boolean isEmpty() { return size == 0; } /** * 将元素压入队列尾部 * @param item */ public void push(T item) { if (size == 0) { first = new Node(); first.
最近用 matlab画图,需要导出图片,但是发现经过拉伸或者改变了标注的位置以避免挡住图形之后,无法确保导出的每一张图片具有相同的大小。就算可以手动调整图片大小,由于白色背景,也无法确保图片并列起来之后在论文或者需要排版的文档中可以保持在同一直线上。因此,搜索问题,找到好的解决方案。 转载至此,供翻阅。
原文地址:http://nanokaleaf.blog.163.com/blog/static/1808303022012101041553362/、
figure图片存储的时候,使用saveas命令,如果不做设定,只能存储默认大小,但是有的时候需要存储特定比例拉伸的图片。
matlab里面figure相关对象的关系是: screen→figure→axis,所以在设置图片大小的时候,先设定figure相对于screen的位置和大小,然后设定axes相对于figure的位置和大小。
图画出来之后,如下命令就可以储存特定大小的图片。下面给出两种方法。
法一 截图
%=========================================================
set(gcf,'position',[100,100, 500, 300]); %设定figure的位置和大小 get current figure
set(gcf,'color','white'); %设定figure的背景颜色
A=getframe(gcf); imwrite(A.cdata,'try.png') %存储调整过大小的图片
%==================================================
还可以根据需求调整坐标轴的位置和大小,比如不想要白边一类
%====================================================
set(gca,'DataAspectRatio',[3,4,1]); %调整坐标轴比率 get current axes
set(gca,'position',[0,0,1,1]); %调整坐标轴位置
%======================================================
最后说明一下,saveas存储的大小是默认大小,imwrite相当于截屏;存图片的时候要养成好习惯,顺便存一个figure,以方便以后修改。
saveas(gcf,'tt.fig'); 法二 设定保持长宽比存图
如果要发表paper,上面这种做法就不可取了,因为存下的图片是截图;不少杂志(比如PR系列),直接说了,Not Screen!(截图丢失信息,不方便出版方的再次排版一类)。
图片画出来以后,执行以下命令,就可以保持长宽比率保存图片(但是图片的绝对大小会变化)。
set(gcf,'color','white','paperpositionmode','auto');
saveas(gcf,'exprimentLightBundles.eps','psc2');
个人觉得如果期刊会议没有特殊要求,使用截图插入的方式还是可行的。供参考。
一、存储的分类 根据服务器类型分为:封闭系统的存储和开放系统的存储, 封闭系统主要指大型机,开放系统指基于Windows、UNIX、Linux等操作系统的服务器; 开放系统的存储分为: 内置存储外挂存储 外挂存储根据连接的方式分为: 直连式存储(Direct-Attached Storage,简称DAS)网络化存储(Fabric-Attached Storage,简称FAS); 网络化存储根据传输协议又分为: 网络接入存储(Network-Attached Storage,简称NAS)存储区域网络(Storage Area Network,简称SAN) 二、简单对比 DAS: 直连式存储(Direct-AttachedStorage) 存储设备是通过电缆(通常是SCSI接口电缆)直接挂到服务器总线上。 DAS方案中外接式存储设备目前主要是指RAID、JBOD等。
NAS:网络附属存储(Network Attached Storage) 存储设备通过标准的网络拓扑结构(例如以太网)连接 NAS是在网络中放置一个单独的存储服务器,此存储服务器开启网络共享。
SAN:存储区域网络(Storage Area Network) SAN连接又分ISCSI(网口)SAS(SAS口)以及FC(光纤口)连接 注:这种连接需要单独的存储产品。可以通过交换机连接。
三、接口、存储技术发展的一些基本概念 IDE、 SATA、 SCSI、 SAS、 光纤通道 前两种主要是个人电脑上用的,IDE 接口现在很少用了,但老电脑还在用,后面三种主要用在服务器上
ATA硬盘一般使用IDE接口,分为PATA硬盘(即parallelATA,并行ATA硬盘接口规范)和SATA硬盘(即serialATA,串行ATA硬盘接口规范)。SATA其实是scsi体系里抽取出的一部分,也就是说scsi能兼容sata,但sata反过来就不行。scsi本质上还是为服务器准备的磁盘系统,它非常强调所有的控制可以由scsi体系自己完成,不需要cpu控制,所以scsi非常省资源,而sata需要cpu介入控制传输过程SCSI和iSCSI二者不是一个层面的概念。 Scsi技术是一种接口,小型计算机系统接口。服务器上用的。iSCSI技术是新储存技术,供硬件设备使用的可以在IP协议的上层运行的SCSI指令集,这种指令集合可以实现在IP网络上运行SCSI协议,使其能够在诸如高速千兆以太网上进行路由选择。将现有SCSI接口与以太网络(Ethernet)技术结合,使服务器可与使用IP网络的储存装置互相交换资料。SAS是新一代的SCSI技术,和SATA硬盘相同,都是采用串行技术以获得更高的传输速度,并通过缩短连结线改善内部空间等。SAS是并行SCSI接口之后开发出的全新接口。兼容SATA。 四、详细介绍 DAS 直连式存储
DAS技术是最早被采用的存储技术,如同PC机的结构,是把外部的数据存储设备都直接挂在服务器内部的总线上,数据存储设备是服务器结构一部分,但由于这种存储技术是把设备直接挂在服务器上,随着需求的不断增大,越来越多的设备添加到网络环境中,导致服务器和存储独立数量较多,资源利用率低下,使得数据共享受到严重的限制。因此适用在一些小型网络应用中。
DAS存储更多的依赖服务器主机操作系统进行数据的IO读写和存储维护管理,数据备份和恢复要求占用服务器主机资源(包括CPU、系统IO等),数据流需要回流主机再到服务器连接着的磁带机(库),数据备份通常占用服务器主机资源20-30%,因此许多企业用户的日常数据备份常常在深夜或业务系统不繁忙时进行,以免影响正常业务系统的运行。直连式存储的数据量越大,备份和恢复的时间就越长,对服务器硬件的依赖性和影响就越大。
直连式存储与服务器主机之间的连接通道通常采用SCSI连接,随着服务器CPU的处理能力越来越强,存储硬盘空间越来越大,阵列的硬盘数量越来越多,SCSI通道将会成为IO瓶颈;服务器主机SCSI ID资源有限,能够建立的SCSI通道连接有限。
无论直连式存储还是服务器主机的扩展,从一台服务器扩展为多台服务器组成的群集(Cluster),或存储阵列容量的扩展,都会造成业务系统的停机,从而给企业带来经济损失,对于银行、电信、传媒等行业7×24小时服务的关键业务系统,这是不可接受的。并且直连式存储或服务器主机的升级扩展,只能由原设备厂商提供,往往受原设备厂商限制。
NAS 网络接入存储 NFS、CIFS
NAS存储也通常被称为附加存储,改进了DAS存储技术,顾名思义,就是存储设备通过标准的网络拓扑结构(例如以太网)连接。可以无须服务器直接与企业网络连接,不依赖于通用的操作系统,所以存储容量可以很好的扩展,对于原来的网络服务器的性能没有任何的影响,可以确保这个网络性能不受影响。NAS是文件级的存储方法,它的重点在于帮助工作组和部门级机构解决迅速增加存储容量的需求。如今用户采用NAS较多的功能是用来文档共享、图片共享、电影共享等等,而且随着云计算的发展,一些NAS厂商也推出了云存储功能,大大方便了企业和个人用户的使用。
NAS产品是真正即插即用的产品。NAS设备一般支持多计算机平台,用户通过网络支持协议可进入相同的文档,因而NAS设备无需改造即可用于混合Unix/Windows NT局域网内,同时NAS的应用非常灵活。
但NAS又一个关键性问题,即备份过程中的带宽消耗。与将备份数据流从LAN中转移出去的存储区域网(SAN)不同,NAS仍使用网络进行备份和恢复。NAS 的一个缺点是它将存储事务由并行SCSI连接转移到了网络上。这就是说LAN除了必须处理正常的最终用户传输流外,还必须处理包括备份操作的存储磁盘请求。
SAN 存储区域网络存储 SAN存储技术的支撑技术就是光纤通道――FC技术,与前面介绍的NAS存储技术完全不同,它不是把所有的存储设备集中安装在一个服务器中,而是通过光纤通道交换机连接存储阵列和服务器主机,形成一个光纤通道存储在网络中,然后在于企业的局域网进行连接,这种技术的最大特性就是将网络和设备的通讯协议与传输介质隔离开,可以在同一个物理连接上传输,高性能的存储系统合宽带网络使用,使得系统在构建成本和复杂程度上大大降低。SAN经过十多年历史的发展,已经相当成熟,成为业界的事实标准(但各个厂商的光纤交换技术不完全相同,其服务器和SAN存储有兼容性的要求)。
SAN提供了一种与现有LAN连接的简易方法,并且通过同一物理通道支持广泛使用的SCSI和IP协议。SAN不受现今主流的、基于SCSI存储结构的布局限制。特别重要的是,随着存储容量的爆炸性增长,SAN允许企业独立地增加它们的存储容量。SAN的结构允许任何服务器连接到任何存储阵列,这样不管数据置放在哪里,服务器都可直接存取所需的数据。因为采用了光纤接口,SAN还具有更高的带宽。
因为SAN解决方案是从基本功能剥离出存储功能,所以运行备份操作就无需考虑它们对网络总体性能的影响。SAN方案也使得管理及集中控制实现简化,特别是对于全部存储设备都集群在一起的时候。最后一点,光纤接口提供了10公里的连接长度,这使得实现物理上分离的、不在机房的存储变得非常容易。
总结:最后概括一下就是,DAS存储一般应用在中小企业,与计算机采用直连方式,NAS存储则通过以太网添加到计算机上,SAN存储则使用FC接口,提供性能更加的存储。NAS与NAS的主要区别体现在操作系统在什么位置,如下图所示。
如今,随着更多的非结构化数据产生,这对NAS和SAN都是一个挑战,NAS+SAN将是未来主要的存储解决方案,也就是目前比较热门的统一存储。既然是一个集中化的磁盘阵列,那么就支持主机系统通过IP网络进行文件级别的数据访问,或通过光纤协议在SAN网络进行块级别的数据访问。同样,iSCSI亦是一种非常通用的IP协议,只是其提供块级别的数据访问。这种磁盘阵列配置多端口的存储控制器和一个管理接口,允许存储管理员按需创建存储池或空间,并将其提供给不同访问类型的主机系统。
统一存储系统:前端主机接口可支持FC 8Gb、iSCSI 1Gb和iSCSI 10Gb,后端具备SAS 6Gb硬盘扩展接口,可支持SAS、SATA硬盘及SSD固态硬盘具备极佳的扩展能力。实现FC SAN与IP SAN、各类存储介质的完美融合,有效整合用户现有存储网络架构,实现高性能SAN网络的统一部署和集中管理,以适应业务和应用变化的动态需求。主机接口及硬盘接口均采用模块化设计,更换主机接口或硬盘扩展接口,无须更换固件,可大大简化升级维护的难度和工作量。
类 AbstractDocument 的API
http://download.oracle.com/technetwork/java/javase/6/docs/zh/api/javax/swing/text/AbstractDocument.html
MediaProvider在android源代码的packages目录下,作为一个系统的ContentProvider,给外部提供二维表访问的方法。
根据常识,当sd卡,松动时我们是不能播放到sd卡的资源的,所以判断是不是有个广播进行事件监听sd卡的状态。儿系统广播一般会在文件注册,在android.mainfest.xml文件中,我们看到:
<receiver android:name="MediaScannerReceiver"> <intent-filter> <action android:name="android.intent.action.BOOT_COMPLETED" /> </intent-filter> <intent-filter> <action android:name="android.intent.action.MEDIA_MOUNTED" /> <data android:scheme="file" /> </intent-filter> <intent-filter> <action android:name="android.intent.action.MEDIA_UNMOUNTED" /> <data android:scheme="file" /> </intent-filter> <intent-filter> <action android:name="android.intent.action.MEDIA_SCANNER_SCAN_FILE" /> <data android:scheme="file" /> </intent-filter> </receiver> 当满足这三个系统的action时,intentfilter动能匹配成功,查阅android文档发现:分别是开机,加载sd卡,浏览文件三种广播事件。接下来查看MediaScannerReceiver的具体实现,它重写的onReceive方法,
public class MediaScannerReceiver extends BroadcastReceiver { private final static String TAG = "MediaScannerReceiver"; @Override public void onReceive(Context context, Intent intent) { final String action = intent.getAction(); final Uri uri = intent.getData(); if (Intent.ACTION_BOOT_COMPLETED.equals(action)) { // Scan both internal and external storage scan(context, MediaProvider.
无法完成请求,因为文件格式模块不能解析该文件
这是因为文件的后缀名发生了改变。
第一: 选择图片,右击,用记事本打开。
第二: 带有“塒NG”的是PNG格式的图片带有 ??JFIF。样子开头的是jpg格式GIF…开头的是gif图片 然后再用photoshop打开就可以了。
【从零开始学习SpirngBoot—常见异常汇总】
在Spirng Boot中集成了PageHelper,然后也在需要使用分页的地方加入了如下代码:
PageHelper.startPage(1,1); 但是就是不生效呢,数据库的所有数据都查询出来了这是咋回事呢?
这个可能你使用错了版本号,主要是pom.xml文件中的版本的引入,错误的版本引入:
<dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>1.0.0</version> </dependency> 我在博客中已经写的很详细了,但是还是有人会掉进坑里,之所以会有这篇文章的出现就是因为已经有人已经掉进坑里了。那么正确的配置是:
<dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>1.1.1</version> </dependency> 请不要使用1.0.0版本,因为还不支持拦截器插件,
1.1.1 是博主写帖子时候的版本,大家使用最新版本即可
比这个版本还更新的理论上也是能正常运行的,除非官网做了大的调整。
第二种不好使的情况就是重新定义了SqlSessionFactory但是并没有配置对应的PageHelper插件,所以导致使用PageHelper.startPage(1,1);无效,那么如果要重新定义SqlSessionFactory的话,那么以下代码可以作为一个参考,其中红色部分是需要注意的地方: @Bean public SqlSessionFactory sqlSessionFactoryBean(DataSourcedataSource)throws Exception { SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean(); sqlSessionFactoryBean.setDataSource(dataSource); PathMatchingResourcePatternResolver resolver =new PathMatchingResourcePatternResolver(); // 以下这句配置很重要!!!! Interceptor[] plugins = new Interceptor[]{pageHelper()}; sqlSessionFactoryBean.setPlugins(plugins); // 指定mybatisxml文件路径 sqlSessionFactoryBean.setMapperLocations(resolver .getResources("classpath:/mybatis/*.xml")); return sqlSessionFactoryBean.getObject(); } pageHelper代码:
public PageHelper pageHelper() { System.out.println("MyBatisConfiguration.pageHelper()"); PageHelper pageHelper = new PageHelper(); Properties p = new Properties(); p.
WeChat SDK for Go 使用Golang开发的微信SDK,简单、易用。
项目地址:https://github.com/silenceper/wechat
文档地址:DOCS
快速开始 以下是一个处理消息接收以及回复的例子:
//配置微信参数 config := &wechat.Config{ AppID: "xxxx", AppSecret: "xxxx", Token: "xxxx", EncodingAESKey: "xxxx", Cache: memCache } wc := wechat.NewWechat(config) // 传入request和responseWriter server := wc.GetServer(request, responseWriter) server.SetMessageHandler(func(msg message.MixMessage) *message.Reply { //回复消息:演示回复用户发送的消息 text := message.NewText(msg.Content) return &message.Reply{message.MsgText, text} }) server.Serve() server.Send() 完整代码:examples/http/http.go
和主流框架配合使用 主要是request和responseWriter在不同框架中获取方式可能不一样:
Beego: ./examples/beego/beego.goGin Framework: ./examples/gin/gin.go 基本配置 memcache := cache.NewMemcache("127.0.0.1:11211") wcConfig := &wechat.Config{ AppID: cfg.AppID, AppSecret: cfg.AppSecret, Token: cfg.Token, EncodingAESKey: cfg.EncodingAESKey,//消息加解密时用到 Cache: memcache, } Cache 设置
/* translation: 一块电路板,大致分为左右两竖排接口。现在有些接口接错了,导致线路有交错。例如左边的1接口接右2, 左2接右1,这两条线路是交错的。现在问不相交的线路最多多少条? solution: lis, dp 这道题要使线不相交,就会发现这是个lis的模型。所以按照lis求法来解就好了。但是注意要使用O(nlogn) 复杂度的解法,不然会超时。 note: 关于O(nlogn)的解法,定义dp[i]为长度为i的序列中末尾元素最小的值。一开始设最长上升子序列的长度为len=1 从第二位开始遍历数列。如果发现a[i] > dp[len],那就说明dp[++len]的值为a[i]。如果a[i]<=dp[len] 则利用二分查找寻找dp[j]>=a[i]的最小指针并返回。 date: 2016.9.7 */ #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> using namespace std; const int max_p = 40000 + 5; const int inf = 1e30; int ports[max_p]; int n, p; int dp[max_p]; int main() { //freopen("in.txt", "r", stdin); scanf("%d", &n); while(n--) { scanf("%d", &p); for(int i = 1; i <= p; i++) scanf("%d", &ports[i]); dp[1] = ports[1]; int len = 1; for(int i = 2; i <= p; i++) { if(ports[i] > dp[len]) dp[++len] = ports[i]; else { int pos = lower_bound(dp, dp + len, ports[i]) - dp; dp[pos] = ports[i]; } } printf("
众所周知,机器学习可以大体分为三大类:监督学习、非监督学习和半监督学习。监督学习可以认为是我们有非常多的labeled标注数据来train一个模型,期待这个模型能学习到数据的分布,以期对未来没有见到的样本做预测。那这个性能的源头--训练数据,就显得非常感觉。你必须有足够的训练数据,以覆盖真正现实数据中的样本分布才可以,这样学习到的模型才有意义。那非监督学习就是没有任何的labeled数据,就是平时所说的聚类了,利用他们本身的数据分布,给他们划分类别。而半监督学习,顾名思义就是处于两者之间的,只有少量的labeled数据,我们试图从这少量的labeled数据和大量的unlabeled数据中学习到有用的信息。
1、社区及社区发现: 网络图内部连接比较紧密的节点子集合对应的子图叫做社区(community),各社区节点集合彼此没有交集的称为非重叠型(disjoint)社区,有交集的称为重叠型(overlapping)社区。对给定的网络图寻找其社区结构的过程称为“社区发现”。大体上看,社区发现的过程就是一种聚类的过程。
2、基本思想 标签传播算法是不重叠社区发现的经典算法,其基本思想是:将一个节点的邻居节点的标签中数量最多的标签作为该节点自身的标签。给每个节点添加标签(label)以代表它所属的社区,并通过标签的“传播”形成同一标签的“社区”结构。
给每个节点添加标签(label)以代表它所属的社区,并通过标签的“传播”形成同一标签的“社区”结构。一个节点的标签取决于它邻居节点的标签:假设节点z的邻居节点有z1至zk,那么哪个社区包含z的邻居节点最多z就属于那个社区(或者说z的邻居中包含哪个社区的标签最多,z就属于哪个社区)。优点是收敛周期短,无需任何先验参数(不需事先指定社区个数和大小),算法执行过程中不需要计算任何社区指标。
时间复杂度接近线性:对顶点分配标签的复杂度为O(n),每次迭代时间为O( m),找出所有社区的复杂度为O (n +m),但迭代次数难以估计
3、传播过程: 1)初始时,给每个节点一个唯一的标签; 2)每个节点使用其邻居节点的标签中最多的标签来更新自身的标签。 3)反复执行步骤2),直到每个节点的标签都不再发生变化为止。 一次迭代过程中一个节点标签的更新可以分为同步和异步两种。所谓同步更新,即节点z在第t次迭代的label依据于它的邻居节点在第t-1次迭代时所得的label;异步更新,即节点z在第t次迭代的label依据于第t次迭代已经更新过label的节点和第t次迭代未更新过label的节点在第t-1次迭代时的label。
注: 1、迭代次数设定一个阈值,可以防止过度运算; 2、对于二分图等网络结构,同步更新会引起震荡; //3、类似(“强”社区>)定义的结构(该社区>=); 4、每个顶点在初始的时候赋予唯一的标签,即“重要性”相同,而迭代过程又采用随机序列,会导致同一初始状态不同结果甚至巨型社区的出现; 5、如果能预测“社区中心”点,能有效提高社区发现的准确度,大幅提高效率; 6、同一节点的邻居节点的标签可能存在多种社区最大数目相同的情况,取“随机”一个作为其标签
4、算法改进思路:初始化或传播改进 1)给节点或边添加权重(势函数、模块密度优化、LeaderRank值、局部拓扑信息的相似度、标签从属系数等),信息熵等描述节点的传播优先度,进而初步确定社区中心点以提高社区划分的精度; 2)标签初始化改进,如提取一些较为紧密的子结构来作为标签传播的初始标签(非重叠最小极大团提取算法 orz。。。)或通过初始社区划分算法先确定社区的雏形再进行传播。 3)标签随机选择改进,将1)中的权值和节点邻接点的度数等作为参考因素,对标签更新过程进行修正。
1)在社区中寻找不重叠三角形作为起始簇的雏形,以提高算法结果的稳定性和运行效率; 2)添加标签熵属性,在迭代过程中不采用随机序列,而是根据每个节点的标签熵来排序序列; 3)在2)的基础上,为了不完全消除标签传播算法的随机性,将排序好的队列平均分成三个部分,在每个部分内,节点进行随机排列。 4)对于同一节点的邻居节点的标签可能存在多种社区最大数目相同的情况,不使用随机方法,而是分析该节点的邻节点的邻节点集标签分布情况来决定该节点的标签 5)在社区中寻找以度最大的若干节点为中心的“雪花型”结构作为起始簇的雏形 在实现的过程中,将上述方案进行组合衍生出更多的可行方案,初步试验结果表明算法的随机性与稳定性很难同时保证,设定起始簇的结构收敛速度快但有可能生成巨型社区;在节点较少的情况下,标签熵的方法准确率和稳定性最好;至于组合方案初步的试验验证发现效果反而下降了。
5、评价标准:社区发现的主要评价指标有Jaccard指数,fsame指数、NMI(规范化交互信息)以及Modularity(模块度)等,常用的训练集是一些真实基准网络,如:karate(空手道俱乐部,34个节点,78条边的无向图)、Football(美国大学橄榄球联盟、115个节点无向图)等 Modularity(模块度):网络中连接社区内部边所占的比例与另一网络中的内部边的期望值之间的差值 Jaccard指数:衡量社区分割正确性的指标,在已知正确划分的情况下通过正确分类的节点对的数量来计量 NMI:依然是已知划分情况下与真实结果差异度的比较指标,其标准差可以衡量算法的稳定性
6、伪代码
<code class="hljs delphi has-numbering" style="display: block; padding: 0px; color: inherit; box-sizing: border-box; font-family: 'Source Code Pro', monospace;font-size:undefined; white-space: pre; border-radius: 0px; word-wrap: normal; background: transparent;">输入:无向图邻接矩阵AdjacentMatrix,节点个数VerticeNum 输出:存储节点标签的分类数组Community <span class="hljs-comment" style="color: rgb(136, 0, 0); box-sizing: border-box;"
关于maxmemory的设置,如果redis的应用场景是作为db使用,那不要设置这个选项,因为db是不能容忍丢失数据的。 如果作为cache使用,则可以启用这个选项(其实既然有淘汰策略,那就是cache了。。。) 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key, # 当此方法处理后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。 # Redis新的vm机制,会把Key存放内存,Value会存放在swap区
准备两张测试表 09:41:52 kiwi@storedb1> select * from t1; ID1 I ------------- - 1 A 2 B 3 C Elapsed: 00:00:00.00 09:41:56 kiwi@storedb1> select * from t2; I ID - -- A A2 B B2 D D2 我们先来看看full outer join 09:42:14 kiwi@storedb1> select t1.id1,t1.id2,t2.id3 from t1 full outer join t2 on(t1.id2=t2.id2); ID1 I ID ------------- - -- 1 A A2 2 B B2 D2 3 C 再来看看union 09:44:54 kiwi@storedb1> select t1.id1,t1.id2,t2.id3 from t1 left outer join t2 on(t1.
no such slot的问题 1、看类声明中有没有Q_OBJECT 2、看slot函数有没有声明 3、查看slot有没有出现拼写错误
Will try to launch the process directly 某个变量没有初始化
no matching function for call to’QAction::QAction()’ : QMainWindow(parent) 没有构造函数,原来是我把变量定义成这样了QAction undoAction;而应该是QAction *undoAction;
QGroupBox里面的控件不能用 本来用个QGroupBox控件挺好的,结果里面的控件死活不能用,里面的控件enabled为true,后来才明白要把QGroupBox控件放到最下面,不能控件都弄好了,最后在上面套一个QGroupBox,这样会导致被套着的控件不能使用
error: crosses initialization of 在case语句里面出的错,在case里面定义变量时,要把整个case语句用大括号包围起来
no matching function for call to ‘MainWindow::connect(QAction*&, const char*, Wave*&, const char*)’ connect(cleanWaveAction,SIGNAL(triggered()),myWave,SLOT(cleanPoints())); 我当时是这样写的 仔细看没用错啊,每个参数都正确啊,后来才发现我自己写MyWave类没有继承QObject类,而参数是要求是QObject类,所以没有找到这个函数
qualified-id in declaration before ‘(’ token void 函数摆放的位置不对,好像要把被引用的代码放到前面
undefined reference to `vtable for MyCanvas’ 把编译生成的文件删除,再编译了一次就行了
继承一个类后自己定义的slot不管用 要想让继承的类定义的slot能用,必须加上Q_OBJECT,这样这个编译器就不会认为这个slot是父类的槽函数
Component is not ready 组件没有准备好,判断一下就行
作为一个软件开发者,你一定会对网络应用如何工作有一个完整的层次化的认知,同样这里也包括这些应用所用到的技术:像浏览器,HTTP,HTML,网络服务器,需求处理等等。
本文将更深入的研究当你输入一个网址的时候,后台到底发生了一件件什么样的事~
1. 首先嘛,你得在浏览器里输入要网址:
&lt;img src="https://pic4.zhimg.com/5d495eb96b21da9986a4969facf76ebb_b.png" data-rawwidth="591" data-rawheight="103" class="origin_image zh-lightbox-thumb" width="591" data-original="https://pic4.zhimg.com/5d495eb96b21da9986a4969facf76ebb_r.png"&gt; 2. 浏览器查找域名的IP地址
&lt;img src="https://pic2.zhimg.com/cb4968ee75d4e74ea8bf75bb413d9885_b.png" data-rawwidth="228" data-rawheight="96" class="content_image" width="228"&gt; 导航的第一步是通过访问的域名找出其IP地址。DNS查找过程如下:
浏览器缓存 – 浏览器会缓存DNS记录一段时间。 有趣的是,操作系统没有告诉浏览器储存DNS记录的时间,这样不同浏览器会储存个自固定的一个时间(2分钟到30分钟不等)。系统缓存 – 如果在浏览器缓存里没有找到需要的记录,浏览器会做一个系统调用(windows里是gethostbyname)。这样便可获得系统缓存中的记录。路由器缓存 – 接着,前面的查询请求发向路由器,它一般会有自己的DNS缓存。ISP DNS 缓存 – 接下来要check的就是ISP缓存DNS的服务器。在这一般都能找到相应的缓存记录。递归搜索 – 你的ISP的DNS服务器从跟域名服务器开始进行递归搜索,从.com顶级域名服务器到Facebook的域名服务器。一般DNS服务器的缓存中会有.com域名服务器中的域名,所以到顶级服务器的匹配过程不是那么必要了。 DNS递归查找如下图所示:
&lt;img src="https://pic2.zhimg.com/0accd7cdad9a8bfa8d5e344399d661e9_b.png" data-rawwidth="500" data-rawheight="178" class="origin_image zh-lightbox-thumb" width="500" data-original="https://pic2.zhimg.com/0accd7cdad9a8bfa8d5e344399d661e9_r.png"&gt; DNS有一点令人担忧,这就是像 wikipedia.org 或者 facebook.com 这样的整个域名看上去只是对应一个单独的IP地址,不过事实上后面可能对应着多个ip地址(也是学习到了,一个ip地址可以对应多个域名听说一个IP可以绑定多个域名,那么…? - 互联网,一个域名也可以对应多个ip地址负载均衡实现,一个域名对应多个IP地址,cry!)还好,有几种方法可以消除这个瓶颈:
循环 DNS 是DNS查找时返回多个IP时的解决方案。举例来说, Facebook.com 实际上就对应了四个IP地址。负载平衡器 是以一个特定IP地址进行侦听并将网络请求转发到集群服务器上的硬件设备。 一些大型的站点一般都会使用这种昂贵的高性能负载平衡器。地理 DNS 根据用户所处的地理位置,通过把域名映射到多个不同的IP地址提高可扩展性。这样不同的服务器不能够更新同步状态,但映射静态内容的话非常好。Anycast是一个IP地址映射多个物理主机的路由技术。 美中不足,Anycast与TCP协议适应的不是很好,所以很少应用在那些方案中。 大多数DNS服务器使用Anycast来获得高效低延迟的DNS查找。
关于DNS的获取流程,我想再补充些知识: DNS是应用层协议,事实上他是为其他应用层协议工作的,包括不限于HTTP和SMTP以及FTP,用于将用户提供的主机名解析为ip地址。 具体过程如下: ①用户主机上运行着DNS的客户端,就是我们的PC机或者手机客户端运行着DNS客户端了 ②浏览器将接收到的url中抽取出域名字段,就是访问的主机名,比如 http://www.baidu.com/ , 并将这个主机名传送给DNS应用的客户端 ③DNS客户机端向DNS服务器端发送一份查询报文,报文中包含着要访问的主机名字段(中间包括一些列缓存查询以及分布式DNS集群的工作) ④该DNS客户机最终会收到一份回答报文,其中包含有该主机名对应的IP地址 ⑤一旦该浏览器收到来自DNS的IP地址,就可以向该IP地址定位的HTTP服务器发起TCP连接 DNS服务的体系架构是怎样的? DNS domain name system 主要作用就是将主机域名转换为ip地址 假设运行在用户主机上的某些应用程序(如Web浏览器或者邮件阅读器)需要将主机名转换为IP地址。这些应用程序将调用DNS的客户机端,并指明需要被转换的主机名。(在很多基于UNIX的机器上,应用程序为了执行这种转换需要调用函数gethostbyname())。用户主机的DNS客户端接收到后,向网络中发送一个DNS查询报文。所有DNS请求和回答报文使用的UDP数据报经过端口53发送( 至于为什么使用UDP,请参看 为什么域名根服务器只能有13台呢? - 郭无心的回答)经过若干ms到若干s的延时后,用户主机上的DNS客户端接收到一个提供所希望映射的DNS回答报文。这个查询结果则被传递到调用DNS的应用程序。因此,从用户主机上调用应用程序的角度看,DNS是一个提供简单、直接的转换服务的黑盒子。 但事实上,实现这个服务的黑盒子非常复杂,它由分布于全球的大量DNS服务器以及定义了DNS服务器与查询主机通信方式的应用层协议组成。
阅读博客的朋友可以参看视频: Linux kernel Hacker, 从零构建自己的内核
有了C语言这一利器后,不多多拿来用,那就太对不起前面的一系列努力了。那么怎么表现C语言的强大功能呢,如果还只是一味的在界面上输出几行字符,那太没意思,考虑到,我们的目标是做出像windows那样具备舒心的图像用户界面那样的系统,所以在这一节,我们由字符模式切换入画面模式,初步体验下,那些绚丽多彩的图像界面是如何发展而成的。
要想由字符模式转入图形模式,我们需要操作硬件,特别是向显卡发送命令,让其进入图形显示模式,就如同前面我们所做的,要操作硬件,一般需要使用BIOS调用,以下几行就是打开VGA显卡色彩功能的代码:
mov al, 0x13h mov ah, 0x00 int 0x10 其中al 的值决定了要设置显卡的色彩模式,下面是一些常用的模式设置: 1. 0x03, 16色字符模式 2. 0x12, VGA图形模式, 640 * 480 * 4位彩色模式,独特的4面存储模式 3. 0x13, VGA图形模式, 320 * 200 * 8位彩色模式,调色板模式 4. 0x6a, 扩展VGA图形模式, 800 * 600 * 4彩色模式
我们采用的是0x13模式,其中320*200*8 中,最后的数值8表示的是色彩值得位数,也就是我们可以用8位数值表示色彩,总共可以显示256种色彩。
系统显存的地址是0x000a0000,当我们执行上面几句代码后,望显存地址写入数据,那么屏幕就会出现相应的变化了。
我们先看看内核的汇编代码部分(kernel.asm):
%include "pm.inc" org 0x9000 jmp LABEL_BEGIN [SECTION .gdt] ; 段基址 段界限 属性 LABEL_GDT: Descriptor 0, 0, 0 LABEL_DESC_CODE32: Descriptor 0, SegCode32Len - 1, DA_C + DA_32 LABEL_DESC_VIDEO: Descriptor 0B8000h, 0ffffh, DA_DRW LABEL_DESC_VRAM: Descriptor 0, 0ffffffffh, DA_DRW LABEL_DESC_STACK: Descriptor 0, TopOfStack, DA_DRWA+DA_32 GdtLen equ $ - LABEL_GDT GdtPtr dw GdtLen - 1 dd 0 SelectorCode32 equ LABEL_DESC_CODE32 - LABEL_GDT SelectorVideo equ LABEL_DESC_VIDEO - LABEL_GDT SelectorStack equ LABEL_DESC_STACK - LABEL_GDT SelectorVram equ LABEL_DESC_VRAM - LABEL_GDT [SECTION .
首先看下基本概念:
(一)在Java运行时环境中,对于任意一个类,能否知道这个类有哪些属性和方法?对于任意一个对象,能否调用它的任
意一个方法?答案是肯定的。这种动态获取类的信息以及动态调用对象的方法的功能来自于Java 语言的反射(Reflection)机制。
Java 反射机制主要提供了以下功能:
①:在运行时判断任意一个对象所属的类。
②:在运行时构造任意一个类的对象。 ③:在运行时判断任意一个类所具有的成员变量和方法。
④: 在运行时调用任意一个对象的方法
反射机制允许程序在运行时通过反射的API获取类中的描述,方法,并且允许我们在运行时改变fields内容或者去调用methods
(二)Java Reflection APIs简介:
在JDK中,主要由以下类来实现Java反射机制,这些类都
位于java.lang.reflect包中
①:Class类:代表一个类。【注:这个Class类进行继承了Object,比较特别】
②:Field 类:代表类的成员变量(成员变量也称为类的属性)。
③:Method类:代表类的方法。
④:Constructor 类:代表类的构造方法。
⑤:Array类:提供了动态创建数组,以及访问数组的元素的静态方法
简要说下是使用方法的步骤:
要想使用使用反射,我们要去获取我们需要进行去处理的类或者对象的Class对象,其中我们主要有三种方法去获取
①:使用Class的静态方法forName():例如:Class.forName("java.lang.Class");
②:使用XXX.Class语法:例如:String.Class;
③:使用具体某个对象.getClass()方法:例如String str="abc";Class<?> tClass=str.getClass();
先看一个例子:这个例子对于指定的类名,使用反射来获取该类中的所有声明的方法,(使用第一种获取Class对象的方法)(主要代码如下:):
package com.jiangqq.reflection;
/**
* 使用反射来获取Class中的生命的方法,包括私有的方法
*/
import java.lang.reflect.Method;
public classReflection1 {
public static void main(String[] args)throws Exception {
//使用Class去调用静态方法forName()获得java.lang.Class的Class对象
Class<?> tClass =Class.forName("java.lang.Class");
//获取该class中声明的所有方法
Method[] methods =tClass.getDeclaredMethods();
for (Method method :methods) {
System.out.println(method);
}
}
}
(三)查看Class的API发现Class类是Reflection API 中的核心类,它有以下几个常用的方法
工作中多人使用版本控制软件协作开发,常见的应用场景归纳如下:
假设小组中有两个人,组长小张,组员小袁
场景一:小张创建项目并提交到远程Git仓库
场景二:小袁从远程Git仓库上获取项目源码
场景三:小袁修改了部分源码,提交到远程仓库
场景四:小张从远程仓库获取小袁的提交
场景五:小袁接受了一个新功能的任务,创建了一个分支并在分支上开发
场景六:小袁把分支提交到远程Git仓库
场景七:小张获取小袁提交的分支
场景八:小张把分支合并到主干
下面来看以上各场景在IDEA中对应的操作。
场景一:小张创建项目并提交到远程Git仓库 创建好项目,选择VCS - > Import into Version Control -> Create Git Repository
接下来指定本地仓库的位置,按个人习惯指定即可,例如这里选择了项目源代码同目录
点击OK后创建完成本地仓库,注意,这里仅仅是本地的。下面把项目源码添加到本地仓库。
下图是Git与提交有关的三个命令对应的操作,Add命令是把文件从IDE的工作目录添加到本地仓库的stage区,Commit命令把stage区的暂存文件提交到当前分支的仓库,并清空stage区。Push命令把本地仓库的提交同步到远程仓库。
IDEA中对操作做了一定的简化,Commit和Push可以在一步中完成。
具体操作,在项目上点击右键,选择Git菜单
因为是第一次提交,Push前需要指定远程仓库的地址。如下图,点击Define remote后,在弹出的窗口中输入远程仓库地址。
场景二:小袁从远程Git仓库上获取项目源码 即克隆项目,操作如下:
输入小张Push时填写的远程仓库地址
接下来按向导操作,即可把项目从远程仓库克隆到本地仓库和IDE工作区。
场景三:小袁修改了部分源码,提交到远程仓库 这个操作和首次提交的流程基本一致,分别是 Add -> Commit -> Push。请参考场景一
场景四:小张从远程仓库获取小袁的提交 获取更新有两个命令:Fetch和Pull,Fetch是从远程仓库下载文件到本地的origin/master,然后可以手动对比修改决定是否合并到本地的master库。Push则是直接下载并合并。如果各成员在工作中都执行修改前先更新的规范,则可以直接使用Pull方式以简化操作。
场景五:小袁接受了一个新功能的任务,创建了一个分支并在分支上开发 建分支也是一个常用的操作,例如临时修改bug、开发不确定是否加入的功能等,都可以创建一个分支,再等待合适的时机合并到主干。
创建流程如下:
选择New Branch并输入一个分支的名称
创建完成后注意IDEA的右下角,如下图,Git: wangpangzi_branch表示已经自动切换到wangpangzi_branch分支,当前工作在这个分支上。
点击后弹出一个小窗口,在Local Branches中有其他可用的本地分支选项,点击后选择Checkout即可切换当前工作的分支。
如下图,点击Checkout
注意,这里创建的分支仅仅在本地仓库,如果想让组长小张获取到这个分支,还需要提交到远程仓库。
场景六:小袁把分支提交到远程Git仓库 切换到新建的分支,使用Push功能
场景七:小张获取小袁提交的分支 使用Pull功能打开更新窗口,点击Remote栏后面的刷新按钮,会在Branches to merge栏中刷新出新的分支。这里并不想做合并,所以不要选中任何分支,直接点击Pull按钮完成操作。
更新后,再点击右下角,可以看到在Remote Branches区已经有了新的分支,点击后在弹出的子菜单中选择Checkout as new local branch,在本地仓库中创建该分支。完成后在Local Branches区也会出现该分支的选项,可以按上面的方法,点击后选择Checkout切换。
场景八:小张把分支合并到主干 新功能开发完成,体验很好,项目组决定把该功能合并到主干上。
在Java中,子类可继承父类中的方法,而不需要重新编写相同的方法。但有时子类并不想原封不动地继承父类的方法,而是想作一定的修改,这就需要采用方法的重写(Override)。方法重写又称方法覆盖。 在《Java编程思想》中提及到:
“覆盖”只有在某方法是基类的接口的一部分时才会出现。即,必须能将一个对象向上转型为它的基本类型并调用相同的方法。
那么,我们便可以据此来对static方法能否被重写的问题进行验证: 例1: class StaticSuper{ public static String staticGet(){ return "Base staticGet()"; } public String dynamicGet(){ return "Base dynamicGet()"; } } class StaticSub extends StaticSuper{ public static String staticGet(){ return "Derived staticGet()"; } public String dynamicGet(){ return "Derived dynamicGet()"; } } public class StaticPolyMorphism { public static void main(String[] args) { StaticSuper sup = new StaticSub(); System.out.println(sup.staticGet()); System.out.println(sup.dynamicGet()); } } 在例1中,如果基类StaticSuper中的static方法staticGet()在子类StaticSub中被重写了,那么sup.staticGet()返回的结果应该是“Derived staticGet()”,实际上结果是如何呢?运行程序后,我们看到输出是: Base staticGet() Derived dynamicGet() 这说明,非静态方法dynamicGet()的确在子类中被重写了,而静态方法staticGet()却没有。对于这一点,我们也可以通过在子类方法上添加@Overide注解进行验证: 如图所示,在子类中的静态方法staticGet()上添加@Override注解会导致编译报错:The method staticGet() of type StaticSub must override or implement a supertype method(StaticSub类的staticGet()方法必须覆盖或者实现一个父型的方法),而非静态方法dynamicGet()则无此报错信息,这也就印证了我们上面的推论。其实,在Java中,如果父类中含有一个静态方法,且在子类中也含有一个返回类型、方法名、参数列表均与之相同的静态方法,那么该子类实际上只是将父类中的该同名方法进行了隐藏,而非重写。换句话说,父类和子类中含有的其实是两个没有关系的方法,它们的行为也并不具有多态性。正如同《Java编程思想》中所说:“一旦你了解了多态机制,可能就会认为所有事物都可以多态地发生。然而,只有普通方法的调用可以是多态的。”这也很好地理解了,为什么在Java中,static方法和final方法(private方法属于final方法)是前期绑定,而其他所有的方法都是后期绑定了。
spring bean中有两个子元素lookup-method和replaced-method,虽然不常用,但觉得很有用,拿出来聊聊。 1.lookup-method
通常称为获取器注入,spring in action中对它的描述是,一种特殊的方法注入,它是把一个方法声明为返回某种类型的bean,而实际要返回的bean是在配置文件里面配置的,可用在设计可插拔的功能上,接触程序依赖。
首先创建一个父类
创建其子类并覆盖who方法 创建调用方法 配置文件 测试 运行结果 说明
1.可以看到,只是调用了一个没有实现的抽象方法,就完成了执行,这貌似是不合理的(没有实现的抽象方法怎么可以被调用呢?)
2.原因就在于,配置文件中的lookup-method的元素,它直接将kobe代表的bean作为getBean的返回值
3.如果有一天我们不需要kobe的逻辑了,那就重新创建一个需要的bean,并将bean id设置为 lookup-method元素的bean属性值就可以了
2.replaced-method
可以在运行时用新的方法替换旧的方法。还是继续按照上边的例子举例,如果我觉得kobe不行,yaoming行,那我就可以用yaoming替换kobe
接着上边的例子,创建一个bean :Yao,要实现spring的MethodReplacer接口
进行配置
测试
执行结果
说明
1.可以看到,执行who的时候,其实执行的是Yao中的方法,也就是说,被替换了
2.lookup-method要执行新的逻辑,需要新加bean;replaced-method则是将之前执行的逻辑替换掉
需要引用jquery.form.js文件,下载地址:http://download.csdn.net/detail/gorch/9630532
前台页面代码:
<script type="text/javascript" src="/js/jquery.js"></script> <script type="text/javascript" src="/js/jquery.form.js"></script> <form method="post" enctype="multipart/form-data" action="ImportExcel_DuiZhang.jsp" id="formImport"> <table width="100%" cellpadding="5px" id="diaTable" style="display:none;"> <tr> <td> <input type="file" name="uploadFile" id="uploadFile" style="width:290px" /> </td> </tr> <tr> <td style="text-align:center;padding-top:10px;"> <a href="javascript:submitImport()" id="btnOK">确定</a> </td> </tr> </table> </form> <script> function submitImport(){ var epath = $('#uploadFile').val(); if(epath==""){ alert( '导入文件不能为空!'); return; } if(epath.substring(epath.lastIndexOf(".") + 1).toLowerCase()=="xlsx"){ alert( '03以上版本Excel导入暂不支持!'); return; } if (epath.substring(epath.lastIndexOf(".") + 1).toLowerCase()!="xls") { alert( '导入文件类型必须为excel!'); return; } $('#btnOK').linkbutton('disable'); $("#formImport").ajaxSubmit({ type: "
先简单介绍一下场景。
服务架构为:haproxy+keepalive + esb+应用。
在esb层实现 https双向认证。这样就需要 haproxy 使用 tcp 模式进行转发。
配置好 haproxy 后,用restclient模拟客户端发送https请求时 客户端报错:
“Unrecognized SSL message, plaintext connection?”
客户端对同一端口(https的端口)使用http协议发送消息时,服务端(esb)日志报错:
“Unrecognized SSL message, plaintext connection?”
网上搜到一篇文章解释这个问题:http://blog.csdn.net/dtlscsl/article/details/50462721
产生该问题的原因是:
客户端产生“Unrecognized SSL message, plaintext connection?”的异常 是因为对方提供的不是https服务的端口;
服务端产生该异常,是因为客户端以 http协议访问 服务端的https服务。
带着这个思路,查了下 haproxy的配置,发现
defaults
log global
mode http
option httplog
option dontlognull
retries 3
option redispatch
默认的方式为http的!
而esb的服务没有配置传输方式!
listen ESB_https 0.0.0.0:8243
mode tcp
log global
option tcplog
balance roundrobin
server ESB_https_126 172.16.0.126:8243 weight 1 maxconn 10000 check inter 3600s
数据库中存字段比如:
性别:男1、女0
状态:正常1 禁用0
权限:管理员0 普通用户1
如何读取出来后,在JSP页面显示中文意思,这里要用到朝EL表达式的三目运算,与JAVA的三目运用一样
<td>${user.role eq 0?"管理员":"普通用户" }</td> <td>${user.status eq 0?"禁用":"正常" }</td> 转载于:https://www.cnblogs.com/sincoolvip/p/5855376.html
JavaScript的event对象用来描述JavaScript的事件,它主要作用于IE和NN4以后的各个浏览器版本中。event对象代表事件状态,如事件发生的元素,键盘状态,鼠标位置和鼠标按钮状态。一旦事件发生,便会生成event对象,如单击一个按钮,浏览器的内存中就产生相应的event对象。 1.在IE中引用event对象
在IE中,event对象被作为window对象属性访问:
window.event
由于window引用部分是可选的,因此脚本像全局引用一样对待event对象:
event.propertyName
这样,一个事件处理程序的任何语句在不进行特殊预处理和初始化的情况下,都可以访问event对象。
2.在W3C中引用event对象
在W3C事件模型中,event对象引用比较复杂。在多数情况下,必须明确地将event对象作为一个参数传递到事件处理函数中。event对象有时自动作为参数传递,这依赖于事件处理函数如何与对象绑定。
如果使用原始的方法将事件处理函数与对象绑定(通过元素标记的一个属性),则必须把event对象作为参数传递。例如:
onKeyUp= "example(event)"
这是在W3C模型中唯一像全局引用一样明确引用event对象的方式,这个引用只作为事件处理函数的参数,在别的内容中不起作用。如果有多个参数,则event对象引用可以以任意顺序排列,例如:
onKeyUp= "example(this,event)"
与元素绑定的函数定义应该有一个参数变量来“捕获”event对象参数:
function example (widget,evt){…}
还可以通过其他方式将事件处理函数绑定到对象(在NN6+中,使用属性赋值和W3C DOM的addEventListener()方法),将这些事件处理函数的引用赋给文档中所需的对象,例如:
document.forms[0].someButton.onKeyUp= example;
document.getElementById(“myButton”).addEventListener("KeyUp",example,false);
通过这些方式进行事件绑定可以防止自己的参数直接到达调用的函数。但是,W3C浏览器自动传送event对象的引用并将它作为唯一参数,这个event对象是为响应激活事件的用户或系统行为而创建的。也就是说,函数需要用一个参数变量来“接收”传递的event对象:
function example (evt){…}
事件对象包含作为事件目标的对象(例如,包含表单控件对象的表单对象)的引用,从而可以访问该对象的任何属性。
3.event对象的属性
(1)altLeft属性
设置或获取左Alt键的状态。检索左Alt键的当前状态,返回值true表示关闭,false为不关闭。
[window.]event. altLeft
由于altLeft属性是boolean值,因此可以将该属性应用到if语句中,根据获取的值不同而执行不同的操作。
(2)ctrlLeft属性
设置或获取左Ctrl键的状态。检索左Ctrl键的当前状态,返回值true表示关闭,false为不关闭。
[window.]event. ctrlLeft
由于ctrlLeft属性是boolean值,因此可以将该属性应用到if语句中,根据获取的值不同而执行不同的操作。
(3)shiftLeft属性
设置或获取左Shift键的状态。检索左Shift键的当前状态,返回值true表示关闭,false为不关闭。
[window.]event. shiftLeft
由于这3个属性的值同样也都是boolean类型的,所以也可以将它们组合成一个条件在if语句中应用,并且也可以和altKey、ctrlKey和shiftKey属性同时使用。
(4)button属性
设置或获取事件发生时用户所按的鼠标键。
[window.]event.button
button 值 和说明
0 表示没有按键、1 按下左键(主键)、2 按下右键、3 同时按下左右键、4 按下中间键、5 同时按下左键和中间键、6 同时按下右键和中间键、
7 同时按下左键 右键 和中间键
button属性仅用于onmousedown、onmouseup、onmousemove事件,对于其他事件鼠标状态、enevt.button返回0;
(5)clientX属性
获取鼠标在浏览器窗口中的X坐标,该属性是一个只读属性,即只能获取到鼠标的当前位置,不能改变鼠标的位置。
[window.]event. clientX
(6)clientY属性
欢迎大家来参观:
https://github.com/kongzhidea?tab=repositories
欢迎大家来参观:
https://github.com/kongzhidea?tab=repositories
可参考: https://github.com/hsz/idea-gitignore
首先先下载 jar包插件 可以 先下载 在安装, 也可以直接在studio中在线安装
本地安装方法:
在线安装方法:
安装完之后 还需要进行一下配置:
通过以上配置就可以自动添加忽略文件了
strlen() 是C语言标准库包含的一个字符串函数,用来返回字符串 s 的长度(不包括结尾的 0),函数的原型是: size_t strlen(const char *s);
编程实现该函数的代码如下:
size_t myStrlen(const char *str) { size_t index = 0; while (str[index] != '\0') { index++; } return index; } 当然这是用字符数组的形式来实现的,我们也可以用指针来实现,代码如下:
size_t myStrlen(const char *str) { const char *p = str; while (*p != '\0') { p++; } return (p - str); } 进行测试如下:
int main() { char *str = "hello world"; cout << " strlen: " << strlen(str) << endl; cout << "
启动Eclipse提示找不到虚拟机解决方法 转载请注明出处:http://blog.csdn.net/qq347198688/article/details/52447508 原因分析 可能是你在重新添加Android环境变量的时候,重新创建了Path环境变量,这样新的环境变量就会把以前的jdk的Path环境变量给覆盖,然后导致Eclipse找不到虚拟机。
可能是你自己误操作把Path的环境变量给删掉了。
解决方法 你可以把Android环境变量跟JDK环境变量写在一起,中间用;隔开,在Path环境变量中加上;%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;
你也可以在eclipse安装路径下的eclipse.ini文件里开始添加以下2行显式指定路径: -vm (加上你自己的javaw.exe所在地方) 例如: -vm D:\Java\jdk1.6.0_31\bin\javaw.exe
80端口跟8080端口其实作用很像,一般认为,80端口是http默认端口,8080一般是连接代理的。
80端口是http协议的默认端口,浏览器会帮助输入协议,www.*****.com其实是www.*****.com:80,而8080端口,经常在访问某个网站或使用代理服务器的时候,在网址后面,:8080端口,apache tomcat默认的服务端口是8080,Linux服务器里Apache跑的是80端口。
至于apache,tomcat和java的关系,apache是卡车,tomcat是桶,java是水。
渣渣是网上看来的
参:
http://tieba.baidu.com/p/2636657664
http://www.zhihu.com/question/26698345