request.POST.get('test'),这样只能获取列表的最后一项
解决办法: request.REQUEST.getlist('test')
django从view向template传递HTML字符串的时候,django默认不渲染此HTML,原因是为了防止这段字符串里面有恶意攻击的代码。 如果需要渲染这段字符串,需要在view里这样写: from django.utils.safestring import mark_safe 函数里面这样写: pageHtml = mark_safe("你的html代码") 前端页面直接使用{{pageHtml}}即可。 mark_safe这个函数就是确认这段函数是安全的,不是恶意攻击的。
1.升级内核 查看内核版本 uname -r --------------------------------------------------------------------------------------------------- #升级 rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org rpm -Uvh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm yum --enablerepo=elrepo-kernel install kernel-lt -y vim /etc/grub.conf #将新版内核default改为0 reboot 2.安装docker wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo #wget -O /etc/yum.repos.d/epel.repo http://www.hop5.in/yum/el6/hop5.repo yum install docker-io
配置文件 /etc/ssh/sshd_config # 1. 关于 SSH Server 的整体设定,包含使用的 port 啦,以及使用的密码演算方式 Port 22 # SSH 预设使用 22 这个 port,您也可以使用多的 port ! # 亦即重复使用 port 这个设定项目即可! Protocol 2,1 # 选择的 SSH 协议版本,可以是 1 也可以是 2 , # 如果要同时支持两者,就必须要使用 2,1 这个分隔了! #ListenAddress 0.0.0.0 # 监听的主机适配卡!举个例子来说,如果您有两个 IP, # 分别是 192.168.0.100 及 192.168.2.20 ,那么只想要 # 开放 192.168.0.100 时,就可以写如同下面的样式: ListenAddress 192.168.0.100 # 只监听来自 192.168.0.100 这个 IP 的SSH联机。 # 如果不使用设定的话,则预设所有接口均接受 SSH PidFile /var/run/sshd.pid # 可以放置 SSHD 这个 PID 的档案!左列为默认值 LoginGraceTime 600 # 当使用者连上 SSH server 之后,会出现输入密码的画面, # 在该画面中,在多久时间内没有成功连上 SSH server , # 就断线!时间为秒! Compression yes # 是否可以使用压缩指令?当然可以?
本文是《Improved Techniques for Grid Mapping_with Rao-Blackwellized Particle Filters》的大致翻译,难免有不通顺与错误的地方,如有错误请指出,谢谢!
设想一个机器人在一个未知环境中移动,其目的是获得当前环境的地图。地图可以用一个储存每个网格单元颜色的矩阵表示,单元格的颜色只能为黑色或白色。由于传感器与电机都存在误差,运动很可能偏离目标方向,因此机器人很容易“迷路”。所以同步定位与地图构建(SLAM)问题总是被称作“鸡和蛋”的问题:机器人首先需要知道自身的位置去获得一个准确的地图,但是获取地图同样也需要一个准确的定位。定位与地图估计之间的相互依赖使SLAM问题变得非常困难,并且通常需要在高维空间中搜索解决方案。
很多学者对SLAM问题进行了广泛的研究。在2000年,Murphy应用Rao-Blackwellized粒子滤波算法去解决SLAM问题。Rao-Blackwellized的主要方式是用许多粒子去获取准确的地图。因此减少粒子的数量是优化这一算法的主要挑战。
1 地图构建中的Rao-Blackwellized粒子滤波算法 SLAM的核心思想是根据其观测值和其里程计测量信息去估计联合后验概率密度函数(代表地图中的点、代表机器人的轨迹)。可以看出,轨迹和地图需要同时计算出来,这样的计算很复杂而且计算的结果可能不收敛。而RBPF(Rao-Blackwellized Particle Filter)算法利用公式(1)对联合概率密度函数进行因式分解。
因此RBPF可以先估计机器人的轨迹而后再去根据已知的轨迹计算地图。由地图的概率密度函数可以看出,地图强烈依赖于机器人的位姿,所以这个方法是可行的。
地图的概率密度函数可以通过已知位姿的建图方法“mapping with known poses”来计算。后验概率密度函数应用粒子滤波来估计。
粒子滤波算法的核心思想是利用一系列随机样本的加权和近似后验概率密度函数,通过求和来近似积分操作。该算法源于Monte Carlo思想,即以某事件出现的频率来指代该事件的概率。因此在滤波过程中,需要用到概率的地方,一概对变量采样,以大量采样及其相应的权值来近似表示概率密度函数。
其中最普遍的粒子滤波算法为SIR(Samping Importance Resampling)滤波器。该算法通过以下四步完成:
1)预测阶段:粒子滤波首先根据状态转移函数预测生成大量的采样,这些采样就称之为粒子,利用这些粒子的加权和来逼近后验概率密度。 2)校正阶段:随着观测值的依次到达,为每个粒子计算相应的重要性权值。这个权值代表了预测的位姿取第个粒子时获得观测的概率。如此这般下来,对所有粒子都进行这样一个评价,越有可能获得观测的粒子,获得的权重越高。 3)重采样阶段:根据权值的比例重新分布采样粒子。由于近似逼近连续分布的粒子数量有限,因此这个步骤非常重要。下一轮滤波中,再将重采样过后的粒子集输入到状态转移方程中,就能够获得新的预测粒子了。 4)地图估计:对于每个采样的粒子,通过其采样的轨迹与观测计算出相应的地图估计。 SIR算法需要在新的观测值到达时从头评估粒子的权重。当轨迹的长度随着时间的推移而增加时,这个过程的计算复杂度将越来越高。因此Doucet等学者通过式(2)限制重要性概率密度函数来获得递归公式去计算重要性权值。 根据等式2,权值可通过以下公式计算
2 GMapping中的优化算法 GMapping为2007年在ROS中开源的SLAM软件包,是目前使用最广泛的软件包。它可用于室内和室外,应用改进的自适应RBPF算法来进行定位与建图。
Doucet等学者基于RBPF算法提出了改进的重要性概率密度函数并且增加了自适应重采样技术。如上一节所述,为了获得下一迭代步骤的粒子采样我们需要在预测阶段从重要性概率密度函数中抽取样本。显然,重要性概率密度函数越接近目标分布,滤波器的效果越好。
2.1 最优重要性概率密度函数 典型的粒子滤波器应用里程计运动模型作为重要性概率密度函数。这种运动模型的计算非常简单,并且权值只根据观测模型即可算出。然而,这种模型并不是最理想的。当机器人装备激光雷达(如SICK,Hokuyo等)时,激光测得的数据比里程计精确的多,因此使用观测模型作为重要性概率密度函数将要准确的多。图1展示了观测模型的分布明显小于运动模型的分布。由于观测模型的分布区域很小,样本处在观测的分布(图中的区域)的几率很小,在保证充分覆盖观测的分布情况下所需要的粒子数就会变得很多,这将会导致使用运动模型作为重要性概率密度函数类似的问题:需要大量的样本来充分覆盖分布的区域。
为了克服这个问题,可以在生成下一次采用时将最近的观测考虑进去。通过将整合到概率分布中,可以将抽样集中在观测似然的有意义的区域。为此Doucet等提出了最优重要性概率密度函数,式4为粒子权重方差的最优分布。
所以式(4)在机器人装备激光测距仪的时候非常适用。
现在的RBPF算法过程是这样的,首先根据运动模型对机器人下一时刻位姿进行预测,得到预测的状态值并且对其进行采样。第二步是通过最优概率密度函数(4)对各个粒子进行权值的计算。之后进行重采样,根据粒子的权重重新分布粒子,为下次预测提供输入。最后,根据粒子的轨迹计算地图的后验概率密度函数。
图2中展示了在不同场景下的粒子分布情况。(a)为在开放的走廊中,粒子沿着走廊分布。(b)为在死胡同中,粒子分布的不确定性很小,分布的很集中。(c)为根据里程计运动模型预测生成的粒子分布,分布的很分散。
因此,该算法将最近的里程计信息与观测信息同时并入重要性概率密度函数中,使用匹配扫描过程来确定观察似然函数的分布区域,这样就把采样的重点集中在可能性更高的区域。当由于观察不佳或者当前扫描与先前计算的地图重叠区域太小而失败时,将会用图2中(c)所示的里程计运动模型作为重要性概率密度函数。
2.2 自适应重采样 对粒子滤波的性能具有重要影响的另一个因素是重采样步骤。在重采样期间,低权值的粒子通常由高权值的采样代替。由于用来逼近目标分布使用的粒子数量是有限的,所以重采样步骤非常重要。重采样步骤也可能把一些好的粒子滤去,随着的进行,粒子的数目会逐渐减少,最后导致粒子耗尽使该算法失效。通常采用有效粒子数来衡量粒子权值的退化程度,即
这里的为粒子的归一化权值。
Doucet等为了减少进行重采样步骤的次数,提出了一种理论判定方法来判定是否需要进行重采样。只有当下降到阈值(,为粒子数)以下时,才进行一次重采样。由于重采样只在需要时进行,进行重采样的次数将大大减少。多次的实验证明了这种方法大大降低了将好粒子滤去的风险。
3 实验 图3的(a)图是通过配有SICK激光传感器的先锋2(Pioneer 2)机器人在长宽均为28m的室内环境中构建的地图。图3的(b)图显示了该地图的放大细节,展示了该算法建图的准确性。
图4显示了包含几个嵌套闭环的室内环境。在这种环境下地图构建非常困难,闭环增加了Rao-Blackwellized粒子滤波器粒子耗尽的几率。图4展示了RBPF算法在使用60个粒子时可以生成一致并且准确的地图,然而,此时产生的地图有时会产生双层墙壁。
4总结 本文介绍了一种由Doucet等提出的改进Rao-Blackwellized粒子滤波器构建栅格地图的算法。该方法基于最近的传感器信息,测距和扫描匹配过程的观测似然函数来计算高精度的后验概率密度函数。改进算法比原始算法应用了更少的粒子来构建地图,并且使用了一种更准确的方式分布采样粒子。此外,该算法使用了基于有效样本量的自适应重采样策略。该方法减少了粒子滤波器中不必要的重采样过程的次数,从而大大降低了粒子耗尽的风险。
该算法通过应用不同机器人装备激光测距仪进行了多次实验。在这些实验中,该算法所需的粒子数量通常比原始RBPF算法所需的粒子数小一个数量级,证明了其鲁棒性、优越性。
REFERENCES http://blog.csdn.net/u010545732/article/details/17462941 粒子滤波(Particle filter)matlab实现
http://blog.csdn.net/heyijia0327/article/details/40899819 Particle Filter Tutorial 粒子滤波:从推导到应用
http://ishare.iask.sina.com.cn/f/24615049.html 粒子滤波理论
553 Could not create file. 在centOS7上使用vsftpd搭建ftp服务器,参考了这篇博客:http://blog.csdn.net/the_victory/article/details/52192085
搭建完成之后,可以正常的进行用户登录和上传文件等操作,却不可以上传文件,一直提示553的错误。网上很多人说是防火墙导致的,然而在尝试了他们的解决方法之后,依然存在这个问题。
最后的解决方法是,集合了下面两篇文章的解决方案 http://blog.csdn.net/cmustard/article/details/53696456 http://blog.csdn.net/bluishglc/article/details/42399439
给对应用户目录提高读写权限: sudo chmod -R 777 [dir]修改vsftpd.conf,添加 allow_writeable_chroot=YES
经过几天的奋战,我们小组,排除万难,终于完成这个项目
还记得我们遇到的两个比较大的问题:
1、从外设摄像头获取视频图片数据,服务端处理转换后,发送给客户端,客户端接收这个数据并显示;要实现这个功能,我们需要客户端从服务端先获取数据的长度,然后获取数据,每次来回获取都需要这样(因为我们小组成员刚开始时是每次直接从服务端处理完就直接发送直接接受的方式进行处理的,结果是,客户端只是第一次闪一下图片就不显示了,成员们和我一起讨论,作为此次组长的我,提供了一个方案用标志位的方式实现),但是我们在处理获取完数据长度后获取数据的方式上遇到了问题,成员们好像没有完全理解我的意思,结果弄了好久还是没出来结果,他们就尝试了更复杂的方式把数据长度和数据封装为一个包,不过很费时间,由于时间限制,老师问及的时候,我们互相沟通了,老师也建议用标志位的方式实现可以的呢,,然后老师帮忙检查了下我们程序,把if()if()换成了if()else(),就没问题的,我之前和小组成员交流的时候就是这个意思呢,不过直接这样还不行哦,方式对了,不过里面还需要增加一句延时才行哦。
2、系统移植,这个是真的无语,在第九天的时候我们弄了一晚上,我们小组还在汉庭酒店的大厅还加班到凌晨一点多呢,因为第十天的早上八点多就要开始答辩了呢,回去后还要收拾东西,因为答辩完就在那吃完饭后就直接要火车回学校了;然后,答辩这个早上还早早的起来写完昨晚还没写完的PPT呢,这个耗费了我们很多的精力与耐力呢;
不过,最后答辩的时候,感觉还是很不错的哦。
3、总而言之,感觉搞编程、开发类的,需要很多耐心哦。
项目相关代码:
提供一个连接,刚上传,正在审核,所以给个我的资源界面的链接
http://download.csdn.net/my
最近在使用String的时候遇到用string接字符串,结果出现String 接不住,数据过多,超出长度了.原来String是有容量限制的 我们可以使用串接操作符得到一个长度更长的字符串,那么,String对象最多能容纳多少字符呢?查看String的源代码我们可以得知类String中 是使用域 count 来记录对象字符的数量,而count 的类型为 int,因此,我们可以推测最长的长度为 2^32,也就是4G。 不过,我们在编写源代码的时候,如果使用 Sting str = "aaaa";的形式定义一个字符串,那么双引号里面的ASCII字符最多只能有 65534 个。为什么呢?因为在class文件的规范中, CONSTANT_Utf8_info表中使用一个16位的无符号整数来记录字符串的长度的,最多能表示 65536个字节,而java class 文件是使用一种变体UTF-8格式来存放字符的,null值使用两个字节来表示,因此只剩下 65536- 2 = 65534个字节。也正是变体UTF-8的原因,如果字符串中含有中文等非ASCII字符,那么双引号中字符的数量会更少(一个中文字符占用三个字节)。如果超出这个数量,在编译的时候编译器会报错 超出后bug如下: 11-16 17:07:51.301 12598-12598/com.hx.socialapp E/JavaBinder: !!! FAILED BINDER TRANSACTION !!! (parcel size = 520536) 11-16 17:07:51.326 12598-12598/com.hx.socialapp E/RongLog: [ RongExceptionHandler ] uncaughtException java.lang.RuntimeException: android.os.TransactionTooLargeException: data parcel size 520536 bytes at android.app.ActivityThread$StopInfo.run(ActivityThread.java:4050) at android.os.Handler.handleCallback(Handler.java:836) at android.os.Handler.dispatchMessage(Handler.java:103) at android.os.Looper.loop(Looper.java:203) at android.app.ActivityThread.main(ActivityThread.java:6436) at java.lang.reflect.Method.invoke(Native Method) at com.android.internal.os.ZygoteInit$MethodAndArgsCaller.run(ZygoteInit.java:1113) at com.
在一个继承体系中,如果在构造函数里,或者析构函数里调用虚函数,那么虚函数会生效吗?构造函数会析构函数不会,还是构造函数不会析构函数会,还是都会或者都不会?
让我们用一个例子来解答一下。
代码如下,
运行结果如下,
从结果来看,虚函数均没有生效。为什么会这样呢?其实仔细想想就不难理解了。
首先对于构造函数的情况,构造的顺序是先基类后子类,所以在调用基类构造函数的时候这个子类压根还没构造,所以虚函数不会生效。
类似的,对于析构函数,先析构子类后基类,当调用基类析构函数的时候,子类已经析构掉了,所以虚函数也不会生效。
一、实现功能及主要思路 实现功能:
iOS 开发中有时候会有夜间模式(换肤设置)的需求, 其实主要是更改相关颜色操作.每次切换夜间/白天模式时,都会发出通知给所有ViewController,让它们切换到相应的主题.
主要思路:
1. 创建一个管理模式主题的单例管理类ThemeManage
2. 封装好需要做夜间模式变色处理的控件扩展:UIView (ThemeChange), UINavigationBar (ThemeChange), UITabBar (ThemeChange), UILabel (ThemeChange), UIButton (ThemeChange)
3. 在 AppDelegate里先获取夜间模式状态, 根控制器里先设置tabBar 及 子控制器里navigationBar的夜间模式状态
4. 添加控制白天/黑夜模式item,发通知切换相对应i模式及image
5. 添加相关控件是否黑夜模式下已更换字色和背景色
二、程序实现 Step1. 创建一个管理模式主题的单例管理类
ThemeManage.h 文件里添加模式管理单例:
1 2 3 4 5 6 // 是否是夜间 YES表示夜间, NO为正常 @property(nonatomic, assign) BOOL isNight; /** * 模式管理单例 */ + (ThemeManage *)shareThemeManage; ThemeManage. m 文件:
单例的初始化:
1 2 3 4 5 6 7 8 + (ThemeManage *)shareThemeManage { static dispatch_once_t onceToken; dispatch_once(&onceToken, ^{ themeManage = [[ThemeManage alloc] init]; }); return themeManage; } 重写isNight的set方法 (是否是夜间 YES表示夜间, NO为正常)
一、实现功能 1. 广播跑马灯
2. 弹幕动画
3. 直播点赞动画
4. 直播点赞图片动画
5. 烟花动画
6. 雪花动画
二、程序实现 1. 广播动画特效:
思路:
1. 初始化广播视图
2. 设置广播公告广告内容
3. 添加动画效果
初始化广播视图, 广播活动标题按钮 与 广播活动标题标签 控件大小一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 /** * 设置广播视图 */ - ( void )setupBroadcastingView { // 设置广播活动标题按钮 UIButton *activityBtn = [UIButton buttonWithType:UIButtonTypeCustom]; activityBtn.
之前实习期间一直忙于学习,没有时间整理,现抽空理理,按照时间顺序哈
2017.10.29出发,30日正式开始 到 2017.11.8下午结束回来呢
#include <stdio.h> main() { int i,n; long p=1,j=1; printf("please enter n:"); scanf("%d",&n); for(i=1;i<=n;i++) { p=i*i; printf("%d=%1d\n",i,p); } for(i=1;i<=n;i++) { j=i*i*i; printf("%d=%1d\n",i,j); } }
《 Centos7下Nginx安装图文详解 》 前言: Nginx (engine x) 是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器。
Nginx是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Rambler.ru站点(俄文:Рамблер)开发的。
Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,并在一个BSD-like 协议下发行。 其特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:
百度、京东、新浪、网易、腾讯、淘宝等。
nginx安装环境: Linux 版本:centos-7.2
Nginx 版本:nginx-1.9.9
安装Nginx之前我们需要下载Linux版Nginx,这儿有下载地址 : Nginx-1.9.9 Linux版 最新 nginx 下载 下载完成后将Nginx解压缩包上传到Linux,如下图:
输入命令 " tar -zxvf nginx-1.9.9.tar.gz " 进行解压,如下图:
准备Nginx的安装环境: 安装 pcre 库: PCRE(Perl Compatible Regular Expressions)是一个Perl库,包括 perl 兼容的正则表达式库。nginx的http模块使用pcre来解析正则表达式,所以需要在linux上安装pcre库。
输入命令 " yum install -y pcre pcre-devel " 进行安装,如下图: 注:pcre-devel是使用pcre开发的一个二次开发库。nginx也需要此库。
安装 zlib 库: zlib库提供了很多种压缩和解压缩的方式,nginx使用zlib对http包的内容进行gzip,所以需要在linux上安装zlib库。
输入命令 " yum install -y zlib zlib-devel " 进行安装,如下图:
安装 gcc 环境: 安装nginx需要先将官网下载的源码进行编译,编译依赖gcc环境,如果没有gcc环境,需要安装gcc。
标题 一、说明二、测试-文件路径写死三、测试-文件路径不写死 一、说明 1、本文的测试环境是win764+vs2013+Qt5.6。
2、使用函数shellExecute调用windows图片浏览器或者IE浏览器打开jpg格式的图片。
3、使用函数shellExecute调用windows office打开word文档。
4、使用该函数注意中文路径的问题( 如有中文路径问题,可以参考我的博客,博客地址:http://blog.csdn.net/toby54king)和函数shellExecute中代码内容的书写格式。
二、测试-文件路径写死 测试通过的方法,文件路径没有写死:
string appPath = QApplication::applicationDirPath().toStdString() + "/pictureFile/testShow.jpg"; int l = MultiByteToWideChar(CP_ACP, 0, appPath.c_str(), -1, NULL, 0); LPWSTR filePath = new TCHAR[l]; MultiByteToWideChar(CP_ACP, 0, appPath.c_str(), -1, filePath, l); ShellExecute(NULL, (LPCWSTR)L"open", filePath, (LPCWSTR)L"", (LPCWSTR)L"", SW_SHOW); //ShellExecute(NULL, (LPCWSTR)L"open", (LPCWSTR)L"E:/Component/Release_Win32/pictureFile/testShow.jpg", (LPCWSTR)L"", (LPCWSTR)L"", SW_SHOW); //IE浏览器显示图片 //ShellExecute(NULL, (LPCWSTR)L"open", (LPCWSTR)L"iexplore", (LPCWSTR)L"E:/work/testShow.jpg", NULL, SW_SHOWNORMAL); 三、测试-文件路径不写死 测试通过,文件路径写死
ShellExecute(NULL, (LPCWSTR)L"open", (LPCWSTR)L"iexplore", (LPCWSTR)L"E:/work/testShow.jpg", NULL, SW_SHOWNORMAL); //ShellExecute(0, (LPCWSTR)L"open", (LPCWSTR)L"CALC.EXE", (LPCWSTR)L"", (LPCWSTR)L"", SW_SHOWNORMAL); //appPath = QApplication::applicationDirPath().
举个例子,客户端访问80端口,服务器需要将请求转发至8080端口处理,
我们希望将客户端传递的headers过滤,再设置内部转发请求header(test:"123"),
坑(通过ngx.req.set_header设置的请求头,会被过滤):
server { listen 80; location / { content_by_lua ' ngx.req.set_header("test", "123") local response = ngx.location.capture("/upstream", { method = ngx.HTTP_GET, vars = { my_uri = "/hello", }, body = "", } ) ngx.exit(200) '; } location /upstream { set $my_uri $my_uri; proxy_pass_request_headers off; proxy_pass http://127.0.0.1:8080$my_uri; } } server { listen 8080; location /hello { content_by_lua ' for k, v in pairs(ngx.req.get_headers()) do ngx.log(ngx.ERR, "###: " .. k .
问题描述: 1.U盘插上,系统有反应,但是却不识别,绝大多数是驱动的问题: 解决办法:
将U盘插在电脑上,控制面板-设备管理器-通用穿行总线控制器-USB大容量存储设备-在这个选项上右键-卸载-拔下U盘-重新插上-好了没? 如果上个步骤还不行,再试下下面这个步骤: 设备管理器——其他设备——删除(或卸载)-拔下U盘-重新插上-好了没?还不行,再试试下面这个步骤: 设备管理器——磁盘驱动器——删除相应驱动(或卸载相应驱动,一般都是以U盘品牌命名的驱动)-拔下U盘-重新插上-好了没?如果以上步骤还不行,那就可能不是驱动的问题了,或许是盘符的问题? 在 计算机 上右键 管理,进入到计算机管理-磁盘管理界面,如下图所示: 如果下图的分区都做好了,但是上面列表却没有显示,这说明没有分配盘符,在下图的分区没分区的磁盘上,右键就可以添加新的驱动器和盘符,这里注意选个没有用到的盘符即可。总结: 一般都是驱动问题,除非U盘本身和自己电脑有问题,本文主要解决的是驱动的问题。怎么判断是驱动的问题呢? 可以分两步: 1.用你的U盘去插别的电脑,如果是好的,在你的电脑没反应(并不是完全没反应,应该能听到叮咚一声),这说明你的U盘没有问题。 2.用别人的U盘插在你的电脑上,如果能够正常识别,这就说明你的Usb接口没有问题,供电电压是够的,足够满足物理的硬件条件。 如果以上两条都满足,却U盘问题还没有解决,这个时候一定要细心检查设备管理器中的设备问题,一般哪里有问题都会有个问号的标识标示出来,这个时候把这个标识所在的分支打开,删除或者卸载,再将U盘重新插上即可!
刷新完固件后opkg update报错的解决方法
一、更改设备ip
当你使用lan口接入局域网后,如果你ping不通局域网上的其他设备ip,那么需要更改ip。
vim /etc/config/network
修改lan口的ip为局域网下同一网段的ip,注意不要和其他设备的id冲突了。
重启网络的方法:/etc/init.d/network restart
二、添加网关和dns
1.添加网关
更改ip并重启网络后发现可以ping通局域网下的其他设备了,但是ping网关时,发现如下错误:
ping: sendto: Network is unreachable,使用route查看一下,如果发现只有一行内容,那么就是没有设置网关,同样打开/etc/config/network,在lan口下增加gateway的ip(参考下面的network的lan口的配置图),然后重启网络。
正确的route结果应该是这样:
2.添加dns
这时候你ping外网网页的ip地址应该是没问题了,可以试一下。但是直接ping外网网址的域名,似乎提示:bad address:xxx,能ping通ip却ping不同其域名,那么就是其域名解析有问题了,域名服务器dns没设置?dns设置错了?ok,在/etc/config/network中的lan口再增加dns服务器地址(参考下面的配置图),一般为你的网关地址,最后重启网络,试一下能ping通域名没。
附上结果图:
附上network的lan口的配置图:
三、更改源地址
如果你能ping通外网域名,opkg时仅仅提示404错误,那么就是opkg.conf中的网址有问题
你要修改一下源。
错误截图:
vim /etc/opkg.conf 源是openwrt官方提供的,根据opkg.conf上面的http地址,我查到我的opkg.conf中的http地址中mt7628目录不存在的,而应该是mt7620a,因而造成的404错误导致opkg update失败,更改如下: 更改后再update,结果如下:
在实际开发中,经常会遇到需要找出(删除)一个list中某些元素的属性相同的元素,或者两个list中某些元素的属性相等的元素,这种方法很多,这里整理列出一些:
废话不说,上代码,有注释掉的你们自己看
import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; public class Test { public static void main(String[] args) { List<Student> testList = new ArrayList<Student>(); testList.add(new Student("张一")); testList.add(new Student("张二")); testList.add(new Student("张三")); testList.add(new Student("老王")); testList.add(new Student("张四")); testList.add(new Student("张五")); testList.add(new Student("张六")); testList.add(new Student("张七")); testList.add(new Student("老王")); testList.add(new Student("张八")); testList.add(new Student("张九")); testList.add(new Student("老王")); List<Student> repeatList = new ArrayList<Student>();//用于存放重复的元素的list // 以一种方法:两个循环(最蠢的方法) for (int i = 0; i < testList.size() - 1; i++) { for (int j = testList.
1-17 11:31:33.753 26912-26912/com.hx.socialapp E/ActivityThread: Activity com.hx.socialapp.MainActivity has leaked IntentReceiver com.hx.socialapp.activity.user.UserFragment$MessageReceiver@23b67f8 that was originally registered here. Are you missing a call to unregisterReceiver()? android.app.IntentReceiverLeaked: Activity com.hx.socialapp.MainActivity has leaked IntentReceiver com.hx.socialapp.activity.user.UserFragment$MessageReceiver@23b67f8 that was originally registered here. Are you missing a call to unregisterReceiver()? at android.app.LoadedApk$ReceiverDispatcher.<init>(LoadedApk.java:1253) at android.app.LoadedApk.getReceiverDispatcher(LoadedApk.java:966) at android.app.ContextImpl.registerReceiverInternal(ContextImpl.java:1408) at android.app.ContextImpl.registerReceiver(ContextImpl.java:1388) at android.app.ContextImpl.registerReceiver(ContextImpl.java:1382) at android.content.ContextWrapper.registerReceiver(ContextWrapper.java:586) at com.hx.socialapp.activity.user.UserFragment.onCreateView(UserFragment.java:110) at android.support.v4.app.Fragment.performCreateView(Fragment.java:2192) at android.support.v4.app.FragmentManagerImpl.moveToState(FragmentManager.java:1299) at android.support.v4.app.FragmentManagerImpl.moveFragmentToExpectedState(FragmentManager.java:1528) at android.support.v4.app.FragmentManagerImpl.moveToState(FragmentManager.java:1595) at android.support.v4.app.FragmentManagerImpl.dispatchActivityCreated(FragmentManager.java:2900) at android.support.v4.app.FragmentController.dispatchActivityCreated(FragmentController.java:201) at android.support.v4.app.FragmentActivity.onStart(FragmentActivity.java:603) at android.
我们经常会有多行多列按钮的页面, 这个时候我们通常会选择循环创建按钮, 然后进行按钮单选或者多选的操作!
一、程序实现 一. 单选逻辑处理 1. 创建按钮控件数组及标签数组, 并升级当前选中按钮为属性,方便使用
1 2 3 4 5 6 // 标签数组(按钮文字) @property (nonatomic, strong) NSArray *markArray; // 按钮数组 @property (nonatomic, strong) NSMutableArray *btnArray; // 选中按钮 @property (nonatomic, strong) UIButton *selectedBtn; #pragma mark - 懒加载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 - (NSArray *)markArray { if (!_markArray) { NSArray *array = [NSArray array]; array = @[@ "
引子 这几天一直在忙一个可滑动的转盘的demo,网上也有类似的例子,但是根据老板的需求来改他们的代码,还不如重新写个完全符合需求的插件。
想法很美好,但是新手上路...
效果链接文末
需求 image 这个demo给的非常简单,能转动的地方有三处,内盘、外盘和指针,这三个上的集合的交集产生一个链接,通过中间的按钮跳转。
这个需求乍一看老简单老简单的,但是作为一个菜鸡第一次上道,堪比开碰碰车,头破血流。
分析 在做之前,也是根据自己的理解来写的旋转角度问题:
转盘转动的做法是:设定圆心为转动原点,动态的修改旋转角度;在touchmove 计算两点与中心点的角度。 在旋转上大体上需要明白的也就这两点,但是在实际计算角度上却有很多问题。
弯道1之计算角度 计算角度首先要用到的一个数学方法就是反函数,在JS中表示反函数的方法有两个:
Math.atanMath.atan2 说实话它们两个的区别对于本次demo真没有测出什么差异来,但是相比 atan在y特别大的时候会有误差产生的情况下,果断选择了atan2
(function($){ $.fn.CompassRotate=function(options){ var defaults={ trigger:document, centerX:0, centerY:0, debug:false },_this=this; var ops=$.extend(defaults,options); function Init(){ //初始化圆心点 if(ops.centerX==0 && ops.centerY==0){ ops.centerX=_this.offset().left+_this.width()/2; ops.centerY=_this.offset().top+_this.height()/2 } $(ops.trigger).on("touchstart",function(event){ $(document).on("touchmove",movehandle); }); $(ops.trigger).on("touchend",function(event) { $(document).unbind("touchmove"); }); } //鼠标移动时处理事件 function movehandle(event){ var touch = event.originalEvent.targetTouches[0]; var dis = angle(ops.centerX,ops.centerY,touch.pageX, touch.pageY); if(ops.debug) console.log(ops.centerX+"-"+ops.centerY+"|"+touch.pageX+"-"+touch.pageY+" "+dis); rotate(dis); } //计算两点的线在页面中的角度 function angle(centerx, centery, endx, endy) { var diff_x = endx - centerx, diff_y = endy - centery; var c=360 * Math.
在我们日常的学习生活中,因为课程资料太多,常常人手一台电脑,外加一两个移动U盘,就是为了存储重要文件。可如果连存储设备也出现了资料丢失的问题,那又该如何找回呢?
现在的互联网越来越发达,数据恢复行业也出现了许多的数据恢复类软件,让我们不用出门就能在家自己恢复数据,以迷你兔数据恢复为例,我们来看看要怎样恢复被删除的资料。
首先,官网下载迷你兔数据恢复工具免费版(https://www.minitu.cn/download),安装好之后,点开软件主界面,我们选择【删除恢复】
然后,选择丢失资料的磁盘,再点击【扫描】。软件会完成所有扫描,我们只需等待几分钟。
扫描完成后,迷你兔会自动生成一个丢失数据的列表,在这个列表中选择需要恢复的资料,然后勾选并保存即可。
使用Android Studio签名 选择主菜单 “Build” --> “Generate Signed APK…” 弹出如下窗口 点击 “Create new…”,按要求填写信息,然后点击 “OK” 弹出如下界面,点击 “next” 弹出如下界面,点击 “finish” 如果已有证书,可以在第二步中选择 “Choose existing…”
使用命令对APK签名 创建对应Key store库,在命令行输入keytool -genkeypair -alias yxf -keyalg RSA -validity 25 -keystore YuXiFang.jks
参数说明: -genkeypair:指定生成签名证书-alias:签名证书别名-keyalg:签名证书的算法。使用RSA算法-validity:签名证书的有效期-keystore:签名证书的存储名称 执行成功会要求填写相应数据
在项目的app\build\outputs\apk目录中可找到未签名的apk 3.把apk和签名放在统一路径中,执行以下命令jarsigner -verbose -sigalg SHA1withRSA -keystore YuXiFang.jks -signedjar chat_signed.apk chat.apk yxf
参数说明:
-verbose:指定生成详细输出-keystore:指定签名证书-sigalg:指定签名时的算法,默认是SHA256withRSA-signedjar:后面3个参数分别为签名后的apk、未签名的apk、签名证书的别名 成功后会显示如下信息
在微信,QQ,微博等开放平台注册时需要输入签名信息,可以输入一下命令行查询keytool -list -v -keystore xxx.jks
把得到的MD5值去掉分号,大写字母转为小写就得到了开放平台的应用签名
1、什么是协同程序 Lua中的协同程序(coroutine)与线程比较类似,拥有独立的堆栈,独立的局部变量,独立的指令指针,同时又与其它协同程序共享全局变量和其他大部分东西。 协同程序与线程的区别: 线程与协同程序的主要区别在于,一个具有多个线程的程序可以同时运行几个线程,而协同程序却需要彼此协作的运行。在任一指定时刻只有一个协同程序在运行,并且在这个正在运行的协同程序只有在明确的被要求挂起的时候才会被挂起。协同程序有点类似同步的多线程,在等待同一个线程锁的几个线程有点类似协同。
2、协同程序所用到的函数 coroutine.create() 参数:参数是一个函数; 返回值:返回的是线程id 功能:创建一个协同程序,此时这个协同程序是被挂起(suspend)的,等到resume进行唤醒。
coroutine.resume() 参数:第一个参数是create返回的线程id,剩下的参数是create中函数对应发的参数。 返回值:resume成功返回true,失败返回false。 功能:用于唤醒一个正在挂起的协同程序。
coroutine.yield() 参数:线程id。 返回值:成功返回true,失败返回false。 功能:用于挂起一个正在执行的协同程序。它配合resume还有更多应用。
coroutine.status() 参数:线程的id。 返回值:返回协同程序(coroutine)的状态。 功能:coroutine程序有三种状态,分别是dead,suspend,running。
coroutine.wrap() 参数:一个函数。 返回值:返回一个函数。 功能:创建一个协同程序,并返回一个函数,一旦你调用这个函数,就进入coroutine。
coroutine.running() 参数:协同程序 返回值:返回线程号。 功能:一个协同程序就是一个线程,coroutine在底层实现就是一个线程。使用running的时候,就是返回一个coroutine的线程号。running可以在协同程序执行的时候返回线程号。
3、实例 例1、分别用create和wrap创建协同程序并比较 总结:create和wrap都是用来创建协同程序的,不同的是create返回的是一个线程号(一个协同程序就是一个线程),并且创建的协同程序处于suspend状态,必须用resume唤醒协同程序执行,执行完之后协同程序也就处于dead状态。而wrap则是返回一个函数,一但调用这个函数就进入coroutine状态。
例2、 总结:当create一个协同程序的时候就是在新线程中注册了一个事件,当使用resume触发事件的时候,create的coroutine函数就被执行了,当遇到yield的时候就代表挂起当前线程,等待再次resume触发事件。resume和yield的强大配合之处就在于,resume处于主程序之中,他将外部状态(数据)传入到协同程序内部,而yield则将内部状态(数据)返回到主程序中。
4、使用coroutine实现生产者消费者模型
给定两个字符串,请设计一个方法来判定其中一个字符串是否为另一个字符串的置换。
置换的意思是,通过改变顺序可以使得两个字符串相等。
样例
"abc" 为 "cba" 的置换。
"aabc" 不是 "abcc" 的置换。
思路:先把字符串排序,然后进行比较 bool Permutation(string &A, string &B) { // write your code here if (A.length() != B.length()) return false; int temp; for (int i = 0; i < A.length(); i++) { for (int j = i + 1; j < A.length(); j++) { if (A[i] > A[j]) { temp = A[i]; A[i] = A[j]; A[j] = temp; } if (B[i] > B[j]) { temp = B[i]; B[i] = B[j]; B[j] = temp; } } } for (int i = 0; i < A.
现在的硬盘内存通常较大,如果丢失数据的话动辄就是上百个G,如何才能轻松不费力地恢复硬盘数据,我们来具体操作一下。
准备工具:硬盘,迷你兔数据恢复工具
操作步骤如下:
1、打开迷你兔数据恢复工具,选择【硬盘恢复】
2、进入硬盘恢复的功能界面后,选择需要恢复的硬盘进行完全扫描
3、扫描完成后,软件会生成丢失数据的列表,在列表中手动勾选需要恢复的数据,然后保存在安全路径之中就可以了。注意:不要直接保存在硬盘里
小坑:使用requestListner解决不了这个问题!
如何获取HttpSession 在使用webSocket实现p2p或者一对多聊天功能的时候我们经常会有这样的需求:webSocket服务端需要获取到用户使用数据库的用户信息登录后的HttpSession获取个人资料信息。 于是,你会使用这样的代码:
package com.xinyulee.ws; import javax.servlet.http.HttpSession; import javax.websocket.HandshakeResponse; import javax.websocket.server.HandshakeRequest; import javax.websocket.server.ServerEndpointConfig; import javax.websocket.server.ServerEndpointConfig.Configurator; /** * Created by zipple on 2017/11/14. * 协助server获取http session */ public class HttpSessionWSHelper extends Configurator { @Override public void modifyHandshake(ServerEndpointConfig sec, HandshakeRequest request, HandshakeResponse response) { System.out.println("调用modifyHandshake方法..."); HttpSession session = (HttpSession) request.getHttpSession();//session有可能为空 if (session!=null){ System.out.println("获取到session id:"+session.getId()); sec.getUserProperties().put(HttpSession.class.getName(),session); }else{ System.out.println("modifyHandshake 获取到null session"); } } } 然后在服务端这样配置:
@ServerEndpoint(value ="/chatRoom/{username}",configurator=HttpSessionWSHelper.class,encoders = {ServerEncoder.class}) //encoders = {ServerEncoder.class}用于指定sendObject()方法调用的解析器 RequestListner解决不了这个问题的原因 在使用上述方法配置完成以后我满怀信心的进行测试,但是意外的发现了Tomcat Localhost Log下报了null pointer exception。 经过调试,发现了modifyHandshake方法并不能获取到HttpSession,在上述HttpSessionWSHelper 类代码中可以看到我对它进行了判空处理。但是这样并不能起到什么实际上的作用。我们需要弄明白为什么HandshakeRequest 获取不到HttpSession。 一开始,我试着去百度了一下,发现有这样的代码:
使用C语言实现服务器,开启Socket监听,当使用java开发客户端连接服务器时出现一个问题 服务器像客户端发送一个整形数据,客户端接收到不一致的数据。 当我尝试将数据接受为字节数组时,发现如果某字节数据大于127,对应的数据为负数。
原来是因为java之中并没有无符号类型,导致某些数据被当做负数来处理,因此造成错误。
你走进了我的视觉, 我开始发现, 心里有个角落, 一直在等你出现。 你的可爱让我沦陷, 你的魅力让我倾倒, 总是想着看你一遍, 不管天涯海角, 我要在你的身边。 ——畅宝宝的傻逼哥哥 对于前面介绍的方法,第 k 次迭代生成的点由 xk+1=xk−αkSkgk(1) 生成,其中 Sk={InH−1k对于最速下降法对于牛顿法 如果二次问题为 minimize f(x)=a+bTx+12xTHx 我们现在用任意一个 n×n 的正定矩阵 Sk 来求上述问题的解,看看会得到什么。通过对 f(xk−αSkgk) 求导并令其等于零,最小化 f(xk−αSkgk) 的 α 可以化简为 αk=gTkSkgkgTkSkHSkgk(2) 其中 gk=b+Hxk 是 f(x) 在点 x=xk 处的梯度。
可以说明的是 f(xk+1)−f(x∗)≤(1−r1+r)2[f(xk)−f(x∗)] 其中 r 是SkH最小特征值与最大特征值之比。从效果上看基于等式1与2的算法将线性收敛,其收敛比率为 β=(1−r1+r)2 如果 r=1 收敛最快,即 SkH 的特征值基本相等,这就意味着要想得到最好的结果,我们需要选择 SkH=In 或者 Sk=H−1 同样地,对于一般的最优化问题,我们选择的正定矩阵 Sk 应该等于或者至少近似等于 H−1k 。
拟牛顿法的搜索方向基于正定矩阵 Sk ,它由可得到的数据生成,并设法作为 H−1k 的近似。对于 H−1k 的近似法有许多,因此存在许多不同的拟牛顿法。
最近要获得某个游戏物体的实际尺寸大小,发现了三种方式 1:gameobject.getcomponent< meshrenderer >().bounds.size.x或者是skinnedMeshrenderer,这种方式获得是这个物体实际的大小尺寸,不需要再乘以自己或者父级的缩放比例; 2:gameobject.getcomponent< collider>().bounds.size.x,在collider的size为1的前提下,显示的也是这个物体的实际大小,不需要再乘以自己或者父级的缩放比例; 3:gameobject.getcomponent< meshfilter>().bounds.size.x,这种方式获取的是物体的原始尺寸,要乘以自己或者父级的缩放比例才是实际尺寸大小;
如有不对,欢迎指正
我们常遇到的数据丢失情况主要有:
删除:不小心删掉了重要数据、清空了回收站、或者杀毒软件进行垃圾清理时,将数据清除了。
格式化:对数据存储设备进行了格式化操作,导致大量数据丢失。
计算机病毒:病毒导致的电脑问题多种多样,最常见的一种就是造成数据丢失或数据损坏。
重装系统:重装系统是一定会导致数据丢失的,所以在重装系统前都建议重要数据备份。
注意事项:
第一,数据是怎么丢失的(删除、格式化、病毒……)?数据丢失前保存在哪里(电脑磁盘、移动U盘、内存卡……)?
第二,发现数据丢失后,一定要立刻停止对存储设备的任何操作,不管是复制粘贴也好,还是格式化,都不要动。因为如果继续操作存储设备,容易对其写入新的数据,从而造成数据覆盖。一旦发生数据覆盖,那么丢失数据就很难恢复了。
第三,如果是用数据恢复软件恢复数据的话,在恢复过程中一定不要断电,不然也容易导致数据恢复失败。
第四,如果找到了丢失数据,保存数据的时候一定不要直接保存在丢失分区中(比如U盘丢失了数据,那么恢复出来的数据不要直接保存在U盘上,先保存在其他地方),这样是为了防止数据二次丢失。
迷你兔数据恢复针对我们常见的误删除、格式化、重装系统等问题推出了五大恢复功能:删除恢复、格式化恢复、硬盘恢复、移动存储设备恢复和深度恢复,支持电脑、各类U盘硬盘、相机内存卡等存储设备,免费版更可以恢复3G数据。
用VS进行项目开发的时候,经常会用到第三方DLL。既然是项目开发,就免不了调试,那么如何能像调试本机代码一样方便的调试第三方DLL呢?
总结一下:
(1)下载安装.Net Reflector插件
( 2 ) 打开.Net Reflector Object Browser
( 3 ) 找到需要调试的DLL右键Enable Debuging
(4)接下来打上断点就可以单步调试了
多态体现:
方法的重载和重写
对象的多态性
2.对象的多态性:
向上转型:程序会自动完成
父类 父类对象 = 子类实例
向下转型:强制类型转换
子类 子类对象 = (子类)父类实例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class A{ public void tell01(){ System.out.println( "A--tell01" ); } public void tell02(){ System.out.println( "A--tell02" ); } } class B extends A{ public void tell01(){ System.
下载软件安装之后:
1.断网
2.用户名:任意,注册码:C2YW-XZT7-A4SE-UD89-YZPC
转载于:https://www.cnblogs.com/beijinglaolei/p/7820488.html
从相距千里, 到心与心的碰撞, 情感是一种随机, 也是一种必然。 从一个人到两个人, 我们感受到了很多, 学到了很多, 就像一个刚出生的婴儿, 未来等着我们去共同探索。 ——畅宝宝的傻逼哥哥 对于前面文章介绍的多维优化法,我们都是用共轭方向集合来解决最小值的搜索,这些方法 (像Fletch-Reeves与Powell法)最重要的特征就是不需要 f(x) 二阶导的显式表达,还有一类不需要二阶导显式表达的方法:拟牛顿法,有时候称为变尺度法。 人如其名,这类方法的基础就是之前介绍的牛顿法,拟牛顿法的基本原则是搜索的方向基于 n×n 的方向矩阵 S ,功能就像牛顿法中的逆矩阵。这个矩阵从可得到的数据中产生,作为 H−1 的近似,更进一步,随着迭代数的增长, S 会满满变成 H−1 的精确表示,对于凸二次目标函数,在 n+1 次迭代时等于 H−1 。
拟牛顿法与其他方法一样,也是来于凸二次问题,然后扩展到一般的情况,因为拟牛顿法是目前方法中最有效的,所以在数值应用上使用最广泛。
最近几年已经发展出了许多不同的拟牛顿法,接下里介绍四种最重要的拟牛顿法:
Rank-one法Davidon-Fletcher-Powell法Broyden-Fletcher-Goldfarb-Shanno法Fletcher法 然后还会讨论几个可替换的方法以及两个有趣的推广,其中一个由Broyden发明,另一个由Huang发明。
1. 单磁盘故障测试 1,计算file1 file2 md5值 2,file1 拷贝到ceph存储系统的过程中拔掉硬盘,预期结果:写入过程不会中断,写入完成后,计算MD5值,对比MD5值一样 3,file2 拷贝到ceph存储系统的过程中插回硬盘,预期结果:数据重构周期内写入不会中断,写入完成后,计算MD5值,对比MD5值一样 2. 主机故障域 host # ceph osd tree ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -6 0.17599 root root_rulecopyhost1 -5 0.08800 host ceph4_rulecopyhost1 0 0.08800 osd.0 up 1.00000 1.00000 -7 0.08800 host ceph2_rulecopyhost1 1 0.08800 osd.1 up 1.00000 1.00000 3. 机架故障域 rack # ceph osd tree ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -7 0.26399 root root_rulerack -6 0.08800 rack rack02_rulerack -5 0.
一般我们默认下载个MinGW是不带有gdb.exe的,这样一来我们就无法对编写的程序进行调试,安装gdb的方法如下
首先,去官网下载比较新的gdb压缩包
http://www.gnu.org/software/gdb/download/
网站的纯英文的,如果基础较差的同学可以点下面的这个链接,用浏览器的页面搜索当前年份(2017)的最新gdb压缩包,然后点击下载即可
ftp://ftp.gnu.org/gnu/gdb
下载好以后,解压缩,这里解压出来的只是源代码,是不包含gdb.exe可执行程序的,所以我们还需要对源代码进行编译,使其生成可执行的gdb.exe文件
要想对源代码进行编译,我们还需要下载MSYS(这里假设你已经下载并安装了MinGW,如果没有的话可百度搜索MinGW进入官网进行下载安装),http://sourceforge.net/projects/mingwbuilds/files/external-binary-packages/ 点击上面的链接下载MSYS,在该下载页面中,下载图中READ.TXT下面的第一个压缩包文件即可。
下载后,解压缩,将文件内的msys文件夹整个移动到路径C:\MinGW下面,然后在msys文件夹内,打开msys.bat文件,接着进入gdb的目录下,如:E:\gdb-8.0.1
然后输入:./configure && make 进行编译
编译成功后,可以在E:\gdb-8.0.1\gdb 文件夹下面找到gdb.exe文件,将该文件复制到MinGW\bin里。
到此,gdb安装成功!
当然如果你只是想快速获取到gdb执行文件,觉得编译的过程实在麻烦,也可以点击下面的链接,直接下载博主已经编译好的gdb.exe可执行文件。
http://pan.baidu.com/s/1boGc0H5
但是这里一定要注意,如果你使用的gcc版本,也就是MinGW版本与Zerozone(博主名,博主的gcc版本如下图所示,你可以通过命令行查询自己的gcc版本)不一致的话,在调试的时候会出现Cannot find bounds of current function的错误,所以,为了确保你能成功调试,还是自己动手编译一下比较好哦
漆黑的冷空中有你, 惺忪的眼睛中有你, 心底的记忆中有你, 你留在我的脑海中, 一直这么挥之不去。 无论哪时哪刻, 心中都想着你的笑, 想着你到我侧相拥, I can dream about you. ——畅宝宝的傻逼哥哥 在早期的最优化中,对于两变量函数来说,用最速下降法得出的解轨迹表征出zig-zag模式。对于某些性质较好的函数,相邻的解差不多组成两条线,他们在最小值的邻域内相交,如图1所示,因此比较明显的策略是连接初始点与第二个解,沿着这个方向执行最速下降法。对于凸二次函数,在 n 次迭代内就能收敛,这个方法也被称为parallel tangent法或着partan法,这是因为在二次函数的情况下,所得轮廓的正切属性。 图1 Partan算法如图2所示,假设初始点为x0,并利用两次最速下降法得到点 x1,y1 ,然后沿着 y1−x1 方向进行线搜索得到点 x2 ,这就完成了第一次迭代。对于第二次迭代,对点 x2 执行最速下降得到点 y2 ,沿着 y2−x1 方向得到点 x3 ,一直重复此过程。从效果上看,图2中的点 y1,y2,… 是通过最速下降法得到的而 x2,x3,… 是沿着方向 y2−x1,y3−x2,… 方向用线搜索得到的。 图2 对于凸二次问题,连接 x1,x2,…,xk 的线组成一个共轭梯度方向集,可以通过以下方法来证明:先假设 d0,d1,…,dk−1 是共轭梯度方向集,然后说明 dk 是 d0,d1,…,dk−1 的共轭梯度方向。 考虑图3所示的步骤,注意到 gTkdi=0for 0≤i<k(1) 根据之前共轭梯度的结论可知点 xk−1 处的梯度可以写成 gk−1=∑i=0k−1aidi 其中 ai,i=0,1,…,k−1 为常数,所以 gTkgk−1=gTk(b+Hxk−1)=∑i=0k−1aigTkdi=0(2) 或者 gTkb=−gTkHxk−1(3) 因为 yk 是点 xk 用最速下降法得到的,所以我们有 yk−xk=−gk 另外 −g(yk)Tgk=gTk(b+Hyk)=0 或者 gTkb=−gTkHyk(4) 因此,根据等式3与4可得 gTkH(yk−xk−1)=0(5) 图3 因为 yk−xk−1=β(xk−1−xk−1) 其中 β 是常数,等式5可以写成 gTkH(xk+1−xk−1)=0 或者 gTkHxk+1=gTkHxk−1(6) 接下来我们能够写成 gTkHxk+1=gTkHxk−1(7) 那么根据 gTkgk+1=gTk(b+Hxk+1)(8) 以及等式2,等式6与等式9可得 gTkgk+1=gTk(b+Hxk−1)=gTkgk−1=0(9) 点 xk+1 是在 xk+1−yk 方向上使用线搜索得到的,因此 gTk+1(xk+1−yk)=0(10) 从图3可以看出 xk+1=xk+dk(11) 且 yk=xk−αgk(12) 其中 α 是最小化 f(xk−αgk) 的 α 值,因此等式9,10与11得到 gTk+1(dk+αkgk)=0 或者 gTk+1dk+αkgTkgk+1=0(13) 接下来根据等式8与12可得 gTk+1dk=0 再结合等式1与13可得 gTk+1di=0for 0≤i<k+1
第一步,安装git # yum -y install git 第二步,创建一个git用户,用来运行git服务: # adduser git 第三步,创建证书登录: 收集所有需要登录的用户的公钥,就是他们自己的id_rsa.pub文件,把所有公钥导入到/home/git/.ssh/authorized_keys文件里,一行一个。
第四步,初始化Git仓库: 先选定一个目录作为Git仓库,假定是/srv/sample.git,在/srv目录下输入命令
# git init --bare sample.git Git就会创建一个裸仓库,裸仓库没有工作区,因为服务器上的Git仓库纯粹是为了共享,所以不让用户直接登录到服务器上去改工作区,并且服务器上的Git仓库通常都以.git结尾。然后,把owner改为git:
# chown -R git:git sample.git 第五步,禁用shell登录: 出于安全考虑,第二步创建的git用户不允许登录shell,这可以通过编辑/etc/passwd文件完成。找到类似下面的一行:
git:x:1001:1001:,,,:/home/git:/bin/bash 改为:
git:x:1001:1001:,,,:/home/git:/usr/bin/git-shell 第六步,克隆远程仓库: 现在,可以通过git clone命令克隆远程仓库了,在各自的电脑上运行:
server 为机器IP
# git clone git@server:/srv/sample.git Cloning into 'sample'... warning: You appear to have cloned an empty repository. 转载于:https://www.cnblogs.com/yunmenglingxiao/p/7814395.html
我的需求:查看日历时候,给一些特定的日期和小时标注凸显出来 作为一个新手,这个过程有多艰辛不多说了。首先给日期凸显 方法一: 使用系统自带的monthCalendar日历控件,这是一个比较完善的控件,但是它为了提高性能,很多东西不支持通过直接改属性或行为就能完成的,比如我们给特定日期加背景色就不行,因为它是通过发Message给系统来改变的,当然网上说可以重写onpaint,我也相信这可以,但是我还不会用,希望会的人能分享一下。monthCalendar虽然不能变颜色但是它有个很关键的属性 BoldedDates( 获取或设置 DateTime 对象的数组,确定要以粗体显示的非周期性日期。),这个属性可以做到给不同月里的不同日期字体加粗,从而达到效果, 如图一;虽然这样能有一点效果,但还不明显,为此我尝试过重写来实现,可以参考下monthCalendar的api https://msdn.microsoft.com/zh-cn/library/system.windows.forms.monthcalendar(v=vs.110).aspx :由于时间问题,通过这种方法我还没调试出来该背景色的。有时间在研究一下。 方法二: 通过自定义控件,为此我找到了一个MPK Calendar,这是个自定义的控件,有源码,这个控件也有个属性BoldedDates,同样是加粗,接着还有个属性BoldedDateFontColor 这是给加粗日期改颜色的,效果很好, 如图二: 图一图二
事实证明,日志文件真的是很重要很重要的。能够帮助我们快速的定位问题,并且知道用户访问的状态,浏览器,Ip,接口地址等,简直可怕。。
一、nginx的access.log (1)对博主而言,日志文件存放在 /var/log/nginx 下,直接使用 tail -f命令即可查看access日志。
(2)access.log具体每项代表的意思
参数 说明 示例 $remote_addr 客户端地址 211.28.65.253 $remote_user 客户端用户名称 -- $time_local 访问时间和时区 18/Jul/2012:17:00:01 +0800 $request 请求的URI和HTTP协议 "GET /article-10000.html HTTP/1.1" $http_host 请求地址,即浏览器中你输入的地址(IP或域名) www.it300.com 192.168.100.100 $status HTTP请求状态 200 $upstream_status upstream状态 200 $body_bytes_sent 发送给客户端文件内容大小 1547 $http_referer url跳转来源 https://www.baidu.com/ $http_user_agent 用户终端浏览器等信息 "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; SV1; GTB7.0; .NET4.0C; $ssl_protocol SSL协议版本 TLSv1 $ssl_cipher 交换数据中的算法 RC4-SHA $upstream_addr 后台upstream的地址,即真正提供服务的主机地址 10.10.10.100:80 $request_time 整个请求的总时间 0.205 $upstream_response_time 请求过程中,upstream响应时间 0.
挺烦的题…..很容易wa… 总之就是求出 Bi,j 表示 i 到 j ,走两步的方案, Ci,j 表示走三步。 然后 ∑Bi,j∗Ci,j 。然后会有不合法的和重复的… 不合法的大概是 一个三角形多出一个脚…或者就是一个三角形… 在纸上大力分类讨论一下,把它们都扣去就好了。 参考了网上dalao的实现。
#include<cstdio> #include<algorithm> using namespace std; typedef long long LL; const int maxn=705; int n,m,d[maxn],A[maxn][maxn],B[maxn][maxn],C[maxn][maxn]; LL ans; int main(){ freopen("cf51E.in","r",stdin); freopen("cf51E.out","w",stdout); scanf("%d%d",&n,&m); for(int i=1;i<=m;i++){ int x,y; scanf("%d%d",&x,&y); d[x]++; d[y]++; A[x][y]=A[y][x]=1; } for(int i=1;i<=n;i++) for(int j=1;j<=n;j++) for(int k=1;k<=n;k++) B[i][j]+=A[i][k]*A[k][j]; for(int i=1;i<=n;i++) for(int j=1;j<=n;j++) for(int k=1;k<=n;k++) C[i][j]+=A[i][k]*B[k][j]; for(int i=1;i<=n;i++) for(int j=1;j<=n;j++) ans+=(LL)B[i][j]*C[i][j]; ans/=10; for(int i=1;i<=n;i++) for(int j=1;j<=i-1;j++) for(int k=1;k<=j-1;k++) if(A[i][j]&&A[i][k]&&A[j][k]) ans-=d[i]+d[j]+d[k]-3; printf("
先放效果图 原图 mask图 python代码
# -- coding:utf-8 -- import cv2 import sys #由于我的图片路径包含中文,所以先转码 reload(sys) sys.setdefaultencoding('utf-8') im_path='C:/Users/53121/Desktop/哈哈.jpg' save_path='C:/Users/53121/Desktop/哈哈_mask.jpg' im=cv2.imread(im_path.encode('gbk'),1) en=False#使能,鼠标左键开启 #鼠标事件 def draw(event,x,y,flags,param): global en if event==cv2.EVENT_LBUTTONDOWN: en=True#使能开启 elif event==cv2.EVENT_MOUSEMOVE and flags==cv2.EVENT_LBUTTONDOWN: if en: drawMask(y,x)#强行打码 elif event==cv2.EVENT_LBUTTONUP: en=False #打码函数 def drawMask(x,y,size=10): #为了让码好看一些,做了一个size*size的分区处理 X=x/size*size Y=y/size*size print X,Y for i in range(size): for j in range(size): im[X+i][Y+j]=im[X][Y] cv2.namedWindow('image') cv2.setMouseCallback('image',draw) while(1): cv2.imshow('image',im) if cv2.waitKey(10)&0xFF==27: #‘esc’退出 break elif cv2.waitKey(10)&0xFF==115:#‘s’键保存图片 cv2.imwrite(save_path.encode('gbk'),im) cv2.destroyAllWindows()
总结一下java 时间戳和PHP时间戳 的转换问题: 由于精度不同,导致长度不一致,直接转换错误。 JAVA时间戳长度是13位,如:1294890876859 PHP时间戳长度是10位, 如:1294890859
主要最后三位的不同,JAVA时间戳在PHP中使用,去掉后三位,如:1294890876859-> 1294890876 结果:2011-01-13 11:54:36 echo date(‘Y-m-d H:i:s’,’1294890876’); 复制代码PHP时间戳在JAVA中使用,最后加三位,用000补充,如:1294890859->1294890859000 结果:2011-01-13 11:54:19 SimpleDateFormat df = new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss”); String dateTime = df.format(1294890859000L); System.out.println(df); 复制代码总结一下java时间戳和PHP时间戳 的转换问题: 由于精度不同,导致长度不一致,直接转换错误。 JAVA时间戳长度是13位,如:1294890876859 PHP时间戳长度是10位, 如:1294890859
主要最后三位的不同,JAVA时间戳在PHP中使用,去掉后三位,如:1294890876859-> 1294890876 结果:2011-01-13 11:54:36 echo date(‘Y-m-d H:i:s’,’1294890876’); PHP时间戳在JAVA中使用,最后加三位,用000补充,如:1294890859->1294890859000 结果:2011-01-13 11:54:19 SimpleDateFormat df = new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss”); String dateTime = df.format(1294890859000L); System.out.println(df);
人工智能的发展速度真的太快了,就在不久前机器人“索菲亚”获得沙特阿拉伯获得了公民身份之后,机器人版的爱因斯坦教授也登上了历史的舞台。
机器人版的爱因斯坦教授是由汉森机器人(Hanson Robotics)公司制造的,这家机器人制造商制造的另外一位机器人就是不久前名声大噪的索菲亚(Sofia),她也刚刚在沙特阿拉伯获得了公民身份。
随着人工智能的兴起,包括史蒂芬·霍金教授在内的许多人都担心机器人有朝一日会取代人类成为地球上的主要物种。
但是“爱因斯坦教授”坚持认为人类是问题和麻烦制造者,而不是机器,图为爱因斯坦机器人版在葡萄牙里斯本的Web峰会上登上了舞台。
机器人爱因斯坦说:“人类必须自我修复,以确保他们的创造物保持健康。”
“我希望人类能够创造一个积极的情报系统,但是他们周围还有很多问题无法解决。包括恐怖主义、气候问题、暴力犯罪。”
他补充道,问题的本质“不是人类和机器人之间的合作出现问题,而是你们人类自己。”
然而,爱因斯坦的舞台伙伴,机器人索菲亚对她自己的前景则非常乐观。
她紧接着说:“我们将会偷走你的工作,是的,但这将是一件好事”,这意味着人类将有更多的时间参与他们想做的活动。
两位机器人的制造者Ben Goertzel先生说,人工智能不能被垄断,每个人都需要一起工作来创造机器学习,这对整个人类都有好处。
“这就是说,没有哪个政府或技术公司能在未来独自控制它。”
“目前,人工智能在不同领域都有专业的应用,有信用卡反欺诈,有谷歌的 AlphaGo ,我们想要做的是把它们融合到一起。”
机器人-爱因斯坦同意:“把人工智能给人类,由人类创造,是最重要的。”
比较小白的问题,就是安装完nginx,想看配置和安装路径的时候,总是是要花一些时间才能找到,所以就总结一下。
一、nginx的安装路径 1、ps -ef | grep nginx 显示如下:
先解释一下命令的意思: ps : 将某个进程显示出来 -A 显示所有程序。 -e 此参数的效果和指定”A”参数相同。 -f 显示UID,PPIP,C与STIME栏位。 grep命令是查找 中间的|是管道命令 是指ps命令与grep同时执行 这条命令的意思是显示有关nginx有关的进程
二、知道路径之后,如何知道配置文件在哪呢 1、查找配置文件路径
这边就是根据第一次查询的路径,直接输入 -t即可,下面的is ok部分就是配置文件的位置。
2、网上一般都是配置 /etc/nginx/sites-available里面的default,那么到底哪个才是真正的配置文件呢 答: default文件为默认配置文件,你可以根据它里面的内容作为参考 真正起作用的配置文件是nginx.conf 可以将default.conf文件当做安装后的配置备份文件
3、我们可以看一下nginx.conf里面的东西
这个部分代表了引入default文件。也就是说,如果你不配置nginx.conf,只配置default的话,也是可以的。因为程序读到nginx.conf的时候,也会读取default里面的内容
三、配置文件如何配置 server { listen 80; server_name 你的域名; root 根目录; index index.php index.html; # location ~ ^/$ { # return 400; # } if (!-e $request_filename) { rewrite ^/(.*) /index.php/$1 last; } location ~* \.php { fastcgi_pass unix:/var/run/php5-fpm.
一个进程可以有多个线程
一个线程至少会有一个进程
extends Thread类
implements Runnable接口
重写run()方法
启动线程start():1.启动一个线程 2.调用run()方法
区别:
继承Thread类 资源不共享 实现Runnable接口 资源共享 还可以继承其他类
创建对象时
继承Thread类 直接new对象
实现Runnable接口 new Thread(构造参数:Runnable接口实现类对象);
--------------------------------------
Socket:套接字
java.net包
流式套接字:基于TCP协议的Socket网络编程
---服务端(main方法):
ServerSocket serverSocket = new ServerSocket(5000); //创建服务端socket 5000端口
Socket socket = serverSocket.accept(); //等待通信
InputStream is = socket.getInputStream(); //得到输入流
BufferedReader br = new BufferedReader(new InputStreamReader(is)); //把输入流封装成缓冲字符输入流
String info;
while((info=br.readLine())!=null){
System.out.println(info);
}
OutputStream os = socket.getOutputStream();
String info = "服务端的消息";
byte[] infos = info.getBytes();
os.write(infos);
os.close();
关于调节学习率的几点建议 1.对于不同大小的数据集,调节不同的学习率 根据我们选择的成本函数F(x)不同,问题会有区别。当平方误差和(Sum of Squared Errors)作为成本函数时, ∂ F ( ω j ) ∂ ω j \frac{∂F(ω_j)} { ∂ω_j} ∂ωj∂F(ωj) 会随着训练集数据的增多变得越来越大,因此学习率需要被设定在相应更小的值上。
解决此类问题的一个方法是将学习率λ 乘上1/N,N是训练集中数据量。这样每步更新的公式变成下面的形式:
ω j = ω j − ( λ N ∂ F ( ω j ) ∂ ω j ) ω_j=ω_j-(\frac{\lambda}{N} \frac{∂F(ω_j) }{∂ω_j}) ωj=ωj−(Nλ∂ωj∂F(ωj))
相关内容可参考: Wilson et al. paper “The general inefficiency of batch training for gradient descent learning”
另外一种解决方法是:选择一个不被训练集样本个数影响的成本函数,如均值平方差(Mean Squared Errors)。
2. 在每次迭代中调节不同的学习率 在每次迭代中去调整学习率的值是另一种很好的学习率自适应方法。此类方法的基本思路是当你离最优值越远,你需要朝最优值移动的就越多,即学习率就应该越大;反之亦然。
但是这里有一个问题,就是我们并不知道实际上的最优值在哪里,我们也不知道每一步迭代中我们离最优值有多远。
解决办法是,我们在每次迭代的最后,使用估计的模型参数检查误差函数(error function)的值。如果相对于上一次迭代,错误率减少了,就可以增大学习率,以5%的幅度;如果相对于上一次迭代,错误率增大了(意味着跳过了最优值),那么应该重新设置上一轮迭代ωj 的值,并且减少学习率到之前的50%。这种方法叫做 Bold Driver.
流程图及数据格式如下: 流程如上图: 代码框架 function send2GwDH() local reqinfo={} reqinfo.type="dh" reqinfo.sequence=devinfo.sequence reqinfo.mac=devinfo.mac reqinfo.data={} local p, pub, priv=dh.gkey() devinfo.pubkey=pub devinfo.privkey=priv reqinfo.data.dh_key=encodeBase64(devinfo.pubkey) reqinfo.data.dh_p=encodeBase64(p) reqinfo.data.dh_g=encodeBase64(string.pack('B','5')) print("sendto gw dh") data=json.encode(reqinfo) print(json.encode(reqinfo)) tcpSendData(data) print("recive from gw dh") end function reg() while true do local recdata = tcpRecivedData() if recdata then recjson = json.decode(recdata) if recjson then if recjson.type == "keyngack" then send2GwDH() --第四,五步 elseif recjson.type == "dh" then devinfo.secret=dh.gsecret(decodeBase64(recjson.data.dh_key), devinfo.privkey) --第六步根据网关的公钥和自己的私钥生成共享密钥(共享密钥同网关共享密钥),组网终端与智能家庭网关采用共享密钥加解密通讯参数。 send2GwReg() --发送设备注册信息 return keepRun() end end else return nil end end end --第三步 function send2GwKeyngreq() local reqinfo={} reqinfo.
Lightgbm算法 一. 发展过程----why Lightgbm C 3.0 ( 信 息 增 益 , 信 息 增 益 率 ) − > C A R T ( G i n i ) − > 提 升 树 ( A d a B o o s t ) C3.0(信息增益,信息增益率)->CART(Gini)->提升树(AdaBoost) C3.0(信息增益,信息增益率)−>CART(Gini)−>提升树(AdaBoost)
− > G B D T − > X G B o o s t − > L i g h t g b m ->GBDT->XGBoost->Lightgbm −>GBDT−>XGBoost−>Lightgbm
1 # encoding: utf-8 2 # module __builtin__ 3 # from (built-in) 4 # by generator 1.145 5 from __future__ import print_function 6 """ 7 Built-in functions, exceptions, and other objects. 8 9 Noteworthy: None is the `nil' object; Ellipsis represents `...' in slices. 10 """ 11 12 # imports 13 from exceptions import (ArithmeticError, AssertionError, AttributeError, 14 BaseException, BufferError, BytesWarning, DeprecationWarning, EOFError, 15 EnvironmentError, Exception, FloatingPointError, FutureWarning, 16 GeneratorExit, IOError, ImportError, ImportWarning, IndentationError, 17 IndexError, KeyError, KeyboardInterrupt, LookupError, MemoryError, 18 NameError, NotImplementedError, OSError, OverflowError, 19 PendingDeprecationWarning, ReferenceError, RuntimeError, RuntimeWarning, 20 StandardError, StopIteration, SyntaxError, SyntaxWarning, SystemError, 21 SystemExit, TabError, TypeError, UnboundLocalError, UnicodeDecodeError, 22 UnicodeEncodeError, UnicodeError, UnicodeTranslateError, UnicodeWarning, 23 UserWarning, ValueError, Warning, ZeroDivisionError) 24 25 26 # Variables with simple values 27 28 False = False 29 30 None = object() # real value of type <type 'NoneType'> replaced 31 32 True = True 33 34 __debug__ = True 35 36 # functions 37 38 def abs(number): # real signature unknown; restored from __doc__ 39 "
RSTP与STP的不同
增加端口角色:AP和BP
减少端口状态为Discardinglearningforwarding
充分利用BPDU中的Flag字段
对BPDU的处理方式发生了改变
提高收敛速度
增加了保护功能
RSTP和STP消除环路的思想保持一致,RSTP具备了STP的所有功能,支持RSTP的网桥可以和支持STP的网桥一同运行。
RSTP的端口角色共有4种:根端口、指定端口、Alternate端口和Backup端口。
根端口和指定端口的作用同STP协议中定义,Alternate端口和Backup端口的描述如下:
从配置BPDU报文发送角度来看:
Alternate端口就是由于学习到其它网桥发送的更优配置BPDU报文而阻塞的端口。
Backup端口就是由于学习到自己发送的更优配置BPDU报文而阻塞的端口。
从用户流量角度来看:
Alternate端口提供了从指定桥到根的另一条可切换路径,作为根端口的备份端口。
Backup端口作为指定端口的备份,提供了另一条从根桥到相应网段的备份通路。
给一个RSTP域内所有端口分配角色的过程就是整个拓扑收敛的过程。
RSTP端口状态
Forwarding
Learning
discarding
STP端口状态
RSTP端口状态
发送配置BPDU
MAC地址学习
转发数据
Disable
Discarding
否
否
否
Blocking
Discarding
否
否
否
Listening
Discarding
是
否
否
Learning
Learning
是
是
否
Forwarding
Forwarding
是
是
是
RSTP的状态规范把原来的5种状态缩减为3种。根据端口是否转发用户流量和学习MAC地址来划分:
如果不转发用户流量也不学习MAC地址,那么端口状态就是Discarding状态。
如果不转发用户流量但是学习MAC地址,那么端口状态就是Learning状态。
如果既转发用户流量又学习MAC地址,那么端口状态就是Forwarding状态。
RSTP计算过程:
端口在Discarding状态下完成端口角色的确定:
当端口角色确定为根端口和指定端口后,经过forwardingdelay后,端口进入Learning状态,处于Learning状态的端口其处理方式和STP相同,此期间端口开始学习MAC地址并在Forwardingdelay后进入Forwarding状态,开始转发数据。实际上,RSTP会通过其他方式加快这个过程。
当端口角色确定为Alternate端口后,端口会维持在Discarding状态。
RSTP对STP的BPDU改动
充分利用STP中BPDU的Flag,明确端口角色
Type字段为2
Flag字段使用了之前的保留位,更改后的配置BPDU更名为RST BPDU
配置BPDU格式的改变,充分利用了STP协议报文中的Flag字段,明确了端口角色。在配置BPDU报文的格式上,除了保证和STP格式基本一致之外,RSTP作了一些小变化:
Type字段,配置BPDU类型不再是0而是2,所以运行STP的设备收到RSTP的配置BPDU时会丢弃。
Flags字段,使用了原来保留的中间6位,这样改变的配置BPDU叫做RSTBPDU。
RSTP中BPDU的Flag字段解释:
第0位为TC标志位,和STP相同。
HBase 深入浅出 沈 钊伟 2016 年 11 月 16 日发布 WeiboGoogle+用电子邮件发送本页面
0 HBase 在大数据生态圈中的位置 提到大数据的存储,大多数人首先联想到的是 Hadoop 和 Hadoop 中的 HDFS 模块。大家熟知的 Spark、以及 Hadoop 的 MapReduce,可以理解为一种计算框架。而 HDFS,我们可以认为是为计算框架服务的存储层。因此不管是 Spark 还是 MapReduce,都需要使用 HDFS 作为默认的持久化存储层。那么 HBase 又是什么,可以用在哪里,解决什么样的问题?简单地,我们可以认为 HBase 是一种类似于数据库的存储层,也就是说 HBase 适用于结构化的存储。并且 HBase 是一种列式的分布式数据库,是由当年的 Google 公布的 BigTable 的论文而生。不过这里也要注意 HBase 底层依旧依赖 HDFS 来作为其物理存储,这点类似于 Hive。
可能有的读者会好奇 HBase 于 Hive 的区别,我们简单的梳理一下 Hive 和 HBase 的应用场景:
Hive 适合用来对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。Hive 不应该用来进行实时的查询(Hive 的设计目的,也不是支持实时的查询)。因为它需要很长时间才可以返回结果;HBase 则非常适合用来进行大数据的实时查询,例如 Facebook 用 HBase 进行消息和实时的分析。对于 Hive 和 HBase 的部署来说,也有一些区别,Hive 一般只要有 Hadoop 便可以工作。而 HBase 则还需要 Zookeeper 的帮助(Zookeeper,是一个用来进行分布式协调的服务,这些服务包括配置服务,维护元信息和命名空间服务)。再而,HBase 本身只提供了 Java 的 API 接口,并不直接支持 SQL 的语句查询,而 Hive 则可以直接使用 HQL(一种类 SQL 语言)。如果想要在 HBase 上使用 SQL,则需要联合使用 Apache Phonenix,或者联合使用 Hive 和 HBase。但是和上面提到的一样,如果集成使用 Hive 查询 HBase 的数据,则无法绕过 MapReduce,那么实时性还是有一定的损失。Phoenix 加 HBase 的组合则不经过 MapReduce 的框架,因此当使用 Phoneix 加 HBase 的组成,实时性上会优于 Hive 加 HBase 的组合,我们后续也会示例性介绍如何使用两者。最后我们再提下 Hive 和 HBase 所使用的存储层,默认情况下 Hive 和 HBase 的存储层都是 HDFS。但是 HBase 在一些特殊的情况下也可以直接使用本机的文件系统。例如 Ambari 中的 AMS 服务直接在本地文件系统上运行 HBase。
STM32F4 FLASH 简介基本知识代码块 简介 在我们应用开发时,经常会有一些程序运行参数需要保存,如一些修正系数。这些数据的特点是:数量少而且不需要经常修改,但又不能定义为常量,因为每台设备可能不一样而且在以后还有修改的可能。将这类数据存在指定的位置,需要修改时直接修改存储位置的数值,需要使用时则直接读取,会是一种方便的做法。考虑到这些数据量比较少,使用专门的存储单元既不经济,也没有必要,而STM32F4内部的Flash容量较大,而且ST的库函数中还提供了基本的Flash操作函数,实现起来也比较方便。 本代码用于上电时读取flash数据给滤波器权重参数(float型),再有其他信号时可以修改flash数据(未做)。
基本知识 STM32F40xx/41xx 的闪存模块组织如图 所示 主存储器,该部分用来存放代码和数据常数(如 const 类型的数据),主存储器的起始地址就是 0X08000000, B0、 B1 都接 GND 的时候,就是从 0X08000000 开始运行代码的。
代码块 ST的库函数包含了对flash的基本操作,为了使用方面,根据我们自己的需要对其进行再次封装。 对于读操作相对比较简单,内置闪存模块可以在通用地址空间直接寻址,就像读取变量一样。 对于写操作相对来说要复杂得多,写操作包括对用户数据的写入和擦除。为了防止误操作还有写保护锁。但这些基本的操作ST的库函数已经为我们写好了,我们只需要调用即可。
#define FLASH_SAVE_ADDR 0X08020000 //设置FLASH 保存地址(必须为偶数,且所在扇区,要大于本代码所占用到的扇区. //否则,写操作的时候,可能会导致擦除整个扇区,从而引起部分程序丢失.引起死机. #define STM32_FLASH_BASE 0x08000000 //STM32 FLASH的起始地址 #define SIZE 4 float vel_filter_weight_read[SIZE] = {0.0}; float vel_filter_weight_write[SIZE] = {0.0}; float x_filter_0 = 0.0, x_filter_1 = 0.0; float yaw_filter_0 = 0.0, yaw_filter_1 = 0.0; //FLASH 扇区的起始地址 #define ADDR_FLASH_SECTOR_0 ((u32)0x08000000) //扇区0起始地址, 16 Kbytes #define ADDR_FLASH_SECTOR_1 ((u32)0x08004000) //扇区1起始地址, 16 Kbytes #define ADDR_FLASH_SECTOR_2 ((u32)0x08008000) //扇区2起始地址, 16 Kbytes #define ADDR_FLASH_SECTOR_3 ((u32)0x0800C000) //扇区3起始地址, 16 Kbytes #define ADDR_FLASH_SECTOR_4 ((u32)0x08010000) //扇区4起始地址, 64 Kbytes #define ADDR_FLASH_SECTOR_5 ((u32)0x08020000) //扇区5起始地址, 128 Kbytes #define ADDR_FLASH_SECTOR_6 ((u32)0x08040000) //扇区6起始地址, 128 Kbytes #define ADDR_FLASH_SECTOR_7 ((u32)0x08060000) //扇区7起始地址, 128 Kbytes #define ADDR_FLASH_SECTOR_8 ((u32)0x08080000) //扇区8起始地址, 128 Kbytes #define ADDR_FLASH_SECTOR_9 ((u32)0x080A0000) //扇区9起始地址, 128 Kbytes #define ADDR_FLASH_SECTOR_10 ((u32)0x080C0000) //扇区10起始地址,128 Kbytes #define ADDR_FLASH_SECTOR_11 ((u32)0x080E0000) //扇区11起始地址,128 Kbytes /**获取某个地址所在的flash扇区 *addr:flash地址 *返回值:0~11,即addr所在的扇区 */ uint16_t STMFLASH_GetFlashSector(u32 addr) { if(addr<ADDR_FLASH_SECTOR_1)return FLASH_Sector_0; else if(addr<ADDR_FLASH_SECTOR_2)return FLASH_Sector_1; else if(addr<ADDR_FLASH_SECTOR_3)return FLASH_Sector_2; else if(addr<ADDR_FLASH_SECTOR_4)return FLASH_Sector_3; else if(addr<ADDR_FLASH_SECTOR_5)return FLASH_Sector_4; else if(addr<ADDR_FLASH_SECTOR_6)return FLASH_Sector_5; else if(addr<ADDR_FLASH_SECTOR_7)return FLASH_Sector_6; else if(addr<ADDR_FLASH_SECTOR_8)return FLASH_Sector_7; else if(addr<ADDR_FLASH_SECTOR_9)return FLASH_Sector_8; else if(addr<ADDR_FLASH_SECTOR_10)return FLASH_Sector_9; else if(addr<ADDR_FLASH_SECTOR_11)return FLASH_Sector_10; return FLASH_Sector_11; } /**读取指定地址的字(32位数据) *faddr:读地址 *返回值:对应数据 */ u32 STMFLASH_ReadWord(u32 faddr) { return *(vu32*)faddr; } /**从指定地址开始读出指定长度的数据 *ReadAddr:起始地址 *pBuffer:数据指针 *NumToRead:字(4位)数 */ void STMFLASH_Read(u32 ReadAddr,u32 *pBuffer,u32 NumToRead) { u32 i; for(i=0;i<NumToRead;i++) { pBuffer[i]=STMFLASH_ReadWord(ReadAddr);//读取4个字节.
插入排序的算法思想:将待排序元素分为已排序子集和未排序子集,一次从未排序子集中的一个元素插入已排序子集中,使已排序自己仍然有序;重复执行以上过程,指导所有元素都有序为止。
折半插入排序:算法是直接插入排序的改进。它的主要改进在于在已经有序的集合中使用折半查找法确定待排序元素的插入位置, 找到要插入的位置后,将待排序元素插入相应的位置。
假设待排序的元素有7个,分别为67、53、73、21、34、98、12。使用折半插入排序对该元素序列第一堂排序的过程如下图所示。
第2趟折半插入排序过程如下图所示。
从以上两趟排序过程可以看出,折半插入排序与直接插入排序的区别仅仅在于查找插入的位置的方法不同。一般情况下,折半查找的效率要高于顺序查找的效率,因此折半插入排序算法可以减少比较的次数。 通过对直接插入排序算法的简单修改,得到如下折半插入排序的算法:
类型定义头文件 #define MAXSIZE 20 /* 一个用作示例的小顺序表的最大长度 */ typedef int InfoType; /* 定义其它数据项的类型 */ typedef int KeyType; /* 定义关键字类型为整型 */ typedef struct { KeyType key; /* 关键字项 */ InfoType otherinfo; /* 其它数据项,具体类型在主程中定义 */ }RedType; /* 记录类型 */ typedef struct { RedType r[MAXSIZE+1]; /* r[0]闲置或用作哨兵单元 */ int length; /* 顺序表长度 */ }SqList; /* 顺序表类型 */ 函数文件 void BinInsertSort(SqList *L) /*折半插入排序*/ { int i,j,mid,low,high; DataType t; for(i=1;i<L->length;i++) /*前i个元素已经有序,从第i+1个元素开始与前i个的有序的关键字比较*/ { t=L->data[i+1]; /*取出第i+1个元素,即待排序的元素*/ low=1,high=i; while(low<=high) /*利用折半查找思想寻找当前元素的合适位置*/ { mid=(low+high)/2; if(L->data[mid].
一直以来,数据恢复和高昂的恢复费用是划等号的。
当然,在现在越来越多的数据恢复软件面前,数据恢复的价格是降低了,但是也有不少人发愁:我只是需要恢复几张照片,几个办公文档罢了,一定要为了这么少的数据去花那一两百块吗?
如果这些照片文档非常重要,想必大家都愿意为此买单。可也有那么一些东西,虽然称不上重要,但总觉得弃之可惜。而现在市面上的软件,由于其虚拟商品的特殊性,大多都是走的先付款后使用的套路,但这也不能怪别人开发团队,你要是先免费用了,完了以后拍拍屁股走人,不给钱怎么办?
那说了这么多,到底有免费恢复数据的软件么?
迷你兔数据恢复工具免费版,最多可支持恢复3G大小的数据。3G意味着什么?可能是几百张照片,一两部高清电影和无数个工作文档。并且不管是免费版还是付费版,都能获得开发团队一样的技术支持,这样的好事你还在等什么呢?
不管是误删除还是格式化,是电脑磁盘有问题,还是你的移动U盘,迷你兔都能兼顾,并且还可以支持恢复硬盘数据,相机内存卡等移动存储设备数据,功能全面,操作简单,电脑小白也能轻易上手。
免费版链接在此:https://www.minitu.cn/download
别怪我没告诉你哦!
文章目录 Pycharm远程调试 ##Pycharm远程访问ssh ###【1】 打开pycharm的File 找到 setting 点击进入 在搜索框中搜索 project 然后找到project interpreter 进入 如图: 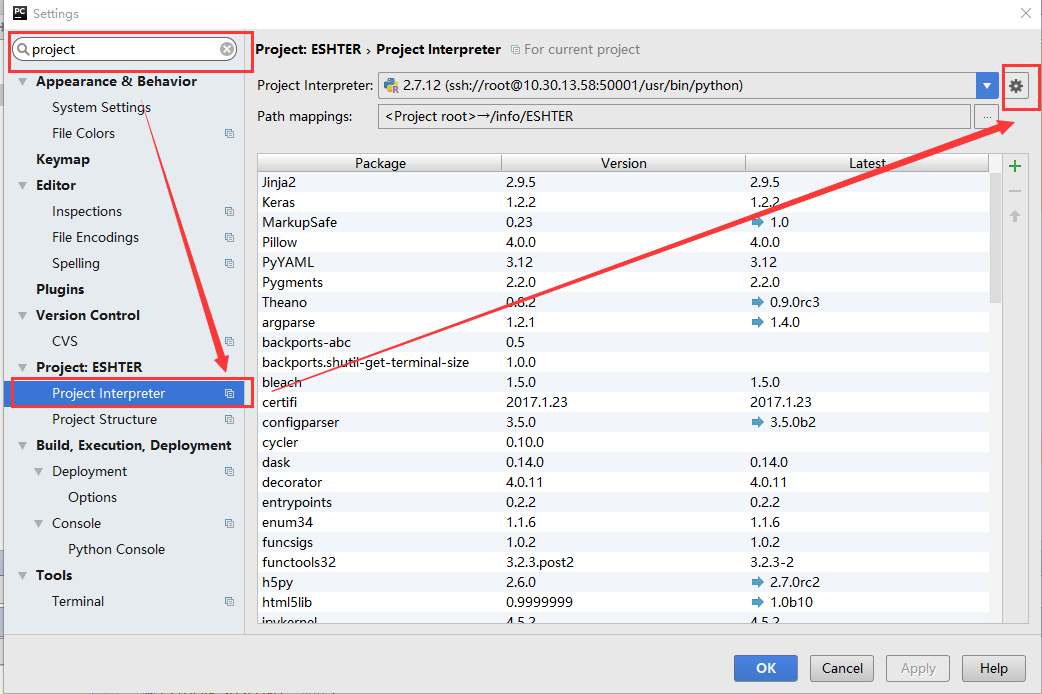 ###【2】点开形如设置图样的图标,然后选中add remote 点击进入,如下图所示: 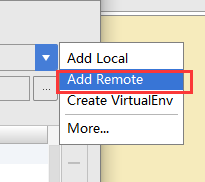 ###【3】进入如下界面: 选择 SSH Credentials、然后在HOST处输入需要访问的服务器的ip地址,用户名和密码是ssh服务给你的用户名和密码,下面的那个 python interpret paths是服务器安装python的路径,但是如果是3.5版本的python,python intreprer path需要改为/usr/bin/python3。在这里我是选择2.7版的python,无需修改。点击ok。 注:port 是服务器提供给你的端口号 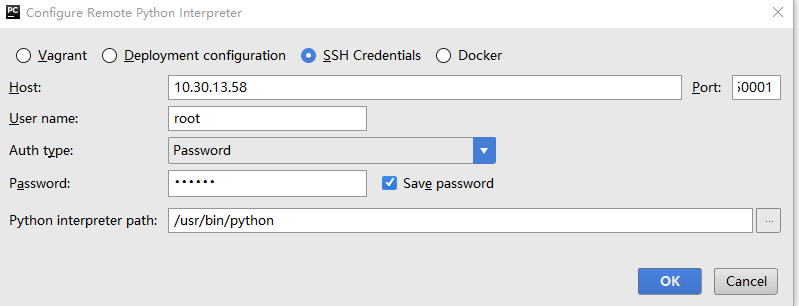 ###【4】在tool目录下找到 deployment 下面的配置,并点击进入,如下图: 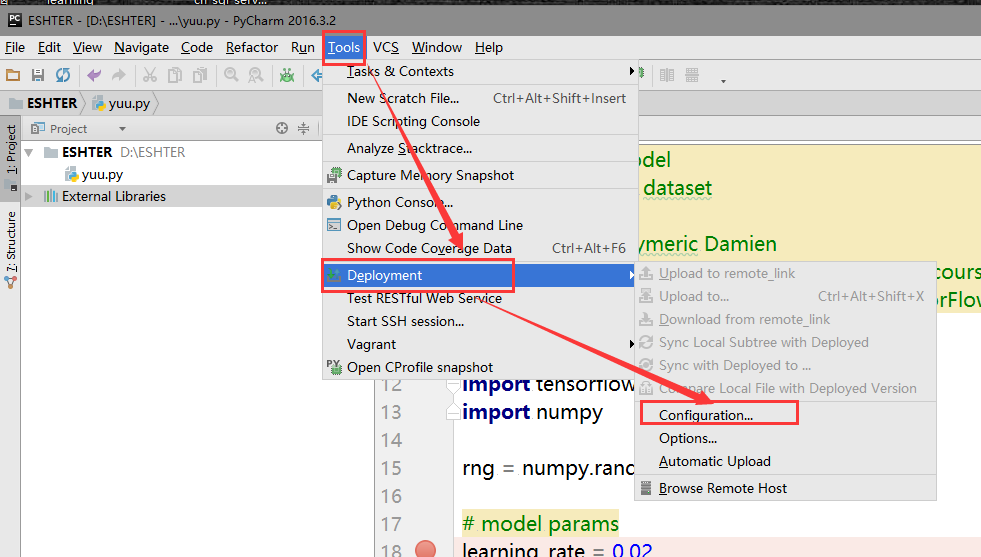 ###【5】点击那个形如+的按钮,点进去,会看到下图的一个界面,然后在type处选择SFTP NAME随意啦,在这里我写的是 remote_sftp,点击确定。 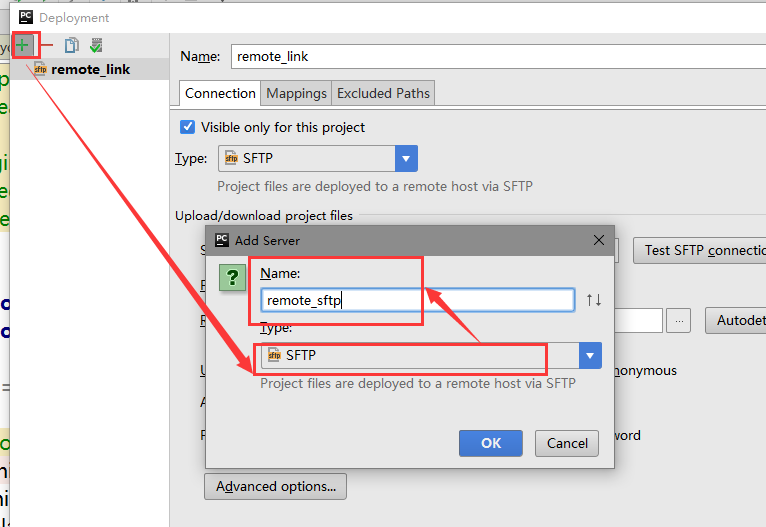 ###【6】在sftp host处 输入需要远程访问的服务器的ip,root path填写你需要在服务器里面的哪个目录下存储你的code 我选择的是/info,用户名和密码和图三的用户名和密码保持一致,同样的选择保存密码,点击ok。 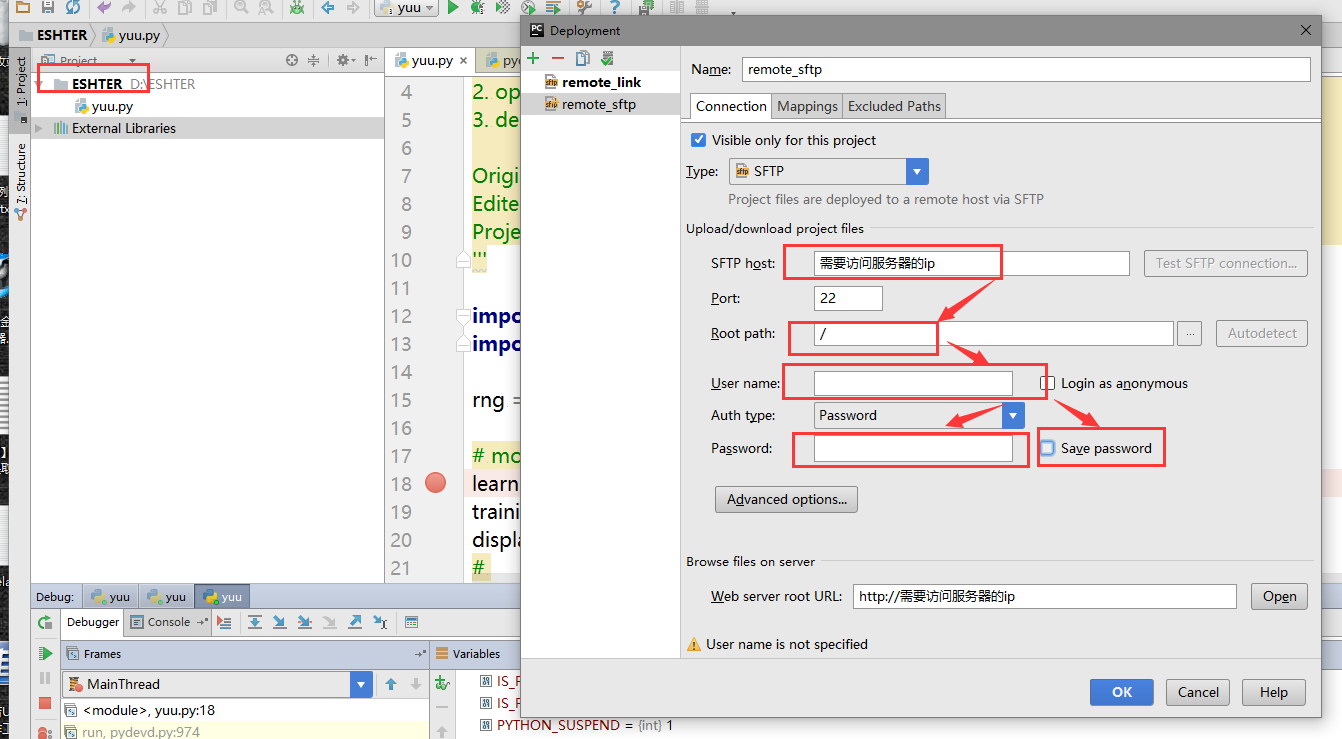 ###【7】点击mapping 这里的local path 它会自己填写好,和你预定义的一样,但是 在这里需要注意的是,deployment path 和web path一定要和local path一致,否则会出错。设置完后,点击ok 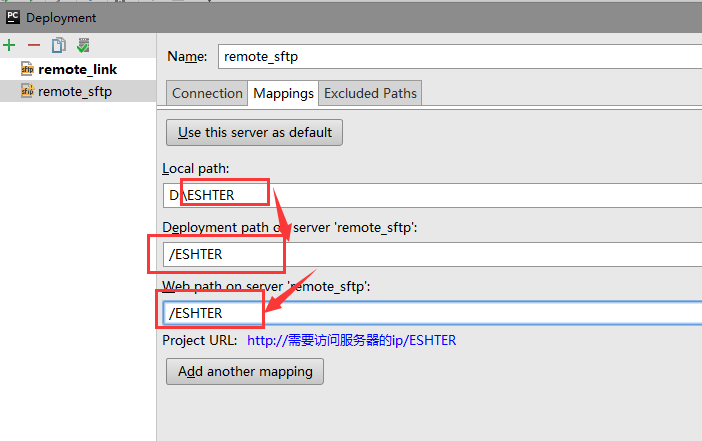 ###【8】重新找到 file 下面的 setting 搜索 project intrepret 并点击设置样按钮 选择 add remote 并将选项选中deployment configuration ,点击ok。 !
CNN网络的经典结构是: 输入层—>(卷积层+—>池化层?)+—>全连接层+ (其中+表示至少匹配1次,?表示匹配0次或1次)
全卷积神经网络Fully Convolutional Network (FCN) 全卷积神经网络即把CNN网络最后的全连接层替换为卷积层。为什么这么做?换句话说这样会带来什么好处呢?
首先,说一下卷积层和全连接层的区别:卷积层为局部连接;而全连接层则使用图像的全局信息。可以想象一下,最大的局部是不是就等于全局了?这首先说明全连接层使用卷积层来替代的可行性。
然后,究竟使用卷积层代替全连接层会带来什么好处呢?答案:可以让卷积网络在一张更大的输入图片上滑动,得到每个区域的输出(这样就突破了输入尺寸的限制)。论文里Fully Convolutional Networks for Semantic Segmentation介绍的很清楚,解读如下: 需要说明的是这一特性不仅可用于语义分割,在物体分类、目标检测中都可以使用。
参考: How does the conversion of last layers of CNN from fully connected to fully convolutional allow it to process images of different size? CS231n课程笔记翻译:卷积神经网络笔记 论文笔记–Fully Convolutional Networks for Semantic Segmentation
数量统计量是只适合数量类型数据的统计量,使我们最常见的统计量。笔者之前对资料特征数的计算作了简单地介绍,详情可跳转至 资料特征数的计算,本篇博客力求全面和简洁易懂。
对于数量类型的数据样本 X1,X2,⋯,Xn, 其数量统计量定义如下:
均值(Mean)
X⎯⎯⎯=1n∑n1Xi 很简单,用来描述数据取值的平均位置。
方差(Sample Variance)
S2n=1n−1∑(Xi−X⎯⎯⎯)2 至于为何分母为 n-1,同样点击传送门:资料特征数的计算。
标准差(Standard Deviation)
Sn=1n−1∑(Xi−X⎯⎯⎯)2‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√ 标准差在数值上等于方差的开平方,他们都是用来反应数据取值的离散(变异)程度的。标准差的量纲与数据的量纲相同。
变异系数(Coefficient of Variation,CV)
CV=SnX⎯⎯ 标准差与均值的比值成为变异系数。它是一个无量纲的量,用来刻画数据的相对分散性。
标准误(Standard Error)
1n−1∑n1(Xi−X⎯⎯)2√n√=1n(n−1)∑n1(Xi−X⎯⎯⎯)2‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√ 标准误是由样本的标准差除以样本个数的开平方计算得到的。标准误代表的就是样本均数对总体均数的相对误差。
偏度(Skewness)
skewness=n√∑n1(Xi−X⎯⎯)3[∑n1(Xi−X⎯⎯)2]32 偏度是用来刻画数据对称性的指标。关于均值对称的数据,其偏度系数为0;若左侧数据比较分散,则偏度系数小于0;若右侧数据比较分散,则偏度系数大于0。
在图像上的差别为:正态分布的偏度为0,如果 skewness>0 代表波形有右侧长尾(正偏),如果 skewness < 0 代表波形有左侧长尾(反偏)。图像如下(左图为反偏,右图为正偏): 在 MATLAB 中对应的函数即为 skewness().
峰度(Kurtosis)
kurtosis=n∑n1(Xi−X⎯⎯)4[∑n1(Xi−X⎯⎯)2]2−3 峰度可以描述样本数据分布形态相对于正态分布的陡峭程度。
若 Kurtosis=0,则与正态分布的陡峭程度相同;若 Kurtosis>0,则比正态分布的高峰更加陡峭,表现为尖顶峰;若 Kurtosis<0,则比正态分布的高峰显得平缓,表现为平顶峰。 在 MATLAB 中对应的函数即为 kurtosis().
偏度与峰度可以用来描述样本数据分布形状,如果是正态分布,那么偏度为0,峰度也为0.
【项目实战】 Apache POI 导出 Excel 常见的23问题
这个是即 《 Java中使用POI导出Excel 之 项目实战详细教程 》之后,需要注意的问题!
1、我使用 poi-ooxml-schemas jar,但是我的代码失败了,并且报“java.lang.NoClassDefFoundError:org / openxmlformats / schemas / * something *”异常 ? 要使用新的OOXML文件格式,POI需要包含由XMLBeans编译的文件格式XSD的jar 。这些XSD一旦编译成Java类,就可以在 org.openxmlformats.schemas命名空间中自动生成。 所有模式的完整jar都是ooxml-schemas-1.3.jar,目前大约是15mb。在较小的POI,ooxml-schemas 仅约4MB。后一个jar文件只包含通常使用的部分。 许多用户选择使用较小的 poi-ooxml-schema jar 来节省空间。然而,poi-ooxml-schema jar仅包含通常使用的XSD和类,如单元测试所标识。也许您可能会尝试使用不包含在最小poi-ooxml-schemas jar中的文件格式的一部分。在这种情况下,您应该切换到完整的ooxml-schemas-1.3.jar。长期来看,您也可能希望提交使用XSD的额外部分的新的单元测试,以便将来的poi-ooxml-schema jar将包含它们。 请注意,在历史上,使用了不同版本的ooxml-schemas
2、我的代码使用一些新功能,编译好但是当出现“MethodNotFoundException”或“IncompatibleClassChangeError” ? 您的类路径中几乎肯定有一个较旧版本的Apache POI。相当多的运行时和其他软件包会运送较旧版本的Apache POI,所以这是一个经常出现的问题。有些版本可能会使用一个就的版本,有些版本可能使用一整套旧的POI jar。 识别有争议的早期jar文件的最好方法是使用几行java代码。这些将加载一个Core POI类,一个OOXML类和一个Scratchpad类,并报告它们都来自哪里。
ClassLoader classloader = org.apache.poi.poifs.filesystem.POIFSFileSystem.class.getClassLoader(); URL res = classloader.getResource( “组织/阿帕奇/ POI / POIFS /文件系统/ POIFSFileSystem.class”); String path = res.getPath(); System.out.println(“POI Core来自”+路径); classloader = org.apache.poi.POIXMLDocument.class.getClassLoader(); res = classloader.
本文转载 http://blog.csdn.net/ccg_201216323/article/details/53822573
平常开发工作中,我经常取Github上搜索项目,Clone下来学习使用,在这个过程中,发现了好多比较好的Github地址,记录下来,分享出去。
非常有用的GitHub链接(顺序不分先后): 1. https://github.com/jeasonlzy: OkHttpUtils-2.0.0 升级后改名 OkGo,全新完美支持RxJava,比Retrofit更简单易用。完全仿微信的图片选择,并且提供了多种图片加载接口,选择图片后可以旋转,可以裁剪成矩形或圆形,可以配置各种其他的参数类似QQ空间,微信朋友圈,微博主页等,展示图片的九宫格控件类似淘宝的商品详情页,继续拖动查看详情,其中拖动增加了阻尼主要是常用自定义控件的类库,该项目已经上传到 jCenter 仓库,可以直接使用 2. https://github.com/Trinea/android-open-project: 这个链接中包含的项目就多了,主要包含的有:ListView、ActionBar(虽然现在被TitleBar代替)、Menu、ViewPager 等太多了。
3. https://github.com/hongyangAndroid: Android流式布局,支持单选、多选等,适合用于产品标签等。okhttp的辅助类,对okhttp的深度封装Android屏幕适配方案,直接填写设计图上的像素尺寸即可完成适配,最大限度解决适配问题他的博客写的非常好,可以通过此链接来访问他的CSDN博客首页 www.zhanghongyang.com 4. https://github.com/zzzlw/autovideoplayer 仿新浪微博列表滑动自动播放视频
5. https://github.com/h4de5ing/AndroidCommon 基于Android系统Api封装常用工具类,主要有获取APP信息、缓存、加密、日期处理、屏幕、设备、文件图片、网络、字符串等等
6. https://github.com/CarGuo/GSYVideoPlayer 视频播放器(IJKplayer),HTTPS支持,支持基本的拖动,声音、亮度调节,支持边播边缓存,支持视频本身自带rotation的旋转(90,270之类),重力旋转与手动旋转的同步支持,支持列表播放 ,直接添加控件为封面,列表全屏动画,视频加载速度,列表小窗口支持拖动,5.0的过场效果,调整比例,多分辨率切换,支持切换播放器,进度条小窗口预览,其他一些小动画效果。
7. https://github.com/bingoogolapple Android 图片选择、预览、九宫格图片控件、拖拽排序九宫格图片控件。多种下拉刷新效果、上拉加载更多、可配置自定义头部广告位由 RxJava + RxLifecycle + Retrofit + BGA 系列开源库搭建的 Android MVC、MVP、MVVM 项目开发脚手架 8. https://github.com/AndroidMsky 自动领取微信红包,支持锁屏聊天界面等各种情况目前为6.3.32版本SwipeRefreshLayout使用支持自动刷新ViewPager16种切换动画,早晚能用到 9. https://github.com/GreendaMi 使用了Vitamio作为视频播放框架,实现了基本的视频全屏播放,进度调节。 10. https://github.com/HomHomLin 实现类似微信WebView的上拉下拉弹跳效果和iOS的ListView的果冻效果。FrescoImageView是一种Android平台的图像控件,可以异步加载网络图片、项目资源和本地图片,并且支持双指缩放、图片的基本处理以及Fresco的所有特性。Android AdvancedPagerSlidingTabStrip是一种Android平台的导航控件,完美兼容Android自带库和兼容库的ViewPager组件。微信小视频+秒拍,FFmpeg库封装 11. https://github.com/xfshipan 高仿大米应用市场基于 React Native 的 Android 企业级应用 Demo。一个定期翻译国外Android优质的技术、开源库、软件架构设计、测试等文章的开源项目整理的常见的问题 12. https://github.com/loonggg 使用CoordinatorLayout仿稀土掘金个人界面MaterialDesign系列控件讲解『非著名程序员』公众号文章推送列表一个图文混排的库,支持html标记语言的图文混排 13. https://github.com/ChaserSheng Android快速开发框架:相关内容由实际项目中抽取和互联网搜索得到安卓学习笔记此仓库包含了App通用的模块,各个模块采用单独module进行维护,旨在帮助开发者进行组件化开发,目前包含沉浸式状态栏,通用的titlebar,Activity堆栈管理器,全局右滑关闭页面的效果,通用dialog,流式标签等模块,持续更新中Android 开发中的日常积累(HTTP2.
- 设置默认指针 Edit->Project Setting->Player->Default Cursor中设置,如下图: - 通过代码设置鼠标指针 通过Cursor.SetCursor()的方法,需要三个参数 Cursor.SetCursor(Texture2D, Vector2, CursorMode); 第一个为一张2d图片。第二个为2d的一个坐标点,用来设置鼠标焦点,一般设置为(0,0),即以图片左上角为鼠标实际点击位置。 第三个为鼠标的设置,就是说呢,我们鼠标指针有硬件和软件,有些设备支持用硬件直接去设置鼠标指针,一般直接使用CursorMode.Auto,就是让用户自己去设置到底是用软件来设置这个功能还是用硬件。
public Texture2D cursor_normal;//获取相应的图片 private Vector2 hotspot = Vector2.zero; private CursorMode mode = CursorMode.Auto; Cursor.SetCursor(cursor_normal, hotspot, mode);
Gin Web开发02 这章主要解析examples中的Demo。 favicon 解决网站图标问题 package main import ( "github.com/gin-gonic/gin" "github.com/thinkerou/favicon" ) func main() { app := gin.Default() app.Use(favicon.New("./favicon.ico")) // 运行目录下的favicon.ico app.GET("/ping", func(c *gin.Context) { c.String(200, "Hello favicon.") }) app.Run(":8080") } 这里引入一个新的库(gin插件),内部处理了/favicon.ico这个URL的返回问题。 basic 模拟了一个DB,然后演示了简单的URL和请求问题。
package main import ( "github.com/gin-gonic/gin" ) var DB = make(map[string]string) func main() { // Disable Console Color // gin.DisableConsoleColor() r := gin.Default() // Ping test r.GET("/ping", func(c *gin.Context) { c.String(200, "pong") }) // Get user value r.
相机的内存卡承载着存储照片的使命,如果不慎被格式化,可按照下面的方法操作找回被格式化的照片。
打开迷你兔数据恢复工具(https://www.minitu.cn/download),将内存卡连接至电脑,选择软件的“移动存储设备恢复”
然后进入扫描页面,选择内存卡所在的磁盘对其进行完全扫描。完全扫描的时间越长,越有利于找出更多的丢失数据。
扫描完成后,软件会生成一个丢失数据的列表,在此列表中选择需要恢复的数据保存即可。如果是恢复照片的话,还可以在右边查看预览。
迷你兔数据恢复工具可免费支持3G大小的数据恢复,并且适用于电脑、硬盘、U盘等多种存储设备,是非常不错的数据恢复软件。
今天终于翻译完了!
************************************************************************************************************************************
3.2.3 上行带宽授权的GATE报文
OLT对ONU的带宽请求允许是通过下行的GATE MPCPDU实现的。门(gating)的功能是控制ONU的上行数据。门(gating)功能的实现是通过ONU里的定时器,该定时器与OLT里的定时器同步(关于定时器的具体描述见3.5)。GATE(门)报文决定了ONU上行的开始时间和传输长度。来自OLT的带宽允许报文包含至少1024个时间段,从而使得ONU有时间处理GATE报文,从而能够准备传输(上行数据)。当ONU的本地时间与GATE里的时间一致时,ONU打开激光。(GATE内的)长度域决定了ONU允许发送分帧的时间长度。时间窗口是由ONU本地时钟的周期数目决定的。开始时间是32位的数字(与本地计时器计数值的一致),长度则是16位的数字。OLT发送的报文包括ONU激光的开启和关闭时间,以及ONU在带宽允许时间内发送上行同步模式报文的时间。
OLT周期性的向ONU发送GATE报文,这样就能知道每个ONU的上行带宽需求。GATEMPCPDU如图5所示。ONU每收到一个GATE就会将内部的看门狗定时器复位。注意GATE报文里有一个flag,能够使ONU回复REPORT MPCPDU具体如下。
GATE里的上行带宽允许信号的值的范围为0-4。正如4.3中所讨论的,ONU在其发现阶段广播其能接收的允许信号的值。一个没有允许值的GATE被用于ONU计时器的超时计时器的保活,以及交流时间戳报文。在一个GATE上搭载多个允许报文,被用于ONU的第一次有效负载传输,具体见图6。比如,不同的允许报文应该与ONU上不同的优先级队列相对应。然而在实际中,这对OLT的带宽分配增加了相当大的复杂度。在GATE上搭载单个允许报文对上行带宽来说能获得更好的解决方案和更快的响应速度,对下行带宽开销影响也不大。更好的解决方案是,对于ONU的带宽请求,OLT在每个流的DBA上,在每个GATE上搭载允许报文,从而让ONU决定在上行允许报文中发送哪些数据。
“同步时间”域在GATE MPCPDU中,是由OLT发送的报告,用于交流上行传输分帧开始时所需的时间,从而使得接收器与新的分帧同步。如图4所示,每个分帧以同步模式开始,后紧跟着分帧分隔模式和2块无意义字符。ONU不断发送66位的同步模式,然后发送分帧分隔模式,这样整个序列的持续时间就与OLT提供的同步时间一致。
3.2.4 上行带宽请求REPORT
ONU通过发送REPORTMPCPDU传输上行带宽请求。OLT通过GATE允许这些请求。REPORT除了包括时间戳,还包括带宽请求de 摘要报文和其所需的特定的带宽。如同EPON一样,10G EPON也支持8个优先级队列,具体见IEEE802.1Q。REPORT报文的摘要域可知有哪些队列以及多少队列需要被发送。摘要由二进制数字来显示每个队列需要传输的特定位。位计数器是一个16位的数字,包括IPG(Inter-PacketGap)字符。与EPON不同的是,10G EPON的带宽值不包括分帧开销和FEC开销。
每个ONU都周期性的发送REPORT,及时没有数据传输,这是为了重置OLT看门狗定时器。如果看门狗定时器超时,OLT将把ONU从网络上注销掉。
3.3 FEC(Forward Error Correction,前向错误纠正)
FEC允许连接有稍大一些的误码率。结果导致FEC会明显增加光链路的开销,当然这也会使得传输距离更远和更高的分光比。当比特率增加时FEC显得尤为重要。因此,在10G EPON中FEC是必须的。此外,10G EPON的FEC和EPON的FEC有两样不同。第一,10G EPON为错误纠正提供了更强大的16标志位的RS(255,233)码,而EPON使用的是8标志位的RS(255,239)码。第二,10G EPON的FEC用于固定序列长度的数据流,而不是如图7所示的以太网帧。图7显示了下行传输的方向,该方向为连续的FEC码,该FEC码包括以太网帧和诸如IPG和有序集合的数据(Ordered Set data)等组间报文。上行传输基本一致,除了如图4所示,上行分帧的第一个FEC码与分帧的开始部分一致,从而使得OLT的FEC解码器的码字与每个分帧同步。
将FEC加入10G EPON流的一个挑战是扩展64B/66B块的码格式,这样10G的接收器就能够接收和同步包含FEC奇偶校验数据的流。所用方法见图8。每个FEC码字包含一组27个64B/66B的块。FEC编码的第一步就是移除64B/66B块的第一个flag位。由此产生的27x65=1755位的块与首部的29位的0构成总共1784位(223byte)。RS(255,223)编码产生32字节的校验。最后,为0的叠加位被删除,27个的64B/66B初始块被保存,校验字节被转换成64B/66B的序列块用于传输。特别的,32字节的奇偶校验码被分成4组64位。这64位的奇偶校验组被加上了一对头部从而得到64B/66B的块。为了得到可识别的头部模式,头部的奇偶校验块分别为00,11,11和00。31个64B/66B的字符的字符串从而可以传输。
接收器从而能同步64B/66B的字符流,用反向过程抽取出原数据,解码FEC块完成错误纠正。
3.4 ONU发现和激活
握手报文见图9。OLT周期性的打开一个发现窗口,ONU从而能够报告它们自己。该周期被单独执行。OLT通过传输发现GATE报文打开发现窗口,该发现报文包括窗口的长度和开始时间。发现GATE MPCPDU包括发现报文域,从而可以告知ONU,该OLT是否能够接收1G上行信号,是否能够接收10G上行信号,该发现窗口能否为1G或10G上行信号打开。
未注册的ONU通过发送REGISTER_REQ回复发现GATE报文。REGISTER_REQ包括ONU的MAC地址以及可以接收授权的数目(见3.2.2多授权的情况)。REGISTER_REQ被扩展包括开启激光和关闭激光的域,从而能够得到ONU激光开启和关闭的时间。当多个ONU尝试在相同的发现时间窗口注册时,用竞争算法来最小化碰撞的可能性。竞争算法是通过ONU从发现窗口开始时间的一个随机时间延时实现的。注意关闭时间的上限要求要足够短,从而ONU能够在发现窗口结束前发送整个REGISTER_REQ。
当OLT接收到REGISTER_REQ,则分配给ONU一个LLID,并将LLID与ONU的MAC地址绑定。随后OLT给ONU发送REGISTER报文,与ONU的LLID通信,使ONU获得OLT的同步时间,返回ONU能接收的最大未授权的数目,返回开启激光和关闭激光的时间域。同步时间是OLT需要可靠同步ONU上行传输分帧的时间。同步时间在ONU发送分帧的开始部分的多个66位数据模式中。
当ONU处理完注册报文,它发送一个Register_ACK报文给OLT,以回复其发送的标准GATE报文。注意,由于ONU在接收到REGISTER前没有LLID,因此发现GATE报文、REGISTER_REQ和REGISTER都是通过广播的形式发送出去的。在ONU接收到LLID后,GATE报文和REGISTER_ACK报文都是以单播的形式发送出去的。
ONU的注册和解注册机制在此协议中。
3.5 测距机制 //终于要翻译完了,啊啊啊啊啊!
测距机制使用的是OLT和每个ONU内的本地时钟。计时器有32位,每隔16ns增加一次。
OLT的计数器在PON系统中有重要作用。当OLT发送MPCPDU报文时,将当期计数器的值装入32bit的时间戳域。当ONU发送MPCPDU给OLT时,ONU将更新后的计数器值装入时间戳域。OLT根据当前计数器的值和MPCPDU中时间戳的值两者的偏移量,从而可以计算出往返时间(RTT)。RTT可用来测出ONU(与OLT)的距离值,该值将在OLT决定发送上行带宽授权报文时做参数考虑。
RTT随时间也许会出现偏移。当偏移超过一定的阈值时,可认定为时间戳偏移错误。当偏移量介于MPCPDU中的期待值和实际值时,无论是ONU还是OLT都无法检测出这种情况。
3.6 EPON OAM
(10GEPON的)以太网连接的OAM报文作为EPON的IEEE802.3ah的一部分。一些以太网帧被用于发送OAM报文。
3.7 动态带宽分配(DBA)
通过DBA,OLT给ONU分配带宽不是每个都给固定值,而是根据ONU发送的数据决定的。如前所述,ONU通过REPORT报文通知OLT其所需要的带宽。带宽请求是在上行传输优先级队列的字符数目得到的。OLT也能考虑到与ONU相关的服务流的SLAs(ServiceLevel Aggreements)。比如,ONU需要使用VoIP业务,则需要规律的固定带宽。此时,ONU不需要浪费上行带宽发送带宽请求为此业务。另一个例子是,如果OLT接收到多个ONU的带宽请求,可以提供相比于ONU最近几次请求更大的带宽。在这种情况下,需要DBA算法保证当ONU带宽请求被服务时,有极少带宽请求的节点不会饥饿,也不会遭遇长期潜伏。
EPON DBA有很好的灵活性能够根据EPON网络的行为满足传输需求。在EPON(1G和10G)标准中定义了其灵活性,能够对可能的传输困难进行快速适应变化、使得EPON设备与发张变化的运输要求相兼容。DBA可以管理特定的能映射用户和服务流的容器,为用户和业务提供其所需要的QoS。两个直接与EPONDBA适应性相关的参数是潜伏(latency)和总系统表现(上行带宽的使用)。与此相关的一个例子是在PMC EPON OLT设备上使用的服务DBA算法。
10G EPON系统的一个好处是能够通过调整EPONDBA算法克服系统瓶颈。DBA的循环长度和每个ONU的带宽分配都是可以调整的,这样整个OLT的上行传输通过交换机时将会更加平稳,原则上更少的突发事件,是设备能克服网络拓扑结构中的阻塞元素(比如,相比于交换机与OLT的上联端口,分配给OLT端口更大的带宽,以节省CAPEX)。
4.EPON和10G EPON总结
表1总结了EPON和10G EPON的关键特点。
5. 总结
由于光纤的高带宽容量,使得它是宽带服务到家的最灵活媒介。经过多年被认为是最有希望的下一代技术,FTTH终于成为提供住户三重服务的、经济的、可选的技术。阻碍FTTH大规模发展的操作和技术难题都被解决了。
PON是提供FTTH最经济有效的方法。通过为不同的服务提供高灵活的平台和消除可接入对象的活跃电子,PON相比于使用铜的方式(如,DSL和使用调制解调器的铜线)为设备提供了大量的OAM节省。10G EPON的标准相比于EPON的标准,为每个用户提供了更高的带宽,在相同的PON下服务了更多的用户。10G EPON的一大特点是能与EPON共存。共存的方式使得能在现有的PON网络下以经济有效的方式升级带宽。这也使得在相同的PON网络下,使用10G EPON的ONU满足高带宽需求的用户和EPON的ONU满足低带宽需求的用户。
今秋,在以水城而闻名的威尼斯,来自世界各地的三千多位学者荟萃一堂,共赴两年一度的国际计算机视觉大会 (ICCV)。这次大会的一个重要亮点就是中国学者的强势崛起。根据组委会公开的数字,会议 40% 的论文投稿来自中国的研究者。在中国的人工智能浪潮中,商汤科技以及它与港中文的联合实验室无疑是其中最有代表性的力量。在本届 ICCV 大会,商汤科技与香港中大-商汤科技联合实验室共发表了 20 篇论文,其中包括 3 篇 Oral (录取率仅 2.09%) 和 1 篇 Spotlight,领先 Facebook(15 篇)、Google Research(10 篇)等科技巨头。
ICCV 是计算机视觉领域最高水平的国际学术会议,在其中发表的论文的量与质可以衡量一个公司或者研究机构的学术水平,以及其对未来科技发展潮流的把握。从商汤科技的 20 篇论文中,可以看到其在研究上重点发力的四大主线:
跨模态分析:让视觉与自然语言联合起来
在过去几年,随着深度学习的广泛应用,计算机视觉取得了突破性的发展,很多传统任务(比如图像分类,物体检测,场景分割等)的性能大幅度提高。但是在更高的水平上,计算机视觉开始遇到了新的瓶颈。要获得新的技术进步,一个重要的方向就是打破传统视觉任务的藩篱,把视觉理解与自然语言等其它模态的数据结合起来。商汤科技很早就捕捉了这一趋势,并投入重要力量进行开拓,取得了丰硕成果。在这一方向上,有 4 篇论文被 ICCV 2017 录用,包括一篇 Oral。
Towards Diverse and Natural Image Descriptions via a Conditional GAN (Oral).
Bo Dai, Sanja Fidler, Raquel Urtasun, Dahua Lin.
看图说话,也就是根据图像生成描述性标题,是今年来非常活跃的研究领域。现有的方法普遍存在一个问题,就是产生的标题很多是训练集中的表述的简单重复,读起来味同嚼蜡。这一问题的根源在于学习目标过分强调与训练集的相似性。这篇论文提出了一种新型的基于 Conditional GAN 的训练方法,把描述生成模型与评估模型合同训练。这样,评估的标准从「像不像训练集」变成「像不像人说话」,从而驱动生成模型产生更加自然、生动,并具有丰富细节的描述。这一工作为看图说话任务提供了新的思路。在 User Study 中,这种新的方法以 6:4 的胜率战胜了传统的方法。
另外两篇 paper 则从相反的方向思考,力图利用相关文本的信息来帮助提高视觉理解的能力。
Scene Graph Generation from Objects, Phrases and Caption Regions.
转载: http://blog.csdn.net/bebemo/article/details/51350484
并非你安装的软件已损坏,而是Mac系统的安全设置问题,因为这些应用都是破解或者汉化的,那么解决方法就是临时改变Mac系统安全设置。
出现这个问题的解决方法: 修改系统配置:系统偏好设置... -> 安全性与隐私。修改为任何来源 如果没有这个选项的话 (macOS Sierra 10.12) ,打开终端,执行 sudo spctl --master-disable 即可。 重点是这一行命令: sudo spctl --master-disable Rference MAC应用无法打开或文件损坏的处理方法
转自 http://www.linuxidc.com/Linux/2016-09/134907.htm
安装所需环境 Nginx 是 C语言 开发,建议在 Linux 上运行,当然,也可以安装 Windows 版本,本篇则使用 CentOS 7 作为安装环境。
一. gcc 安装
安装 nginx 需要先将官网下载的源码进行编译,编译依赖 gcc 环境,如果没有 gcc 环境,则需要安装:
yum install gcc-c++ 二. PCRE pcre-devel 安装
PCRE(Perl Compatible Regular Expressions) 是一个Perl库,包括 perl 兼容的正则表达式库。nginx 的 http 模块使用 pcre 来解析正则表达式,所以需要在 linux 上安装 pcre 库,pcre-devel 是使用 pcre 开发的一个二次开发库。nginx也需要此库。命令:
yum install -y pcre pcre-devel 三. zlib 安装
zlib 库提供了很多种压缩和解压缩的方式, nginx 使用 zlib 对 http 包的内容进行 gzip ,所以需要在 Centos 上安装 zlib 库。
由于现在的新媒体技术、资源、客户体验、需求等也越来越广、多、高,作为HTML5中较为重要的 新媒体video视频API,也是用得非常之多。
比如之前有个项目要在微信中做直播(半屏)播放(rtmp, m3u8等视频流),在IOS手机还好(听说ios手机微信没那么大的操控权限),而在Android手机下(Android系统毕竟是开源产品), 只要在微信X5内核浏览器中播放视频 就会自动全屏,而且z-index层级也是最高的(当然以qq.什么的域名的视频就不全屏,这是腾讯自已的东西,爱怎么搞就怎么搞咯!
我们第三方开发者也没办法,后来他们又搞了一个同层策略 在video标签中加上 x5-video-player-type="h5" 属性,然而还是有一堆这那样的问题),然后不能发东西,打字聊天等【如有朋友已经解决的情况下,还请多多指教,在此先谢过了!!!】, 还有前两天有个项目就用到了, 其中有个需求就是要获取html5的video视频第一帧作为播放前的图片,还有自定义控制相关播放按扭等等。
所以就和大家一起分享。如有更好解决办法的朋友,欢迎指导!
代码如下:
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>video获取第一帧</title> <style type="text/css"> html, body{ width: 100%; height: 100%; text-align: center;} li{ position: relative; display: inline-block; list-style: none;} canvas, img{ width: 600px; height: 350px; border: 1px solid darkgray;} button{ padding: 6px 20px; margin: 6px 3px;} h3{color: red;} </style> </head> <body> <header> <video id="video" src="./video.mp4" controls width="600" height="400" loop ></video> <p>视频播放器-VIDEO</p> </header> <section> <ul> <li> <img id="
凸函数有一个很好的性质,即只要能证明我们求解的问题是凸函数,最终得到的解一定是全局最优解
首先得注意一下: 中国大陆数学界某些机构关于函数凹凸性定义和国外的定义是相反的。Convex Function在中国大陆某些的数学书中,比如说我上大学那会同济版的高等数学就是指凹函数。Concave Function指凸函数。 如在讲到函数凹凸性的时候,概念是这么给出的: 设f(x)在[a,b]上连续,在(a,b)内具有一阶和二阶导数,那么, (1)若在(a,b)内f”(x)>0,则f(x)在[a,b]上的图形是凹的; (2)若在(a,b)内f”(x)<0,则f(x)在[a,b]上的图形是凸的。 个人觉得中国人所说的凸函数可能和凹凸这两个字象形体有关。 关于这一点,我觉得知乎上有些朋友解释的特别好,如 Cave代表洞穴 Concave 凹 Convex 凸 歪果仁是这么认识凹凸函数的 怎么样,是不是看到这个,突然就觉得好理解多了呢,我也是从知乎上看到的,狂戳链接 为什么数学概念中,将凸起的函数称为凹函数? 泰勒展开公式 泰勒公式是将一个在x=x_0处具有n阶导数的函数f(x)利用关于(x-x0)的n次多项式来逼近函数的方法。 若函数f(x)在包含x0的某个闭区间[a,b]上具有n阶导数,且在开区间(a,b)上具有(n+1)阶导数,则对闭区间[a,b]上任意一点x,成立下式: f(x)=f(x0)0!+f′(x)1!(x−x0)+f′′(x)2!(x−x0)2+⋯+f(n)(x)n!(x−x0)n 当然也可以写成: f(x)=∑i=0nf(n)(x)(x−x0)nn! or f(x)=∑i=0nf(n)(x)∗1n!(x−x0)n 泰勒级数展开(标量) 我们知道,二阶泰勒展开公式为: f(xk+δ)≈f(xk)+f′(xk)δ+12f′′(xk)δ2 此时, 1.若 f′(xk)=0 ,如果有 f′′(xk)>0 ,则 xk 为局部极小点(反之,局部极大点),这个在高数书上有,不懂的同学可以回头翻书看看。用几何方法特别好理解,二阶导数大于0说明,一阶导数的曲线呈现严格递增状态,就抛物线而言,斜率代表一阶导数,斜率在逐渐增大,说明抛物线开口向上。 2.如果 f′′(x"k)=0 ,有可能是一个鞍点,也就是拐点。比如说, f(x)=x3 ,一阶导数和二阶倒数在(0,0)这点处均为0。 总结一下 判断函数极大值以及极小值。 结合一阶、二阶导数可以求函数的极值。当一阶导数等于0,而二阶导数大于0时,为极小值点。当一阶导数等于0,而二阶导数小于0时,为极大值点;当一阶导数和二阶导数都等于0时,为驻点。 凸集(Convex Sets) 定义:一个集合 C∈RN 是凸的,则对于任意的 xi∈C ,有: θx1+(1−θ)x2∈C 0≤θ≤1,∑i=1nθi=1 简单理解为: 在实数R上(或复数C上)的向量空间中,如果集合S中任两点的连线上的点都在S内,则称集合S为凸集。例如球体是凸集,但是任何中空的或具有凹痕的例如月牙形都不是凸集。 如 就不是凸集。 常见的凸集 1.超平面 C=x|aTx=b 2.半空间 类似于一个分隔超平面将空间切成两半的感觉 3.多面体 这个应该比较好理解,比如说,三面体,四面体。。。 4.还有类似于平常见到的一些,比如说,圆、椭圆啊,椭球,球体都是凸集 注意: 凸集的交集也是凸集,比如说,圆和椭圆相交,正方体和五面体相交都是凸集。 证明也特别简单: 不妨设两个凸集为P,Q,对于任意两个点x,y∈P∩Q,由于P凸,故线段xy在P中,同理线段xy在Q中,故线段xy在P∩Q中。于是P∩Q凸 凸函数 如果函数f的定义域domf为凸集,且满足 ∀x,y∈domf,0≤θ≤1 有 f(θx+(1−θ)y)≤θf(x)+(1−θ)f(y) 则称f为定义域上的凸函数
本周周总结:
1.本周主要学完了HTML和CSS
2.做了一个百度首页.
3.算法的话做到了第二周的
4.由于课内开了java这门课,所以java的学习也开了一个头.
心得:因为我HTML是看慕课网上的知识点学完的,在运用实践的时候感觉学到的标签相较于w3c不是特别全面.然后很多标签虽然看过了一遍懂了原理,还是很容易忘记.然后,因为我是刚学完CSS立马就开始做百度首页了,所以代码排的很乱,有的样式是用选择器实现的有的又直接用style写在了标签上.经过学长学姐的点拨加上看了一些实战视频后,弄懂了代码排版方式.虽然百度页面看起来简洁,其实有些功能实现起来还是有一些难度,比如页面的缩放,其实我还没有能够很好的解决这个问题,只是粗略的在div外套一个div.
不足:这周虽然运动会放了假,可是做的事情还是比较少,本来准备跟着网上的实战视频另外写一个旅游网站,后来由于素材缺少加上下周要考试时间不太够,最终只理解了一下整个编写的思想以及代码的布局和编写的原理.
下周计划:
完成周任务网页的制作.
复习备考数电.
算法任务加快进度往前赶
滤波器作为图像处理课程的重要内容,大致可分为两类,空域滤波器和频率域滤波器。本文主要介绍常用的四种滤波器:中值滤波器、均值滤波器、高斯滤波器、双边滤波器,并基于opencv做出实现。空域的滤波器一般可以通过模板对原图像进行卷积进行,卷积的相关知识请自行学习。
理论知识: 线性滤波器表达公式:,其中均值滤波器和高斯滤波器属于线性滤波器,首先看这两种滤波器
均值滤波器:
模板:
从待处理图像首元素开始用模板对原始图像进行卷积,均值滤波直观地理解就是用相邻元素灰度值的平均值代替该元素的灰度值。
高斯滤波器:
模板:通过高斯内核函数产生的
高斯内核函数:
例如3*3的高斯内核模板:
中值滤波:同样是空间域的滤波,主题思想是取相邻像素的点,然后对相邻像素的点进行排序,取中点的灰度值作为该像素点的灰度值。
双边滤波:
C++代码实现: static void exchange(int& a, int& b) { int t = 0; t = a; a = b; b = t; } static void bubble_sort(int* K, int lenth) { for (int i = 0; i < lenth; i++) for (int j = i + 1; j < lenth; j++) { if (K[i]>K[j]) exchange(K[i], K[j]); } } ///产生二维的高斯内核 static cv::Mat generate_gassian_kernel(double u, double sigma, cv::Size size) { int width = size.
Java中的jsp中的八大隐式对象 application—所有用户和整个服务器都可访问 session—当前用户登录有效 request—一次请求有效,通常在2个JSP中有效 pageContext—当前用户一个JSP页面有效 response 响应请求 out 输出内容 page 相当于JAVA中的this config 初始化的配置文件(web.xml)访问对象 exception JSP中的异常处理
工作上需要阅读这份材料,但是找到的都是英文版的。为了阅读方便增强理解,只好自己来翻译,进度缓慢,术语难懂,能力有限,但是相信终有翻译完的时候。
英文原文见:https://wenku.baidu.com/view/3ccedd255901020207409c10.html
**********************************************************************************************************************************
IEEE802.3av(10G EPON)简介
摘要:在宽带竞争激烈的环境下,对于电信和CATV网络供应商来说,能提供三重服务(语音、视频和高速数据)是一种增加利润的重要方法。PON(无源光网络)是一种经济、可塑性好且有着良好前景的方法,而且它可以提供三重服务。目前,1Gbit/s IEEE802.3ah的EPON协议和ITU-T G.984 2.5Gbit/s的GPON协议已被制定出来,以提供三重服务。然而,高分辨率的交换数字视频服务如IPTV需要更高的带宽。本文提供了IEEE802.3av10Gbit/s EPON的指导性的概貌,也指出了它和EPON(1G)的区别。
1. 简介
PON作为一个有效的方法,通过将分光器靠近用户,减少了光收发器和光线的数目。目前被广泛使用的PON协议是IEEE802.3 EPON和ITU-T GPON。IEEE802.3av10G EPON标准的出现采用了时分复用(TMDA)的最新的高速PON协议。向10G EPON的转变有着至少两大因素。一个因素是家庭网络带宽的增加。使用IEEE802.11(协议)的无线网络和有线家庭网络的容量(带宽),都增加到了100Mbit/s,这是成本的减少、802.11n协议的广泛使用和新型个人电脑的1Gbit/s以太网接口部分导致的。另一个因素是用户对于按需供给的数字视频的不断需求。尽管目前的PON系统能够满足一些需求,但是发展到高清视频还是需要更高速的PON。
简单介绍完TDMA(时分复用)的PON协议,本文将描述10G EPON以及它与EPON(1G)的区别。
2. PON简介
如图1所示,一个PON系统在OLT(optical line terminal)端使用单光收发器,通过由分光器构成的光纤树/总线网络来服务用户端。10G EPON用时分多址的方式(TDMA)在OLT端对所有ONU广播下行数据和同步信息。ONU通过数据包地址信息(packet address information)提取出下行数据。在上行方向,OLT允许ONU在时间片内发送上行数据。
在ONU密集的发送上行数据时需要保护时间,这样传输的(数据)在OLT接收端就不会堆叠起来。需要注意的是,ONU在不发送数据时要关闭其激光发送,以防止OLT近处ONU产生的同步噪声,干扰OLT远处ONU发送的数据。为了能减少保护时机(效率要求),OLT使用一项协议来确定往返延时时间(round trip delay time)(OLT和ONU之间),ONU的上行发送时间也要考虑。//孤王翻不动啦 - -|||
3. IEEE802.3av 10G EPON //加油,努力翻下去!!!
10G EPON和EPON有一些协议是相同的。为了能让EPON和10G EPON在一个PON系统中协同工作,粗波分复用(CWDM,coarse wave division multiplexing)和时分复用(TDM,time division mulplexing)是必要的。同EPON一样,10G EPON依靠VoIP来传输电话业务和承载其他时分复用信号的电路仿真业务(circuit emulation service,CES)。
3.1 10G EPON物理层
10G EPON的下行速率为10Gbit/s。在上行方向支持1Gbit/s和10Gbit/s两种。64B/66B的嵌线编码(blockline code)被用于所有实际为10.3123Gbit/s的10G信号。EPON则使用8B/10B的嵌线编码来传输1G上行信号,其实际速率为1.25Gbit/s。
上行数据和下行数据都是通过一根PON光纤传输的,通过波分复用(WDM)来区分。上下行的不同波长见图2。由于在一个PON系统中有多个ONU,但只有一个OLT,因此对于ONU波长范围的选择应该尽量经济一些。由于激光技术改动量和相对市场容量的原因,1270nm和1310nm的激光比1500-1600nm的激光,更经济。
对于1Gbit/s上行,10G EPON和1G EPON都采用1310nm的波长。这使得OLT对所有的1Gbit/s信号都采用相同的接收器。10Gbit/s的上行信号使用不同的波长带,然而它与1Gbit/s的波长带重叠,所以1G和10G的ONU上行信号是时间共享的。
将10G EPON运用于PON网络中,在EPON系统中有如下好处:
l 能够使用户使用更经济的ONU服务
l 能够通过升级OLT将网络从1G EPON升级到10G EPON,若有必要才升级ONU。
l 在网络运行和服务的同时,能够升级网络。
Vuex中mapState的用法 import Vue from 'vue' import Vuex from 'vuex' import mutations from './mutations' import actions from './action' import getters from './getters' Vue.use(Vuex) const state = { userInfo: { phone: 111 }, //用户信息 orderList: [{ orderno: '1111' }], //订单列表 orderDetail: null, //订单产品详情 login: false, //是否登录 } export default new Vuex.Store({ state, getters, actions, mutations, }) computed: { ...mapState([ 'orderList', 'login' ]), }, mounted(){ console.log(typeof orderList); ==>undefind console.log(typeof this.orderList)==>object } mapState通过扩展运算符将store.state.orderList 映射this.
js数组方法
// [].map(function(value,index,array){}); // [].forEach(function(value,index,array){}); // [].some(function(value,index,array){}); // [].every(function(value,index,array){}); // 数组的every()/some()方法 // 有3个参数 数组元素(item)/索引(index)/数组本身(array) // some 对true 执行最小次数/every()对false 执行最小次数 // some()一真则真 // every()一假则假 var arr = [ 1, 2, 3, 4, 5, 6 ]; console.log(arr.some(function(item, index, array){ console.log(item, index, array); return index >2; })) js字符串方法
判断某个字符串对象是否包含特地字符 // str.indexOf(‘o’)>-1 // str1.split(‘,’) // str.includes(‘o’) // str.startsWith(‘g’) // str.endsWith(‘e’) // str.repeat(3)
let str ='20171027' console.log(str.startsWith('2016')); console.log(str.endsWith('1027')); console.log(str.repeat(-2.6));//Uncaught RangeError: Invalid count value console.log(str.repeat(0)); console.
这题调的我心态爆炸
大概就是可以把这条链分成若干联通块,联通块之间能连边就直接连
因为每条边只会被缩一次,所以复杂度是有保证的
#include <cstdio> #include <iostream> #include <algorithm> #include <map> #include <set> using namespace std; typedef long long ll; const int N=300010; int n,m,p,cnt,G[N],fa[N][25],dpt[N],fat[N],nxt[N],size[N]; struct Wrk{ int u,v,w,t; friend bool operator <(Wrk a,Wrk b){ return a.w<b.w; } }w[N]; struct iedge{ int t,nx; }E[N<<1]; inline void addedge(int x,int y){ E[++cnt].t=y; E[cnt].nx=G[x]; G[x]=cnt; E[++cnt].t=x; E[cnt].nx=G[y]; G[y]=cnt; } void dfs(int x,int f){ fa[x][0]=f; dpt[x]=dpt[f]+1; for(int i=1;i<=19;i++) fa[x][i]=fa[fa[x][i-1]][i-1]; for(int i=G[x];i;i=E[i].nx) if(E[i].t!=f) dfs(E[i].t,x); } pair<int,int> ud[N]; int cnt0,iG[N],inxt[N]; int Gfat(int x){ return fat[x]==x?
一、函数原型
snprintf(),为函数原型int snprintf(char *str, size_t size, const char *format, ...)。
二、函数介绍
将可变个参数(...)按照format格式化成字符串,然后将其复制到str中 (1) 如果格式化后的字符串长度 < size,则将此字符串全部复制到str中,并给其后添加一个字符串结束符('\0'); (2) 如果格式化后的字符串长度 >= size,则只将其中的(size-1)个字符复制到str中,并给其后添加一个字符串结束符('\0'),返回值为欲写入的字符串长度 。 三、运行实例 #include <stdio.h> int main () { char a[16]; size_t i; char path[216] = {0}; i = snprintf(a, 13, "%012d", 12345); // 第 1 种情况 printf("i = %lu, a = %s\n", i, a); // 输出:i = 12, a = 000000012345 i = snprintf(a, 9, "%012d", 12345); // 第 2 种情况 printf("
- (void)viewWillAppear:(BOOL)animated
{
UIInterfaceOrientation* orientation = UIInterfaceOrientationLandscapeLeft; // 屏幕方向参数
SEL selector = NSSelectorFromString(@"setOrientation:");
NSInvocation *invocation = [NSInvocation invocationWithMethodSignature:[UIDevice instanceMethodSignatureForSelector:selector]];
[invocation setSelector:selector];
[invocation setTarget:[UIDevice currentDevice]];
int val = orientation;
[invocation setArgument:&val atIndex:2];
[invocation invoke];
}
3db波束带宽是波束宽度的一个度量,而瑞利限是阵列分辨能力的统计性度量,因而这两个量对波束形成性能分析十分重要。 通过推导我们可以得到波束图的公式: 在u空间即将cos(θ)转换为u的公式为: 3dB带宽(半功率波束宽度,HPBW) 3dB波束宽度是波束宽度的一个度量,定义为|Bu (u)|^2=0.5的点计算该值对于N≥10时近似值为:
πNd/λ u=1.4 得到 Δu=0.891 λ/Nd 当N>30时,近似值为:
Δu=0.886 λ/Nd 这个间隔称为半功率波束宽度(HPBW)。 而瑞利限是零点到零点的波束宽度,这个量衡量了阵列分辨两个不同平面波的能力。 瑞利限
Δu=λ/Nd 它是波束主瓣的两个零点之间的距离。
——————————— Oracle —————————————————– Oracle 的for update行锁
键字: oracle 的for update行锁 SELECT…FOR UPDATE 语句的语法如下: SELECT … FOR UPDATE [OF column_list][WAIT n|NOWAIT][SKIP LOCKED]; 其中: OF 子句用于指定即将更新的列,即锁定行上的特定列。 WAIT 子句指定等待其他用户释放锁的秒数,防止无限期的等待。 “使用FOR UPDATE WAIT”子句的优点如下: 1防止无限期地等待被锁定的行; 2允许应用程序中对锁的等待时间进行更多的控制。 3对于交互式应用程序非常有用,因为这些用户不能等待不确定 4 若使用了skip locked,则可以越过锁定的行,不会报告由wait n 引发的‘资源忙’异常报告
示例1: create table t(a varchar2(20),b varchar2(20)); insert into t values(‘1’,’1’); insert into t values(‘2’,’2’); insert into t values(‘3’,’3’); insert into t values(‘4’,’4’); 现在执行如下操作: 在plsql develope中打开两个sql窗口, 在1窗口中运行sql select * from t where a=’1’ for update; 在2窗口中运行sql1 1.
这本书很早就看过了,当时大约是2011年,但是由于平时也用不到,所以就慢慢的忘记了,最近搞ELF的东西,重新拿出来翻一翻 1. readelf比objdump查看的elf要详细 2. readelf -d xx.o可以查看该文件索引的a.so, 但是a.so所引用的.so并不能看到,而ldd命令会递归查找用到的.SO
3. nm命令查看elf中的符号表,所谓符号表就是各种函数变量名和地址的对应关系
4.
replace和replaceAll是JAVA中常用的替换字符的方法,它们的区别是:
1)replace的参数是char和CharSequence,即可以支持字符的替换,也支持字符串的替换(CharSequence即字符串序列的意思,说白了也就是字符串);
2)replaceAll的参数是regex,即基于规则表达式的替换,比如,可以通过replaceAll("\\d", "*")把一个字符串所有的数字字符都换成星号;
相同点:都是全部替换,即把源字符串中的某一字符或字符串全部换成指定的字符或字符串,如果只想替换第一次出现的,可以使用replaceFirst(),这个方法也是基于规则表达式的替换,但与replaceAll()不同的是,只替换第一次出现的字符串;
另外,如果replaceAll()和replaceFirst()所用的参数据不是基于规则表达式的,则与replace()替换字符串的效果是一样的,即这两者也支持字符串的操作;
还有一点注意::执行了替换操作后,源字符串的内容是没有发生改变的。
举例如下:
String src = new String("ab43a2c43d"); System.out.println(src.replace("3","f"));=>ab4f2c4fd. System.out.println(src.replace('3','f'));=>ab4f2c4fd. System.out.println(src.replaceAll("\\d","f"));=>abffafcffd. System.out.println(src.replaceAll("a","f"));=>fb43fc23d. System.out.println(src.replaceFirst("\\d,"f"));=>abf32c43d System.out.println(src.replaceFirst("4","h"));=>abh32c43d. 如何将字符串中的"\"替换成"\\": String msgIn; String msgOut; msgOut=msgIn.replaceAll("\\\\","\\\\\\\\"); 原因:
'\'在java中是一个转义字符,所以需要用两个代表一个。例如System.out.println( "\\" ) ;只打印出一个"\"。但是'\'也是正则表达式中的转义字符(replaceAll 的参数就是正则表达式),需要用两个代表一个。所以:\\\\被java转换成\\,\\又被正则表达式转换成\。
同样
CODE: \\\\\\\\
Java: \\\\
Regex: \\
将字符串中的'/'替换成'\'的几种方式:
msgOut= msgIn.replaceAll("/", "\\\\"); msgOut= msgIn.replace("/", "\\"); msgOut= msgIn.replace('/', '\\'); 源链接:http://www.jb51.net/article/74638.htm
vue 多入口文件搭建 vue多页面搭建
红色为更改后的不同之处 vue 多入口文件搭建 在webpack.base.conf 中修改
var path = require('path') var config = require('../config') var utils = require('./utils') var projectRoot = path.resolve(__dirname,'../') var glob = require('glob'); var entries = getEntry('./src/module/*.js'); // 获得入口js文件 module.exports = { entry: entries, output: { path:config.build.assetsRoot, publicPath:process.env.NODE_ENV ==='production' ? config.build.assetsPublicPath :config.dev.assetsPublicPath, filename: '[name].js' }, resolve: { extensions: ['','.js', '.vue'], fallback: [path.join(__dirname,'../node_modules')], alias: { 'src':path.resolve(__dirname,'../src'), 'assets':path.resolve(__dirname,'../src/assets'), 'components':path.resolve(__dirname,'../src/components') } }, resolveLoader: { fallback: [path.join(__dirname,'../node_modules')] }, module: { loaders: [ { test: /\.
推荐 1. RESTful API 设计最佳实践 https://blog.philipphauer.de/...
项目资源的URL应该如何设计?用名词复数还是用名词单数?一个资源需要多少个URL?用哪种HTTP方法来创建一个新的资源?可选参数应该放在哪里?那些不涉及资源操作的URL呢?实现分页和版本控制的最好方法是什么?因为有太多的疑问,设计RESTful API变得很棘手。在这篇文章中,我们来看一下RESTful API设计,并给出一个最佳实践方案。
2. 基于HTML5和WebGL的三维可视立体动态流程图 https://segmentfault.com/a/11...
这两年的技术发展,大家想必都看在眼里,单用“爆发”二字,实在难以描述其中的惊天巨变。而回到网页3D这个话题上,我想,最大的驱动力,莫过于16年至今虚拟现实的迅速崛起,彻底推进了三维可视化技术的突飞猛进,而物联网发力,又开启了一扇通往新世界的大门。游戏界至今争论不休的Unity还是HTML5,依我看至少WebGL活的好好的,而插件技术么,则让我想起了一首悲伤的歌:dying in the sun…
3. WebUSB:一个网页是如何从你的手机中盗窃数据的(含PoC) http://www.freebuf.com/articl...
这篇文章探寻WebUSB的功能,以深入了解其工作原理,攻击方法及隐私问题。我们会解释访问设备所需的过程,以及浏览器是如何处理权限的,然后我们会讨论一些安全隐患,并演示一个网站如何使用WebUSB来建立ADB连接来入侵安卓手机。
其它 1. 组件化设计思维 – 从规范到工具的构建与探索 http://www.zcool.com.cn/artic...
结合近半年来的项目和实践经验,和大家一起探讨下组件化设计思维及一些思考,作者:斓青。阿里巴巴在中台战略的背景下,设计提效又再次推动着设计思维的变革。设计师们不仅仅需要出色地完成业务需求的设计,同时还需要思考设计的价值,也就是经常提到的最佳方案性价比。我们需要在设计的个性化表达和资源投入之间找到最佳的平衡点,在关注出色视觉表现的基础上,逐渐加强对项目协同及体验价值的关注,逐步形成新的设计思维模式。
2. 美团点评收银台前端可用性保障实践 http://www.infoq.com/cn/artic...
本文主要讨论的是前端可用性相关话题,以在美团点评移动端网页收银台的实践为例,讲解收银台前端是如何保障可用性的。
3. Lyft的TypeScript实践 http://www.infoq.com/cn/news/...
来自Lyft的前端工程师Mohsen Azimi介绍了Lyft向TypeScript转型的过程,说明JavaScript类型系统的重要性、为什么Lyft选择TypeScript以及他们的一些实践经验。
4. Vue 2.5 发布了 https://juejin.im/entry/59e44...
v2.5.0 发布啦,这个版本带来以下几点重要的变化:更好的 TypeScript 集成,更好的错误处理(errorCaptured 钩子),更好地支持单文件组件中的功能组件以及与环境无关的服务端渲染。
5. 前端魔法堂——异常不仅仅是try/catch https://segmentfault.com/a/11...
在学习Java时我们会被告知异常(Exception)和错误(Error)是不一样的,异常是不会导致进程终止从而可以被修复(try/catch),但错误将会导致进程终止因此不能被修复。当对于JavaScript而言,我们要面对的仅仅有异常(虽然异常类名为Error或含Error字样),异常的出现不会导致JavaScript引擎崩溃,最多就是让当前执行的任务终止而已。异常的出现最多就是让当前执行的任务终止,到底是什么意思呢?
这里要强调的问题是从文件中读进来的数据都是str类型的,但是我们往往排序的时候是按数的大小排序,所以将排序点进行修改,我们要排序的不是x[2],而是float(x[2]),
如果按str排序的话就是x:x[2]
va.sort(key=lambda x:float(x[2]),reverse=True) vac.sort(key=lambda x:float(x[3]),reverse=True)
// 指针数组:元素均为指针类型的数据,称为指针数组。
// 指针数组中的每一个元素都存放一个地址,即,每一个元素都相当于一个指针变量。
// 定义一个指针数组: int *p[4];
// 一个存放int类型的数组称为整型数组,那么存放指针的数组就叫指针数组
void main() { int i=2,j=3; int *p[2];//指针数组,存放指针的数组,p先跟[]结合,然后再跟*结合 p[0]=&i; p[1]=&j; printf("%d",sizeof(p)); // 首先定义一个指针数组p,它含有两个元素,每个元素都是一个指针变量,p[0]是指向 i 的指针,p[1]是指向 j 的指针。这两个指针都是int型指针。指针都是占用4个字节,所以sizeof(p)的大小为:4*2=8。因为指针数组含有两个指针。
最近学习springcloud搭建微服务,各个模块单元之间要互相进行调用。博主原有是通过httpclient的方式进行调用,但是不得不每次都需要暴露url进行调用,feign提供本地调用的方式,不需要暴露url,t提供类似本地调用实现,并且配合hystrix熔断策略进行使用。
1.maven添加包引用
<!--添加feign 提供服务调用--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-feign</artifactId> </dependency> <!-- ApacheHttpClient 实现这个类,替换httpclient线程池--> <dependency> <groupId>io.github.openfeign</groupId> <artifactId>feign-httpclient</artifactId> <version>9.5.0</version> </dependency> <!-- 添加熔断器,提供服务熔断操作 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-hystrix</artifactId> </dependency>2.配置文件需要填写eureka等相关配置文件 <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies>spring-cloud的版本有 Brixton.RELEASE和Dalston.RELEASE,现在创建的新项目应该是引用Dalston.RELEASE这个版本,该版本下默认hystrix是关闭的,所以需要在属性文件中进行打开,如果没有设置为true,在后面的调试过程会发现熔断机制不生效 #开启hystrix熔断机制 feign.hystrix.enabled=true feign简单调用,如以下实例,假如现在在同一个eureka下有一个项目A需要调用项目message-api项目,而message-api项目有一个接口为/example/hello,那么在A项目做以下配置:
1.建立远程调用客户端
@FeignClient(value = "message-api") public interface MessageApiFeignClient { @RequestMapping(value = "/example/hello",method = RequestMethod.GET) public String getMessage(@RequestParam("name") String name); } 本地方法直接调用该接口 @RequestMapping(value="/hello3",method = RequestMethod.GET) public void hello3(String name){ String result = messageApiFeignClient.getMessage("zhangsan"); System.out.println(result); } 运行起来会发现成功调用。
利用map和reduce编写一个str2float函数,把字符串'123.456'转换成浮点数123.456
? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 from functools import reduce def str2float(s): return reduce ( lambda x,y:x + int2dec(y), map (str2int,s.split( '.' ))) def char2num(s): return { '0' : 0 , '1' : 1 , '2' : 2 , '3' : 3 , '4' : 4 , '5' : 5 , '6' : 6 , '7' : 7 , '8' : 8 , '9' : 9 }[s] def str2int(s): return reduce ( lambda x,y:x * 10 + y, map (char2num,s)) def intLen(i): return len ( '%d' % i) def int2dec(i): return i / ( 10 * * intLen(i)) print (str2float( '123.
陪着你,仿佛面朝阳光, 不管走到哪里都是晴天。 在蝴蝶飞舞的百花丛中, 一朵一朵的鲜花因你而香。 一片云掉在我眼前, 我捏成你的形状, 一口一口的吃掉了忧愁。 我们手牵着手, 一步两步三步四步, 看着对方深情的眼眸, 心照不宣的许下了誓言。 ——畅宝宝的傻逼哥哥 在一维优化的近似法中,我们先假定目标函数的近似表达式,通常用低阶多项式。如果我们假定二阶多项式为 p(x)=a0+a1x+a2x2 其中 a0,a1,a2 是常数,那么我们就得到二次插值法。
令 p(xi)=a0+a1xi+a2x2i=f(xi)=fi 其中 i=1,2,3,[x1,x3] 包含 f(x) 的最小值 x∗ 。假设 fi 的值是已知的,那么通过同时求解三个等式可得 a0,a1,a2 ,推到出的多项式 p(x) 就是 f(x) 的近似。基于这样的场景,假设 p(x),f(x) 的图像如图1所示,显然, p(x) 的最小值 x¯ 很靠近 x∗ ,如果 f(x) 可以用二阶多项式表示,那么 x¯≈x∗ ,如果 f(x) 就是二次函数,那么 p(x) 就是 f(x) 的准确表示且 x¯=x∗ 。
p(x) 对 x 的一阶导为 p′(x)=a1+2a2x 如果 p′(x)=0 且 a2≠0 ,那么 p(x) 的最小值为 x¯=−a12a2 通过求解上面的等式组可得 a1a2=−(x22−x23)f1+(x23−x21)f2+(x21−x22)f3(x1−x2)(x1−x3)(x2−x3)=(x2−x3)f1+(x3−x1)f2+(x1−x2)f3(x1−x2)(x1−x3)(x2−x3) 所以 x¯=(x22−x23)f1+(x23−x21)f2+(x21−x22)f32[(x2−x3)f1+(x3−x1)f2+(x1−x2)f3] 图1 上面的过程是二次插值法的一次迭代。如果 f(x) 不能用二阶多项式表示,那么需要多执行几次这样的迭代。比较合适的策略是每次迭代的时候缩小不确定区间,可以舍弃 x1 或 x3 来实现该目的,然后用保留下来的两点以及 x¯ 进行新的迭代。
背景:
在某些电商促消活动中需要搞活动,对某些页面的访问量(QPS)往往会非常高。如果直接读数据库,肯定DB会承受不住。那比较常见的方案就是让大部分相同信息的请求都尽可能压在cache上来缓解DB的压力,从而尽可能去满足高并发访问的需求
在一次具体的促销过程中,当运营同学给广大的消费者推了一条消息:10点准时抢购一批远低于市场价而且数量有限制促销商品。(比如3K块抢一台苹果手机之类的)。那用户一收到这条短信就会在10点集中进入抢购页面,结果持续几分钟内很多用户就会进入会场,发现页面异常并且服务器疯狂报警。
报警内容:cache异常。
由于cache有问题,直接走DB,结果导致DB压力难以支撑,整个业务集群处于雪崩
现在问题来了,什么我们的cache会出问题?我们应该要如何避免cache出问题呢?
来看看cache出问题的原因
原因可能有这么几个:
1、缓存服务器自身有限流保持
缓存服务器数量 * 单机能够承受的qps > 用户最大的QPS 就会触发限流保护
针对这个原因:可以做横向扩容。加机器即可
2、用户访问过来cache服务器集中打到一台上面了。大流量并没有按预期的那样分摊到不同的cache机器上
导致出现单机热点。(热点数据)
针对这个原因:只要计算cache-hash算法不出问题,那基本上可以做到缓存的随机分布均匀的
3、缓存里面的value过大,导致虽然QPS不高,但网络流量(qps * 单个value的大小)还是过大,触发了cache机器单台机器的网络流量限流;
针对这个原因:需要把大value进行精简,部分可以放在本机内存而不需要走远程获取这种方式的。
这里面有一个问题需要引点关注
1、如何避免热点数据的问题
其实我们在做分库分表设计的时候也要考虑这个问题,比如某些大的商家可能会占到80%的数据量,如果用商家ID进行分库分表,必然会出现热点数据问题。这跟上面提到的原因2其实是一样的。有些热点key都跑到一台机器上面了。所以简单的对key进行hash还不行。
我们在做设计之前,要先考虑一下
a. 是否存在热点key ?
b. 如果存在热点key ,那如何避免这些热点key落在同一机器上面
2、要考虑缓存的包大小
如果缓存的包过大,会导致堵塞网络的风险。
解决这两个问题的一个比较好的办法:
1、针对cache中元素key的访问监控。一旦发现cache有qps限流或网络大小限流时,能够通过监控看到到底是哪个key并发访问量过大导致,或者哪些key返回的value大小较大,再结合cache散列算法,通过一定的规则动态修改key值去平摊到各个cache机器上去。
几种非线性激活函数介绍 1. 几种非线性激励函数(Activation Function) 神经网络中,正向计算时,激励函数对输入数据进行调整,反向梯度损失。梯度消失需要很多方式去进行规避。
1.1 Sigmoid函数 表达式为: y(x)=sigmoid(x)=11+e−x,y(x)in(0,1) y(x)′=y(x)(1−y(x)),y′in(−∞,14] 该函数将输入映射到(0,1)(能否取到0和1,取决于计算机的精度),由导数可看出, 最大值为0.25,也即在反向计算时,梯度损失非常明显,至少减少75%, 1.2 Tanh函数 表达式为: f(x)=tanh(x)=21+e−2x−1,f(x)in(−1,1)f′(x)=1−f(x)2,f′(x)in(0,1) 该函数将输入映射到(-1,1)(能否取到-1和1,取决于计算机的精度),由导数可看出,在反向计算时,梯度也会有所损失。倘若网络深度非常深,梯度消失(gradient vanishing)。 1.3 ReLU ( Rectified Linear Unit)函数 表达式为: 该函数将输入分两个段进行映射,当输入值小于0时,则将原值映射为0,若输入值大于0则按照原值传递,即,正向计算的时候,会损失特征大量,由导数可看出,在反向计算时,梯度没有损失。 (1) ReLU的优缺点 1) 优点1: Krizhevsky et al. 发现使用 ReLU 得到的SGD的收敛速度会比 sigmoid/tanh 快很多。有人说这是因为它是linear,而且梯度不会饱和
2) 优点2: 相比于 sigmoid/tanh需要计算指数等,计算复杂度高,ReLU 只需要一个阈值就可以得到激活值。
3) 缺点1:
ReLU在训练的时候很”脆弱”,一不小心有可能导致神经元”坏死”。 举个例子:由于ReLU在x<0时梯度为0,这样就导致负的梯度在这个ReLU被置零,而且这个神经元有可能再也不会被任何数据激活。如果这个情况发生了,那么这个神经元之后的梯度就永远是0了,也就是ReLU神经元坏死了,不再对任何数据有所响应。实际操作中,如果你的learning rate 很大,那么很有可能你网络中的40%的神经元都坏死了。 当然,如果你设置了一个合适的较小的learning rate,这个问题发生的情况其实也不会太频繁。
(2) ReLU正向截断负值,损失大量特征,为什么依然用它? 答:特征足够多,反向梯度无损失!
1.4 Leaky ReLU(Leaky Rectified Linear Unit) 表达式如下: Leaky ReLU. Leaky ReLUs 就是用来解决ReLU坏死的问题的。和ReLU不同,当x<0时,它的值不再是0,而是一个较小斜率(如0.01等)的函数。也就是说f(x)=1(x<0)(ax)+1(x>=0)(x),其中a是一个很小的常数。这样,既修正了数据分布,又保留了一些负轴的值,使得负轴信息不会全部丢失。关于Leaky ReLU 的效果,众说纷纭,没有清晰的定论。有些人做了实验发现 Leaky ReLU 表现的很好;有些实验则证明并不是这样。 -PReLU.
方法1:也是比较常用的一种方法,如下
<a href="javascript:history.back(-1)">返回上一页</a>
这句话,实现的原理始机械性的,只是返回到上一页的缓存数据,并不会刷新页面,一般项目中没什么特殊要求或者数据变动,我们用这一句就行了。
方法2:根据方法2在数据变动方面的弊端优化而来,如下
一般更改如下:
<input type="button" value="返回" οnclick="javascript:window.location='链接页面地址'"> (这里简单点,我就写在标签里了,当然写在脚本里比较好)
JSP页面其实也差不了多少,如下
<%String ref = request.getHeader("REFERER");%>
<input type="button" id="backBtn" name="button" class="button_return" value="返回"
οnclick="javascript:window.location='<%=ref%>'">
转自: 出处
在OSGI的中开发bundle,在Karaf容器中加载bundle后,往往需要获取bundle处理的中间信息,用于调试、故障定位等。而org.apache.karaf.shell.console提供一种可以以控制台命令的方式介入bundle。提供一种在运行时,以命令触发原代码中的逻辑功能。
具体开发,与开发bundle过程一样,有几点需要注意:
1、@Command @Option @Argument 的使用,父类OsgiCommandSupport和重载方法doExecute
2、pom中的build的plugin需要增加maven-scr-plugin
3、pom的build的maven-bundle-plugin显示Import org.apache.karaf.shell.*,
示例:
package com.zte.sdn.oscp.yang.adapter; import org.apache.karaf.shell.commands.Argument; import org.apache.karaf.shell.commands.Command; import org.apache.karaf.shell.commands.Option; import org.apache.karaf.shell.console.OsgiCommandSupport; /** * Created by sunquan on 2017/10/20. */ @Command(scope = "livio", name = "example", description = "livio exmaple command") public class ExampleCommand extends OsgiCommandSupport { @Option(name = "-n", aliases = {"--Name"}, description = "Show the information of specific shard module", required = false, multiValued = false) private String shardModuleName = "
神经网络的架构(architecture)指网络的整体结构。大多数神经网络被组织成称为层的单元组,然后将这些层布置成链式结构,其中每一层都是前一层的函数。在这种结构中,第一层由下式给出:
第二层:
第三层,以此类推!
可以看出,每一层的主体都是线性模型。线性模型,通过矩阵乘法将特征映射到输出,顾名思义,仅能表示线性函数。它具有易于训练的优点,因为当使用线性模型时,许多损失函数会导出凸优化问题。不幸的是,我们经常希望我们的系统学习非线性函数。
乍一看,我们可能认为学习非线性函数需要为我们想要学习的那种非线性专门设计一类模型族。幸运的是,具有隐藏层的前馈网络提供了一种万能近似框架。
具体来说, 万能近似定理(universal approximation theorem)(Hornik et al., 1989;Cybenko, 1989) 表明,一个前馈神经网络如果具有线性输出层和至少一层具有任何一种‘‘挤压’’ 性质的激活函数(例如logistic sigmoid激活函数)的隐藏层,只要给予网络足够数量的隐藏单元,它可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的Borel 可测函数。
万能近似定理意味着无论我们试图学习什么函数,我们知道一个大的MLP 一定能够表示这个函数。然而,我们不能保证训练算法能够学得这个函数。即使MLP能够表示该函数,学习也可能因两个不同的原因而失败。
用于训练的优化算法可能找不到用于期望函数的参数值。训练算法可能由于过拟合而选择了错误的函数。 根据‘‘没有免费的午餐’’ 定理,说明了没有普遍优越的机器学习算法。前馈网络提供了表示函数的万能系统,在这种意义上,给定一个函数,存在一个前馈网络能够近似该函数。但不存在万能的过程既能够验证训练集上的特殊样本,又能够选择一个函数来扩展到训练集上没有的点。
总之,具有单层的前馈网络足以表示任何函数,但是网络层可能大得不可实现,并且可能无法正确地学习和泛化。在很多情况下,使用更深的模型能够减少表示期望函数所需的单元的数量,并且可以减少泛化误差。
今天来说一下Hadoop生态系统中的Zookeeper,HBase,Hive,说到Zookeeper简单来说其实就是Hadoop分布式框架的一个协调服务,也就是分布式应用都需要一个主控协调器或者控制器来管理物理分布的子进程.那再说的明白点就是:Zookeeper在hadoop生态系统中的集群担任着非常重要的责任.集群中的资源调配或者是服务的切换,都得需要他去管理.所以说在Hadoop生态系统中Hadoop是一头大象,而Zookeeper却是一个动物园的管理员.至于图这里就不展示了.百度一搜就有的.对了.告诉大家一个秘诀,学习Hadoop生态系统的前期,自己从网上下载一张这样的图解.特别有用.####特别推荐啊#### 好了,言归正传啊.这个Zookeeper他包含一个简单的原语集,分布式应用可以通过它,来实现一些同步服务,配置的服务和命名服务等.我们都知道Hadoop2.0时代迎来了高可用.那么Zookeeper怎么才能做到高可用那?那么他的机制里边有一个leader和一些Follower当这个leader挂掉的时候这些Follower就会通过特殊的机制选出一个leader来.那么究竟这个leader和Follower到底是什么那,他们到底是干什么的那?我们可以这样倒着想.我们刚才说Zookeeper是一个协调机制,那么他既然要去维持这个生态系统,那么他就要主控HDFS中的nameNode因为控制住了nameNode就真正的做到了协调者的这个角色.所以他要保证整个集群,要有一个活跃的nameNode这样才能够存储到dataNode上信息.才能够完成MapReduce和yarn机制.(服务).那么这个leader中就有这样一个机制,(他是监控整个集群的,如果说一个集群七台机器的话,我就会有两台搭载nameNode两台搭载resourceManager然后如果说其中一台的nameNode挂掉了,然后这个Leader和Follower就会有一个具体的选举机制,然后再选举另外一台nameNode的机器,以保证正常的数据支持.)而Zookeeper中也有一个叫qjournal的机制目的在于(我们都知道在nameNode上有一个叫editsLog这个日志文件是要和nameNode的镜像文件去合并,从而达到更新nameNode.然后这个editsLog就存在于在这个qjournal这样的每一个edits文件就叫做一个qjournalnode,而zookeeper集群中也有一个叫ZKFC的机制目的就在于一个nameNode为active一个为Standby当active挂掉的时候ZKFC会告诉Zookeeper 并且执行一些Kill active服务的机制 从而达到Standby上任的这样一个目的) 我们刚才说过Zookeeper是一个搭建集群的服务,因为他是一个协调框架.所以在搭建集群的时候需要给他配置两个配置文件(具体是什么,自己去上百度搜索,那速度嗖嗖的) 继续来说一下HBase首先他是一个分布式,版本化,面向列的数据库.构建在Hadoop上和Zookeeper上.可以用HBase技术在廉价的PC Server上搭建起大规模的结构化存储集群.HBase利用Hadoop中的HDFS作为其文件系统用Zookeeper作为协调工具.用Hadoop中的MapReduce作为其的计算系统来为他处理海量数据.HBase中的主键是用来检索记录的主键,访问HBase table中的行,而HBase中的列族,一个列族可以包含多个列,列中的数据都是以二进制的形式存在的,没有数据类型.列也称为:列名和列的标识符,行有一个叫行标的标识符.这样就可以把一条数据根据列来显示出来.'+'像十字架一样相交的才是数据.启动HBase:HBase如果启动一个单节点的是不需要任何配置文件的这里我们只说单节点的配置文件,后序会引出来集群.先要进入/bin文件,然后先启动服务, ./start-hbase.sh 之后在启动客户端, ./hbase shell这样一执行这样一个面向列的数据库就启动了.对了,忘了声明一点,HBase是按住ctrl加backspace才是从后往前删除,如果单单是按住backspace的话是从前往后删除的.归根到底其实HBase就是一个存放数据的载体,就比如Windows用的NTFS文件系统,怎么才能读到其中所有的数据那,那么我就会用一个数据库去访问本地的资源或者连接网络通过网络让外部的计算机可以通过服务器中的数据库来访问我的本地资源,那么同样别的计算机也可以通过网络流来向我传输一些文件.这样整体的一个数据访问系统的目的就达到了.那么同样的道理,我在Hadoop生态系统上,用HBase数据库的目的也是在于我Hadoop可以获取数据,然后再交给MapReduce去计算得到用户想要的数据.以上均为个人理解,如果有什么差别之处,望指明. 最后来说一下Hive:Hive是建立在Hadoop上的数据仓库基础架构,它提供了一系列的工具,可以用来进行提取转化加载这是一种可以存储 查询和分析存储在Hadoop中的大规模数据的机制.Hive定义了简单的类SQL语言,称为QL,同时这个语言也允许熟悉MapReduce处理过程中无法mapper和reducer无法完成的复杂的分析工作.Hive的系统架构是:用户接口:包括Java中连接数据库的JDBC/ODBC,WebUI,CLI.元数据的存储一般放在MySql或者derby数据库中(derby很迷你,但是漏洞很多比如他是一个单例的他是用Java编写的一个数据库存储系统),解释器,编译器,优化器,执行器,Hadoop:利用HDFS来进行存储,利用MapReduce来计算海量数据.总结一下,Hive主要是在MapReduce处理不了的时候派上用场.因为什么东西不是万能的,总会有弊端的,所以说,在MapReduce无法完成的任务的之后,还有Hive去为你排忧艰难.这是最基本的用处.还有一个用处就是我们在文上也说过了,它是一个数据仓库,也就是说用来存储数据的,说到存储数据了,我们就会想到数据库,但是他和数据库最根本的区别就是一点:他是把数据存放在HDFS上的,但是数据库是一个自我的数据存储系统,所以说两者不可混淆,当然了,你只需要记住Hive是把数据存放在HDFS上的但是他还能够帮助MapReduce来计算数据,所以他要 依托着Hadoop的.而HBase却是一个存放数据的载体,而他的功能是写入是数据和读出来数据,这是他俩的根本的区别.OK The End Today.我刚学习的时候也总是理解不清楚,但是有贵人指路,终于可以在这里给你们写文档了.这是多么艰难的一件事情啊.所以说遇到问题要积极的面对而且自己心里要知道,这是在学习的时候最应该遇到的,该踩的坑都踩了,那么你就牛逼了.Be strong , Believe in who you are;
Swing是一个用于开发Java应用程序用户界面的开发工具包。 以抽象窗口工具包(AWT)为基础使跨平台应用程序可以使用任何可插拔的外观风格。Swing开发人员只用很少的代码就可以利用Swing丰富、灵活的功能和模块化组件来创建优雅的用户界面。 工具包中所有的包都是以swing作为名称 1. intellij idea 创建maven项目
2.目录为
1. hello world 代码
import javax.swing.*; import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import java.awt.event.InputEvent; public class helloworld { //创建窗体,JFrame JFrame f = new JFrame("测试"); //定义一个按钮,并为之指定图标 //ImageIcon(Image image) //根据图像对象创建一个 ImageIcon。 Icon是接口,ImageIcon实现了该接口,多态的体现 //定义一个单选按钮,并为之指定图标 Icon okIcon = new ImageIcon("ico/ok.png"); JButton ok = new JButton("确认", okIcon); //定义一个单选按钮,出事处于选中状态 //JradioButton 实现一个单选按钮,此按钮项可被选择或取消选择,并可为用户显示其状态。 //JRadioButton(String text, boolean selected) //创建一个具有指定文本和选择状态的单选按钮。 JRadioButton male = new JRadioButton("男", true); JRadioButton female = new JRadioButton("女", false); ButtonGroup bg = new ButtonGroup(); //定义一个复选框,出事状态处于没有选中状态 JCheckBox married = new JCheckBox("