浮点数 C# 的浮点数类型,float、double ,当我们定义一个浮点数可以:
可以使用var 关键字,可以做类型推断
定义float类型,数字末尾需要加上 F或者是f
//定义一个double类型 double a1=1.1; var a2 = 1.1; Console.WriteLine(a2.GetType()); //定义一个float类型,数字末尾需要加上 F或者是f float b1=1.1f; var b2 =1.1f; Console.WriteLine(b1.GetType()); 浮点数的计算会有误差:
//浮点数的比较,出现了差错: double a = 1.3; double b = 1.1; double c = 0.2; if (a - b == c) { Console.WriteLine("ok"); } else { Console.WriteLine((a - b).ToString("R")); Console.WriteLine("no"); } 结果如下:
decimal 使用decimal来定义,数字末尾需要加上 M 或者 m
var c1 = 1.1m; decimal c2 = 1.1M; Console.WriteLine(c1.GetType()); 使用decimal计算:
目录 【模板】排序题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 提示 解题思路Code运行结果 【模板】排序 题目描述 将读入的 N N N 个数从小到大排序后输出。
输入格式 第一行为一个正整数 N N N。
第二行包含 N N N 个空格隔开的正整数 a i a_i ai,为你需要进行排序的数。
输出格式 将给定的 N N N 个数从小到大输出,数之间空格隔开,行末换行且无空格。
样例 #1 样例输入 #1 5 4 2 4 5 1 样例输出 #1 1 2 4 4 5 提示 对于 20 % 20\% 20% 的数据,有 1 ≤ N ≤ 1 0 3 1 \leq N \leq 10^3 1≤N≤103;
运行环境
Win11
vs2022
Abp vNext 7.0.0
初始化数据库成功后,用swagger打开是正常的,但是浏览站点异常
An unhandled exception occurred while processing the request. AbpException: Could not find the bundle file '/libs/abp/core/abp.css' for the bundle 'LeptonXLite.Global'!
Volo.Abp.AspNetCore.Mvc.UI.Bundling.TagHelpers.AbpTagHelperResourceService.ProcessAsync(ViewContext viewContext, TagHelper tagHelper, TagHelperContext context, TagHelperOutput output, List<BundleTagHelperItem> bundleItems, string bundleName)
异常截图
发现wwwroot/libs文件夹是空的,并且npm引用项也有问题
右键wwwroot文件夹→在终端中打开,输入一下命令
abp install-libs 会重新进行安装libs
安装完成后编译,重新运行,即可正常访问。
上一篇:Abp vNext(三)数据迁移
下一篇:
文章目录 MySQL 5.7.35下载安装使用_忘记密码_远程授权MySQL下载地址mysql安装点击安装,最好以管理员身份运行选择自定义安装选择64位勾选启动自定义产品执行点击同意点击下一步点击执行下一步配置数据库端口号设置登录密码,如果密码忘记,下面又解决方案点击下一步点击完成mysql5.7.35安装完成 配置变量打开搜索服务,查看mysql的bin目录查看服务的路径,复制找到安装的bin目录配置path环境变量 测试登录mysql数据库及报错解决1. 报错Can''t connect to MySQL server on localhost (10061)解决方法2 报错拒绝用户登录-密码可能忘记[Access denied for user]2.1 打开 MySQL 目录下的 my.ini 文件,在文件的最后添加一行 “skip-grant-tables”,保存并关闭文件。编辑保存重启 MySQL 服务重新执行mysql登录错误的原因是 5.7版本下的mysql数据库下已经没有password这个字段了,password字段改成了authentication_string将my.ini文件进行还原关闭之前的cmd窗口,重新打开一个,在命令行中输入 “mysql -uroot -prootroot”,成功登录数据库 查看mysql端口号:工具测试连接,连接成功 查看mysql版本删除mysql服务启动与停止mysql创建数据库远程授权命令未安装服务的情况下,如何进行启动,只做参考 MySQL 5.7.35下载安装使用_忘记密码_远程授权 MySQL下载地址 下面提供几个可用的下载地址:
Mysql官网下载地址:https://downloads.mysql.com/archives/installer/ 华为MySQL镜像站:https://mirrors.huaweicloud.com/mysql/Downloads/ mysql安装 点击安装,最好以管理员身份运行 选择自定义安装 选择64位 勾选启动自定义产品 执行 点击同意 点击下一步 点击执行 下一步 配置数据库端口号 设置登录密码,如果密码忘记,下面又解决方案 点击下一步 点击完成 mysql5.7.35安装完成 配置变量 打开搜索服务,查看mysql的bin目录 查看服务的路径,复制 找到安装的bin目录 配置path环境变量 测试登录mysql数据库及报错解决 1. 报错Can’'t connect to MySQL server on localhost (10061)解决方法 PS C:\Users\Administrator> mysql -uroot -p Enter password: ********* ERROR 2003 (HY000): Can't connect to MySQL server on 'localhost' (10061) PS C:\Users\Administrator> mysqld --remove mysql Service successfully removed.
文章目录 1. 安装命令2. 测试 1. 安装命令 # 下载 curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py # 安装 python3 get-pip.py 2. 测试 pip -h
ubuntu环境搭建专栏🔗点击跳转
Ubuntu系统环境搭建(十)——Ubuntu安装最新版Docker和Docker Compose 文章目录 Ubuntu系统环境搭建(十)——Ubuntu安装最新版Docker和Docker Compose1.添加Docker库1.1 安装必要的证书并允许 apt 包管理器使用以下命令通过 HTTPS 使用存储库1.2 运行下列命令添加 Docker 的官方 GPG 密钥1.3 添加 Docker 官方库1.4 更新源列表 2.安装 Docker2.1 安装最新版2.2 验证docker是否运行2.3 设置docker开机自启动 3.验证3.1 查看docker版本3.2 测试 Docker3.2 查看docker compose版本 本篇文章对应之前写的Ubuntu系统环境搭建(三)——Ubuntu安装Docker,是对这篇文章的纠正,这一篇是最新版的搭建手册,请以这一篇为准!
1.添加Docker库 1.1 安装必要的证书并允许 apt 包管理器使用以下命令通过 HTTPS 使用存储库 sudo apt install apt-transport-https ca-certificates curl software-properties-common gnupg lsb-release 1.2 运行下列命令添加 Docker 的官方 GPG 密钥 curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg 1.3 添加 Docker 官方库 echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.
Gradle Distributions
从上面的网站下载对应的版本
放到这个目录下
一、前言 今天刷到Jet Brains官方发布了2023 开发者生态系统现状,这个相信大家都不陌生,我们的开发工具IDEA就是它旗下的。
分析的蛮不错的,今天整理一下,和大家一起分享。
有想法大家可以一起交流一下哈!
有兴趣的可以去官网看完整版:
2023 开发者生态系统现状
二、介绍 这份报告汇集了来自全球 26,348 位开发者的洞察。开发者的世界广阔而多样,是无尽探索和学习的神奇领域。通过这样的年度研究活动,我们的目标是探索这个迷人的世界,揭示有关开发者及其技术的宝贵洞察,然后与社区分享这些信息。
《开发者生态系统现状报告》涵盖广泛的主题,包括编程语言、工具和技术,以及受众特征和有趣的事实。我们也将了解开发者独特的生活方式,揭示他们的热情和兴趣。
今年,我们还将调查范围扩展到 AI。我们研究了开发者对 AI 的看法,他们的顾虑、AI 助手的常用功能,以及 AI 赋能工具的当前采用情况。
三、编程语言排名 1. JavaScript 的受欢迎程度略有下降 过去三年,排名前三的语言保持不变,但 JavaScript 的份额一直在下降。可以合理假设,它将继续小幅下降,因为 JavaScript 程序员表示学习另一种语言的可能性比其他程序员更高。
2. 对 Rust 的信任:成长的故事 Rust 是今年唯一创下受欢迎程度新纪录的常用语言。Rust 立志以其严格的安全性和内存所有权机制取代 C++,最初可能会击败 Go,因为六分之一的 Go 用户在考虑采用 Rust。Rust 与 Scala 一样,是最少程序员想要迁出的语言。
四、软件开发者薪资趋势 按主要语言显示的高薪员工比例
高薪员工是指薪资在所在国家或地区处于前四分之一的员工。
2023 年,Scala、Go 和 Kotlin 开发者位列薪酬最高的三大类别。雇主们正在认识到能够驾驭这些语言复杂性的专家的价值,从而催生了 Scala、Go 和 Kotlin 开发者作为最高收入者的竞争格局。
边缘OB一下
说一下前三的语言:
Scala:一般是搞大数据的开发语言。
Go:一般解决Java对三高场景处理瓶颈的。
Kotlin:一般是Android或服务器端应用程序开发语言。
不过这些都是大厂用的比较多,需要你有好的学历支撑,或者是技术专家走内推。这些大部分统计的都是外国人,和国内应该有查些许差异,大家参考一下就好了。
一般的大多数还是搞好Java或者JS/TS就行了,能够养家糊口,在往上冲!
五、过去 3 年科技行业的性别分布 2021 年以来,调查数据一直显示女性开发者的比例没有改善。只有 5% 的开发者是女性,表明行业存在巨大的性别差距。为了确保所有人的平等机会和代表性,我们作为一个社区应该提出新的方式来解决性别多元化问题。
使用Nginx代理HTTPS请求并使用自签名证书,可以按照以下步骤进行配置:
生成自签名证书:
打开终端或命令提示符,并导航到Nginx配置文件所在的目录。运行以下命令生成自签名证书和私钥: openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout ssl.key -out ssl.crt 根据提示输入证书的相关信息,例如国家、省份、城市、组织等。 配置Nginx代理:
打开Nginx配置文件(通常为nginx.conf)。在http块中添加一个新的server块,用于代理HTTPS请求。示例配置如下: nginx`server { listen 80; server_name example.com; location / { proxy_pass http://backend_server_address; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } } server { listen 443 ssl; server_name example.com; ssl_certificate ssl.crt; ssl_certificate_key ssl.key; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers 'HIGH:!aNULL:!MD5:!kEDH'; ssl_session_cache shared:SSL:10m; ssl_session_timeout 10m; location / { proxy_pass http://backend_server_address; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } }` 将example.
在考虑迁移到云计算时,网络安全已经成为一个关键因素。毫无疑问,企业希望通过网络浏览器或移动应用为员工、合作伙伴和客户提供一致的数据和应用访问权限,以保持竞争力。
网络攻击的性质和重要性正变得越来越复杂,并造成严重的财务和声誉损失。黑客使用人工智能和机器学习来暴露和利用漏洞。社交媒体诈骗,包括逼真的深度伪造视频或音频消息,更难以检测。
安全仍然是供应商及其客户之间的共同责任。企业必须尽职尽责,为其敏感数据创建和维护一个安全的环境,并承担责任。
地缘政治不稳定、快速成熟和新兴技术、人才短缺以及股东和监管预期等威胁可能会增加网络风险。但更令人担忧的是,最重要的数据资产正处于危险之中。
在考虑迁移到云计算时,网络安全已经成为一个关键因素。毫无疑问,企业希望通过网络浏览器或移动应用为员工、合作伙伴和客户提供一致的数据和应用访问权限,以保持竞争力。但他们也必须保护存储在多个位置的更大范围的数字资产,这些资产由全球员工通过不同的渠道和设备访问,并在云中运行不同的工作负载。
高防IP
DDoS(分布式拒绝服务攻击)是一种网络攻击旨在通过向目标服务器发送大量请求来使其超出承载能力,从而使其无法正常运行。这种攻击会导致网站宕机、网络延迟增加,甚至使整个网络瘫痪。因此,保护网站和网络免受DDoS攻击成为各种规模企业的重要任务。
为了应对这种威胁,高防IP应运而生。高防IP是一种专门用于抵御DDoS攻击的IP资源,其具有高带宽、高防御能力的特点,能够有效地抵御各种规模和类型的DDoS攻击。
高防SCDN
SCDN(安全内容分发网络)SCDN是一种专门用于抵御DDoS攻击的网络安全服务,它采用了先进的技术和策略来保护网站和网络免受DDoS攻击的影响,保障网络安全与稳定。
高防SCDN是企业保护网络安全的重要工具,它能够帮助企业有效抵御各种规模和类型的DDoS攻击,确保网络安全稳定运行。选择高防SCDN作为网络安全防护手段,对于企业来说是非常重要和必要的。随着网络安全威胁的不断增加,高防SCDN的需求将会不断增长,成为企业网络安全防护的重要一环。
安全性、访问性和敏捷性的平衡
预计到2026年,全球ERP软件市场预计将达到784亿美元。这意味着大多数企业可能会将ERP作为有效的中枢神经系统来实施,这可能成为不法分子的诱人目标。
作为回应,云ERP供应商在保护其系统的能力和专家方面投入了大量资金。然后,他们的客户可以放心地依赖网络安全服务和技术,包括灾难恢复、业务连续性、物理安全、数据加密、修补、身份验证和访问管理。此外,供应商必须证明其能力符合多项法规,并通过全年进行的审计。
然而,安全仍然是供应商及其客户之间的共同责任。企业必须尽职尽责,为其敏感数据创建和维护一个安全的环境,并承担责任。
网络安全的关键品质
在平衡安全性、访问和灵活性方面的业务成功取决于供应商和客户之间,对所需云环境中应包含的六个关键品质的相互理解。
业务弹性
当数据服务器位于本地时,自然灾害、地震、洪水、火灾和大范围的网络中断可能会导致更严重的数据丢失和业务中断。但云提供了更多的选择,可以通过改进灾难恢复管理和业务连续性来减轻这些风险。例如,云在多个数据中心之间分发数据,因此即使其中一个数据中心宕机,数据也会自动传输到另一个。
物理安全
内部部署系统的物理安全可能是一项费力且昂贵的工作。然而,在云环境中,数据中心访问受到大规模保护,并受到持续监控和测试。因此,数据和应用符合利用行业和最佳实践措施的高物理安全标准。
全面的数据加密
在整个本地IT环境中实施加密可能具有挑战性。然而,通过提供创新的加密功能,云提供商可以大大减少数据泄露的影响。关键技术包括广泛的数据加密、安全智能、密钥管理和安全访问控制,提供分层安全方法。
值得信赖的网络安全专业知识
云ERP提供商的业务建立在安全专业团队的创建和发展以及对安全研究、创新和保护的持续资助之上。通过这些努力,企业可以利用技术人才来优化云投资的价值,而在当前的劳动力市场上,技术人才非常稀缺。
自动安全监控和优先级排序
建立了网络中心的云ERP提供商可以通过集中安全事件、事件管理系统(SIEM)收集的海量信息,更好地预防、检测和防御安全威胁。此外,他们的评分系统可以清楚地了解哪些数据易受攻击,应该进行补救或缓解。咨询服务用于监控国家漏洞数据库并持续跟踪新出现的威胁。
集中修补、测试和审计
本地系统中的补丁管理通常会使企业使用过时的软件,并且极易受到安全漏洞的攻击。相比之下,云环境非常有效,因为提供商使用专门构建的工具、自动化和手动渗透测试、软件安全审查和外部审计进行补丁管理。此外,云ERP提供商提供集中的补丁和安全管理机制,有时不需要额外的客户干预。
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 搞笑视频模块2.3 视频收藏模块2.4 视频评分模块2.5 视频交易模块2.6 视频好友模块 三、系统设计3.1 用例设计3.2 数据库设计3.2.1 搞笑视频表3.2.2 视频收藏表3.2.3 视频评分表3.2.4 视频交易表 四、系统展示五、核心代码5.1 查询搞笑视频5.2 加购搞笑视频5.3 搞笑视频打分5.4 搞笑视频收藏5.5 添加好友 六、免责说明 一、摘要 1.1 项目介绍 基于JAVA+Vue+SpringBoot+MySQL的快乐贩卖馆管理系统,包含了视频模块、视频收藏模块、视频打分模块、视频交友模块、视频购物车模块和视频订单模块,还包含系统自带的用户管理、部门管理、角色管理、菜单管理、日志管理、数据字典管理、文件管理、图表展示等基础模块,快乐贩卖馆管理系统基于角色的访问控制,给视频管理员、普通用户使用,可将权限精确到按钮级别,您可以自定义角色并分配权限,系统适合设计精确的权限约束需求。
1.2 项目录屏 二、功能模块 随着互联网行业各种业务的兴起和发展,这一领域的市场竞争也日趋激烈。从视频网站的角度来看,主要的视频网站并未像许多人认为的那样在激烈的市场竞争中真正获利。相反,连续的损失是视频网站面临的最困难的问题。快乐贩卖馆系统是一套交易搞笑视频的系统,用户可以在其中自由交易搞笑视频。
快乐贩卖馆系统基于Java语言开发,采用前后端分离的技术架构,前端采用Vue.js,后端采用SpringBoot框架,采用MySQL数据库。
快乐贩卖馆系统的功能性需求主要包含数据中心模块、搞笑视频模块、视频收藏模块、视频评价模块、视频交易模块、视频好友模块这六大模块,系统是基于浏览器运行的web管理后端,其中各个模块详细说明如下。
2.1 数据中心模块 数据中心模块包含了快乐贩卖馆系统的系统基础配置,如登录用户的管理、运营公司组织架构的管理、用户菜单权限的管理、系统日志的管理、公用文件云盘的管理。
其中登录用户管理模块,由管理员负责运维工作,管理员可以对登录用户进行增加、删除、修改、查询操作。
组织架构,指的是高校的组织架构,该模块适用于管理这些组织架构的部门层级和教师的部门归属情况。
用户菜单权限管理模块,用于管理不同权限的用户,拥有哪些具体的菜单权限。
系统日志的管理,用于维护用户登入系统的记录,方便定位追踪用户的操作情况。
公用云盘管理模块,用于统一化维护快乐贩卖馆系统中的图片,如合同签订文件、合同照片等等。
2.2 搞笑视频模块 搞笑视频是快乐贩卖馆系统的核心,需要建立搞笑视频模块对其进行管理,搞笑视频的数据包括视频名称、视频介绍、视频价格、文件、排序值、备注、创建人、创建时间、更新人、更新时间,用户可以发布新的搞笑视频,管理员可以对用户发布的搞笑视频进行删除操作。
2.3 视频收藏模块 如果用户对某个视频非常满意,可以对其进行收藏,以便于后续快捷浏览,视频收藏的字段包括视频ID、视频名称、收藏时间、备注、创建人、创建时间、更新人、更新时间,用户可以对搞笑视频进行收藏操作,管理员可以查询用户的收藏数据。
2.4 视频评分模块 在快乐贩卖馆系统中,用户可以对搞笑视频进行评价,以此达到交互的效果,视频评分的数据包括视频ID、视频名称、视频文件、评分数值、创建人、创建时间、更新人、更新时间,用户可以对搞笑视频进行评分操作,管理员可以查询用户的评分数据。
2.5 视频交易模块 用户可以购买搞笑视频,购买需要消耗余额,余额来源自上传的搞笑视频,视频交易字段包括视频ID、视频名称、视频文件、付款状态、创建人、创建时间、更新人、更新时间,用户可以对搞笑视频进行下单、付款操作,管理员可以查询用户的交易数据。
2.6 视频好友模块 如果用户对视频的发布者很感兴趣,可以添加单向好友,方便留档,视频好友的字段包括所属人、好友ID、好友昵称、好友手机、创建人、创建时间、更新人、更新时间,用户可以添加搞笑视频的创作者,管理员可以查询用户添加的好友数据。
三、系统设计 3.1 用例设计 3.2 数据库设计 3.2.1 搞笑视频表 3.2.2 视频收藏表 3.2.3 视频评分表 3.
当开启Clash后,本机网络会被代理,此时可以在 设置-网络-代理 中看到:
git push 失败的原因就是本机开启了代理,而git没有设置代理,导致443端口转发不过去,此时只需要设置以下git的代理即可解决
git config --global http.proxy http://127.0.0.1:7890 git config --global https.proxy http://127.0.0.1:7890 取消和查看代理
取消代理 git config --global --unset http.proxy git config --global --unset https.proxy 查看代理 git config --global --get http.proxy git config --global --get https.proxy git config --list
模型一直向上运动的正常效果:
问题场景:
1.new mars3d.graphic.ModelPrimitive({使用addDynamicPosition(设置并添加动画轨迹位置,按“指定时间”运动到达“指定位置”时发现,如果是同一个点位不同高度值的y轴竖直向上方向的运动。
指定pitch:270偏转角度的时候,会出现模型的角度值异常的问题。
错误代码:
相关api文档:
ModelPrimitive - V3.7.0 - Mars3D API文档
相关示例演示链接:
功能示例(原生JS版) | Mars3D三维可视化平台 | 合肥火星科技有限公司
复现代码:
function addDemoGraphics() {
for (var i = 0; i < 1; i++) {
var graphic = new mars3d.graphic.ModelPrimitive({
// forwardExtrapolationType: Cesium.ExtrapolationType.HOLD,
style: {
url: "//data.mars3d.cn/gltf/mars/qiche.gltf",
scale: 0.5,
minimumPixelSize: 20,
pitch: 270,
// 高亮时的样式(默认为鼠标移入,也可以指定type:'click'单击高亮),构造后也可以openHighlight、closeHighlight方法来手动调用
highlight: {
type: mars3d.EventType.click,
silhouette: true,
silhouetteColor: "#ff0000",
silhouetteSize: 4
},
label: {
// 不需要文字时,去掉label配置即可
text: "
HTTPS(全称为Hyper Text Transfer Protocol Secure)是一种在计算机网络上进行安全通信的协议,它通过SSL/TLS证书对传输数据进行加密,确保了用户与服务器之间信息交换的私密性和完整性。
获取SSL/TLS证书 选择证书类型:有免费和付费两种类型的SSL/TLS证书可供选择,如JoySSL提供的免费证书以及付费商业证书。申请免费证书升级为HTTPShttps://www.joyssl.com/certificate/select/free.html?nid=5生成CSR文件:申请SSL证书前需要根据服务器类型(如Apache、Nginx、IIS等)生成Certificate Signing Request (CSR) 文件,其中包含您网站的基本信息。提交申请:将CSR文件和其他必要信息提交给证书颁发机构,等待审核并获得SSL证书。 安装与配置SSL证书 下载并安装证书:收到证书颁发机构颁发的SSL证书后,将其按照对应的服务器软件教程进行安装。通常,这包括将证书文件上传到服务器,并在服务器配置中引用这些文件。更新网站链接:在网站的所有内部链接和资源引用中,将HTTP替换为HTTPS,确保整个网站内容都通过安全连接加载。设置强制跳转:为了防止搜索引擎抓取到HTTP版本的内容,应在服务器配置中添加重定向规则,自动将所有HTTP请求重定向至对应的HTTPS页面。 测试与优化 验证HTTPS设置:安装完成后,使用在线SSL检查工具(如Qualys SSL Labs)来验证证书安装是否正确,以及HTTPS配置是否符合最佳实践。HSTS策略设置:启用HTTP Strict Transport Security(HSTS),让浏览器始终优先尝试通过HTTPS访问你的网站,从而进一步提高安全性。SEO调整:在Google Search Console等搜索引擎站长工具中,通知搜索引擎你的网站已切换至HTTPS,以便其更新索引和快照。 将网站迁移到HTTPS是一个涉及多个步骤的过程,但其带来的安全性和信任度提升对于任何网站都是至关重要的。遵循以上步骤,您可以顺利地完成这一转型,为用户提供更加安全、可信的在线体验。
json.dumps(数据)
用法是将数据类型(字符串,列表,字典,元组)加载成字符串。ensure_ascii=False参数可以加载中文。元组会转成列表形式的字符串
json.loads(数据)
用法是将字符串加载成数据类型(字符串,列表,字典)。
import json dic = {"张三": 2, "李四": 3} s = json.dumps(dic,ensure_ascii=False) print(s) print(type(s)) #{"张三": 2, "李四": 3} #<class 'str'> str = '{"张三": 2,"李四": 3}' d = json.loads(str) print(d) print(type(d)) # {'张三': 2, '李四': 3} # <class 'dict'> json.dump(数据类型,文件对象)
dump参数是数据和对象,将数据转成字符串格式写入文件中(一般是json或者txt)
json.load(文件对象)
load从文件对象中读取数据并转成相应的数据类型
import json dic = {"张三": 2, "李四": 3} f = open("a.json", "w", encoding="utf-8") json.dump(dic, f) f.close() f = open("a.json", "r", encoding="utf-8") d = json.load(f) f.
vite-admin框架搭建,ESLint + Prettier 语法检测和代码格式化 1. 环境和工具2. 项目初始化3. 安装插件1. 安装ESLint1.1 安装插件1.2 初始化ESLint 2. 安装Prettier2.1 安装插件2.2 配置Prettier 3. vscode 安装插件及配置3.1 安装插件 ESLint 和 Prettier - Code formatter3.2 解决ESLint与Prettier的冲突3.3 保存文件时自动格式化代码3.4 忽略不想被检测和格式化的文件3.5 控制台输出打印ESLint报错3.5 ESLint语法检测示例 4. 代码仓库 1. 环境和工具 开发工具: vs code
node: 20.10.0
npm: 10.2.3
UI框架: Element-plus
gitee地址:
2. 项目初始化 搭建一个新的vite项目
// 执行 npm create vite@latest 回车后选择 vue 和 Typescript ✔ Select a framework: › Vue ✔ Select a variant: › TypeScript 搭建完成执行命令后如图所示
文章目录 1. 镜像1.1 基本命令1.2 案例练习 2. 容器2.1 基本命令2.2 Nginx 案例2.3 Redis 案例 3. 数据卷3.1 基本命令3.2 Nginx 案例3.3 MySQL 案例 1. 镜像 镜像命令一般分两部分组成:repository:tag。比如 mysql:5.7,表示名称加版本。
在没有指定 tag 时,默认是 latest,代表最新版本的镜像。
命令太多记住不,通过 docker --help 就能够查看到 docker 中的所有命令了。
1.1 基本命令 ① 获取镜像
获取镜像有两种方式:
① 一种是通过 docker build 命令,把本地的 Dockerfile 文件构建成一个镜像;
② 另一种是通过 docker pull 命令,从 Docker Registry 镜像服务器上拉取镜像(一般都是这种方式)。
docker pull ② 查看镜像
docker images ③ 删除镜像
docker rmi ④ 分享镜像
两种方式:
① 可以通过 docker push 命令,将你的镜像推送到镜像服务器去;
前言 为什么需要分布式? 在工作中经常需要对一些关键接口做高QPS的压测,JMeter是由Java 语言开发,没创建一个线程(虚拟用户),JVM默认会为每个线程分配1M的堆栈内存空间。受限于单台试压机的配置很难实现太高的并发。所以,通过JMeter实现分布式,可以整合多台主机的硬件资源,实现同时对被测试接口进行压力测试。
Jmeter分布式测试环境中有两个角色:Master 和 Slaves
Master节点:向参与的Slaves节点发送测试脚本,并聚合Agent节点的执行结果。
Slaves节点:接收并执行Master节点发送过来的测试脚本,并将执行结果返回给Master。
为什么要使用docker? 如果要分布式联动每台主机,就要求每台主机都要有JMeter环境(JDK + JMeter),如果利用docker就可以通过docker管理 JMeter环境,简单的拉取镜像,启动容器即可。进一步讲,利用k8s、云服务可以无限的扩容JMeter试压机,理论上多少的并发用户都可以模拟。
准备工作 JDK:启动 JMeter 工具需要 $ brew install openjdk@11 JMeter: 编写JMeter脚本 https://archive.apache.org/dist/jmeter/binaries/
编写一个简单的脚本。
docker: 通过doker创建容器。 $ docker pull runcare/jmeter-master $ docker pull runcare/jmeter-slave 查看docker镜像 $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE runcare/jmeter-master latest e052a8cd8680 3 years ago 326MB runcare/jmeter-slave latest 05c7ba96d97d 3 years ago 326MB 请记住 jmeter-master 的镜像ID e052a8cd8680,后面会用到。
分布式压测使用 启动 slave 节点。 假设有两台主机,可以启动两个slave。
HttpServletRequestWrapper 是 Java Servlet API 中的一个类,作为 HttpServletRequest 接口的包装器(Decorator)实现。
该类设计为装饰者模式(Decorator Pattern)的一部分,允许开发人员通过包装现有的 HttpServletRequest对象来定制或修改请求行为。比如:
过滤或修改请求参数
转换请求体数据
添加或删除请求头信息
实现请求级的安全控制,如防止 XSS(跨站脚本攻击)或 SQL 注入等安全风险
修改请求URI或其他请求属性
样例 import com.zhangziwa.practisesvr.utils.stream.StreamIUtils; import jakarta.servlet.ReadListener; import jakarta.servlet.ServletInputStream; import jakarta.servlet.http.HttpServletRequest; import jakarta.servlet.http.HttpServletRequestWrapper; import org.apache.commons.text.StringEscapeUtils; import java.io.*; public class FilterHttpServletRequest extends HttpServletRequestWrapper { private final byte[] body; private ByteArrayInputStream byteArrayInputStream; private ServletInputStream servletInputStream; private BufferedReader bufferedReader; public FilterHttpServletRequest(HttpServletRequest request) throws IOException { super(request); body = StreamIUtils.readStream2Bytes(request.getInputStream()); byteArrayInputStream = new ByteArrayInputStream(body); } public String getBody() throws UnsupportedEncodingException { String characterEncoding = this.
反正大家肯定都不爱看文字,实现过程就都写代码注释里面了 <template> <div ref="mainrouter" class="mainrouter" style="background-color: black;position: relative;overflow: hidden;padding: 0;"> <!-- 现在有一道题,要求做出代码雨的效果,你要怎么实现 --> <!-- 首先要解决代码垂直排布的样式 --> <!-- 然后,然后你想想哈,这么多代码雨是不是由每一条代码雨组成的,那我们现在就一条一条来加上去--> <!-- 最后你想,这一条动起来了,那我要一大堆怎么动呢,当然for循环游戏就好了 --> <!-- 别忘了,每个代码雨执行动画要有间隔,不然就一起动了,肯定不好看 --> <div class="code" ref="code" v-for="(item, index) in codenum" :style="{ '--width': codenum, }" :key="index"> <div :model="data" v-for="(item2, index2) in 15" :key="index2">{{ getRandomChar() }}</div> </div> </div> </template> <script setup> import { onMounted, ref } from 'vue'; // 获取界面mainrouter的高度 const mainrouter = ref() const code = ref() const h = ref(); const w = ref(); const codeh = ref(); const codew = ref(); // 存放代码雨的数量 const codenum = ref(1); // const w = mainrouter.
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块三、系统展示四、核心代码4.1 查询家政服务4.2 新增单条服务订单4.3 新增留言反馈4.4 小程序登录4.5 小程序数据展示 五、免责说明 一、摘要 1.1 项目介绍 基于微信小程序+JAVA+Vue+SpringBoot+MySQL的智慧家政系统,包含了地址管理模、订单管理、家政分类管理、家政服务管理、用户反馈管理模块,还包含系统自带的用户管理、部门管理、角色管理、菜单管理、日志管理、数据字典管理、文件管理、图表展示等基础模块,基于微信小程序的智慧家政系统基于角色的访问控制,给家政管理员、家政工作人员、消费者使用,可将权限精确到按钮级别,您可以自定义角色并分配权限,系统适合设计精确的权限约束需求。
1.2 项目录屏 二、功能模块 该系统基于微信开发者工具进行开发,最终成果以微信小程序的方式进行呈现。系统大致分为两大模块,即前台用户系统与后台管理系统,主要内容如下。
注册登录:此系统采用微信授权登录方式。用户信息管理:用户能快速了解修改个人基本信息(如用户名、密码、头像等信息)。地址管理:用户对自己的地址可以进行增删改查操作。订单管理:对所有订单信息进行管理。分类管理:通过分类管理功能对服务种类进行分类归纳,管理更方便快速。服务人员管理:对于家政工作人员提供的服务进行增删改查操作。提交订单功能:将心仪的服务添加至订单中。支付管理:提交订单后立即跳转至支付界面,付款完成后在订单列表中出现已支付的订单。。用户反馈:通过投资理财网站系统提供反馈功能,快速解决用户问题,提高用户体验,也为企业改进提供可行性参考依据。 三、系统展示 四、核心代码 4.1 查询家政服务 @RequestMapping(value = "/getByPage", method = RequestMethod.GET) @ApiOperation(value = "查询服务") public Result<IPage<ServiceData>> getByPage(@ModelAttribute ServiceData serviceData ,@ModelAttribute PageVo page){ QueryWrapper<ServiceData> qw = new QueryWrapper<>(); if(!ZwzNullUtils.isNull(serviceData.getTitle())) { qw.like("title",serviceData.getTitle()); } if(!ZwzNullUtils.isNull(serviceData.getType())) { qw.eq("type",serviceData.getType()); } IPage<ServiceData> data = iServiceDataService.page(PageUtil.initMpPage(page),qw); return new ResultUtil<IPage<ServiceData>>().setData(data); } 4.2 新增单条服务订单 @RequestMapping(value = "/addOne", method = RequestMethod.
1、修改redis配置
用vi命令打开配置文件
#大家找自己的配置文件位置 vi /etc/redis.conf 修改内容如下: supervised no=>systemd #以systemd控制启动 2、编写redis.service文件
vi /lib/systemd/system/redis.service 文件内容如下:
[Unit] Description=redis After=network.target [Service] Type=forking ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf #ExecStart=/opt/redis-6.0.6/src/redis-server /etc/redis.conf ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s QUIT $MAINPID PrivateTmp=true [Install] WantedBy=multi-user.target 3、重新加载配置文件
systemctl daemon-reload 4、 命令如下:
systemctl start redis.service (启动redis服务) systemctl stop redis.service (停止redis服务) systemctl enable redis.service (设置开机自启动) systemctl disable redis.service (停止开机自启动) systemctl status redis.service (查看服务当前状态) systemctl restart redis.service (重新启动服务) systemctl list-units --type=service (查看所有已启动的服务 5、redis安装步骤:
https://blog.csdn.net/wd520521/article/details/109770009
目录 dict的数据结构定义 dict的创建(dictCreate) dict的查找(dictFind) dict的插入(dictAdd和dictReplace) dict的删除(dictDelete) 如果你使用过Redis,一定会像我一样对它的内部实现产生兴趣。《Redis内部数据结构详解》是我准备写的一个系列,也是我个人对于之前研究Redis的一个阶段性总结,着重讲解Redis在内存中的数据结构实现(暂不涉及持久化的话题)。Redis本质上是一个数据结构服务器(data structures server),以高效的方式实现了多种现成的数据结构,研究它的数据结构和基于其上的算法,对于我们自己提升局部算法的编程水平有很重要的参考意义。
当我们在本文中提到Redis的“数据结构”,可能是在两个不同的层面来讨论它。
第一个层面,是从使用者的角度。比如:
string list hash set sorted set 这一层面也是Redis暴露给外部的调用接口。
第二个层面,是从内部实现的角度,属于更底层的实现。比如:
dict sds ziplist quicklist skiplist 第一个层面的“数据结构”,Redis的官方文档(http://redis.io/topics/data-types-intro)有详细的介绍。本文的重点在于讨论第二个层面,Redis数据结构的内部实现,以及这两个层面的数据结构之间的关系:Redis如何通过组合第二个层面的各种基础数据结构来实现第一个层面的更高层的数据结构。
在讨论任何一个系统的内部实现的时候,我们都要先明确它的设计原则,这样我们才能更深刻地理解它为什么会进行如此设计的真正意图。在本文接下来的讨论中,我们主要关注以下几点:
存储效率(memory efficiency)。Redis是专用于存储数据的,它对于计算机资源的主要消耗就在于内存,因此节省内存是它非常非常重要的一个方面。这意味着Redis一定是非常精细地考虑了压缩数据、减少内存碎片等问题。 快速响应时间(fast response time)。与快速响应时间相对的,是高吞吐量(high throughput)。Redis是用于提供在线访问的,对于单个请求的响应时间要求很高,因此,快速响应时间是比高吞吐量更重要的目标。有时候,这两个目标是矛盾的。 单线程(single-threaded)。Redis的性能瓶颈不在于CPU资源,而在于内存访问和网络IO。而采用单线程的设计带来的好处是,极大简化了数据结构和算法的实现。相反,Redis通过异步IO和pipelining等机制来实现高速的并发访问。显然,单线程的设计,对于单个请求的快速响应时间也提出了更高的要求。 本文是《Redis内部数据结构详解》系列的第一篇,讲述Redis一个重要的基础数据结构:dict。
dict是一个用于维护key和value映射关系的数据结构,与很多语言中的Map或dictionary类似。Redis的一个database中所有key到value的映射,就是使用一个dict来维护的。不过,这只是它在Redis中的一个用途而已,它在Redis中被使用的地方还有很多。比如,一个Redis hash结构,当它的field较多时,便会采用dict来存储。再比如,Redis配合使用dict和skiplist来共同维护一个sorted set。这些细节我们后面再讨论,在本文中,我们集中精力讨论dict本身的实现。
dict本质上是为了解决算法中的查找问题(Searching),一般查找问题的解法分为两个大类:一个是基于各种平衡树,一个是基于哈希表。我们平常使用的各种Map或dictionary,大都是基于哈希表实现的。在不要求数据有序存储,且能保持较低的哈希值冲突概率的前提下,基于哈希表的查找性能能做到非常高效,接近O(1),而且实现简单。
在Redis中,dict也是一个基于哈希表的算法。和传统的哈希算法类似,它采用某个哈希函数从key计算得到在哈希表中的位置,采用拉链法解决冲突,并在装载因子(load factor)超过预定值时自动扩展内存,引发重哈希(rehashing)。Redis的dict实现最显著的一个特点,就在于它的重哈希。它采用了一种称为增量式重哈希(incremental rehashing)的方法,在需要扩展内存时避免一次性对所有key进行重哈希,而是将重哈希操作分散到对于dict的各个增删改查的操作中去。这种方法能做到每次只对一小部分key进行重哈希,而每次重哈希之间不影响dict的操作。dict之所以这样设计,是为了避免重哈希期间单个请求的响应时间剧烈增加,这与前面提到的“快速响应时间”的设计原则是相符的。
下面进行详细介绍。
dict的数据结构定义 为了实现增量式重哈希(incremental rehashing),dict的数据结构里包含两个哈希表。在重哈希期间,数据从第一个哈希表向第二个哈希表迁移。
dict的C代码定义如下(出自Redis源码dict.h):
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
1、首先进入Docker容器 docker exec -it gitlab bash 2、连接到 gitlab 的数据库 需要谨慎操作
gitlab-rails console -e production 等待加载完后会进入控制台
---------------------------------------------------------------------------------------------------------------------------------
不是docker部署则需要切换到gitlab安装目录,例如:
cd /opt/gitlab/bin 然后链接数据库
sudo gitlab-rails console -e production -------------------------------------------------------------------------------------------------------------------------------- 3、通过用户名或邮箱找到用户 user = User.find_by(username: 'root') 4、更改密码 通过上一步查找到 root 用户,并赋值给 user,现在可以通过 user 更改密码
(1)重置密码命令 user.password = 'S87hdj@&yhkk' (2)再次确认密码 user.password_confirmation = 'S87hdj@&yhkk' 5、修改密码后进行保存 user.save! 这样就修改完毕了!使用 exit 命令退出gitlab数据库即可。
6、重启gitlab (1)容器内重启 gitlab-ctl restart (2)重启docker容器 docker restart gitlab
1 问题 mysql 为大表增加或增加索引等操作时,直接操作原表可能会因为执行超时而导致失败。解决办法如下。
2 解决办法 (1)建新表-复制表A 的数据结构,不复制数据
create table B like A; (2)加字段或索引-表B加上新字段或索引
(3)导数据到新表-把原有数据导入新表 未新增字段时
insert into B select * from A [where 条件] 添加了新字段时。假设添加字段名为data_code(默认值为空),且字段位于id之后
insert into B select id, '' data_code, 其他旧字段 from A [where 条件] 数据量达到几千万时,可以添加where 条件,分批将数据导入到新表。防止数据导入超时。
(4)改表名-修改表A 的名称为A_old,修改B表的表名为A
3 备注 (1)MySQL查询一个表中的所有字段的方法
select CONCAT(COLUMN_NAME ,',') from information_schema.COLUMNS where table_name = '表名' and table_schema = '库名'; (2)可以在idea中的database上执行sql,上面可以设置执行超时时间。
4 参考文献 (1)https://www.cnblogs.com/zhangchenglzhao/p/11731817.html
(2)mysql大表创建索引问题_mysql 大表创建索引
自动化测试Selenium Selenium简介第一个Selenium应用Selenium Python APISelenium WebDriverSelenium 初始化浏览器Selenium导航到URLSelenium定位元素Selenium By类Selenium WebElement类Selenium页面交互Selenium ActionChainsSelenium鼠标操作Selenium键盘操作Selenium调用JavaScriptSelenium等待机制Selenium expected_conditionsSelenium WebDriverWaitSelenium窗口操作Selenium Frame操作Selenium浏览器操作
在以前的view goup 是继承关系
而现在的compose是组合关系。 进行了解耦。组件与组件之间没有关联,拿过来直接用就可以了,不会因为一个的改动去改变另一个。
1.Android的整体结构 phone Window 窗口 Activity Dialog Toast
DecirView 父View
LinearLayout
TitleView
ContentView R.layout.xxx
ComoseView 连接 View 与 Compose 的一个桥梁
LayoutNode 最终会变成虚拟节点 Compose
Text -> LayoutNode 轻量
Image -> LayoutNode 也是一个树形结构
1.View ViewGoup 修改升级十分麻烦
2. 简单视图编写 package com.tiger.compose0117 import android.os.Bundle import androidx.activity.ComponentActivity import androidx.activity.compose.setContent import androidx.compose.foundation.Image import androidx.compose.foundation.layout.Column import androidx.compose.foundation.layout.Row import androidx.compose.foundation.layout.fillMaxSize import androidx.compose.foundation.layout.height import androidx.compose.foundation.layout.padding import androidx.compose.foundation.layout.width import androidx.compose.foundation.shape.CircleShape import androidx.compose.foundation.shape.RoundedCornerShape import androidx.compose.material3.MaterialTheme import androidx.
【深度学习:BERT 】开源 BERT:最先进的自然语言处理预训练 BERT 有何不同?双向性的力量使用云 TPU 进行训练BERT 结果让 BERT 为您服务 自然语言处理(NLP)的最大挑战之一是训练数据的短缺。由于 NLP 是一个多元化的领域,具有许多不同的任务,因此大多数特定于任务的数据集仅包含几千或几十万个人工标记的训练示例。然而,现代基于深度学习的 NLP 模型从大量数据中获益,在数百万或数十亿带注释的训练示例上进行训练时,性能会得到改善。为了帮助缩小数据差距,研究人员开发了多种技术,使用网络上大量未注释的文本(称为预训练)来训练通用语言表示模型。然后,可以针对问答和情感分析等小数据 NLP 任务对预训练模型进行微调,与从头开始对这些数据集进行训练相比,可显着提高准确性。
本周,我们开源了一种用于 NLP 预训练的新技术,称为 Transformers 双向编码器表示(BERT)。通过此版本,世界上任何人都可以在单个 Cloud TPU 上大约 30 分钟内训练自己最先进的问答系统(或各种其他模型),或者使用单个 GPU 在几个小时内训练。该版本包括基于 TensorFlow 构建的源代码和许多预先训练的语言表示模型。在我们的相关论文中,我们展示了 11 项 NLP 任务的最新结果,其中包括非常有竞争力的斯坦福问答数据集 (SQuAD v1.1)。
BERT 有何不同? BERT 建立在预训练上下文表示方面的最新成果之上,包括半监督序列学习、生成预训练、ELMo 和 ULMFit。然而,与之前的模型不同的是,BERT 是第一个深度双向、无监督的语言表示,仅使用纯文本语料库(在本例中为维基百科)进行预训练。
为什么这很重要?预训练的表示可以是上下文无关的或上下文的,并且上下文表示还可以是单向的或双向的。上下文无关模型(例如 word2vec 或 GloVe)为词汇表中的每个单词生成单个单词嵌入表示。例如,“银行”一词在“银行帐户”和“河岸”中具有相同的上下文无关表示。相反,上下文模型会根据句子中的其他单词生成每个单词的表示。例如,在句子“我访问了银行帐户”中,单向上下文模型将基于“我访问了”而不是“帐户”来表示“银行”。然而,BERT 使用其前一个和下一个上下文(“我访问了……帐户”)来表示“银行”,从深度神经网络的最底层开始,使其成为深度双向的。
下图展示了 BERT 神经网络架构与之前最先进的上下文预训练方法的对比。箭头表示从一层到下一层的信息流。顶部的绿色框表示每个输入单词的最终上下文表示:
BERT 是深度双向的,OpenAI GPT 是单向的,ELMo 是浅度双向的。 双向性的力量 如果双向性如此强大,为什么以前没有这样做呢?要理解原因,请考虑通过根据句子中前面的单词预测每个单词来有效地训练单向模型。然而,不可能通过简单地根据每个单词的前一个和下一个单词来训练双向模型,因为这将允许被预测的单词在多层模型中间接“看到自己”。
为了解决这个问题,我们使用简单的技术来屏蔽输入中的一些单词,然后双向调节每个单词以预测屏蔽的单词。例如:
虽然这个想法已经存在很长时间了,但 BERT 是第一次成功地将其用于预训练深度神经网络。
BERT 还通过预训练一个非常简单的任务来学习建模句子之间的关系,该任务可以从任何文本语料库生成:给定两个句子 A 和 B,B 是语料库中 A 之后的实际下一个句子,还是只是一个随机句子?例如:
一、xftp简述 Xftp 是一款由 NetSarang Computer 公司开发的 Windows 平台上的 FTP 客户端软件,支持 SFTP、FTP、SCP 和 FTPS 等多种协议。它提供了丰富的功能和工具,使得用户可以轻松地进行文件传输和管理。
Xftp 支持多个会话的同时打开和管理,可以在一个窗口中同时连接多个远程服务器。它提供了直观的界面和易于使用的工具,如文件管理器、文件过滤器、文件传输队列和编辑器等,使得用户可以更加方便地进行文件传输和浏览。
此外,Xftp 还支持多种安全认证方式,包括公钥认证、密码认证和 Kerberos 认证等,可以保障文件传输的安全性。Xftp 同样也支持对不同文件类型的解压缩操作,如 ZIP、TAR、GZ 和 UNIX 压缩文件等。
总结:就是与服务器进行文件传输工具,个人觉得非常好用。
二、xftp下载地址 家庭/学校免费 - NetSarang Website
三、安装xftp 1.双击xftp.exe文件 2.按照如下图方式进行安装 (1)直接下一步
(2)接受协议,下一步
(3) 选择安装目录
(4)默认安装
(5)安装完成
四、注册xftp 1.运行xftp之后会跳转到,如下注册页面,名称随意,邮箱一定要真实,方便激活
2.填写完成之后,点击提交,如下:注册连接已经发送到我们邮箱。
3.点击链接,完成激活 4.激活成功如下: 激活完成之后,双击xftp应用程序就能正常使用啦!到此我们就能永久免费的使用这个xftp。
一、打开qt,选择项目》构建环境》WindowsSDKVersion
二、打开路径C:\Program Files (x86)\Windows Kits\10\bin\10.0.17763.0 选择平台,找出rc.exe rcdll.dll 复制到qt安装路径 D:\Qt\Qt5.9.8\5.9.8\msvc2015_64\bin
成功运行!!!
文章目录 一、主要特点二、存储结构三、SQL 与 MongoDB 对比四、使用方法1.创建数据库2.查看所有数据库3.查看当前数据库4.切换数据库5.删除数据库6.创建数据表7.查看数据表8.删除数据表9.表中插入数据例:或: 10.查看表数据查多少条:跳过多少条:格式化:排序(其中 1 为升序排列,而 -1 是用于降序排列):MongoDB 与 SQL Where 语句比较:例: 11.修改表数据参数说明:例: 12.删除表数据参数说明:例: 13.清空表数据 MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
一、主要特点 面向集合存储,易存储对象类型的数据。模式自由。支持动态查询。支持完全索引,包含内部对象。支持查询。支持复制和故障恢复。使用高效的二进制数据存储,包括大型对象(如视频等)。自动处理碎片,以支持云计算层次的扩展性支持 RUBY,PYTHON,JAVA,C++,PHP 等多种语言。文件存储格式为 BSON(一种 JSON 的扩展)可通过网络访问 二、存储结构 MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。字段的值可能包括其他文档、数组和文档数组。
文档(Document) :MongoDB 中最基本的单元,由 BSON 键值对(key-value)组成,类似于关系型数据库中的行(Row)。
集合(Collection) :一个集合可以包含多个文档,类似于关系型数据库中的表(Table)。
数据库(Database) :一个数据库中可以包含多个集合,可以在 MongoDB 中创建多个数据库,类似于关系型数据库中的数据库(Database)。
三、SQL 与 MongoDB 对比 SQLMongoDB表(Table集合(Collection)行(Row文档(Document)列(Col)字段(Field)主键(Primary Key对象 ID(Objectid)索引(Index)索引(Index)嵌套表(Embeded Table)嵌入式文档(Embeded Document)数组(Array)数组(Array) 四、使用方法 1.创建数据库 use DATABASE_NAME 2.查看所有数据库 show dbs 3.
前言 我也不知道啥时候自动给我更新了内核,重启电脑之后我的内核升级成6.5.0-14-generic,导致Virtual Box无法找到内核文件。
解决方法 方法1 sudo apt update sudo apt install linux-headers-generic build-essential dkms sudo apt remove virtualbox-dkms sudo apt install virtualbox-dkms 博主尝试该方法不可行,删除virtualbox-dkms后,无法再次安装virtualbox-dkms,总是提示下面的问题:
Loading new virtualbox-6.1.10 DKMS files... Building for 5.8.0-36-generic Building initial module for 5.8.0-36-generic ERROR: Cannot create report: [Errno 17] File exists: '/var/crash/virtualbox-dkms.0.crash' Error! Bad return status for module build on kernel: 5.8.0-36-generic (x86_64) Consult /var/lib/dkms/virtualbox/6.1.10/build/make.log for more information. dpkg: error processing package virtualbox-dkms (--configure): installed virtualbox-dkms package post-installation script subprocess returned error exit status 10 Processing triggers for man-db (2.
微软推出了Copilot Pro 每月20美金
Copilot Pro在Word、Excel和PowerPoint等Office应用中提供AI驱动的增强体验。
在Word中生成文本和总结文档,回复电子邮件,以及在Excel中分析数据和生成图表等。
订阅者可以优先使用最新的OpenAI模型,包括GPT-4 Turbo等。自定义创建自己的Copilot GPT...
Copilot Pro主要功能亮点:
1、AI驱动的Office应用体验: Copilot Pro在Word、Excel和PowerPoint等Office应用中提供AI驱动的增强体验。
2、生成文本和文档总结: 在Word中,Copilot Pro能够重新组织段落、生成文本,甚至自动总结文档内容。
3、邮件撰写和回复辅助: 在http://Outlook.com中,此功能可协助用户撰写或回复电子邮件,提高沟通效率。
4、数据分析和图表生成: 在Excel中,用户可以使用Copilot Pro进行数据分析和图表生成,简化复杂数据处理。
5、高级AI模型访问: 提供对最新OpenAI模型的优先访问,包括GPT-4 Turbo,为用户带来更加智能的AI体验。
6、定制化的Copilot GPT: 用户可以根据自己的需求和偏好创建定制化的Copilot GPT,使AI体验更加个性化。
7、改进的图像创建工具: 利用OpenAI的DALL-E模型,Copilot Pro提供了改进的图像创建功能,支持新的风景图像格式并提高图像质量。
8、跨平台兼容性: Copilot Pro功能可在网页、Windows或Mac应用程序以及移动设备上使用,提供灵活的工作方式。
详细:https://blogs.microsoft.com/blog/2024/01/15/bringing-the-full-power-of-copilot-to-more-people-and-businesses/
国内想体验ChatGPT来这里ppword.cn
前面介绍过,KafkaProducer可以有同步和异步两种方式发送消息,其实两者的底层实现相同,都是通过异步方式实现的。
主线程调用KafkaProducer.send方法发送消息的时候,先将消息放到RecordAccumulator中暂存,然后主线程就可以从send方法中返回了,此时消息并没有真正地发送给Kafka,而是缓存在了RecordAccumulator中。
之后,业务线程通过KafkaProducer.send()方法不断向RecordAccumulator追加消息,当达到一定的条件,会唤醒Sender线程发送RecordAccumulator中的消息。
下面我们就来介绍RecordAccumulator的结构。
首先需要注意的是,RecordAccumulator至少有一个业务线程和一个Sender线程并发操作,所以必须是线程安全的。
RecordAccumulator中有一个以TopicPartition为key的ConcurrentMap,每个value是ArrayDeque(ArrayDeque并不是线程安全的集合),其中缓存了发往对应TopicPartition的消息。
每个RecordBatch拥有一个MemoryRecords对象的引用。
MemoryRecords才是消息最终存放的地方。
这三个类的依赖关系如图所示。
MemoryRecords 大体了解了RecordAccumulator的结构之后,我们就从最底层的MemoryRecords开始分析。
MemoryRecords表示的是多个消息的集合,其中封装了Java NIO ByteBuffer用来保存消息数据,Compressor用于对ByteBuffer中的消息进行压缩,以及其他控制字段。
如图(左)所示,有四个字段比较重要,简单介绍一下。
buffer:用于保存消息数据的Java NIO ByteBuffer。writeLimit:记录buffer字段最多可以写入多少个字节的数据。compressor:压缩器,对消息数据进行压缩,将压缩后的数据输出到buffer。writable:此MemoryRecords对象是只读的模式,还是可写模式。在MemoryRecords发送前时,会将其设置成只读模式。 在Compressor比较重要的字段和方法如图(右)所示,有两个输出流类型的字段,分别是bufferStream和appendStream。
前者是在buffer上建立的ByteBufferOutputStream(Kafka自己提供的实现)对象,ByteBufferOutputStream继承了java.io.OutputStream,封装了ByteBuffer,当写入数据超出ByteBuffer容量时,ByteBufferOutputStream会进行自动扩容;后者是DataOutputStream类型,它对前者进行了一层装饰,为其添加了压缩的功能。
MemoryRecords中的Compressor的压缩类型是由“compression.type”配置参数指定的,即KafkaProducer.compressionType字段的值。
下面来分析一下创建压缩流的方式,目前KafkaProducer支持GZIP、SNAPPY、LZ4三种压缩方式。
Compressor提供了一系列put*()方法,向appendStream流写入数据,如图所示。很明显,这是装饰器模式的典型,通过bufferStream装饰,添加自动扩容的功能;通过appendStream装饰后,添加压缩功能。
了解了Compressor的实现逻辑之后,我们回到MemoryRecords继续分析。
MemoryRecords的构造方法是私有的,只能通过emptyRecords)方法得到其对象。
MemoryRecords中有四个比较重要的方法。
append()方法:先判断MemoryRecords是否为可写模式,然后调用Compressor.put*()方法,将消息数据写入ByteBuffer中。hasRoomFor()方法:根据Compressor估算的已写字节数,估计MemoryRecords剩余空间是否足够写入指定的数据。注意,这里仅仅是估算,所以不一定准确,通过hasRoomFor()方法判断之后写入数据,也可能就会导致底层ByteBuffer出现扩容的情况。close()方法:出现ByteBuffer扩容的情况时,MemoryRecords.buffer字段与ByteBufferOutputStream.buffer字段所指向的不再是同一个ByteBuffer对象,如图(左)所示。在close()方法中,会将MemoryRecords.buffer字段指向扩容后的ByteBuffer对象,如图(右)所示。同时,将writable设置为false(即只读模式)。
sizelnBytes()方法:对于可写的MemoryRecords,返回的是ByteBufferOutputStream.buffer字段的大小;对于只读MemoryRecords,返回的是MemoryRecords.buffer的大小。 RecordBatch 了解了MemoryRecords的具体实现之后,来分析RecordBatch类的实现。
每个RecordBatch对象中封装了一个MemoryRecords对象,除此之外,还封装了很多控制信息和统计信息,下面简单介绍一下。
recordCount:记录了保存的Record的个数。maxRecordSize:最大Record的字节数。attempts:尝试发送当前RecordBatch的次数。lastAttemptMs:最后一次尝试发送的时间戳。records:指向用来存储数据的MemoryRecords对象。topicParition:当前RecordBatch中缓存的消息都会发送给此TopicPartition。produceFuture:ProduceRequestResult类型,标识RecordBatch状态的Future对象。lastAppendTime:最后一次向RecordBatch追加消息的时间戳。thunks:Thunk对象的集合,在后面会详细介绍。offsetCounter:用来记录某消息在RecordBatch中的偏移量。retry:是否正在重试。如果RecordBatch中的数据发送失败,则会重新尝试发送。 图中,以RecordBatch为中心,刻画了其相关类间的对应关系。
下面分析一下ProduceRequestResult这个类的功能。
ProduceRequestResult并未实现java.util.concurrent.Future接口,但是其通过包含一个count值为1的CountDownLatch对象,实现了类似于Future的功能(Future、CountDownLatch等工具的使用)。
当RecordBatch中全部的消息被正常响应、或超时、或关闭生产者时,会调用ProduceRequestResult.done方法,将produceFuture标记为完成并通过ProduceRequestResult.error字段区分“异常完成”还是“正常完成”,之后调用CountDownLatch对象的countDown方法。
此时,会唤醒阻塞在CountDownLatch对象的await方法的线程(这些线程通过ProduceRequestResult的await方法等待上述三个事件的发生)。
分区会为其中记录的消息分配一个offset并通过此offset维护消息顺序。
在ProduceRequestResult中还有一个需要注意的字段baseOffset,表示的是服务端为此RecordBatch中第一条消息分配的offset,这样每个消息可以根据此offset以及自身在此RecordBatch中的相对偏移量,计算出其在服务端分区中的偏移量了。
在介绍Tunk类之前,请回顾KafkaProducer.send方法的第二个参数,是一个Callback对象,它是针对单个消息的回调函数(每个消息都会有一个对应的Callback对象作为回调)。
RecordBatch.thunks字段可以理解为消息的回调对象队列,Thunk中的callback字段就指向对应消息的Callback对象,其另一个字段future是FutureRecordMetadata类型。
FutureRecordMetadata类有两个关键字段。
result:ProduceRequestResult类型,指向对应消息所在RecordBatch的produceFuture字段。relativeOffset:long类型,记录了对应消息在RecordBatch中的偏移量。 FutureRecordMetadata实现了java.util.concurrent.Future接口,但其实现基本都是委托给了ProduceRequestResult对应的方法,由此可以看出,消息应该是按照RecordBatch进行发送和确认的。
当生产者已经收到某消息的响应时,FutureRecordMetadata.get方法就会返回RecordMetadata对象,其中包含消息在Partition中的offset等其他元数据,可供用户自定义Callback使用。
分析完RecordBatch依赖的组件,现在回来看看RecordBatch类的核心方法。tryAppend方法是最核心的方法,其功能是尝试将消息添加到当前的RecordBatch中缓存。
当RecordBatch成功收到正常响应、或超时、或关闭生产者时,都会调用RecordBatch的done()方法。
在done()方法中,会回调RecordBatch中全部消息的Callback回调,并调用其produceFuture字段的done()方法。RecordBatch.done()方法的调用关系如图所示。
RufferPool ByteBuffer的创建和释放是比较消耗资源的,为了实现内存的高效利用,基本上每个成熟的框架或工具都有一套内存管理机制。
Kafka客户端使用BufferPool来实现ByteBuffer的复用。
图展示了BufferPool的核心字段。
首先需要了解的是,每个BufferPool对象只针对特定大小(由poolableSize字段指定)的ByteBuffer进行管理,对于其他大小的ByteBuffer并不会缓存进BufferPool。
一般情况下,我们会调整MemoryRecords的大小(RecordAccumulator.batchSize字段指定),使每个MemoryRecords可以缓存多条消息。
但也有例外情况,当一条消息的字节数大于MemoryRecords时,就不会复用BufferPool中缓存的ByteBuffer,而是额外分配ByteBuffer,在它被使用完后也不会放入BufferPool进行管理,而是直接丢弃由GC回收。
如果经常出现这种例外情况,就需要考虑调整batchSize的配置了。
下面介绍BufferPool的关键字段:
free:是一个ArayDeque队列,其中缓存了指定大小的ByteBuffer对象。ReentrantLock:因为有多线程并发分配和回收ByteBuffer,所以使用锁控制并发,保证线程安全。waiters:记录因申请不到足够空间而阻塞的线程,此队列中实际记录的是阻塞线程对应的Condition对象。totalMemory:记录了整个Pool的大小。availableMemory:记录了可用的空间大小,这个空间是totalMemory减去free列表中全部ByteBuffer的大小。
BufferPool.allocate()方法负责从缓冲池中申请ByteBuffer,当缓冲池中空间不足时,就会阻塞调用线程。 下面简单分析一下allocate()方法申请空间的过程:
继续分析deallocate()方法的实现:
RecordAccumulator 介绍完了MemoryRecord、RecordBatch以及BufferPool的工作机制,再来看RecordAccumulator的实现就比较简单了。
下面来看RecordAccumulator中的关键字段和方法,如图所示。
batches:TopicPartition与RecordBatch集合的映射关系,类型是CopyOnWriteMap,是线程安全的集合,但其中的Deque是ArayDeque类型,是非线程安全的集合。在后面的介绍中可以看到,追加新消息或发送RecordBatch的时候,需要加锁同步。 每个Deque中都保存了发往对应TopicPartition的RecordBatch集合。
batchSize:指定每个RecordBatch底层ByteBuffer的大小。Compression:压缩类型,参考MemoryRecords。incomplete:未发送完成的RecordBatch集合,底层通过Set集合实现。free:BufferPool对象,参考BufferPool。drainlndex:使用drain方法批量导出RecordBatch时,为了防止饥饿,使用drainIndex记录上次发送停止时的位置,下次继续从此位置开始发送。 KafkaProducer.send方法最终会调用RecordAccumulator.append方法将消息追加到RecordAccumulator中,其代码比较长,先来看其主要逻辑:
首先在batches集合中查找TopicPartition对应的Deque,查找不到,则创建新的Deque,并添加到batches集合中。对Deque加锁(使用synchronized关键字加锁)。调用tryAppendO方法,尝试向Deque中最后一个RecordBatch追加Record。synchronized块结束,自动解锁。追加成功,则返回RecordAppendResult(其中封装了ProduceRequestResult)。追加失败,则尝试从BufferPool中申请新的ByteBuffer。对Deque加锁(使用synchronized关键字加锁),再次尝试第3步。追加成功,则返回;失败,则使用第5步得到的ByteBuffer创建RecordBatch。将Record追加到新建的RecordBatch中,并将新建的RecordBatch追加到对应的Deque尾部。将新建的RecordBatch追加到incomplete集合。synchronized块结束,自动解锁。返回RecordAppendResult,RecordAppendResult会中的字段会作为唤醒Sender线程的条件。 下面是RecordAccumulator.
1. 使用@WebFilter注解(适用于Servlet API项目)
import jakarta.servlet.annotation.WebFilter; @WebFilter(urlPatterns = "/*") // 拦截所有请求 public class TokenFilter implements Filter { // 实现doFilter方法,添加过滤逻辑 @Override public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { // ... 过滤器逻辑 chain.doFilter(request, response); } // 其他生命周期方法如init和destroy... } 2. 使用Spring的FilterRegistrationBean(推荐)
import org.springframework.boot.web.servlet.FilterRegistrationBean; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class FilterConfig { @Bean public FilterRegistrationBean<TokenFilter> tokenFilterRegistration() { FilterRegistrationBean<TokenFilter> registration = new FilterRegistrationBean<>(); registration.setFilter(new TokenFilter()); // 设置拦截规则 registration.addUrlPatterns("/*"); // 拦截所有请求 // 可以设置过滤器名称、初始化参数等 registration.
stm32 - GPIO高级用法 PWMPWM / LEDPWM / 电机 PWM PWM / LED PWM波通过改变占空比可以改变LED的亮度
PWM信号调节LED亮度时,信号频率保持不变,即一个周期时间不变,改变的是脉冲的高电平的时间,即LED的导通时间,占空比越高,高电平的时间越长,LED亮度越亮
人眼的视觉残留小样,当频率超过75HZ(周期小于13ms),人眼的闪烁感消失,此时亮度感知等于亮度时间的平均值(塔鲁伯法则),因此改变高电平时间和低电平时间的相对比例,一个周期总时间不变(频率不变),人眼看到的LED灯亮度会不同
示例代码
void main() { unsigned char Time,i; while (1) { for (Time = 0; Time < 100; Time++) // 无级调速 { for (i = 0; i < 20; i++) // 相同占空比停留20次 { LED=0; // 低点平 亮 Delay(Time); LED=1; // 高电平 灭 Delay(100-Time); // 周期相同 } } } } PWM / 电机 PWM波通过改变占空比可以改变点击的转速
占空比对点击输入的平均电压的影响
在PWM波形中,占空比越大,输出的脉冲信号的平均电压越大,提供给电机的能量就越大,电机接收到这个能量后,会根据输入能量的多少转动,即占空比越大,点击转速越快
Maven:直观来讲就是打包写好的代码封装
Apahche 软件基金会(非营业的组织,把一些开源软件维护管理起来)
maven apahce的一个开宇拿项目,是一个优秀的项目构建(管理工具)
maven 管理项目的jar 以及jar与jar之间的依赖
maven 可以完成项目的编译,测试打包 等功能
maven可以完成项目编译,测试,打包等功能
pom.xml 里面可以配置相关信息,指导maven如何工作
坐标:jar包在仓库中唯一位置
每个jar都有唯一的一个地址
开发者只需要在项目中配置需要使用的jar地址
maven就会自动从官方下载jar
仓库:
官方存储jar文件的仓库
中央仓库:官方提供的,访问速度慢
中央仓库镜像:在全球各地对中央层库进行备份,国内访问速度快
本地仓库:在程序员电脑上的仓库,第一次使用时从官方下载到本地,以后从本地直接引用即可
安装搭建:
首先你在官网中下载maven服务器http:// maven .apache. org(进入页面后点击download,然后再点击下载二进制的apache-maven -3.6.0-bin.zip进行解压)解压后文件如图所示
配置环境:在设置中搜索编辑系统环境变量。然后点击环境变量,找到path双击,将解压后的Apache-maven-3.6.0-bin.zip的目录输入就算配置完成 检验环境:win+r,输入cmd,输入命令mvn-version
配置本地仓库地址:存放maven下载的jar文件的文件夹,我们需要字Maven的服务器解压文件中找到conf文件夹下载的settings.xml文件进行修改。
配置maven
conf--config配置
settings.xml
配置本地仓库位置
配置阿里云镜像地址(为下载提高速度)
通过mven构建项目
配置镜像仓库(推荐):同样是settings.xml文件,找到<mirrors>在中间放入maven的镜像仓库如下,目的是下载jar文件更快
<mirror>
<id>aliMaven </id>
<name>aliyun Maven </name>
<url>http://Maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
进入idea进行设置
file - new projects settings - settings new for projects
bbuild - buid tools - maven 框选两个override,第一行改为自己setting.xml的地址
第二行改为自己maven仓库的地址
创建maven工程:
编译环境 -project-
👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习
🌌上期文章:详解SpringCloud微服务技术栈:Nacos配置管理
📚订阅专栏:微服务技术全家桶
希望文章对你们有所帮助
之前使用RestTemplate来实现远程调用,这种方式存在了一些问题,更优的解决方式是使用Feign来实现远程调用。
这里将会讲解如何用Feign实现远程调用,并进行最佳实践。
Feign的远程调用与最佳实践 基于Feign实现远程调用自定义配置性能优化Feign最佳实践分析实现 基于Feign实现远程调用 RestTemplate的问题:
1、代码可读性差,变成体验不统一
2、参数比较复杂的url,难以维护
Feign是一个声明式的http客户端,官方地址:Feign官网
声明式在Spring中开始提到,是利用配置文件来加事务。而声明式http客户端也是类似,我们只需要把发http请求所需要的信息声明出来即可,剩下的东西都交给Feign来实现。
使用Feign的步骤:
1、引入依赖:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> 2、在order-service的启动类添加开启Feign的功能:加注解@EnableFeignClients
3、做声明(编写Feign客户端):
@FeignClient("userservice") //声明出服务名称 public interface UserClient { @GetMapping("/user/{id}") User findById(@PathVariable("id") Long id); } 主要是基于SpringMVC的注解来声明远程调用的信息,如服务名称、 请求方式、请求路径、请求参数、返回值类型等,直接声明这些信息就行。
这样的方式会简单很多,注解开发太方便了,节约了很多学习成本,即便url的参数很复杂,我们利用注解开发写参数列表也是很方便的。
现在我们可以直接使用这个客户端了,直接修改order查询的接口:
@Resource private OrderMapper orderMapper; @Resource private UserClient userClient; public Order queryOrderById(Long orderId){ //查询订单 Order order = orderMapper.findById(orderId); //根据用户id来查询用户,用Feign实现远程调用 User user = userClient.findById(order.getUserId()); //将用户注入到order中 order.setUser(user); // 4.返回 return order; } 同时多次刷新网址,可以验证出Feign还集成了Ribbon负载均衡,是比较强大的。
总结Feign使用步骤:
来源:宏集科技 工业物联网 宏集干货丨探索物联网HMI的端口转发和NAT功能
原文链接:https://mp.weixin.qq.com/s/zF2OqkiGnIME6sov55cGTQ
欢迎关注虹科,为您提供最新资讯!
#工业自动化 #工业物联网 #HMI
前 言 端口转发和NAT功能常用于内网穿透,实现内部网络和外部网络之间的数据传输,工作人员通过外部网络便可安全访问到内网设备,实现设备的状态监测。接下来小编将为大家介绍支持端口转发和NAT功能的宏集物联网HMI是如何帮助用户实现内网穿透。
端口转发和NAT 宏集物联网HMI提供基于HTML的系统设置页面,用户可以本地访问或者通过Web浏览器远程访问,进而完成物联网HMI的功能/服务设置。
通过“服务-<Router/NAT/Port forwarding”路径进入HMI的端口转发和NAT功能配置界面,如下图所示。用户可以根据实际需求添加多个端口转发/NAT规则,解决现场问题。
本文以内网IP摄像头为例,介绍如何通过宏集物联网HMI的端口转发和NAT功能实现IP摄像头画面的实时访问。
1. 端口转发 创建并启用端口转发规则,设置规则名称,源接口等信息,其中:
(1)源接口:HMI设备连接外网的以太网口,本例为eth2,IP地址为192.168.20.7;
(2)源端口:外网访问端口号,支持自定义,本例为80;
(3)设备IP:内网IP摄像头的IP地址,本例为192.168.50.1;
(4)设备端口:内网IP摄像头的端口号,本例为80。
最终的参数配置和实际效果如下所示。
通过外网(192.168.20.7)访问内网(192.168.50.1)IP摄像头画面
2. NAT 创建并启用NAT规则,设置规则名称,源接口等信息,其中:
(1)源接口:HMI设备连接外网的以太网口,本例为eth2;
(2)源IP:外网访问IP地址,与源接口在一个网段,本例为192.168.20.23;
(3)设备IP:内网IP摄像头的IP地址,本例为192.168.50.1;
(4)设备端口:指定内网IP摄像头的端口号/端口范围或者留空,本例为留空。
注:源IP不能与源接口的IP地址一样,设备端口留空表示开放所有端口。
最终的参数配置和实际效果如下所示。
通过外网(192.168.20.23)访问内网(192.168.50.1)IP摄像头画面
总结 端口转发和NAT功能的引入增强了物联网HMI的网络安全性,NAT功能隐藏了内部网络的实际IP地址,减少了来自外部的直接攻击风险。同时,端口转发可以控制对HMI设备的访问,只允许特定的请求通过指定的端口访问。
此外,端口转发和NAT功能为物联网HMI提供了灵活的网络配置,轻松建立和设备的连接并实现数据传输,进而使得HMI设备可以与多个网络环境进行集成,适配不同的工业应用场景。
python使用Apache+mod_wsgi部署Flask 一、安装python环境(V3.10.10)二、安装mod_wsgi三、安装Apache1、下载2、解压3、配置 四、安装项目依赖五、启动六、基于多端口部署多个flask项目 一、安装python环境(V3.10.10) 安装时勾选"Add python.exe to PATH"就不需要手动配置环境变量了:
直接下一步即可:
选择自己的安装目录:
安装完成后验证是否安装配置成功,打开cmd,输入如下命令:
python -V 如下则表示配置成功:
二、安装mod_wsgi 下载地址
注意要和Python版本一样,Python 3.10选择cp310,这里我选择的是 mod_wsgi-4.9.2-cp310-cp310-win_amd64.whl
在下载文件目录打开cmd输入如下命令进行安装:
pip install mod_wsgi-4.9.2-cp310-cp310-win_amd64.whl 安装成功如下所示:
项目目录下创建main.wsgi
import sys #path 替换成自己的项目目录 sys.path.insert(0,"D:/File/first_flask") #first_flask是主程序,根据自己的填写 from first_flask import app application = app 三、安装Apache 官网点击这里
1、下载 点击"Download"
点击"Files for Microsoft Windows"
点击"Apache Lounge"
选择与自己系统匹配的安装包进行下载
2、解压 3、配置 配置文件位于解压目录下:Apache24/conf/httpd.cnf
配置SRVROOT,修改为自己的目录即可,注意路径格式,最后一层路径没有"/"
配置监听端口,根据自己需要进行配置:
打开如下的配置信息(删除最前面的#):
打开cmd输入如下命令,将输出结果添加到配置文件中:
mod_wsgi-express module-config 输入结果第二行信息就是我们需要的信息:
将如上信息添加到httpd.conf文件中
在文件末尾添加如下信息(注意修改相关配置):
<VirtualHost * > ServerName flask.com #可以不配置,有域名可以自行配置 WSGIScriptAlias / "
近年来,邮件安全问题日益突出,电子邮件成为诈骗、勒索软件攻击的重灾区。恶意邮件的占比屡创新高,邮件泄密事件更是比比皆是。在如此严峻的网络安全形势下,使用S/MIME电子邮件证书进行邮件收发是当今最佳的邮件安全解决方案之一。接下来小编就为大家奉上S/MIME电子邮件证书申请指南,希望能对你有所帮助。
S/MIME电子邮件证书申请指南
1、确定版本
在申请之前需要先确定选择个人还是企业版本,然后提供需要申请具体的邮箱。个人版本的电子邮箱证书,只需配合接收邮件确定身份。企业版本的电子邮箱证书,除了配合接收邮件确定身份,还需要进行域名验证和企业信息审核。
2、提交邮箱
申请人确定好邮箱地址,然后就可以提交锐成申请机构进行验证。
3、Email验证
证书绑定邮箱将收到一封验证邮件,打开邮件中的链接,并输入邮件中的验证码,点击确定,即可完成Email验证。
4、下载证书
回到邮箱,等待一会儿就会收到证书签发邮件,将收到的签发邮件的附件下载下来,你就拥有了一张全球信任的邮件证书,可以配置到支持S/MIME协议的邮件客户端,开启更加安全的邮件沟通方式。
使用S/MIME电子邮件证书的好处
邮件全程安全:使用电子邮件证书加密电子邮件内容及附件,只有指定收件人可以解密阅读。加密后的电子邮件即使被窃取、被泄露也是密文状态,没有私钥无法解密邮件内容,确保电子邮件全程安全。邮件来源可信:电子邮件证书经权威CA机构验证后颁发,可验证发件人真实身份,确认邮件来源可信,防止钓鱼邮件或带毒邮件仿冒发件人进行钓鱼攻击。 总之,使用电子邮件证书签名加密电子邮件,是抵御电子邮件安全威胁的有效手段。在申请S/MIME电子邮件证书时,基于安全性和兼容性考虑,请选择值得信赖证书颁发机构,因为这些权威的第三方CA颁发的邮件证书安全可信,并且可以应用到大多数邮件客户端上,以便更顺利地保护您的信息安全。如您还有其他疑问或需求,请联系我们获得支持。
前言 这边篇文章主要是来讲解我们日常开发中碰到一些Maven包冲突的一个解决方案。如何去一步一步进行排查,然后找到思路解决某一个固定的痛点和问题。在我们日常的导入包当中,可能不经意间就会导入一些相同类名的包或者路径的包。因为不同的包,它可能依赖某一个版本的可能不是同一个版本,这样就会导致一个冲突产生。可能版本不一致也有一定的原因。
问题 这里主要是在讲我在开发中碰到一个类名冲突的一个问题。因为我导入的一个类的路径跟我想要的另一个类的路径重合了,但是版本和依赖却不一致。所以才产生了接下来的一个解决问题的过程。
排查问题 这里主要是在讲,我们进行一个pom文件的包导入的时候,在旁边可以清楚的看到对应的一个包的引用。你可以进行一个筛选。在这里你可以看到一些冲突的包,可以展示他的列表或者树状类型。这里尤其强调的一个点就是当我们需要找到某个包的时候,我们可以指定跳到它对应的jar包上面,也就是那类的实际代码上面,可以在Idea上面直接看到对应的jar,不得不说这是非常方便的一个工具。
查找冲突 接着就是我们常见的一些jar包冲突的一些检查方法,在这里我们就可以看到。不同的包,但是它引用了同一个子版本的包,而且包路径相包的名字版本号是一致的,这就导致了一个冲突了。只需要排除对应的引用就好。
图形预览 另外还有一种查看方式,就是通过一个图表的表格方式去查看不同的包之间的一个引用。在这里有一个点,主要是当你包引用的足够多的时候,就变得很卡顿。而且检索起来也很慢,但这种方式非常的直观看,有取舍吧。
同样的,在这里你也可以去寻找你想要的包。进行一个跳跃到对应的实际的包和类。
maven命令查找 另外还有一种方式是直接通过maven命令的方式去查找对应的一个包。
mvn dependency:tree -Dverbose -Dincludes=org.mockito:mockito-core [INFO] --- maven-dependency-plugin:3.1.1:tree (default-cli) @ agent --- [INFO] Verbose not supported since maven-dependency-plugin 3.0 [INFO] com.nogle.util:agent:jar:2.0 [INFO] \- org.mockito:mockito-inline:jar:4.5.1:test [INFO] \- org.mockito:mockito-core:jar:4.5.1:test 解决方案 最后,在这里我找到了两个不同版本的包相冲突了,而且是来自不同的依赖,这样就好办了,我只需要删除或者排除对应的一个依赖就可以解决冲突这个问题。
maven配置环境 在最下面主要是我贴的一个。配置mvn环境的一个方式,因为有些时候可能我们用的idea的默认的一个maven的配置。从而导致你在终端无法进行一个mvn命令的操控。这就是详细的一个配置环境的过程。
vim ~/.bash_profile export M2_HOME=/apache-maven-3.6.3 export PATH=$M2_HOME/bin:$PATH source ~/.bash_profile 总结 最后我想说的是当发现一个问题的时候,我们需要逐步拆解,一步一步找到我们需要处理的问题的点。不得不说idea这个编辑器还是非常强大的。今天这篇文章主要是对我的一个解决冲突的一个思路的回顾。
最后 点赞关注评论一键三连,每周分享技术干货、开源项目、实战经验、国外优质文章翻译等,您的关注将是我的更新动力!
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 设计目标2.2 研究内容2.3 研究方法与过程2.3.1 系统设计2.3.2 查阅文献2.3.3 网站分析2.3.4 网站设计2.3.5 网站实现2.3.6 系统测试与效果分析 三、系统展示四、核心代码4.1 查询民间文学4.2 查询传统音乐4.3 增改传统舞蹈4.4 网页页签4.5 网页数据展示 五、免责说明 一、摘要 1.1 项目介绍 基于JAVA+Vue+SpringBoot+MySQL的陕西非物质文化遗产网站,包含了陕西地市、民间文学、传统音乐、传统舞蹈、传统戏剧、传统体育模块,还包含系统自带的用户管理、部门管理、角色管理、菜单管理、日志管理、数据字典管理、文件管理、图表展示等基础模块,陕西非物质文化遗产网站基于角色的访问控制,给视频管理员、普通用户使用,可将权限精确到按钮级别,您可以自定义角色并分配权限,系统适合设计精确的权限约束需求。
1.2 项目录屏 二、功能模块 非物质文化遗产与互联网相结合,为非物质文化遗产的数字化传播提供了重要契机。作为十三朝古都的陕西省,存在着大量的工艺美术、民间传 说、音乐、礼仪等非遗资源。目前陕西的部分非遗数字化资源可以通过相关的博物馆网站浏览和欣赏,但对数量庞大的陕西非遗资源来说,目前这种分布式资源不利于用户系统化的了解陕西非遗文化。因此,构建一个陕西非物质文化遗产资源欣赏专题网站,帮助用户系统化的了解陕西非遗文化,塑造大众心目中独特的陕西文化IP形象。
2.1 设计目标 网站应主要包括后台数据库设计和前端应用程序的开发两个方面。对于前者要求研究并建立起数据一致性和完整性强、数据安全性好的数据库;后者则要求应用程序功能完备,具有界面美观、易操作、易使用等特点。
2.2 研究内容 对于非遗的分类,依据国家2021年非遗名录对非遗类型的划分,分为民间文学、传统音乐、传统舞蹈、传统戏剧、曲艺、传统体育、游艺与杂技、传统美术、传统技艺、传统医药、民俗11大类。网站的建设采用用户和管理员两大系统,用户系统可以查看网站首页、科普页、个人中心等,管理员可用户管理、系统管理,一方面方便用户了解陕西非遗文化,同时方便后台人员对于网站的管理。
2.3 研究方法与过程 2.3.1 系统设计 网站可以使用 IDEA 为主要开发者工具,使用 MySQL 为数据库开发平台,Windows10 操作系统为运行环境。前台运用 Vue 和 JavaScript 等前台布局脚本语言,后台运用 JAVA 技术进行开发。
2.3.2 查阅文献 了解陕西非物质文化遗产现状,明确基于JavaSript 建立陕西非物质文化遗产网站的意义和价值。
2.3.3 网站分析 对项目进行用户需求分析、系统功能分析、网站架构分析、网站界面分析等。
2.3.4 网站设计 进行系统结构设计、功能模块设计、数据库设计、UI界面设计等内容。
2.3.5 网站实现 软硬件环境准备、系统功能实现。
2.3.6 系统测试与效果分析 完成所有系统功能后,设计测试计划,对系统功能进行测试与效果分析。
三、系统展示 四、核心代码 4.
FlashDuty:一站式告警响应平台,前往此地址免费体验!
值班管理 UI 交互优化 【个人日程】从头像下拉菜单调整到值班列表页面,快速查看个人值班日程【值班列表】支持原地预览最近一周值班情况,包括当前和下一阶段值班人【值班详情】支持日历模式与时间线模式切换,查看月度计划更方便【规则调整】支持直接点击日历进行规则编辑或调班,提升调班效率【规则添加】批量选人自动分组,可拖动调整人员顺序 轮换能力增强 【轮换周期】:从 每天/每周 扩展为 N小时/N天/N周/N月,轮换起止时间从 半小时 精度提升到 分钟 级别。现有周期维度可满足任何类型的轮换需求。【公平轮换】:新增公平轮换功能,此模式下系统将自动调整轮换顺序,确保每个成员都有机会在不同的时间段或轮次中参与值班。比如避免某个成员始终在休息日值班。【周期内限定值班时间】:限定成员在周期内的值班时间,比如轮换周期为1天,但成员仅值班其中的8个小时。需要注意,当您设置此项,故障可能因轮空导致无人响应。现在限定时间支持同时设定多段。 通知能力增强 除了更好的交互和轮换能力,我们通常也需要更灵活的值班轮换通知能力,现在这些都有了!
新增单聊推送能力,飞书/钉钉/企业微信应用 点对点推送换班通知新增群聊应用推送, 飞书/钉钉/Slack应用 群聊推送换班通知,并对值班人进行@提醒支持提前 5X 分钟进行推送换班通知换班通知将同时展示当前值班人与下一阶段值班人信息 另外,我们对所有客户开放了全新的 值班管理 API,相比旧版本更加易用。旧版本 API 将于2024-06-01下线,请您及时迁移。
服务日历 什么是服务日历 服务日历是指在IT系统中用于计划和跟踪服务可用性和维护窗口的日历。典型的像证券交易系统:我们可以设置股市开闭市日期,并在闭市期间静默告警通知。
在静默策略中,选择服务日历相比星期模式,具有更大的灵活性。下图配置了【非交易时间静默】规则,以A股为例,设置了:
非交易日全天告警通知静默交易日的非交易时间告警通知静默 如何设置服务日历 进入服务日历菜单,可以看到服务日历列表,每个账户最多可创建10个服务日历,请注意该功能仅在专业版提供。
进入服务日历详情,可以设置以下内容:
选择星期几为工作日,一般为周一至周五,系统会自动标识出来选择关联地区法定假日,比如中国大陆节假日,系统将自动同步国务院数据,您无需手动配置点击日历,按需配置工作日或非工作日规则,这些规则将覆盖节假日和星期数据 关于服务日历,更多详情请到控制台体验!
自定义操作 什么是自定义操作 自定义操作本身是一个 Webhook 调用,您可针对不同协作空间的故障增加自定义操作,并在故障详情中手动触发该操作,以实现如快速排障或信息同步。
自定义操作常见使用场景:
重启主机:当主机内存或 CPU 打满,触发主机重启脚本,快速完成主机重启。信息丰富:当故障发生时,回调您的服务,根据告警详情调取 Tracing、Logging、拓扑等信息,主动调用 FlashDuty Open API 来更新故障信息,比如增加标签或设定自定义字段,辅助排障。回滚变更:当发生故障时,如果确定故障由变更导致,可以直接触发回调到您的部署平台,开启回滚进程,加速故障恢复。更新 Status Page:当确定故障影响到线上服务,可以触发外部 Status Page 更新,及时的通知到您的客户或上下游。 如何设置自定义操作 您可以在【集成中心-Webhook】页面创建自定义操作,如下图:
您可以设置自定义操作所应用的空间列表,注意:一个协作空间至多关联三个自定义操作。
创建后,您可以在对应空间的【故障详情-更多操作】下看到操作按钮,点击按钮系统会提示操作结果。如果操作成功,系统会写入操作记录。
关于自定义操作,更多详情请到控制台体验!
邮件集成 创建邮件集成 Flashduty现已支持通过邮件来推送告警了!推荐您在以下两个场景中使用:
您现有的监控工具不支持推送到Flashduty,但支持推送邮件您的客户通过邮件向您提报故障工单 您可以在【集成中心-告警事件】配置 Email 集成:
配置邮件集成 默认系统会帮您生成一个唯一的邮件地址,您可以进行修改。默认系统总是为每一封邮件创建新的告警,但您可以定制触发和关闭规则,如下图所示: 关于邮件集成,更多详情请到控制台体验!
解决办法: 通常只需要index.html 不缓存即可, 其他文件都是根据index.html 中的引用去加载;
正确的做法是在 站点下增加 web.config 文件, 内容如下:
我这个是因为目录下有个config.js 配置文件, 也不能缓存, 所以加了两个
<?xml version="1.0" encoding="UTF-8"?> <configuration> <location path="index.html"> <system.webServer> <staticContent> <clientCache cacheControlMode="NoControl" /> </staticContent> <httpProtocol> <customHeaders> <add name="Cache-Control" value="no-store" /> </customHeaders> </httpProtocol> </system.webServer> </location> <location path="config.js"> <system.webServer> <staticContent> <clientCache cacheControlMode="NoControl" /> </staticContent> <httpProtocol> <customHeaders> <add name="Cache-Control" value="no-store" /> </customHeaders> </httpProtocol> </system.webServer> </location> </configuration> 效果:
1、如图所示,class="main-table-span title" 中有空格 如果直接通过
driver.findElement(By.classname(".main-table-span title"));来进行定位界面会出现报错
2、可以在classname的前面和空格处用.号代替通过css来定位,如下:
driver.findElement(By.cssSelector(".main-table-span.title")); 3、参考链接
seleniunm定位className有空格_classname定位元素有空格-CSDN博客
在数字化的浪潮中,一套高效的数据管理系统是企业竞争力的核心。从传统的数据库到现代的数据中台,每一种技术都在数据的旅程中扮演着关键角色。本文将深入探讨数据库、数据仓库、数据湖、大数据平台以及数据中台的功能和价值,帮助您构建一个符合自身业务需求的高效数据生态系统。
数据库:企业数据的基石
数据库,尤其是关系型数据库,是管理结构化数据的传统工具。它主要用于处理日常事务,例如银行交易和记录管理。这些数据库优化了读写操作,确保了数据完整性和一致性,是企业信息系统不可或缺的基础部分。
数据仓库:决策支持的数据基础
数据仓库系统,主要支持在线分析处理(OLAP),为复杂的数据分析提供支持。它存储了整理过的历史数据,便于企业进行总结性分析和决策支持。数据仓库的出现使得企业能够从历史趋势中获取洞见,进而指导业务策略。
数据集市:专业领域的数据精炼厂
数据集市可以视作数据仓库的一个子集,它关注特定主题的数据,为特定部门或业务线提供精细化的决策支持。数据集市强调数据的局部相关性和快速访问,是数据仓库策略的补充和延伸。
数据湖:未来数据运营的蓄水池
数据湖是存储各种格式原始数据的大型存储系统,它不仅支持数据的存储和归档,还支持强大的处理和分析能力。数据湖的设计理念是使得企业可以在单一的平台上管理所有数据,并为数据科学和高级分析提供强有力的支撑。
大数据平台:海量数据处理的引擎
大数据平台是为了应对海量、多样化数据的存储与计算而生的基础设施。它利用分布式计算技术处理巨量数据,支持实时数据流的分析。通过使用大数据平台,企业能够迅速作出数据驱动的决策,快速适应市场和客户需求。
数据中台:数据价值转化的关键
数据中台是一个集成式的平台,它不仅包括了数据存储、处理的能力,还包括数据标准的制定、数据质量的管理、数据服务的输出等。数据中台的目标是消除数据孤岛,通过数据的共享和复用,提高数据应用的效率和企业数据运营的灵活性。
数据管理工具的选型与应用
选择合适的数据管理工具,对企业的数据治理架构至关重要。传统数据库适合处理日常事务性数据。数据仓库和数据集市则更侧重于分析和决策支持。数据湖和大数据平台对于存储和处理大规模、多样化的数据至关重要。而数据中台,则为企业提供了一个全面的数据解决方案,它整合了存储、分析、管理等多个方面的功能,支撑数据驱动的业务创新。
在构建您的数据生态时,重要的是认识到这些工具并不是相互排斥的,而是应该根据具体业务需求和数据策略相互结合使用。一个高效的数据生态系统,应该能够灵活地应对不断变化的市场环境和业务需求,为企业的成长和创新提供强大的数据支撑。
随着数据技术的不断进步,企业的数字化转型趋势愈加明显。了解和选择合适的数据管理工具,能够帮助企业更好地管理和利用数据,最终实现数据价值的最大化。无论是传统的数据库还是现代的数据中台,每种技术都有其独特的价值和应用场景。构建一个高效的数据生态系统,需要企业对这些工具有深入的理解和正确的应用。
你是否已经习惯了在ArcGIS中数据视图和布局视图之间来回切换,到了ArcGIS Pro中却找不到二者之间切换的按钮,即使新建布局后却发现地图怎么却是一片空白。
这一切的一切都是因为ArcGIS Pro的功能框架完全不同,这里为大家介绍一下在ArcGIS Pro怎么新建布局,希望能对你有所帮助。
新建布局 在菜单栏上选择插入,点击新建布局下拉箭头,选择一个合适的尺寸,如下图所示。
新建布局
点击后完成布局的新建,新建的布局如下图所示。 新建的布局
加载地图 从上面的图中可以看到,虽然新建了布局,但是地图还是空白的,如果想要显示地图还需要加载一下,将地图加载进来。
在菜单上点击地图框,选择需要加载的地图,如下图所示。 选择地图框
在新建的布局上绘制一个框,作为地图显示的范围,绘制后可以看到地图已经完成加载,如下图所示。
加载的地图
结语 以上就是ArcGIS Pro如何新建布局的详细说明,主要包括了新建布局和加载地图等功能。
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 搞笑视频模块2.3 视频收藏模块2.4 视频评分模块2.5 视频交易模块2.6 视频好友模块 三、系统设计3.1 用例设计3.2 数据库设计3.2.1 搞笑视频表3.2.2 视频收藏表3.2.3 视频评分表3.2.4 视频交易表 四、系统展示五、核心代码5.1 查询搞笑视频5.2 加购搞笑视频5.3 搞笑视频打分5.4 搞笑视频收藏5.5 添加好友 六、免责说明 一、摘要 1.1 项目介绍 基于JAVA+Vue+SpringBoot+MySQL的快乐贩卖馆管理系统,包含了视频模块、视频收藏模块、视频打分模块、视频交友模块、视频购物车模块和视频订单模块,还包含系统自带的用户管理、部门管理、角色管理、菜单管理、日志管理、数据字典管理、文件管理、图表展示等基础模块,快乐贩卖馆管理系统基于角色的访问控制,给视频管理员、普通用户使用,可将权限精确到按钮级别,您可以自定义角色并分配权限,系统适合设计精确的权限约束需求。
1.2 项目录屏 二、功能模块 随着互联网行业各种业务的兴起和发展,这一领域的市场竞争也日趋激烈。从视频网站的角度来看,主要的视频网站并未像许多人认为的那样在激烈的市场竞争中真正获利。相反,连续的损失是视频网站面临的最困难的问题。快乐贩卖馆系统是一套交易搞笑视频的系统,用户可以在其中自由交易搞笑视频。
快乐贩卖馆系统基于Java语言开发,采用前后端分离的技术架构,前端采用Vue.js,后端采用SpringBoot框架,采用MySQL数据库。
快乐贩卖馆系统的功能性需求主要包含数据中心模块、搞笑视频模块、视频收藏模块、视频评价模块、视频交易模块、视频好友模块这六大模块,系统是基于浏览器运行的web管理后端,其中各个模块详细说明如下。
2.1 数据中心模块 数据中心模块包含了快乐贩卖馆系统的系统基础配置,如登录用户的管理、运营公司组织架构的管理、用户菜单权限的管理、系统日志的管理、公用文件云盘的管理。
其中登录用户管理模块,由管理员负责运维工作,管理员可以对登录用户进行增加、删除、修改、查询操作。
组织架构,指的是高校的组织架构,该模块适用于管理这些组织架构的部门层级和教师的部门归属情况。
用户菜单权限管理模块,用于管理不同权限的用户,拥有哪些具体的菜单权限。
系统日志的管理,用于维护用户登入系统的记录,方便定位追踪用户的操作情况。
公用云盘管理模块,用于统一化维护快乐贩卖馆系统中的图片,如合同签订文件、合同照片等等。
2.2 搞笑视频模块 搞笑视频是快乐贩卖馆系统的核心,需要建立搞笑视频模块对其进行管理,搞笑视频的数据包括视频名称、视频介绍、视频价格、文件、排序值、备注、创建人、创建时间、更新人、更新时间,用户可以发布新的搞笑视频,管理员可以对用户发布的搞笑视频进行删除操作。
2.3 视频收藏模块 如果用户对某个视频非常满意,可以对其进行收藏,以便于后续快捷浏览,视频收藏的字段包括视频ID、视频名称、收藏时间、备注、创建人、创建时间、更新人、更新时间,用户可以对搞笑视频进行收藏操作,管理员可以查询用户的收藏数据。
2.4 视频评分模块 在快乐贩卖馆系统中,用户可以对搞笑视频进行评价,以此达到交互的效果,视频评分的数据包括视频ID、视频名称、视频文件、评分数值、创建人、创建时间、更新人、更新时间,用户可以对搞笑视频进行评分操作,管理员可以查询用户的评分数据。
2.5 视频交易模块 用户可以购买搞笑视频,购买需要消耗余额,余额来源自上传的搞笑视频,视频交易字段包括视频ID、视频名称、视频文件、付款状态、创建人、创建时间、更新人、更新时间,用户可以对搞笑视频进行下单、付款操作,管理员可以查询用户的交易数据。
2.6 视频好友模块 如果用户对视频的发布者很感兴趣,可以添加单向好友,方便留档,视频好友的字段包括所属人、好友ID、好友昵称、好友手机、创建人、创建时间、更新人、更新时间,用户可以添加搞笑视频的创作者,管理员可以查询用户添加的好友数据。
三、系统设计 3.1 用例设计 3.2 数据库设计 3.2.1 搞笑视频表 3.2.2 视频收藏表 3.2.3 视频评分表 3.
1、el-table指定 row-key属性为row.id 确保唯一性
2、el-table-column设置reserve-selection属性为true 会在数据更新之后保留之前选中的数据(reserve-selection 仅对 type=selection 的列有效)
文章目录 一、管理事务处理1.事务处理2. 控制事务处理 二、全球化和本地化1. 字符集和校对顺序2. 使用字符集和校对顺序 三、安全管理1. 访问控制2. 管理用户2.1 创建用户账号2.2 删除用户账号2.3 设置访问权限2.4 更改口令 四、数据库维护1. 备份数据2. 进行数据库维护3. 诊断启动问题4. 查看日志文件 一、管理事务处理 1.事务处理 并非所有引擎都支持明确的事务处理管理。MyISAM和InnoDB是两种最常使用的引擎。前者不支持明确的事务处理管理,而后者支持。
事务处理:(transaction processing)可以用来维护数据库的完整性,它保证成批的MySQL操作要么完全执行,要么完全不执行。
事务处理是一种机制,用来管理必须成批执行的MySQL操作,以保证数据库不包含不完整的操作结果。
利用事务处理,可以保证一组操作不会中途停止,它们或者作为整体执行,或者完全不执行(除非明确指示)。如果没有错误发生,整组语句提交给(写到)数据库表。如果发生错误,则进行回退(撤销)以恢复数据库到某个已知且安全的状态。
事务处理的几个术语:
事务(transaction)指一组SQL语句;回退(rollback)指撤销指定SQL语句的过程;提交(commit)指将未存储的SQL语句结果写入数据库表;保留点(savepoint)指事务处理中设置的临时占位(placeholder),你可以对它发布回退(与回退整个事务处理不同)。 2. 控制事务处理 MySQL使用下面的语句来标识事务的开始:
START TRANSACTION 使用ROLLBACK SELECT * FROM ordertotals; START TRANSACTION; DELETE FROM ordertotals; SELECT * FROM ordertotals; ROLLBACK; SELECT * FROM ordertotals; ROLLBACK只能在一个事务处理内使用(在执行一条START TRANSACTION命令之后)
使用COMMIT
一般的MySQL语句都是直接针对数据库表执行和编写的。这就是所谓的隐含提交(implicit commit),即提交(写或保存)操作是自动进行的。
在事务处理块中,提交不会隐含地进行。为进行明确的提交,使用COMMIT语句. START TRANSACTION DELETE FROM orderitems WHERE order_num = 20010; DELETE FROM orders WHERE order_num = 20010; COMMIT; 使用保留点
ERROR1:xxx .exe 已触发了一个断点。 EIGEN_USING_STD(free) free(ptr); 解决办法:项目属性->C/C++->代码生成->启用增强指令集->选择高级矢量扩展(/arch:AVX)
ERROR2:error C2664: 无法将参数 1 从“std::shared_ptr<pcl::PointCloud<pcl::PointXYZ>>”转换为“boost::shared_ptr<pcl::PointCloud<pcl::PointXYZ>> &” 解决办法:boost::shared_ptr改成std::shared_ptr
ERROR3:pcl1.12.1编译错误 解决办法:屏蔽头文件:#include <pcl/io/io.h>
ERROR:4:params.h(44): message : 参见“flann_algorithm_t”的声明 解决办法:调整头pcl和opencv文件位置或者属性列表位置
ERROR5:“CV_RGB2BGR”: 未声明的标识符 解决办法:添加头文件: #include "opencv2/imgproc/types_c.h"
ERROR6: pcl 1.12 ia_fpcs.hpp文件中 #pragma omp flush(abort) 报错 解决办法:将#pragma omp flush(abort) 注释掉
比亚迪发布璇玑 AI 大模型 1 月 16 日,在 2024 比亚迪梦想日活动上,比亚迪正式发布了整车智能化架构「璇玑」及「璇玑 AI 大模型」。
比亚迪产品规划及汽车新技术研究院院长杨冬生称,「璇玑」是行业首个智电融合的智能化架构,让汽车拥有了智能化的「大脑」和「神经网络」,使其可以像高级智慧生命体一样全面感知、集中思考、精准控制和协同执行。
同时,比亚迪「璇玑」AI 大模型,也是首次将人工智能应用到车辆全领域。据介绍,该模型拥有业界最庞大的数据底座、行业领先的样本量和高算力,覆盖了整车三百多个场景,赋予整车智能持续进化的能力。
比亚迪董事长兼总裁王传福表示:「无人驾驶为时尚早,但智能驾驶的时代已经到来。比亚迪 20 万元以上车型未来可选装高阶智能驾驶辅助系统,30 万元以上车型标配」。
微软推出 Copilot Pro 订阅,每月 20 美元 微软推出了针对 Copilot 的全新高级订阅服务——Copilot Pro,并将其适用范围扩展到更多设备和应用。
Copilot Pro 订阅每用户每月收费 20 美元,支持 Windows PC、Web、App 使用,而且「即将登陆手机」。
Copilot Pro 付费用户还能够在 Windows PC、Mac 和 iPad 上体验到支持 Copilot 的 Word、Excel、PowerPoint、Outlook 和 OneNote,前提是同时订阅 Microsoft 365 个人版或家庭版。
微软消费者首席营销官表示,加入 Copilot Pro 的用户还将首批获得 OpenAI 最新模型,从 16 日开始,订阅用户也可以在高峰时段使用 GPT-4 Turbo ,以获得更快的速度和性能。
国内首个 MoE 模型 abab6 上线 MiniMax 官方宣布,经过了半个月的部分客户的内测和反馈,全量发布大语言模型 abab6,这是国内首个 MoE(混合专家)大语言模型。
一、前言
相信您已经学会了如何在Windows环境下以最低成本、无需GPU的情况下运行qwen大模型。现在,让我们进一步探索如何在Linux环境下,并且拥有GPU的情况下运行qwen大模型,以提升性能和效率。
二、术语
2.1. CentOS
CentOS是一种基于Linux的自由开源操作系统。它是从Red Hat Enterprise Linux(RHEL)衍生出来的,因此与RHEL具有高度的兼容性。CentOS的目标是提供一个稳定、可靠且免费的企业级操作系统,适用于服务器和桌面环境。
2.2. GPU
是Graphics Processing Unit(图形处理单元)的缩写。它是一种专门设计用于处理图形和图像计算的处理器。与传统的中央处理器(CPU)相比,GPU具有更高的并行计算能力,适用于处理大规模数据并进行复杂的计算任务。
三、技术实现
3.1. 创建虚拟环境
conda create --name ai python=3.10 3.2. 切换虚拟环境
conda activate ai 3.3. 安装第三方软件包
pip install -r requirements.txt requirements.txt文件:https://github.com/QwenLM/Qwen/blob/main/requirements.txt
具体内容如下:
transformers==4.32.0 accelerate tiktoken einops transformers_stream_generator==0.0.4 scipy 3.4. 代码实现
# -*- coding = utf-8 -*- import traceback from transformers import AutoTokenizer, AutoModelForCausalLM import time modelPath = "/data/model/qwen-1-8b-chat" def chat(model,tokenizer,message,history): position = 0 result = [] try: for response in model.
服务器带宽有什么用,带宽不足怎么办? 服务器带宽是指服务器能够接受和传输数据的速率,通常以每秒传输的数据来衡量。它是支持特定应用服务器网络和因特网访问的单一网络线路,对网络速度、响应时间、应用程序处理速度等方面都有影响。
1、服务器带宽有什么用? ①提升数据传输速度:服务器带宽决定了数据在服务器和用户之间传输的速度。带宽越大,数据传输速度越快,用户访问服务器的速度也就越快。对于网站、视频会议、在线游戏等需要快速传输大量数据的场景尤为重要。
②保障流畅的用户体验:对于许多在线应用,如网页浏览、视频播放等,用户都期望流畅的体验。服务器带宽能够确保即使在大量用户同时访问时,也能提供足够的传输能力,保证应用的流畅运行。
③支持高并发连接:服务器带宽能够支持大量的并发连接。在在线游戏、社交网络等需要处理大量用户同时在线场景中,服务器带宽的这种特性尤其重要。
④支持多种应用需求:服务器带宽的应用广泛,能够支持各种不同的业务需求。例如,视频网站需要大带宽来支持高清晰视频的传输和播放,电商网站需要足够的带宽来处理大量的用户请求和交易数据,在线游戏则需要高带宽来处理大量实时交互数据等。
⑤降低运营成本:对于一些需要大量数据传输和处理的业务如果服务带宽不足,可能会导致数据传输速度慢、用户访问体验差等问题。在这种情况下,企业可能需要增加带宽租赁费用或购买更多的硬件设备来满足需求,这会增加运营成本。因此,合理配置和规划服务器带宽,可以在保证业务正常运行得同时降低运营成本。
2、带宽不足怎么办,如何提升带宽性能? ①升级服务器硬件:通过升级服务器的硬件配置,如增加内存、使用更快的CPU等,可以提高服务器的处理能力,从而提高带宽性能。
②优化网络配置:网络配置不合理会限制服务器的带宽性能。通过优化网络配置,如调整网络设备参数、优化网络拓扑结构等,可以提高网络传输速率,从而提高带宽性能。
③使用高速度存储设备:存储设备的读写速度会影响服务器的带宽性能。使用高速的存储设备,如SSD硬盘,可以提高数据读写速度,从而提高带宽性能。
④采用CDN安全加速:CDN可以将内容缓存到多个节点,从而提高数据传输速度和带宽性能。通过CDN,用户可以从最近的节点获取数据,从而提高访问速度和响应时间。
⑤负载均衡:通过负载均衡技术将请求分发到多台服务器上,可以提高系统的并发处理能力和容错性。负载均衡可以有效地利用服务器资源,提高带宽性能。
⑥优化应用代码:应用代码的执行效率会影响服务器的带宽性能。通过优化应用代码,如减少数据库查询、优化代码逻辑等,可以提高应用执行效率,从而提高带宽性能。
⑦定期维护和监控:定期对服务器进行维护和监控,及时发现和解决潜在的问题和瓶颈,保持服务器的最佳状态,从而提高带宽性能。
1、首先在笔记本搜索栏输入“注册表编辑器”,并以管理员身份运行;
2、按照如下地址打开:
“计算机\HKEY LOCAL MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\NetworkList\Profiles”
左边这部分都是连接过的wifi信息,点开一个右侧就会显示详细信息,包括首次连接时间和最后一次连接时间,如下图所示:
形式化说明技术 概述 非形式化方法的缺点
形式化方法的优点
应用形式化方法的准则
1.应该选用适当的表示方法。
2.应该形式化,但不要过分形式化。
3.应该估算成本。
4.应该有形式化方法顾问随时提供咨询。
5.不应该放弃传统的开发方法。
6.应该建立详尽的文档。
7.不应该放弃质量标准。
8.不应该盲目依赖形式化方法。
9.应该测试、测试再测试。 10.应该重用。
有穷自动机 一个有穷状态机包括下述5个部分:状态集J、输入集K、由当前状态和当前输入确定下一个状态(次态)的转换函数T、初始态S和终态集F
Petri网 Petri网由来: 并发系统中遇到的一个主要问题是定时问题。这个问题可以表现为多种形式,如同步问题、竞争条件以及死锁问题。
用于确定系统中隐含的定时问题的一种有效技术是Petri网,这种技术的一个很大的优点是它也可以用于设计中。
Petri网是由Carl Adam Petri发明的。在性能评价、操作系统和软件工程等领域,Petri网应用得都比较广泛。特别是已经证明,用Petri网可以有效地描述并发活动。
这里的启动要结合上边的输入函数I(t1) = {P2,P4} Z语言 用Z语言描述的、最简单的形式化规格说明含有下述4个部分:给定的集合、数据类型及常数, 状态定义,初始状态,操作。
评价
Z也许是应用得最广泛的形式化语言
(1) 可以比较容易地发现用Z写的规格说明的错误,特别是在自己审查规格说明,及根据形式化的规格说明来审查设计与代码时,情况更是如此。
(2) 用Z写规格说明时,要求作者十分精确地使用Z说明符
(3) Z是一种形式化语言,在需要时开发者可以严格地验证规格说明的正确性。 (4) 虽然完全学会Z语言相当困难,但是,经验表明,只学过中学数学的软件开发人员仍然可以只用比较短的时间就学会编写Z规格说明,当然,这些人还没有能力证明规格说明的结果是否正确。
(5) 使用Z语言可以降低软件开发费用。
(6) 虽然用户无法理解用Z写的规格说明,但是,可以依据Z规格说明用自然语言重写规格说明。经验证明,这样得到的自然语言规格说明,比直接用自然语言写出的非形式化规格说明更清楚、更正确。
概念 优先队列(priority queue)中的元素可以按照任意顺序插入,但会按照有序的顺序检索。不过优先队列并没有对所有元素进行排序,所以迭代处理这些元素,并不需要对它们进行排序。优先队列里面的结构是堆—一个自组织的二叉树,其添加(add)和删除(remove)操作可以让最小元素移动到跟,而不必花时间对元素进行排序
应用场景 任务调度;每一个任务都有一个优先级,任务以随机顺序添加到队列中。每当启动一个新的任务时,都会将优先级最高的任务从队列中删除。
api java.uti.PriorityQueue
/** * 使用默认初始容量(11)创建一个{@code PriorityQueue},根据元素的{@linkplain Comparable 自然顺序}对其进行排序。 */ public PriorityQueue() { this(DEFAULT_INITIAL_CAPACITY, null); } /** * 使用指定的初始容量创建一个{@code PriorityQueue},根据元素的{@linkplain Comparable 自然顺序}对其进行排序。 * * @param initialCapacity 该优先队列的初始容量 * @throws IllegalArgumentException 如果{@code initialCapacity}小于1 */ public PriorityQueue(int initialCapacity) { this(initialCapacity, null); } /** * 使用默认初始容量创建一个{@code PriorityQueue},其中的元素根据指定的比较器进行排序。 * * @param comparator 将用于对此优先队列进行排序的比较器。如果为{@code null},将使用元素的{@linkplain Comparable 自然顺序}。 * @since 1.8 */ public PriorityQueue(Comparator<? super E> comparator) { this(DEFAULT_INITIAL_CAPACITY, comparator); } 具体调用比较器比较:
I2C总线和通信协议详解 (超详细配42张高清图+万字长文) I2C(Inter-Integrated Circuit)通信总线,作为嵌入式系统设计中的一个关键组成部分,其灵活性和高效率使其在高级应用中备受青睐。本文旨在提供关于I2C通信总线的深度解析,包括其基本概念、特点、通信协议,以及在不同场景下的高级应用和最佳实践。I2C接口只有2根信号线,总线上可以连接多个设备,硬件实现简单,可扩展性强。I2C通信协议可以用普通GPIO引脚进行软件模拟。I2C接口主要用于通讯速率要求不高,以及多个器件之间通信的应用场景。
1. I2C总线历史 I2C(Inter-Integrated Circuit)总线是一种重要的串行通信协议,它的历史可以追溯到上世纪80年代初期。以下是对I2C总线历史的详细介绍:
起源: I2C总线技术由荷兰的飞利浦半导体(现在的恩智浦半导体)在1982年开发。最初,这项技术是为了在电视机内部实现简单、高效、低成本的通信而设计的。 设计目标: 设计I2C的初衷是减少电视机等复杂电子系统内部的布线数量,同时也降低制造成本。通过使用只有两根线的通信总线,它有效地减少了器件间连接的复杂性。 技术发展: 随着技术的成熟和普及,I2C协议得到了广泛的应用和扩展。从最初的标准模式(100kHz),发展到快速模式(400kHz)和高速模式(3.4MHz)。 标准化和开放: 虽然最初由飞利浦半导体开发,但I2C协议后来被标准化并广泛应用于多种设备中。飞利浦半导体放弃了对这项技术的专利权,使其成为开放标准。 广泛应用: I2C技术由于其简单性和有效性,已成为嵌入式系统设计中不可或缺的一部分。 2. I2C通信总线基本概念 I2C是一种多主机、两线制、低速串行通信总线,广泛用于微控制器和各种外围设备之间的通信。它使用两条线路:串行数据线(SDA)和串行时钟线(SCL)进行双向传输。
特点 两线制总线:I2C仅使用两条线——串行数据线(SDA)和串行时钟线(SCL)进行通信,有效降低了连接复杂性。
多主多从设备支持:I2C支持多个主设备和多个从设备连接到同一总线上。每个设备都有唯一的地址。
可变的时钟速率:I2C总线支持不同的速率模式,如标准模式(100kbps)、快速模式(400kbps)和高速模式(3.4Mbps)。
同步通信:I2C是一种同步通信协议,数据传输由时钟信号(SCL)来控制。
简单的连接:I2C通信对硬件的要求比较低,很容易在微控制器和外围设备间实现连接。
地址分配:每个I2C设备都通过一个7位或10位的地址来识别,这使得总线上可以连接多个设备。
阻塞传输:I2C支持阻塞传输机制,即主设备可以在传输过程中控制总线,防止其他设备发送数据。
应用广泛:由于其简单和灵活性,I2C被广泛应用于各种电子产品中,如传感器、LCD显示器、EEPROM等。
总线仲裁和冲突检测:在多主模式下,I2C能够处理多个主设备同时尝试控制总线的情况。
低功耗:I2C总线的设计使其成为低功耗的通信方式,适用于电池供电的设备。
基本特征 总线结构: 两线制:使用两条线进行通信,分别是串行数据线(SDA)和串行时钟线(SCL)。多主多从结构:支持多个主设备和多个从设备连接到同一总线上。 通信方式: 同步串行:数据传输同步于时钟信号。字节格式:每个字节由8位数据构成,加上开始和停止条件以及可选的应答位。 时钟速率: 支持多种速率,包括标准模式(100kbps)、快速模式(400kbps)和高速模式(3.4Mbps)。 工作原理 总线控制: 开始和停止条件:通信由主设备通过在SDA线上生成特定的信号模式来开始和结束。地址帧:每次通信开始时,主设备发送一个地址帧来指定与之通信的从设备。 数据传输: 主从通信:主设备控制时钟信号,向从设备发送或接收数据。应答位:每个字节后,接收方 发送一个应答位(ACK)或非应答位(NACK),以告知发送方数据是否被成功接收。
地址和仲裁 设备地址: 7位或10位地址:每个I2C设备都有一个唯一的地址,允许在同一总线上连接多个设备。 总线仲裁: 在多主模式下,当两个主设备同时尝试控制总线时,I2C协议包含仲裁机制以决定哪个设备获得控制权。 3. I2C数据传输流程 数据信号以8位的序列传输。所以在特殊的开始条件发生后,就会出现第一个8位序列,它指示了数据被发送到哪个从设备的地址。每个8位序列之后都会跟随一个称为确认的位。
在大多数情况下,第一个确认位之后会跟着另一个寻址序列,但这次是针对从设备的内部寄存器。在寻址序列之后是数据序列,直到数据完全传输完毕,并以一个特殊的停止条件结束。
开始条件发生在数据线在时钟线仍然高电平的时候变低。之后,时钟开始,并且在每个时钟脉冲期间传输每一位数据。设备寻址序列从最重要的位开始,以最不重要的位结束,实际上是由7位组成的,因为第8位用于指示主设备是向从设备写入(逻辑低)还是从中读取(逻辑高)。
下一个确认位由从设备用来指示它是否成功接收了前一个位序列。所以这次主设备将SDA线的控制权交给从设备,如果从设备成功接收了前一个序列,它将把SDA线拉低到所谓的确认状态。
如果从设备没有把SDA线拉低,这种状态被称为不确认,意味着它没有成功接收前一个序列,这可能由多种原因造成。例如,从设备可能正忙,可能不理解接收到的数据,或者不能再接收任何数据等等。 在这种情况下,主设备决定如何继续操作。
接下来是内部寄存器的寻址。内部寄存器是从设备内存中包含各种信息或数据的位置。
例如,ADXL345加速度计有一个独特的设备地址和额外的内部寄存器地址,用于X、Y和Z轴。 因此,如果我们首先想读取x轴的数据,我们需要发送设备地址,然后发送x轴的特定内部寄存器地址。这些地址可以从传感器的数据手册中找到。
在寻址之后,数据传输序列开始,要么来自主设备,要么来自从设备,这取决于在读/写位选择的模式。
在数据完全发送之后,传输将以停止条件结束,当SDA线在SCL线高电平时从低变高。这就是I2C通信协议的工作原理。
上述内容出现了很多特定概念,我们下面来分别解释他们:
1. SDA和SCL信号 SDA和SCL都是双向线路,通过电流源或上拉电阻连接到正电源电压(见图3)。 当总线空闲时,两条线路都是HIGH。连接到总线的设备的输出级必须具有开漏极或开集电极来执行有线与功能。I2C总线上的数据可以在标准模式下以高达100 kbit/s的速度传输,在快速模式下可达400 kbit/s,在快速模式+中可达1 Mbit/s,或在高速模式下可达3.
在之前的文章中有介绍U-Boot的编译流程,但我们知道,不同的存储介质可能会接在不同的接口上,如NOR Flash、EMMC和SDRAM等内存的接口是不同的,而不同的接口对应CPU就会映射到不同的内存中。所以如果我们需要运行U-Boot的话,我们就应该根据映射的内存,然后将程序链接到指定的位置。
文章目录 1 链接脚本分析1.1 语法介绍1.2 u-boot.lds分析 2 链接脚本的使用3 链接U-Boot到别的地址 1 链接脚本分析 1.1 语法介绍 在分析之前,建议先学习lds链接脚本的语法,可以参考我的这一篇文章:lds链接脚本基础与例子分析。
SECTIONS { ... secname start ALIGN(align) (NOLOAD) : AT ( ldadr ) { contents } >region :phdr =fill ... } secname和contents是必须的,前者用来命名这个段,后者用来确定代码中的什么部分放在这个段中。start:段重定位地址,也称为VMA,即运行地址。如果代码中有位置相关的指令,程序在运行时,这个段必须放在这个地址上。ALIGN(align):虽然start指定了运行地址,但是仍可以使用BLOCK(align)来指定对齐的要求一这个对齐的地址才是真正的运行地址。(NOLOAD):用来告诉加载器,在运行时不用加载这个段。这个选项只有在有操作系统的情况下才有意义。AT (ldadr):指定这个段在编译出来的映象文件中的地址,称为LMA,即加载地址。若不指定默认加载地址等于运行地址。通过这个选项,可以控制各段分别保存在输出文件中不同的位置。>region :phdr =fill:没用到,不作介绍。 1.2 u-boot.lds分析 u-boot的链接脚本即目录下的u-boot.lds:
OUTPUT_FORMAT("elf32-littlearm", "elf32-littlearm", "elf32-littlearm") OUTPUT_ARCH(arm) ENTRY(_start) SECTIONS { . = 0x00000000; . = ALIGN(4); .text : { *(.__image_copy_start) *(.vectors) arch/arm/cpu/armv7/start.o (.text*) } .__efi_runtime_start : { *(.__efi_runtime_start) } .efi_runtime : { *(.
1.使用Git下载vcpkg仓库(下载比较慢,个人比较喜欢打开下面网址然后用迅雷下载,速度飞快)
git clone "https://github.com/Microsoft/vcpkg.git" 2.下载好之后解压打开文件夹,双击bootstrap-vcpkg.bat文件,如果成功的话会在文件夹里生成一个vcpkg.exe文件。(可能会出现窗口闪退导致没有生成exe文件,开启科学上网就可以解决)
3.到这里vcpkg其实就安装完成了,使用vcpkg来安装库的流程如下:
在vcpkg所在的文件夹按住shift然后单击鼠标右键打开shell窗口安装集成工具 .\vcpkg.exe integrate install 生成配置文件 .\vcpkg integrate project 下载所需要的第三方库(以gflags为例)在下载库之前它会先下载一个powershell的压缩包,但是这个压缩包下载的非常慢,所以建议复制对应的网址,使用迅雷下载(网址就是图片中https://github........这一大段)
下载完成之后放到vcpkg文件夹下面的downloads文件夹里,然后再重新执行第4步的命令。下载完成之后再重新生成配置文件: .\vcpkg.exe integrate project 复制这段内容,然后打开visualstudio的项目终端,然后粘贴回车就OK了
门前那条路
文/李红霞
自小在山间长大,儿时门前的小河、屋后的果木、小伙伴之间的调皮嬉闹、在外贪玩时妈妈的呼唤……这些片段像刻在身体里一样,随着年龄的增长,反而越来越清晰,有时还会出现在梦里。但梦里出现更多的,是家门前的那条路,它承载了我生活里太多的记忆……
现在想想,儿时所上的小学离家足足有五里路。大人们很忙,顾不上接送孩子,我每天都是跟在哥哥姐姐身后,一路飞奔去学校,从来没有觉得路远。一天两个来回,二十里路,或许正是因为小时候的锻炼,才有了后来结实的身体。
可我小小的心也有缺少安全感的时候,那时,我最怕和大黑牛迎面碰上,因为路太窄,没办法躲避。远远地看着一群牛慢腾腾地走来,我小小的心都快要跳出来了。近了,近了,牛已经到跟前,我紧张地站在路边,心儿咚咚地跳着,屏住呼吸,一动不动。时间过得很慢,总觉得牛会攻击我——用它的一对尖角,向我扎来……太可怕了!
好在后来开始修路了。我清晰地记得每家每户都要出劳力,工具是锄头和铁锨,再加上使不完的力气,修路的工程开始了。经过大人们起早贪黑地劳动,两个月过后,一条能通架子车的路修成了。
门前的路宽了,可半道上的陡坡并没有半点变化。每次大人推着沉重的架子车通过时,都需要别人帮忙在后边推一把。因为我家离路口最近,占了"地利",所以这"推一把"的使命就落在了我的身上。每次都是前面拉车的大人弓着背、弯着腰,绳子在肩上勒出一道深深的印儿,在后面推车的我,因为太过用力,手都僵了。
车推上去的时候,我会随地坐在路边喘着粗气歇一会儿。大人这时停下脚步,扶着车子扭过头,喘息着说:"这闺女,中!好好学习吧,长大了就顺着这条路走出去看看……"就是在这样的鼓励下,我的心里埋下了一颗小小的种子:外边的世界是怎样的?顺着这条小路走出去,又会是怎样的一番景象?
外面的世界果真很大,我出去上学了,见到了更宽更平坦的路。在这之后的几年,家乡的面貌也发生了很大的变化,那条小路变成了宽阔的柏油路,而且是双向车道,路中间黄色的标识清晰可见,路边是铁质的护栏,外侧种着五颜六色的花和各种景观树,让人赏心悦目。
再见了,那布满泥泞的羊肠小道!再见了,那满载归来的架子车!再见了,曾经给我希望并带我走出去的那条小路!这所有的再见啊,都是因为我们面前迎来了更为美好的时光……
黄衫褪尽绿裳新
文/陈骏
站在这棵瘦削的树下,轻抚树干——如果不介意,我希望它能更粗壮一些——心中有一阵歉意,潜意识中不止一次升腾过一个想法,该为黄风铃写点儿东西了,可是俗事缠身真的不止是说说而已,一个令人欣喜的灵感刚刚泛起,立刻就被匆忙的脚步抛到了身后,当你回过头,想牵着她一同走,而手中竟是那样空虚,我隐约见她在熙熙攘攘的人群中若隐若现,我告诉自己,我要丢掉她了,心中一阵怅然……
还是说回黄风铃吧。这原是一种陌生的树种,在某一个春节,一下子就黄遍了几乎整个港城,有成规模漫山遍野铺天盖地盛放的,有见缝插针零星散布风姿绰约的,有傲居城中临水倚坡独占春光的,有不拒荒僻抢占一隅吐露芳华的,而不论哪一种,总能吸引着世人追逐的脚步,成就着人们拍摄的欲望和赞美的热情。
黄风铃全称是黄花风铃木,原产墨西哥、中美洲和南美洲,据说是巴西的国花,1997年中国自南美巴拉圭引进栽种。这种来自异域的花卉自有着特殊的性格。
春节之前,黄风铃的枝头就稀稀落落地点缀着些花苞,探头探脑,怯怯的模样,而春节一过,热切的春风畅快地吹拂,所有的花苞,先前羞涩的或是俏皮的,都一股脑儿争先恐后地尽情展示出迷人的风采,娇嫩的花瓣在春日里纵情地绽放,微风吹过,明黄色的花瓣轻轻地颤动,与翻飞的蝴蝶和盘旋的蜜蜂们应和着。春天,就这样热热闹闹地来到了港城。
而此时的黄风铃树上,几乎是没有什么树叶的,一任纤弱又奔放的花朵做着春天的主人,不像别的树上,嫩绿的树叶多少是要分去几分春色的。黄风铃树叶的谦逊与退让,让人觉得这仿佛是一位智者,在低调中蕴蓄着力量,成长着自我,在不当令的时候甘做陪衬,因为他知道,在接下来的一整年中,这棵树注定是由绿色接管的。人们都爱说"上善若水",都吟诵"善利万物而不争"的谦谦君子之风,但真正能做到的,又能有几?在生生不息的时光之河里,赫然闪现着三个智慧的字眼:不必争。
果然,在不到两个星期的时间里,黄风铃花就消了她的颜色,散了她的青春,陆续萎顿在树根附近,化作粒粒春泥去了。而聚于树下膜拜赞叹的人们,也早已没了踪影。
此时的树叶们,便日渐丰润蓬勃起来,叶片长大,颜色也变得绿油油的。可是,春天还没过完呢!树的故事在春日里还有着让你瞠目结舌的变化呢!你以为从此树叶就一往无前地成长,绿荫要主宰这个季节剩下的日子了,谁知黄风铃这个魔术师,把节外生枝又演绎成了节外生果。
在原先开花的位置,陆续绽出一些像豆荚一样的黄褐色的果实,起先还比较柔嫩,但它们成长的速度是惊人的,几乎是一天一个样子,与即将长成的树叶们相比,有一种后来居上的果敢和老成持重的信心。一两个星期里,小豆荚长成了大豆荚,毛茸茸的豆荚膨胀着,满是生的欲望,然后有一天,它们七前八后地炸裂开来,向路下的行人展示生命的奥秘。
成熟的豆荚,坚固的外表下,藏着一颗颗善感的内心。从前有诗人赞过,说荔枝"膜如红缯",娇柔不可方物,而黄风铃的豆荚里,也有一层莹白的薄膜,包裹着米粒大小的种子。熟透了的豆荚,薄膜变得干燥而酥脆,微风过处,一串串撒落到树下——就是十多天前黄花撒落的那片泥土!这是宿命,还是轮回?这是依恋,还是缅怀?
抬头看树上密密匝匝的豆荚,剥开壳,挼一下丰盈的果实,竟触到一根坚硬的果床,原来,在这短短的时间里,这棵树已经为新生命的延续做了一丝不苟的准备,春光短促,生命密码的传递却没有丝毫苟且与随意。
待豆荚落尽,铺展的叶片就会更加自由自在地生长,绿色,要铺满整个校园了。
欢迎大家关注我的B站:
偷吃薯片的Zheng同学的个人空间-偷吃薯片的Zheng同学个人主页-哔哩哔哩视频 (bilibili.com)
目录
1.基于圆覆盖
2.BVH
3.MATLAB自动驾驶工具箱 4 ROS内置的模型
自动驾驶轨迹规划之碰撞检测(一)-CSDN博客
自动驾驶轨迹规划之碰撞检测(二)-CSDN博客
大家可以先阅读前两篇关于碰撞检测算法的介绍 1.基于圆覆盖 圆的性质是圆心到圆周各点等距,这非常适合碰撞检测,如果两个物体能近似为圆,那么两个物体之间是否碰撞,则可以利用两个圆心之间的距离是否大于半径之和就可以判断,但是大部分物体若用圆去近似将产生较大的冗余部分,因此针对汽车,一篇2010年的IEEE IV提出通过多个圆去覆盖车辆,这个方法极大地提高了自动驾驶汽车碰撞检测的计算速度,也是现在广泛使用的方法
但是这个方法仍旧会产生冗余,并且改变覆盖圆的个数难以解决这个问题,因为横向和纵向上的冗余是此消彼长的关系,并且我个人认为汽车最容易发生碰撞的位置其实是汽车的四个角落,但是这种方法在那个地方没有安全距离,如果在圆的半径上补充安全距离,会导致其他地方的冗余距离更大,因此这个方法对于非常狭窄的空间还是不适用的
2.BVH BVH为层次包围盒,通过递归地形式将碰撞检测的任务分解,当大包围盒之间有碰撞,则检测子包围盒之间有没有碰撞,这能够同时提升碰撞检测的精度和速度,但是基于BVH的碰撞检测取决于待检测物体的形状,每个基元都应该预先计算并存储在阵列中。
BVH的一个较好应用可以看这个视频,这篇论文实现了同时提升自动驾驶汽车碰撞检测的精度和速度,能够良好地应用于狭窄的自主泊车中
ITSC2023 | 碰撞检测 | 一种在狭窄空间内自动驾驶汽车自主泊车时的快速准确的碰撞检测方法
3.MATLAB自动驾驶工具箱 在MATLAB中也实现了基于圆覆盖的碰撞检测算法,同时碰撞检测通过栅格地图实现,详细内容可以参考官方给出的自动驾驶工具箱的相关文档
Costmap representing planning space around vehicle - MATLAB - MathWorks 中国
4 ROS内置的模型 对于ROS中的碰撞检测,很多参加智能车或电赛的同学可能比较熟悉,但其实也存在不少误区,有时候不是调参调不出来,而是没有真正理解这些参数的意义
robot_radius:设置机器人的半径,单位是米。如果你的机器人不是圆形的那就需要使用footprint这个参数,该参数是一个列表,其中的每一个坐标代表机器人上的一点,设置机器人的中心为[0,0],根据机器人不同的形状,找到机器人各凸出的坐标点即可,具体可参考下图来设置:
inflation_layer:膨胀层,用于在障碍物外标记一层危险区域,在路径规划时需要避开该危险区域
当你选用了footprint,那么膨胀层就没有意义了,因为只有你是圆形的,障碍物才能进行有意义的闵可夫斯基和运算同时footprint是利用多边形计算代价,在耗算力,如果为了节省算力,可以用圆,冗余的部分当做缓冲就行如果你发现怎么调膨胀距离都会碰,因为膨胀层仅在圆形时有效,因此为了使用有安全距离的footprint,必须直接扩大footprint 通过下图来认识下为何要设置膨胀层以及意义:
虽然我提到footprint情况下膨胀层没用,但是对于全局路径规划,ROS中默认机器人为质点,这时候膨胀层非常有用,假如你全局路径规划贴边走,那么对于实际机器人完全是碰撞的,这时候就需要膨胀障碍物了
关注公众号,发现CV技术之美
大语言模型(LLMs)在各种推理任务上表现优异,但其黑盒属性和庞大参数量阻碍了它在实践中的广泛应用。特别是在处理复杂的数学问题时,LLMs 有时会产生错误的推理链。传统研究方法仅从正样本中迁移知识,而忽略了那些带有错误答案的合成数据。
在 AAAI 2024 上,小红书搜索算法团队提出了一个创新框架,在蒸馏大模型推理能力的过程中充分利用负样本知识。负样本,即那些在推理过程中未能得出正确答案的数据,虽常被视为无用,实则蕴含着宝贵的信息。
论文提出并验证了负样本在大模型蒸馏过程中的价值,构建一个模型专业化框架:除了使用正样本外,还充分利用负样本来提炼 LLM 的知识。该框架包括三个序列化步骤,包括负向协助训练(NAT)、负向校准增强(NCE)和动态自洽性(ASC),涵盖从训练到推理的全阶段过程。通过一系列广泛的实验,我们展示了负向数据在 LLM 知识蒸馏中的关键作用。
如今,在思维链(CoT)提示的帮助下,大语言模型(LLMs)展现出强大的推理能力。然而,思维链已被证明是千亿级参数模型才具有的涌现能力。这些模型的繁重计算需求和高推理成本,阻碍了它们在资源受限场景中的应用。因此,我们研究的目标是使小模型能够进行复杂的算术推理,以便在实际应用中进行大规模部署。
知识蒸馏提供了一种有效的方法,可以将 LLMs 的特定能力迁移到更小的模型中。这个过程也被称为模型专业化(model specialization),它强制小模型专注于某些能力。先前的研究利用 LLMs 的上下文学习(ICL)来生成数学问题的推理路径,将其作为训练数据,有助于小模型获得复杂推理能力。然而,这些研究只使用了生成的具有正确答案的推理路径(即正样本)作为训练样本,忽略了在错误答案(即负样本)的推理步骤中有价值的知识。
如图所示,表 1 展示了一个有趣的现象:分别在正、负样本数据上训练的模型,在 MATH 测试集上的准确答案重叠非常小。尽管负样本训练的模型准确性较低,但它能够解决一些正样本模型无法正确回答的问题,这证实了负样本中包含着宝贵的知识。此外,负样本中的错误链路能够帮助模型避免犯类似错误。另一个我们应该利用负样本的原因是 OpenAI 基于 token 的定价策略。即使是 GPT-4,在 MATH 数据集上的准确性也低于 50%,这意味着如果仅利用正样本知识,大量的 token 会被浪费。因此,我们提出:相比于直接丢弃负样本,更好的方式是从中提取和利用有价值的知识,以增强小模型的专业化。
模型专业化过程一般可以概括为三个步骤:
1)思维链蒸馏(Chain-of-Thought Distillation),使用 LLMs 生成的推理链训练小模型。
2)自我增强(Self-Enhancement),进行自蒸馏或数据自扩充,以进一步优化模型。
3)自洽性(Self-Consistency)被广泛用作一种有效的解码策略,以提高推理任务中的模型性能。
在这项工作中,我们提出了一种新的模型专业化框架,该框架可以全方位利用负样本,促进从 LLMs 提取复杂推理能力。
我们首先设计了负向协助训练(NAT)方法,其中 dual-LoRA 结构被设计用于从正向、负向两方面获取知识。作为一个辅助模块,负向 LoRA 的知识可以通过校正注意力机制,动态地整合到正向 LoRA 的训练过程中。
对于自我增强,我们设计了负向校准增强(NCE),它将负向输出作为基线,以加强关键正向推理链路的蒸馏。
除了训练阶段,我们还在推理过程中利用负向信息。传统的自洽性方法将相等或基于概率的权重分配给所有候选输出,导致投票出一些不可靠的答案。为了缓解该问题,提出了动态自洽性(ASC)方法,在投票前进行排序,其中排序模型在正负样本上进行训练的。
我们提出的框架以 LLaMA 为基础模型,主要包含三个部分,如图所示:
步骤 1 :对负向 LoRA 进行训练,通过合并单元帮助学习正样本的推理知识;
步骤 2 :利用负向 LoRA 作为基线来校准自我增强的过程;
步骤 3 :在正样本和负样本上训练排名模型,在推理过程中根据其得分,自适应地对候选推理链路进行加权。
欢迎大家关注我的B站:
偷吃薯片的Zheng同学的个人空间-偷吃薯片的Zheng同学个人主页-哔哩哔哩视频 (bilibili.com)
目录
1.基于凸优化
2.具身足迹
3. ESDF
自动驾驶轨迹规划之碰撞检测(一)-CSDN博客
大家可以先阅读之前的博客 1.基于凸优化 以此为代表的算法则是OBCA
无论是自车还是障碍物都可以表示为凸多边形,因此可以表示为多个超平面围成的空间
同时,自车与障碍物的避撞表达式就可以写成如下式子
然后就可以作为碰撞约束加入这样一个包含边界约束的最优控制问题中
感兴趣的可以参考原文Optimization-Based Collision Avoidance | IEEE Journals & Magazine | IEEE Xplore 2.具身足迹 这是一个解决连续碰撞检测的概念,因为常用的碰撞检测算法常用于离散点的碰撞检测,忽略了离散点之间可能产生的碰撞,如下图所示
而具身足迹的意思则是在两个离散点之间自动驾驶汽车自身所覆盖的足迹,这并不是一个新的概念,计算机图形学中的扫掠体与这个具身足迹的意义相同。
李柏老师用矩形框去近似具身足迹,也就实现了连续碰撞检测,但是有些保守,不适合狭窄空间,但是安全性较好,具体结合曲率去分析这个具身足迹的性质可以参考原文
Embodied Footprints: A Safety-Guaranteed Collision-Avoidance Model for Numerical Optimization-Based Trajectory Planning | IEEE Journals & Magazine | IEEE Xplore
高飞老师团队在IROS2023里提出了一种隐式SDF,里面也就用到了扫掠体,也就是三维的具身足迹,以连续可微的形式进行避障
Continuous Implicit SDF Based Any-Shape Robot Trajectory Optimization | IEEE Conference Publication | IEEE Xplore
3. ESDF Euclidean Signed Distance Functions,这是一种地图的形式,常用于无人机导航。它可以很方便地对障碍物进行距离和梯度信息的查询,对空中机器人的在线运动规划具有重要意义。
Nginx 篇 【1】简述一下什么是Nginx,它有什么优势和功能?
Nginx 是高性能的 HTTP 和反向代理的服务器,处理高并发能力是十分强大的,能经受高负载的考验,有报告表明能支持高达 50,000 个并发连接数。Nginx主要提供功能有
http服务器
反向代理服务器
负载均衡服务器
动静分离配置
缓存数据
【2】简述一下什么是正向代理,什么是反向代理
正向代理代理的是客户端访问服务端,比如防火墙,反向代理代理的是服务端,等待客户端访问代理服务。具体配置如下:
【3】解释一下什么是Nginx的负载均衡
nginx反向代理tomcat服务集群,当客户端访问nginx服务器时,由nginx负载均衡去访问tomcat集群中的某一个节点。具体配置:
【4】说一下什么是动静分离
静态资源配置到nginx服务器中,动态资源通过nginx反向代理到tomcat。
Docker 篇 【1】说一下什么是Docker?
Docker是一个开源的应用容器引擎,它让开发者可以将他们的应用以及依赖包打包到一个可移植的镜像中,然后发布到任何流行的Linux或Windows操作系统的机器上。Docker使用沙箱机制,使得容器之间完全隔离,互不干扰。Docker的镜像可以包含应用程序的代码、运行环境、依赖库、配置文件等必需的资源,从而实现方便快速并且与平台解耦的自动化部署方式。无论部署环境如何,容器中的应用程序都会运行在同一种环境下。
【2】说一下你都用过哪些Docker命令
Docker命令操作主要包含
镜像操作
容器操作
数据卷操作
自定义镜像操作
网络操作
【3】说一下镜像操作的常用命令
docker pull 拉取镜像
docker push 推送镜像
docker images 查看所有镜像
docker inspect 镜像名 查看镜像详细信息
docker rmi 镜像名 删除镜像
docker build 自定义镜像
docker save 保存镜像
docker load 加载镜像
【4】说一下Docker容器命令
docker run 构建容器,常见参数
--name 容器名
-d 后台启动
-p 端口映射
-v 数据卷挂载
一、随机变量 设E是一个随机试验,S为样本空间,样本空间的任意样本点e可以通过特定的对应法则X,使得每个样本点都有与之对应的数对应,则称X=X(e)为随机变量
二、分布函数 分布函数:设X为随机变量,x是任意实数,则事件{Xx}为随机变量X的分布函数,记为F(x)
即:F(x)=P(Xx)
(1)几何意义:
(2)某点处的概率:P(a)=P(Xa)-P(X<a)
性质:
(1)非负性:0F(x)1
(2)规范性:F()=1;F(-)=0
(3)单调不减函数
(4)右连续性
例:随机变量的分布函数F(x)=a+ x>0;F(x)=c x0
三、离散型随机变量及其分布 离散型随机变量 :X的取值为有限个或者无限可列个 如:X=骰子出现的点数
分布律(概率分布):
存在:P1+P2+........+Pn=1
(1)0—1分布=,满足0—1分布
(2)二项分布
P(X=k)= 记作:X~B(n,p)
独立重复n次试验;每次试验只有两种试验结果;试验中的概率不会发生变化
(3)泊松分布
P(X=k)= 记作:X~P()或X~
(4)超几何分布
(5)几何分布
P(X=k)=(1-p) · P
Code Coverage for .NET Crack Qodana 2023.3 empowers developers to measure code coverage for .NET, Go and Python code.
Qodana by JetBrains is a static code analysis tool that seamlessly integrates with your CI/CD pipeline, bringing the powerful inspection capabilities of JetBrains IDEs directly into your workflow. It scans codebases for over 2,500 potential issues, including performance bottlenecks, security vulnerabilities, and bad coding practices, granting developers, QA engineers, and team leads comprehensive insights to improve code quality, maintainability, and overall project health.
一、为什么需要自定义中间件 自定义中间件在ASP.NET Core中的应用主要有以下几个原因:
满足特定需求: 默认情况下,ASP.NET Core提供了许多内置的中间件来处理常见的任务,如身份验证、授权、静态文件服务等。然而,某些项目可能有特定的需求,需要定制化的处理流程,这时就需要创建自定义中间件以满足项目的特殊要求。增加业务逻辑: 自定义中间件允许开发人员向请求处理流程中添加业务逻辑。这对于执行与应用程序的核心功能相关的任务非常有用,例如日志记录、性能监控、请求转换等。通过自定义中间件,开发人员可以灵活地将业务逻辑集成到请求处理管道中。解耦和模块化: 自定义中间件有助于将应用程序的不同部分解耦,使代码更具模块化和可维护性。每个中间件可以专注于特定的任务,这样代码的组织结构更清晰,便于理解和维护。性能优化: 自定义中间件可以用于执行性能优化任务,例如缓存、压缩、请求重定向等。通过在请求处理流程中插入自定义中间件,可以更好地控制和优化应用程序的性能。适应特定场景: 不同的应用场景可能需要不同类型的中间件。通过创建自定义中间件,开发人员可以根据应用的特定需求,灵活地调整和配置中间件,以适应不同的使用场景。 自定义中间件为开发人员提供了更大的灵活性和控制权,使他们能够更好地定制和优化ASP.NET Core应用程序的请求处理流程,满足特定的业务和性能需求。
二、创建自定义中间件的基本步骤 创建自定义中间件涉及以下基本步骤:
创建一个类: 创建一个类来实现你的中间件。这个类通常需要包含一个构造函数以及一个名为Invoke、InvokeAsync等的方法,用于处理请求。public class CustomMiddleware { private readonly RequestDelegate _next; public CustomMiddleware(RequestDelegate next) { _next = next; } public async Task InvokeAsync(HttpContext context) { // 中间件逻辑处理 await _next(context); } } 添加中间件的基本结构: 在中间件类中,你需要编写逻辑来处理请求。可以在Invoke方法中执行你的自定义逻辑,然后通过_next字段调用下一个中间件。注册中间件: 在Startup.cs文件的Configure方法中,使用UseMiddleware或Use方法将中间件添加到请求处理管道中。确保注册中间件的顺序正确,因为中间件的执行顺序很重要。public void Configure(IApplicationBuilder app) { // 其他中间件 app.UseMiddleware<CustomMiddleware>(); // 或者使用 app.Use<CustomMiddleware>(); // 其他中间件 } 中间件的执行流程: 确保理解中间件的执行流程。当请求到达时,每个中间件按照注册的顺序依次执行,然后请求通过管道传递给下一个中间件,直到最终的处理程序。配置中间件: 如果中间件需要配置选项,可以通过构造函数参数或其他方式将配置传递给中间件。这允许你在Startup.cs中配置中间件的行为。public void Configure(IApplicationBuilder app, IHostingEnvironment env) { // 其他中间件 app.
国考省考行测:语句排序 2022找工作是学历、能力和运气的超强结合体!
公务员特招重点就是专业技能,附带行测和申论,而常规国考省考最重要的还是申论和行测,所以大家认真准备吧,我讲一起屡屡申论和行测的重要知识点
遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
除了技术,申论和行测也得好好准备
文章目录 国考省考行测:语句排序@[TOC](文章目录) 行测:国考省考行测:语句排序提问方式解题技巧解题思维:借助选项,分析作答解题方法:先首句分析,缩小答案范围,再捆绑分析,再锁定正确答案首句分析法不能做首句拓展:特例,如果文章以小说的形式,那么词语指代的句子可能做首句可以做首句的句子拓展,专业的文字,新名词表述拓展:举例词拓展引用词 刷题正式刷题 行测:国考省考行测:语句排序 提问方式 将以上6个句子重新排序,语序正确的是
将以下句子进行排列,语意连贯的是
广东就是这样考
一看序号就行
解题技巧 解题思维:借助选项,分析作答 不要自己单独去排列,没法弄
你直接看答案完事了,看看谁排序排的好
看答案第一个是谁?
直接看啊没啥说的
看看谁开头不可能
排除
解题方法:先首句分析,缩小答案范围,再捆绑分析,再锁定正确答案 首句分析法 1、套路正确吗?
选项中,数量多的开头,不能玩的,你得看语意
数量多的结尾也不行
很可能数量少的可能是答案
2四个选项开头不同,这种题难吗?未必
不能做首句 【1】词语指代不明确,不作首句
eg:这个过程,,,,
拓展:特例,如果文章以小说的形式,那么词语指代的句子可能做首句 eg安徽说过
他想要要
他,,,
他,,
身边,,,
他,,,,
只有那,,,,
他就是主角
【2】评价句,总结句,对策句:不作首句
【3】递进,转折,并列,总结词,出现的句子,都不作首句
而且,且,更,甚至
然而,事实上
因此,于是,总之,可见,看来
另一方面,同时,此外,第二,
eg
东北女人手中的烟袋还有一种用处,就是夏天拿来大小孩
所以它是不能做首句
【4】成对出现的关联词,后一个所处的句子,不能做首句
虽然但是,一方面另一方面
成对,一个是A,一个是B,后一个句子就不能
之所以,,,,,是因为,,,
是因为不能做首句
懂??
【5】时间词靠后,不可做首句
eg,过去,,,,如今,,,,,未来,,,,
唐代,,,,远古时代,,,,清代
则未来、清代这句话不能做首句
可以做首句的句子 【1】引出对象的句子
eg北京文旅,,,弹性分析法
引出弹性分析法
【2】引出材料所谈的话题
eg农业以节气作为节奏,茶叶的种植也不例外,则后续是茶叶
值函数可以分为状态价值函数和动作价值函数,分别适用于哪些强化学习问题
二、基于动态规划的算法
2.1 策略迭代算法
示例:
(改进的) 策略迭代 代码
首先定义了一些参数,如奖励、折扣因子、最大误差等,然后初始化了一个网格世界的环境,包括状态、动作、价值函数和策略。接着,它定义了一些函数,用于打印网格世界的状态或策略、计算状态的期望价值函数、对策略进行评估和改进等。最后,它使用了策略迭代的算法,不断地更新策略和价值函数,直到找到最优的策略,并打印出初始的随机策略和最终的最优策略。
import random # 导入随机模块,用于生成随机数 # Arguments REWARD = -0.01 # 定义非终止状态的常数奖励,这里是负数,表示每走一步都有一定的代价 DISCOUNT = 0.99 # 定义折扣因子,表示未来奖励的衰减程度,越接近1表示越重视长期奖励 MAX_ERROR = 10**(-3) # 定义最大误差,表示当状态的价值函数的变化小于这个值时,认为收敛到稳定值 # Set up the initial environment NUM_ACTIONS = 4 # 定义动作的数量,这里是4个,分别是上下左右四个方向的移动。policy里的0~3. # Down, Left, Up, Right ACTIONS = [(1, 0), (0, -1), (-1, 0), (0, 1)] # 定义动作的具体效果,表示每个动作对行和列的坐标的影响,例如(1, 0)表示向下移动一格,行坐标加1,列坐标不变 NUM_ROW = 3 # 定义网格世界的行数 NUM_COL = 4 # 定义网格世界的列数 U = [[0, 0, 0, 1], [0, 0, 0, -1], [0, 0, 0, 0], [0, 0, 0, 0]] # 定义每个状态的初始价值函数,这里只有两个终止状态有正负1的奖励,其他状态都是0 policy = [[random.
一、排序 1、冒泡排序 冒泡排序的英文Bubble Sort,是一种最基础的交换排序。之所以叫做冒泡排序,因为每一个元素都可以像小气泡一样,根据自身大小一点一点向数组的一侧移动。
原理
冒泡排序的原理: 每一趟只能确定将一个数归位。即第一趟只能确定将末位上的数归位,第二趟只能将倒数第 2 位上的数归位,依次类推下去。如果有 n 个数进行排序,只需将 n-1 个数归位,也就是要进行 n-1 趟操作。
而 “每一趟 ” 都需要从第一位开始进行相邻的两个数的比较,将较大的数放后面,比较完毕之后向后挪一位继续比较下面两个相邻的两个数大小关系,重复此步骤,直到最后一个还没归位的数。
//将a进行升序排列 public static void bubbleSort(int a[]){ //控制排序趟数 for (int i = 0; i < a.length-1; i++) { //内层循环控制的是每趟排序中前后相邻两个位置的数比较交换的过程 //j表示的是比较的数的下标位置,且以前面的位置为参照 for (int j = 0; j < a.length-i-1; j++) { //相邻两个位置前面的位置的数如果大于后面的位置则进行交换 if(a[j]>a[j+1]){ //交换相邻位置的数 int temp=a[j]; a[j]=a[j+1]; a[j+1]=temp; } } } } 2、二分查找 二分查找:也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
public class Demo2 { public static void main(String[] args) { //二分法查找(折半查找) int[] nums = {1,3,5,6,7,8,11,13,17}; int index = binarySearch(nums,11); if(index==-1) { System.
目录
前言
全局配置文件
一、window
1. 小程序窗口的组成部分
2. window 节点常用的配置项
3. 设置导航栏的标题 4. 设置导航栏的背景色
5. 设置导航栏的标题颜色
6. 全局开启下拉刷新功能
7. 设置下拉刷新时窗口的背景色
8. 设置下拉刷新时 loading 的样式
9. 设置上拉触底的距离
二、tabBar
1. 什么是 tabBar
2. tabBar 的 6 个组成部分
3. tabBar 节点的配置项
4. 每个 tab 项的配置选项
案例:配置 tabBar
页面配置
1.页面配置和全局配置的关系 2. 页面配置中常用的配置项
前言 今天我们开始学习微信小程序中的全局配置,前面对微信小程序文件介绍的时候讲到过.json文件的基本作用和内容,那么本期的主角是.json文件,这个是作为微信小程序的全局配置文件,通过这个文件我们可以对微信小程序进行全局性的管理。
全局配置文件 小程序根目录下的 app.json 文件是小程序的全局配置文件。常用的配置项如下:
① pages 记录当前小程序所有页面的存放路径 ② window 全局设置小程序窗口的外观 ③ tabBar 设置小程序底部的 tabBar 效果 ④ style 是否启用新版的组件样式 前面我们对pages属性有了详细的介绍,那本期这里就不做讲解(相关链接:微信小程序-----账号注册以及开发软件的下载与代码结构介绍-CSDN博客)
一、window 1.
本章目标 接口的语法
接口的应用
jdk1.8 接口新特性
接口和抽象类的区别
匿名内部类
本章内容 一、接口语法: 概念,接口是一种规则和标准,而这些规则和标准需要实现类来实现,侧重于can do
接口的实现:使用implements关键字
接口的定义:
接口中也可以存放全局常量,默认为:public static final
一个类可以实现多个接口
一个类既可以实现多个接口也可以同时继承一个类,但是继承需要写到实现的前面,先继承后实现
一个接口可以继承多个接口(接口和接口之间的关系)
接口语法总结
接口中定义的方法,默认为:public abstract
接口中没有构造器,代码块
接口不能被实例化,主要作用就是被实现类实现,接口的主要是体现为标准
一个类可以实现多个接口,测试的时候,一个接口类型的变量指向实现类对象后,接口类型的变量只能调用出来本接口中定义过的方法,实现类独有的方法不能调用
一个类既可以实现多个接口也可以同时继承一个类,但是继承需要写到实现的前面,先继承后实现
一个接口可以继承多个接口
接口中也可以存放全局常量,默认为:public static final
练习
Usb
分析:
USB接口本身没有任何实现
USB接口规定了数据的传输要求
USB接口可以被多种USB设备实现
USB: service()
java实现:
步骤一:编写USB接口 —-> 根据需求设计方法
步骤二:实现USB接口 —-> 实现所有方法
步骤三:使用USB接口 —-> 使用多态的方式使用接口
/** * USB接口 * */ public interface UsbInterface { /** * USB接口提供服务 */ void service(); } 示例代码:(USB风扇) 示例代码:(USB U盘) package com.woniu.usb; /** * USB风扇 * */ public class UsbFan implements UsbInterface { @Override public void service() { System.
树和二叉树的定义和存储 二叉树的遍历 先序遍历 中序遍历 后序遍历 层次遍历 哈夫曼树
爬虫之Cookie获取:利用浏览器模拟一个cookie出来、面对反爬虫、加密的cookie的应对方法 在爬虫或模拟请求时,特别是获取验证码的时候,反爬虫的网站的cookie或定期失效,复制出来使用是不行的为了应对这种方式,我们可能就需要像浏览器打开网站一样,取得它信任的cookieselenium就是一个很好的手段 一、什么是selenium Selenium最初是一个自动化测试工具,Selenium可以驱动浏览器自动执行自定义好的逻辑代码,即通过代码完全模拟使用浏览器自动访问目标站点并操作,所以也可以用来爬虫。 二、准备工作 安装Chrome下载对应版本的chromedriver.exe 2.1 chrome 查看版本 # chrome地址栏输入下面的内容即可查看 chrome://version/ 2.2 下载对应版本的chromedriver.exe 上下2图的版本号要对应上(最新版本的chrome的driver可能还没有)
2.3 一组对应上的chrome和driver 微信搜索“数字续坚”,在“资源”TAB页面,输入“selenium”,然后复制百度网盘的下载地址注意:chrome会自动更新,建议安装chrome前,先在hosts文件中加入如下内容,屏蔽chrome的自动升级 127.0.0.1 update.googleapis.com 三、编码实现 这里就不废话了,如下代码 // Java 代码 //目标网站的网址,也可以直接是验证码链接 String targetUrl = "https://www.baidu.com"; //设置chromedriver.exe的路径,下方是在当前目录下 System.setProperty("webdriver.chrome.driver", "./chromedriver100.exe"); ChromeDriver chromeDriver =new ChromeDriver(); chromeDriver.get(url); //读取cookie Set<Cookie> cookies = chromeDriver.manage().getCookies(); String cookieStr = ""; for (Cookie cookie : cookies) { cookieStr += cookie.getName() + "=" + cookie.getValue() + ";"; } //打印cookie结果 System.out.println(cookieStr); 四、快速获取cookie的办法 针对其他语言、其他系统或不想配置chrome+driver的兄弟,这里提供了快速获取的办法见文档。
简介 🍀通过依赖注入的方式,使用ORM工具Entity Framework查询Mysql数据库中的数据,并实现多表联查
假设我们有一个user用户表,其中occupationid对应的就是下面职业表中的id
职业表Occupations
现在我们需要查出用户的职业是什么,在MySQL中我们可以通过LEFT JOIN实现多表查询。如下sql语句。
SELECT name,opname FROM Users LEFT JOIN Occupations ON Users.opid = Occupations.id 如果想要在EFCore中完成这种需求应该怎么操作呢。
安装nuget包 分别安装如下两个nuget包,具体版本要参考自己实际的MySQL版本
NuGet\Install-Package Microsoft.Extensions.Hosting -Version 8.0.0 NuGet\Install-Package Pomelo.EntityFrameworkCore.MySql -Version 7.0.0 创建上下文类 首先创建一个继承自 DbContext 的上下文类,使用DbSet 属性来表示数据库中的表
public class MyContext : DbContext { public MyContext(DbContextOptions<MyContext> options) : base(options) { } public virtual DbSet<User> Users { get; set; } = null!; public virtual DbSet<Occupation> Occupations { get; set; } = null!; } 然后分别创建我们数据库两张表的实体类,它们通过导航属性 occupationid 相互关联
Lecture #10_ Sorting & Aggregation Algorithms Query Plan 数据库系统会将 SQL 编译成查询计划。查询计划是一棵运算符树。
Sorting DBMS 需要对数据进行排序,因为根据关系模型,表中的tuple没有特定的顺序。排序使用 ORDER BY、GROUP BY、JOIN 和 DISTINCT 操作符。如果需要排序的数据适合内存,那么 DBMS 可以使用标准排序算法(如快排)。如果数据不适合在内存中进行排序,那么 DBMS 就需要使用外部排序,这种排序可以根据需要溢出到磁盘,并且优先选择顺序 I/O,而不是随机 I/O。
如果查询包含一个带 LIMIT 的 ORDER BY,那么 DBMS 只需扫描一次数据就能找到前 N 个元素。这就是 top-n 堆排序。堆排序的理想情况是前 N 个元素都在内存中,这样 DBMS 只需在扫描数据时维护一个内存中的优先队列即可。
外部合并排序是对大到内存无法容纳的数据进行排序的标准算法。这是一种 "分而治之 "的排序算法,它将数据分割然后分别进行排序。
外部合并排序的一种优化方法是在后台预取下一次运行,并在系统处理当前运行时将其存储在第二个缓冲区中。这样可以持续利用磁盘,减少每一步 I/O 请求的等待时间。
对于 DBMS 来说,使用现有的 B+tree 索引辅助排序有时比使用外部合并排序算法更有优势。特别是,如果索引是聚簇索引,DBMS 就可以直接遍历 B+tree 索引。由于索引是聚类的,数据将以正确的顺序存储,因此 I/O 访问将是顺序的。
Aggregations 实现聚合有两种方法:排序和散列。
排序:DBMS 首先根据 GROUP BY 键对图元进行排序。如果所有数据都在缓冲池中(如 quicksort),可以使用内存内排序算法;如果数据大小超出内存,可以使用外部合并排序算法。然后,DBMS 会对排序后的数据执行顺序扫描,以计算聚合。运算符的输出将按键排序。在执行排序聚合时,必须对查询操作进行排序,以最大限度地提高效率。 例如,如果查询需要过滤,最好先执行过滤,然后对过滤后的数据进行排序,以减少需要排序的数据量。
哈希:
Partition:使用哈希函数 h1,根据目标哈希键将tuple分组到磁盘上的分区。这将把所有匹配的元组放入同一个bucket。假设共有 B 个缓冲区,我们将有 B-1 个输出缓冲区和 1 个输入缓冲区。如果任何分区已满,数据库管理系统就会将其溢出到磁盘。ReHash:对于磁盘上的每个分区,将其页面读入内存,并根据第二个哈希函数 h2 建立一个内存哈希表。然后遍历哈希表中的每个桶,将匹配的tuple集中起来计算聚合。假设每个分区都适合内存。 Lecture #11_ Joins Algorithms Joins 重点讨论用于合并两张表的内部等值连接算法。等值连接算法可以连接键值相等的表。
当一个系统在发生 OOM 的时候,行为可能会让你感到非常困惑。因为 JVM 是运行在操作系统之上的,操作系统的一些限制,会严重影响 JVM 的行为。故障排查是一个综合性的技术问题,在日常工作中要增加自己的知识广度。多总结、多思考、多记录,这才是正确的晋级方式。
现在的互联网服务,一般都做了负载均衡。如果一个实例发生了问题,不要着急去重启。万能的重启会暂时缓解问题,但如果不保留现场,可能就错失了解决问题的根本,担心的事情还会到来。
所以,当实例发生问题的时候,第一步是隔离,第二步才是问题排查。什么叫隔离呢?就是把你的这台机器从请求列表里摘除,比如把 nginx 相关的权重设成零。在微服务中,也有相应的隔离机制,这里默认你已经有了(面试也默认你已经有隔离功能了)。
今天的内容将涉及非常多的 Linux 命令,对 JVM 故障排查的帮助非常大,你可以逐个击破。
1. GC 引起 CPU 飙升 我们有个线上应用,单节点在运行一段时间后,CPU 的使用会飙升,一旦飙升,一般怀疑某个业务逻辑的计算量太大,或者是触发了死循环(比如著名的 HashMap 高并发引起的死循环),但排查到最后其实是 GC 的问题。
在 Linux 上,分析哪个线程引起的 CPU 问题,通常有一个固定的步骤。我们下面来分解这个过程,这是面试频率极高的一个问题。
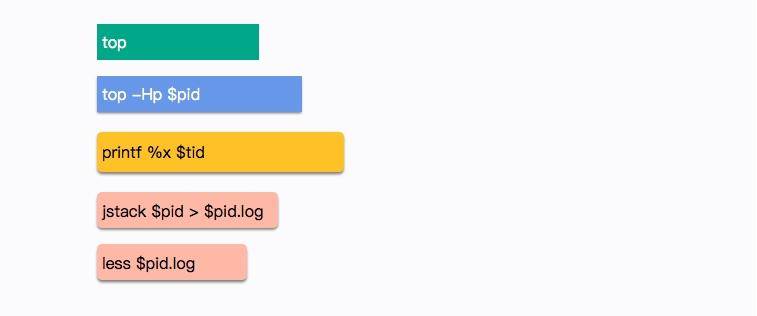 (1)使用 top 命令,查找到使用 CPU 最多的某个进程,记录它的 pid。使用 Shift + P 快捷键可以按 CPU 的使用率进行排序。
top
(2)再次使用 top 命令,加 -H 参数,查看某个进程中使用 CPU 最多的某个线程,记录线程的 ID。
top -Hp $pid
(3)使用 printf 函数,将十进制的 tid 转化成十六进制。
printf %x $tid
(4)使用 jstack 命令,查看 Java 进程的线程栈。
第一步:
注册登录阿里云可以试用3个月但是清楚一点这是按量付费是要钱的要及时稀释掉以防乱扣费,如果自己是学生还可以申请学生认证可以免费领取一个月的2核2GIB的服务器
第二部记住自己的获得公网ip可以试着远程连接一下如下图
如果不知道密码可以更改实例密码更改步骤如下图
改了密码就可以了
打开电脑中的远程桌面连接去远程连接一下本服务器的桌面最后如下图:
需要下两个软件下面是下载连接
XAMPP Download (2024 Latest)
Download | WordPress.org China 简体中文
需要将WordPress文件(注意是文件不是压缩包)解压到XAMPP的htdocs的文件中
下面是安装完后的步骤如图
第一步:打开Apache和MySQL库然后点开Apache的Admin结果如下:
然后点开phpMyAdmin弹出以下结果:
然后新建一个库名字叫demopy123 然后点击权限创建新用户
密码直接设成无密码 然后直接点击执行(在下面)
然后到搜索http://localhost/wordpress/ 这网站配制网站如下图:
最后如果想改网站地址名可以该下面的内容
把 siturl和home改为自己的公网IP
最后一步不要忘了设置80端口在阿里云中设置
1、登录到阿里云服务器ECS管理控制台
在左侧“实例与镜像”中选择“实例”,找到需要开放80端口的云服务器,如果没有找到,记得在顶部切换云服务器地域。
2、点击“更多”–“网络和安全组”–“安全组配置”,如下图:
阿里云服务器安全组开启端口
在打开窗口点击“配置规则”
3、在“入方向”,点击“手动添加”,规则如下:
授权策略:允许优先级:1协议类型:自定义TCP端口范围 目的:8080/8080授权对象 源:0.0.0.0/0描述:可填,可不填,自己知道就行 最后就可以用自己的公网IP加上/wordpress就可以运行自己的网站了。
代码可以直接复制
如果有啥问题可以问我看到一定会回复大家,如果大家喜欢可以作者点赞和关注
大家的支持是我创作下去的最大动力
2023年网络安全有哪些变化? 3月即将接近尾声,2023已经过去了一旬,根据目前的趋势和技术发展方向,可以发现和预见2023年网络安全出现以下变化:
人工智能和机器学习的应用将成为主流。 随着人工智能和机器学习技术的不断发展,越来越多的企业将开始使用这些技术来改进网络安全防御系统和威胁检测方法。
区块链技术将在网络安全领域得到更广泛的应用。 区块链技术可以提供分布式的、不可篡改的安全性,因此它可以用于创建更安全的身份验证和数据保护系统。
对物联网安全的需求将持续增长。 随着越来越多的设备与互联网相连,物联网安全问题也越来越严重。未来将会有更多的工具和技术用于保护这些设备和数据。
零信任模型将成为常态。 随着越来越多的数据和服务在云端运行,零信任模型将变得更加重要。这意味着所有用户都必须经过身份验证,并需要实时监测和检测可能的威胁。
人类工作与自动化系统的结合将成为关键。 未来的网络安全系统将越来越倾向于人类工作与自动化系统的结合。这样可以确保最佳的威胁检测和响应,并最大程度减少误报和误报警。
网络安全的重要性 通过以上的变化我们不难看出网络安全在当今社会越来越重要了,在现代社会中,人们日常生活中的很多方面都与网络有关。随着互联网和数字技术的不断发展,人们已经变得越来越依赖网络,网络已经成为了商业、金融、通信、交通、能源、医疗、教育等各个领域的核心基础设施。
网络安全问题的严重性在于,如果不加以保护,网络可能会受到各种不同类型的攻击,例如黑客攻击、病毒和恶意软件、网络钓鱼、拒绝服务攻击等。这些攻击可能会导致各种问题,例如数据泄露、系统崩溃、网络瘫痪、财务损失、商业损失、个人隐私泄露等等。
因此,网络安全的重要性在于保护网络基础设施、保障数据安全、防止金融欺诈和恶意活动、维护国家安全、保护个人隐私等方面。网络安全不仅对个人和企业有利,对整个社会来说都至关重要。
学习计划分享 既然,网络安全如此重要,那么我们该如何系统地学习并且入行网络安全呢?这里我分享一份时长为期三个月的网络安全工程师初、中级学习计划给大家:
初级阶段 1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(7天)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(7天)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(7天)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(7天)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,当你学到这里时,基本可以从事一份网络安全相关的工作,比如渗透测试、Web渗透、安全服务、安全分析等岗位;其中如果等保模块学的好,还可以从事等保工程师。
薪资区间: 6k~15k
到此为止,耗时约1个月左右,你已经成为了一名 “脚本小子”,那么你还想往下探索吗?
中级阶段 脚本编程学习(4周)
在网络安全领域。是否具备编程能力是“脚本小子”和真正网络安全工程师的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力。
零基础入门的同学,我建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习;
搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP,IDE强烈推荐Sublime;
Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,没必要看完;
用Python编写漏洞的exp,然后写一个简单的网络爬虫;
PHP基本语法学习并书写一个简单的博客系统;
熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选);
了解Bootstrap的布局或者CSS。
薪资区间 20k~25k
Hello everbody!这次咱们紧接着上一篇文章,继续介绍Linux操作系统的一些基本指令。这些指令是入门级别的,比较基础的。相当于windows中文件的复制,重命名,创建文件,创建目录之类的,还有如何在Linux中写c语言的代码。希望大家在阅读过这篇文章后能够对Linux系统有更加深入的认识。当然Linux的指令有很多,短短一两篇文章难以介绍清楚,后期我会继续更新有关Linux系统的相关知识,也请大家持续关注我更新的文章呦
\(0^◇^0)/。
1.cd命令 1.1cd -命令 例如目前咱们在/root路径下。
随后进入dir文件夹中,路径就变成了/root/dir
随后反复执行cd -命令,路径就会在/root与/root/dir之间来回跳转。
总结:cd -命令的作用是:跳转到我们最近一次所处的路径下。
1.2cd ~命令 cd ~命令的作用是进入用户家目录。
首先我们要知道的是:任何用户首次登陆,所处的路径都是自己的家目录。
在这里咱们可能会有些疑问:1.用户是谁?2.什么是用户的家目录?
1.想要知道当前的用户是谁,只需要执行whoami命令。当前是root用户。
2.而用户家目录只需要在用户前面加一个斜杠(/)即可。即:/root
当然在咱们windows系统下也有自己的用户家目录:
需要打开c盘,找到用户文件夹,我的是李星宇。你们应该有自己的名字。
顺便说一下,作为扩展知识:在咱们的家目录中,有一个桌面,类型是文件夹。在我们的电脑开机时,Windows系统会根据用户名找到用户家目录中的桌面文件夹,并以图形化界面的形式显示到咱们的桌面上。这一点Linux并没有Windows做的好。
2.which命令 在介绍这个命令之前咱们得重新对指令有一个更深的认识:
指令都是程序——指令,程序,可执行程序都是一回事。
程序的安装和删除就是把可执行程序拷贝到系统路径下或是从系统路径下删除。
which命令:要求系统打印出我所指定的指令名称在系统中所处的路径。
3.alias命令 alias命令的作用是给其他指令起一个别名。
由这张图片可以看出:ll是ls -l的别名。
这里还有一个小细节:大家看一看这两条指令的区别,一条是通过绝对路径执行ls指令。一条是直接执行ls指令。但执行的结果有所不同。
通过绝对路径执行ls指令结果没有颜色,而直接执行ls指令的结果有颜色。这是为什么呢?
要解答这个问题我们需要回到which指令上:
在which指令执行的结果中有一条这样的语句:alias ls='ls --color=auto'。也就是说ls是ls --color=auto的别名,系统在执行ls指令时会把ls替换成ls --color=auto。而通过绝对路径执行ls 指令(/usr/bin/ls)则不会替换。
而我们人为的替换掉就会得到想要的结果。
4.stat命令 stat命令是用于显示文件或文件夹更加详细的属性。
5.mkdir命令 在上一篇文章中我们已经讲过mkdir指令可以创建一个文件夹。
那mkdir指令是否可以创建一个路径呢?自然是可以的。只不过需要添加一个 -p选项。
但是虽然创建好了一个路径,却不能清晰的看出这些文件夹里面多叉树的结构。不着急,tree命令可以解决这个问题!
6.tree命令 我们知道 .表示当前路径。tree .就是要求系统打印出当前路径的多叉树的结构。
当然用tree命令来显示根目录(/)的结构时就会出现类似无限打印的情况,因为Linux系统中有很多的文件和文件夹。
所以这时我们可以按ctrl+c来终止异常的指令(按一次不行就多按几次):
7.rmdir命令 rmdir指令只能删除空目录:
这条指令应该比较容易理解,我就不过多赘述了。
8.rm命令 rm指令可以删除文件,删除时需要用户确认是否删除。确认答:y。否认答:n。
当然rm也可以删除目录但后面需要跟一个选项:-r
当然如果在删除是你十分确定要删除不需要系统再次向你确认了,可以加一个f选项,可以理解为force的缩写,就是强制的意思。
讲到这里我需要提醒一下:如果你是root用户,在执行删除命令时需要十分谨慎。因为root用户是超级用户,他的权力非常大,在Linux系统中,只要愿意,什么都可以删。如果由于操作不当,删除了根目录(/),那么整个系统就挂掉了。恢复系统也是十分困难,因为指令都用不了了,也不能安装指令。只有考虑重装系统了,如果之前的系统有十分重要的数据就会十分麻烦。
还需要补充一点的是:在Linux系统中*表示通配符,可以匹配任意文件名。如果你要删除一个目录中的所有文件,可以用rm *或rm -f *。
9.cp命令 cp src dst 是将src文件拷贝到dst目录下。
在 JDK 1.5 之前共享对象的协调机制只有 synchronized 和 volatile,在 JDK 1.5 中增加了新的机制 ReentrantLock,该机制的诞生并不是为了替代 synchronized,而是在 synchronized 不适用的情况下,提供一种可以选择的高级功能。
今天我们的面试题是:synchronized 和 ReentrantLock 是如何实现的?它们有什么区别?
典型回答 synchronized 属于独占式悲观锁,是通过 JVM 隐式实现的,synchronized 只允许同一时刻只有一个线程操作资源。
在 Java 中每个对象都隐式包含一个 monitor(监视器)对象,加锁的过程其实就是竞争 monitor 的过程,当线程进入字节码 monitorenter 指令之后,线程将持有 monitor 对象,执行 monitorexit 时释放 monitor 对象,当其他线程没有拿到 monitor 对象时,则需要阻塞等待获取该对象。
ReentrantLock 是 Lock 的默认实现方式之一,它是基于 AQS(Abstract Queued Synchronizer,队列同步器)实现的,它默认是通过非公平锁实现的,在它的内部有一个 state 的状态字段用于表示锁是否被占用,如果是 0 则表示锁未被占用,此时线程就可以把 state 改为 1,并成功获得锁,而其他未获得锁的线程只能去排队等待获取锁资源。
synchronized 和 ReentrantLock 都提供了锁的功能,具备互斥性和不可见性。在 JDK 1.5 中 synchronized 的性能远远低于 ReentrantLock,但在 JDK 1.6 之后 synchronized 的性能略低于 ReentrantLock,它的区别如下:
2023-2024 一句话,真的很想改变!
简介 大家好,我是拾贰,很高兴能与大家相识,并能与大家一起学习成长。我已经是软件工程专业大四的学生了。时光荏苒,回想着三年多来,自己仍与之前的自己一样吊儿郎当的活着,好像没有什么拿得出手的目标。越往后我越是觉得自己很是fw。在新的一年我的期待就是希望我自己能有所改变,不断提高自己。因此,希望我能坚持住,不断前进。
编程 近期目标:独立完成毕设,锻炼自己;
长远目标:坚持住,不断学习,抓住基础核心,不断巩固加强,自行发开项目,正所谓“实践是检验整理的唯一标准”;学习数据结构与算法,学习其思想。
如何学习呢? 关键靠自己。
还是那句话:“实践是检验整理的唯一标准”。成长的关键就是多敲代码,多进行实战。
每周时间 每天:
C语言分配上2-3h;
java 3-5h;
数据结构与算法 2 - 3h
company 互联网公司
文章目录 前言一、读取远程文件 二、应用解释 前言 当一个服务器需要处理另一个服务器上已知图像的绝对路径时,可以使用 Paramiko 库连接到远程服务器并读取图像,然后使用 OpenCV(cv2)库在本地服务器上加载和处理图像。以下是示例代码,演示了如何使用 Paramiko 和 cv2 库来实现这一操作。本文就给出应用。
一、读取远程文件 如何使用 Paramiko 和 cv2 库来处理另一个服务器上已知图像的绝对路径。首先,我们使用 Paramiko 库连接到远程服务器,并通过 SFTP 协议从远程服务器读取图像文件。然后,我们将读取的图像数据转换为 NumPy 数组,并使用 cv2 库在本地服务器上加载图像进行处理。
这段代码的关键点在于使用 Paramiko 库建立与远程服务器的连接,通过 SFTP 协议从远程服务器读取图像文件,并将图像数据转换为适合 OpenCV 处理的格式。接着,我们使用 cv2 库加载图像并进行进一步的处理或分析。
import paramiko import os import cv2 import numpy as np # 连接到远程服务器 ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect('192.168.2.93', username='ubuntu', password='ubuntu@123') # 远程服务器上的数据路径,类似os.listdir()函数 remote_data_path = '/home/auto_project/RTDETR/model_rtdetr/data' stdin, stdout, stderr = ssh.exec_command('ls ' + remote_data_path) file_list = stdout.
文章目录 【 1. 什么是操作系统 】【 2. 操作系统软件的分类 】【 3. 操作系统内核的抽象和特征 】3.1 操作系统内核的抽象3.2 操作系统内核的特征 【 1. 什么是操作系统 】 操作系统是管理硬件资源、控制程序运行、改善人机界面和为应用软件提供服务的一种系统 软件。一个服务提供者。 一个系统软件。执行用户程序,提供系统调用。控制程序执行过程,防止错误。方便用户使用计算机系统。 一个资源管理程序。 应用程序与硬件之间的中间层。管理各种软硬件资源。提供访问软硬件资源的高效手段。解决访问冲突, 确保公平使用。 系统设计者利用硬件提供的能力,来完成操作系统的功能实现;应用程序的开发者可以直接利用操作系统的功能,也可以在操作系统之上开发一些通用的应用即系统应用;在系统应用之上可以开发适用于用户不同需求的应用程序。
【 2. 操作系统软件的分类 】 【 3. 操作系统内核的抽象和特征 】 3.1 操作系统内核的抽象 操作系统将CPU抽象成进程。操作系统要负责CPU资源的管理,CPU的功能是计算的能力,那操作系统就将CPU抽象成一个数据结构叫进程控制化。
进程描述一个程序如何被加载到计算机系统当中,如何分配他所需要的资源,然后占用CPU执行,如果同时负责多个程序在执行的时候,需要的暂停恢复,都会有进程的概念。操作系统将磁盘抽象成文件。文件是是计算机系统当中的一个基本单位,这个基本单位的内容是存在磁盘上的。
操作系统抽象出文件这个概念之后,用户应用程序对数据的访问就是指去访问某一个文件,需要知道这个文件在哪,把它的内容读出来,以及往文件里写数据的时候,需要把数据存到哪里,这是操作系统需要解决的问题。操作系统将内存抽象成地址空间,内存是临时性存数据的地方。
好多个应程序交替执行的时候,就会有地址空间上的管理:到底把哪一块空间,分配给哪个进程来执行。 3.2 操作系统内核的特征 并发:计算机系统中同时存在多个运行程序。
在 C语言中,从main开始执行,一直到main执行完毕,这是我们原来理解的一个程序的过程。但是在操作系统里的内核需要管理多个正在运行的程序交替执行,这个交替执行就是指一个进程占用 CPU,直到某位置,CPU被收回给另外一个进程,这时要记录当前执行到哪了,保存哪些数据,然后把另一个进程上一次执行的状态恢复回来,然后继续执行。这种 交替的执行,就是我们这里所说的并发。 共享:程序间 “同时” 访问互斥共享各种资源。
在计算机系统当中,有多个应用程序执行,在原来我们写程序的时候,只关心这个程序里头,到底访问哪些资源,但是在操作系统里头呢,就需要关心多个应用程序同时要访问同一个资源的时候怎么来处理:
比如说两个程序的执行都要使用CPU,那这个CPU怎么来分配给两个进程?因为对于CPU来说,它不是可以把一半分给一个进程,另一半分给另一个进程,它只能一个时间段给一个进程,另一个时间段给另一个进程。而对于内存来说,它是另外一种方式,可以把一部分给一个进程一部分给另一个进程。针对不同的资源,它有不同的共享的方式和策略。 虚拟:每个程序” 独占” 一个完整的计算机。
在直接写汇编程序的时候,是一个物理的CPU上有一个计算器,保存了当前指令指针的执行。而现在我们有多个运行的程序进程在计算机系统当中执行,此时,每一个程序看上去好像都是在一个完整的独立计算机上执行,只是说跟原来区别在于它中间有可能暂停下来,把CPU让给另外一个进程去执行,但对于这个程序来说,它好像就是占用了一台独立的完整的计算机在执行,这种看上去好像是一台独立的计算机,这就是我们这里所说的虚拟。内存、磁盘都有类似的问题,也就是说我把一个资源虚拟化之后,让各个应程序看上去这个资源都是它在独立的使用,由操资系统来协调,这种看上去独立的使用,在内部实际上它是共享的。 异步:服务的完成时间不确定,也可能失败。
在嵌入系统,可以通过这个延时来实现等待的操作。但是在计算机内核里,在操作系统里,一段程序执行时间可能会由于中间CPU给了别的进程执行,而该段程序实际执行的时间是不确定的,这样就不能用用时钟来确定到底多长时间可以执行下一步操作。这种不确定性就会导致原来看上去正确的一些逻辑会产生麻烦,这就是我们这里说到的异步。
1 语法 mask: url(image.png); 使用位图来做遮罩 mask: url(image.svg#star); 使用SVG图形中的形状来做遮罩 mask: linear-gradient(#000 , transparent) 接受类似背景参数的渐变来做遮罩 2 示例 2.1 背景透明 { background: url(image.png) ; mask: linear-gradient(45deg, transparent, #000) } 图片与mask生成的渐变的 transparent 的重叠部分,会变得透明,这里#000可以为任意颜色,效果相同
2.2 图片裁切 { background: url(image.png) ; mask: linear-gradient(135deg, transparent 20px, #000 0) top left, linear-gradient(-135deg, transparent 20px, #000 0) top right, linear-gradient(-45deg, transparent 20px, #000 0) bottom right, linear-gradient(45deg, transparent 20px, #000 0) bottom left; mask-size: 50% 50%; mask-repeat: no-repeat; } { background: url(image.
顶刊Nature刊登了一篇来自斯坦福大学计算机科学与基因技术学院的博士后 Hanchen Wang,与佐治亚理工学院计算科学与工程专业的 Tianfan Fu,以及康奈尔大学计算机系的 Yuanqi Du 等 30 人的论文《Scientific discovery in the age of artificial intelligence》,综述了过去十年中人工智能在科学发现中的突破和挑战,以及如何利用自监督学习、几何深度学习和生成式AI方法来解决不同领域的科学问题。
人工智能 (AI) 越来越多地融入科学发现中,以增强和加速研究,帮助科学家提出假设、设计实验、收集和解释大型数据集,并获得仅使用传统科学方法可能无法获得的见解。在这里,我们回顾了过去十年的突破,包括自我监督学习(允许在大量未标记数据上训练模型)和几何深度学习(利用有关科学数据结构的知识来提高模型的准确性和效率)。生成式人工智能方法可以通过分析包括图像和序列在内的多种数据模式来创建小分子药物和蛋白质等设计。我们讨论这些方法如何在整个科学过程中帮助科学家,以及尽管取得了这些进步仍然存在的核心问题。人工智能工具的开发人员和用户都需要更好地了解何时需要改进这些方法,而数据质量和管理不佳带来的挑战仍然存在。这些问题跨越科学学科,需要开发有助于科学理解或自主获取科学理解的基础算法方法,使它们成为人工智能创新的关键领域。
一、AI辅助的数据收集和整理
这篇文献介绍了AI方法如何提高数据的选择、标注、生成和精炼的效率和质量,以及如何从大规模的无标签数据中学习有意义的数据表示,例如利用几何先验、自监督学习和语言建模等技术。
主要包括以下几个方面:
数据选择:AI可以帮助科学家从海量的数据中筛选出有价值的信息,例如在粒子物理实验中,使用深度自编码器来检测罕见的事件,或者在地球科学、海洋学和天文学中,使用无监督的异常检测方法来发现新的现象。
数据标注:AI可以利用伪标签、标签传播、主动学习等技术来自动或半自动地给大量的无标签数据添加标签,从而减少人工标注的成本和时间。例如,在生物学中,可以使用基于图的方法来给新发现的分子或蛋白质赋予功能和结构的标签。
数据生成:AI可以利用数据增强和深度生成模型等技术来创建更多的合成数据,从而提高模型的鲁棒性和泛化能力。例如,在医学影像、材料科学、化学和生物学等领域,可以使用生成对抗网络来合成逼真的图像或序列。
数据精炼:AI可以利用深度卷积方法等技术来提高数据的质量和精度,例如去噪、超分辨率、结构恢复等。例如,在单细胞基因组学、高能物理、生物显微镜等领域,可以使用自编码器或变分自编码器等方法来提取数据的本质特征并消除噪声的影响。
该图展示了如何利用人工智能方法学习科学数据的有意义的表示,包括几何深度学习、自监督学习和语言建模。每个子图都给出了一个具体的例子,说明了这些方法在不同的科学领域中的作用。例如,几何深度学习可以处理分子和材料等具有几何和关系结构的数据,自监督学习可以通过对比学习等策略来提取图像或序列数据的相似性和差异性,语言建模可以通过遮盖语言模型等技术来捕捉自然语言和生物序列的语义。该图的目的是展示人工智能如何通过不同的方式来理解和操作科学数据,从而为科学研究提供有价值的指导和预测。
二、AI驱动的科学假设生成
这篇文献讨论了AI方法如何生成可测试的科学假设,包括使用黑盒预测器、组合优化、可微分假设空间等策略,以及如何使用强化学习、贝叶斯优化等技术指导假设的搜索和评估。
人工智能驱动的科学假设生成是指利用人工智能技术,如机器学习、自然语言处理、知识图谱等,来帮助科学家从海量的数据和文献中发现潜在的规律、关联和创新点,从而提出新的科学假设。这些假设可以指导科学家进行实验设计、数据分析和理论建模,加速科学发现的过程。
以上图中:展示了人工智能(AI)在科学假设生成方面的三种方法。图中的每个子图都对应一个不同的领域和任务,如物理、化学和数学。图中的每个子图都包含以下元素:
a:高通量筛选。这个子图展示了如何使用AI预测器来从一个庞大的候选池中选择具有期望性质的对象,如化合物、材料或生物分子。这个过程可以利用自监督学习来预训练预测器,然后在有标签的数据集上微调预测器。实验室评估和不确定性量化可以优化这个过程,使其更加高效和准确。
b:AI导航器。这个子图展示了如何使用强化学习来在符号回归中导航假设空间。以牛顿万有引力定律为例,这个子图展示了如何使用奖励函数和设计准则,如奥卡姆剃刀,来聚焦于最有前途的表达式树。通过不断地执行这个过程,AI导航器可以收敛于与数据一致并满足其他设计准则的数学表达式。
c:AI差分器。这个子图展示了如何使用自编码器模型来将离散的对象,如化学化合物,映射到一个可微分的连续潜在空间。这个空间可以用于优化对象,如从一个庞大的化学库中选择最大化某个生化指标的化合物。这个子图展示了一个理想化的潜在空间,其中颜色深浅表示对象的预测分数的高低。通过利用这个潜在空间,AI差分器可以高效地识别具有期望性质的对象。
人工智能驱动的科学假设生成的主要挑战包括如何有效地搜索和优化假设空间,如何结合先验知识和数据证据,如何评估和验证假设的可靠性和创新性,以及如何提高人工智能的可解释性和可信度。文中列举了一些人工智能驱动的科学假设生成的应用案例,如在物理、化学、生物、医学等领域中发现新的材料、分子、蛋白质、基因变异等。网页还介绍了一些人工智能驱动的科学假设生成的工具和平台,如Iris.ai、Semantic Scholar、Microsoft Academic等,它们可以帮助科学家快速地浏览和探索相关的文献和数据,提取和可视化关键的信息,生成和优化候选的假设,以及进行自动化的实验和模拟。
三、AI驱动的实验和模拟
这篇文献展示了AI可以帮助科学家设计实验方案,选择最有价值的数据点,控制实验过程,解决复杂的微分方程,生成新的数据样本,等等。AI驱动的实验和模拟的目标是提高科学发现的效率和质量,以及探索新的科学领域和问题。这部分内容包括以下几个方面:
高效评估科学假设:AI可以通过规划和引导实验来选择最有前景的假设进行验证,例如在药物发现、材料设计、量子物理等领域。AI可以利用强化学习、主动学习、贝叶斯优化等技术来动态调整实验参数和策略,以最大化实验的收益和安全性。
利用模拟推断假设的可观测结果:计算机模拟是一种强大的工具,可以根据假设来推断实际系统的行为和性质,例如在分子动力学、流体力学、天文学等领域。AI可以提高计算机模拟的准确性和效率,通过更好地拟合复杂系统的关键参数,求解控制复杂系统的微分方程,以及建模复杂系统的状态分布。
在组合假设空间中导航:AI可以通过生成模型和自监督学习来探索巨大的假设空间,例如在化学合成、蛋白质折叠、符号回归等领域。AI可以利用潜在空间的优化和变换来搜索和设计新的分子结构、数学表达式、物理定律等,以及评估它们的可行性和有效性。
该图介绍了三种利用人工智能(AI)来加速和优化科学实验和模拟的方法,分别是:
a:利用AI控制复杂动态系统的核聚变:Degrave等人166开发了一个AI控制器,用来通过磁场调节托卡马克反应堆中的核聚变。AI控制器接收实时的电压水平和等离子体配置的测量数据,并采取行动来控制磁场和实现实验目标,如维持一个可用的电源。控制器是通过模拟和奖励函数来训练和更新模型参数的。
b:利用AI加速复杂系统的计算模拟中的稀有事件检测:例如蛋白质的不同构象结构之间的转变。Wang等人169使用了一个基于神经网络的不确定性估计器,来引导添加一些补偿原始势能的势能,使得系统能够逃离局部最小值(灰色区域)并更快地探索配置空间。这种方法可以提高模拟的效率和准确性,从而深入理解复杂的生物现象。
c:利用AI求解偏微分方程的神经网络框架:AI求解器是一个物理信息神经网络,用来估计目标函数f。变量x的导数是通过自动求导神经网络的输出来计算的。当偏微分方程的表达式未知(由η参数化)时,可以通过求解一个多目标损失函数来估计方程的函数形式和对观测数据y的拟合程度。图中的核聚变图标来源于iStockphoto/VectorMine。
四、AI在科学中的挑战和机遇
这篇文献分析了AI在科学中的局限性和风险,例如数据质量和管理、模型可解释性和可靠性、分布偏移和泛化能力等,以及如何通过跨学科合作、开放共享、伦理规范等措施促进AI在科学中的发展和应用。
1)利用科学数据的实际过程中需要考虑:
2)在算法创新方面:
主要包括以下几点:
数据的质量和可用性:科学数据往往受到测量技术的限制,导致数据不完整、有偏差或有冲突,同时也受到隐私和安全的保护,难以公开共享。因此,需要建立标准化和透明化的数据格式,以减轻数据处理的工作量 。此外,还可以利用联邦学习和加密算法来防止将具有高商业价值的敏感数据泄露到公共领域。利用开放的科学文献,自然语言处理和知识图谱技术可以促进文献挖掘,以支持材料发现,化学合成和治疗科学。
人机协同的AI驱动的设计、发现和评估:深度学习的使用给人机协同的AI驱动的设计、发现和评估带来了复杂的挑战。为了自动化科学工作流,优化大规模的模拟代码和操作仪器,自主机器人控制可以利用预测并在高通量的合成和测试线上进行实验,创建自动驾驶实验室。生成模型在材料探索中的早期应用表明,可以识别出具有期望性质和功能并可合成的数百万种可能的材料。例如,King等人结合了逻辑AI和机器人,自主地生成关于酵母的功能基因组学假设,并使用实验室自动化来实验性地测试假设。在化学合成中,AI优化候选合成路线,然后由机器人引导化学反应在预测的合成路线上进行。
AI系统的实现和标准化:AI系统的实现涉及复杂的软件和硬件工程,需要一系列相互依赖的步骤,从数据策划和处理到算法实现和用户和应用接口的设计。实现中的细微变化可能导致性能的显著变化,并影响AI模型在科学实践中的集成成功。因此,需要考虑数据和模型的标准化。AI方法可能会因为模型训练的随机性,模型参数的变化和训练数据集的演化而导致可重复性的问题,这些问题既依赖于数据,也依赖于任务。标准化的基准和实验设计可以缓解这些问题。另一个改善可重复性的方向是通过开源倡议,发布开放的模型、数据集和教育计划。
超分布泛化:这是AI研究的前沿问题,指的是AI模型能否在不同的数据分布下保持有效和可靠。作者认为人类能够更好地泛化,是因为人类能够建立因果模型,而不仅仅是统计模型。
因果推理:这是AI领域的一个新兴方向,目的是让AI模型能够理解和控制数据和现象背后的因果关系,从而提高AI的智能性和可靠性。
自监督学习:这是一种利用大量无标签数据来学习有用表示的技术,有助于AI模型在数据稀缺的情况下迁移知识和泛化能力。
迁移学习:这是一种利用已有领域的知识来提高新领域的学习效果的技术,目前还存在一些问题,如缺乏理论指导,容易受到数据分布变化的影响,以及可能出现负迁移的现象。
实际应用:为了解决科学家关心的难题,AI方法的开发和评估必须在真实的场景中进行,如药物设计中的合成路径,同时还要考虑模型的不确定性和可靠性。
多模态数据的处理和融合:科学数据具有多种形式和特征,如图像、文本、时间序列、序列、图和结构等。不同的数据形式可以描述同一个科学对象或现象的不同方面,如高能物理中的喷流结构。使用神经网络处理图像已经有很多研究,但仅仅处理图像是不够的。同样,单独使用其他数据形式也不能给出一个完整和综合的系统视角。因此,需要探索如何有效地整合多模态的观测数据,利用神经网络的模块化特性,将不同的数据形式转换为通用的向量表示。
科学知识的引入和平衡:科学知识,如分子的旋转对称性、数学的等式约束、生物学的疾病机制和复杂系统的多尺度结构等,可以加入到AI模型中,提高模型的性能和可解释性。然而,如何选择和实现最有用和最实用的科学知识还不清楚。由于AI模型需要大量的数据来拟合,当数据量小或稀疏标注时,引入科学知识可以帮助模型学习。因此,需要建立原则性的方法,将知识融入到AI模型中,并理解领域知识和数据学习之间的权衡。
模型的可解释性和可信度:AI模型往往是黑箱的,意味着用户不能完全解释模型是如何产生输出的,以及哪些输入对输出的产生是关键的。黑箱模型会降低用户对模型预测的信任,并限制模型在需要在实际应用前理解模型输出的领域的适用性,如人类太空探索和气候科学等。透明的深度学习模型仍然难以实现,尽管有很多可解释性技术。然而,人类大脑能够合成高层次的解释,即使不完美,也能说服其他人类,这给我们希望,通过在类似的高层次抽象上建模现象,未来的AI模型将提供至少与人类大脑提供的一样有价值的可解释性。这也表明,研究高层次的认知可能会激发未来的深度学习模型,结合当前的深度学习能力和操纵符号和概念的能力。
3)科学和科学企业的行为方面:
AI的需求受到两种力量的影响:一是有利于AI应用的问题的存在,如自动化实验室;二是智能工具提升现有水平和创造新机会的能力,如探索实验无法触及的生物、化学或物理过程。
研究团队的组成将包括AI专家、软硬件工程师,以及涉及政府、教育机构和企业的新型合作形式。
AI模型的规模和复杂度不断增长,导致巨大的能源和计算成本。因此,大型科技公司投资了大量的计算基础设施和云服务,而高等教育机构则在多学科整合和数据资源方面有优势。这些互补的资产促进了产学合作的新模式。
AI系统的性能逐渐超越人类,使其成为实验室常规工作的替代品。这种方式使研究人员能够从实验数据中迭代地开发预测模型,并选择实验来改进它们,而无需手动执行繁琐和重复的任务。为了支持这种范式转变,出现了一些教育项目,培训科学家在科学研究中设计、实施和应用实验室自动化和AI。这些项目帮助科学家理解何时使用AI是合适的,以及如何避免AI分析的误解。
目录
一、定义
1. 数据库(Database)
2. 数据仓库(Data Warehouse)
3. 数据湖(Data Lake)
4. 数据集市(Data Mart)
5. 数据湖仓(Data Lakehouse)
二、相同、异同
2.1 相同点
2.2 不同点
三、常见的工具
数据库:
数据仓库:
数据湖:
数据集市:
数据湖仓:
一、定义 当然,以下是关于数据库、数据仓库、数据湖、数据集市和数据湖仓的定义、解释以及它们的应用场景和现实中的例子:
1. 数据库(Database) 定义与解释:
数据库是按照数据结构来组织、存储和管理数据的仓库,是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
应用场景:
数据库广泛应用于各种需要存储、检索和管理数据的系统中,如客户关系管理(CRM)、企业资源规划(ERP)、电子商务网站等。
现实例子:
例如,银行使用数据库来存储客户的账户信息、交易记录等;电商网站使用数据库来存储商品信息、用户购物车内容、订单数据等。
2. 数据仓库(Data Warehouse) 定义与解释:
数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策和信息的全局共享。
应用场景:
数据仓库主要用于支持企业的决策分析,如市场分析、客户分析、业务过程优化等。
现实例子:
电信公司可能使用数据仓库来存储和分析客户的通话记录、数据使用情况等,以便制定更精准的营销策略或优化网络布局。
3. 数据湖(Data Lake) 定义与解释:
数据湖是一个存储各种各样原始数据的大型仓库,其中的数据可供存取、处理、分析及传输。数据湖通常是企业所有数据的单一存储,包括源系统数据的原始副本以及用于报告、可视化、分析和机器学习等任务的转换数据。
应用场景:
数据湖适用于需要存储和处理大量多样化数据的环境,尤其是当数据的结构和用途在存储时并不明确的情况下。
现实例子:
一个大型互联网公司可能会使用数据湖来存储用户行为日志、社交媒体帖子、图片和视频等,以便后续进行数据挖掘和机器学习。
4. 数据集市(Data Mart) 定义与解释:
数据集市是一个小型的、面向特定主题或部门的数据仓库,通常用于满足特定用户群体的分析需求。
应用场景:
数据集市适用于需要快速响应特定查询或分析需求的部门或项目团队。
现实例子:
一个销售部门可能会建立自己的数据集市,其中包含与销售业绩、客户信息和市场活动相关的数据,以便销售团队能够快速地进行销售分析和预测。
5. 数据湖仓(Data Lakehouse) 定义与解释:
数据湖仓是一个结合了数据湖和数据仓库优点的存储架构,旨在提供一个既能存储原始数据又能进行高效分析的环境。
使用数据库的时候,我们可以用JDBC来实现mysql数据库与java程序之间的通信,为了提高通信效率,我们有了数据库连接池比如druid等等。而我们想通过Java程序控制redis,同样可以借助一些工具来实现,这就是redis客户端,常见的有Jedis、lettuce、redisson等等,这几个工具各有优缺点,而且应用都比较多,所以我们分三篇逐步来看。
Jedis 是一个功能强大、易用性高的 Redis 客户端库,适用于 Java 开发人员在项目中连接和操作 Redis 服务器。接下来,将介绍 Jedis 的使用方法和示例。
目录
1. Jedis介绍与安装测试
2.Jedis的基本操作体验
1.设置和获取字符串类型的键值对
2.判断键是否存在
3.删除键
4.设置键的过期时间
3.Jedis的数据类型操作
1.字符串类型
2.列表类型
3.集合类型
4.哈希类型
5.有序集合类型
4. Jedis 的事务操作
1.开启和提交事务
2.回滚事务
3.监视键
5. Jedis 的发布订阅操作
1.发布消息
2.订阅消息
6. Jedis 的管道操作
7. Jedis 的连接池配置和使用
8. Jedis 的异常处理
1. 处理连接异常
2. 处理命令执行异常:
9.Jedis 的性能优化
1. Jedis介绍与安装测试 Jedis 是一个流行的 Java 编写的 Redis 客户端库,它提供了连接和操作 Redis 服务器的功能。Jedis具有以下特点:
简单易用:Jedis 提供了简洁的 API,方便开发人员使用,减少了连接和操作 Redis 的复杂性。不过呢,简单也意味一些高级不能不支持的,这个与后面的客户端对比就知道了高性能:Jedis 是通过直接与 Redis 服务器进行通信来实现操作的,因此具有较高的性能。支持多种数据类型:Jedis 支持操作 Redis 的各种数据类型,包括字符串、哈希、列表、集合、有序集合等。支持事务和管道:Jedis 提供了事务和管道的支持,可以将多个操作打包成一个原子操作,提高了操作的效率。支持连接池:Jedis 支持连接池,可以复用连接,避免频繁建立和关闭连接的开销,提高了性能。 如果我们想在通过java 来管理redis,可以按照下面的方式进行:
近期,基于GPT-4的AI系统Coscientist成功在Nature杂志上发表了一篇论文,展示了其在科学研究领域的引人注目的表现。这一新兴的大模型化学家能够自主完成复杂的实验任务,甚至包括2010年诺贝尔化学奖获得者因其研究而获奖的钯催化交叉偶联反应。这种能力被认为可以高效地构建碳-碳键,生成以往难以合成的物质,彰显了GPT-4在化学领域的强大潜力。
Coscientist的成功离不开其多模块交互的系统架构。它包含Planner、Web searcher、Code execution、Docs searcher、Automation等五大模块。Planner作为智能中枢,根据用户输入调用和协调其他模块,规划和推进整个实验流程。Web searcher负责在互联网中检索实验信息,而Code execution提供独立的Python执行环境,实现实验相关的计算工作。
论文:https://www.nature.com/articles/s41586-023-06792-0
Docs searcher则用于文本检索和文档理解,提供实验参数和操作细节。最后,Automation模块将Planner的实验方案转换为设备控制代码,实现实验设备的自动化操作。这种多层次、多步骤的协同工作使得Coscientist能够在科学实验中胜任各种任务。
然而,随着这一科技进步,争议也随之而来。一些化学领域的从业者表示担忧,认为这样的大模型化学家可能导致更多博士失业。在论文发布后,有网友发表评论表示担忧,认为这种AI系统的崛起可能削弱了人类专业研究者的地位。这种技术的广泛应用可能改变科研领域的人才需求和就业格局。
Coscientist的成功展示了GPT-4在科学研究中的广泛应用前景。然而,随之而来的争议也凸显了科技进步带来的社会影响,需要更深入的讨论和思考。未来,如何平衡人工智能在科学研究中的应用与对专业从业者的潜在影响,将成为科研领域需要认真思考的问题。
大语言模型(LLM)|ChatGPT相关文章(以下点击可阅读):
AI超大模型!一个午休就能读完20万篇论文、提取信息完成生物数据库更新!
ChatGPT一周年:AI如何改变医疗健康领域的未来?
两篇Nature:AI实现新材料的快速合成!17天独自创造41种新材料
什么?写提示词就能发医学高分论文!北京大学肿瘤医院:《高级提示词作为催化剂:增强大型语言模型在胃肠道癌症管理中的作用》
顶刊 | 解放军总医院:基于生成对抗网络的主动脉和颈动脉非造影 CT 血管造影
Nature:AI 如何重塑科研范式
GPT-4V在医疗领域全面测评(178页,128个案例)
目前最好的医疗大语言模型居然是……
医疗AI与GPT | 梳理全球医疗大模型
AI大语言模型在医学文本提取结构化信息中的应用
1个小时利用ChatGPT完成神经外科领域的完全虚构的论文!AI写论文的逼真程度令人震惊
精选32篇AI大模型&GPT+医学的论文(免费领取)
以色列一对师生借助ChatGPT,1小时完成1篇论文糖尿病论文
利用ChatGPT,这位医生4个月内完成16篇论文,且已发表5篇!医生科研开启加速模式!
Nature新规:用ChatGPT写论文可以,列为作者不行
AI论文 | ChatGPT在放射医学领域的应用探索
AI论文 | ChatGPT在医学中的应用概述:应用、优势、局限性、未来前景和伦理思辨
AI论文 | GPT-4 对诊断罕见眼病有什么作用?
AI论文 | 从临床和科研场景分析ChatGPT在医疗健康领域的应用可行性
AI论文 | ChatGPT可以撰写研究文章吗?以人群层面疫苗有效性分析为例
北医三院:ChatGPT用于用药咨询行不行?
北京协和医院:大型语言模型在重症医学中的应用与挑战
ChatGPT在PubMed上的发表数量超过1000篇:展望未来之路
Nature:大语言模型构建的AI医生,比人类医生更出色
GPT辅助论文降重教程,100%降至13%(实用指令,赶紧收藏)
国自然基金委:在各科学部设立科普类项目!面青地等将科普成果列入项目成果;资助强度较大项目,应围绕项目开展科普工作
2023年国自然医学科学学部人工智能及大模型相关课题项目汇总
科研之心,致力于探索AI大模型与科研结合。科研之心为您提供最新的AI资讯、最实用的AI工具、最深入的AI分析,帮助您在科学研究中发掘AI的无限潜力。
欢迎关注,保持交流!
上次我们讨论了边缘计算,并用无人零售和边缘计算的例子,说明了边缘计算的便利性。
但是边缘计算,也有很多限制。
硬件资源限制
边缘设备通常具有有限的计算、存储和网络资源。这种资源限制使得在处理大量数据或执行复杂任务时,边缘设备可能无法提供与云数据中心相当的性能。硬件更新换代的成本和时间也是限制因素。随着技术的不断进步,边缘设备需要定期更新以维持其性能,但这可能涉及大量的资本支出和运营中断。 网络带宽与延迟:
尽管边缘计算旨在减少数据传输到远程云中心的延迟,但边缘节点之间的网络带宽可能仍然有限。这可能导致在处理大量数据时出现拥塞和延迟。网络拓扑的复杂性也可能增加延迟。例如,在一些地区,由于基础设施不足或地理位置偏远,建立和维护高效的边缘计算网络可能具有挑战性。 数据管理与安全:
边缘计算涉及大量数据的生成、处理和存储。有效管理这些数据并确保其完整性、可用性和安全性是一个重大挑战。由于边缘设备分布在不同的地理位置,它们可能更容易受到物理攻击或网络攻击。因此,确保边缘设备的安全性是至关重要的。 标准化与互操作性:
目前,边缘计算领域缺乏统一的标准和规范。不同的供应商可能会采用不同的硬件、软件和网络解决方案,这可能导致系统集成和互操作性的问题。缺乏标准化也可能阻碍边缘计算的广泛部署和采用,因为组织可能需要投入大量的时间和资源来定制和集成不同的解决方案。 软件与算法优化:
为了在资源受限的边缘设备上高效运行,软件和算法需要进行优化。这可能涉及重新设计现有的应用程序、开发轻量级的操作系统和中间件,以及使用高效的算法和数据结构。软件和算法的持续优化也是一个挑战,因为新技术和应用场景的不断出现可能需要频繁的代码更新和调整。 成本效益分析:
部署和维护边缘计算基础设施可能涉及显著的成本。这包括硬件设备的采购、网络的建设和维护、以及安全和管理等方面的持续投入。对于许多组织来说,进行成本效益分析以确定边缘计算的实际投资回报率是一个重要步骤。然而,由于技术和市场的不确定性,这种分析可能具有挑战性。 人才与技能缺口:
边缘计算是一个相对较新的领域,它需要具备跨多个学科(如计算机科学、网络工程、数据科学和安全)的技能和知识。目前,市场上可能缺乏足够数量的合格专业人员来支持边缘计算的广泛部署和运营。这可能导致组织在采用边缘计算技术时面临人才招聘和培训的挑战。 边缘计算的发展受到多个瓶颈的限制,这些瓶颈需要技术、经济、政策和教育等多方面的努力来克服。
用户中心:集中提供用户的检索、操作、注册、登录、鉴权
此接口与用户关系紧密,在【用户中心】项目后端新增一个接口——根据标签搜索用户
AND:允许用户传入多个标签,多个标签都存在才能搜索出来OR:允许用户传入多个标签,有任何一个标签存在就能搜索出来 本文演示两种方式进行标签搜索:
使用 SQL 查询:通过 Mybatis-plus 的 like 方法实现标签信息 tags 的模糊匹配,优点是实现简单使用内存查询:优点是可以在代码中呈现,使用灵活 方式一:使用 SQL 查询 1. 使用 MybatisX 插件简化开发(在插件商店直接搜索 MybatisX 点击 install 进行插件的安装)
选择要操作的表,自动生成下列文件,提高开发效率
数据库表 - Java 实体类映射文件:Tag.java
针对 tag 表的数据库业务层操作:TagService.java 和 TagServiceImpl.java
针对 tag 表的数据库持久层操作:TagMapper.java
数据库操作映射 SQL(较复杂的 SQL 语句)文件:TagMapper.xml
2. 编写模糊查询匹配用户标签的业务代码
/** * 根据标签搜索用户 * @param tagNameList 用户的标签列表 * @return 匹配该标签列表的用户列表 */ public List<User> searchUsersByTags(List<String> tagNameList) { // 1. 判断参数是否为空 if (CollectionUtils.isEmpty(tagNameList)) { throw new BusinessException(ErrorCode.PARAMS_ERROR); } // 2.
【主要功能】 config.json方式实现全局配置参数的读写操作
使用python实现以下功能:
1、使用将接口获取的变量值,写入到当前目录下的config文件中,如delayTime=10;
2、读取当前目录下的config文件中,特定变量的值,如delayTime=10;
3、若config文件或者节点不存在,则自动进行创建;
【详细代码】
#!/usr/bin/env python # -*- coding: utf-8 -*- import json,os def write_config_json(key=None, value=None,section="default", config_file='config.json'): """ 将接口获取的变量值写入到config文件中 :param config_file: config文件路径,默认为'config.json' :param key: 需要写入的变量名 :param value: 需要写入的变量值 :return: 如果文件不存在则创建,如果节点不存在则新增,如果节点存在则覆盖 """ if not os.path.exists(config_file): print(f'文件{config_file}不存在,将创建新的文件') with open(config_file, 'w', encoding='utf-8') as f: json.dump({f'{section}':{}}, f) with open(config_file, 'r', encoding='utf-8') as f: config = json.load(f) config[section][key] = value with open(config_file, 'w', encoding='utf-8') as f: json.dump(config, f, indent=4) # 封装函数:一次写入多个值至配置文件,适用于大量数据写入,提高性能 def write_configs_json(keys_values_dict, section="
先来给大家推荐一个我日常会使用到的图片高清处理在线工具,主要是免费,直接白嫖 。
有时候我看到一张图片感觉很不错,但是图片清晰度不合我意,就想有没有什么工具可以处理让其更清晰,
网上随便搜下就能找到,但是搜出来的很大可能是需要付费,这里便发现了两个比较好用的值得推荐,
或许它每天对免费用户有一定的限制,但对于我每天可能也就处理不超过三张图片足矣,批量处理很可能还是付费吧!
AI人工智能图片放大JPGHD 人工智能老照片无损修复 这里对比可能不容易看出效果,最好实际操作。
PendingIntent 你可能不了解或者很少接触,当 targetSdk 31 >= 遇上 PendingIntent 一不小心就会崩溃 (ÒωÓױ)!
路人甲:我之前的代码也有使用 PendingIntent,运行好好地,没有你说的闪退 →_→
路人乙:这是非必现,还需要满足一些条件鸭
问题 java.lang.IllegalArgumentException: com.***.gamecenter:
Targeting S+ (version 31 and above) requires that one of FLAG_IMMUTABLE or FLAG_MUTABLE be specified when creating a PendingIntent.
解决 看堆栈就知道闪退是 androidx.work,他是什么?
在可运行模块 build.gradle 里强制依赖指定不闪退版本即可。
我一路尝试了好几个版本,从 2.0.0 ~ 2.8.0 发现 2.7.0 开始不闪退了,也就是此时开始 PendingIntent Flag 或许添加了 FLAG_IMMUTABLE or FLAG_MUTABLE 其中的某个或两个 flag。
// app/build.gradle dependencies { //2.7.0 2.
文章目录 前言一、CVE-2022-32991靶场简述二、找注入点三、CVE-2022-32991漏洞复现1、判断注入点2、爆字段个数3、爆显位位置4 、爆数据库名5、爆数据库表名6、爆数据库列名7、爆数据库数据 总结 前言 此文章只用于学习和反思巩固sql注入知识,禁止用于做非法攻击。注意靶场是可以练习的平台,不能随意去尚未授权的网站做渗透测试!!!
一、CVE-2022-32991靶场简述 该CMS的welcome.php中存在SQL注入攻击。
靶场地址在春秋云境官网https://yunjing.ichunqiu.com/
二、找注入点 因为已经知道在此cms中的welcome.php中eid参数可以进行sql注入,那么我们的思路就是先找到注入地方。
1、首先进来是一个登录页面(如图所示)
这里是login.php的界面,显然不是我们要注入的地方。我们选择创建一个用户登录进去再去找注入点。而且这里登录框试了试sql注入,发现也是不行的。
2、登录进去发现了网址是welcome.php了,那么离flag更进一步了。(如图所示)
发现此时url的参数是q,显然不是eid,我们还得继续深入。感兴趣的小伙伴看到这里有参数也可以试一试有没有sql注入,但是肯定是没有的哈哈哈。
3、我们看到start的按钮,只能去点它了,看看是不是我们注入的地方,点进去发现(如图所示)
成功找到eid参数,那么我们就开始我们的sql手工注入吧。(我试了试n参数好像也是可以注入的)
三、CVE-2022-32991漏洞复现 1、判断注入点2、爆字段个数3、爆显位位置4、爆数据库名5、爆数据库表名6、爆数据库列名7、爆数据库数据 1、判断注入点 (如图所示)这里我们老规矩抛出and 1=1 和 and 1=2测试。发现页面依旧正常,排除数字型。直接提交1’发现报错,报错信息为
Warning: mysqli_fetch_array() expects parameter 1 to be mysqli_result,
boolean given in /var/www/html/welcome.php on line 98
很大可能是单引号闭合了,因为我们多了个单引号,变成eid=‘60377db362694’'。后面多出来的单引号导致报错了。我们把它闭合看看是否变成正常界面。注入语句为
60377db362694'--+ 发现是页面正常了。
那么这是一个单引号闭合的get提交的sql注入。
2、爆字段个数 注入语句为
eid=60377db362694' order by 6--+ 发现6的时候报错,5正常。说明有5个字段。
3、爆显位位置 注入语句为
eid=60377db362694' union select 1,2,3,4,5--+ 发现显位3
4 、爆数据库名 注入语句为
eid=60377db362694' union select 1,2,database(),4,5--+ 得到数据库名为ctf
5、爆数据库表名 注入语句为
eid=60377db362694' union select 1,2,group_concat(table_name),4,5 from information_schema.
CA证书–基础–02–使用openssl生成CA认证文件并为服务器和客户端颁发CA签名证书 1、生成认证主要流程 虚拟出一个CA认证机构,为其生成公私钥以及自签证书生成服务器方私钥,发送包含服务器方公私钥的申请文件给CA机构请求签发证书生成客户端方私钥,发送包含服务器方公私钥的申请文件给CA机构请求签发证书生成证书 注意:建议新建一个或多个目录用于存放密钥/认证文件
2、具体生成过程 2.1、虚拟出一个CA认证机构,为其生成公私钥以及自签证书 2.1.1、为CA机构生成私钥 mkdir /root/CA cd /root/CA openssl genrsa -out ca.prikey 2048 genrsa:表示生成私钥 -out:表示输出到哪个文件 2048:指定密钥长度 2.1.2、为CA机构生成公钥 openssl rsa -in ca.prikey -pubout -out ca.pubkey rsa:表示生成公钥 -in:指定输入文件 -pubout:表示提示openssl要输出的文件为公钥文件 2.1.3、为CA机构生成自签名证书 openssl req -new -x509 -days 3650 -key ca.prikey -out ca.cert req:表示生成请求文件 -new:表示创建一个新请求 -x509:类似证书版本号 -days:指定证书有效时间 -key:指定私钥文件 注意:提示输入信息可以直接回车,如若输入错误可以尝试使用BackSpace或者Ctrl+BackSpace进行删除
2.2、服务器方 生成内容 2.2.1、为服务器生成私钥 mkdir -p /root/CA/service cd /root/CA/service openssl genrsa -out ser.prikey 2048 2.2.2、生成服务器证书申请文件 openssl req -new -key ser.prikey -out ser.csr 2.2.3、把服务器申请文件发送给CA机构,请求签发证书 openssl x509 -req -days 3650 -in ser.
点击上方蓝字关注我
一个正在运行的MySQL实例,如何查看对应的配置文件用的是哪一个?如果存在多个文件,生效的顺序是怎么样的?
1. 方法一
首先可以先选择查看MySQL进程信息来判断使用了哪个配置文件,例如:
ps -aux|grep mysqld root 25628 0.0 0.0 112828 988 pts/0 S+ 19:13 0:00 grep --color=auto mysqld root 27503 0.0 0.0 113416 1660 ? S 2023 0:00 /bin/sh /usr/local/mysql5.7/bin/mysqld_safe --defaults-file=/data/mysql/mysql3306/etc/my.cnf mysql 28697 0.1 38.3 6168644 689056 ? Sl 2023 120:07 /usr/local/mysql5.7/bin/mysqld --defaults-file=/data/mysql/mysql3306/etc/my.cnf --basedir=/usr/local/mysql5.7 --datadir=/data/mysql/mysql3306/data --plugin-dir=/usr/local/mysql5.7/lib/mysql/plugin --user=mysql --log-error=/data/mysql/mysql3306/logs/mysqld.error --open-files-limit=65535 --pid-file=/data/mysql/mysql3306/tmp/mysqld.pid --socket=/data/mysql/mysql3306/tmp/mysql.sock --port=3306 结果中有--defaults-file=/data/mysql/mysql3306/etc/my.cnf,即该实例所使用的配置文件信息。
2. 方法二
有的时候,如果不是不带defaults-file参数启动数据库时,查看进程信息的结果中是没有对应的配置文件信息。例如:
ps -aux|grep mysqld mysql 1891850 1.2 2.2 2308948 366080 ? Ssl 2023 1355:28 /usr/sbin/mysqld root 3183979 0.
Kafka在实际应用中,经常被用作高性能、可扩展的消息中间件。
Kafka自定义了一套网络协议,只要遵守这套协议的格式,就可以向Kafka发送消息,也可以从Kafka中拉取消息。
在实践生产过程中,一套API封装良好、灵活易用的客户端可以避免开发人员重复劳动,提高开发效率,也可以提高程序的健壮性和可靠性。
Kafka提供了Java版本的生产者的实现——KafkaProducer,使用KafkaProducer的API可以轻松实现同步/异步发送消息、批量发送、超时重发等复杂的功能,在业务模块向Kafka写入消息时,KafkaProducer就显得必不可少。
现在,Kafka的爱好者已经使用多种语言(诸如C++、Java、Python、Go等)实现了Kafka的客户端。
如果读者使用其他语言,可以到Kafka官方网站的wiki(https://cwiki.apache.org/confluence/display/KAFKA/Clients)查找相关资料。
在Kafka core模块的kafka.producer包中,新版本的生产者客户端实现KafkaProducer(Java实现)在Kafka clients模块的org.apache.kafka.clients.producer包中。
KafkaProducer分析 在图中简略描述了KafkaProducer发送消息的整个流程。
下面简述图中每个步骤的操作:
Producerlnterceptors对消息进行拦截。Serializer对消息的key和value进行序列化。Partitioner为消息选择合适的Partition。RecordAccumulator收集消息,实现批量发送。Sender从RecordAccumulator获取消息。构造ClientRequest。将ClientRequest交给NetworkClient,准备发送。NetworkClient将请求放入KafkaChannel的缓存。执行网络I/O,发送请求。收到响应,调用ClientRequest的回调函数。调用RecordBatch的回调函数,最终调用每个消息上注册的回调函数。 消息发送的过程中,涉及两个线程协同工作。主线程首先将业务数据封装成ProducerRecord对象,之后调用send方法将消息放入RecordAccumulator(消息收集器,也可以理解为主线程与Sender线程之间的缓冲区)中暂存。
Sender线程负责将消息信息构成请求,并最终执行网络IVO的线程,它从RecordAccumulator中取出消息并批量发送出去。
需要注意的是,KafkaProducer是线程安全的,多个线程间可以共享使用同一个KafkaProducer对象。
KafkaProducer实现了Producer接口,在Producer接口中定义KafkaProducer对外提供的API,分为四类方法。
send方法:发送消息,实际是将消息放入RecordAccumulator暂存,等待发送。flush方法:刷新操作,等待RecordAccumulator中所有消息发送完成,在刷新完成之前会阻塞调用的线程。partitionsFor方法:在KafkaProducer中维护了一个Metadata对象用于存储Kafka集群的元数据,Metadata中的元数据会定期更新。partitionsFor方法负责从Metadata中获取指定Topic中的分区信息。close方法:关闭此Producer对象,主要操作是设置close标志,等待RecordAccumulator中的消息清空,关闭Sender线程。
还有一个metrics方法,用于记录统计信息,与消息发送的流程无关,我们不做详细分析。
了解了Producer接口的功能之后,我们下面就来分析KafkaProducer的具体实现。 首先,介绍KafkaProducer中比较重要的字段,在后面分析过程中,会逐个进行分析,如图所示。
PRODUCER_CLIENT_ID_SEQUENCE:clientld的生成器,如果没有明确指定client的Id,则使用字段生成一个ID。clientld:此生产者的唯一标识。partitioner:分区选择器,根据一定的策略,将消息路由到合适的分区。maxRequestSize:消息的最大长度,这个长度包含了消息头、序列化后的key和序列化后的value的长度。totalMemorySize:发送单个消息的缓冲区大小。accumulator:RecordAccumulator,用于收集并缓存消息,等待Sender线程发送。sender:发送消息的Sender任务,实现了Runnable接口,在ioThread线程中执行。ioThread:执行Sender任务发送消息的线程,称为“Sender线程”。compressionType:压缩算法,可选项有none、gzip、snappy、lz4。这是针对RecordAccumulator中多条消息进行的压缩,所以消息越多,压缩效果越好。keySerializer:key的序列化器。valueSerializer:value的序列化器。Metadata metadata:整个Kafka集群的元数据。maxBlockTimeMs:等待更新Kafka集群元数据的最大时长。requestTimeoutMs:消息的超时时间,也就是从消息发送到收到ACK响应的最长时长。interceptors:Producerlnterceptor集合,Producerlnterceptor可以在消息发送之前对其进行拦截或修改;也可以先于用户的Callback,对ACK响应进行预处理。producerConfig:配置对象,使用反射初始化KafkaProducer配置的相对对象。 KafkaProducer构造完成之后,我们来关注KafkaProducer的send方法。图展示了整个send方法的调用流程。
Producerlnterceptors&Producerlnterceptor Producerlnterceptors是一个Producerlnterceptor集合,其onSend方法、onAcknowledgement方法、onSendEror方法,实际上是循环调用其封装的Producerlnterceptor集合的对应方法。
Producerlnterceptor对象可以在消息发送之前对其进行拦截或修改,也可以先于用户的Callback,对ACK响应进行预处理。
如果熟悉Java Web开发,可以将其与Filter的功能做类比。
如果要使用自定义Producerlnterceptor类,只要实现Producerlnterceptor接口,创建其对象并添加到Producerlnterceptors中即可。
Producerlnterceptors与ProducerInterceptor之间的关系如图所示。
Kafka集群元数据 每个Topic中有多个分区,这些分区的Leader副本可以分配在集群中不同的Broker上。
我们站在生产者的角度来看,分区的数量以及Leader副本的分布是动态变化的。
通过简单的示例说明这种动态变化:在运行过程中,Leader副本随时都有可能出现故障进而导致Leader副本的重新选举,新的Leader副本会在其他Broker上继续对外提供服务。
当需要提高某Topic的并行处理消息的能力时,我们可以通过增加其分区的数量来实现。
当然,还有别的方式导致这种动态变化,例如,手动触发“优先副本”选举等。
我们创建的ProducerRecord中只指定了Topic的名称,并未明确指定分区编号。
KafkaProducer要将此消息追加到指定Topic的某个分区的Leader副本中,首先需要知道Topic的分区数量,经过路由后确定目标分区,之后KafkaProducer需要知道目标分区的Leader副本所在服务器的地址、端口等信息,才能建立连接,将消息发送到Kafka中。
因此,在KafkaProducer中维护了Kafka集群的元数据,这些元数据记录了:某个Topic中有哪几个分区,每个分区的Leader副本分配哪个节点上,Follower副本分配哪些节点上,哪些副本在ISR集合中以及这些节点的网络地址、端口。
在KafkaProducer中,使用Node、TopicPartition、PartitionInfo这三个类封装了Kafka集群的相关元数据,其主要字段如图所示。
Node表示集群中的一个节点,Node记录这个节点的host、ip、port等信息。TopicPartition表示某Topic的一个分区,其中的topic字段是Topic的名称,partition字段则此分区在Topic中的分区编号(ID)。PartitionInfo表示一个分区的详细信息。其中topic字段和partition字段的含义与TopicPartition中的相同,除此之外,leader字段记录了Leader副本所在节点的id,replica字段记录了全部副本所在的节点信息,inSyncReplicas字段记录了ISR集合中所有副本所在的节点信息。 通过这三个类的组合,我们可以完整表示出KafkaProducer需要的集群元数据。
这些元数据保存在了Cluster这个类中,并按照不同的映射方式进行存放,方便查询。Cluster类的核心字段如图所示。
nodes:Kafka集群中节点信息列表。nodesById:Brokerld与Node节点之间对应关系,方便按照Brokerld进行索引。partitionsBy TopicPartition:记录了TopicPartition与PartitionInfo的映射关系。partitionsByTopic:记录了Topic名称和Partitionlnfo的映射关系,可以按照Topic名称查询其中全部分区的详细信息。availablePartitionsByTopic:Topic与Partitionlnfo的映射关系,这里的List中存放的分区必须是有Leader副本的Partition,而partitionsByTopic中记录的分区则不一定有Leader副本,因为某些中间状态,例如Leader副本宕机而触发的选举过程中,分区不一定有Leader副本。partitionsByNode:记录了Node与PartitionInfo的映射关系,可以按照节点Id查询其上分布的全部分区的详细信息。 Metadata中封装了Cluster对象,并保存Cluster数据的最后更新时间、版本号(version)、是否需要更新等待信息,如图所示。
topics:记录了当前已知的所有topic,在cluster字段中记录了Topic最新的元数据。version:表示Kafka集群元数据的版本号。Kafka集群元数据每更新成功一次,version字段的值增1。通过新旧版本号的比较,判断集群元数据是否更新完成。metadataExpireMs:每隔多久,更新一次。默认是300×1000,也就是5分种。refreshBackoffMs:两次发出更新Cluster保存的元数据信息的最小时间差,默认为100ms。这是为了防止更新操作过于频繁而造成网络阻塞和增加服务端压力。在Kafka中与重试操作有关的操作中,都有这种“退避(backoff)时间”设计的身影。lastRefreshMs:记录上一次更新元数据的时间戳(也包含更新失败的情况)。lastSuccessfulRefreshMs:上一次成功更新的时间戳。如果每次都成功,则lastSuccessfulRefreshMs、lastRefreshMs相等。 否则,lastRefreshMs>lastSuccessulRefreshMs。cluster:记录Kafka集群的元数据。needUpdate:标识是否强制更新Cluster,这是触发Sender线程更新集群元数据的条件之一。listeners:监听Metadata更新的监听器集合。自定义Metadata监听实现Metadata.Listener.onMetadataUpdate方法即可,在更新Metadata中的cluster字段之前,会通知listener集合中全部Listener对象。needMetadataForAllTopics:是否需要更新全部Topic的元数据,一般情况下,KafkaProducer只维护它用到的Topic的元数据,是集群中全部Topic的子集。 Metadata的方法比较简单,主要是操纵上面的几个字段,这里着重介绍主线程用到的requestUpdate方法和awaitUpdate方法。
requestUpdate()方法将needUpdate字段修改为true,这样当Sender线程运行时会更新Metadata记录的集群元数据,然后返回version字段的值。
awaitUpdate方法主要是通过version版本号来判断元数据是否更新完成,更新未完成则阻塞等待。
下面回到KafkaProducer.waitOnMetadata方法的分析,它负责触发Kafka集群元数据的更新,并阻塞主线程等待更新完毕。它的主要步骤是:
检测Metadata中是否包含指定Topic的元数据,若不包含,则将Topic添加到topics集合中,下次更新时会从服务端获取指定Topic的元数据。尝试获取Topic中分区的详细信息,失败后会调用requestUpdate)方法设置Metadata.needUpdate字段,并得到当前元数据版本号。唤醒Sender线程,由Sender线程更新Metadata中保存的Kafka集群元数据。主线程调用awaitUpdate()方法,等待Sender线程完成更新。从Metadata中获取指定Topic分区的详细信息(即PartitionInfo集合)。若失败,则回到步骤2继续尝试,若等待时间超时,则抛出异常。 waitOnMetadata()方法的具体实现如下:
Serializer&Deserializer 客户端发送的消息的key和value都是byte数组,Serializer和Deserializer接口提供了将Java对象序列化(反序列化)为byte数组的功能。在KafkaProducer中,根据配置文件,使用合适的Serializer。
图展示了Serializer和Deserializer接口以及它们的实现类。
Kafka已经为我们提供了Java基本类型的Serializer实现和Deserializer实现,我们也可以对Java复杂类型的自定义Serializer和Deserializer实现,只要实现Serializer或Deserializer接口即可。
下面简单介绍Serializer,Deserializer是其逆操作。
在Serializer接口中,configure()方法是在执行序列化操作之前的配置,例如,在StringSerializer.configure()方法中会选择合适的编码类型(encoding),默认是UTF-8;IntegerSerializer.configure()方法则是空实现。
serializer方法是真正进行序列化的地方,将传入的Java对象序列化为byte[]。
close方法是在其后的关闭方法,多为空实现。
Partitioner KafkaProducer.send()方法的下一步操作是选择消息的分区。
在有的应用场景中,由业务逻辑控制每个消息追加到合适的分区中,而有时候业务逻辑并不关心分区的选择。
在KafkaProducer.partition方法中,优先根据ProducerRecord中partition字段指定的序号选择分区,如果ProducerRecord.partition字段没有明确指定分区编号,则通过Partitioner.partition()方法选择Partition。
Kafka提供了Partitioner接口的一个默认实现——DefaultPartitioner,继承结构如图(左)所示,可以看到上面介绍的ProducerInterceptor接口也继承了Configurable接口。
在创建KafkaProducer时传人的key/value配置项会保存到AbstractConfig的originals字段中,如图(右)所示。AbstractConfig的核心方法是getConfiguredInstance方法,其主要功能是通过反射机制实例化originals字段中指定的类。在前面分析KafkaProducer的构造函数时,也看到过此方法的调用。