百度安全验证
目录
一、前言
二、硬件
三、软件
四、手机端设置
五、总结
一、前言 基于前面的51小车模块,我增加了循迹模块,先给大家看看效果吧:
二、硬件 循迹模块
1.循迹模块三个IO,硬件原理,亮灯返回1,灭灯返回0,当检测到黑线时返回0,检测到白色时返回1,因此可以设置寻黑线设置
2.P16接左边循迹,P17接右边循迹
三、软件 完整代码可在本文末尾下载
main.c
#include <REGX52.H> #include "UART.h" #include "Timer0.h" #include "Nixie.h" #include "Delay.h" sbit IN1 = P1^0; // 左上 sbit IN2 = P1^1; // 左下 sbit IN3 = P1^2; // 右上 sbit IN4 = P1^3; // 右上 sbit ENA = P2^6; //使能A sbit ENB = P2^7; //使能B sbit out0 = P2^0; // 右边避障,有障碍物就亮,输出0 sbit out1 = P2^1; // 左边避障,有障碍物就亮,输出0 sbit outleft = P1^6; //左边循迹,亮灯返回值为1 sbit outright = P1^7; //右边循迹,检测到黑线灭灯,返回0 unsigned char PWM; //PWM波 unsigned char date;//输入缓冲区 static unsigned char speed = 100; //设置速度初始值 void stop() // 停 { IN1=0; IN2=0; IN3=0; IN4=0; } void forward() // 向前 { IN1=1; IN2=0; IN3=1; IN4=0; } void back() // 向后 { IN1=0; IN2=1; IN3=0; IN4=1; } void left() // 向左,只有左轮动 { IN1=1; IN2=0; IN3=1; IN4=1; } void avoid_left()//向左,左右伦同时转动 { IN1=1; IN2=0; IN3=0; IN4=1; } void right() // 向右,只有右轮动 { IN1=1; IN2=1; IN3=1; IN4=0; } void avoid_right()//向左,左右伦同时转动 { IN1=0; IN2=1; IN3=1; IN4=0; } void increase(void)//加速 { speed += 5; // 每次增加5 if(speed >= 100) // 上限是100 { speed = 100; } } void reduce(void)//减速 { speed -= 5; // 每次减少5 if(speed <= 0) // 下限是0 { speed = 0; } } void avoid(void)//避障模式 { if(out0 == 0) // 右边有障碍物,左转 { avoid_left(); } if(out1 == 0) // 左边有障碍物,右转 { avoid_right(); } if(out0 == 1 && out1 == 1) // 没有障碍物,前进 { forward(); } if(out0 == 0 && out1 == 0) // 有障碍物,停止 { stop(); } } void Follow_the_trail (void) { if(outleft == 0 && outright == 0)//悬空,停止移动 { stop(); } if(outleft == 1 && outright == 1) //在赛道上,直线行驶 { forward(); } if(outleft == 1 && outright == 0) //偏离赛道向右,因向左行驶 { left(); } if(outleft == 0 && outright == 1) //偏离赛道向左,因向右行驶 { right(); } } //串口中断 void Time_Int () interrupt 4 { if(RI == 1) // RI为1时软件置0 { RI = 0; // 清除接受标志 date = SBUF; // 接收数据缓存在date中 switch (date) { case ('1'): { forward(); break; } case ('2'): { back(); break; } case ('3'): { left(); break; } case ('4'): { right(); break; } case ('0'): { stop(); break; } case ('5'): { increase(); break; } case ('6'): { reduce(); break; } } } } //定时器0 void time_control() interrupt 1 { TL0 = 0x66; //设置定时初值 TH0 = 0xFC; //设置定时初值 PWM++; if (PWM == 100) { PWM = 0; } if(PWM <= speed)//大于PWM波则打开使能 { ENA = 1; ENB = 1; } if(PWM > speed)//小于PWM波则关闭使能 { ENA = 0; ENB = 0; } } void main () { UsartConfiguration(); // 串口初始化 Timer0Init();//定时器0初始化 while(1) { //在数码管可以看到当前的速度是多少 Nixie(1, speed/100); Delay(5); Nixie(2, (speed/10)%10); Delay(5); Nixie(3, speed%10); Delay(5); //启动避障模式,将此模式存放在主函数当中 if(date == '7') { avoid(); } //启动循迹模式,将此模式存放在主函数当中 if(date == '8') { Follow_the_trail(); } } } UART.
哈喽啊,好久不见朋友们,昨天蓝桥杯刚过去,趁着我题目还记着,来给你们讲一下
还是那句话,点赞关注加复制代码 \doge.
题目描述我只讲个大概!!!
第一题 题目 给你两个数a,b要求输出两数中较大的一个
解析 没错这是一道非常弱智的题目,我当时看到的时候给我震惊住了(第一次参加真没想到原来真的那么简单),这里给大家用多种方法解答
方法一 库中自带函数版
#include <iostream> #include <cmath> using namespace std; int main(){ int a,b; cin >> a >> b; cout << max(a, b); return 0; } 方法二 自己写函数版
#include <iostream> using namespace std; int ma(int a, int b){ if(a > b){ return a; } return b; } int main(){ int a,b; cin >> a >> b; cout << ma(a, b); return 0; } 方法三 if判断版
一、使用jdbc连接
使用jdbc连接没有大变化,使用的时候和mysql过程比较类似,除了Cypher
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; public class JDBCConnection { public static void jdbcNeo4j() throws ClassNotFoundException, SQLException{ Class.forName("org.neo4j.jdbc.Driver"); String url ="jdbc:neo4j:http://localhost:7474"; Connection conn = DriverManager.getConnection(url, "neo4j_user", "neo4j_passwd"); Statement stmt = conn.createStatement(); /*ResultSet rs = stmt.executeQuery("match (n) return n.age,n.name,n"); while(rs.next()) { System.out.println(rs.getString("n.name")+"\t"+rs.getString("n.age")); System.out.println("rs.getString(\"n\")\t"+rs.getString("n")); System.out.println("rs.getString(2)\t"+rs.getString(2)); System.out.println("rs.getString(3)\t"+rs.getString(3)); }*/ ResultSet rs = stmt.executeQuery("match (n) return n limit 10"); while(rs.next()) { System.out.println(rs.getRow()); System.out.println(rs.getMetaData().getColumnName(0)); } } public static void main(String[] args) throws ClassNotFoundException, SQLException { jdbcNeo4j(); } } 二、使用GraphDatabase连接
一、Java对象头 由于Java面向对象的思想,在JVM中需要大量存储对象,存储时为了实现一些额外的功能,需要在对象中添加一些标记字段用于增强对象功能,这些标记字段组成了对象头。
对象头包含两部分:运行时元数据(Mark Word)和类型指针(Klass Word)
以32位虚拟机为例:
普通对象:
数组对象:数组对象还需要记录数组长度
其中,运行时元数据Mark Word结构为:
哈希值(HashCode),可以看作是堆中对象的地址GC分代年龄(年龄计数器) (用于新生代from/to区晋升老年代的标准, 阈值为15)锁状态标志 (用于JDK1.6对synchronized的优化 -> 轻量级锁)线程持有的锁偏向线程ID (用于JDK1.6对synchronized的优化 -> 偏向锁)偏向时间戳 类型指针: 指向类元数据InstanceKlass,确定该对象所属的类型。指向的其实是方法区中存放的类元信息
二、Monitor(锁) Monitor被翻译为监视器或管程;
每个 Java 对象都可以关联一个 Monitor 对象,如果使用 synchronized 给对象上锁(重量级)之后,该对象头的Mark Word 中就被设置指向 Monitor 对象的指针(将对象与Monitor对象关联)。
图解: 如下图所示,我们有一个临界区代码,当Thread2执行到synchronized(obj),访问共享资源的时候:
首先会将synchronized中的锁对象中对象头的MarkWord去尝试指向操作系统提供的Monitor对象,让锁对象中的MarkWord和Monitor对象相关联. 如果关联成功, 将obj对象头中的MarkWord的对象状态从01改为10。因为该Monitor没有和其他的obj的MarkWord相关联,所以Thread2就成为了该Monitor的Owner(所有者)。然后,又来了一个Thread1执行synchronized(obj)代码,它首先会检查是否能执行临界区代码,即检查obj是否关联了Montior,此时已经有关联了, 它就会去看看该Montior有没有所有者(Owner), 发现有所有者了(Thread2);Thread1也会和该Monitor关联, 该线程就会进入到它的EntryList(阻塞队列),EntryList是一个列表,若此时Thread3也执行到synchronized(obj)代码,也会进入阻塞队列。当Thread2执行完临界区代码后, Monitor的Owner(所有者)就空出来了. 此时就会通知Monitor中的EntryList阻塞队列中的线程, 这些线程通过竞争, 成为新的所有者。 刚开始 Monitor 中 Owner 为 null当 Thread-2 执行 synchronized(obj) 就会将 Monitor 的所有者 Owner 置为 Thread-2,Monitor中只能有一个 Owner在 Thread-2 上锁的过程中,如果 Thread-3,Thread-4,Thread-5 也来执行 synchronized(obj),就会进入 EntryList BLOCKEDThread-2 执行完同步代码块的内容,然后唤醒 EntryList 中等待的线程来竞争锁,竞争时是非公平的图中 WaitSet 中的 Thread-0,Thread-1 是之前获得过锁,但条件不满足进入 WAITING 状态的线程 注意:
一些必须要知道的事:
这个镜像的主要目的是为了将服务器或者群晖等linux场景中的资料备份到百度网盘中容器的基础镜像为ubuntu镜像。容器的备份周期为每天的凌晨两点。 具体步骤如下:
下载镜像。
docker pull hanhongyong/baidu_backup:latest 生成容器。
docker run -it -d --name=baidu -v /root/Docker_Microsoft365_E5_Renew_X/:/baidupy hanhongyong/baidu_backup:latest 其中,/root/Docker_Microsoft365_E5_Renew_X/为你的服务器上要备份的文件的路径,/baidupy为在百度网盘上生成的路径,为了系统的稳定性,建议你依旧采取这个路径,如果为了区别在不同服务器上的文件,可以采用子文件夹的形式。如下:
docker run -it -d --name=baidu -v /root/Docker_Microsoft365_E5_Renew_X/:/baidupy/Docker_Microsoft365_E5_Renew_X hanhongyong/baidu_backup:latest 进入容器,进行百度网盘的授权。
进入容器:
docker exec -it baidu /bin/bash 进行百度授权,输入命令bypy info。然后复制上面的链接到浏览器,复制授权码到命令行,回车。
4. 以上便完成了部署。但是为了确定可以上传。可以查看一下命令是否正常开启。
输入crontab -l,查看是否相同。
输入service cron status,查看是否为正常运行。
高级版:
脚本中的start_backup.sh为备份的文件夹,可以根据需要修改。
文件中的start.sh为开启crontab的命令,如果上面显示cron is not running的话,可以运行这个脚本进行启动。
如果需要更改备份时间的次数,可以更改/etc/cron.d的backup-cron文件进行修改。
一些开发相关命令(与部署无关,不必理会!)
#构建镜像 docker build -t hanhongyong/baidu_backup:latest . docker tag hanhongyong/baidu_backup:latest hanhongyong/baidu_backup:latest #上传镜像 docker push hanhongyong/baidu_backup:latest 制作不易,欢迎Star!!!
Github:https://github.com/hongyonghan/Docker_Baidu_Backup
CSDN:https://blog.csdn.net/qq_40605167/article/details/123282892
DockerHub:https://hub.docker.com/repository/docker/hanhongyong/baidu_backup
1 矩阵的值域(定义)
设, , 以 , 表示A的第i个列向量,称子空间为矩阵的值域,记为
值域有如下结论
(1)
(2)(矩阵的秩数) (线性空间V中线性无关向量组所含向量最大个数称为维数)
(3) 证明
2 零度 (定义)
设 称集合为A的核空间(零空间),记为, 它是齐次线性方程组的解空间,它是的一个子空间
A 的核空间的维数称为A的零度,记为.
即: 通过上述例子,得出结论:的列数 (1)
又因为 的行数 (2)
通过(1) - (2) 可得: A的列数 - A的行数
3 子空间的交与和(定义)
设是线性空间V的两个子空间,则:
分别称为两个子空间的交与和。
4 若是线性空间V的两个子空间则 均为V的子空间 。 (定理)
证明:
5 是包含在中的最大子空间;
是包含在的最小子空间。
5 若是线性空间V的子空间,则有
定理
6 直和(定义) 设是线性空间V 的子空间,若其空间中任一元素只能唯一表示为的一个元素与的一个元素之和,即, 存在唯一的,使得 ,则称
为的直和,记为.
7 为直和的充要条件是 推论
推论1 设是线性空间V 的子空间,令,则 的充要条件为
推论2 如果 为 的基, 为的基,且为直和,则为为直和的基。
新学期第一天开始写的这篇文章,看看我啥时候能把他发出去。假期当然是啥也没干了,之前还信誓旦旦说回家一定能学习,学个毛线。开始学习啦,去年年末把环境配置好了之后,实验发现他不准,用的D435i摄像头是红外的,在水里误差太大,所以最终目地的话就是要给他整准,这脑子一天天啥也不记得,真想去测一个记忆力,看看是不是有问题...首先的话学习一下基础的摄像头的成像原理~
双目立体视觉深度相机的深度测量过程,如下:
1、标定:首先需要对双目相机进行标定,得到两个相机的内外参数、单应矩阵。
2)校正:根据标定结果对原始图像校正,校正后的两张图像位于同一平面且互相平行。
3)找像素点:对校正后的两张图像进行像素点匹配。
4)深度:根据匹配结果计算每个像素的深度,从而获得深度图。
目录
一、理想双目相机成像模型
二、相机成像原理
2.1世界坐标系和相机坐标系之间的转换(刚体变换:物体不会发生形变,只需要进行旋转和平移)
2.2相机坐标系(Oc)与图像坐标系(Ox-y)之间的转换(透视投影:从3D转换到2D)
2.3图像坐标系(Ox-y)与像素坐标系(Ou-v)(仿射变换)
三、总结一下下
一、理想双目相机成像模型 c1、c2是左右两个双目相机(位置对齐)。相机焦距f,相机之间距离为b,右上角为目标位置P(x,y),目标的水平坐标为x,相机离目标垂直距离(所求目标距离相机的深度)为z。
如果要计算深度z,必须要知道:
(1)相机焦距f,左右相机之间距离b。这些参数可以通过先验信息或者相机标定得到。
(2)视差d。需要知道左相机的每个像素点(xl, yl)和右相机中对应点(xr, yr)的对应关系。这是双目视觉的核心问题。
二、相机成像原理 想标定得先成像,所以先来搞清楚相机是如何成像滴
相机成像系统中,共包含四个坐标系:世界坐标系、相机坐标系、图像坐标系、像素坐标系。
世界坐标系:描述目标物体在真实世界的位置而引入的三维世界坐标系。
相机坐标系:以相机为中心,从相机角度描述物体位置,作为像素坐标系—世界坐标系的桥梁。
图像坐标系:描述真实物体在相机焦距处成像的坐标系,用来连接相机坐标系与像素坐标系。
像素坐标系:描述物体在照片上数字图像的位置而引入的一种数字坐标系。
从一个坐标系到另一个坐标系,物体之间的坐标系变换都可以表示坐标系的旋转变换加上平移变换。
为啥向上面那样写呢:以绕Z轴旋转为例
如下图,绕Z转,Z不变,我们把三维转为二维,根据几何关系就可以得到,其他两个也一样。
原理知道了以后,我们看这四个坐标系如何变换,由现实中的物体最后在图像中成像
世界坐标系相机坐标系图像坐标系像素坐标系
2.1世界坐标系和相机坐标系之间的转换(刚体变换:物体不会发生形变,只需要进行旋转和平移) 如下图,R表示旋转矩阵,T表示偏移变量
2.2相机坐标系(Oc)与图像坐标系(Ox-y)之间的转换(透视投影:从3D转换到2D) 说白了就是用,,来表示x,y,下图为理想的图像坐标系,实际会产生畸变,需要矫正。
2.3图像坐标系(Ox-y)与像素坐标系(Ou-v)(仿射变换) 像素坐标系和图像坐标系都在成像平面上,但是原点所在位置不同,单位不同。图像坐标系的原点为相机光轴与成像平面的交点(上图点o),通常情况下是成像平面的中点,图像坐标系的单位是mm,而像素坐标系的原点在图像左上角(本文第三张图上有画),单位是pixel。
2.3.1两坐标轴都为直角坐标系(uv垂直)
图像上的每点坐标 (u,v) 分别表示每一帧采集的图像在系统中的存储的数组的列数与行数,坐标 (u,v) 所对应的值就是该点的灰度信息。设点o在图像像素坐标系中记为 (u0,v0) ,每个像素沿 x 轴的实际物理尺寸大小是 dx,沿 y 轴的实际物理尺寸大小是dy ,单位值mm,即1pixel=dx mm。则能得到两个坐标系间的关系式 。
2.3.2两坐标轴有一个轴平行,一个轴不平行
三、总结一下下 三个穿起来就变成了:
其中,Xw,Yw,Zw为在世界坐标系下一点的物理坐标,u,v为该点对应的在像素坐标系下的像素坐标,Zc为尺度因子。最右边等式的第一个是相机的内参,内参矩阵取决于相机的内部参数。其中, f为像距,dx,dy分别表示X,Y方向上的一个像素在相机感光板上的物理长度(即一个像素在感光板上是多少毫米),u0,v0分别表示相机感光板中心在像素坐标系下的坐标,表示感光板的横边和纵边之间的角度(90度表示无误差)。第二是相机的外参,外参矩阵取决于相机坐标系和世界坐标系的相对位置,R表示旋转矩阵,T表示平移矢量。
下一篇我们就看一下啥叫标定。
一、模式原理分析 在上一讲中,我们介绍了工厂模式中的抽象工厂模式,为便于你更好地理解,我们还通过家具厂的实例讲解了抽象工厂的使用步骤,并结合 Spring Framework 框架中的 BeanFactory 说明了寻找正确抽象的重要性。
今天我们接着来讲解另外一个工厂模式:工厂方法模式(Factory Method Pattern)。
工厂方法模式就是我们俗称的工厂模式,和抽象工厂模式很类似,但工厂方法模式因为只围绕着一类接口来进行对象的创建与使用,使用场景更简单和单一,在实际的项目中使用频率反而比抽象工厂模式更高。
工厂方法模式的原始定义是:定义一个创建对象的接口,但让实现这个接口的类来决定实例化哪个类。
工厂方法模式的目的很简单,就是封装对象创建的过程,提升创建对象方法的可复用性。
我们直接来看看工厂方法模式的 UML 图:
从图中可以看出,工厂方法模式包含三个关键角色:
抽象接口(也叫抽象产品);
核心工厂;
具体产品(也可以是具体工厂)。
其中,核心工厂通常作为父类负责定义创建对象的抽象接口以及使用哪些具体产品,具体产品可以是一个具体的类,也可以是一个具体工厂类,负责生成具体的对象实例。于是,工厂方法模式便将对象的实例化操作延迟到了具体产品子类中去完成。
不同于抽象工厂模式,工厂方法模式侧重于直接对具体产品的实现进行封装和调用,通过统一的接口定义来约束程序的对外行为。换句话说,用户通过使用核心工厂来获得具体实例对象,再通过对象的统一接口来使用对象功能。
工厂方法模式对应 UML 图的代码实现如下:
//抽象产品 public interface IProduct { void apply(); } //核心工厂类 public class ProductFactory { public static IProduct getProduct(String name){ if ("a".equals(name)) { return new Product_A_Impl(); } return new Product_B_Impl(); } } //具体产品实现A public class Product_A_Impl implements IProduct{ @Override public void apply() { System.out.println("use A product now"
dataloader datasetSamplercollate_fn 数据增强torchvision和albumentations基本操作torchvision和albumentations实现自己的数据增强 整个pytorch数据读取顺序是Dataset、sampler产生indices、collate_fn根据indices对数据进行合并处理 class DataLoader(object): ... def __next__(self): if self.num_workers == 0: indices = next(self.sample_iter) # Sampler batch = self.collate_fn([self.dataset[i] for i in indices]) # Dataset if self.pin_memory: batch = _utils.pin_memory.pin_memory_batch(batch) return batch 从上边的代码快可以看到self.sample_iter提供图片列表的index,collate_fn是对图片和label进行合并操作。
dataset class custom_dset(Dataset): def __init__(self, img_path, txt_path, img_transform=None, loader=default_loader): with open(txt_path, 'r') as f: lines = f.readlines() self.img_list = [ os.path.join(img_path, i.split()[0]) for i in lines ] self.label_list = [i.split()[1] for i in lines] self.
A. 合数个数(5 分)
答案:1713
试题 A: 合数个数(5 分)
【问题描述】
一个数如果除了 1 和自己还有其他约数,则称为一个合数。例如:1, 2, 3不是合数,4, 6 是合数。
请问从 1 到 2020 一共有多少个合数。
【答案提交】
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
思路:
1~2020共有2020个数,因此我们只要求出素数的个数,结果便是2020-素数个数。
#include<bits/stdc++.h> using namespace std; #define INF 1e18 typedef long long LL; const int maxn=1e4+10; const int mod=998244353; int ans=2020; bool is_prime(int x){ for(int i=2;i*i<=x;i++){ if(x%i==0) return false; } return true; } int main(){ iostream::sync_with_stdio(false); int n=2020; for(int i=1;i<=n;i++){ if(is_prime(i)) ans--; } cout<<ans<<endl; return 0; } B.
前言 在学习帧同步框架源码之前,先过一遍基础知识:Unity基础学习六,网络同步_u013617851的博客-CSDN博客
视频地址:帧同步教程【合集】_哔哩哔哩_bilibili
github地址:GitHub - JiepengTan/Lockstep-Tutorial: 帧同步 教程
1.ServeraLifeCircle服务端 服务端ServerLauncher.Main() 启动入口:
服务端Server收到协议,进入Dispatch()分发函数:
2. new ClientLifeCycle 客户端 启动和初始化Awake:
启动和初始化Start:
收到网络协议: Unity脚本Update()函数,以及帧同步真的_Update()帧的更新: 3.启动服务端的方法 3.1 代码目录新建一个dll项目 3.2 添加LockstepEngine和SimpleServer的解决方案 3.3 给SimpleServer加上引用 3.4 修复 AssemblyInfo.cs 特性重复报错 顺便在配置文件SimpleServer.csproj中
</PropertyGroup>中
加入一行<GenerateAssemblyInfo>false</GenerateAssemblyInfo>
然后把报错点开的那个XXXXXXXXXXXX.AssemblyInfo.cs文件,用资源管理器打开,删除掉。
重新对SimpleServer右键清理,右键编译。
3.4 安装服务器启动的.Net环境 Download .NET Core 2.2 SDK (v2.2.207) - Windows x64 Installer
3.5 启动SimpleServer 和 游戏客户端 桌面的XXXX.exe和Unity编辑器同时启动,然后游戏就会开始:(只启动一个,会进入等待)
4. new Replay ClientMode and Debug (回放功能,客户端模式,Debug) 4.1 回放功能初始化 4.2 回放功能的Update更新 4.3 客户端模式初始化 4.4 客户端模式更新和输入 4.5 Debug 5.
解决方案步骤:
打开vscode编辑器,本文演示的vscode是英文版
点击左下角齿轮状的图标
在弹出的菜单中选择【Settings】
Settings点击后,会出现一个设置窗口
在Settings窗口中点击左侧的【Text Editor】菜单
在右侧出现的设置界面中下滑,找到并点击【Edit in settings.json】即可打开settings.json
思想:使用哈希函数将键映射到存储桶。
想要插入一个新的键,哈希函数将决定该键该分配到哪个桶中,并将该键存储在相应的桶中。
想要搜索一个键的时候,哈希表使用哈希函数来查找相应的桶,并在特定的桶中进行搜索。
设计哈希函数:取决于键值的范围和桶的数量。完美的哈希函数可以使键和桶之间的一对一映射。在大多数情况下,哈希函数并不完美,会产生哈希冲突。
冲突解决:在同一个桶中存在了多个键。
如何解决冲突?
链表:将相同的哈希值的元素都放入这一链表当中。
开放地址:在h处产生冲突,则要从h出发找到下一个不冲突的位置。不断地检测h+1、h+2、h+3...
再哈希:再使用另外一个哈希函数产生一个新的地址。
什么地方适用哈希表?
二分法;快速删除、添加、查找....
一、链地址法
设计哈希表的大小为base。开辟一个大小为base的数组,数组的每一个位置是一个链表。
为了尽可能避免冲突,应该将base取为一个质数。
在这里取base为769。
先声明一个链表:
struct List{ int val; //保存键值使用 struct List *next; //指向下一个 }; 声明一个哈希函数,作用是求得余数后将其放入对应的数组中:
const int base = 769; int hash(int key) { return key%base; } 写出一些方便调用的子函数:
添加值到数组元素的函数:
//@explain: struct传进来前面定义的结构体,x为要添加的变量 void listPush(struct List *head,int x) { //分配空间 struct List* tmp = malloc(sizeof(struct List)); //将读取进来的值,存放在这个结构体的变量中 tmp -> val = x; //指向下一个值 tmp -> next = head -> next; //保存头指针使用 head -> next = tmp; } 删除链表中的值函数:
该报警一般是因为加入了第三方的插件程序造成的。解决办法如下操作所示:
光标选中项目名称,单击鼠标右键选择【在文件资源管理器中打开文件夹】
找到Properties文件夹licenses.licx文件,然后右键选择删除。
在Properties文件夹下新建一个空的txt文档并重新命名为为licenses.licx,单击右键,将“licenses.licx.txt”中的“.txt”删除,并点击【确定】。
licenses.licx的文件类型变为licx,再次运行程序报警解除。
一般来说,理解 HTTP 构建的网络应用,只要关注客户端(clinet)和服务端(server),两个端的交互来自客户端的 request,以及服务端的response。所谓的http服务器,主要在于如何接受客户端的 request,并向服务端返回response。
Http接收和响应来自客户端的HTTP请求,需要用到golang自带的net.http包,实现动态请求处理。Go语言内置的net/http包提供了HTTP客户端和服务端的实现。
在接受的过程中路由(router)十分重要,路由url到函数的映射,而这里的路由目的就是为了找到处理器函数(handler),函数将对来自客户端request进行处理,同时构建response返回至服务器。
一、路由 路由就是url到函数的映射
route就是你访问一个页面的地址。router就是由一群地址组成的东西。
当访问/healthz路径时,会执行healthz函数
服务器端
简单来说,对于服务器,当接收到客户端发来的HTTP请求,会根据请求的URL,来找到相应的映射函数,然后执行该函数,并将函数的返回值发送给客户端。
静态资源服务器:url映射函数可以理解为一个文件读取操作
动态资源服务器:url映射可以理解为从数据库读取操作,或是数据处理
客户端 路由的映射函数通常是进行一些DOM的显示和隐藏操作。
二、HTTP请求的接收与处理流程 1、客户端将请求发送到服务器(指定URL)。
2、服务器将请求指向到正确的处理器,然后由该处理器对请求进行处理。
3、处理器处理请求,执行必要的动作。
4、处理器将结果返回给客户端。
三、开始创建http server 在理解以上概念后,就要进入http server的创建了。创建httpserver有两个步骤,首先是注册路由,接下来就是其次就是实例化一个server对象,开始监听来自客户端request。
注册路由 通过这个包的http.HandleFunc函数,我们可一个注册一个请求处理器,该函数的第一个参数是请求路径的字符串,第二个参数即为处理请求的函数主体func(ResponseWriter, * Request) 类型的函数。
http.HandleFunc("/", httpAccessFunc) http.Handle和http.HandleFunc区分 Go 网络编程:使用 Handler 和 HandlerFunc - 简书
简单的httpserver package main import ( "io" "log" "net/http" ) func main() { http.HandleFunc("/healthz", healthz) //handle定义请求访问该服务器里的/healthz路径,就有下面healthz去处理,healthz一般为健康检查 err := http.ListenAndServe(":80", nil) if err != nil { log.Fatal(err) } } //定义handle处理函数,只要该healthz被调用,就会写入ok func healthz(w http.
垃圾回收器CMS与G1的区别 1. CMS1.0 概念1. 1 步骤如下:1.2 CMS的优点:1.3 CMS的缺点:1.4 使用场景 2. G12.0 概念2.1 步骤如下:2.2 G1的特点2.3 使用场景 1. CMS 1.0 概念 CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,基于并发“标记清理”实现,在标记清理过程中不会导致用户线程无法定位引用对象。仅作用于老年代收集。
1. 1 步骤如下: 初始标记(CMS initial mark):独占CPU,stop-the-world,(为了保证引用更新的正确性,Java将暂停所有其他的线程,这种情况被称为“Stop-The-World”,导致系统全局停顿) 仅标记GCroots能直接关联的对象,速度比较快;并发标记(CMS concurrent mark):可以和用户线程并发执行,通过GCRoots Tracing 标记所有可达对象;重新标记(CMS remark):独占CPU,stop-the-world, 对并发标记阶段用户线程运行产生的垃圾对象进行标记修正,以及更新逃逸对象;并发清理(CMS concurrent sweep):可以和用户线程并发执行,清理在重复标记中被标记为可回收的对象。 1.2 CMS的优点: 支持并发收集.
低停顿,因为CMS可以控制将耗时的两个stop-the-world操作保持与用户线程恰当的时机并发执行,并且能保证在短时间执行完成,这样就达到了近似并发的目的.
1.3 CMS的缺点: CMS收集器对CPU资源非常敏感,在并发阶段虽然不会导致用户线程停顿,但是会因为占用了一部分CPU资源,如果在CPU资源不足的情况下应用会有明显的卡顿。
无法处理浮动垃圾:在执行‘并发清理’步骤时,用户线程也会同时产生一部分可回收对象,但是这部分可回收对象只能在下次执行清理是才会被回收。如果在清理过程中预留给用户线程的内存不足就会出现‘Concurrent Mode Failure’,一旦出现此错误时便会切换到SerialOld收集方式。
CMS清理后会产生大量的内存碎片,当有不足以提供整块连续的空间给新对象/晋升为老年代对象时又会触发FullGC。且在1.9后将其废除。
1.4 使用场景 它关注的是垃圾回收最短的停顿时间(低停顿),在老年代并不频繁GC的场景下,是比较适用的。
2. G1 2.0 概念 G1收集器的内存结构完全区别去CMS,弱化了CMS原有的分代模型(分代可以是不连续的空间),将堆内存划分成一个个Region(1MB~32MB, 默认2048个分区),这么做的目的是在进行收集时不必在全堆范围内进行。它主要特点在于达到可控的停顿时间,用户可以指定收集操作在多长时间内完成,即G1提供了接近实时的收集特性。
2.1 步骤如下: 初始标记(Initial Marking):标记一下GC Roots能直接关联到的对象,伴随着一次普通的Young GC发生,并修改NTAMS(Next Top at Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可用的Region中创建新对象,此阶段是stop-the-world操作。
根区间扫描,标记所有幸存者区间的对象引用,扫描 Survivor到老年代的引用,该阶段必须在下一次Young GC 发生前结束。并发标记(Concurrent Marking):是从GC Roots开始堆中对象进行可达性分析,找出存活的对象,这阶段耗时较长,但可与用户程序并发执行,该阶段可以被Young GC中断。最终标记(Final Marking):是为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程Remembered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set中,此阶段是stop-the-world操作,使用snapshot-at-the-beginning (SATB) 算法。筛选回收(Live Data Counting and Evacuation):首先对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划,回收没有存活对象的Region并加入可用Region队列。这个阶段也可以做到与用户程序一起并发执行,但是因为只回收一部分Region,时间是用户可控制的,而且停顿用户线程将大幅提高收集效率。 2.
自然常数 e 可以用级数 1+1/1!+1/2!+⋯+1/n!+⋯ 来近似计算。本题要求对给定的非负整数 n,求该级数的前 n+1 项和。
输入格式: 输入第一行中给出非负整数 n(≤1000)。
输出格式: 在一行中输出部分和的值,保留小数点后八位。
输入样例: 10 输出样例: 2.71828180 #include <stdio.h> double fact( int n ); int main(){ int n; double sum = 1.0; do{ scanf("%d", &n); }while( n<0 || n>1000 ); //保证n的范围 for( int i=1; i<=n; i++){ sum += 1.0 / fact(i); } printf("%.8lf", sum); return 0; } double fact( int n ){ if( n <= 1 ) return n; else return n * fact( n-1 ); }
display ip int brief 查看接口ip地址 display int brief 查看接口的简要信息 display this 查看当前配置过的命令 display current-configuration 显示当前配置文件 display saved-configuration 显示保存的配置文件 display this 查看当前模式下的配置 display current-configuration 关键词(查看关键词的配置) display mac-address 查看MAC表 display arp 查看ARP表 display ip routing-table 查看路由表 display ospf peer 查看ospf邻居关系 display ospf lsdb 查看链路关系数据库 display int Eth-Trunk 查看链路聚合状态 display clock 查看系统当前时间 eNSP命令大全
kali linux 自带有namp,无需下载安装,命令形式为namp +
点击可查看使用说明信息
扫描目标计算机,一般可以获取以下信息:
是否在线
所在网络的拓扑
开放的端口
所使用的操作系统
所运行的服务与版本
所存在的漏洞
常用命令穷举
经典单个主机IP/域名普通扫描:
nmap 目标IP 只检测是否联网:
nmap -sn 目标IP 多个不连续目标:
nmap [目标ip1 ip2 ip3......] 区域全目标:
nmap [IP地址范围] 目标全子网:
nmap [IP地址/掩码位数] 屏蔽ping协议:
nmap -PN [目标IP] 仅可ping协议:
nmap -sP [目标IP] 使用ARP协议:
nmap -PR [目标IP] 使用TCP协议:
1.半扫描,迅速且隐蔽
nmap -sS 目标IP 2.全扫描,完成3次握手
nmap -sT 目标IP 反向域名解析:
nmap -sL 目标IP 使用UDP协议:
nmap -sU [目标IP] 查看服务版本:
nmap -sV 详细服务信息:
nmap -sC 确定正在运行的机器:
nmap -P0 目标IP 发送一个设置了SYN标志位的空TCP报文,尝试建立连接:
个人废话… 我呢,基于诸多原因,中途不想读研考研,准备秋招去了。因为没什么经验,所以磕磕碰碰。秋招末尾拿到了满意的大厂offer😄,觉得有必要将几个月的秋招经验总结总结。面试前的各种知识点的准备是很重要的这篇文章并不是知识点的总结,而是知识点的准备思路😗。往期相关文章
校招面试个人经验——简历篇
校招面试个人经验——项目篇
校招面试个人经验——算法篇
校招面试个人经验——面试篇 什么是八股文? 八股文就是面试中常出现的问题,往往都是一些看起来高大上但是实际工作中没啥用的东西。它是各种面试知识点的统称,我想可能是因为它的乏味,所以叫八股文吧。 八股文含有哪些? 一般计算机应届生需要复习到以下内容
○ 数据结构
○ 算法
○ 设计模式
○ 计算机网络
○ 操作系统
○ 数据库
○ 其它
此外视岗位不同,还需要额外复习其它知识,比如我面Android开发,则为
○ Java
○ Java JVM
○ Android
○ 其它
怎么找八股文? 八股文的话,能通过以下途径寻找
○ 找八股文大杂烩网站
○ 找知识点汇总文档
○ 查看面经的知识点
○ 自行百度查知识点后面我会列出我在准备过程中遇到的一些觉得有用的网站 八股文大杂烩网站 汇总的网站,比如个人网页、Github、Gitee、博客、知乎等等
我觉得有用的几个网站如下:
○ Android校招面试指南(相对全面和详细)
○ 计算机基础面试问题全面总结(经典问题问的概率大)
○ CS-Notes
○ 【面试题】技术面试题汇总
○ Java-Interview
○ JCSprout
除了我列的这些外,大家可以去牛客、知乎上面逛逛,上面总会有人推荐一些好用的汇总网站。或者去百度百度,也是容易找到的。
找知识点汇总文档 大都来自那些网课群里的免费资源(有点像你关注我网课,我就给你资料😂)👉点这里👈这些文档里面的内容太多太杂了,大家挑选需要的内容看看就行(我没看多少😂) 查看面经的知识点 论面试经验,当然是牛客面经啦,能分很多类,比如岗位、公司、应聘类型有些人会把自己的面试经历记录到牛客上,从中能看到有哪些知识点被问到了,是查漏补缺的好方法(记得我当时少说也看了上百篇面经了😢)不能盲目看面经 😮,我觉得看面经得晚点看,当八股文看得差不多时,再去看面经,当成考试习题那样子,看看自己几斤几两。要注意是实习面经还是校招面经(难度不同)。此外,选择那些要面试的公司的面经,毕竟每个公司问的东西多少会有些偏差,难易程度也不同,这样能避免不必要的精力。 自行百度查知识点 懂得都懂,找度娘😏一般就是看到面经上不会的知识点,就去百度查要注意当查出个所以然时,最好把网址分类收藏了,既过段时间不会忘记,又方便面试前再次复习扫一眼 😗。我当时收藏了些有关问题的网址,可能对你们有帮助👉书签👈 八股文怎么复习? 复习除了背背背,还要伴随着以下思考,能更好的发现哪些知识还未掌握。常见知识点的内部原理及构造,比如:HashMap的基本原理。需要知道这个东西由什么组成,一些内部方法是怎么实现的,甚至还需要稍微看看源代码。知识点之间的比较,比如:TCP和UDP的区别、堆和栈的区别(从数据结构和操作系统两个维度出发)。当复习到某个知识点时,需要想下是否有同类能去比较的知识点。常见知识点的再次涉广,比如:http和TCP哪个更快(初次看会以为面试官问的是煞笔问题,http不是含有tcp吗?但其实考究的是看你知不知道http3.
目录
1.前言:
2.背景介绍:
3.Dubbo:
4.动态数据源:
5.分布式事务:
6.运行及结果:
1.前言: 本文code的github地址:GitHub - wdquan1985/dubbo-dynamicDatasource-jtaAtomikos
分布式现在已经是web开发必须掌握的知识,虽然其有一定的难度,必须掌握的知识点包括以下两部分:
(1).分布式架构RPC框架:例如Duboo,spring cloud等。本文中使用Dubbo
(2).分布式事务:遇到分布式系统,就几乎不可避免的遇到分布式事务的问题,分布式事务包括四种模式 -- XA、TCC、AT、Saga。2PC/3PC协议是指两阶段提交和三阶段提交,四种分布式事务模式的实现,基本上都使用了2PC协议,因为3PC太难实现。可以参考这篇文章: 分布式事务的4种模式 - 知乎, 去了解分布式事务的全貌。
下面两种情况下,需要分布式事务:
数据库的水平拆分:单业务系统架构
业务数据库起初是单库单表,但随着业务数据规模的快速发展,数据量越来越大,对数据库表的增删改查将会越来越慢。单库单表逐渐成为瓶颈。所以我们对数据库进行了水平拆分,将原单库单表拆分成数据库分片。如下图所示,分库分表之后,原来在一个数据库上就能完成的写操作,可能就会跨多个数据库,这就产生了跨数据库事务问题。访问不同的数据库,要开启不同的事务
业务服务化拆分:多个应用服务
在业务发展初期,“一块大饼”的单业务系统架构,能满足基本的业务需求。但是随着业务的快速发展,系统的访问量和业务复杂程度都在快速增长,单系统架构逐渐成为业务发展瓶颈,代码可维护性差,容错率低,测试难度大,敏捷交付能力差等诸多问题,微服务应运而生。
如下图所示,按照面向服务架构(SOA)的设计原则,将单业务系统拆分成多个业务系统,降低了各系统之间的耦合度,使不同的业务系统专注于自身业务,更有利于业务的发展和系统容量的伸缩。
微服务的诞生一方面解决了上述问题,但是另一方面却引入新的问题,业务系统按照服务拆分之后,一个完整的业务往往需要调用多个服务,所以其中主要问题之一就是如何保证微服务间的业务数据一致性,这成为了一个难题,每个服务访问数据库(即使是相同的数据库)都要开启一个新的事务
(3).分布式事务的实现:
符合XA 模式的由TM, RM控制的两阶段提交,RM由关系型数据库厂商提供实现(例如mysql,oracle数据库,本身支持分布式事务),java对XA规范的实现叫做JTA,JTA中TM具体实现包括Atomikos,Narayana,JOTM,BTM等。但是这种XA模式是有局限性的,只能够解决单个应用(单业务系统架构)中跨越多个数据源时(分布式数据库,数据库的水平拆分)数据操作的事务一致性问题,但是遇到分布式系统(例如Dubbo)中多个应用服务之间( 分布式服务,业务服务化拆分)数据操作的事务一致性问题时,它就不起作用了,也就是说只适用于单业务系统架构,当然了,在分布式系统中,如果没有遇到跨微服务访问数据库的事务问题时,跟这个其实也是类似的。还有其它局限性,例如必须要拿到所有数据源,而且数据源还要支持XA协议;性能比较差,要把所有涉及到的数据都锁定,是强一致性的,会产生长事务。本文是初探分布式事务,所以选择使用Atomikos, 这对分布式事务有一个初步的了解很有帮助。会在以后的文章中选择其它的分布式事务实现,例如TCC的seata。总结:XA模式是分布式强一致性的解决方案,但性能低而使用较少,CAP理论中,很多互联网应用都是选择满足AP的。如何解决 JTA/XA 的局限性呢?阿里的Seata 分别实现了 AT、TCC、SAGA 和 XA (XA尚未实现,请等待)事务模式,为用户打造一站式的分布式解决方案。以后会写文章研究阿里seata的使用。可以学习Seata入门理论介绍文章:分布式事务 Seata 及其三种模式详解Seata官网地址:Seata 2.背景介绍: 我们为什么要使用Dubbo?
随着Internet的发展,web应用的规模不断扩大,最终,我们发现传统的架构(单片应用,垂直架构等)已经无法满足需求。分布式服务架构和流计算架构是必须的,并且迫切需要一个治理架构来确保架构的有序发展。
整体架构:
在流量非常低的情况下,只有一个应用,所有的功能被部署在一起(即一个server上,例如一个tomcat),这样可以减少部署节点,降低成本。此时,数据访问框架(ORM)是简化CRUD工作负载的关键。
垂直架构:
当流量较大时,增加单片应用程序的实例(简单的集群,例如用nginx做负载均衡)并不能很好的加速访问,提高效率的一种方法是将单片应用拆分为离散的应用,此时,用于加速前端页面开发的Web框架(MVC)是关键。
分布式服务架构:
当垂直应用程序越来越多时,应用程序之间的交互是不可避免的,一些核心业务被提取出来并作为独立的服务来服务,从而逐渐形成一个稳定的服务中心,这样前端应用程序就可以更好地响应不断变化的市场需求。 很快。 此时,用于业务重用和集成的分布式服务框架(RPC)是关键。
流计算架构:
当服务越来越多时,容量评估变得困难,而且小规模的服务也经常造成资源浪费。 为解决这些问题,应添加调度中心,以根据流量管理集群容量并提高集群利用率。 目前,用于提高机器利用率的资源调度和治理中心(SOA)是关键。
3.Dubbo: Dubbo官网:https://dubbo.apache.org/zh/
Dubbo架构:
指定节点角色:
Provider:提供者提供并且暴露远程服务Consumer:调用Provider提供的远程服务Registry:注册中心负责服务注册和发现Monitor:监控中心计算服务的调用次数和耗时Container:远程服务在容器中启动,容器管理服务的生命周期 代码:
代码分为三部分:
dubbo-example-common: 通用API(接口定义),以及数据库表对应的model。dubbo-example-consumer: 服务消费者,基于Springboot提供了Controller层,用户可以通过http请求访问。dubbo-example-provider: 服务提供者,基于Springboot集成了Atomikos + mybatis-plus + mysql, 对多数据源提供了分布式事务管理。 父pom.
一、前言 我们在日常开发中,避不开的就是参数校验,有人说前端不是会在表单中进行校验的吗?在后端中,我们可以直接不管前端怎么样判断过滤,我们后端都需要进行再次判断, 为了安全 。因为前端很容易拜托,当测试使用 PostMan 来测试,如果后端没有校验,不就乱了吗?肯定会有很多异常的。今天小编和大家一起学习一下JSR303专门用于参数校验的,算是一个工具吧!
二、JSR303简介 JSR-303 是 JAVA EE 6 中的一项子规范,叫做 Bean Validation,官方参考实现是Hibernate Validator。
Hibernate Validator 提供了 JSR 303 规范中所有内置 constraint 的实现,除此之外还有一些附加的 constraint。
Hibernate官网
官网介绍:
验证数据是一项常见任务,它发生在从表示层到持久层的所有应用程序层中。通常在每一层都实现相同的验证逻辑,这既耗时又容易出错。为了避免重复这些验证,开发人员经常将验证逻辑直接捆绑到域模型中,将域类与验证代码混在一起,而验证代码实际上是关于类本身的元数据。
Jakarta Bean Validation 2.0 - 为实体和方法验证定义了元数据模型和 API。默认元数据源是注释,能够通过使用 XML 覆盖和扩展元数据。API 不依赖于特定的应用程序层或编程模型。它特别不依赖于 Web 或持久层,并且可用于服务器端应用程序编程以及富客户端 Swing 应用程序开发人员。
三、导入依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-validation</artifactId> </dependency> 四、常用注解 约束注解名称约束注解说明@Null用于验证对象为null@NotNull用于对象不能为null,无法查检长度为0的字符串@NotBlank只用于String类型上,不能为null且trim()之后的size>0@NotEmpty用于集合类、String类不能为null,且size>0。但是带有空格的字符串校验不出来@Size用于对象(Array,Collection,Map,String)长度是否在给定的范围之内@Length用于String对象的大小必须在指定的范围内@Pattern用于String对象是否符合正则表达式的规则@Email用于String对象是否符合邮箱格式@Min用于Number和String对象是否大等于指定的值@Max用于Number和String对象是否小等于指定的值@AssertTrue用于Boolean对象是否为true@AssertFalse用于Boolean对象是否为false 所有的大家参考jar包
五、@Validated、@Valid区别 @Validated:
Spring提供的支持分组校验可以用在类型、方法和方法参数上。但是不能用在成员属性(字段)上由于无法加在成员属性(字段)上,所以无法单独完成级联校验,需要配合@Valid @Valid:
JDK提供的(标准JSR-303规范)不支持分组校验可以用在方法、构造函数、方法参数和成员属性(字段)上可以加在成员属性(字段)上,能够独自完成级联校验 总结: @Validated用到分组时使用,一个学校对象里还有很多个学生对象需要使用@Validated在Controller方法参数前加上,@Valid加在学校中的学生属性上,不加则无法对学生对象里的属性进行校验!
区别参考博客地址
例子:
@Data public class School{ @NotBlank private String id; private String name; @Valid // 需要加上,否则不会验证student类中的校验注解 @NotNull // 且需要触发该字段的验证才会进行嵌套验证。 private List<Student> list; } @Data public class Student { @NotBlank private String id; private String name; private int age; } @PostMapping("
1. 查看所有进程信息:
adb shell ps -A
则得到:
USER PID PPID VSZ RSS WCHAN ADDR S NAME root 1 0 12510356 5276 ep_poll 0 S init root 2 0 0 0 kthreadd 0 S [kthreadd] ... system 603 1 12539680 3468 ep_poll 0 S servicemanager ... system 1065 879 23323448 443428 ep_poll 0 S system_server .... 可以看出 :
PID 1065 对应的是 system_server进程
PID 603 对应的 servicemanager 进程 (用于Binder 通信)
2. 查看某个进程下的所有线程信息:
极其易懂法,只能查正在链接WiFi 1,按住快捷键Win+R,打开运行,输入control打开控制面板。
在控制面板中点击查看网络和internet,进入后点击:查看网络状态和任务。 打开后找到自己链接的无线,单击无线状态面板,然后点击无线属性。 打开后切换到安全选项卡。 在下边的显示字符前边打勾,就可以看到无线的密码了。 此法较为专业,但有时候不行
第一步:按下win+R调出运行窗口,开始输入'cmd'命令后回车打开命令提示符窗口。(记住要以管理员身份运行)
打开cmd
第二步:首先输入'netsh'命令回车,再次输入'wlan show profile'命令进行查看电脑连接过的wifi。
第三步:开始输入命令获取wifi密码:
wlan show profile hf(wifi名称) key=clear
此时你就可以在关键词后面看到wifi密码了。
最好使方法
笔记本已连接的密码忘记,想要找回密码,之前的win7电脑,可以勾选显示字符,就能查看到密码,但是电脑升级win10系统后,电脑密码就没法显示查看了。此时在网上发现一种方法,执行两条命令,在文件夹下生成一个wift配置文件,其中就能显示的看到我们所连接的wifi的密码。
打开cmd
命令1输入命令:netsh wlan show profiles
此命令作用,显示电脑曾经连接过的所有wifi名称,如图1.1
命令2输入命令:netsh wlan export profile name=TYFLH_2.4G folder=. key=clear
此命令作用,name=后面跟的是wifi名称,folder=后面跟的是生成文件目录名称 其中 .代表的是当前目录,即c:\Users\admin\
,在c:\Users\admin\目录下会生成一个WLAN-TYFLH_2.4G.xml文件,
如图2.1:
3.打开图2.1标红部分xml文件即可看到wifi密码。如图3.1
至此就可以知道之前忘记wifi的密码了。
命令3输入命令:
也可以通过命令:
netsh wlan show profiles 无线配置名称 key=clear
直接查看连接过的某个wifi 的密码 ,不用生成文件。
如下:
1.关于set
C++ STL 之所以得到广泛的赞誉,也被很多人使用,不只是提供了像vector, string, list等方便的容器,更重要的是STL封装了许多复杂的数据结构算法和大量常用数据结构操作。vector封装数组,list封装了链表,map和set封装了二叉树等,在封装这些数据结构的时候,STL按照程序员的使用习惯,以成员函数方式提供的常用操作,如:插入、排序、删除、查找等。让用户在STL使用过程中,并不会感到陌生。
关于set,必须说明的是set关联式容器。set作为一个容器也是用来存储同一数据类型的数据类型,并且能从一个数据集合中取出数据,在set中每个元素的值都唯一,而且系统能根据元素的值自动进行排序。应该注意的是set中数元素的值不能直接被改变。C++ STL中标准关联容器set, multiset, map, multimap内部采用的就是一种非常高效的平衡检索二叉树:红黑树,也成为RB树(Red-Black Tree)。RB树的统计性能要好于一般平衡二叉树,所以被STL选择作为了关联容器的内部结构。
关于set有下面几个问题:
(1)为何map和set的插入删除效率比用其他序列容器高?
大部分人说,很简单,因为对于关联容器来说,不需要做内存拷贝和内存移动。说对了,确实如此。set容器内所有元素都是以节点的方式来存储,其节点结构和链表差不多,指向父节点和子节点。结构图可能如下:
A
/ \
B C
/ \ / \
D E F G
因此插入的时候只需要稍做变换,把节点的指针指向新的节点就可以了。删除的时候类似,稍做变换后把指向删除节点的指针指向其他节点也OK了。这里的一切操作就是指针换来换去,和内存移动没有关系。
(2)为何每次insert之后,以前保存的iterator不会失效?
iterator这里就相当于指向节点的指针,内存没有变,指向内存的指针怎么会失效呢(当然被删除的那个元素本身已经失效了)。相对于vector来说,每一次删除和插入,指针都有可能失效,调用push_back在尾部插入也是如此。因为为了保证内部数据的连续存放,iterator指向的那块内存在删除和插入过程中可能已经被其他内存覆盖或者内存已经被释放了。即使时push_back的时候,容器内部空间可能不够,需要一块新的更大的内存,只有把以前的内存释放,申请新的更大的内存,复制已有的数据元素到新的内存,最后把需要插入的元素放到最后,那么以前的内存指针自然就不可用了。特别时在和find等算法在一起使用的时候,牢记这个原则:不要使用过期的iterator。
(3)当数据元素增多时,set的插入和搜索速度变化如何?
如果你知道log2的关系你应该就彻底了解这个答案。在set中查找是使用二分查找,也就是说,如果有16个元素,最多需要比较4次就能找到结果,有32个元素,最多比较5次。那么有10000个呢?最多比较的次数为log10000,最多为14次,如果是20000个元素呢?最多不过15次。看见了吧,当数据量增大一倍的时候,搜索次数只不过多了1次,多了1/14的搜索时间而已。你明白这个道理后,就可以安心往里面放入元素了。
2.set中常用的方法
begin() ,返回set容器的第一个元素
end() ,返回set容器的最后一个元素
clear() ,删除set容器中的所有的元素
empty() ,判断set容器是否为空
max_size() ,返回set容器可能包含的元素最大个数
size() ,返回当前set容器中的元素个数
rbegin ,返回的值和end()相同
rend() ,返回的值和rbegin()相同
写一个程序练一练这几个简单操作吧: 1 #include <iostream> 2 #include <set> 3 4 using namespace std; 5 6 int main() 7 { 8 set<int> s; 9 s.
目录 写在前面十四个表白效果及使用说明(最后几个是最新的效果)购买本文前12个代码怎么在页面添加文字和背景音乐?如何得到自己喜欢的音乐链接地址?怎么修改背景颜色或字体颜色?其他表白代码跨年表白代码最新表白代码(绝对好看)常见问题说明 写在前面 个人主页地址(包含一些效果的在线演示):皮小孩的个人主页
(8.1更新)需要本文前12个表白代码可以进链接扫码下载—>>>网页爱心表白代码大全
扫码支付成功后会得到百度网盘链接和提取码,里面有本文的前12个表白代码,每个代码都有详细的使用说明,教你怎么修改文字、照片、背景音乐等。
购买过程中有问题请及时联系qq1975728171.(比如:购买链接失效、购买后没有百度网盘链接、无法使用支付宝支付等等问题)
对象生日快乐祝福代码—>>>html生日快乐代码
和ta在一起100天纪念代码—>>>相爱xxx天纪念html代码
表白你愿意吗烟花特效(背景是飘落的花瓣)—>>>网页表白代码烟花特效
十四个表白效果及使用说明(最后几个是最新的效果) 本文共有14个表白效果,几乎每个代码都有详细的使用说明和独立的支付入口,扫码支付成功后会得到该资源的百度网盘链接和提取码。
如果你用电脑,直接打开手机支付宝扫码支付成功后刷新页面即可;如果你用手机,那么把支付页面截图再去支付宝扫一扫,支付成功同样会得到链接和提取码,这时候只需要选择复制链接,记住提取码就可以复制到网上提取了。
每个代码的效果都是以动图形式展示,有些效果不能完全展示,可以通过视频看部分代码组合效果—>>>程序员表白代码组合视频展示
效果1:
时间会一直走到,全程有背景音乐,下载资源后有详细的使用说明。(包括教你怎么改文字、背景音乐和在一起的时间等)
当然如果你们还没在一起,可以把上面的时间去掉。
效果1下载地址—>>>爱心跳动
代码1使用说明:(下载资源后得到)
效果2:
时间会一直走到,全程有背景音乐,下载资源后有详细的使用说明。(包括教你怎么改文字、背景音乐和在一起的时间等)
当然如果你们还没在一起,可以把上面的时间去掉。
效果2下载地址—>>>动态爱心
代码2使用说明:(下载资源后得到)
附:代码2加3d旋转照片组合效果—>>>爱心加照片
效果3:
代码3补充说明:
这个代码需要的话进–>>这个链接购买,扫码付费后会出现百度网盘链接和提取码,里面有详细的使用说明,照片、文字、背景音乐都可以修改。
效果4:
代码4补充说明:
这个代码需要的话进–>>这个链接购买,扫码付费后会出现百度网盘链接和提取码,里面有详细的使用说明,照片、文字、背景音乐都可以修改。
效果5:
画爱心,鼠标点击之后爱心扩散,满屏的宝贝!
代码5补充说明:
这个代码需要的话进–>>这个链接购买,扫码付费后会出现百度网盘链接和提取码,里面有详细的使用说明,照片、文字、背景音乐都可以修改。
效果6:
点击愿意会有烟花特效,不愿意的话会说一些表白的话。烟花页面下面有表白文字自动输出,可以更改。背景是高清动态花瓣,十分好看,可以调透明度。
代码6补充说明:
需要这个代码去我的另一篇博客下载—>>>网页表白代码烟花特效
效果7:
中间可以是女朋友的名字,比如嘉悦,可以写成jia yue.
代码7补充说明:
这个代码需要的话进–>>这个链接购买,扫码付费后会出现百度网盘链接和提取码,里面有详细的使用说明,文字、背景音乐都可以修改。
效果8:
代码8补充说明:
这个代码需要的话进–>>这个链接购买,扫码付费后会出现百度网盘链接和提取码,里面有详细的使用说明,轮播照片、背景音乐都可以修改。
效果9:
附带音频(可以自己修改音频,比如你的录音等等)。
代码9补充说明:
这个代码需要的话进–>>这个链接购买,扫码付费后会出现百度网盘链接和提取码,里面有详细的使用说明,轮播照片、背景音乐都可以修改。
效果10:
表白弹幕墙自动发送(可以修改弹幕内容),鼠标滑过星空会变化,十分炫酷。
代码10补充说明:
这个代码需要的话进–>>这个链接购买,扫码付费后会出现百度网盘链接和提取码,里面有详细的使用说明。
效果11:
开始是画小人biubiubiu发射爱心,然后显示大爱心。上面是你们在一起的时长,全程有背景音乐。
代码11补充说明:
这个代码需要的话进–>>这个链接购买,扫码付费后会出现百度网盘链接和提取码,里面有详细的使用说明,在一起时间、背景音乐都可以修改。
效果12:
这个代码需要的话进这个文章下载—>>>爱心加照片
里面有详细的使用说明,可以换照片和滚动文字。
效果13:
可以改文字(也就是你想对ta说的话),修改你们在一起的时间。
下载地址—>>>爱心自动打字
效果14:
这是表白模板,可以套用,改里面的文字照片即可。
进这个文章下载–>>>情侣相恋100天纪念模板
购买本文前12个代码 (8.
Redis安装说明(转 侵删) 1.单机安装Redis1.1.安装Redis依赖1.2.上传安装包并解压1.3.启动1.3.1.默认启动1.3.2.指定配置启动1.3.3.开机自启 2.Redis客户端2.1.Redis命令行客户端2.2.图形化桌面客户端2.2.1.安装2.2.2.建立连接 大多数企业都是基于Linux服务器来部署项目,而且Redis官方也没有提供Windows版本的安装包。因此课程中我们会基于Linux系统来安装Redis. 此处选择的Linux版本为CentOS 7.
Redis的官方网站地址:https://redis.io/
1.单机安装Redis 1.1.安装Redis依赖 Redis是基于C语言编写的,因此首先需要安装Redis所需要的gcc依赖:
yum install -y gcc tcl 1.2.上传安装包并解压 然后将课前资料提供的Redis安装包上传到虚拟机的任意目录:
例如,我放到了/usr/local/src 目录:
解压缩:
tar -xzf redis-6.2.6.tar.gz 解压后:
进入redis目录:
cd redis-6.2.6 运行编译命令:
make && make install 如果没有出错,应该就安装成功了。
默认的安装路径是在 /usr/local/bin目录下:
该目录以及默认配置到环境变量,因此可以在任意目录下运行这些命令。其中:
redis-cli:是redis提供的命令行客户端redis-server:是redis的服务端启动脚本redis-sentinel:是redis的哨兵启动脚本 1.3.启动 redis的启动方式有很多种,例如:
默认启动指定配置启动开机自启 1.3.1.默认启动 安装完成后,在任意目录输入redis-server命令即可启动Redis:
redis-server 如图:
这种启动属于前台启动,会阻塞整个会话窗口,窗口关闭或者按下CTRL + C则Redis停止。不推荐使用。
1.3.2.指定配置启动 如果要让Redis以后台方式启动,则必须修改Redis配置文件,就在我们之前解压的redis安装包下(/usr/local/src/redis-6.2.6),名字叫redis.conf:
我们先将这个配置文件备份一份:
cp redis.conf redis.conf.bck 然后修改redis.conf文件中的一些配置:
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0 bind 0.0.0.0 # 守护进程,修改为yes后即可后台运行 daemonize yes # 密码,设置后访问Redis必须输入密码 requirepass 123321 Redis的其它常见配置:
# 监听的端口 port 6379 # 工作目录,默认是当前目录,也就是运行redis-server时的命令,日志、持久化等文件会保存在这个目录 dir .
golang标准库os模块-进程相关操作 package main import ( "fmt" "os" "time" ) func main() { // 获取当前正在运行的进程id fmt.Printf("os.Getpid(): %v\n", os.Getpid()) // 父id fmt.Printf("os.Getppid(): %v\n", os.Getppid()) // 设置新进程的属性 attr := &os.ProcAttr{ // files指定新进程集成的活动文件对象 // 前三个分别为 标准输入 标准输出 标准错误输出 Files: []*os.File{ os.Stdin, os.Stdout, os.Stderr, }, // 新进程的环境变量 Env: os.Environ(), } p, err := os.StartProcess("C:\\Windows\\System32\\notepad.exe", []string{"C:\\Windows\\System32\\notepad.exe", "D:\\a.txt"}, attr) if err != nil { fmt.Printf("err: %v\n", err) } fmt.Printf("p: %v\n", p) fmt.Println("进程ID--->", p.Pid) // 通过进程ID查找进程 p2, err2 := os.
最近在训练网络,发现无法使用GPU,一直报错cuda out of memory.查阅了网上很多方法,记录一下我的解决过程。
可能原因及解决方法 (一) 原因:大量其他进程占用了GPU
解决:kill占用GPU的进程,释放GPU
参考博文:链接
(二) 原因:batch_size过大
解决:将batch_size调小一点,再次测试看能否运行。
(三) 原因:不知道这个怎么描述,没有用到所有的GPU?
解决:在代码中添加os.environ['CUDA_VISIBLE_DEVICES']="0, 1",这个序号是你的设备的GPU的编号,我的设备上只有0,1号GPU。
参考博文:链接
(四) 原因:程序运行过程中产生大量中间量,pytorch不清除这些中间量,从而造成了GPU爆内存。
解决:清除过程中产生的中间量
参考博文:添加链接描述
我的问题的解决 修改过程 上述的(一)(二)(三)(四)都尝试了之后,未能解决我的程序的问题。
我的程序报错的地方:
将其改为:
这一步不保存中间的梯度信息。
继续报错:element 0 of tensors does not require grad and does not have a grad_fn
继续改,原因是require_grad是False,改为True:train_loss = train_loss.requires_grad_(True)
哦莫,就成了!喜大普奔!还是GPU跑得快啊!
说明 当我把batch_size改成8后就又跑不动了,我的GPU太拉胯了,最后batch_size改为4跑的。
小疑问 运行时,CPU的利用率70%+,GPU0的利用率恒为1%,GPU1的利用率不到20%,磁盘利用率大幅增加。为什么CPU的利用率仍然这么高?而GPU的利用率却不是很高?之前用CPU跑的时候,每次CPU的利用率都接近100%。难道是我电脑显卡不好?!
py文件如何调用不同文件夹下的py文件,参考博客:
https://blog.csdn.net/lwgkzl/article/details/81161985
py文件调用同文件夹下的py文件,参考博客:
https://www.cnblogs.com/AmyHu/p/10654500.html
Web应用开发技术笔记 第一章1.1 WEB技术概述Web的三要素静态网页动态网页(Applet)动态网页动态Web的发展静态网页动态网页的比较 1.2 Web应用程序的工作原理C/S结构优缺点对比B/S结构优缺点对比Web应用程序的开发 1.3 动态Web技术PHPASP/ASP.NETJSP 1.4 JAVA Web开发的方式与体系结构JSP的工作原理JAVA开发Web程序几种方式 第二章2.1 HTMLhtml,css,javascript的关系html文件的基本结构 2.2 常用标签文本相关标签图像标签页面链接标签表格标签文字布局 2.3 表单标签2.4 HTML5新标签新属性不再使用HTML5新特性和效果HTML5 优点客户端存储数据新的表单输入类型和属性 第三章 CSS3.1 CSS简介CSS布局和Table布局3.2 如何在网页中应用样式表内嵌样式表内部样式表外部样式表 3.3 CSS语法可选的值选择器 3.4 CSS布局与定位盒属性行内元素和块元素 3.5 响应式 Web 设计响应式Web设计的优势RWD 核心方法轻量级CSS框架 第一章 1.1 WEB技术概述 Web的三要素 展示资源:超文本技术(HTML)
资源地址:统一资源定位技术(URL)
获取资源:应用层协议(HTTP)
静态网页 可否用静态WEB技术开发一个电子商务网站?
答:不能,买卖需要有交互,网页需要实时更新,而静态网站的加载一次成型,无法做到和网页的交互与实时更新。
动态网页(Applet) Applet存在的问题
不允许进行文件读写,无法进行数据库操作
属胖客户端,下载速度缓慢
发展限制,推广受阻:
Applet 需要浏览器给予支持,而且还要根据不同的版本安装不同版本的JVM
SUN和微软之间的版权矛盾,微软的IE浏览器在一段时间内不支持JVM
动态网页 这类网页文件不仅含有HTML标记,而且含有程序代码(在服务器端运行),这种网页的后缀一般根据不同的程序设计语言而不同,如ASP.NET文件的后缀为.aspx;JSP文件为.jsp。
两个显著特点:
可以动态产生页面
支持客户端和服务器端的交互功能
动态Web的发展 CGI(Common Gateway Interface,公共网关接口)
CGI技术允许服务端的应用程序根据客户端的请求,动态生成HTML页面,这使客户端和服务端的动态信息交换成为了可能。
CGI是一个标准,采用多进程的机制进行处理,每当一个新用户连接到服务器上时,服务器就为其分配一个新的进程 ,效率低。
1994年, PHP
Rasmus Lerdorf发明了专用于Web服务端编程的PHP(Personal Home Page Tools)语言。
1996年, ASP
导语 | 消息队列是分布式系统中重要的中间件,在高性能、高可用、低耦合等系统架构中扮演着重要作用。本文对Kafka、Pulsar、RocketMQ、RabbitMQ、NSQ这几个消息队列组件进行了一些调研,并整理了相关资料,为业务对MQ中间件选型提供参考。
一、概述
消息队列是分布式系统中重要的中间件,在高性能、高可用、低耦合等系统架构中扮演着重要作用。分布式系统可以借助消息队列的能力,轻松实现以下功能:
解耦,将一个流程的上游和下游拆开,上游专注生产消息,下游专注处理消息。
广播,一个上游生产的消息轻松被多个下游服务处理。
缓冲,应对流量突然上涨,消息队列可以扮演一个缓冲器的作用,保护下游服务使其可以根据实际的消费能力处理消息。
异步,上游发送消息后可以马上返回,下游可以异步处理消息。
冗余,保留历史消息,处理失败或当出现异常时可以进行重试或者回溯防止丢失。
近几年出现了一些关注度较高的消息队列中间件选型,如Kafka、Pulsar、RocketMQ等,首先从宏观上做一些对比:
结论:
日志处理、大数据处理等场景,高吞吐量、低延迟的特性考虑,Kafka依旧是一个较好的选型。
针对业务交易数据,有延迟消息、队列模式消费、异地容灾,多消息主题等场景,可以选用TDMQ/Pulsar。
其他一些业务自定义的使用场景,由于后台技术栈是Golang,可以考虑采用NSQ进行定制开发或研究学习。
消息中间件性能跟服务端、客户端参数、使用场景等方面上有很大关系,在系统上线前,还需要根据实际应用场景进行压测调优。
二、架构简介
(一)Kafka (来源:https://zhuanlan.zhihu.com/p/38269875)
一个Kafka集群由多个Broker和一个ZooKeeper集群组成,Broker作为Kafka节点的服务器。同一个消息主题Topic可以由多个分区Partition组成,分区物理存储在Broker上。负载均衡考虑,同一个Topic的多个分区存储在多个不同的Broker上,为了提高可靠性,每个分区在不同的Broker会存在副本。
ZooKeeper是一个分布式开源的应用程序协调服务,可以实现统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等工作。Kafka里的ZooKeeper主要有一下几个作用:
Broker注册,当有Broker故障的时候能及时感知。
Topic注册,维护Topic各分区的个副本所在的Broker节点,以及对应leader/follower的角色。
Consumer注册,维护消费者组的offset以及消费者与分区的对应关系,实现负载均衡。
(二)Pulsar (来源:https://cloud.tencent.com/developer/article/1845616)
Pulsar有三个重要的组件,Broker、BookKeeper和ZooKeeper,Broker是无状态服务,客户端需要连接到Broker上进行消息的传递。BookKeeper与ZooKeeper是有状态服务。BookKeeper的节点叫Bookie,负责存储消息和游标,ZooKeeper存储Broker和Bookie的元数据。Pulsar以这种架构,实现存储和计算分离,Broker负责计算,Bookie负责有状态存储。
Pulsar的多层架构影响了存储数据的方式。Pulsar将Topic分区划分为分片(Segment),然后将这些分片存储在Apache BookKeeper的存储节点上,以提高性能、可伸缩性和可用性。Pulsar的分布式日志以分片为中心,借助扩展日志存储(通过Apache BookKeeper)实现,内置分层存储支持,因此分片可以均匀地分布在存储节点上。由于与任一给定Topic相关的数据都不会与特定存储节点进行捆绑,因此很容易替换存储节点或缩扩容。另外,集群中最小或最慢的节点也不会成为存储或带宽的短板。
(三)RocketMQ (来源:https://rocketmq.apache.org/docs/rmq-arc/)
RocketMQ是阿里开源的消息中间件,它是一个开源的分布式消息传递和流式数据平台。总共有四大部分:NameServer,Broker,Producer,Consumer。
NameServer主要用来管理brokers以及路由信息。broker服务器启动时会注册到NameServer上,并且两者之间保持心跳监测机制,以此来保证NameServer知道broker的存活状态。而且,每一台NameServer都存有全部的broker集群信息和生产者/消费者客户端的请求信息。
Broker负责管理消息存储分发,主从数据同步,为消息建立索引,提供消息查询等能力。
(四)RabbitMQ (来源:https://www.cxymm.net/article/Super_RD/70238869)
RabbitMQ基于AMQP协议来实现,主要由Exchange和Queue两部分组成,然后通过RoutingKey关联起来,消息投递到Exchange然后通过Queue接收。
(五)NSQ (来源:https://zhuanlan.zhihu.com/p/37081073)
NSQ主要有nsqlookup、nsqd两部分组成:
Nsqlookup为守护进程,负责管理拓扑信息并提供发现服务。客户端通过查询nsqlookupd获取指定Topic所在的nsqd节点。nsqd往nsqlookup上注册和广播自身topic和channel的信息。
nsqd在服务端运行的守护进程,负责接收,排队,投递消息给客户端。
二、选型要点
先来个汇总,接下来会对消息队列中间件的各项功能进行逐个分析。
(一)功能 消费推拉模式
客户端消费者获取消息的方式,Kafka和RocketMQ是通过长轮询Pull的方式拉取消息,RabbitMQ、Pulsar、NSQ都是通过Push的方式。
pull类型的消息队列更适合高吞吐量的场景,允许消费者自己进行流量控制,根据消费者实际的消费能力去获取消息。而push类型的消息队列,实时性更好,但需要有一套良好的流控策略(backpressure)当消费者消费能力不足时,减少push的消费数量,避免压垮消费端。
延迟队列
消息延迟投递,当消息产生送达消息队列时,有些业务场景并不希望消费者立刻收到消息,而是等待特定时间后,消费者才能拿到这个消息进行消费。延迟队列一般分为两种,基于消息的延迟和基于队列的延迟。基于消息的延迟指为每条消息设置不同的延迟时间,当队列有新消息进入的时候根据延迟时间排序,当然这样会对性能造成较大影响。另一种基于队列的延迟指的是设置不同延迟级别的队列,队列中每个消息的延迟时间都是相同的,这样免去了基于延迟时间排序对性能带来的损耗,通过一定的扫描策略即可投递超时的消息。
延迟消息的使用场景比如异常检测重试,订单超时取消等,例如:
服务请求异常,需要将异常请求放到单独的队列,隔5分钟后进行重试;
用户购买商品,但一直处于未支付状态,需要定期提醒用户支付,超时则关闭订单;
面试或者会议预约,在面试或者会议开始前半小时,发送通知再次提醒。
Kafka不支持延迟消息。Pulsar支持秒级的延迟消息,所有延迟投递的消息会被Delayed Message Tracker记录对应的index,consumer在消费时,会先去Delayed Message Tracker检查,是否有到期需要投递的消息,如果有到期的消息,则从Tracker中拿出对应的index,找到对应的消息进行消费,如果没有到期的消息,则直接消费正常的消息。对于长时间的延迟消息,会被存储在磁盘中,当快到延迟间隔时才被加载到内存里。
RocketMQ开源版本延迟消息临时存储在一个内部主题中,不支持任意时间精度,支持特定的level,例如定时5s,10s,1m等。
RabbitMQ需要安装一个rabbitmq_delayed_message_exchange插件。
NSQ通过内存中的优先级队列来保存延迟消息,支持秒级精度,最多2个小时延迟。
死信队列
由于某些原因消息无法被正确的投递,为了确保消息不会被无故的丢弃,一般将其置于一个特殊角色的队列,这个队列一般称之为死信队列。与此对应的还有一个“回退队列”的概念,试想如果消费者在消费时发生了异常,那么就不会对这一次消费进行确认(Ack), 进而发生回滚消息的操作之后消息始终会放在队列的顶部,然后不断被处理和回滚,导致队列陷入死循环。为了解决这个问题,可以为每个队列设置一个回退队列,它和死信队列都是为异常的处理提供的一种机制保障。实际情况下,回退队列的角色可以由死信队列和重试队列来扮演。
Kafka没有死信队列,通过Offset的方式记录当前消费的偏移量。
Pulsar有重试机制,当某些消息第一次被消费者消费后,没有得到正常的回应,则会进入重试Topic中,当重试达到一定次数后,停止重试,投递到死信Topic中。
RocketMQ通过DLQ来记录所有消费失败的消息。
日常学习笔记 ++i与i++的区别 1. 赋值顺序不同 :i++ 返回原来的值,++i 返回加1后的值。 例如在Java中:
public class Test{ public static void main(String [] args){ int i = 1; int s = ++i; int x= i++; System.out.printLn(i); System.out.printLn(s); System.out.printLn(x); } } 答案:“3, 2, 2”。
解析:i++改变的只有i,++i既改变i,又改变赋值变量;
2. i++ 不能作为左值,而++i 可以。 左值是对应内存中有确定存储地址的对象的表达式的值,而右值是所有不是左值的表达式的值。一般来说,左值是可以放到赋值符号左边的变量。但能否被赋值不是区分左值与右值的依据。
++i = 1;//正确 i++ = 1;//错误 也可以这么理解
++ i 是先加后赋值;i ++ 是先赋值后加;++i和i++都是分两步完成的。因为**++i 是先加,后面一步才赋值**的,所以它能够当作一个变量进行级联赋值,++i = a =b,即 ++i 是一个左值;i++ 的后面一步是自增,不是左值。
3. 效率不同 比如i=3,b=i++就是说b=3,完成之后让i变成4,b=++i就是先让i++变成4,然后b=4,其中++i比i++效率要高些。一般来说在循环域里面,这两者并没有什么很大的区别,但是要注意其生存周期,以及i值在程序流中的变化。
两者单独使用时一样 独立使用时++i 和 i++二者效果一样,就是 i=i+1。表达式中i++取i的值参与运算,而++i取i+1的值参与运算。举例 a = ++i,相当于 i=i+1; a = i; a = i++,相当于 a = i; i=i+1。
声明:此篇文章是个人学习笔记,并非教程,所以内容可能不够严谨。可作参考,但不保证绝对正确。如果你发现我的文章有什么错误,非常欢迎指正,谢谢哦
torch.mean参数简单介绍 #求所有元素的平均值:input是要处理的张量;返回值是1个数,张量形式 torch.mean(input, *, dtype=None) → Tensor #沿张量中某个维度求平均值:input是要处理的张量,dim是想求的维度,keepdim是否保留长度为1的维度;返回值是张量形式,维数默认和原张量一样。 torch.mean(input, dim, keepdim=False, *, dtype=None, out=None) → Tensor 实验验证函数和参数作用 数据集 以batch=2,channel=2,hight=4, width=4的图片为例,即维度为[2, 2, 4, 4]的张量:
batch1:(红色、橙色为两个不同的通道,下同)
batch2:
以下用代码实验: data = torch.tensor( [[[ [9.0, 0, 7, 6], [3, 2, 6, 8], [7, 5, 4, 4], [4, 8, 3, 5]], [ [3, 8, 7, 2], [9, 6, 1, 2], [2, 0, 8, 0], [2, 9, 8, 4]]], [[ [6, 1, 5, 6], [2, 3, 4, 8], [5, 3, 3, 3], [4, 1, 8, 4]], [ [3, 6, 5, 4], [4, 9, 8, 5], [7, 1, 5, 4], [4, 4, 8, 6]]] ] ) total_mean = torch.
Centos7一个网卡突然出现两个网卡,导致业务地址无法访问
解决方案:
1.ipconfig查看网卡信息
2.把你实际在用的网卡信息进行编辑,确定为静态IP(BOOTPROTO=static)以及增加NM_CONTROLLED=no
3.保存退出后重启网络service network restart
4.最后重启服务器即可
脚本需求 删除下载文件或带标识字符串的广告文件名,用以识别正常文件名称。
实现方法 直接上Bat脚本,根据个人需求直接替换"xiaowen-"字段内容即可,该脚本支持对特殊符号进行删除,操作前如有需要请及时备份原文件。
脚本具体内容如下:
@echo off setlocal enabledelayedexpansion for /f "delims=" %%1 in ('dir /a /b') do ( :: "!wind:<strong>=!" , </strong>这里跟要删除的字符串名称,支持删除特殊符号 set wind=%%1 ren "%%~1" "!wind:xiaowen-=!" ) 注意事项: 通过记事本创建脚本后,另存文件为ANSI格式并修改后缀名为.bat,避免格式错误导致脚本无法执行或执行后没有修改成功。
图示参考如下:
执行脚本步骤及结果如下:
1 Byte=8bit
1MB =8Mb
1Mb=0.125MB
1Kb=1024bit
1KB=1024 Byte
1 MB=1024KB=1024*1024B
1 MB/s=8Mb/s=1024KB/s
1Mbps=1000Kbps=1000/8KBps=125KBps
Chap 5 MATLAB函数 5.1 函数简介 一个典型的MATLAB函数如下:
function f = fact(n) % H1 Comment Line % Other Comment Line1 % Other Comment Line... f = prod(1:n); end function关键字标志着函数的开始,=左边是输出列表,=右边是函数名,紧跟函数名的是输入列表。
function下的第一个行注释称为H1注释行,应当是对本函数功能的总结,可以通过lookfor命令搜索到。
从H1注释行到第一个空行或者第一个可执行语句间的注释可以通过help命令搜索到。
lookfor fact; help fact; function 关键字(必需)对关键字使用小写字符。输出参数(可选)如果您的函数返回一个输出,则您可以在 function 关键字后面指定输出名称。function myOutput = myFunction(x)如果您的函数返回多个输出,请将输出名称括在方括号中。function [one,two,three] = myFunction(x)如果没有输出,您可以将其忽略。function myFunction(x)您也可以使用空的方括号。function [] = myFunction(x)函数名称(必需)有效的函数名字遵守与变量名称相同的规则。它们必须以字母开头,可以包含字母、数字或下划线。注意为避免混淆,对函数文件及函数文件内的第一个函数使用相同名称。MATLAB 将您的程序与文件名而不是函数名称相关联。脚本文件不能与文件中的函数具有相同的名称。输入参数(可选)如果您的函数接受任何输入,请在函数名称之后将输入名称括在圆括号中。用逗号将各个输入隔开。function y = myFunction(one,two,three)如果没有输入,可以忽略圆括号。 函数以end语句、文件末尾或局部函数的定义行结束。虽然end有时不是必须的,但一般都会加上end提高代码可读性。
5.2 按值传递变量 MATLAB函数的参数传递的机制是按值传递,但其实MATLAB会分析传入的参数是否在函数内被修改了,如果没有修改就不会对参数进行复制,而是使用外面的变量;如果修改了复制操作才会执行。
5.3 选择性参数 许多MATLAB函数支持选择性输入参数和输出参数,比如对于plot函数来说,既可以输入两个参数,也可以输入八个参数,对于max的输出,可以选择输出一个,也可以输出两个。
MATLAB中有专门的函数用于 获取选择性参数的信息 和 报告其错误:
NameFunctionnargin实际输入参数的个数nargout实际输出参数的个数nargchk如果调用参数过多或过少会返回一个标准错误信息error显示错误信息,并中止函数以免产生这个错误warning显示警告信息,并继续执行函数inputname返回对特定参数个数的实际变量名 注意:inputname返回的是***函数传入参数的工作区变量的名称***,如果输入参数是数字、表达式或索引表达式而不是变量,则它没有名称。要用inputname(n)来获取某个参数的名称,例如打印输入参数的变量名:
function argTest(arg1, arg2, arg3) % disp every arg in narginchk(1, 3); % use modern usage above instead of below % message = nargchk(minargs, maxargs, nargin); % error(message); for i = 1 : nargin disp(inputname(i)); end end 以前一般是将nrgchk和error结合着用,但现在MATLAB推荐使用narginchk和nargoutchk来代替,如果输入参数过多或过少,matlab会有报错:
synchronized锁升级过程依次为无锁、偏向锁、轻量级锁、重量级锁,部分文章认为synchronized锁不存在降级过程,但在openjdk的hotsopt jdk8u里是有锁降级的机制的。
对象头 锁升级示意图 1. 无锁到偏向锁 线程A执行到同步代码块时,检查对象头锁标志位是否为01,再看偏向锁标志位是否为0(即检查对象是否为无锁状态),通过CAS操作尝试修改MarkWord字段,这里CAS操作只尝试一次,失败的话说明发生锁竞争,立即升级为轻量级锁。成功修改后执行同步代码块,执行完毕后不主动释放偏向锁。将Lock Record中的obj设置为null,表示当前线程不在同步代码块中。
2. 偏向锁到轻量级锁 线程B执行到同步代码块时,检查到对象头锁标志位为01且偏向锁标志位为1,说明该锁已被线程占有。检查Thread Id是否为当前线程(B线程),是的话就执行同步代码块,否则就进入锁撤销逻辑,jvm会在安全点暂停所有线程,判断持有锁线程的当前状态,分两种情况:
线程已死亡或没在执行同步代码块: JVM维护了一个集合存放所有存活的线程,通过遍历该集合判断某个线程是否存活。进行锁撤销操作,对象由偏向锁变为无锁且不可偏向状态,线程B通过CAS操作尝试修改Thread Id失败升级为轻量级锁,成功则执行同步代码块。线程正在执行同步代码块: 说明发生了锁竞争,进行锁撤销,将对象头MarkWord置为无锁状态并升级为轻量级锁。 注: 当锁处于偏向锁状态时,只要有多个线程尝试获取同一把锁,该锁都会升级为轻量级锁,区别是升级的时机不同。
3. 轻量级锁到重量级锁 线程C执行到同步代码块时,检查到对象头锁标志位00,说明该锁为轻量级锁。通过CAS操作尝试修改MarkWord字段,因为自旋的原因这里尝试多次CAS操作,多次尝试都失败的话将锁升级为重量级锁,线程睡眠等待被唤醒。自旋成功则执行同步代码块,执行完毕后释放锁恢复MarkWord数据,然后检查锁是否升级为重量级锁(线程执行同步代码块的时候可能有其他线程过来抢占锁且不成功,这时锁会升级为重量级锁)。如果升级为重量级锁的话还要执行一步操作 唤醒其他线程。
轻量级锁的获取与释放 获取: 线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录(Lock Recored)的空间,并将对象头中的MarkWord复制到锁记录中,官方称为Displaced Mark Word。然后线程尝试使用CAS将对象头中的MarkWord替换为指向锁记录的指针。如果成功,当前线程获得锁,执行同步代码块。(当线程再次进入同步代码块时,只需检查对象头中的MarkWord中的指针是否指向当前线程的锁记录,不是的话执行自旋CAS操作,是的话直接执行同步代码块)如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。多次自旋仍未获取锁则锁升级为重量级锁。
释放: 线程获取锁且执行完同步代码块,开始释放锁,通过CAS操作将之前复制在栈桢中的 Displaced Mard Word 替换回 MarkWord 中。如果成功说明执行同步代码块和释放过程中没有其他线程竞争,如果失败说明锁已经升级为重量级锁,这时候唤醒其他进程。
相关问题 轻量级锁竞争中的自旋等待 jvm进行线程之间的切换需要耗费一定的时间,部分情况切换线程耗费的时间比同步代码块执行的时间还要长。这时线程在获取不到锁的情况下自旋一定次数之后极有可能碰到获得锁的线程释放锁,所以,轻量级锁适用于那些同步代码块执行很快的场景,这样线程原地等待很短的时间就能够获得锁了。自适应自旋: jdk1.7之后自旋次数由jvm自动调整,判断依据是前一次在同一个锁上自旋的时间以及锁的拥有者的状态。
锁消除 锁消除是指虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除。
锁粗化 在使用锁的时候,需要让同步块的作用范围尽可能小,这样做的目的是为了使需要同步的操作数量尽可能小,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁。
批量重偏向与批量撤销 当只有一个线程反复进入同步块时,偏向锁带来的性能开销基本可以忽略,但是当有其他线程尝试获得锁时,就需要等到SafePoint时将偏向锁撤销为无锁状态或升级为轻量级/重量级锁。详细可以看这篇文章。总之,偏向锁的撤销是有一定成本的,如果说运行时的场景本身存在多线程竞争的,那偏向锁的存在不仅不能提高性能,而且会导致性能下降。因此,JVM中增加了一种批量重偏向/撤销的机制。
存在如下两种情况:
一个线程创建了大量对象并执行了初始的同步操作,之后在另一个线程中将这些对象作为锁进行之后的操作。这种case下,会导致大量的偏向锁撤销操作。存在明显多线程竞争的场景下使用偏向锁是不合适的,例如生产者/消费者队列。 批量重偏向(bulk rebias)机制是为了解决第一种场景。批量撤销(bulk revoke)则是为了解决第二种场景。
其做法是:以class为单位,为每个class维护一个偏向锁撤销计数器,每一次该class的对象发生偏向撤销操作时,该计数器+1,当这个值达到重偏向阈值(默认20)时,JVM就认为该class的偏向锁有问题,因此会进行批量重偏向。每个class对象会有一个对应的epoch字段,每个处于偏向锁状态对象的mark word中也有该字段,其初始值为创建该对象时,class中的epoch的值。每次发生批量重偏向时,就将该值+1,同时遍历JVM中所有线程的栈,找到该class所有正处于加锁状态的偏向锁,将其epoch字段改为新值。下次获得锁时,发现当前对象的epoch值和class的epoch不相等,那就算当前已经偏向了其他线程,也不会执行撤销操作,而是直接通过CAS操作将其mark word的Thread Id 改成当前线程Id。
当达到重偏向阈值后,假设该class计数器继续增长,当其达到批量撤销的阈值后(默认40),JVM就认为该class的使用场景存在多线程竞争,会标记该class为不可偏向,之后,对于该class的锁,直接走轻量级锁的逻辑。
参考文章:
jvm锁升级的过程
死磕Synchronized底层实现–偏向锁
批量重偏向和批量撤销理解
技术博客地址: 西贝博客
软考在职业资格考试中,越来越多的考生选择考计算机软考证书,但又特别纠结和犹豫,不知道应该报哪个软考高级?哪个更好考?
软考高级资格共分有五个分别是:信息系统项目管理师、系统分析师、系统架构师设计师、网络规划设计师、系统规划与管理师。
目前认可度和知名度相对比较高的是:信息系统项目管理师。
高级的5个考试中大部分都是一年考一次,只有信息系统项目管理师考试是一年两次的,另外,高级的考试都要考到论文,而信息系统管理是现在非常热门的一个行业,历年真题比较多,可借鉴参考的论文范文也比较多。因此信息系统项目管理师的考试难度也不是很高的。
信息系统项目管理师考核内容:信息系统项目管理知识和方法;项目整体绩效评估方法;常用项目管理工具;信息系统相关法律法规、技术标准与规范。
信息系统项目管理师综合知识评分标准
信息系统项目管理师综合知识:只有选择题,是机器阅卷,符合答案即得分
信息系统项目管理师案例分析评分标准:案例分析为主观题,老师阅卷。观点能正确切题,表达清楚即得分。
信息系统项目管理师论文评分标准:
论文满分是75分,论文评分可分为优良、及格与不及格3个档次。评分的分数可分
(1)60分至75分优良(相当于百分制80分至100分)。
(2)45分至59分及格(相当于百分制60分至79分)。
(3)0分至44分不及格(相当于百分制0分至59分)。
评分时可先用百分制进行评分,然后转化为以75分为满分(乘0.75)。
信息系统项目管理师证书用途?
1.能力提升 如高级的信息系统项目管理师,除了考查IT技术以外,同时还要项目管理的知识。这也是软考认证的根本目的,提升IT人士的综合能力。
2、升职加薪 在79%的软件行业雇主更倾向有证的学生,软考证书的也会成为衡量员工的项目管理能力的标准,会给予涨薪或奖励,同时也是企业内部升职的条件之一。
3、以考代评 所谓的以考代评,就是考过对应的级别,就能获得对应级别的职称。在中国中高级职称是可以做很多事情的,除了升职加薪,对买车、买房、摇号等都是有好处的。
4、积分入户 软考证书在申请北上广等城市户口是可以加分的(积分入户城市)
5、企业申资 系统集成的企业为了能够获得更多的大项目,必须申请企业的资质级别,申请资质的条件之一,就是要求员工求员工有一定数量的中级系统集成项目管理工程师,高级的信息系统项目管理师证书。项目申报成功后,公司持证人员给予奖励。
6、政策扶持 政策扶持继续教育专项附加扣除税的扣除
本期主题:
unix环境高级编程——UNIX体系架构
文件IO 0.初始UNIX1.系统调用2.库函数2.1 C语言的运行库 3.shell 0.初始UNIX 这里略过unix的历史不讲,网上有比较详细的资料。
我们可以将操作系统定义为一种软件 ,这种软件所做的事情包括控制计算机各种硬件资源,提供应用程序的运行环境,通常这种软件被称为内核(kernel)。
整体的系统架构图如下所示:
内核的接口被称为系统调用
公用函数库构建在系统调用之上
应用程序既可以使用公用函数库,也可以是使用系统调用
shell是一个特殊的应用程序,为运行其他应用程序提供了接口
1.系统调用 /dev目录中的设备文件的用法都是相同的,它们都可以被打开、读、写和关闭。
下面是用于访问设备驱动程序的底层函数(系统调用)。
open:打开文件或设备read:从打开的文件或设备里读数据write:向文件或设备写数据close:关闭文件或设备ioctl:把控制信息传递给设备驱动程序。 可以直接用系统调用 open()、read()、close()来实现文件的操作,绕过glibc的fopen、fread、fclose
2.库函数 针对底层硬件的输入输出,频繁的使用系统调用效率会非常低,原因在于:
操作系统需要频繁的从 用户态 切换到 内核态,减少这种开销的一个好方法是,在程序中尽量减少系统调用的次数,并且让每次系统调用完成尽可能多的工作。硬件本身的特性决定,例如,磁带机通常一次能写的数据块长度是10k。所以,如果你试图写的数据量不是10k的整数倍,磁带机还是会以10k为单位卷绕磁带,从而在磁带上留下了空隙。 需要运行库的原因除了刚刚讲的效率低问题,还有一个就是有了标准库,会更方便上层的开发:
使用简便。运行库本身就是语言级别,一般相对设计比较友好;形式统一。运行库有自身的标准,是相互兼容的,这个不会随着操作系统或者编译器的变化而变化,例如在windows上和在Linux上都是fread()函数; 因此为了给设备和磁盘文件提供更高层的接口,Linux发行版(和UNIX)提供了一系列的标准函数库。
它们是一些由函数构成的集合,你可以把它们应用到自己的程序中,比如提供输出缓冲功能的标准I/O库。
你可以高效地写任意长度的数据块,库函数则在数据满足数据块长度要求时安排执行底层系统调用。这就极大降低了系统调用的开销。
以下就是常用的标准I/O库函数
fopen、fclosefread、fwritefflushfseekfgetc、getc、getcharfputc、putc、putcharfgets、getsprintf、fprintf和sprintfscanf、fscanf和sscanf 2.1 C语言的运行库 任何一个C应用程序,背后都需要庞大的代码来进行支撑,使得该程序能够正常运行。这样的代码集合被称为 运行时库(runtime library),而C语言的运行库,被称为CRT(C运行库)。
一个C的运行库大致包含以下功能:
启动和退出:包含入口函数以及入口函数所依赖的部分;标准函数:C语言标准库的函数实现;I/O:I/O功能的封装和实现堆:堆的实现语言实现:语言中一些特殊功能的时间调试功能 glibc
glibc是GNU C library,是GNU旗下的C标准
glibc的发布版本主要有两部分构成
一部分是头文件,例如 stdio.h/ stdlib.h等另一部分是库的二进制文件部分,libc.so以及libc.a等 3.shell shell是一个用户可以跟操作系统交互的可视化终端,它允许用户向操作系统输入需要执行的命令,这点与Windows的命令提示符类似,但是功能更为强大。
在Linux中安装多个shell是完全可行的,用户可以挑选一种自己喜欢的shell来使用。
下图显示了shell(实际上是两种shell:bash和csh)和其他程序环绕在Linux内核的四周。
在Linux系统中,默认总是作为/bin/sh安装的标准shell是GNU工具集中的bash(GNU Bourne-Again Shell)。
背景:客户现场的一次艰苦的调优过程(https://www.cnblogs.com/kingbase/p/16015834.html),让我觉得非常有必要让数据库用户了解函数的不同稳定性属性,及其对于SQL性能可能带来的影响。很多DBA、开发人员根本就不在意,或者根本就没意识到函数稳定性对于性能的影响,这就导致出现性能问题时没有头绪。以下的例子都是实际客户现场问题的提炼,为了让用户有直观的了解。
一、函数的三种稳定态 函数的稳定性状态,简单地说就是相同的输入参数情况下,函数返回值是否相同。稳定性使得优化器可以判断不同函数的行为。为了得到最佳的优化结果,在创建函数时我们应该指定与函数功能相对应稳定性级别。
如果本应该是 volatile ,而设置成 immutable,会导致结果错误。如:currtid 函数,不同时刻执行的结果可能是不同的,必须是volatile 。如果本应该是 immutable,而设置成 volatile , 就会导致性能问题。如:trunc 函数,不同时刻执行结果应该是相同的,只需执行一次即可。 PostgreSQL 或 KingbaseES 函数在定义时有三种稳定态级别:volatile、stable 和 immutable。默认情况下,创建函数的稳定性为volatile。以下是这三种函数的区别:
Volatile 函数可以做任何事情,包括修改数据库。在调用中,输入同样的参数可能会返回不同的结果,比如:currtid 。在一个Query中,对于每一行都会重新计算该函数。Stable 函数不能修改数据库,单个Query中所有行给定同样的参数确保返回相同的结果。这种稳定级别允许优化器将多次函数调用转换为一次。在索引扫描的条件中使用这种函数是可行的,因为索引扫描只计算一次比较值(comparison value),而不是每行都计算一次。Immutable 函数不能修改数据库,在任何情况下,只要输入参数相同,返回结果就相同。这种级别的函数,优化器可以提前进行计算,在查询过程中作为常量参数。比如:SELECT...WHERE x=2+2 可以简化为SELECT...WHERE x=4。 KingbaseES 为了兼容Oracle,增加了 Deterministic稳定态,等价于 immutable 。
以下例子同时在PostgreSQL 与 KingbaseES 进行过验证。
二、等式左边函数稳定性与性能 结论:等式左边的 volatile 函数可能导致函数不必要的被重复执行。
1、构建例子:创建三种稳定性的函数。 create or replace function test_volatile(id integer) returns bigint volatile language sql as $$ select count(*) from t1 $$ ; / create or replace function test_stable(id integer) returns bigint stable language sql as $$ select count(*) from t1 $$ ; / create or replace function test_immutable(id integer) returns bigint immutable language sql as $$ select count(*) from t1 $$ ; / 例子数据如下:
人工智能iTOP-RK3568开发板
主频2.0GHz丨双核GPU丨独立NPU
4K高清 USB3.0 SATA3.0 PCIE3.0 双千兆以太网
资料全开源丨即时在线支持丨供货无忧
四核高性能64位处理器 Cortex-A55架构 主频高达2.0GHz
iTOP-RK3568开发板采用瑞芯微RK3568处理器,是一款中高端通用型SOC,22nm工艺制程。内部集成了四核64位Cortex-A55处理器
iTOP-RK3568继承了双核心架构GPU、ARM G52 2EE、支持PenGL ES1.1/2.0/3.2、OpenCL2.0、Vulkan1.1、内嵌高性能2D加速硬件 内置独立NPU,可用于轻量级人工智能应用
算力达0.8T支持0.8T算力,支持深度学习框架:Tensorflow,TF-lite,Pytorch,Caffe,ONNX MXNet,Keras,Darknet,人工智能的框架可在iTOP-3568开发板上轻松实现
iTOP-RK3568拥有不错的视频编解码能力,高性能VPU支持4K 60帧视频解码,多路视频源同时解码 H.265/H.264/VP9/VP8视频和1080P 100fps H.265/H.264/VP9视频解码
支持HDMI 2.0,图像和声音同步输出,连接电视或显示器,它就是一台真正的‘电脑’! 同时还支持EDP、MIP、VGA接口
丰富接口高扩展性支持:CAMERA、OTG、USB3.0、SARADC、UART*2、HDMI、VGA、EDP、CAN RS485、WIFI/BT、4G全网通
流畅运行Android11、buildroot+QT、Yocto、Debian系统
主要面向物联网网关、NVR存储、控工平板、工业检测、工控和、卡拉OK、云终端、车载中控等行业定制市场
主要参数
CPU: RK3568
主频: 四核 A55(2GHz)
内存: 2GB,硬件兼容 4GB
存储器: 16GB EMMC
电源管理芯片: 使用 RK809,支持动态调频等
GPU: ARM G52 2EE,支持OpenGL ES 1.1/2.0/3.2,OpenCL 2.0,Vulkan 1.1.内嵌高性能2D加速硬件
NPU: 支持0.8T算力
多媒体: 支持4K 60fps H.265/H.264/VP9视频解码,支持1080P 60fps H.265/H.264视频编码,支持8M ISP,支持HDR
支持显示屏: MIPI7寸屏、LVDS7寸屏、LVDS10.1寸屏、HDMI屏幕
核心板参数
尺寸: 65mm*55mm
核心板高度: 连同连接器在内 0.
旧的vs2019创建的python 项目,用vs2022打开编译出现如下错误。
严重性 代码 说明 项目 文件 行 禁止显示状态 错误 找不到 .NETFramework,Version=v4.0 的引用程序集。要解决此问题,请为此框架版本安装开发人员工具包(SDK/目标包)或者重新定向应用程序。可在 https://aka.ms/msbuild/developerpacks 处下载 .NET Framework 开发人员工具包 DTrms.V2.DingNotification C:\Program Files\Microsoft Visual Studio\2022\Professional\MSBuild\Current\Bin\amd64\Microsoft.Common.CurrentVersion.targets 1217 根据refs这是一个bug,可用的workaround,是手动添加到项目文件xx.pyproj中:
<PropertyGroup> <TargetFrameworkVersion>v4.8</TargetFrameworkVersion> <TargetFrameworkMoniker>.NETFramework,Version=$(TargetFrameworkVersion)</TargetFrameworkMoniker> </PropertyGroup> 另外:根据python环境判断是否要重新创建虚拟环境。
refs:
https://github.com/Microsoft/PTVS/issues/6747
基于74HC595串行动态数码管显示
一、74HC595简介 74HC595是一个8位串行输入、平行输出的位移缓存器:平行输出为三态输出。在SCK的上升沿,单行数据由SDL输人到内部的8位位移缓存器,并由Q7‘输出,而平行输出则是在LCK的上升沿将在8位位移缓存器的数据存人到8位平行输出缓存器。当串行数据输人端OE的控制信号为低使能时,平行输出端的输出值等于平行输出缓存器所存储的值。而当OE为高电位,也就是输出关闭时,平行输出端会维持在高阻抗状态。
串行输入,并行输出。
符号引脚描述Q0~Q7第15脚,第1~7脚8位并行数据输出GND第8脚地Q7’第9脚串行数据输出,级联输出端,接下一个595的DS端 MR ‾ \overline{\text{MR}} MR第10脚低电平有效,清空移位寄存器中已有的数据,一般不用,接高电平即可SH_CP或SCK第11脚移位寄存器时钟引脚,上升沿时,移位寄存器中的数据整体后移,并接受新的数据(从DS输入)。ST_CP 或RCK第12脚存储寄存器时钟输入引脚。上升沿时,数据从移位寄存器转存带存储寄存器。 OE ‾ \overline{\text{OE}} OE第13脚低电平有效,输出使能控制脚,所以接GNDDS第14脚串行数据输入引脚VCC第16脚电源 二. 输入 串行输入
SH_CP上升沿输入,输入一位往后移动一位
void LED_OUT(u8 outdata) { u8 i; for(i=0;i<8;i++)//循环8次 高位先行 { if (outdata & 0x80)//逐一取出最高位 1000 0000 b DIO=1;//送出“1” else DIO=0;//送出“0” outdata<<=1;//执行左移一位操作 SCLK=0; SCLK=1;//SCLK产生上升沿,移位寄存器中的数据整体后移,并接受新的数据(从DS输入) } } 例:输入11010110
①SH_CP(SCLK)上升沿,移位寄存器中的数据整体后移,并接受新的数据(从DS输入) 高 位 先 行 \color{red}{高位先行} 高位先行
②SH_CP上升沿,SH_CP(SCLK)上升沿,移位寄存器中的数据整体后移,并接受新的数据(从DS输入)
③SH_CP上升沿×6
三. 输出 ST_CP(RCK,存储寄存器时钟输入引脚)上升沿时,数据从移位寄存器转存带存储寄存器。
四. 4位数码管模块使用 电路图如下所示,图中是8位数码管的电路图,与4位相似,都具有两片595驱动芯片,两片595级联在一起,第二片595(U4)是对数码管的8段码进行段码操作,第一片595(U3)是对8位数码管进行位选操作,即选择哪一个数码管进行显示操作。
虽然595具有存储寄存器,但是只能对一位数码管的数据进行数据锁存。
代码如下,基于STM32F407
/* *PB4...........DIO *PB5...........RCLK *PB6...........SCLK */ #define DIO PBout(4) //串行数据输入 #define RCLK PBout(5) //存储寄存器 锁存控制信号(上升沿有效) #define SCLK PBout(6) //移位寄存器 时钟脉冲信号(上升沿有效) void HC595_Init(void) { GPIO_InitTypeDef GPIO_InitStructure; RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_GPIOB,ENABLE); //使能GPIOG的时钟 GPIO_InitStructure.
1)实验平台:正点原子STM32MP157开发板
2)购买链接:https://item.taobao.com/item.htm?&id=629270721801
3)全套实验源码+手册+视频下载地址:http://www.openedv.com/thread-318813-1-1.html
4)正点原子官方B站:https://space.bilibili.com/394620890
5)正点原子STM32MP157技术交流群:691905614
第十七章 通用定时器实验 本章我们主要来学习通用定时器,STM32MP157有10个通用定时器(TIM2TIM5,TIM12 TIM17)。我们将通过四个实验来学习通用定时器的几个功能,分别是通用定时器中断实验、通用定时器PWM输出实验、通用定时器输入捕获实验和通用定时器脉冲计数实验。
本章分为如下几个小节:
17.1、通用定时器简介;
17.2、通用定时器中断实验;
17.3、通用定时器PWM输出实验;
17.4、通用定时器输入捕获实验;
17.5、通用定时器脉冲计数实验(外部时钟模式1);
17.6、通用定时器脉冲计数实验(外部时钟模式2);
17.1 通用定时器简介
17.1.1 STM32MP157的通用定时器
定时器资源
STM32MP157的通用定时器有10个之多,其基本特性也是不尽相同,为了更好的区别各个定时器的特性,我们列了一个表格,如下所示:
表17.1.1. 1定时器基本特性表
由上表知道:除了TIM2和TIM5是32位的计数器,其他定时器是16位的。通用定时器和高级定时器是在基本定时器的基础上,添加了一些额外功能,基本定时器有的功能通用定时器都有,而且还增加了递减计数、PWM生成、输入捕获、输出比较等功能。高级定时器又包含了通用定时器的所有功能,此外还增加带可编程死区的互补输出、重复计数器、断路输入等功能。以上定时器中,通用定时器数量较多,并且其特性也有一定的差异,但是基本原理一样。
2. 通用定时器框图
下面我们以TIM2/TIM3/TIM4/TIM5的框图为例来学习通用定时器框图,其他通用定时器的框图会有差异,因为内容比较多,大家学习了这里的框图再看ST官方的手册其他的定时器框图就会比较容易理解。通过学习通用定时器框图会有一个很好的整体掌握,同时对之后的编程也会有一个清晰的思路。
图17.1.1. 1通用定时器框图
如上图,通用定时器的框图比基本定时器的框图复杂许多,为了方便介绍,我们将其分成六个部分讲解:
●①时钟源
通用定时器时钟可由下列的时钟源提供:
1)内部时钟 (CK_INT)
2)外部时钟模式 1:外部输入引脚 (TIx),x=1,2,3,4
3)外部时钟模式 2:外部触发输入 (ETR)
4)内部触发输入 (ITRx):使用一个定时器作为另一定时器的预分频器
内部时钟 (CK_INT)
这里的内部时钟 (CK_INT)实际来自APB1,定时器TIM2TIM7和定时器TIM12TIM14挂在APB1总线上,定时器TIM1、TIM8和TIM15~TIM17挂在APB2上。TIM2/TIM3/TIM4/TIM5定时器的时钟源是APB1经过一个倍频器才接到这些定时器的(即时钟不是直接来自APB1),当APB1的预分频系数为1时,此倍频器倍频值为1,定时器的时钟频率等于APB1的频率;当 APB1的预分频系数为其它数值时,此倍频器倍频值为2,定时器的时钟频率等于APB1的频率2倍。这个情况跟基本定时器的一样,请回顾基本定时器的这部分内容,最后得到TIM2/TIM3/TIM4/TIM5定时器的时钟频率为2倍的APB1,即209MHZ。如下图,可以在STM32CubeMX上动态配置时钟:
图17.1.1. 2 定时器时钟
外部时钟模式 1
图17.1.1. 3 TI2外部时钟连接示例
根据上图,我们做简单的描述:
时钟信号
如果时钟源选择的是外部时钟模式 1,即时钟信号来自外部输入引脚TI1TI4中的某一个(即定时器的通道TIMx_CH1 TIMx_CH4),属于触发输入TRGI。
滤波器和边沿检测
外部输入引脚输入的信号经过滤波器处理以后,再经过边沿检测器输出上升沿或者下降沿有效信号。滤波器的功能,简单来说就是多次检测视为一次有效,也就是连续进行N次采样检测,如果采样检测的结果都是高电平,则说明这是一个有效的电平信号,这样便可以过滤掉那干扰信号。
触发源选择
触发输入源有很多,可以来自内部触发ITRx(x等于0~4)、边沿检测器TI1F_ED、滤波后的定时器输入1(TI1FP1)、滤波后的定时器输入2(TI2FP2)、外部触发输入(ETRF)中的某一个。其中ITRx可由内部其他定时器产生信号,即使用一个定时器作为另一个定时器的预分频器,提供触发信号的定时器工作于主模式,接受触发信号的定时器工作于从模式。
上图中,采用外部时钟模1时,如果时钟信号来自外部输入引脚TI2,通过配置TIMx_SMCR 寄存器的TS[4:0]= 00101可以配置触发信号来自滤波后的定时器输入 1 (TI1FP1),也可以配置TIMx_SMCR寄存器的TS[4:0]= 00100选择TI1边沿检测器(TI1F_ED)为触发源。
1.问题描述 在用pycharm过程中,用pip去安装一些第三方包的时候会出现如下错误,缺少C++编译器,因为有些程序需要使用,没有C++接口会报错,查阅相关资料及自己的解决方案
(venv) D:\ml-lab>pip install pdf2docx error: Microsoft Visual C++ 14.0 is required. Get it with “Build Tools
for Visual Studio”: https://visualstudio.microsoft.com/downloads/
首先缺失Microsoft Visual C++ 14.0,想到的就是去Microsoft官网上找它,然后下载。
2.下载Microsoft Visual C++ Build Tools 你需要通过这个链接安装Visual C++ Build tools
https://visualstudio.microsoft.com/visual-cpp-build-tools/
vs_community__d7ca5ca772a243ca8e0e5983cf5d204a.exe
然后我下载了Visual Studio Installer
在打开的窗口中选中第二个选项卡”单个组件“
在搜索框输入14,并选中最后带有x64x86的,安装即可
3.更新包 然后开启你的电脑PC,接着运行以下命令更新Python包:
pip install --upgrade setuptools
运行一个由 Vite 构建的 Vue3 项目,之前还好好的能正常跑,但拉取新代码之后再次执行 npm run dev 就提示 ‘vite’ 不是内部或外部命令,也不是可运行的程序 或批处理文件。
百思不得其解,最终解决方案如下:
1、删除 node_modules 文件夹 和 package-lock.json 文件
2、重新执行 npm i 安装依赖
3、npm run dev 启动项目
1、字符串
字符串可以用单引号,也可以用双引号,也可以不用引号
单双引号的区别: 双引号里可以有变量,单引号则原样输出; 双引号里可以出现转义字符,单引号则原样输出; 单引号字串中不能出现单引号。 1.1、拼接字符串
#!/bin/bash str1='i' str2='love' str3='you' echo $str1 $str2 $str3 echo $str1$str2$str3 echo $str1,$str2,$str3 输出:
i love you iloveyou i,love,you 1.2、获取字符串长度 ${#str}
#!/bin/bash/ str='i love you' echo ${#str} # 输出:10 1.3、截取字符串
#! /bin/bash str='i love you' echo ${str:1} #从第一个截取末尾,注意从0,开始 echo ${str:2:2} #从第二个开始截取2个 echo ${str:0} #从0开始,也就是全部截取 echo ${str:-3} #负数无效,是为0 输出:
love you lo i love you i love you 1.4、查找字符串
#!/bin/bash/ str="i love you" echo `expr index "
引言:当我们学习 vue框架时候,在学习组件化编程的时候我们会使用到vue—cli,即是vue脚手架 接下来给大家分享如何创建脚手架
第一步 1.打开cmd窗口运行以下代码
npm config set registry https://registry.npm.taobao.org
将npm包换为淘宝镜像
(这一步不做的话下载速度会很慢,因为npm包的服务器是在国外,访问下载的速度都很慢!!!)
第二步 2.执行如下代码 全局安装脚手架
npm install -g @vue/cli
第三步 3.切换到你要创建项目的目录,然后使用命令创建项目 运行vue create xxx
假如切换到某个位置,这里做个演示
图片中的xxx代表的是你要创建的项目的名字
第四步 4.在创建文件的目录下运行 npm run serve
会得到如下结果
将网址打开就有vue官方默认写的一个类似hello world 的案例
注意 在执行vue create xxx这行代码时候,中途会让你选择用vue2还是vue3写代码,根据自己的需求选择即可!
希望可以帮助到大家!
本文记录在centos7系统上搭建SVN服务器步骤。
目录 离线安装SVN在线安装SVN升级SVN版本创建SVN版本库Windows安装SVN客户端 离线安装SVN 1、下载安装包
subversion-1.14.1.tar.gz:http://subversion.apache.org/download/
sqlite-autoconf-3140000.tar.gz:http://www.sqlite.org/download.html(数据库依赖包)
apr-1.7.0.tar.gz,apr-util-1.6.1.tar.gz:http://apr.apache.org/download.cgi
zlib-1.2.11.tar.gz:http://linux.softpedia.com/get/Programming/Libraries/zlib-159.shtml
2、安装apr-1.7.0.tar.gz
$ tar -xzvf apr-1.7.0.tar.gz $ cd apr-1.7.0/ $ ./configure --prefix=/opt/svn/apr-1.7.0 如果报如下错误:
configure: error: no acceptable C compiler found in $PATH 需要安装gcc编译器,下载gcc包及依赖包:http://mirrors.aliyun.com/centos/7/os/x86_64/Packages/
mpfr-3.1.1-4.el7.x86_64.rpm libmpc-1.0.1-3.el7.x86_64.rpm kernel-headers-3.10.0-123.el7.x86_64.rpm glibc-headers-2.17-55.el7.x86_64.rpm glibc-devel-2.17-55.el7.x86_64.rpm cpp-4.8.2-16.el7.x86_64.rpm gcc-4.8.2-16.el7.x86_64.rpm 安装:
$ rpm -Uvh *.rpm --nodeps --force 然后重新安装apr
如果报错:rm: cannot remove ‘libtoolT’: No such file or directory
解决方案: configure文件,注释掉 $RM “$cfgfile” ,然后重新编译安装。
3、安装apr-util
$ tar -xvzf apr-util-1.6.1.tar.gz $ cd apr-util-1.6.1 $ .
目录
什么是SQL Server报告服务(SSRS)?
先决条件
安装SQL Server报告服务(SSRS)
配置SQL Server报告服务
结论
在本文中,我们将在Windows机器上配置Microsoft SQL Server Reporting Services。
什么是SQL Server报告服务(SSRS)? SQL Server Reporting Services(SSRS)提供了一组用于创建、部署和管理报表的本地工具和服务。您可以使用数据、表格、图形、图表和图像来设计报告。您可以轻松地在本地或远程服务器上部署报告。
先决条件 机器上安装了Microsoft SQL Server。如果您的SQL Server数据库引擎实例托管在另一台机器上,请配置命名管道和TCP/IP设置(请在此处查看我的文章)。 安装SQL Server报告服务(SSRS) 让我们在本地计算机上安装和配置SQL Server Reporting Services 。
第 1 步
让我们首先下载SSRS的安装介质。要下载兼容的安装媒体,请首先运行SQL Server安装程序。现在单击安装SQL Server Reporting Services链接,它将启动SSRS的下载页面。从该页面下载SSRS报告的安装媒体。
第 2 步
现在双击并运行下载的安装媒体。您将看到以下屏幕。单击安装报告服务按钮。
第 3 步
接下来,您将看到以下屏幕。从选择免费版本下拉菜单中选择Express或Developer版本,然后单击Next按钮。
第 4 步
在下一个屏幕上,只需接受许可条款并单击“下一步”按钮。
第 5 步
现在仅安装Reporting Services选项已被选中,因此只需单击下一步按钮。
第 6 步
选择您选择的安装位置。我将使用默认位置。单击安装按钮。
第 7 步
它将开始安装SSRS,这需要一些时间。
第 8 步
安装完成后,单击“配置报表服务器”按钮,或者如果您想稍后安装,只需单击“关闭”按钮。
算法相关数据结构总结:
序号数据结构文章1动态规划动态规划之背包问题——01背包 动态规划之背包问题——完全背包
动态规划之打家劫舍系列问题
动态规划之股票买卖系列问题
动态规划之子序列问题
算法(Java)——动态规划2数组算法分析之数组问题3链表算法分析之链表问题 算法(Java)——链表4二叉树算法分析之二叉树 算法分析之二叉树遍历
算法分析之二叉树常见问题
算法(Java)——二叉树5哈希表算法分析之哈希表
算法(Java)——HashMap、HashSet、ArrayList6字符串算法分析之字符串
算法(Java)——字符串String7栈和队列算法分析之栈和队列
算法(Java)——栈、队列、堆8贪心算法算法分析之贪心算法9回溯Java实现回溯算法入门(排列+组合+子集)
Java实现回溯算法进阶(搜索)10二分查找算法(Java)——二分法查找11双指针、滑动窗口算法(Java)——双指针
算法分析之滑动窗口类问题 算法中双指针主要包括首尾双指针(对撞双指针),快慢双指针;通过指针的移动解决问题。
数组或字符串相关的问题经常需要运用双指针来求解。而双指针又分为快慢指针和左右指针。
其中快慢指针主要用于解决链表问题,而首尾指针用于解决数组问题。
文章目录 1. 快慢双指针1)剑指offer22:链表中倒数第k个节点2)判断链表是否有环 2. 首尾双指针1)剑指offer57:和为s的两个数字2)剑指offer21:调整数组顺序使奇数位于偶数前面 3. 滑动窗口(双指针)1)剑指offer57_Ⅱ:和为s的连续正数序列 1. 快慢双指针 顾名思义,快慢指针是指一个指针走的快,一个指针走得慢。
1)剑指offer22:链表中倒数第k个节点 算法(Java)——链表中,通过快慢双指针求链表中倒数第k个节点。
题目:输入一个链表,输出该链表中倒数第k个节点。
解题思路:快慢指针,先让快指针走k步,然后两个指针同时走,当快指针到头时,慢指针就是链表倒数第k个节点。
使用双指针可以不用统计链表长度。
初始化:前指针,后指针,双指针都指向头节点head构建双指针距离:前指针先向前走k步双指针同时移动:循环,直到前指针到尾节点跳出,后指针指向倒数第k个节点返回值:返回后指针即可
算法代码: class Solution { public ListNode getKthFromEnd(ListNode head, int k) { if(head==null||k<=0) { return null; } //定义两个指针节点 ListNode pre=head; ListNode last=head; //先将一个节点往后移动k-1个距离 while(pre!=null && k>0){ pre=pre.next; k--; } //一起移动,第一个节点移动到末尾,第二个结点移动到倒数第k个节点 while(pre!=null) { pre=pre.next; last=last.next; } return last; } } 2)判断链表是否有环 思路:快指针每次走两步,慢指针每次走一步。如果链表中存在环,总有那么一个时刻快指针比慢指针多走了一圈,此时他们相遇。
2020年,基于自注意力机制的Vision Transformer将用于NLP领域的Transformer模型成功地应用到了CV领域的图像分类上,并在ImageNet数据集上得到88.55%的精度。
然而想要真正地将Transformer模型应用到整个CV领域,有两点问题需要解决。
1、超高分辨率的图像所带来的计算量问题;
2、CV领域任务繁多,如语义分割,目标检测,实力分割等密集预测型任务。而最初的Vision Transformer是不具备多尺度预测的,因此仅在分类一个任务可以很好地工作。
针对第一个问题,通过参考卷积网络的工作方式,以及窗口自注意力模型,Swin Transformer提出了一种带移动窗口的自注意力模型。通过串联窗口自注意力运算(W-MSA)以及滑动窗口自注意力运算(SW-MSA),使得Swin Transformer在获得近乎全局注意力能力的同时,又将计算量从图像大小的平方关系降为线性关系,大大地减少了运算量,提高了模型推理速度。
针对第二个问题,在每一个模块(Swin Transformer Block)中,Swin Transformer通过特征融合的方式(PatchMerging,可参考卷积网络里的池化操作)每次特征抽取之后都进行一次下采样,增加了下一次窗口注意力运算在原始图像上的感受野,从而对输入图像进行了多尺度的特征提取,使得在CV领域的其他密集预测型任务上的表现也是SOTA。
下图为paperwithcode上的截图,截止2022/1/22号,Swin Transformer在各个CV任务上依然呈现霸榜状态。在CV领域,一般在某个任务上可以提高1%就已经很了不起了,而Swin Transformer则是在各个任务上提高了2%~3%的精度。
将Swin Transformer核心
制成SwinT模块的价值
如下图所示,Swin Transformer的核心模块就是黄色部分,我们需要将这个部分制成一个通用的SwinT接口,使得更多熟悉CNN的开发者将Swin Transformer应用到CV领域的不同任务中。
这么做的价值有两点:
1、Swin Transformer自身的能力强大,这个接口将不会过时。①实现超大尺寸整张图片的全局注意力运算所需要的超级计算单元短时间内不会出现(个人开发者也很难拥有这种算力),也就是说,窗口注意力依然能持续使用一到两年;②现在一般认为,简单有效的才是最好的,而Swin Transformer的实现则非常简单,很容易让人看懂并记住其工作原理;③实践上,Swin Transformer也得到了SOTA,并且成功地获得了马尔奖,简单与强大两者加在一起才是能拿马尔奖的原因。
2、实现方便快捷的编程,例如我们要将Unet变成Swin-Unet,我们将只需要直接将Conv2D模块替换成SwinT模块即可。我们通常需要在同一个网络中,不仅使用Swin Transformer中的块,也会使用到Conv2D模块(例如Swin Transformer用在上层抽取全局特征,Conv2D用在下层抽取局部特征),因此我们要对原Swin Transformer模型进行架构上的更改。
移动窗口为什么能有全局特征抽取的能力
Swin Transformer中注意力机制是如何运行的,如下图。首先,我们对每个颜色内的窗口进行自注意力运算,如[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]每个列表内的元素做自注意力运算。
然后,滑动窗口,可以看作背景黑框在图像上滑动对图像进行的重新切分。
最后,将图像补回原来的大小,这一步是方便代码的编写,并且对窗口中原本不相邻的区域不做注意力运算。注意,窗口是由黑框决定的。也就是说,由于原图像中[4,7,10,13]相邻,因此左上角[4,7,10,13]一起做注意力运算;而[16,11,6,1]原本不相邻,因此右下角[16],[11],[6],[1]单独做注意力运算,而[16],[11]之间不做注意力运算。左下角[12,15],[2,5]各自相邻,因此[12,15]做注意力运算,[2,5]做注意力运算[12,15]和[2,5]之间不做注意力运算。
通过这两步,美妙的事情发生了,我们首先在第一步建立了[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]各自窗口之间的联系,然后在第二步建立了[4,7,10,13]之间的联系。可以观察到,通过这二步,我们得以建立[1,2,3,4,5,6,7,8,9,10,11,12]之间的联系,滑动窗口+原始窗口就如同一个高速通道在图像的左上角和右下角之间建立起了自注意力的联系,从而获得了全局感受野。
我们可以发现,滑窗和不滑窗两步是缺一不可的。只有两者同时存在,我们才能够建立全局的注意力。因此,W-MSA和SW-MSA必须作为一个整体一起使用。后续在我们的SwinT模块的源代码中,将使用W-MSA、SW-MSA和PatchMerging下采样,并将这三部分整合成一个模块。本文章的后续我们将演示这个接口如何使用,利用这个接口真实地搭建一个SwinResnet网络并对其进行性能测试!
SwinT接口的使用方式
SwinT接口的源代码可以参考:
https://aistudio.baidu.com/aistudio/projectdetail/3288357
#导入包,miziha中含有SwinT模块 import paddle import paddle.nn as nn import miziha #创建测试数据 test_data = paddle.ones([2, 96, 224, 224]) #[N, C, H, W] print(f'输入尺寸:{test_data.shape}') #创建SwinT层 ''' 参数: in_channels: 输入通道数,同卷积 out_channels: 输出通道数,同卷积 以下为SwinT独有的,类似于卷积中的核大小,步幅,填充等 input_resolution: 输入图像的尺寸大小 num_heads: 多头注意力的头数,应该设置为能被输入通道数整除的值 window_size: 做注意力运算的窗口的大小,窗口越大,运算就会越慢 qkv_bias: qkv的偏置,默认None qk_scale: qkv的尺度,注意力大小的一个归一化,默认None #Swin-V1版本 dropout: 默认None attention_dropout: 默认None droppath: 默认None downsample: 下采样,默认False,设置为True时,输出的图片大小会变为输入的一半 ''' swint1 = miziha.
解决 cannot find moudle for path 问题 问题解决方法 问题 解决方法 win+r 然后输入go env -w set GO111MODULE=auto然后重启IDEA即可
CSRF的介绍以及利用方式 一、什么是CRSF?二、利用GET请求方式的CSRF漏洞。2.1 场景介绍2.2 登陆2.3 CSRF漏洞利用2.4 CSRF漏洞触发2.5登陆管理员账号并验证 三、利用POST请求方式的CSRF漏洞。 一、什么是CRSF? 跨站请求伪造(Cross-site request forgery),也被称为 one-click attack 或者 session
riding,通常缩写为 CSRF 或者 XSRF,
是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法。跟跨网站脚本(XSS)相比,XSS利用的是用户对指定网站的信任,CSRF 利用的是网站对用户网页浏览器的信任。
跨站请求攻击,简单地说,是攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并运行一些操作(如发邮件,发消息,甚至财产操作如转账和购买商品)。
由于浏览器曾经认证过,所以被访问的网站会认为是真正的用户操作而去运行。
这利用了web中用户身份验证的一个漏洞:简单的身份验证只能保证请求发自某个用户的浏览器,却不能保证请求本身是用户自愿发出的。
从这里可以看出:
攻击者并不能通过CSRF攻击来直接获取用户的账户控制权,也不能直接窃取用户的任何信息。他们能做到的,是欺骗用户的浏览器,让其以用户的名义运行操作(也就是忽悠网站来达到目的)
这张图是我偷来滴!感觉更容易理解!
上图可以简单总结为三步:
(1)用户登陆A站,并保留登陆信息
(2)用户访问B站, B站携带A站登陆信息恶意请求A站
(3)A站无法识别请求方,当作合法请求处理,从而遭受攻击
CSRF的攻击方式分为两种:get型和post类型!
二、利用GET请求方式的CSRF漏洞。 2.1 场景介绍 我们使用两个浏览器Chrome和FireFox,有两个用户admin和smithy,模拟环境。
admin拥有最高权限,smithy为普通用户。
管理员为admin,使用Chrome登陆DVWA,并管理系统。(用户名:admin,密码:password)
我们是攻击者,使用FireFox登陆DVWA。(用户名:smithy,密码:password)
注意:我们是在Low级别攻击,两个用户的级别都需要调到Low。
目标是拿到管理员权限。
2.2 登陆 管理员在Chrome使用[admin, password]登陆。
攻击者在火狐使用[smithy, password]登陆。
攻击者发现CSRF漏洞
验证我们的账号密码正确。
我们修改密码为123456。
密码修改成功,发现修改密码请求时明文传输,后端可能没有验证操作。
我们可以使用其他账号测试能触发CSRF,保证能触发再"攻击"管理员。我们这里跳过,假定已经确定了后端没有验证,存在CSRF漏洞。
2.3 CSRF漏洞利用 CSRF利用方法很多,可以直接将地址URL编码后发送给管理员,进而触发CSRF,修改管理员密码。
我们这里利用一个存储型XSS漏洞,来触发CSRF漏洞。
在XSS(stored)注入代码:
<img src=http://127.0.0.1/dvwa-master/vulnerabilities/csrf/?password_new=123456&password_conf=123456&Change=Change#> 所有点击这个页面的用户的密码都会被修改为123456。后面需要使用"正当或不正当"途径引导管理员使用浏览器点击该页面即可。管理员的密码会自动被修改为123456。
2.4 CSRF漏洞触发 管理员点击到被注入脚本的页面。
我们打开network:
成功触发csrf漏洞
此时密码已经修改为123456
2.5登陆管理员账号并验证 三、利用POST请求方式的CSRF漏洞。 环境:espcms_V5
一、Vue 3编译报错
error Component name "Login" should always be multi-word vue/multi-word-comp error Component name "Login" should always be multi-word vue/multi-word-comp
分析:语法检查的时候把不规范的代码(即命名不规范)当成了错误
解决方案: 更改组件名(这个比较麻烦),也就是重新起个组件名,使其符合命名规范,如: StudentName 或者 student-name修改配置项,关闭语法检查
1.在项目的根目录找到(没有就创建)vue.config.js文件 const { defineConfig } = require('@vue/cli-service') module.exports = defineConfig({ transpileDependencies: true, lintOnSave:false }) 更多:
VSCode中Vue3插件使用整理_Vue3开发插件
Element-ui和Element-Plus的区别_Element2和Element3的区别 Vue3+Element Plus开发搭建_Vue3+Element3开发搭建
一:一个月的天数
问题描述 :
输入年和月,输出该月有几天。
输入说明 :
输入两个整数,中间以空格分隔,第一个整数表示年,第二个整数表示月。
输出说明 :
输出该年该月的天数,输出时,行首与行尾均无空格,仅输出一个整数。
输入范例 :
2000 2
输出范例 :
29
#include<iostream> using namespace std; int main(){ int year,month; scanf("%d%d",&year,&month); if(year%4==0&&year%100!=0||year%400==0 && month==2) printf("29\n"); else if(month==2) printf("28\n"); else if(month==1||month==3||month==5|| month==7||month==8||month==10||month==12) printf("31\n"); else printf("30\n"); return 0; } 二:银行存款到期日
银行存款有3个月、6个月定期等。从键盘输入一个日期(即为存款日期)以及定期的时间长度(单位为月,输入的时间长度可为小于等于60的任意正整数),请编程输出该定期存款的到期日期。 下面以3个月定期为例,说明定期的概念。
比如:
输入2014年4月30日,则到期日是2014年7月30日;
输入2014年3月31日,则到期日是2014年6月30日(6月没有31日,所以30日就到期);
输入2014年11月30日,则到期日是2015年2月28日;
输入2015年11月30日,则到期日是2016年2月29日。
输入说明 :
共输入4个整数,中间以空格分隔,第一个整数表示年,第二个整数表示月,第三个整数表示日,第四个整数表示定期长度(单位为月)。
输出说明 :
输出到期日期,共输出三个整数,中间以一个空格分隔,行首与行尾均无空格。
#include<stdio.h> int run(int year)//闰年判断 { if((year%4==0&&year%100!=0)||year%400==0) return 1; else return 0; } int main() { int year,month,date,regular,yearresult,monthresult,dateresult; //输入年月日期限,输出年月日 scanf("
最近几个新入职的同学说被数据库,数据集市,数据仓库整的有点懵,不太清楚它们之间的关系和区别。周末小编在买菜的过程中灵光一闪,决定从买菜这件小事来聊聊数据仓库。
当我们想做饭时首先需要考虑的就是想做的菜需要买什么材料,比如小炒肉,我们需要青椒和猪肉。早期的时候,我们需要分别去蔬菜店买青椒,去肉铺买猪肉。这个过程我们需要花费很多的时间和精力,甚至有的时候跑了一大段路却发现店里没有我想买的东西,或者我买到了青椒,却发现肉铺没有肉卖了这种尴尬的情况。后来逐渐建设了农贸市场,由每个材料供货商供货,种类齐全,并按照一定的规则摆放整齐,我们想要买什么菜按照指示牌就可以快速地定位。
我们可以把数据库比作一个个小店铺或者供货商,他们的强项在于事务处理,比如从农民伯伯手上去收购蔬菜,从屠宰厂批发猪肉等,将这些原材料汇总起来,至于怎么摆放供客户挑选,通过各种市场分析去增长销量等不是他们擅长的。数据库主要就是面向事务设计的,与ERP,CRM,OA等各类业务系统集成并完成业务过程数据的组织管理,他们解决的是基本的业务流程管理,通过数据的录入,删除,修改,查询及用户在业务系统操作界面中做的增删改查操作,和业务系统底层的数据库例如MySQL,Oracle,SQL Server完成数据的交互,数据也沉淀在这些数据库中。
那聪明的同学已经知道数据仓库其实就像“农贸市场”,把各种供货商手上的货源收集起来,按照一定的规则摆放整齐供客户挑选,同时可以通过整个农贸市场的销售经营情况进行一些细致的分析,对整个市场有更好的了解,从而促销相应的采购,销售策略等等。数据仓库是构建面向分析的集成化数据环境,为企业提供决策支持,它出于分析性报告和决策支持的目的而创建。
那什么是数据集市呢?数据集市可以比喻成各种专区,卖蔬菜农产品的,卖水产海鲜的,卖肉禽的等等。数据集市其实就是一个面向小型的部门或工作组级别的小型数据仓库,只专注于某一个方面的主题分析。
图片来源:包图网
数据仓库本身并不生产数据,数据来源于外部,并且开放给外部应用,这也是为什么叫仓库,不叫工厂的原因。例如农贸市场并不种植蔬菜、养殖各种水产禽类,而是从各供货商获取材料。数据集市可以从自己的数据源获取数据,也可以从数据仓库中获取某一主题的数据。那从供货商到农贸市场的中间过程,其实就是所谓的“ETL”过程。ETL就是extract,Transform和load,指的是清洗,转换和加载。我们都知道,供货商提供的货不是什么都要的,我们要筛选出有价值的,畅销的品种,有些坏的,不新鲜的菜在进农贸市场的过程中就需要去除掉。而不同的供货商提供的货可能也存在一些一样的种类,那么在搬运到农贸市场中就需要做一些归类合并,按照更好的一种陈列方式摆放整齐供客户挑选。这个从供货商搬运,清洗,转换,加载各种菜的过程就是ETL过程。在这个过程中,还涉及到ETL的方式和频率。比如水产海鲜,很多都是速冻空运过来的,一些需求量比较小的比如澳龙可能几天才送一次,而一些蔬菜是人们日常需要的,大都是周边蔬菜大棚产的,就会由货车每天运输进农贸市场。这些菜被运送到农贸市场后,会根据一定的规则进行摆放让客户挑选。我们可以根据不同的规则对这些菜进行管理,就像数据仓库的技术框架一样,我们可以选择一般的技术框架或者大数据技术框架,不同的选择最终决定了我们数据仓库的使用效果和投入成本。因此,数据仓库的本质还是一个数据库,它将各个异构的数据源,数据库的数据统一管理起来,并且完成了相应数据的剔除,格式转换,最终按照一种合理的建模方式来完成源数据的组织形式的转变,以更好的支持前端的可视化分析。关于数据库和数据集市,数据仓库的区别,我们简单做个总结一下:
特性数据库数据仓库数据集市出发点面向事务处理设计面向企业主题设计面向部门或工作组主题功能捕获和存储数据分析数据分析数据数据来源从单个系统会获取从多个数据源抽取和标准化一般数据仓库数据量小大中小存储内容一般是在线数据通常是历史数据通常是历史数据服务对象业务人员企业数据分析师、高层部门数据分析师、领导 那数据仓库有什么价值呢?咱们先来说一个啤酒和尿布的故事。某超市货架上将啤酒与尿布放在一起售卖,这看似不相关的两个东西,为什么会放在一起售卖呢?原来在早期的时候,该店面经理发现每周啤酒和尿布的销量都会有一次同比增长,但一直搞不清楚原因。后来商家通过对原始交易记录进行长期的详细分析后发现,很多年轻的父亲在下班后给孩子买完尿布后,大都会顺便买一点自己爱喝的啤酒。于是该商家将尿布与啤酒摆放在一起售卖,通过它们的潜在关联性,互相促进销售。“啤酒与尿布”的故事一度成为营销界的神话。从上面可以看出,数据仓库除了将各数据源抽取集成到一起为数据管理和运用提供方便外,还可以按照不同的主题,将不同种类的数据进行归类组织,从多维度、多角度挖掘出一些有价值的东西,为了企业的分析和决策提供数据依据。而一般数据库主要是面向事务处理,对数据分析性能不佳。此外,通常一个公司的业务系统会有很多,不同的业务系统往往管理部门不同,地域不同,各个数据库系统之间是相互隔离的,无法从这些不同系统的数据之间挖掘出关联关系。因此基于这些特性,数据仓库可用于人工智能、机器学习、风险控制、无人驾驶,数据化运营、精准运营,广告精准投放等场景。星环科技是国内领先的大数据基础软件公司,围绕数据的集成、存储、治理、建模、分析、挖掘和流通等数据全生命周期提供基础软件与服务,于2016年被国际知名分析机构 Gartner 选入数据仓库及数据管理分析魔力象限,位于远见者象限,在前瞻性维度上优于 Cloudera、Hortonworks 等美国主流大数据平台厂商,是Gartner 发布该魔力象限以来首个进入该魔力象限的中国公司。Transwarp ArgoDB是星环科技面向数据分析型业务场景的分布式闪存数据库产品,主要用于构建离线数据仓库、实时数据仓库、数据集市等数据分析系统。2019年8月,ArgoDB成为全球第四个通过TPC-DS基准测试并经过TPC官方审计的数据库产品。
基于星环科技ArgoDB的数据仓库解决方案,通过对数据的清洗、治理、建模、管理、分析,形成数据仓库,为业务人员和管理人员提供管理决策服务。结合星环科技事件存储库Event Store和实时流计算引擎构建实时数据仓库,可以高速接入实时消息数据(吞吐量可以达到数百万记录/秒),或者从交易型数据库实时同步数据到ArgoDB,并对数据进行实时增删改查,以及高速的数据复杂加工和统计分析。基于星环科技ArgoDB的数据仓库解决方案特性:
★多模型数据库
支持关系型、搜索、文本、对象等数据模型
★完整的SQL支持
支持完整的SQL标准语法,兼容Oracle、IBM DB2、Teradata方言,兼容Oracle和DB2的存储过程,支持业务平滑迁移
★支持超大规模集群
天然分布式架构,集群节点规模无上限,数据存储容量随节点规模线性扩容,可支持2000+节点集群
★混合负载支持
支持实时数据与混合负载,支持海量数据的离线批量处理、在线实时分析和多维度的复杂关联统计等功能
★分布式事务保障
支持完整4种事务隔离级别,保障事务在分布式系统下正常运转,高吞吐的,确保数据强一致,高可用的事务保证
典型案例
某农商行基于ArgoDB构建了新一代数据仓库,通过支持Oracle方言,极大降低了原先Oracle数据库业务数据和现有分析型业务的迁移成本。在分析型业务方面以更低成本、更高性能完整替代了传统Oracle数据仓库,确保分析型业务与交易型业务的隔离。平台满足了行内包括历史明细数据查询、交易流水查询、实时交易大屏、大额交易提醒等十多个关键查询业务场景需求。针对各类分析型业务的自动性能优化,保障了多用户高并发场景下的性能要求。结合实时流引擎Slipstream,将源数据库Oracle的增量数据以秒级延时快速同步到ArgoDB数仓,尤其确保了对源系统数据有删改的经常性调账退款业务数据能即时反映在分析系统中。平台基于实时落库的业务数据实现了多流水表多维度数据整合的交互式复杂分析能力,将原本基于Oracle的离线级分析能力提升到秒级的准实时级交互式分析能力,为行内未来多种复杂的分析型业务应用的拓展与更高的实时性要求打下坚实的技术基础。
进行前端搭建工作之前,我们先把准备好后台数据接口。
asp.net core项目创建
项目名称我们可以随意编辑一个
我们使用.net5作为目标框架,.net core3.0以后就不叫core了 叫.net5.0了
创建好项目
JWT组件管理
在刚刚创建好的项目右键点击管理NUGet程序包
我们在浏览界面 查找JWTbearer,点击安装即可,注意我们的项目是使用.net5.0那么我们jwt版本请选择5.0.14
后台项目我们就搭建好了并且将需要的组件也配置好了
将基本的中间件引入配置到项目中
打开Startup.cs文件,在Configure方法中让应用支持认证,授权,MVC这些模块
public void Configure(IApplicationBuilder app, IWebHostEnvironment env) { if (env.IsDevelopment()) { app.UseDeveloperExceptionPage(); } else { app.UseExceptionHandler("/Error"); } app.UseStaticFiles(); app.UseAuthentication(); app.UseRouting(); app.UseAuthorization(); app.UseMvc(); } (上一篇)VUE+Ant Design Vue+.Net Core搭建后台框架-(3)引入组件
192.168.8.231是kafka/zookeeper/nacos/redis
192.168.8.232是gateway:2019服务/back:9002服务
192.168.8.233是schedule:9006服务
1.修改bootstrap.yml中的nacos地址
fisher-gateway-service
fisher-back-service
fisher-schedule-service
2.修改nacos中的nacos地址
fisher-gateway-service
fisher-back-service
fisher-schedule-service
3.测试接口
http://192.168.8.232:9002/menu/selectMenuTreeByRole http://192.168.8.233:9006/publishPlan/selectInOutPortView?current=1&size=1000&shipStatus=%E8%BF%9B%E5%8F%A3&ascSort=PLAN_BERTH_TIME 4.测试通过路由跳转
http://192.168.8.232:2019/admin/menu/selectMenuTreeByRole http://192.168.8.232:2019/schedule/publishPlan/selectInOutPortView?current=1&size=1000&shipStatus=%E8%BF%9B%E5%8F%A3&ascSort=PLAN_BERTH_TIME
一、类的基本概念 1、类与对象 (1)类和对象概念 类:对某一类事物的描述,是抽象的、概念上的定义
对象:实际存在的属该类事物的具体的个体,因而也称为实例(instance)
类是对象的模板、图纸;对象是类的一个实例,是实实在在的个体。一个类可以对应多个对象。
(2)类的构成:数据成员+函数成员 数据成员:域变量、属性、成员变量等。表示类的属性。函数成员:成员方法、方法等。描述对象的行为。 二、定义类 1、类修饰符:4种 修饰符含义public将一个类声明为公共类,它可以被任何对象访问abstract将一个类声明为抽象类,没有实现方法,需要子类提供方法的实现,所以不能创建该类的实例final将一个类声明为非继承类,表示它不能被其他类继承缺省表示只有在相同包中的对象才能使用这样的类 注意:同一个Java程序内,若定义了多个类,则最多只能有一个类声明为public,这种情况下文件名称必须和声明成 public 的类的名称相同。
2、成员变量 (1)格式 [修饰符] 变量类型 变量名 [=初值];
(2)成员变量的修饰符 4种访问控制符+4种修饰符
修饰符含义public公共访问控制符。指定该变量为公共的,它可以被任何对象的方法访问private私有访问控制符。指定该变量只允许自己类的方法访问,其他任何类(包括子类)中的方法均不能访问此变量。protected保护访问控制符。指定此变量只可以被它自己的类及其子类或同一包中的其他类访问,在子类中可以覆盖此变量缺省缺省访问控制符。表示同一个包中的其他类可以访问此变量,而其他包中的类不能访问该变量final最终修饰符。指定此变量的值不能改变static静态修饰符。指定此变量被类的所有对象共享,即所有的实例都可以使用该变量transient过渡修饰符。指定该变量是一个系统保留,暂无特别作用的临时性变量volatile易失修饰符。指定该变量可以同时被几个线程控制和修改 3、成员方法 (1)成员方法修饰符 修饰符含义public公共访问控制符。指定该方法为公共的,它可以被任何对象的方法访问private私有访问控制符。指定该方法只允许自己类的方法访问,其他任何类(包括子类)中的方法均不能访问此方法。protected保护访问控制符。指定此方法只可以被它自己的类及其子类或同一包中的其他类访问缺省缺省访问控制符。表示同一个包中的其他类可以访问此成员方法,而其他包中的类不能访问该成员方法final最终修饰符。指定此方法不能被重载static静态修饰符。指定不需要实例化一个对象就可以调用的方法abstract抽象修饰符。指定该方法只声明方法头,而没有方法体,抽象方法需要在子类中被实现synchronized同步修饰符。在多线程程序中,该修饰符用于对同步资源加锁,以防止其他线程访问,运行结束后解锁native本地修饰符。指定此方法的方法体是由其他语言(如C)在程序外部编写的 4、成员变量与局部变量的区别 成员变量:属于类的变量
局部变量:属于方法的变量
(1)从语法形式上看,成员变量是属于类的,而局部变量是在方法中定义的变量或是方法的参数;成员变量可以被访问控制符(public、private、protected)、static修饰符修饰,而局部变量则不能被访问控制符与static修饰。
注:成员变量和局部变量都可以被final修饰
(2)从变量在内存中的存储方式上看,成员变量是对象的一部分,而对象是存在堆内存中,而局部变量存在于栈内存中
(3)从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而产生,随着方法调用的结束而自动消失
(4)成员变量如果没有被赋初值,则会自动以类型的默认值赋值(有一种情况例外,被final修饰但没有被static修饰的成员变量必须显示地赋值);而局部变量则不会自动赋值,必须显示地赋值后才能使用
三、对象的创建与使用 使用类创建对象,可以将对象理解为一种新型的变量。对象一旦完成了他的工作,将被销毁,所占用的资源将被系统回收以供其他对象使用。
1、创建对象 与数组创建类似
2、对象的使用 注:Java程序中有n个类,编译后产生n个.class文件
3、在类定义内调用方法 this关键字
四、参数的传递 this指定成员变量,用于区分成员变量和局部变量。
注意:当参数是基本数据类型时,则是传值方式调用;当参数是引用型的变量时,则是传址方式调用。
五、匿名对象 1、概念 当一个对象被创建之后,在调用该对象的方法时,不定义对象的引用变量,而直接调用这个对象的方法,这样的对象叫做匿名对象
2、场景 (1)一个对象只需要进行一次方法调用
(2)将匿名对象作为实参传递给一个方法调用
在res->values->styles文件中加入:
<style name="MyRadioButton" parent="Theme.AppCompat.Light"> <item name="colorControlNormal">#FF9800</item> <item name="colorControlActivated">@color/loginNormal</item> </style> 然后在RadioButton的属性中加入:
android:theme="@style/MyRadioButton" 即可
巨人网络社招前端面经 面试平台面试时长内容 面试平台 腾讯会议
面试时长 45分钟
内容 自我介绍讲一讲块作用域与函数作用域(来自简历)讲一讲你所了解的微前端(来自简历)G6图形库(来自简历)口述使用DFS查找树节点你是怎么体现你持续学习和时间管理能力的(来自个人介绍)你做过的或者你了解的前端性能优化方案如何将元素脱离文档流(上一回答中有提到)一个表格有几万条数据,渲染你可能会卡顿,你如何处理浏览器同一域名同一时间能发几个请求能说一下CDN是什么吗我很好奇简历中的“机器自动登录”(来自简历)说一下浏览器的宏任务微任务浏览器从输入url到页面展示出来所经历的事Vue双向绑定的原理Vue在列表渲染的时候中的key的作用工作过程中遇到的有挑战的问题以及怎么解决的继续聊了项目(来自上一个问题的回答)反问
本专栏包含Java SE全部内容,博主一篇篇用心码完,在博主学习Java SE的路上整理和总结的,希望会对大家有所帮助,博主还会持续输出高质量文章,您的关注是博主最大的动力🚩
博客主页>>> 努力的小鳴人
JavaSE超详总结 专栏传送门:https://blog.csdn.net/m0_64996150/category_11571308.html?spm=1001.2014.3001.5482
专栏内所有文章全部上过综合热榜,最高综合热榜第二,这篇文章是 Java SE专栏索引,方便大家查阅
【01章Java语言概述】 包含了:什么是Java?Java语言、计算机编程语言、Java技术体系平台、Java应用领域、Java语言特点、Java两种核心机制、Java虚拟机,垃圾收集机制;Java语言环境、什么是JDK,JRE?
【02章Java基本语法】 包含了:变量、运算符、数据类型转换;
程序流程控制:顺序、分支、循环、嵌套结构、break、continue关键词
【03章Java数组】 热榜第二
包含了:一维数组,默认初始化、基本数据类型、二维数组、二维数组内存分析
【附章1Java数组中常见算法】 十大排序算法,动图详细讲解:直接选择排序、堆排序、冒泡排序、快速排序、直接插入排序、折半排序,Shell排序、归并排序、桶式排序、基数排序
【04章Java面向对象编程(上)】 包含了:面向对象编程的三大特征封装性,栈,堆,方法,属性,构造器
【04章Java面向对象编程(中)】 包含了:继承性、方法重写、多态性、Object类
【04章Java面向对象编程(下)】 包含了:分析main方法、静态代码块、非静态代码块、抽象类与抽象方法、接口、内部类、匿名内部类
【附章2Java面向对象编程 this、super、final】 包含了:详解三大关键字this、super、final
【05章Java异常处理】 包含了:异常、try-catch-finally、throws、throw、自定义异常类
【附章3Java比较器】 包含了:两大排序:自然排序、定制排序
【06章多线程】 包含了:基本概念、线程的创建使用、生命周期、线程的同步和通信
【07章Java常用类】 包含了:String、日期时间API、Java比较器、System类、Math类、BigInteger与BigDecimal
【附章4包装类】 包含了:八个分类、各个作用、自动装箱与自动拆箱。包装类的缓存区
【08章Java枚举类】 包含了:枚举类、自定义枚举类、enum关键词及其自定义枚举类
【09章Java注解】 包含了:注解概述、三大常见注解、自定义注解、四个元注解
【10章Java集合】 包含了:集合框架两大体系、Collection接口、Iterator迭代器、List接口及其实现类、Set接口及其实现类、Map接口及其实现类与以上的方法脑图、Collections工具类
【深入分析Map接口】 包含了:HashMap LinkHashMap TreeMap
【深入分析 HashMap】 包含了:HashMap
【深入分析Set接口】 包含了:HashSet LinkedHashSet TreeSet
【深入分析List接口】 包含了:ArrayList LinkedList Vector
【11章Java泛型】 包含了:为什么要有泛型?集合中使用泛型、自定义泛型结构、在继承上的说明、通配符的使用
【附章5计算机字符编码】 包含了:基础知识、ASCII、ISO8859-1、GB2312、GBK、Unicode、UTF-8多种字符编码集的说明
【12章 Java IO流】 包含了:四大抽象类、输出流、输入流、File类、节点流、缓冲流、转换流、打印流、数据流、对象流、随机存取文件流
【13章网络编程】 包含了:概述、计算机网络、IP和端口号、网络协议、TCP\IP协议,TCP网络编程,三次握手与四次握手、UDP网络编程,URL编程
ts:官网地址:https://www.tslang.cn/ 首先通过 npm 全局安装 TypeScript:npm i -g typescript 全局 安装 ts命令: npm install -g typescript 使用 tsc -v 检测是否安装成功 创建ts项目过程:
1.新建一个ts文件 2.在控制终端输入tsc --init 3.点击终端然后打开配置任务 4.运行项目即可 什么是ts :ts就是 添加了 类型系统的 js ;适用于任何 规模;js的超集,他可以编译成纯javascript;typeScript可以在任何浏览器、任何计算机和任何操作系统上运行,并且是开源的。 // js ---- 解释型的 动态类型 弱类型的语言 // ts ---- 编译型的 静态类型 弱类型的语言 // ts 特点 ts 微软开发的,遵循 最新的 es5 es6 规范
ts需要 编译成 js才能够被浏览器执行
完全兼容 js, vue3 很适合 适用ts开发
还有一些其他的 框架 : react angular,像 c java 后台语言 ;适用于 很大的规模,生态系统 强大.
一、重启策略:Pod在遇到故障之后重启的动作1、always2、never3、onfailure3.1 非0状态3.2 为0状态 二、探针附:pod各种状态解释:1、Pod一直处于Pending状态2、Pod一直处于Waiting 或 ContainerCreating状态3、Pod 一直处于CrashLoopBackOff状态4、Pod处于Error状态5、Pod 处于Terminating或 Unknown状态 一、重启策略:Pod在遇到故障之后重启的动作 1:Always:当容器终止退出后,总是重启容器,默认策略
2:OnFailure:当容器异常退出(退出状态码非0)时,重启容器
3:Never:当容器终止退出,从不重启容器。
(注意:k8s中不支持重启Pod资源,只有删除重建,重建)
1、always [root@master test]# vim always.yaml apiVersion: v1 kind: Pod metadata: name: foo spec: containers: - name: busybox image: busybox args: - /bin/sh - -c - sleep 30; exit 3 [root@master test]# kubectl apply -f always.yaml 创建中
运行中
出错了
立即重启
证明重启策略默认是always,总是自动拉取
2、never [root@master test]# vim never.yaml apiVersion: v1 kind: Pod metadata: name: foo01 namespace: zy spec: containers: - name: busybox image: busybox args: - /bin/sh - -c - sleep 30; exit 3 restartPolicy: Never [root@master test]# kubectl apply -f never.
前言: 首先感谢大佬的开源代码
GitHub - fb029ed/yolov5_cpp_openvino: 用c++实现了yolov5使用openvino的部署
以及他写的原版yolov5部署代码
C++实现yolov5的OpenVINO部署_Tom Hardy的博客-CSDN博客
接下来我要在他的代码的基础上,部署yoloface四点模型代码
一、项目介绍: 在大佬原版的模型中,输出为1*3*20*20*85(其中一个detect的输出,剩下两个的20分别变为40和80。)这里85=conf(1)+xywh(4)+cls(80)
而我训练的模型,输出为1*3*20*20*30,30=conf(1)+xywh(4)+point(2*4)+cls(17)。共4个关键点,17个类。
二、灰度填充 由于我的训练模型对长宽比有着较高的要求,所以对图片预处理时,不能直接resize,而要进行灰度填充。
2.1 python源码: def letterbox(img, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True): #yoloface # Resize image to a 32-pixel-multiple rectangle https://github.com/ultralytics/yolov3/issues/232 shape = img.shape[:2] # current shape [height, width] if isinstance(new_shape, int): new_shape = (new_shape, new_shape) # Scale ratio (new / old) r = min(new_shape[0] / shape[0], new_shape[1] / shape[1]) if not scaleup: # only scale down, do not scale up (for better test mAP) r = min(r, 1.
点击上方“C语言与CPP编程”,选择“关注/置顶/星标公众号”
干货福利,第一时间送达!
大家好,我是唐唐。今天给大家分享一些经典的C++面试题。 1.new、delete、malloc、free之间的关系 malloc 和 free 都是 C/C++ 语言的标准库函数,new/delete 是 C++ 的运算符。
new 调用构造函数,delete 会调用对象的析构函数,而 free 只会释放内存。
它们都可用于申请动态内存和释放内存。但对于非内部数据类型的对象而言,光用 malloc/free 无法满足动态对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于 malloc/free 是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加给 malloc/free。因此C++语言需要一个能完成动态内存分配和初始化工作的运算符new,以及一个能完成清理与释放内存工作的运算符 delete。注意:new/delete 不是库函数。
2.delete和delete []的区别 delete 只会调用一次析构函数,而 delete[] 会调用每一个成员函数的析构函数。
在 More Effective C++ 中有更为详细的解释:“当 delete 操作符用于数组时,它为每个数组元素调用析构函数,然后调用 operator delete 来释放内存。”delete 与 new 配套,delete [] 与 new [] 配套
MemTest *mTest1=new MemTest[10]; MemTest *mTest2=new MemTest; Int *pInt1=new int [10]; Int *pInt2=new int; delete[]pInt1; //-1- delete[]pInt2; //-2- delete[]mTest1;//-3- delete[]mTest2;//-4- 在 -4- 处报错。
本人win11实机验证解决方法:在win11中安装完VC++6.0后,找到VC++6.0的安装目录X:\Program Files (x86)\Microsoft Visual Studio\Common\MSDev98\Bin\文件夹下的MSDEV.exe,将其改名为MSDEV1.exe,再给它在桌面新建一个快捷方式,右键单击此快捷方式-属性-兼容性-勾选“以兼容模式运行这个程序”,接着操作系统选择windows 7,保存关闭,双击快捷方式MSDEV1.exe即可运行。
作者:王小伙
链接:https://www.zhihu.com/question/473474907/answer/2159021187
来源:知乎
使用深度优先遍历,若从有向图上的某个顶点u出发,在 DFS(u)结束之前出现一条从顶点v到u的边,由于v在生成树上是u的子孙,则图中必定存在包含u和v的环,因此深度优先遍历可以检测一个有向图是否有环。
拓扑排序时,当某顶点不为任何边的头时才能加入序列,存在环时环中的顶点一直是某条边的头
不能加入拓扑序列。也就是说,还存在无法找到下一个可以加入拓扑序列的顶点,则说明此图存在回路。
关键路径能否判断一个图有环,则存在一些争议。关键路径本身虽然不允许有环,但求家关键路径的算法本身无法判断是否有环,判断是否有环是求关键路径拓扑排序。
所以这个问题的答案主要取决于你从哪个角度出发看问题
(ps:求最短路径是允许图有环的。)
Spring-security认证过程
1.请求会进入AuthticationFilter, AuthticationFilter的作用在于验证系统设置受限资源的过滤器。
2.第二步,跳转到UsernamePasswordAuthticationToken进行账号密码验证,如:UsernamePasswordauthtication(authtication),UsernamePasswordAuthticationToken的作用在于验证请求,生成authtication。
第三步,把authtication交给AuthticationManager管理,而AuthticationProvider是被AuthticationManager所管理的,而AuthticationProvider是用于管理认证方式的,接着会通过加密PasswordEncoder。
第四步,而AuthticationProvider是需要用户的信息以及UserDetailsService的认证实现方式的,而UserDetailsService是被UserDetail继承的,UserDetail是封装了User用户信息,所以大概流程就是:User->UserDetail->UserDetailsService
第五步,把User信息封装进AuthticationProvider,再进入AuthticationManager中的ProviderManager然后再次返回AuthnticationFilter中。
AuthticationFilter中包含了SecurityContext,而SerurityContext中又存在authntication,而此时的authntication存放着用户的信息,principal和Authorities。
目录
引用:
简述
一、环境配置
1.1 非 Spring 环境下使用 RestTemplate
注意:
1.2、Spring 环境下使用 RestTemplate
二、API 实践
2.1、GET 请求
不带参的get请求
带参的get请求(restful风格)
带参的get请求(使用占位符号传参)
2.2、POST 请求
模拟表单请求,post方法测试
模拟表单请求,post方法测试(对象接受)
模拟 JSON 请求,post 方法测试
模拟页面重定向,post请求
2.3、PUT 请求 2.4、DELETE 请求
2.5、通用请求方法 exchange 方法
2.6、excute()指定调用方式
注意:
2.6 手动指定转换器(HttpMessageConverter)
2.7 设置底层连接方式
2.8 设置拦截器(ClientHttpRequestInterceptor)
引用 引用了很多作者的内容,有一小部分是自己添加的 ,原文在这里:
真不是我吹,Spring里这款牛逼的网络工具库我估计你都没用过! Springboot — 用更优雅的方式发HTTP请求(RestTemplate详解) - 云+社区 - 腾讯云
RestTemplate - 简书
简述 RestTemplate 是一个执行HTTP请求的同步阻塞式工具类,它仅仅只是在 HTTP 客户端库(例如 JDK HttpURLConnection,Apache HttpComponents,okHttp 等)基础上,封装了更加简单易用的模板方法 API,方便程序员利用已提供的模板方法发起网络请求和处理,能很大程度上提升我们的开发效率。 是Spring用于同步client端的核心类,简化了与http服务的通信,并满足RestFul原则,程序代码可以给它提供URL,并提取结果。默认情况下,RestTemplate默认依赖jdk的HTTP连接工具。当然你也可以 通过setRequestFactory属性切换到不同的HTTP源,比如Apache HttpComponents、Netty和OkHttp。
文章目录 yolov4细节总结目的introductionRelated workObject detection modelsBags of freebies数据增强(光度畸变和几何畸变、遮挡、MixUp)focal losslabel smoothingIoU loss Bag of specials增大感受野SPPASPPRFB attention特征整合good activation function后处理方式NMS MethodologySelection of architectureSelection of BoF and BoSAdditional improvementsMosaic(数据增强)SAT(数据增强)CmBNSAMPAN YOLOv4 ExperimentsExperimental setupInfluence of different features on Classifier training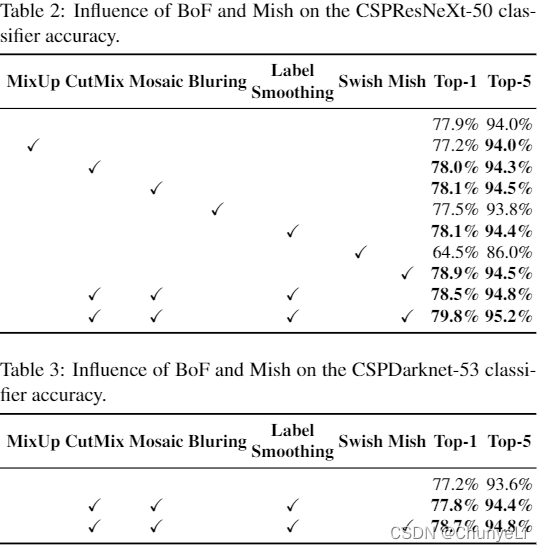Influence of different features on Detector trainingInfluence of different backbones and pretrained weightings on Detector trainingInfluence of different mini-batch size on Detector training yolov4细节总结 YOLOv4
目的 寻找CNN中的通用trick
introduction 实时(用一个GPU),训练也只用一个GPU,准确性高。
contributions
Related work Object detection models 一个检测器:
①backbone(预训练)
背景 最近项目中基于需求限制需要使用mineMap地图绘制路段,路段数据有3万+条(大概27.6M),前后端请求一次耗时38s,这么长的基础数据请求时间对任何一个项目来说都是无法接受的。基于此前后端做了以下操作以期解决这个问题:
后端清除不需要的返回字段,处理后数据大小降至18.6M,请求时间缩短至28s前端寻求浏览器存储大量数据的方案只在第一次打开页面时请求,后续均从浏览器存储中获取数据(indexDB)路段数据由基础路段和虚拟路段组成,虚拟路段可能会变化,沟通此处需求是否可以变更为只渲染不变的基础路段数据,这样方案可以变更为前端项目里直接请求本地json文件即可,不再需要请求后端 虽然最后不再采用indexDB存储,但是还是记录下vue中使用indexDB的相关代码
indexDB IndexedDB 是一种底层 API,用于在客户端存储大量的结构化数据(也包括文件/二进制大型对象(blobs))。该 API 使用索引实现对数据的高性能搜索。虽然 Web Storage 在存储较少量的数据很有用,但对于存储更大量的结构化数据来说力不从心。而 IndexedDB 提供了这种场景的解决方案。
indexDB操作步骤如下:
打开/创建数据库(如果没有就会创建)。首次创建则在数据库中创建一个对象仓库(也就是建一个表)。数据库操作(增删改查等) 代码如下 全局定义几个变量:
let indexDB let db let objectStore 数据库操作(created里):
const that this // 创建indexDB内存数据库,存储基础路段数据 indexDB = window.indexedDB.open('sectionsData') // 数据库首次创建版本,或者window.indexedDB.open传递的新版本(版本数值要比现在的高) indexDB.onupgradeneeded = function (event) { db = event.target.result if (!db.objectStoreNames.contains('sections')) { objectStore = db.createObjectStore('sections', { keyPath: 'sectionCode' })// 定义主键,相当于id objectStore.createIndex('sectionCode', 'sectionCode', { unique: true }) objectStore.createIndex('flow', 'flow', { unique: false }) objectStore.createIndex('trafficStatus', 'trafficStatus', { unique: false }) objectStore.
字典中的键值对
键和值之间用冒号分割,键值对之间用逗号分割
在添加键值对时,Python不关心键值对的添加顺序,只关心键与值之间的关联关系
在使用字典存储用户提供的数据或者在编写能自动生成大量键值对的代码时,一般要先建立空字典
使用del语句删除键值对--须指定字典名以及要删除的键,使用del的删除为永久删除
遍历字典
items()返回一个键值对的列表
user_0 = { 'username': 'efermi', 'first': 'enrico', 'last': 'fermi', } for key, value in user_0.items(): print('\nKey: ' + key) print('Value: ' + value) 此处key为键,value为值
需注意:在遍历字典时,python同样不在意键值对的存储顺序,即键值对的返回顺序有可能与存储顺序不同,python只跟踪键和值之间的关联关系
遍历字典中所有的键
favorite_languages={ 'jen':'python', 'Erica':'C', 'edward':'ruby', 'phill':'php', } for name in favorite_languages.keys(): print(name.title()) 可以使用,sorted()排序
favorite_languages={ 'jen':'python', 'Erica':'C', 'edward':'ruby', 'phill':'php', } for name in sorted(favorite_languages.keys()): print(name.title()+", thank you for taking the poll.") 遍历字典的值
使用方法value(),来返回一个值列表
集合set要求其中的每一个元素都是独一无二的,可以使用此方法来剔出重复项
favorite_languages = { 'jen': 'python', 'Erica': 'C', 'edward': 'C', 'phill': 'php', } print("
公众号:踏歌的 Java Daily
// 调用 String name = "江踏歌"; String replace = replace(name , 1, name .length(), '*'); /** * 替换指定字符串的指定区间内字符为固定字符<br> * 此方法使用{@link String#codePoints()}完成拆分替换 * * @param str 字符串 * @param startInclude 开始位置(包含) * @param endExclude 结束位置(不包含) * @param replacedChar 被替换的字符 * @return 替换后的字符串 * @since 3.2.1 */ public static String replace(CharSequence str, int startInclude, int endExclude, char replacedChar) { if (isEmpty(str)) { return str(str); } final String originalStr = str(str); int[] strCodePoints = originalStr.
为了帮助理解 DevOps 和软件交付中一些关键的概念,下面列出了必须阅读的十大 DevOps 书籍。无论新手还是老手,这里总会有一本适合你的书。
一、《凤凰项目:一个IT运维的传奇故事》 作者:Gene Kim、Kevin Behr 、 George Spafford
在其他的每一个十大必读书籍名单中,也一定能找到这本书。这本畅销书的最新扩展版中加入了合著者 Gene Kim 的一个新后记,并对 DevOps 手册中描述的三种方式进行了更深入的研究。
二、《持续交付:发布可靠软件的系统方法》 作者:Jez Humble、David Farley
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UN9hEye2-1646032819142)(/img/bVcYaOY)]
作者介绍了最先进的技术,包括自动化基础架构管理和数据迁移,以及虚拟化技术的使用。对于每一部分,他们都会指出关键问题,确定最佳方案,并说明如何降低风险。无论你是开发人员、系统管理人员、测试人员还是经理,这本书都会缩短一个团队把想法转化为技术发布所用的时间。
三、 《DevOps实践指南》 作者:Gene Kim、Jez Humble、Patrick Debois 、 John Willis
效法《凤凰项目》,《DevOps 实践指南》面向领导者,通过展示如何整合产品管理、发展、质量保证、IT 运营和信息安全这些方面来全面提升公司并在市场中取胜,从而复制这些不可思议的成果。
四、《加速:精益软件和DevOps的科学》 作者:Nicole Forsgren、Jez Humble 和 Gene Kim
读者将了解到如何考核团队绩效,以及为了提高绩效应该在哪些能力上加大投入。这本书非常适合各个级别的管理人员来阅读。
五、《DevOps实施手册:在多级IT企业中使用DevOps 》 作者:Sanjeev Sharma
DevOps 一直是过去十年中 IT 最热门的趋势之一,大量的成功案例证明了DevOps的有效性,在全球任何规模、行业或 IT 成熟度水平的组织中均适用。《DevOps 实施手册》展示了如何让你的团队参与到DevOps中去,这样就可以加快产品的生产,并通过创新做得更好。
六、 《引领转型:大规模应用敏捷和 DevOps 准则》 作者:Gary Gruver 、Tommy Mouser
《引领转型:大规模应用敏捷和 DevOps 准则》是一份面向管理人员的指南,它为改进开发和交付提供了清晰的框架。与专注于提高团队效率的传统敏捷和 DevOps 方法不同,这本有声读物的目标是协调大型组织中跨团队的工作——这种改进仅能由管理人员来完成。
七、《在企业中发起和推广DevOps》 作者 :Gary Gruver
最近,有很多人在传说 SpringBoot要出3.0的版本了,并且宣布不再支持 Java 8,最低要求是 Java 17了。
其实,早在2021年9月份,关于 Spring Framework 6.0的消息出来的时候,Spring 官方就已经明确了不会向下兼容,最低的 JDK 版本是 JDK 17。
2022年,Spring Framework 6.0和 SpringBoot 3.0都会推出,在此之前,Java社区很坚挺,一直是"新版任你发,我用Java 8",不管新版本怎么出,很少有人愿意升级。
这一次,Spring 直接来了个大招,跨过 JDK 8-16,直接升级到 JDK 17 ,不知道会对 Java生态产生怎样的影响。
为什么是 Java 17
这么多新版本的 JDK,而且2022年还会推出 JDK 18 和 JDK 19,为什么 Spring 选择了 JDK 17呢。
主要是因为他是一个 LTS版本,所谓 LTS,是 Long Term Support,也就是官方保证会长期支持的版本。
从 JDK 诞生到现在,还在长期支持的版本主要有 JDK 7、JDK 8 、JDK 11以及 JDK 17
这一次 Spring直接跨越了 JDK 11,升级到 JDK 17,主要的考虑应该是因为JDK 17有更多的新特性支持。
接下来我们介绍几个新特性,这些新特性都是我们开发者息息相关的,或者说是会影响我们写代码的。
JDK 17 支持的新特性
前端面试知识点整理——项目整理
文章目录 一、华工线上黑市(安卓)二、二手闲置商场&健身管理系统(小程序)三、birthday app(swift)四、给Joey的生日页面(移动端)五、开发者博客(vue) 一、华工线上黑市(安卓) 1.MVP架构方面 先介绍整个架构是怎样的,并与传统的mvp架构的区别
后来经过两次变革
(1)抽出了base层,包括baseactivity(定义一些通用的view接口的函数,和一些绑定样式、初始化的函数)和basepresenter(定义一些绑定和解绑view的函数)
(2)把model层进行了整合,将所有网络请求封装在一个类当中,对于上层就像在调用api获取数据一样
首先定义了一个okhttpclientutil的类,类里面封装了相应的post和get等请求,然后我们可以直接在blackmarketapi里面,在调用登录、显示商品、上传图片、获得排序等等时来调用这些封装好的请求方法,把相应的参数和回调函数传进去,非常方便的进行网络请求。
2.xml样式
他会有一些线性布局linearlayout(水平、垂直方向上线性排列)、相对布局relativelayout(随意一些)、framelayout(所有控件默认摆放在布局的左上角)、百分比布局,还有一些listview、recyclerview的滚动控件
实现两栏布局的话,可以考虑使用linearlayout布局来划分怎么排列,使用一些例如android:layout_weight=“1”,来划分剩余空间
二、二手闲置商场&健身管理系统(小程序) 1.页面的一个结构:(全局大体也差不多)
js:Page里面保存了一些数据,还有调用一些页面的生命周期函数,以及自己定义的函数
json:页面的json用来注册一些组件,定义当前页面的标题、窗口的一些其他属性
wxml:整体和html很像,但是它是经过了微信的封装,例如块级元素在小程序中是用view标签来展示,行内元素使用text标签来展示。在里面可以绑定一些事件函数,也有一些wx:if、wx:for的一些指令,还可以使用mustache语法
wxss:和css很像,经常会用单位rpx
2.微信对小程序进行了怎样的封装
3.小程序的双线程模型
渲染层:wxml和wxss运行在渲染层,渲染层使用webview线程渲染(有多个页面则用多个webview渲染)
逻辑层:js脚本运行于逻辑层,逻辑层使用jscore运行js脚本
这两个线程都会经由微信客户端(native)进行中转交互
界面渲染整体流程:
(1)在渲染层,宿主环境会把wxml转化成对应的js对象
(2)将js对象再次转成真实的dom树,交由渲染层线程渲染
(3)数据变化时,逻辑层提供最新的变化数据,通过setData方法从逻辑层传递到Native,再转发到渲染层,js对象发生变化比较进行diff算法对比
(4)将最新变化的内容反映到真实的dom树中,更新ui
虚拟 DOM 机制 virtual Dom
用JS对象模拟DOM树 -> 比较两个DOM树 -> 比较两个DOM树的差异 -> 把差异应用到真正的DOM树上
4.小程序为什么要采用双线程模型
(1)为了管控安全,不允许操作dom,不希望能够获取到用户的隐私数据
(2)限制一些api的掉用
5.小程序的组件化开发
尽可能地将页面拆分成一个个小的、可复用的组件
自定义组件的步骤:
(1)创建:在组件的json文件里面进行组件声明(“component”: true)、在wxml中编写组件模板、在wxss中编写样式、在js文件中定义数据或其他相关逻辑
(2)使用:在使用的页面的json中注册(usingComponent)、在wxml中直接使用
6.小程序的基础库
小程序的基础库是JavaScript编写的,它可以被注入到渲染层和逻辑层运行。主要用于:
在渲染层,提供各类组件来组件页面的元素
在逻辑层,提供各种API来处理各种元素。
处理数据绑定、组件系统、事件系统、通信系统等一系列框架逻辑
小程序的渲染层和逻辑层是两个线程管理,两个线程各自注入了基础库。
小程序的基础库不会打包在小程序的代码中,它会被提前内置在微信客户端。这样可以:
降低业务小程序的代码包大小
可以单独修复基础库中的Bug,无需修改到业务小程序的代码包
参考:微信小程序底层原理
7.使用了小程序云开发里面的数据库 以及 微信的代码管理来进行多人协作开发
8.小程序的生命周期
页面的生命周期
有渲染层(view thread)和逻辑层(app service)两个线程同时执行,逻辑层会加载page,并执行onload和onshow,进入阻塞,等待请求。渲染层要先进行初始化,请求一些逻辑层的数据(mustache里面的数据),准备渲染的时候也会通知逻辑层。逻辑层知道渲染层开始渲染时,会执行onready。页面渲染完成。
公众号:踏歌的 Java Daily
上代码 @Autowired private pervice perviceService; @RequestMapping(value = "/add", method = RequestMethod.POST) @ResponseBody @ApiOperation("获取信息") public OfferOrderReturn add(HttpServletRequest request, HttpServletResponse response) { try { //request获取输入流 BufferedReader reader = new BufferedReader(new InputStreamReader(request.getInputStream())); //读取输入流的内容转换为String类型IOUtils必须引入org.apache.dubbo.common.utils.IOUtils;包 String body = IOUtils.read(reader); System.out.println(body ); perviceService.index(body); } catch (Exception e) { LOG.info("*****存在问题*****"); } finally { } //如果需要返回值并且try有返回值此时只需要返回null return null; } 创作不易请多多支持,更多详情请关注wx工作号:xvguo1127
公众号:踏歌的 Java Daily
Dataway集成Spring Boot Dataway踩坑指南
文章目录 Dataway集成Spring Boot前言一、什么是Dataway二、DataWay集成Spring Boot引入依赖启用 Hasor初始化必要的表(例:MySQL)初始化数据源 加强版!!! 前言 Java早已厌烦了controller、service、dao,尤其是一些很简单的管理系统对一些单表的增删改;我也是偶然在一个项目初期进行使用,参与DataWay集成Spring Boot的全过程。
参考链接:https://www.hasor.net/doc/
以下是本篇文章正文内容,下面案例可供参考
一、什么是Dataway DataQL(Data Query Language)DataQL 是一种查询语言。旨在通过提供直观、灵活的语法来描述客户端应用程序的数据需求和交互。数据的存储根据其业务形式通常是较为简单的,并不适合直接在页面上进行展示。因此开发页面的前端工程师需要为此做大量的工作,这就是 DataQL 极力解决的问题。
二、DataWay集成Spring Boot 引入依赖 Dataway 是 Hasor 生态中的一员,使用 Dataway 第一步需要通过 hasor-spring 打通两个生态。
**注意:**这里要看Spring Boot的版本号,官方没有提供对照文档,一般用spring boot 版本2.4.1不会出什么问题。还要看一个版本冲突问题,我在做的过程中由于初始项目引入过多的依赖jar包,搞了两天才解决
<!-- 引入依赖 --> <dependency> <groupId>net.hasor</groupId> <artifactId>hasor-spring</artifactId> <version>4.2.2</version> <!-- 查看最新版本:https://mvnrepository.com/artifact/net.hasor/hasor-spring --> </dependency> <dependency> <groupId>net.hasor</groupId> <artifactId>hasor-dataway</artifactId> <version>4.2.2</version> <!-- 查看最新版本:https://mvnrepository.com/artifact/net.hasor/hasor-dataway --> </dependency> <!-- 我做的过程中引发问题的jar包 --> <dependency> <groupId>net.sourceforge.nekohtml</groupId> <artifactId>nekohtml</artifactId> </dependency> 启用 Hasor @EnableHasor() // 在Spring 中启用 Hasor @EnableHasorWeb() // 将 hasor-web 配置到 Spring 环境中,Dataway 的 UI 是通过 hasor-web 提供服务。 然后第二步,在应用的 application.
本文仅供学习清华大学出版社所出数目《Python编程300例》使用,如有侵权,请联系本人删除。 1、问题描述 反转一个只有3位数的整数 2、问题示例 输入number=123,输出321;输入number=900,输出=9。 3、代码实现 class Solution: #参数number:一个3位整数 #返回值:反转后的数字 def reverseInteger(self,number): h = int(number/100) t = int(number%100/10) z = int(number%10) return (100*z+10*t+h) class Solution2: #使用字符串反转法完成 def reverseInteger(self,str): str1 = '' str1 = str1.join(reversed(str)) if str1[0] == '0' and str1[1] != '0': str1 = str1[1:] # str1 = str1[1:2]实际使用中是左闭右开区间,实际上是截取了索引位为1的字符, # 使用str1 = str1[1:]在此实例中与str1 = str1[1:3]效果等同 elif str1[0] == '0' and str1[1] == '0': str1 = str1[2] return str1 #主函数 if __name__ == '__main__': # solution = Solution() # while True: # str_num = input("
论使用什么系统,都有用到ip地址的时候,习惯了windows系统的人很容易就能查找出系统的ip,但是在linux系统如何查看ip呢?作为Linux新手,以Ubuntu的使用经验,我知道Ubuntu查看IP有两种方式。
第一种是在终端中使用命令“ifconfig -a”,如果提示找不到“ifconfig”,根据提示安装“net-tools”,运行命令“sudo apt install net-tools”即可安装。,然后再运行命令“ifconfig -a”就可以查看网络连接信息了。但是这种方式有个缺点,正常情况下,只会有两组连接信息,你看不是“lo”的那一组就好了。如果你安装了一些会自动下载插件的软件,使用命令可能就会出现很多组网络信息,不熟悉系统的朋友可能不知道应该看那一个。
第二种方式是直接在“网络”里面查看网络连接情况。“设置->网络->有线连接”。点击“有线连接”后面的设置图标即可看见网络连接情况。根据系统右上角也是可以进入到网络里面去的,点击右上角,然后点击“有线设置”。
命令运行记录:
shenqh@shenqh-virtual-machine:~$ ifconfig -a
Command 'ifconfig' not found, but can be installed with:
sudo apt install net-tools
shenqh@shenqh-virtual-machine:~$ sudo apt install net-tools
[sudo] shenqh 的密码:
正在读取软件包列表... 完成
正在分析软件包的依赖关系树 正在读取状态信息... 完成 下列【新】软件包将被安装:
net-tools
升级了 0 个软件包,新安装了 1 个软件包,要卸载 0 个软件包,有 0 个软件包未被升级。
需要下载 194 kB 的归档。
解压缩后会消耗 803 kB 的额外空间。
获取:1 http://cn.archive.ubuntu.com/ubuntu bionic/main amd64 net-tools amd64 1.60+git20161116.90da8a0-1ubuntu1 [194 kB]
获取:1 http://cn.archive.ubuntu.com/ubuntu bionic/main amd64 net-tools amd64 1.
Namomo Spring Camp 每日一题 Week 1Day2 No Crossing Problem Statement 一个有 n n n个点 m m m条边的有向图, 你需要找到恰好经过 k k k个点的最短路径, 要求每次选的边不能越过之前已经经过的节点. 即对于路径中 x → y x\to y x→y. 不存在以前经过的点 t t t使得三者编号满足 min ( x , y ) ≤ t ≤ max ( x , y ) \min(x,y)\leq t\leq \max(x,y) min(x,y)≤t≤max(x,y).
Solution 首先我们考虑选择一条边 x → y x\to y x→y. 如果 x < y x<y x<y那么后续我们选择路径的时候不能经过点 k k k满足 k < x k<x k<x的点, 如果 x > y x>y x>y那么后续选择路径的时候不能经过点 k k k满足 k > x k>x k>x的点.
由于img.onload方法不同于其他函数,他是一个事件回调。
js是单线程的 他会先按照顺序执行主程序 当主程序执行完成后才会执行事件回调 所以在批量导出图片时onload事件总是最后执行
采用了很多办法 ,网上提供的所有解决办法我都试过了,没有能解决的。所以我将解决方法转到后端来实现,但是node.js默认是单线程,一个node.js应用无法利用多核资源,将网络图片转成base64后再利用exceljs库写到excel中单张图片就需要一秒多的时间,所以最终采用定时器来解决,最近比较忙,就不详细阐述了,代码放下面:
js代码如下:
function main(data, sign, l) { var timer = setInterval(function () { var url = data[sign].asin_img; var img = new Image(); img.src = url; img.crossOrigin = "*"; if (img.complete == true) { var base64 = getBase64Image(img); data[sign].img = base64; sign++; computedLong(sign, l) if (sign >= l) { clearInterval(timer); uploadBase(data) } } }, 100) } function getBase64Image(img) {//根据网络图片的地址将图片转为base64 nodejs exceljs库需要 如不明白为什么 可以去看一下exceljs的官方文档 var canvas = document.
Tomcat架设简单Websocket服务器
用的时候打开就行了,先不管它
Unity中新建场景
建UI(UGUI)
有一个连接按钮Button
一个信息输入框InputField
一个发送按钮Button
一个断开按钮Button
一个消息显示框Text
场景中建一个GameObject,在上面加个脚本,就叫WSMgr好了
用到了BestHTTP这个插件
using System.Collections; using System.Collections.Generic; using UnityEngine; using BestHTTP; using BestHTTP.WebSocket; using System; using BestHTTP.Examples; using UnityEngine.UI; using System.Text; public class WSMgr : MonoBehaviour { //public string url = "ws://localhost:8080/web1/websocket"; public string url = "ws://localhost:8080/web1/ws"; public InputField msg; public Text console; private WebSocket webSocket; private void Start() { init(); } private void init() { webSocket = new WebSocket(new Uri(url)); webSocket.
golang接口值类型接收者和指针类型接收者 值接受者是一个拷贝是一个副本,指针接受者传递的是指针 定义接口和结构体
type Pet interface { eat() } type Dog struct { name string } 实现接口 接受者是值类型
func (dog Dog) eat() { fmt.Printf("dog: %p\n", &dog) fmt.Println("dog eat...") dog.name = "嘿嘿" } 测试代码
dog := Dog{name: "点小花"} fmt.Printf("dog: %p\n", &dog) dog.eat() fmt.Printf("dog: %v\n", dog) 实现接口 接受者是指针类型
func (dog *Dog) eat1() { fmt.Printf("dog: %p\n", &dog) fmt.Println("dog eat...") dog.name = "嘿嘿" } 测试代码
dog := Dog{name: "花花"} fmt.Printf("dog: %p\n", &dog) dog.eat1() fmt.
概念
php静态化分为:纯静态化 和 伪静态化;
纯静态化又分为:局部静态化 和 完全静态化
纯静态化:是把PHP生成的动态页面保存成静态的html文件,用户访问该静态页面,而不是用户每一次访问都重新生成一张相同的网页,优点就是减小服务器开销,
局部静态化:是生成的静态文件中,有局部的数据还是通过ajax技术动态获取的;
完全静态化:即不存在动态获取数据的情况,所以内容都来自静态的html页面
伪静态化:Apache服务器rewrite配置
纯静态化的实现
利用php内置的ob函数实现页面的静态化,大概步骤如下:
我是要生成的静态内容,也可以在该处链接数据库生成动态内容于此
ntents( 'index.html', ob_get_clean() );//把生成的静态内容保存到index.html文件,而不是输出到浏览器 ?>
触发系统生成纯静态化页面
方法:页面添加缓存时间;手动触发
页面添加缓存时间
nce( $file_name );//引入文件 }else{ ob_start( ); ?> 我是要生成的静态内容
ntents( $file_name, ob_get_contents() )//输出到浏览器 }
如果后台数据存在更细,定时刷新不能及时更改静态页面,怎么办?所有引入了手动触发的功能
Linux下的crontab定时扫描程序
*/5****php/data/static/index.php PHP伪静态
Apache服务器rewrite配置
在httpd.conf文件中,找到
#注释:去掉前边的" # "开启rewrite服务,重启服务器生效
#LoadModule rewrite_module modules/mod_rewrite.so
#注释:http-vhosts.conf文件是虚拟域名配置的文件,开启改文件可以配置虚拟域名,一般默认是开启的
#Include conf/extra/httpd-vhosts.conf
rewrite伪静态配置
ServerAdmin webmaster@dummy-host.example.com documentRoot "c:/Apache24/docs/dummy-host.example.com" ServerName dummy-host.example.com ServerAlias www.dummy-host.example.com ErrorLog "logs/dummy-host.example.com-error.log" CustomLog "logs/dummy-host.example.com-access.log" common #配置规则如下所示 RewriteEngine on RewriteRule ^/vidio/([0-9]*).html$ /vidio.
一、前言 通过STM32F103C8T6控制单个数码管动态显示数字0-9及字母A、B、C、D、E、F。
二、概述 数码管,也称作辉光管,是一种可以显示数字和其他信息的电子设备。玻璃管中包括一个金属丝网制成的阳极的多个阴极。
(一)数码管引脚图及功能 数码管(LED Segment Displays)是由多个发光二极管封装在一起组成“8”字型的器件,引线已在内部连接完成,只需引出它们和各个笔划,公共电极。共阳极就是把所有LED的阳极连接到共同接点com,每个LED的阴极分别为a、b、c、d、e、f、g及dp(小数点);共阴极则是把所有LED的阴极连接到共同接点com,而每个LED的阳极分别为a、b、c、d、e、f、g及dp(小数点),如下图所示
(二)数码管共阴共阳的区别 按发光管的单元连接方式可分为共阳极数码管和共阴极数码管。
共阳数码管是指将所有发光二极管的阳极接到一起形成公共阳极(COM)的数码管,共阳极数码管在应用时将公共极COM接到+5V,当某一字段发光二极管的阴极为低电平时,相应字段就点亮,当某一字段的阴极为高电平时,相应字段就不亮。
共阴数码管是指将所有发光二极管的阴极接到一起形成公共阴极(COM)的数码管,共阴极数码管在应用时将公共极COM接到GND,当某一字段发光二极管的阳极为低电平时,相应字段就点亮,当某一字段的阳极为高电平时,相应字段就不亮。
(三)字型码 共阳极字型码表
共阴极字型码表
三、硬件连接 四、程序 1、初始化函数
void Digital_Tube_Pin_Init(void) { GPIO_InitTypeDef GPIO_InitStructure; //打开时钟 RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOB,ENABLE); //推挽输出 GPIO_InitStructure.GPIO_Mode = GPIO_Mode_Out_PP; GPIO_InitStructure.GPIO_Pin = GPIO_Pin_8 | GPIO_Pin_9 | GPIO_Pin_10 | GPIO_Pin_11 | GPIO_Pin_12 | GPIO_Pin_13 | GPIO_Pin_14 | GPIO_Pin_15; GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz; GPIO_Init(GPIOB,&GPIO_InitStructure); GPIO_SetBits(GPIOB, GPIO_Pin_8 | GPIO_Pin_9 | GPIO_Pin_10 | GPIO_Pin_11 | GPIO_Pin_12 | GPIO_Pin_13 | GPIO_Pin_14 | GPIO_Pin_15); } 2、显示函数
void Digital_Tube_Display(GPIO_TypeDef* GPIOx,u8 val) { uint16_t display_val = val << 8; GPIO_Write(GPIOx,display_val); } 3、主函数
市场上DC-DC高压模块和其他升压模块广泛应用于工业自动化控制等行业,电源模块是一个带负反馈的稳压系统,它的性能指标大致可以分为静态指标和动态指标。以下是俞霖科技小编对电源模块的九大主要性能指标和作用以及其应用的领域。
一、电源模块的作用和优势
电源模块是电压转换设备之一,它的主要功能是将交流电和直流电相互转换,除此之外,它还具有维护方便,设计灵活,节省成本和时间,高功率,高效率和高可靠性的优点。
在某种程度上,也可以说电源模块是一个带负反馈的稳压系统,它的性能指标大致可以分为静态指标和动态指标。以下是俞霖科技小编对电源模块的九大主要性能指标和作用以及其应用的领域。
静态指标输出电压精度
测量模块的实际输出电压与标称输出电压之间的差。
效率
在实现电源模块的电压转换和功率传输的同时,它还测量其自身的损耗。
电压调整率(源效应)
测量模块在不同输入电压下的输出电压变化。
温度漂移
当模块的环境温度不同时,测量输出电压的变化。
电流调整率(负载效应)
输出电流不同时测量模块的输出电压变化状态。
交叉调节率
仅针对2个电路或多个模块,测量模块某个电路的输出功率变化对其他电路的输出电压的影响。
输出电压波动
测量模块输出DC电压上AC电压分量的大小。
动态指示器启动超调和启动时间
测量电源模块打开时输出电压的建立过程或稳定过程的状态。
负载阶跃响应
负载阶跃变化时,模块测量输出电压的变化。测量的主要指标是超调或下降的幅度以及恢复时间的长度。
二、电源模块的应用领域
目前,市场上有各种AC-DC,DC-DC高压模块和其他升压模块,广泛应用于机械,电力,电信,通讯,仪器仪表,工业测量系统,医疗设备,工控智能化,汽车智能化,智能楼宇控制,汽车电子,安防,环保,食品,冷暖空调系统,水处理,石油开采,化工,煤矿开采,冶金,船舶,军工等领域。
三、俞霖科技DC-DC电源模块
1. DC-DC电源模块特点
效率高达 80%以上
1*2英寸标准封装
单电压输出
稳压输出
工作温度: -40℃~+85℃
阻燃封装,满足UL94-V0 要求
温度特性好
可直接焊在PCB 上
2. DC-DC电源模块技术参数
3. DC-DC电源模块简述
HRB W2~20W 系列模块电源是一种DC-DC升压变换器。该模块电源的输入电压分为:4.5~9V、9~18V、及18~36VDC标准(2:1)宽输入电压范围(宽电压输入模块电源是指输入电压可以允许在很宽的范围内变化)。输出单电压:50V、100VDC、110VDC、150VDC、200VDC、250VDC、400VDC、500VDC、600VDC、800VDC、1000VDC等,具有功率密度大,输出功率高,应用范围广等优点。
一、编译准备 1、libzip源码下载 点击下载 2、CMake 点击下载 3、编译工具VS2017 点击下载 二、CMake生成VS2017工程 1、CMake配置Configure 2、CMake生成VS工程 三、编译安装libzip二进制开发库 1、编译libzip源码 2、安装libzip二进制开发库 3、笔者预编译的二进制库 x64: 点击下载
文章目录 yolo1yolo2yolov3yolov3 spp (包括CIoU 和Focal Loss) https://github.com/WZMIAOMIAO/deep-learning-for-image-processing yolo1 xy是小网格中的,(0,1)
w,h是整个图像中的 ,(0,1)
confidence=bounding box是否含有object×预测的与gt之间的iou。
为每个目标的概率+预测的目标边界框和真实的目标边界框的重合程度。
为什么w和h要根号?
假设蓝色为预测的边界框,绿色为真实边界框。
假设目标越小 ,预测的边界框与真实边界框偏移相同的情况下 ,IOU就越大,检测效果越差。
所以应该要让小目标的偏差设的更大一些。
confidence损失的前一项是正样本(C=1)的损失计算,后者是负样本的( C=0)。
YOLOv1存在的问题:
1.因为每个cell只预测一组类别 ,所以对群体聚集的小目标检测结果较差。
2.输入尺寸变化时,检测效果较差;
3.定位不准确。(因为直接预测坐标信息)
yolo2 class大于9000
采用anchor偏移的方式,recall提升较高,map略微上升
t_0是confidence,也受到sigmoid限制。
高层和底层信息融合,为了更好提取细节信息。
每10个batch,就随机输入网络的图片尺寸(32的倍数)。
用224是为了方便对比。
yolov3 用了新的backbone,效果持平同时fps也比较高。和resnet相比,没有最大池化层,而是用了卷积。
http://blog.csdn.net/qq_37541097/article/details/81214953
yolov3 spp (包括CIoU 和Focal Loss) A^c是蓝色框,u是并集。GIoU在两者不相交时也可提供损失。
CIoU(D)是将C计算IoU时把其换成DIoU
负样本挖掘没focal loss好。
正负样本。
难易样本。
右边曲线表示:
p_t越大,就表示越容易分类。这部分就降低其权重。
越小,表示越难分类,这部分就提高其权重。
这里的α是用来平衡γ的(平衡套娃)。
前两者都是易分样本,所以权重降低比较好。
前提:数据标注要正确。
1. 动态规划算法介绍 理解动态规划 ~ 知乎好文
LeetCode简单的动态规划题:
斐波那契数爬楼梯使用最小花费爬楼梯【有点小坑】不同路径不同路径 II 【注意初始值的设置】最小路径和 LeetCode较难的动态规划题:
343. 整数拆分96. 不同的二叉搜索树 总结:
动态规划与其说是一个算法,不如说是一种方法论。
该方法论主要致力于将“合适”的问题拆分成三个子目标一一击破:
1.建立状态转移方程2.缓存并复用以往结果3.按顺序从小往大算 2. “01背包”问题 概念:有N件物品和一个最多能装重量为W 的背包。第i件物品的重量是weight[i],价值是value[i]。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。
本案例视频链接 ~ 尚硅谷
分析:
图解分析:
案例分析:
1. 假如现在只有 吉他(G) , 这时不管背包容量多大,只能放一个吉他1500(G) 2. 假如有吉他和音响, 验证公式:v[1][1] =1500 (1). i = 1, j = 1 (2). w[i] = w[1] = 1 j = 1 v[i][j]=max{v[i-1][j], v[i]+v[i-1][j-w[i]]} : v[1][1] = max {v[0][1], v[1] + v[0][1-1]} = max{0, 1500 + 0} = 1500 3.
pycharm 的Django console运行时报错:
django.core.exceptions.ImproperlyConfigured: Requested setting LOGGING_CONFIG, but settings are not configured. You must either define the environment variable DJANGO_SETTINGS_MODULE or call settings.configure() before accessing settings. 原因:
pycharm找不到settings.py文件导致的。
解决方案:
运行的时候,设置settings.py文件。
步骤:
1.依次点击File -> Setting… -> Build, Execution,Deployment -> Console -> Django Console
把starting script的内容修改为:
import sys; print('Python %s on %s' % (sys.version, sys.platform)) import os import django; print('Django %s' % django.get_version()) sys.path.extend([WORKING_DIR_AND_PYTHON_PATHS]) os.environ['DJANGO_SETTINGS_MODULE'] = 'settings' if 'setup' in dir(django): django.
Go语言中,通过在结构体内置匿名的成员来实现继承。
package main type People struct { name string age int } func (people People) speak() { println("I am a people") fmt.Printf("%T\n", people)//main.People } type Student struct { People grade int } func main() { var xiaoming Student xiaoming.name = "xiaoming" xiaoming.age = 18 xiaoming.grade = 2 xiaoming.speak() //编译期变成xiaoming.People.speak() //继承来的成员变量不能这样赋值 var xiaoming2 = Student{ //name: "xiaoming", //age : 18, grade: 22, } xiaoming2.speak() } 通过嵌入匿名的成员,不仅可以继承匿名成员的内部成员,还可以继承匿名成员的方法。需要注意的是,所有继承来的方法的接收者参数依然是那个匿名成员本身,而不是当前变量。
在Go语言中,this就是实现该方法的类型的对象。
/** * ++i 和 i++的区别 * ++i是先加1,再用 * i++是先用,用完再加1 */ public class Test { @org.junit.Test public void test01(){ int i=1; System.out.println(i++);// 结果是1 System.out.println(++i);// 结果是3 System.out.println(i);// 结果是3 } @org.junit.Test public void test02(){ int i=1; System.out.println(++i);// 结果是2 System.out.println(i++);// 结果是2 System.out.println(i);// 结果是3 } }