c++编程中,单例模式经常用到,单例模式有懒汉模式和饿汉模式两种。
懒汉模式直接采用静态变量,但是占用内存。
饿汉模式,根据需要动态生成,但是多个线程同时调用,存在线程安全问题。
下面主要总结饿汉模式中几种线程安全写法:
1.使用静态互斥量
#include<mutex>
class SingleModeSecure {
public:
~SingleModeSecure() {}
static SingleModeSecure* Instance(void)
{
static SingleModeSecure* pSingleModeSecure = nullptr;
static std::mutex sMutex;
if (!pSingleModeSecure)
{
std::lock_guard<std::mutex> lock(sMutex);
if (nullptr == pSingleModeSecure)
{
pSingleModeSecure = new SingleModeSecure();
}
}
return pSingleModeSecure;
}
protected:
private:
SingleModeSecure() { }
};
2.使用std::call_once创建单例模式
class SingleModeSecure2
{
public:
~SingleModeSecure2() {}
static SingleModeSecure2* Instance(void)
{
static SingleModeSecure2* pSingleModeSecure2 = nullptr;
static std::once_flag one_flag;
std::call_once(one_flag, []() { std::cout << "
文章目录 1.分层模型1.1OSI七层模型1.2TCP/IP四层模型 2.网络应用程序设计模式2.1C/S【client/server】2.2 B/S【browser/server】2.3协议的概念 3.协议3.1网络接口层协议-----以太网帧协议3.2网络层协议----IP协议IP协议的首部格式(IPV4)IP地址 3.3传输层协议----TCP/UDP协议TCP的三次握手【重点】TCP四次挥手【重点】 1.分层模型 1.1OSI七层模型 OSI(Open System Interconnection,开放系统互连)七层网络模型称为开放式系统互联参考模型 ,是一个逻辑上的定义,一个规范,它把网络从逻辑上分为了7层。每一层都有相关、相对应的物理设备,比如路由器,交换机。OSI 七层模型是一种框架性的设计方法 ,建立七层模型的主要目的是为解决异种网络互连时所遇到的兼容性问题,其最主要的功能使就是帮助不同类型的主机实现数据传输。它的最大优点是将服务、接口和协议这三个概念明确地区分开来,通过七个层次化的结构模型使不同的系统不同的网络之间实现可靠的通讯。 1.2TCP/IP四层模型 应用层—http,ftp,ssh
传输层----TCP/UDP协议
网络层----IP协议
网络接口层-----以太网帧协议
比如我们使用QQ向朋友发送消息:
2.网络应用程序设计模式 2.1C/S【client/server】 优点
协议选用灵活可以缓存数据 缺点
对用户安全构成威胁开发工作量大,调试困难 2.2 B/S【browser/server】 优点:跨平台
缺点:只能使用http
2.3协议的概念 规则:数据传输和数据解释的规则原始协议----->(改进、完善)------> 标准协议典型协议:TCP/UDP HTTP FTP IP ARP 3.协议 3.1网络接口层协议-----以太网帧协议 以太网帧大小必须在641518字节(不包含前导码和定界符),即包括目的地址(6B)、源地址(6B)、类型(2B)、数据、FCS(4B)在内,其中数据段大小在461500字节之间。
认识MAC地址(网卡编号)
MAC地址用来识别数据链路层中相连的节点;长度为48位, 及6个字节. 一般用16进制数字加上冒号的形式来表示(例如: 08:00:27:03:fb:19)在网卡出厂时就确定了, 不能修改. mac地址通常是唯一的(虚拟机中的mac地址不是真实的mac地址, 可能会冲突; 也有些网卡支持用户配置mac地址) 类型2字节
当类型为0800时,正常发送IP数据报
当帧类型为0806时,会发送arp数据报-,根据IP获取对方的mac地址
当帧类型为0835时,会发送parp数据报,返回自己的mac地址
arp数据报,根据IP获取对方的mac地址【比如我们从北京向上海的主机发送消息,要获取广州主机的MAC地址】
认识IP
IP协议有两个版本, IPv4(32位)和IPv6(128位)
IP地址是在IP协议中, 用来标识网络中不同主机的地址;对于IPv4来说, IP地址是一个4字节, 32位的整数;我们通常也使用 “点分十进制” 的字符串表示IP地址, 例如 192.168.0.1 ; 用点分割的每一个数字表示一个字节, 范围是 0 - 255; 3.
8.18 Django 视图 - FBV 与 CBV
FBV(function base views) 基于函数的视图,就是在视图里使用函数处理请求。
CBV(class base views) 基于类的视图,就是在视图里使用类处理请求。
FBV
基于函数的视图其实我们前面章节一直在使用,就是使用了函数来处理用户的请求,查看以下实例:
路由配置:
urls.py 文件
urlpatterns = [
path("login/", views.login),
]
views.py 文件
from django.shortcuts import render,HttpResponse
def login(request):
if request.method == "GET":
return HttpResponse("GET 方法")
if request.method == "POST":
user = request.POST.get("user")
pwd = request.POST.get("pwd")
if user == "runoob" and pwd == "123456":
return HttpResponse("POST 方法")
else:
return HttpResponse("POST 方法1")
CBV
基于类的视图,就是使用了类来处理用户的请求,不同的请求我们可以在类中使用不同方法来处理,这样大大的提高了代码的可读性。
定义的类要继承父类 View,所以需要先引入库:
一.cve-2022-22947漏洞复现 首先打卡靶机vulfocus
访问页面
然后抓包,添加如下路由及数据包然后点击发送。
然后刷新路由
刷新后,再次访问
命令被执行。
二.cve-2022-22963 漏洞复现 首先开启靶机vulfocus
访问页面,然后抓包
开启nc
发送以下payload后,发现shell被反弹
shell被反弹回来
三.CVE-2022-22965漏洞复现 开启靶机vulfocus
然后访问网页
然后发送如下payload。 然后访问,发现执行成功
常见整型基本数据类型:short,short int,unsigned short,int,long,long int,unsigned long,long long,usigned long long。
这几种数据类型的区别和基本概念:①它们所占字节数不同,输入输出时数据范围也就不同。 // ②大致分为signed和unsigned两种:1)像long,short这类,前面是默认加上了signed。unsigned意思是数据范围前面不能带符号,即最小只能取为0,而最大取值范围也有所变大。 2)signed输入输出时格式说明不同(见后文)。int和long int的区别: 一般我们可以认为long是long int的简写形式,也就是int可以被省略掉(但是在long double中,double就不可以省略),short和short int也同样,所以不需要为区别long和long int来烦恼啦~。 字节占位数据范围short216-2^15~2^15-1unsigned short2160~2^16-1int432-2^31~2^31-1unsigned int4320~2^32long4/832/64-2^31~2^31-1unsigned long4/832/640~2^32-1long long864-2^63~2^63-1unsigned long long8640~2^64-1 上表中字节,占位,数据范围,这三者是有规律的哦!
在不同系统和编译平台中,long的字节数有所变化,但是很多情况下占四个字节。上表中long的数据范围是按照四字节计算的(数太大打不下啦QAQ)。
在早期16位系统和某些早期编译平台中int所占字节数是2位,但现在大多都是32和64位系统,所以int所占字节数大部分情况下都占4字节。
格式说明 ①有符号类:整型为%d,短整型为%hd,长整型为%ld long long为%lld(c99版本) ②无符号类:整型为%u,短整型为%hu,长整型为%lu ,unsigned long long为%llu 就酱,拜拜~
目录
双指针
最长连续不重复子序列编辑
二进制中1的个数
区间和
区间合并
双指针 最长连续不重复子序列 思路:
设左右指针 j,i;用 i 遍历数组,对【j,i】范围路径数值出现次数记录若次数大于1,则将 j 向前走,直到范围中没有重复数字对每一步记录,即比较每个范围的长度,取最大值 #include<iostream> using namespace std; int a[100010],s[100010]; int main() { int n,j=0,res=0; cin>>n; for(int i=0;i<n;i++) { cin>>a[i]; s[a[i]]++; while(s[a[i]]>1) { s[a[j]]--; j++; } res=max(res,i-j+1); } cout<<res<<endl; return 0; } 二进制中1的个数 思路:
位运算(& | ~ ^ >> <<)_NO.-LL的博客-CSDN博客
利用模板
while(b) b=b&(b-1); //二进制中有多少个1就循环多少次
#include<iostream> #include<algorithm> #include<cstdio> #include<cstring> using namespace std; const int N=1e5+10; int cnt(int b) { int res=0; while(b) { b=b&(b-1); res++; } return res; } int main() { int n,b; cin>>n; for(int i=0;i<n;i++) { cin>>b; cout<<cnt(b)<<"
转载记录,以防丢失
一、在CentOS更新后,并不会自动删除旧内核。所以在启动选项中会有多个内核选项,可以手动使用以下命令删除多余的内核:(正常下,第一个选项正常启动,第二个选项急救模式启动(系统出项问题不能正常启动时使用并修复系统))
1.查看系统当前内核版本:
# uname -a
Linux localhost.localdomain 3.10.0-229.20.1.el7.x86_64 #1 SMP Tue Nov 3 19:10:07 UTC 201 GNU/Linux
2.查看系统中全部的内核RPM包:
# rpm -qa | grep kernel
kernel-3.10.0-229.14.1.el7.x86_64
kernel-3.10.0-229.el7.x86_64
abrt-addon-kerneloops-2.1.11-22.el7.centos.0.1.x86_64
kernel-tools-libs-3.10.0-229.20.1.el7.x86_64
kernel-3.10.0-229.20.1.el7.x86_64
kernel-tools-3.10.0-229.20.1.el7.x86_64
3.删除旧内核的RPM包
yum remove kernel-3.10.0-229.14.1.el7
yum remove kernel-3.10.0-229.el7
4.重启系统
# reboot
注意:不需要手动修改/boot/grub/menu.lst
二、CentOS7开机时的菜单选择时间由5秒缩短为2秒,尝试过修改:
vim /etc/default/grub
修改timeout =2
vim /boot/grub2/grub.cfg
修改centos/grub.cfg中的以下部分内容后重启CentOS7,OK!
if [ x$feature_timeout_style = xy ] ; then
set timeout_style=menu
set timeout=2
# Fallback normal timeout code in case the timeout_style feature is
目录
一、V4L2简介
二、V4L2操作流程
1.打开摄像头
2.查询设备的属性/能力/功能
3.获取摄像头支持的格式
4.设置摄像头的采集通道
5.设置/获取摄像头的采集格式和参数
6.申请帧缓冲、内存映射、入队
(1)申请帧缓冲
(2)内存映射
(3)入队
7.开启视频采集
8.读取数据、对数据进行处理
9.结束视频采集
三、应用编程
一、V4L2简介 V4L2(Video for linux two)是 Linux 内核中视频类设备的一套驱动框架,为视频类设备驱动开发和应用层提供了一套统一的接口规范。使用 V4L2 设备驱动框架注册的设备会在 Linux 系统/dev/目录下生成对应的设备节点文件,设备节点的名称通常为 videoX(X 标准一个数字编号:/dev/videox),每一个 videoX 设备文件就代表一个视频类设备。应用程序通过对 videoX 设备文件进行 I/O 操作来配置、使用设备类设备。
二、V4L2操作流程 V4L2摄像头驱动框架的访问是通过系统IO的接口 ------ ioctl函数,ioctl专用于硬件控制的系统IO的接口。
#include <sys/ioctl.h> //包含头文件
int ioctl(int fd, unsigned long request, ...);
fd: 文件描述符
request: 此参数与具体要操作的对象有关, 表示向文件描述符请求相应的操作
...: 可变参函数, 第三个参数需要根据 request 参数来决定,配合 request 来使用
返回值: 成功返回 0,失败返回-1
ioctl()是一个文件 IO 操作的杂物箱,可以处理的事情非常杂、不统一,一般用于操作特殊文件或硬件外设,可以通过 ioctl 获取外设相关信息。通过 ioctl()来完成,搭配不同的 V4L2 指令(request
PyInstaller的作用是将Python源文件(.py)打包,变成直接可运行的可执行文件。
首先需要下载安装PyInstaller库,在cmd中输入pip install PyInstaller。即可下载安装。
对源文件打包:
pyinstaller <Python 源文件文件名>
打包后,源程序所在目录将会产生dist和build两个文件夹。
build是PyInstaller存储临时文件的目录,可以安全删除。
dist存放与源程序同名的打包程序(即生成的打包文件)。
目录中其他文件是可执行文件的动态链接库。
pyinstaller -F <Python源程序文件名>
使得只生成打包文件(即独立的可执行文件),参数-F的作用。
注意:
1,文件路径不能出现英文空格和英文句号(.);
2,源文件必须是UTF-8编码,暂不支持其他编码类型。
参数功能-h,--help查看帮助--clean清理打包过程中的临时文件-D,--onedir 默认值,生成dist目录
-F,--onefile在dist文件夹中只生成独立的打包文件-i <图标文件名.ico>指定打包文件使用的图标(icon)文件 例子:
pyinstaller -F SnowView.py 只生成SnowView.exe文件
pyinstaller -i snowflake.ico -F SnowView.py 为SnowView.py文件增加一个图标,名称为snowflake.ico
一、服务端 本项目通过SpringBoot+Mybatis整合WebService,实现服务端接收客户端传入的数据并将其写入数据库等功能。
1、导入依赖 <!--CXF webService--> <dependency> <groupId>org.apache.cxf</groupId> <artifactId>cxf-spring-boot-starter-jaxws</artifactId> <version>3.2.5</version> </dependency> <dependency> <groupId>org.apache.cxf</groupId> <artifactId>cxf-rt-transports-http</artifactId> <version>3.3.6</version> </dependency> 2、建一个pojo包存放实体类User import lombok.AllArgsConstructor; import lombok.Data; @Data @AllArgsConstructor public class User { private Integer id; private String userId; private String userName; } 3、UserDao 处理数据 package cn.edu.usts.sbmpservice.dao; import cn.edu.usts.sbmpservice.pojo.User; import org.apache.ibatis.annotations.Mapper; import org.springframework.stereotype.Repository; @Mapper @Repository public interface UserDao { int addUser(User user); User queryUser(Integer id); } 4、建一个service包存放服务类 UserService package cn.edu.usts.sbmpservice.service; import cn.edu.usts.sbmpservice.pojo.User; import javax.jws.WebParam; import javax.jws.WebService; import java.
目录
前言
1. 新建项目引入依赖
2.新建工具类
3.新建测试类JavaClientDemo
(1)静态代码块获取docekrClient (2)静态代码块获取docekrClient (3) 打印镜像列表
(4) 从本地导入镜像
(5) 给镜像打上要推送的到的harbor仓库的标签
(6) 通过Dockerfile构建镜像并打标签
(7) 将镜像推送到Harbor仓库上
(8) 完整代码
结语
前言 本篇旨在通过最基础的代码实现简单的docker镜像获取、构建加载及将镜像推送到harbor仓库等基础操作。前提已经安装好了docker和harbor。
1. 新建项目引入依赖 <dependency> <groupId>com.github.docker-java</groupId> <artifactId>docker-java</artifactId> <version>3.2.8</version> </dependency> <dependency> <groupId>com.github.docker-java</groupId> <artifactId>docker-java-transport-httpclient5</artifactId> <version>3.2.8</version> </dependency> 本文引入docker-java的依赖。
2.新建工具类 新建client连接等操作的工具类DockerUtils 和 用来解压的工具类UnCompress
package com.workhard.utils; import com.alibaba.fastjson.JSON; import com.github.dockerjava.api.DockerClient; import com.github.dockerjava.api.async.ResultCallback; import com.github.dockerjava.api.command.BuildImageCmd; import com.github.dockerjava.api.command.BuildImageResultCallback; import com.github.dockerjava.api.command.LoadImageCmd; import com.github.dockerjava.api.command.TagImageCmd; import com.github.dockerjava.api.model.*; import com.github.dockerjava.core.DefaultDockerClientConfig; import com.github.dockerjava.core.DockerClientImpl; import com.github.dockerjava.httpclient5.ApacheDockerHttpClient; import com.github.dockerjava.transport.DockerHttpClient; import org.slf4j.Logger; import org.
目录 1.项目数据及源码2.GAN介绍3.设计网络并训练3.1.定义训练参数3.2.构建判别器和生成器3.3.构建模型3.4.查看mnist数据集图片3.5.进行训练 4.显示结果 1.项目数据及源码 可在github下载:
https://github.com/chenshunpeng/Handwritten-numeral-generation-based-on-GAN
2.GAN介绍 参考自:传送门
先介绍一下生成模型(Generative model)与判别模型(Discriminative mode)的概念:
生成模型:对联合概率进行建模,从统计的角度表示数据的分布情况,刻画数据是如何生成的,收敛速度快,例如朴素贝叶斯,GDA,HMM等判别模型:对条件概率 P ( Y ∣ X ) P(Y|X) P(Y∣X)进行建模,不关心数据如何生成,主要是寻找不同类别之间的最优分类面,例如LR,SVM等 判别模型在深度学习乃至机器学习领域取得了巨大成功,其本质是将样本的特征向量映射成对应的label;而生成模型由于需要大量的先验知识去对真实世界进行建模,且先验分布的选择直接影响模型的性能,因此此前人们更多关注于判别模型方法
生成式对抗网络(Generative Adversarial Networks,GAN)是蒙特利尔大学的Goodfellow Ian于2014年提出的一种生成模型, 在之后引起了业内人士的广泛关注与研究
GAN中包含了两个模型,一个是生成模型 G G G ,另一个是判别模型 D D D ,下面通过一个生成图片的例子来解释两个模型的作用:
生成模型 G G G :不断学习训练集中真实数据的概率分布,目标是将输入的随机噪声转化为可以以假乱真的图片(生成的图片与训练集中的图片越相似越好)判别模型 D D D :判断一个图片是否是真实的图片,目标是将生成模型 G G G 产生的“假”图片与训练集中的“真”图片分辨开 GAN的实现方法是让 D D D 和 G G G 进行博弈,训练过程中通过相互竞争让这两个模型同时得到增强。由于判别模型 D D D 的存在,使得 G G G 在没有大量先验知识以及先验分布的前提下也能很好的去学习逼近真实数据,并最终让模型生成的数据达到以假乱真的效果(即 D D D 无法区分 G G G 生成的图片与真实图片,从而 G G G 和 D D D 达到某种纳什均衡)
目录 1.项目数据及源码2.任务介绍3.数据预处理4.图像可视化5.建立模型6.进行训练 1.项目数据及源码 可在github下载:
https://github.com/chenshunpeng/Cat-dog-recognition-based-on-CNN
2.任务介绍 数据结构为:
big_data ├── train │ └── cat │ └── XXX.jpg(每个文件夹含若干张图像) │ └── dog │ └── XXX.jpg(每个文件夹含若干张图像) ├── val │ └── cat │ └── XXX.jpg(每个文件夹含若干张图像) │ └── dog └── ─── └── XXX.jpg(每个文件夹含若干张图像) 需要对train数据集进行训练,达到给定val数据集中的一张猫 / 狗的图片,识别其是猫还是狗
3.数据预处理 引入头文件
import torch from torch import nn from torch.utils.data import DataLoader from torchvision import datasets from torchvision.transforms import ToTensor, Lambda, Compose import matplotlib.pyplot as plt import torchvision.transforms as transforms import numpy as np 数据读取与预处理
目录 1.项目数据及源码2.任务介绍3.数据处理3.1.数据预处理3.2.可视化数据3.3.配置数据集 4.网络设计4.1.Xception简单介绍4.2.设计网络模型 5.模型评估5.1.准确率评估5.2.绘制混淆矩阵5.3.进行预测 1.项目数据及源码 可在github下载:
https://github.com/chenshunpeng/Animal-recognition-based-on-xception
2.任务介绍 数据结构为:
data ├── cat(文件夹含1000张图像) │ ├── chook(文件夹含1000张图像) │ ├── dog(文件夹含1000张图像) │ └── horse(文件夹含1000张图像) 需要把数据分成训练集train和验证集val,对train数据集进行训练,达到给定val数据集中的一张猫 / 狗的图片,识别其是猫还是狗的目的
3.数据处理 3.1.数据预处理 设置GPU环境进行训练:
import tensorflow as tf gpus = tf.config.list_physical_devices("GPU") if gpus: tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用 tf.config.set_visible_devices([gpus[0]],"GPU") # 打印显卡信息,确认GPU可用 print(gpus) 输出:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')] 导入图片数据:
import matplotlib.pyplot as plt # 支持中文 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 import os,PIL # 设置随机种子尽可能使结果可以重现 import numpy as np np.
目录 1.介绍1.1.项目数据及源码1.2.数据集介绍1.3.任务介绍1.4.ResNet网络介绍 2.数据预处理3.展示数据4.进行迁移学习4.1.训练全连接层4.2.训练所有层 5.测试网络效果5.1.测试数据预处理5.2.结果可视化 1.介绍 1.1.项目数据及源码 可在github下载:
https://github.com/chenshunpeng/Flower-recognition-model-based-on-pytorch
1.2.数据集介绍 flower_data ├── train │ └── 1-102(102个文件夹,共264 MB) │ └── XXX.jpg(每个文件夹含若干张图像) ├── valid │ └── 1-102(102个文件夹,共32.8 MB) └── ─── └── XXX.jpg(每个文件夹含若干张图像) cat_to_name.json:每一类花朵的"名称-编号"对应关系 1.3.任务介绍 实现102种花朵的分类任务,即通过训练train数据集后,从valid数据集中选取某一花朵图像,能准确判别其属于哪一类花朵
1.4.ResNet网络介绍 参考文章:Pytorch Note31 深度残差网络 ResNet
在ResNet网络中有如下两个亮点:
提出residual结构(残差结构),并搭建超深的网络结构(突破1000层)使用Batch Normalization加速训练(丢弃dropout) 在ResNet网络提出之前,传统的卷积神经网络都是通过将一系列卷积层与下采样层进行堆叠得到的。但是当堆叠到一定网络深度时,就会出现两个问题:
梯度消失或梯度爆炸退化问题(degradation problem) 这是在ImageNet数据集中更深的残差网络的模型,这里面给出了残差结构给出了主分支上卷积核的大小与卷积核个数,表中的xN表示将该残差结构重复N次:
对于我们ResNet18/34/50/101/152,表中conv3_x, conv4_x, conv5_x所对应的一系列残差结构的第一层残差结构都是虚线残差结构。因为这一系列残差结构的第一层都有调整输入特征矩阵shape的使命(将特征矩阵的高和宽缩减为原来的一半,将深度channel调整成下一层残差结构所需要的channel)
ResNet-50:我们用3层瓶颈块替换34层网络中的每一个2层块,得到了一个50层ResNe。我们使用1x1卷积核来增加维度。该模型有38亿FLOPResNet-101/152:我们通过使用更多的3层瓶颈块来构建101层和152层ResNets。值得注意的是,尽管深度显著增加,但152层ResNet(113亿FLOP)仍然比VGG-16/19网络(153/196亿FLOP)具有更低的复杂度 2.数据预处理 引入头文件:
import os import matplotlib.pyplot as plt %matplotlib inline import numpy as np import torch from torch import nn import torch.
@[TOC]一键清理系统垃圾文件
bat @echo off
echo CLEAR…
COLOR 17
cd
C:
del /f /s /q %systemdrive%*.tmp
del /f /s /q %systemdrive%*._mp
del /f /s /q %systemdrive%*.log
del /f /s /q %systemdrive%*.gid
del /f /s /q %systemdrive%*.chk
del /f /s /q %systemdrive%*.old
del /f /s /q %systemdrive%\recycled*.*
del /f /s /q %windir%*.bak
del /f /s /q %windir%\prefetch*.*
rd /s /q %windir%\temp & md %windir%\temp
del /f /q %userprofile%\cookies*.*
del /f /q %userprofile%\recent*.
一、如何使用终端操作数据库 点击查看
二、如何使用可视化工具操作数据库 1、可视化数据库操作工具: NavicatSQLyog 新建数据库时:
表名:自拟
引擎选:InnoDB
字符集选:utf8
排序规则选:utf8_general_ci
2、数据库的字段属性(重点) unsigned:
无符号的整数声明了该列不能声明为负数 zerofill:
0填充不足的位数,使用0来填充,int(3): 5—005 自增:
通常理解为自增,自动在上一条记录的基础上+1(默认)通常用来设计唯一的主键 index,必须时整数类型可以自定义设计主键自增的起始值和步长 ==非空:==not null
假设设置为not null,如果不给他赋值,就会报错!NULL,如果不填写,默认就是null 默认:
设置默认的值gender,默认值为 男,如果不指定该列的值,则会有默认值! 拓展:
/*每个表,都必须存在以下五个字段!表示一个记录存在意义! id 主键 'version' 乐观锁 is_delete 伪删除 gmt_creat 创建时间 gmt_update 修改时间 */ 可视化工具中使用命令行建表:
-- 创建表格注意点:使用英文(),表的名称 和 字段 尽量使用'' 括起来 -- 字符串使用单引号括起来! -- 所有的语句后面加 ,(英文符号) 最后一个字段不用加 -- PRIMARY KEY 主键,一般一个表只有一个唯一的主键 CREATE TABLE IF NOT EXISTS 'student'( 'id' INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号', 'name' VARCHAR(25) NOT NULL DEFAULT '匿名' COMMENT '姓名' )ENGINE=InnoDB DEFAULT CHARSET=utf8; 格式:[ ]内表示可选
S9-分支限界 前言9.1.1 LC-检索LC-检索的特殊情况 9.1.1 15-谜问题定理9.115-谜问题的求解方法 9.1.1 LC-检索的抽象化控制算法9.1 LC-检索 9.1.1 LC-检索的特性定理9.2改进算法LC改进算法与LC算法不同之处 算法9.2 改进LC算法定理9.3 LC-检索的总结分支限界与回溯的比较分支限界法解决问题带有限期的作业排序问题FIFOBB处理带有期限的作业问题LIFOBB处理带有期限的作业问题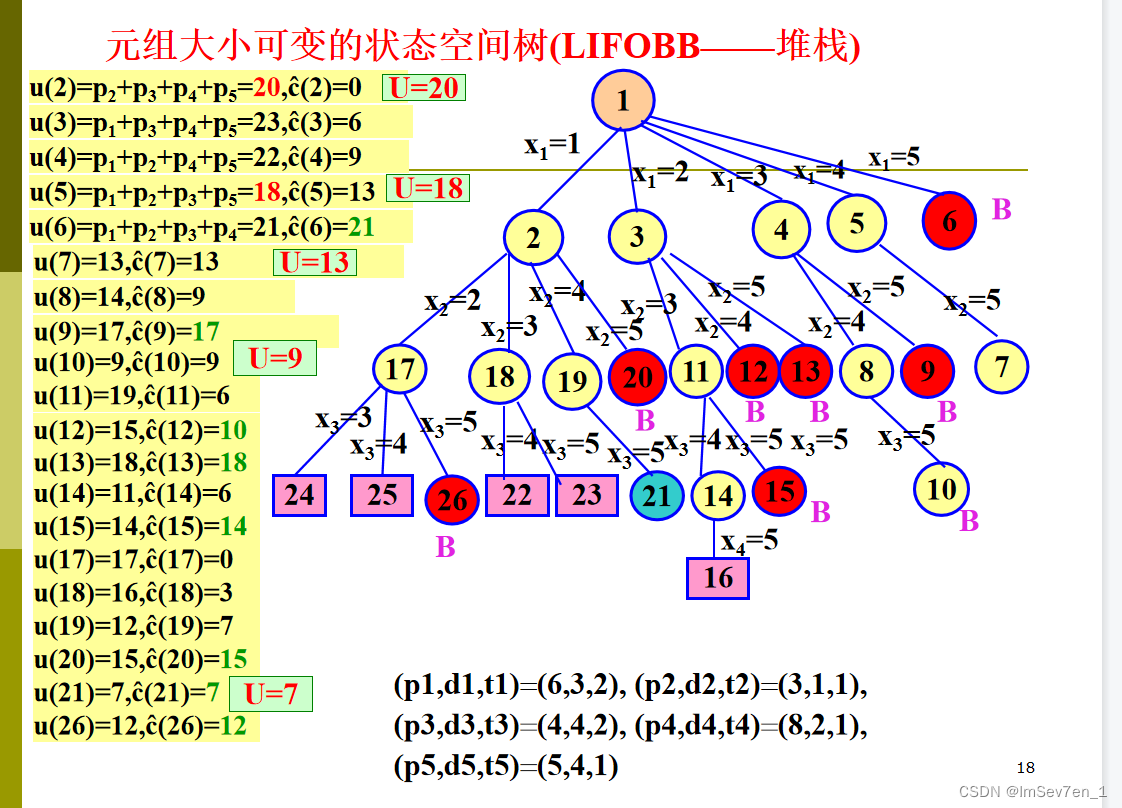LCBB处理带有期限的作业问题 9.1.6效率分析定理9.4定理9.5定理9.6定理9.7 前言 分支限界法与回溯法类似,都是在解空间树中寻找问题解的算法。
两者本质区别在于搜索策略即结点生成次序不同:
回溯:当前E-结点生成任一个儿子结点后,该儿子结点立即成为新的E结点,深度优先次序。分支限界:当前E-结点生成所有儿子结点后,再生成其他活结点的儿子结点且借助限界函数避免生成不包含答案结点子树的状态空间,广度优先(FIFO 队列实现)、D-检索(LIFO 堆栈实现)、LC-检索。
分支限界法搜索答案节点步骤: 9.1.1 LC-检索 定义:用成本估计函数来选择下一个E结点的检索策略。
LC检索的提出:
成本函数c(X):
得到成本函数常常是比较困难的,所以采用估计函数g(X)来代替成本函数。
估计函数g(X):
用来估计由X到达一个答案节点所需要的成本。
而仅考虑估计函数g(X)则会导致检索偏向于纵向检索,因此不仅考虑结点X到一个答案结点的估计成本值ĝ(X),还应考虑由根结点到结点X的成本h(X)
即:ĉ(X)=f(h(X))+ĝ(X)其中,f(.)是一个非降函数,不妨将f的作用理解为调整h和ĝ在成本估计函数ĉ中的影响比例。使f(.)不等于0,可以减少算法作偏向于纵深检查的可能性,使算法优先检索更靠近答案结点且又离根较近的结点。
LC-检索的特殊情况 9.1.1 15-谜问题 定理9.1 判断15-谜问题能否由初始状态到达目标状态:
其中 LESS(X)和X的取值如下:
15-谜问题的求解方法 空白牌的移动顺序依次为:上、右、下、左
法1:FIFO检索
法2:深度优先检索
法3:LC检索
9.1.1 LC-检索的抽象化控制 c(.)、c(X)、c(T)
LC算法搜索一个答案结点,具体步骤:
算法9.1 LC-检索 9.1.1 LC-检索的特性 定理9.2 理论上如何使得算法LC在到达一个最小成本的答案结点终止:
证明:
改进算法LC 上述的成本函数常常难以得到。
改进算法与LC算法不同之处 算法9.2 改进LC算法 定理9.3 证明:
LC-检索的总结 分支限界与回溯的比较 分支限界法解决问题 带有限期的作业排序问题 问题描述:
使用分支限界法,分别借助成本的估计函数ĉ (.)为c(X)的下界,同时设置最小成本的上界U(当前找到的最小成本),把ĉ(X) >U活结点杀死
什么是单点登录 单点登录(Single Sign On),简称为 SSO,在分布式架构项目中,只需要在一个节点进行登录验证,就能够在其它的所有相关节点实现访问。
实现方案:
JWT+Gateway方案
OAuth2方案
共享session
这里我们实现一下第一种方案:
1.用户发送请求给网关,在网关当中设置的有登录白名单,白名单放行
2.放行后去访问用户服务,进行密码校验,如果密码正确进入登录成功处理器,生成token
3.返回token给前台,保存到localstorage中
4.然后再次发送请求并携带token进入网关,在网关对token进行验证,验证成功之后放心,失败返回错误信息给前台
具体实现: 网关配置:
spring: cloud: gateway: routes: # 路由 - id: order-service-route uri: lb://order-service # 服务名称 predicates: # 断言 - Path=/order/**,/orders/** # 匹配路径 - id: product-service-route uri: lb://product-service predicates: - Path=/product/**,/products/** - id: user-service-route uri: lb://user-service predicates: - Path=/user/**,/login/**,/logout/** globalcors: cors-configurations: # 跨域配置 '[/**]': # 匹配所有路径 allowed-origins: # 允许的域名 - "http://localhost:8080" allowed-headers: "*" # 允许的请求头 allowed-methods: "
如何驱动直流电机H桥驱动 直流减速电机驱动设计MOS管控制直流H桥电路分析正反转正转反转损坏原因分析刹车调速 单片机引脚驱动?那上桥臂可不可以跟下桥臂一样呢?最终得出结论 电路设计 直流减速电机驱动设计 MOS管控制直流 我们知道单个MOS管可以控制直流电机的启动与停止,但是不能控制直流电机的正反转状态。如果要实现正反转,就需要用到H桥。
有两个MOS管组成的称为一个半桥。在上面的上桥臂也叫上管,在下面就下桥臂也叫下管。
两个半桥组成一个完整的H桥。
我们看看H桥的拓扑结构,中间连接的负载也就是直流电机。
假设我们在4个MOS管连接上MCU的引脚就可以控制4个MOS管来控制电流的流通状态,最终我们可以实现直流电机的正反转以及调速和刹车。
H桥电路分析 正反转 正转 假设要4个管通用不同的电流会有什么变化,我们来看看。
Q1导通,Q4导通。很明显,直流电机流过了电流。现在以为以他为正转。
反转 而Q1截止Q4截止 Q3导通。 Q2导通。直流电机就是反转。
损坏 当一个半桥。 Q1跟Q2导通很明显,电源VCC直接到GND地很明显是在短路状态。很容易烧坏MOS管。
上下桥同时导通的原因有:(1)MOS管的自带延时通断 (2)单片机的逻辑控制错误。
例如:
电机现在是正转,突然来一个反转信号而导致MOS管的开关时间没有迅速关断状态。最终导致一个半桥的导通。最终短路损坏MOS管
原因分析 电机正好从正转切到反转时Q1的下降沿正好对准Q2的上升沿,由于MOS管的通道,实际的边缘可能会有不同程度的滞后,这就导致某一时刻上下两MOS管的控制电压,同时为高电平时从而导致上管和下管导通。
为了让避免上下MOS管的道通需要加入死区。所谓的死区就是在上下两路控制信号的上升和下降沿之间,插入一小段头为低电平的区间,大约几百纳秒,从而避免上下两管的同时导通。
现在的MCU都有控制死区的组件。比如有stm32,还有STC等单片机。
如STC8H手册中的死区寄存器,详细的可以下载看看,里面包括有控制电机的代码和原理图
刹车 我们知道线圈有一个很大的特点。当电流减少时它会阻碍该电流的减弱。我们就是利用续流回路的特性。
可以使用直流电机将两个导线短接可以明显感觉到有一定的阻力。
当Q1跟Q3导通。 Q2跟Q4截止。也就是说上两个管的上桥臂导通。起到刹车作用。也或者也可以Q1跟Q3的截止Q2跟Q4倒通也起到同样的作用。直流电机会刹车。
调速 当上桥臂Q1输入信号为PWM模式,Q4为导通状态。那么经过pwm的占空比。直流电机的速度随之变化。占空比越大,速度就越快,占空比越少速度就越慢。当然也可以为。 Q4为输入PWM Q1导通。
单片机引脚驱动? 单片机能否直接驱动NMOS和PMOS管吗?当中还需要什么条件来驱动MOS?
关键参数:
VGSTH
RDSON对应的VGS电压 :栅极开启电压
图片
假如下桥使用的是si2302MOS管。
从数据手册中可以看到Vgs导通电压。为0.5~1.5伏。但是要注意这是最低的开启电压。
让MOS管完全导通的电压为以下图所示。
从上面截图可以看出VGS=4.5伏V时,内阻为65mΩ;当VGS=2.5时,内阻为80mΩ。结论是单片机可以直接驱动下桥臂,前提是相对应的电压要符合要求。
那上桥臂可不可以跟下桥臂一样呢? 在9V电源电压下,Q1跟Q4的MOS管道通,Q1的MOS S极连接电机端点处就有9V电压,由此VGS=3.3-9V=-5.7V 结果是VGS<0 不符合MOS管开启条件,也就是说MOS管开了一瞬间就马上关闭了。所以上桥臂使用N沟道的MOS管是无法使用单片机来控制的。要用到附加器件自举升压电路辅助。
既然上桥无法使用NMOS管来开启那么使用PMOS管会这么呢?
导通条件VGS<0 VG<VS
断开条件VGS>0 VG>VS
上桥使用的是si2301MOS管。手册数据如下
可以看到使用si2301MOS管。它的VGS为-2.5V。
最终我们使单片机输出0V。可以让PMOS导通。Vs=9V, VGS=-9V 导通
但是想要关闭就行不通了。可以看到栅极开启电压VGS为-04.~-1.5V 让其关断应 VGS>-1.
目录 一、M25P16二、源码2.1 顶层模块2.2 按键模块2.3 SPI 模块2.4 数码管模块 三、仿真模块四、管脚配置五、验证结果 本文内容:基于 SPI 协议控制开发板上的 FLASH 进行数据读写操作
一、M25P16 查看开发板原理图,可以知道 FLASH 使用的是 M25P16 芯片,存储总容量 16 Mbit,采用串行方式传输数据
找一篇 M25P16 的手册,参照手册上面进行编程
芯片对应的管脚,其中 W(写保护)、HOLD(保持)用不着,可以忽略掉,其它的管脚后面会讲
根据 CPOL 和 CPHA 的取值不同,共有四种 SPI 传输模式,这里用的模式 3,也就是时钟 C 空闲状态高电平,在时钟 C 的上升沿对 D / Q 进行数据采样
存储容量,共 32 个扇区,每个扇区 256 页,每页 256 个字节
这里只需要用到 WREN、READ、PP、SE 指令即可,进行基本的读写操作,其它指令可以自行拓展
写指令,片选 S 拉低,表示数据传输阶段,拉高表示空闲状态,C 表示系统时钟,D 表示主机发送数据,FLASH 接收数据,Q 表示 FLASH 发送数据,主机接收数据写指令只需要发送一个 8’h06 给 FLASH 即可,FLASH 会在时钟的上升沿进行采样
SE 指令(扇区擦除),发送一个 8’hd8 然后跟上 3byte 的地址,指定一个扇区进行擦除,即使指定了页地址或者字地址,它只认扇区地址,因为扇区擦除嘛,擦除的是一个扇区,也就是将一个扇区的数据变为 8’hff注意!!发送 SE 指令之前,必须先发送一个 WREN 指令,然后片选 S 拉高至少 100ns ,然后再拉低片选 S ,再发送 SE 指令,SE 与 3 byte 地址之间不需要拉低 100ns,发送完后,S 拉高,需要给 FLASH 1s 左右的时间让它进行扇区擦除
JAVA 操作redis工具类,拿来即用
/** * @author L_DY * @version 1.0 * @description * @date 2020-09-17 10:19:10 */ @Service public class JedisServiceUtil { @Autowired private JedisPool jedisPool; @Autowired private RedisTemplate<String, Object> redisTemplate; /** * 存入缓存,如果不设置过期时间,则key相同的值会被覆盖 * @author L_DY * @date 10:25 2020/9/17 * @params key * @params value * @return boolean **/ public boolean set(String key, String value){ Jedis jedis = jedisPool.getResource(); String result = jedis.set(key, value); jedis.close(); return "OK".equals(result); } public boolean setFloor(String key, String value){ Jedis jedis = jedisPool.
文章目录 一.boost/process库介绍二.实现子进程的创建及管理2.1 主进程程序2.1.1 main.cpp2.1.2 processhelper.hpp2.1.3 processhelper.cpp2.1.4 编译 2.2 子进程程序2.3 文件目录2.3 执行 三.在子进程中kill父进程2.2.1 mian.cpp2.2.2 subprocess.cpp2.2.3 编译 & 执行: 四.总结 一.boost/process库介绍 什么是boost::process:一个进程管理模块,可以启动、等待、终止子进程,和子进程通信。
Boost.Process提供了一个灵活的C++ 进程管理框架。它允许C++ developer可以像Java和.Net程序developer那样管理进程。它还提供了管理当前执行进程上下文、创建子进程、用C++ 流和异步I/O进行通信的能力。该库以完全透明的方式将所有进程管理的抽象细节呈现给使用者,且该库是跨平台的。
例程:
#include <boost/process.hpp> #include <string> #include <iostream> using namespace boost::process; int main() { ipstream pipe_stream; // 创建管道流 // 执行gcc --version,并将该子进程的stdout重定向到前面创建的管道 // std_out是boost::process定义的一个标签,使用形如 std_out>ipstream的语句表示重定向子进程stdout // boost::process是平台无关的,因此这只是一个标签,真正的重定向流程发生在底层逻辑 child c("gcc --version", std_out > pipe_stream); std::string line; // 不断地从管道中读取子进程的输出,并通过父进程(也就是自己)的stderr输出 // ~~又是个不用花括号的败家子~~ while (pipe_stream && std::getline(pipe_stream, line) && !line.empty()) std::cerr << line << std::endl; // 等待子进程退出,类似std::thread::join() c.
将一个数组中的值按逆序重新存放。 例如,原来顺序为8,6,5,4,1,要求改为1,4,5,6,8.
代码如下:
#include<stdio.h> int main() { int a[5]={0},i,j; for(i=0;i<5;i++){ scanf("%d",&a[i]); } for(j=4;j>=0;j--){ printf("%d ",a[j]); } return 0; }
今天学习scrapy爬虫,运行时出现出现报错:NotImplementedError: XXXXSpider.parse callback is not defined
上论坛翻了一下,答案集中在父类继承的问题上,但我不懂父类继承要怎么修改,翻看评论区,发现有人跟我一样,幸好楼下就有解答,特地把修改父类继承的答案抄来,记录一下,方便以后查找
在xxx.py文件下,导入模块新增导入代码:
from scrapy.spiders import CrawlSpider 然后修改class模块,这里放出修改后导入模块和class模块附近的代码段:
import scrapy from scrapy.spiders import CrawlSpider class XXXSpider(CrawlSpider): 在修改完之后,报错消失了,但我在scrapy运行无误的情况下并没有爬到数据,努力破解中。
目录 一、源码1.1 顶层模块1.2 按键模块1.3 IIC模块1.4 数码管模块 二、仿真文件三、管脚配置文件四、验证结果 本文内容:FPGA 作为主机,控制 EEPROM 芯片,进行数据读写,同时将写入或读出的数据和地址显示在数码管上,并有标记
前一篇文章:基于 FPGA 使用 Verilog 实现 IIC(I2C) 协议回环数据传输 的 FPGA 作为从机,PC 作为主机,所以 FPGA 是以从机的形式写的源码本篇文章,是以 FPGA 作为主机,控制 EEPROM 芯片数据读写,区别也不是很大,协议也完全相同,原理就不介绍了,直接上源代码 一、源码 1.1 顶层模块 IIC_top.v
/*========================================*\ filename : IIC_top.v description : IIC顶层模块 up file : reversion : v1.0 : 2022-8-22 16:15:32 author : 张某某 \*========================================*/ module IIC_top ( input clk , input rst_n , input [ 1:0] key_in , inout SDA , output SCL , output [ 5:0] SEL , output [ 7:0] DIG ); // Parameter definition wire [ 1:0] press ; wire SDA_in ; wire SDA_out ; wire SDA_oe ; wire [ 7:0] data ; wire [ 7:0] address ; wire [ 1:0] eeprom_state ; // Signal definition // Module calls key_filter U_key_filter( /*input */ .
表单非空验证基本上项目里必有的功能。element组件提供了非常方便的方法来进行非空验证。
从表单新增到表单编辑是没有问题的,但是如果第一次进入页面是先点的编辑表单,然后再去新增表单,这时候就会出现一个问题,打开新增表单时自动触发了非空验证,即还没有填写数据也没有进行接口请求,就已经验证了。而且一般是下拉选或单选、多选等表单项。
解决方法:
因为表单一般是放在`dialog`弹窗里的,我们可以在`watch`监听弹窗的`visible`属性。弹窗打开时先移除验证,`this.$refs.form.clearValidate()`
watch: { 'dialogInfo.dialogVisible'(visible) { if (visible) { // 弹窗打开时先移除验证(止第一次进入先点编辑再点新增,会自动触发非空验证) this.$nextTick(() => { this.$refs.form.clearValidate() }) } } },
一、qps是什么 QPS
QPS即每秒查询率,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
每秒查询率
因特网上,经常用每秒查询率来衡量域名系统服务器的机器的性能,即为QPS。
对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
计算关系:
QPS = 并发量 / 平均响应时间
并发量 = QPS * 平均响应时间
二、 TPS是什么 TPS:Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。TPS包括一条消息入和一条消息出,加上一次用户数据库访问。(业务TPS = CAPS × 每个呼叫平均TPS)
TPS是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值。
例如:天猫双十一,一秒完成多少订单
三、QPS与TPS的区别是什么呢? 举个栗子:假如一个大胃王一秒能吃10个包子,一个女孩子0.1秒能吃1个包子,那么他们是不是一样的呢?答案是否定的,因为这个女孩子不可能在一秒钟吃下10个包子,她可能要吃很久。这个时候这个大胃王就相当于TPS,而这个女孩子则是QPS。虽然很相似,但其实是不同的。
四、如何提高单机qps 1、机器本身
1.1、cpu
1.2、内存
1.3、IO
1.4、网络
2、程序代码
3、逻辑架构
五、机器本身 分析的整体方法是由浅入深、层层深入,先看服务器本身的指标有没有遇到短板,这个层面的分析也是相对最容易的,在配置层面(ulimit相关例如fd等)检查没有问题后,从下面四个方面进行分析。
1、cpu
cpu粗面上看有两个指标,当前使用率和负载,使用率反应的是当前cpu使用的情况,而负载反应的是cpu任务的队列情况,也就是说任务排队情况。一般cpu使用率在70%以下,负载在0.7*核心数以下,cpu的指标就算正常。
也有例外情况得分析cpu的详细指标,在运维小米消息系统的一个模块时,服务器用的是阿里云的ecs,整体cpu利用率不到30%,但业务就是跑不上量,和肖坤同学查后发现cpu0的软中断极高,单核经常打到100%,继续查后发现网络中断都在cpu0上无法自动负载,和阿里云工程师确认后是所在机型不支持网卡多队列造成的,最终定位cpu的单核瓶颈造成了业务整体瓶颈,如下图:
cpu用满的解决办法简单粗暴,在程序无bug的前提下,换机型加机器,cpu本身没单独加过。
2、内存
内存常规看的是使用率。这个在做cdn的小文件缓存时遇到过,当时用的是ats,发现程序经常重启,业务跟着抖动,查日志后发现系统OOM了,当内存快要被占满的时候,kernel直接把ats的进程给杀掉,然后报out of socket memory,留的截图如下:
同样,在应用层没有优化空间时,那就加内存吧!!
3、IO
IO主要指硬盘,一般用iostat -kdx 1看各种指标,当 %util超过50%,且偶发到100%,这说明磁盘肯定是到瓶颈了。
要进一步查看是否由于IO问题造成了系统堵塞可以用vmstat 1 查看,下图b对应因IO而block的进程数量。
这个在新浪做图片业务时遇到过,是一个源站的裁图业务,设计上为了避免重复裁图,在本地硬盘上存了一份近7天的数据,由于用python写的,没有像JVM那种内存管理机制,所有的IO都在硬盘上。有一天业务突然挂了,和开发查了2个多小时未果,中间调整了各种参数,紧急扩容了两台机器依然不起作用,服务的IO高我们是知道的,查看IO数据和历史差不多,就没往那方面深考虑,后邀请经验颇多的徐焱同学参与排查,当机立断将IO处理逻辑由硬盘迁到内存上,IO立马下来了,服务恢复。
IO问题也得综合的解决,一般从程序逻辑到服务器都要改造,程序上把重IO的逻辑放在内存,服务器上加SSD吧。
4、网络
网络主要是看出、入口流量,要做好监控,当网卡流量跑平了,那么业务就出问题了。
同样在运维图片业务时遇到过网卡跑满的情况,是一个图片(小文件)的源站业务,突然就开始各种5XX告警,查后5XX并无规律,继而查网卡发现出口流量跑满了,继续分析,虽然网卡是千兆的,但按理就cdn的几个二级回源点回源,不至于跑满,将文件大小拿出来分析后,发现开发的同学为了省事儿,将带有随机数几十M的apk升级包放这里了,真是坑!!
网卡的解决方式很多,做bond和换万兆网卡(交换机要支持),当前的情况我们后来改了业务逻辑,大于多少M时强制走大文件服务。
六、程序代码 当查了cpu、内存、IO、网络都没什么问题,就可以和开发好好掰扯掰扯了,为什么服务器本身没什么压力,量却跑不上去,不要以为开发写的程序都很优良,人无完人何况是人写出来的程序呢?
很多时候就是程序或框架本身的问题跑不上去量,这个过程运维还是要协助开发分析代码逻辑的,是不是程序cpu和内存使用的不合理?是不是线程池跑慢了?是不是用的同步没改异步?要把代码执行的所有逻辑环节一一分析,找出瓶颈点,解决掉,常用的方法是日志埋点或者用专业的apm工具做钻取分析。
如果暂时不好解决,可以考虑是不是可以跑一下多实例。
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>日期时间带星期农历js代码</title>
</head>
<body>
<script>
var CalendarData=new Array(20);
var madd=new Array(12);
var TheDate=new Date();
var tgString="甲乙丙丁戊己庚辛壬癸";
var dzString="子丑寅卯辰巳午未申酉戌亥";
var numString="一二三四五六七八九十";
var monString="正二三四五六七八九十冬腊";
var weekString="日一二三四五六";
var sx="鼠牛虎兔龙蛇马羊猴鸡狗猪";
var cYear;
var cMonth;
var cDay;
var cHour;
var cDateString;
var DateString;
var Browser=navigator.appName;
function init()
{
CalendarData[0]=0x41A95;
CalendarData[1]=0xD4A;
CalendarData[2]=0xDA5;
CalendarData[3]=0x20B55;
CalendarData[4]=0x56A;
CalendarData[5]=0x7155B;
CalendarData[6]=0x25D;
CalendarData[7]=0x92D;
CalendarData[8]=0x5192B;
CalendarData[9]=0xA95;
CalendarData[10]=0xB4A;
CalendarData[11]=0x416AA;
CalendarData[12]=0xAD5;
CalendarData[13]=0x90AB5;
CalendarData[14]=0x4BA;
CalendarData[15]=0xA5B;
CalendarData[16]=0x60A57;
CalendarData[17]=0x52B;
CalendarData[18]=0xA93;
CalendarData[19]=0x40E95;
madd[0]=0;
需要先把图片格式转换为.ico类型
在这个网址在线转换很方便:https://www.easyicon.net/covert/
在加一行来显示图标(注意,如果加入了没有效果,检查一下路径是否正确,文件名是否正确)
在网页标题左侧显示:
在收藏夹显示图标:
————————————————
版权声明:本文为CSDN博主「Jorwnpay」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41748900/article/details/90079643
CPU中央处理单元包含基本的运算单元AUL,存储单元cache等基本资源,实现硬件设备的基本控制功能。中央处理器作为一个普世概念,实际根据具体数据处理功能方向不同,细分位DSP、MCU和MP。其中DSP主要是做数据处理,MCU做无系统的简单控制功能,MP做上系统的微处理器。其中DSP主要做音视频数字信号处理,MCU做大系统芯片中的小部件控制功能,多作为边缘简单设备的微智能控制;MP主要做整个系统的集成和大型APP程序运行的地方。MPLD/FPGA是现场编程门阵列器件,最核心特点便是可编程,通过硬件编程语言随意写出需要的业务处理逻辑。GPU、NP,前者专业的图像处理单元,后者是专业的网络处理器。ASIC核心是专用,芯片的起始阶段,以上所有芯片都是ASIC中的一员,随着技术成熟和专业细分的出现,很多被广泛应用的芯片场景独立出来,便形成了如上百花齐放。当前业内所讲到的ASIC基本上指定一些功能模块独立,设计简单的小芯片,或者是某个公司根据自己对相关业务领域的理解而设计的特定功能芯片。当然这些ASIC也可以不独立生产,其核心功能以IP的形式出现在SOC中。
目前常见的出货芯片设计都是SOC(具体原因见芯片设计这篇文章),SOC一块片子上集合了多种外部控制IC模块,包含了中央核心处理器,和边缘ASIC小的专项功能控制模块,这些控制模块一般都会根据具体功能命名。小的ASIC比方说串口控制,或者USB控制。大的ASIC模块比方说WIFI模块。对于三星这样的大厂,小的ASIC模块都可以自己进行设计完成的,对于大的ASIC模块一般会买大型公司的IP集合再芯片当中。当然对于某项专业功能需求比较高的功能模块,就会把打的ASIC模块单独做一块小芯片实现,比方说手机中复杂的电源管理,或者射频芯片。另外讲射频模块作为独立芯片划分出来,目的也是为了减少射频电路对于主芯片的干扰。
作者之前做网络交换公司供职,做过网络处理ASIC芯片驱动和可编程网络处理器NP驱动开发工作,后期也基于FPGA芯片做过部分限速工作。其中ASIC主要是博通和marvel两家,这两家的芯片转发表象设计都是完全固定下来的,需要怎么配置也是给出了对应的SDK接口,配置按照文档说明即可。后期很快接触自研网络处理器XXP、XXX、XXX+几款可编程网络处理器芯片。可编程主要表现在微码可编程,表象可以灵活定制,功能完全可以利用处理器现有的资源进行整合。这种处理器包含x*x个硬件核,每个硬件核资源包含四项分别是报文解析存储单元(发送修改的报文也是从这里发出去),寄存器数据倒入,计算对应flag和查表结果寄存器。FPGA芯片主要用来限速,实现的功能标根据FPGA给出的硬件模块描述符完成表象功能配置和管理。
当然嵌入式开发工作是在针对确定的产品上进行,复杂的SOC芯片增加部分外围电路形成PCB产品板。一个复杂的产品,开发涉及的任务很多,每个人只能针对这个产品上面的某个模块或者某几个模块完成开发工作。对应的变出现了招聘网站上面各种类型的工作岗位。
图1. 内核 - 芯片 - 产品
目前作者接触到的产品主要有接入网转发单板、JZ2440开发板、AI处理卡。设计的开发主要是网络转发和各种设备驱动编写工作。
Multiple Inheritance Requires QObject to Be First(多重继承QObject一定要放在前面)
我在用class My_Node : public QGraphicsItem,public QObject来生成自己的类时,想使用信号和槽机制,但这是dys_node.h中没有Q_OBJECT,不能使用信号槽。我将Q_OBJECT加上之后,出现几个不知道是什么的错误。然后我将工程目录下的Makefile删除,然后重新编译、链接文件,刚才的错误消失了,但出现如下三个错误:
error: 'staticMetaObject' is not a member of 'QGraphicsItem'
error: 'qt_metacast' is not a member of 'QGraphicsItem'
error: 'qt_metacall' is not a member of 'QGraphicsItem'
通过google,我发现这个错误是由于没有继承QObject类而引起的,但是我已经继承了QObject类了啊,到底是怎么回事呢?
最后终于在网上找到了答案,当多继承的时候,要将QObject放在前面,即将类的声明改为
class My_Node : public QObject,public QGraphicsItem
问题就解决了!!!
下面是我从网络上找到的说明原文:
Just got this error message while compiling a tiny class that derives from QTreeWidgetItem:
error C2039: 'staticMetaObject' : is not a member of 'QTreeWidgetItem'
提示:这里可以使IDEA上传代码到Gitee、需要自己手动操作
目录
前言
一、打开Gitee官网(进行注册登录)
1.登录进去找到右上角添加仓库 (进行所示图操作)
二、启动IDEA
1.IDEA关联Gitee
2.找到git下载好git程序
3.进行操作(提交代码到Gitee)
前言 IDEA上传代码到Gitee
提示:以下是本篇文章正文内容,下面案例可供参考
一、打开Gitee官网(进行注册登录) 进入看右上角
没有账号的可以注册
1.登录进去找到右上角添加仓库 (进行所示图操作) 点击新建仓库 然后出现如下图进行操作
出现下图 先别动 进入IDEA
二、启动IDEA 提示:这里IDEA没有安装的去官网进行安装下载
1.IDEA关联Gitee 创建项目 项目名和Gitee仓库名一致(完全相同)
2.找到git下载好git程序 如图操作
如果没有安装下载git即可
3.进行操作(提交代码到Gitee) 点击OK后IDEA右上角会有如下图所示
然后找到项目如下图所示
右键项目
在这里输入如下
复制上图箭头所指放到下图URL中点击OK
然后找到如下图一步步操作
COMMIT完点击如下图箭头
出现下图点击push即可
等待OK就行(建议网络要好不然会失败不过失败多试几次就回OK)
成功后去Gitee找到项目进行看是否上传成功(刷新页面) 出现下图表示上传成功
输入两个正整数num1和num2,求其最大公约数和最小公倍数。 一、求最大公约数? 分析:最大公因数,也称最大公约数、最大公因子,指两个或多个整数共有约数中最大的一个。
1、穷举法(使用 for 和 if)
#include <stdio.h> #include <stdlib.h> int main() { int num1,num2,i,gcd;//最大公约数greatest common divisor printf("请输入两个数,用空格隔开:\n"); scanf("%d %d",&num1,&num2); for(i=1;i<=num1&&i<=num2;++i) { //判断i是否为最大公约数 if(num1%i==0&&num2%i==0) { gcd=i; } } printf("%d和%d的最大公约数是:%d\n",num1,num2,gcd); system("pause"); return 0; } 运行结果:
2、相减法(使用 while 和 if)
设有两整数a和b:
① 若a>b,则a=a-b
② 若a<b,则b=b-a
③ 若a==b,则a(或b)即为两数的最大公约数
④ 若a!=b,则再回去执行①。
例如求27和15的最大公约数过程为:
27-15=12( 15>12 )
15-12=3( 12>3 )
12-3=9( 9>3 )
9-3=6( 6>3 )
6-3=3( 3==3 )
因此,3即为最大公约数。
#include <stdio.h> #include <stdlib.h> int main() { int num1,num2,gcd;//最大公约数greatest common divisor printf("
一、WPF学习 1、什么是WPF? WPF(Windows Presentation Foundation)是微软推出的基于Windows的用户界面框架,属于.NET Framework 3.0的一部分。它提供了统一的编程模型、语言和框架,真正做到了分离界面设置人员与开发人员的工作;同时它提供了全新的多媒体交互用户图形界面。
使用WPF(Windows Presentation Foundation),你可以创建适用于Windows且具有非凡视觉效果的桌面客户端应用程序。
WPF通过一套完善的应用程序开大功能对核心进行了扩展,这些功能包括可扩展应用程序标记语言(XAML)、控件、数据绑定、布局、二维和三维图形、动画、样式、模板、文档、媒体、文本和板式。WPF属于.NET,因此可以生成整合.NET API其他元素的应用程序。
2、WPF的特点 优点:
①、MVVM模式,数据和视图分离
②、类库多,上手快,可以快速开发
③、灵活的控件组合,可以修改已经存在的控件的外观
④、可以应用不同样式不同的控件,易于管理
⑤、支持动画,高级图形,高级数据绑定,3D等功能
⑥、绚丽的展示效果WPF除了可以使用传统的Windows installer以及ClickOnce方式来发布我们的桌面的应用程序之外,还可以将我们的应用程序稍加改动发布为基于浏览器的应用程序。
缺点:
①、对微软系统依懒性太强,到了非微软的操作sit上,很多FrameWork里面的类库就不好使了。
②、技术更新速度快
3、WPF组成结构 Windows Presentation Foundation由引擎和编程框架两个主要部分组成
3.1 Windows Presentation Foundation引擎
WPF引擎统一了开发人员和设计人员体验文档、媒体和UI的方式,为基于浏览器的体验、基于窗体的应用程序、图形、视频、音频和文档提供了一个单一的运行时库。WPF是的应用程序不仅能够充分利用现代计算机中现有的图形硬件的全部功能,而且能够利用硬件将来的进步。例如,WPF的基于矢量的呈现引擎使应用程序可以灵活地利用高DPI监视器,而无需开发而能源或用户进行额外的工作。同样,当WPF检测到支持硬件加速的视频卡时,它将利用硬件加速功能。
3.2 WPF框架
WPF框架为媒体、用户界面设计和文档提供的解决方案远远超过开发人员现在所拥有的。WPF的设计考虑了可扩展性,使开发人员可以完全在WPF引擎的基础上创建自己的控件,可以通过对现有WPF空间进行在分类来创建自己的控件。WPF框架的核心是用于形状、文档、图像、视频、动画、三维以及用于放置空间和内容的面板的一系列控件。这些“自我控件”为开发下一代用户体验提供了构造块。
Microsoft在引入WPF的同时,还引入了XAML,这是一种公开便是Windows应用程序用户界面的标记语言,可使开发人员和设计人员用来构建和重用UI的工具更加丰富。对于web开发人员,XAML提供了熟悉的UI说明模式。XAML还使UI设计从基础代码中分离出来,从而使开发人员和设计人员之间的合作更加紧密。
4、为什么选择WPF? 对于企业:WPF实现改进的客户关系和不同的应用程序。通过提供能够快速、更好的视觉效果、独特的用户体验的技术,用来建立与客户的密切关系,使企业可以建立稳定的数字客户关系和独特的品牌化机会。而且,由于WPF是窗体、文档、视频、三维以及其他功能的综合,因此企业可以创建持久的用户体验解决方案,并集成到客户的日常活动中。
对开发人员和设计人员:WPF提供了统一的UI平台,因此他们只需要你学习一个模式,就可以获得无限可能的UI体验
对于.NET开发人员:其框架是熟悉的,并且它最终将减少提供最佳用户体验和通信逻辑所需的代码行数
对于设计人员:WPF提供的平台可消除内容、媒体和应用程序之间的边界。最重要的是,WPF可以使开发人员和设计人员同步紧密的合作来快速提供不同的连通体验
6、控件 6.1 实质
先从UI上分析,UI的功能是让用户观察和操作数据,为了能显示数据和响应用户的操作通知程序(通过事件来通知,如何处理事件有时一系列的算法),所以控件就是显示数据和响应用户操作的UI元素,也即:控件就是数据和行为的载体
6.2 数据驱动UI
什么是数据驱动UI呢?
传统的GUI界面都是由Windows消息通过事件传递给程序,程序根据不同的操作来表达式出不同的数据体现在UI界面上,这样数据从某种程序上,收到很大的限制,WPF中是数据驱动UI,数据是核心,处于主动的,UI属于数据并表达数据,是被动的。WPF数据第一,控件第二
6.3 控件的分类
布局控件:是可以容纳多个空间或者嵌套其他布局的控件,用于在UI上组织和排列控件。其父类为Panel。内容控件:只能容纳一个控件或者布局空间作为他的内容,所以经常借助布局控件来规划其内容,其父类为ContentControl带标题内容控件:相当于一个内容控件,但是可以加一个标题,标题部分也可以容纳一个控件或者布局,其父类为HeaderedContentControl条目控件:可以显示一列数据,一般情况下,是数据的类型是相同的。其共同的基类为itemsControl带标题的条目控件:和上面的带标题内容控件类同,其基类为HeaderedContentControl特殊内容控件:这类控件比较独立,但也必将常用。如TextBox、TextBlock、Image等 想了解更多可以去微软官网和百度查询
微软官网:https://docs.microsoft.com/zh-cn/dotnet/desktop/wpf/introduction-to-wpf?view=netframeworkdesktop-4.8
百度百科:https://baike.baidu.com/item/WPF/5299594?fr=aladdin
7、WPF和WinFrom的区别 WPF和WinFrom最重要的区别,WinFrom只是标准窗体控件顶部的一层(如文本框),而WPF从零开始,几乎在所有场景下都不依赖于标准窗体控件
例:有一个图片和文字的按钮。它并不是一个标准窗体控件,WinFroms无法提供现成的,所有需要自己画图片,实现支持图像的按钮,或使用第三方控件。相反,在WPF中按钮可以包含任何东西,因为她本质上是一个带内容弄和不同状态的边框。WPF的按钮就好像是一个看不见的物体,可以放入各种其他控件到里面,部分WPF控件都是如此。你是想要一个带图片和文字的按钮?只需要把一张图片和一个文本块放到按钮里面就搞定了。在标准WinFroms控件之外好像找不到这种灵巧的方式,这就是为什么带图片的按钮这种简单的控件会有如此大市场的原因
7.1 WPF的优势
①、比较性,从而更符合目前的标准
②、微软正在使用它开发很多新应用,比如Visual Studio
③、更灵活,你不必自己去写控件或者买控件
④、你所使用的第三方控件更多的聚焦在WPF上,因为它比较新
⑤、XAML使得GUI的创建和编辑更加容易,而且允许拆分设计器(XAML)和代码器(C#,VB.NET)
⑥、数据绑定,你可以更加彻底的分离数据和布局
⑦、用硬件加速绘制图形用户界面,性能更好
1.开机之前,在这个界面按e,进入编辑模式(要快一点,不然就错过了)
2.然后进入这个界面后:
3.往下找到 以linux16开头的一段:
4.在UTF-8后面输入 init=/bin/sh 输入完成后,直接按快捷键: Ctrl+x 进入单用户模式。
5. 接着,在光标闪烁的位置中输入: mount -o remount,rw / (注意:各个单词间有空格,逗号左右不要有空格),完成后按键盘的回车键(Enter),再在新的一行输入passwd然后回车 如图
6.输入两次密码(密码不会在上面显示,输入完成即可回车,最好是八位及以上,不强求)输入完成后进入新的一行
7.接着,在鼠标闪烁的位置中(最后一行中)输入:touch /.autorelabel(注意:touch后面有一个空格),完成后按键盘的回车键
8.继续在光标闪烁的位置中,输入: exec /sbin/init(注意: exec后面有一个空格),完成后按键盘的回车键 ,等待 系统自动修改密码(这个过程时间可能有点长,耐心等待),完成后,系统会自动重启,新的密码生效了,这个界面记住多等久一点!!!!!
9.记住多等久一点!!!!!
10.系统会自动重启,新密码生效
一、do while循环 do...while循环
do
循环语句;
while(表达式); (先执行在判断,至少执行一次,和while一样,想要执行多条语句需要用{}引起来)
二、循环练习 1.计算n的阶乘 代码如下:
int main() { int n = 0; scanf("%d", &n); int i = 0; int ret = 1; for (i = 1; i <= n; i++) {ret = ret * i;} printf("%d\n", ret); return 0; } 2.计算1-10的阶乘 在上面代码的基础上限值循环次数为十次,并且每次结果相加即可
int main() { int n=0; int i=0;, int ret=1; int sum=0; for(i= 1;i<=10;i++) { ret*=i; sum=sum+ret; } printf("%d\n", ret); return 0; } 3.
断言Predicate
Spring Cloud Gateway(简称Gateway)支持断言Predicate功能,该断言功能是基于Spring WebFlux的HandlerMapping实现的。Gateway包含了很多路由断言工厂,并且这些工厂对应着HTTP请求的很多属性进行了处理,当客户端HTTP请求时,HandlerMapping会获取请求参数,并与Gateway中配置的Predicates进行比对,若满足规则就按规则约定进行路由放行,否则拒绝访问或报404错误。
|如何使用断言
| 断言如何工作
| 一些注意事项
一、如何使用断言
在Gateway中,使用断言Predicate比较简单,其提供了简单的配置就可实现断言功能,我们需在如下位置配置:
spring.cloud.gateway.routes.predicates,常见断言用法如下:
1、After
After只接受一个参数,即DateTime格式时间,客户端访问Gateway接口的时间在After指定之后的时间是允许访问的,否则,当前访问被拦截:
- Path=/api/test/**
- After=2022-08-01T15:59:59Z[Asia/Shanghai]
当请求接口到来时,该断言工厂AfterRoutePredicateFactory通过apply判别请求接口时间是否大于在所配置时间,若是则放行,否则觉得访问,返回404错误。
2、Before
Before只接受一个参数,即DateTime格式时间,客户端访问Gateway接口的时间在Before指定之前的时间是允许访问的,否则,当前访问被拦截:
- Path=/api/test/**
- Before=2022-08-01T15:59:59Z[Asia/Shanghai]
当请求接口到来时,该断言工厂BeforeRoutePredicateFactory通过apply判别请求接口时间是否小于在所配置时间,若是则放行,否则觉得访问,返回404错误。
3、Between
Between接受两个参数,格式依然为DateTime格式时间,客户端访问Gateway接口的时间在Between指定的时间区间之内是允许访问的,否则,当前访问被拦截:
- Path=/api/test/**
- Between=2022-08-01T15:59:59Z[Asia/Shanghai], 2022-08-02T15:59:59Z[Asia/Shanghai]
4、Cookie
Cookie用来指定当前客户端请求头的cookie设置,只有当客户端请求头传递了cookie并且值与gateway设置的相等则放行,否则请求被拦截:
- Path=/api/test/**
- Cookie=test-001,hello-gateway
如何设置当前请求的Cookie昵?我们可使用postman来指定请求的cookie,具体设置如下:
5、Header
Header用来设定请求头匹配属性的,当前请求头属性与gateway所指定属性规则相同时,gateway断言放行该请求,否则拒绝访问,具体如下配置:
- Path=/api/test/**
- Header=Cus-Test-Request-Id, \d+
如上配置\d+为正则表达式,代表属性Cus-Test-Request-Id的值可匹配若干数字串,使用postman配置如下:
6、Host
Host用来匹配当前请求的host规则,该参数一般为自动计算,不需要手动设置,只有当前请求头中的host满足gateway所设定支持的host规则时,断言才会放行请求,否则截断请求:
- Path=/api/test/**
- Host=localhost,**.xxx.com,127.0.0.1:10000
如上,一般需要指定IP或域名+端口号,若端口为80则可不指定,其中**代表任意名字的域名地址。上面配置的127.0.0.1:10000满足当前网关的IP+端口号,故请求放行。
7、Method
Method用来指定gateway断言支持的请求方式,如:GET、POST或是PUT等,目前大多用的是GET和POST方式,只有请求方式在gateway所设定支持请求方式范围内,则放行请求:
- Path=/api/test/**
- Method=GET,POST
如上代表支持GET和POST两种请求方式,其它方式则被拒绝。在postman中体现如下,改为GET请求即可放行:
8、Path
正如上面所设定的- Path=/api/test/**所示,代表gateway所支持的路由接口地址,其中**代表任何级别的接口名,如:/api/test/hello-world或/api/test/hello/world等,Path还可指定单个级别接口,配置规则:- Path=/api/test/{segment},如:/api/test/hello,而不支持/api/test/hello/world格式:
predicates:
- Path=/api/test/{segment},/api2/test2/{segment}
一、本地安装
1)去官网进行下载AmaterasUML
或直接下载安装包:Amateras下载地址 将下载好的压缩包进行解压
2)如图,解压后会一个名为AmaterasUML_1.3.2文件夹。打开此文件夹里面有三个后缀名为.jar的文件
3)打开eclipse的安装目录找到dropins文件夹
找到dropins文件后并打开
4)将之前解压好的AmaterasUML_1.3.2文件夹复制到dropins文件夹中
5)将AmaterasUML_1.3.2中的三个jar文件复制到 eclipse的plugins文件夹中
二、在线安装
Amateras Eclipse Plug-inshttps://takezoe.github.io/amateras-update-site/
跟刚才一样的在线安装方法,全选之后next+finish,再重启之后就行了!!!
然后就可以舒舒服服的使用UML插件了!
最近应该项目的需要,需要使用一个工具类来访问数据库。
但是这个工具类又被定义成静态访问了。
我们也需要设置一个静态变量来访问数据库。
@Autowired private static VisaRepository visaRepository; private static VisaCheckeeRepository visaCheckeeRepository; 上面的代码在编译的时候是没有问题的。
但是在程序运行的时候提示空对象异常。
类加载后静态成员是在内存的共享区,静态方法里面的变量必然要使用静态成员变量。
通过日志我们可以非常明确的知道上面异常的主要原因就是因为 VisaRepository 这个变量没有初始化,简单来说就是没有被 @Autowired 上去。
问题和解决 在 Spring 框架中,不能 @Autowired一个静态变量,使之成为一个Spring bean。
这是因为当类加载器加载静态变量时,Spring上下文尚未加载。所以类加载器不会在bean中正确注入静态类。
这个和静态变量这个属性有关的,因为静态变量总是先于 Spring 的 上下文加载。
使用构造函数 其实 IDEA 已经非常明确的建议我们不要使用变量 @Autowired 的方式。
而建议使用构造方法或者 Setter 的方式。
Marks a constructor, field, setter method, or config method as to be autowired by Spring's dependency injection facilities. This is an alternative to the JSR-330 javax.inject.Inject annotation, adding required-vs-optional semantics.
背景说明 之前在开发项目时,项目时一边开发 ,一边在生产环境中提供服务。由于处于开发前期,项目代码不是很健壮,再加上生产环境多变(不可控)和人员操作不当,导致异常频频发生。二生产环境 只能看到部分日志 和db,虽然可排查,但是耗时耗力,定位错误的成本非常大。于是 就想 :程序在报错时,如果可以把报错所在的类、方法、以及行数 返回给前端,这样的话,排查与定位 就会变得非常轻松,只需要根据返回的信息 ,直接找到那行代码即可。
原理 根据jvm的运行机制可知, 一个线程的执行,它所有的链路信息,都会存储在堆栈当中,包括调用关系,如:谁调用谁
开发 springboot + 自定义异常 + RestControllerAdvice全局异常处理
注: 本文的代码 , 均为模拟代码,点到为止。
自定义异常类 本文的堆栈信息获取 放在了 自定义异常类里。如需放在其它位置 ,则需要 debug : StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
这行代码 ,查看 你需要的信息 在堆栈信息数组中的位置
package com.example.myexception.excetion; public class MyException extends RuntimeException{ private String message; @Override public String getMessage() { return message; } public MyException() { } public MyException(String message) { //获取当前线程的堆栈信息 (里面包含整个链路的调用信息 ,包括谁调用谁的关系信息) StackTraceElement[] stackTrace = Thread.
安装JDK 在官网下载JDK
我下载的是 jdk-8u341-linux-x64.tar.gz
一、上传 在/usr/local中创建java文件夹
mkdir /usr/local/java 把JDK上传到java目录下
可以用ls命令查看一下
二、解压 输入命令
tar -xzvf jdk-8u341-linux-x64.tar.gz jdk-8u341-linux-x64.tar.gz是我下载的JDK文件名,此处输入自己下载对应的文件名,解压之后可以看到/usr/local/java目录下多出了一个文件夹
解压之后JDK的安装包可以删掉
三、配置JAVA环境变量 java命令测试,直接输入java,出现-bash:java:command nor found说明没有配置java环境变量
需要配置的环境变量 项目Value备注PATH指定命令搜索路径,shell执行命令时会到PATH所指定的路径中查看能否找到命令程序jdk的/bin中包含经常要访问的javac、java、javadoc等命令,设置后可以在任何目录下执行该命令CLASSPATH指定类搜索路径,JVM通过CLASSPATH来寻找类设置jdk的/lib中的dt.jar和tools.jar以及当前目录"."给CLASSPATHJAVA_HOME指向jdk安装目录Eclipse、NetBeans、Tomcat等软件会通过JAVA_HOME来使用jdk使用vim编辑 vim /etc/profile 或使用文本编辑器打开
修改.bash_profile或者/etc/profile在末尾引入环境变量,JAVA_HOME的值填写自己解压包的路径
export JAVA_HOME=/usr/local/java/jdk1.8.0_341 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin export PATH=$PATH:${JAVA_PATH} 完成上述修改后,执行命令:
source /etc/profile 或者重启
输入命令查看java版本,返回版本信息说明环境变量设置生效
安装MySQL 我是在docker环境部署的MySQL,docker部署框架支持mysql服务器的简单安装和配置。
一、安装Docker环境 #安装Docker yum install docker -y #启动Docker服务 service docker start 因为Docker在线安装镜像是从国外的DockerHub网站下载文件,所以速度超级慢,所以我们要给Docker设置加速器。我用的是腾讯云主机,所以设置腾讯云加速器是最快的。
打开/etc/docker/daemon.json文件,然后设置成如下内容:
{ "registry-mirrors":["https:mirror.ccs.tencentyun.com"] } 重新启动Docker服务,加速器才能生效
service docker restart 二、安装MySQL 利用刚才设置的加速器,我们可以在线安装MySQL镜像,这里我下载8.0.23版本的MySQL数据库
docker pull mysql:8.0.23 创建容器的时候,我们需要把MySQL容器内的数据目录映射到CentOS系统上面。如果MySQL容器挂掉了,数据库文件不会丢失。我们新建一个MySQL容器,挂载上这个数据目录就又能正常使用MySQL了。
项目版本号大小比较 软件版本号格式一般为X.Y.Z( Major.Minor.Patch),X为主版本号,Y为次版本号,Z为修订号。例如:1.12.123。
最近在项目中碰到一个业务:需要从版本数组中获取最大的版本号。那我们要怎么处理版本之间的大小比较呢?
方案一:直接字符串比较(❌) 字符串比较:是从第一位起逐位进行比较。字符串比较中"10" < “2” 。
"1.2.0" < "1.10.0" // false "2.0.0" < "10.0.0" // false 方案二:转化成整型比较(❌) let formatVersionNum = (version) => { let resNum = version.toString().replaceAll(".", "") return +resNum } let v1 = formatVersionNum("1.12.0") // 1120 let v2 = formatVersionNum("10.1.0"); // 1010 v1 < v2 // false 方案三:版本数字头部补位比较(✅) 我们将X.Y.Z 格式化成12位字符串后进行比较。
转化规则:按着“.”拆成3个元素,对每位元素进行转化,保证每位元素长度为4,不足4位头补位0,再拼接成12位字符串。例如1.12.123 转化为000100120123
let formatVersionNum = (version) => { version = version.toString() const [_1st, _2nd, _3rd] = version.
文章目录 一、什么是IP地址二、什么是IPV4和IPV6二、分类的IP地址三、IP地址分类三、常用的三种类别的IP地址四、公有地址和私有地址总结 一、什么是IP地址 IP地址是给因特网上的每一个主机(或路由器)的每一个接口分配一个在全世界范围是唯一的32位的标识符。IP地址的结构使得我们可以在因特网上很方便进行寻址。
IP地址编址共经过了三个历史阶段:
(1)分类的IP地址:这是最基本的编址方法
(2)子网的划分:这是对最基本的编址方法的改进
(3)构成超网:这是比较新的五分类编址方法
本次只讨论最基本的分类IP地址。
二、什么是IPV4和IPV6 IPV4
网际协议版本4(Internet Protocol version 4,IPv4),又称互联网通信协议第四版,是网际协议开发过程中的第四个修订版本,也是此协议第一个被广泛部署的版本。IPv4是互联网的核心,也是使用最广泛的网际协议版本,由32位二进制数组成,一般用点分十进制表示。其后继版本为IPv6,直到2011年,IANA IPv4位址完全用尽时,IPv6仍处在部署的初期。
IPV4是由网络部分和主机部分组成
IPV6
IPv6(Internet Protocol Version 6)的优势就在于它大大地扩展了地址的可用空间,IPv6地址有128位长。如果地球表面(含陆地和水面)都覆盖着计算机,那么IPv6允许每平方米拥有7*1023个IP地址;如果地址分配的速率是每微秒100万个,那么需要1019年才能将所有的地址分配完毕。由128位二进制数组成,一般用冒号隔开,十六进制表示。
IPV6分为公有网络地址和私有网络地址
当我们打开一个手机APP时,很多在打开页面底部会显示支持IPV6。但目前使用比较广泛的还是IPV4。
二、分类的IP地址 分类的IP地址就是将IP地址划分为若干个固定类,每一类地址都由两个固定长度的字段组成:
IP地址:网络号+主机号。
网络号:标志主机(或路由器)所连接到的网络。一个网络号在整个因特网范围内必须是唯一的。
主机号:标志该主机(或路由器)。一个主机号在它前面的网络号所指明的网络范围内必须是唯一的。
由此可见,一个IP地址在整个因特网范围内是唯一的。
三、IP地址分类 三、常用的三种类别的IP地址 1.A类地址(范围:1.0.0.1~126.255.255.254)
⑴A类地址的第一个字节为网络地址,其余三个字节为主机地址。另外第1个字节的最高位固定为0。
⑵A类地址包含私有地址和保留地址
2.B类地址(范围:128.0.0.1~191.255.255.254)
⑴B类地址第一个字节和第二个字节为网络地址,其他两个字节为主机地址。另外第1个字节的最高位固定为10。
⑵B类地址包含私有地址和保留地址
3.C类地址(范围:192.0.0.1~223.255.255.254)
⑴C类地址第一个、第二个、第三个字节均为网络地址,第四个字节为主机地址。另外第1个字节的最高位固定为110。
⑵C类地址中只包含私有地址
四、公有地址和私有地址 公有IP地址段:
A类:1.0.0.1 - 9.255.255.254和11.0.0.1 - 126.255.255.254
B类:128.0.0.1 - 172.15.255.254和172.32.0.0 - 172.255.255.254
C类:192.0.0.1 - 192.168.255.254和192.169.0.0 - 223.255.255.254
以127开头的IP地址都代表本机(广播地址,127.255.255.255除外)127.0.0.1为本机回环地址
以下范围内的IP地址属于内网保留地址,即不是公网IP,而是属于私有IP:
A类:10.0.0.1 - 10.255.255.254
B类:172.16.0.1 - 172.31.255.254
C类:192.168.0.1 - 192.168.255.254
1、Feign对负载均衡的支持 Feign 本身已经集成了Ribbon依赖和自动配置,因此我们不需要额外引入依赖,可以通过 ribbon.xx 来进行全局配置,也可以通过服务名.ribbon.xx 来对指定服务进行细节配置配置(参考之前,此处略)
Feign默认的请求处理超时时长1s,有时候我们的业务确实执行的需要一定时间,那么这个时候,我们就需要调整请求处理超时时长,Feign自己有超时设置,如果配置Ribbon的超时,则会以Ribbon的为准。
Ribbon设置
#针对的被调用方微服务名称,不加就是全局生效 lagou-service-resume: ribbon: #请求连接超时时间 ConnectTimeout: 2000 #请求处理超时时间 ReadTimeout: 15000 # Feign 超时时间设置 #对所有操作都进⾏重试 OkToRetryOnAllOperations: true ####根据如上配置,当访问到故障请求的时候,它会再尝试访问⼀次当前实例(次数由MaxAutoRetries配置), ####如果不⾏,就换⼀个实例进⾏访问,如果还不⾏,再换⼀次实例访问(更换次数由MaxAutoRetriesNextServer配置), ####如果依然不⾏,返回失败信息。 MaxAutoRetries: 0 #对当前选中实例重试次数,不包括第⼀次调⽤ MaxAutoRetriesNextServer: 0 #切换实例的重试次数 NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #负载策略调整 2、Feign对熔断器的支持 在Feign客户端工程配置文件(application.yml)中开启Feign对熔断器的支持。
# 开启Feign的熔断功能 feign: hystrix: enabled: true Feign的超时时长设置那其实就上面Ribbon的超时时长设置,Hystrix超时设置(就按照之前Hystrix设置的方式就OK了)
注意:
开启Hystrix之后,Feign中的方法都会被进行一个管理了,一旦出现问题就进入对应的回退逻辑处理针对超时这一点,当前有两个超时时间设置(Feign/hystrix),熔断的时候是根据这两个时间的最小值来进行的,即处理时长超过最短的那个超时时间了就熔断进入回退降级逻辑 hystrix: command: default: execution: isolation: thread: timeoutInMilliseconds: 15000 自定义FallBack处理类(需要实现FeignClient接口)
package com.lagou.edu.controller.service; import org.springframework.stereotype.Component; /** * 降级回退逻辑需要定义一个类,实现FeignClient接口,实现接口中的方法 * 此接口是我们进行Feign远程调用时所创建的接口 */ @Component public class ResumeFallback implements ResumeServiceFeignClient{ @Override public Integer findDefaultResumeState(Long userId) { return -6; } } 在@FeignClient注解中关联2)中自定义的处理类
GetX的优势 1.内部实现了路由管理,相比目前主流的fluro框架更轻量,并且路由跳转无需上下文对象,支持自定义路由中间件和动态路由传参等功能。
2.提供两种简单灵活的实现状态管理的方式。
3.它内部实现了依赖注入,可以快速的获取到某个状态管理器(GetxController)。
4.在实际开发中,通过上述三点配合使用,可以将界面、业务、路由、依赖等进行分离。在做到UI刷新及跨界面交互的同时,又能提高整体模块代码的可维护性和架构的可扩展性
5.提供修改全局语言/主题和其他的一些高级Api以及GetUtils工具类等。
6.可以全局获取上下文对象,所以上述场景都是不需要Context的。
7.只有用到的模块才会被编译到代码中,不会导致包体积增大。
8…
状态管理 常用的几种状态管理对比 1.Bloc非常安全和高效,但是模版代码太多,实现太过复杂。
2.Provider内部使用InheritedWidget且依赖上下文对象,对其ChangeNotifier类的任何访问都必须在widget树或widget子树内。
3.Fish_redux层次划分是比较细的,但是写起来很费劲,每次都要生成很多文件。
4.那其实每种方式都有其优缺点,但是Get并不是比任何其他状态管理更好,而是通过和它提供的其他模块搭配使用,使得模块代码更简单灵活且易维护而已。
GetxController * 1.主要是用于分离UI代码与业务逻辑2.提供可以手动刷新UI的方法(update())3.提供和StatefulWidget类似的生命周期,常用的有以下这三个方法1.onInit:数据初始化、加载缓存等处理2.onReady:界面渲染第一帧后调用,刷新UI的操作需要在这里处理3.onClose:做一些清除资源等处理
Get提供响应式状态 和简单状态两种状态管理器
响应式状态管理器 主要通过Obx和GetX Widget实现,但是GetX Widget 会多消耗内存,所以只介绍Obx的使用
1.创建控制器并继承GetxController,通过.obs扩展方法声明响应式变量(Rx)class Controller extends GetxController { var count = 0.obs}extension DoubleExtension on double { RxDouble get obs => RxDouble(this);} 2.使用Obx方法实现定点刷新final logic = Get.find<Controller>();Obx(() => Text( '${logic.count.value}',)); 3.Obx()方法刷新的条件* 只有当响应式变量的值发生变化时,才会执行刷新操作,当某个变量初始值为:0,再赋值为:0,并不会执行刷新操作* 该响应式变量改变时,只有包裹该响应式变量的Obx()方法才会执行刷新操作(局部刷新)
简单状态管理器GetBuilder 1.创建控制器并继承GetxControllerclass Controller extends GetxController { int counter = 0; void increment() { counter++; update();}} 2.通过GetBuilder包裹想要刷新的UI// Stateless/StatefulGetBuilder<Controller>( // 未注入的控制器需要进行初始化 init: Controller(), builder: (_) => Text( '${_.
一、查找
1、打印本机所有软件包 adb shell pm list packages
2、输出和安装包相关联的文件(包括apk的路径) adb shell pm list packages -f
3、输出本机禁用的包 adb shell pm list packages -d
4、输出本机启用的包 adb shell pm list packages -e
5、打印输出系统包名 adb shell pm list packages -s
6、打印输出第三方安装包 adb shell pm list packages -3
7、输出包和安装信息(安装来源) adb shll pm list packages -i
8、输出包和为安装包信息(安装包来源) adb shell pm list packages -u
9、根据用户id查询用户空间的所有包 adb shell pm list packages --user <USER_ID> 其中USER_ID代表连接设备顺序,从0开始
10、设置过滤参数进行查询 adb shell pm list packages -e “com”
文章目录 1. redis初识1.1 Redis是什么1.2 Redis特性1.3 Redis单机安装1.4 卸载流程1.5 服务端三种启动方式1.6 客户端连接 2. 通用命令3. 数据类型命令3.1 字符串命令3.2 列表命令3.3 哈希命令3.4 集合命令3.5 有序集合命令 4. 慢查询4.1 默认配置4.2 修改配置4.3 慢查询队列相关命令 5. 发布订阅5.1 订阅相关命令5.2 实例 6. Bitmap 位图6.1 位图应用原理6.2 位图常用命令 1. redis初识 1.1 Redis是什么 Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglogs等数据类型。内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区
是一个 cs 架构的开源软件非关系型(没有外键关联关系)数据库数据都放在内存中(读写速度超级快,每秒的 qps 10w)以 key-value 形式存储有5大数据类型(字符串,list,hash,集合,有序集合)
好处 Redis典型使用场景
缓存系统:使用最广泛的就是缓存 计数器:网站访问量,转发量,评论数(文章转发,商品销量,单线程模型,不会出现并发问题) 消息队列:发布订阅,阻塞队列实现(简单的分布式,blpop:阻塞队列,生产者消费者) 排行榜:有序集合(阅读排行,点赞排行,推荐(销量高的,推荐)) 社交网络:很多特效跟社交网络匹配,粉丝数,关注数 实时系统:垃圾邮件处理系统,布隆过滤器 1.2 Redis特性 速度快:10w ops(每秒10w读写),数据存在内存中,c语言实现,单线程模型
持久化:rdb 和 aof
5大数据结构
BitMaps位图:布隆过滤器 本质是 字符串
HyperLogLog:超小内存唯一值计数,12kb HyperLogLog 本质是 字符串
GEO:地理信息定位 本质是有序集合
C++编程规范:头文件 提倡 每一个.c文件(main.c除外)应有一个同名.h文件,用于声明需要对外公开的接口。
所有头文件都应当使用#define 防止头文件被多重包含,为了保证唯一性,更好的命名是PROJECTNAME_PATH_FILENAME_H。
**示例:**假定SYS工程的pwm模块的pwm.h,其目录为SYS/include/pwm/pwm.h,可按如下方式保护:
#ifndef SYS_INCLUDE_PWM_PWM_H #define SYS_INCLUDE_PWM_PWM_H ... #endif 头文件的版权声明部分以及头文件的整体注释部分(如阐述此头文件的开发背景、使用注意事项等)可以放在保护符(#ifndef XX_H)前面。
头文件中应放置对外部的声明,如对外提供的函数声明、宏定义、类型定义等。
头文件应当刚好自包含: 自包含就是任意一个头文件均可独立编译(不多不少)。
如果一个文件包含某个头文件,还要包含另外一个头文件才能工作的话,就会增加交流障碍,给这个头文件的用户增添不必要的负担。.c/.h文件禁止包含用不到的头文件 示例:
如果a.h不是自包含的,需要包含b.h才能编译。每个使用a.h头文件的.c文件,为了让引入的a.h的内容编译通过,都要包含额外的头文件b.h。额外的头文件b.h必须在a.h之前进行包含,这在包含顺序上产生了依赖。
头文件的包含关系是一种依赖。应当让不稳定的模块依赖稳定的模块,从而当不稳定的模块发生变化时,不会影响(编译)稳定的模块。
示例:
若a.c主要实现a.h中的内容,则a.c的头文件包含顺序应为(不同块的头文件应该用空行隔开):
a.hC系统文件C++系统文件其他库.h文件本项目内的.h文件 **优点:**当a.h中遗漏某些必要的库时,a.c的构建会立刻终止,因此能够立刻对a.h进行维护。
头文件包含时可以使用源代码目录树结构排列,如#include "src/pwm.h",增强可读性。
禁止 禁止在extern "C"中包含头文件。
示例:
头文件中引入extern "C"期望g++编译器以gcc的方式对某些函数进行编译(c++允许函数重载,其编译后生成汇编代码和C不同)。若在extern "C"中包含头文件,则可能造成extern "C"的循环嵌套、某些不期望以C方式编译的函数被处理。
禁止头文件循环依赖:a.h包含b.h,b.h包含c.h,c.h包含a.h,则三个文件任意一个改变时,另外两个都会重新编译;若a.h包含b.h,b.h包含c.h,则c.h改变时,仅有c.h和b.h被重新编译。
步骤说明 1、下载
Apache VS16 二进制文件和模块下载 (apachelounge.com)
根据电脑选择对应版本压缩包进行下载
2、解压安装包
解压到自定义的文件目录下
此处我解压至系统D盘根目录下
3、修改配置文件
D:\httpd-2.4.53-win64-VS16\Apache24\conf\http.conf
修改Define SRVROOT "D:/httpd-2.4.53-win64-VS16/Apache24"
将Define SRVROOT "C:/Apache24"修改成Define SRVROOT "D:/httpd-2.4.53-win64-VS16/Apache24"
4、运行服务器
双击D:\httpd-2.4.53-win64-VS16\Apache24\bin\httpd.exe
5、验证是否配置成功
打开浏览器,在地址栏输入本机IP地址
显示It works!
6、文件存放路径
D:\httpd-2.4.53-win64-VS16\Apache24\htdocs\
将文件存放至此目录下,用户可通过访问浏览器输入服务器IP地址下载所需文件
附 1、设置开机自动运行
命令行:httpd.exe -k install
2、运行报错。
D:\httpd-2.4.53-win64-VS16\Apache24\bin>httpd.exe
AH00558: httpd.exe: Could not reliably determine the server's fully qualified domain name, using ::1. Set the 'ServerName' directive globally to suppress this message
修改httpd-2.4.53-win64-VS16\Apache24\conf\http.conf文件
将#ServerName www.example.com:80修改成ServerName localhost:80
3、注意确保您已安装 Visual C++
操作系统64位:vc_redist_x64
操作系统32位:vc_redist_x86
参考文章 (66条消息) Windows 下Apache服务器搭建_sunqian666888的博客-CSDN博客_apache注册windows服务https://blog.
项目场景: 在打包pyqt5 文件为exe 文件的过程中,如果没有报图片也资源打包进去的话,可能出现图片资源在外面可见的部分,
在这个过程学习到一些方法,记录分享
问题描述 图片资源不希望是可以见的情况,需要把图片资源也打包到配置里面,但是main_ui.spec spec 文件里面没有看到有配置进去的功能,
1.需要先把图片资源转换为二进制的文件之后再使用就可以了,首先在图片资源下面新建,rcc 文件,把图片的名字包括扩展名。
如下面的格式
myimage.rcc <RCC> <qresource> <file>add.png</file> <file>baocun.png</file> <file>bianji.png</file> <file>car_icon.png</file> <file>gongyezidonghua.png</file> <file>icon_ruanjiansuoche-copy.png</file> <file>jian.png</file> <file>save-fill.png</file> <file>tihuan.png</file> <file>yunxingzhong.png</file> </qresource> </RCC> 2、使用pyccr 打包为二进制的py文件
pyrcc5 F:\my_work\my_py_qt5\sb_lock\my_assets\myimage.rcc -o F:\my_work\my_py_qt5\sb_lock\my_assets\resource_rc.py 这样就可以在自己的目录下面可以生成一个1.py的文件,自己命名你自己需要的名字
3、在项目的起始py文件里面import 刚刚生成的那个py 文件
import resource_rc 4、这样就可以在全局去使用。使用方式如下:
import resource_rc self.setWindowIcon(QIcon(':/gongyezidonghua.png')) 原因分析: 大部分功能qt 都会有包含的,如果没有找到好的解决方法,可以百度查找下。
解决方案: OK。解决问题。这样打包之后可以不需要把图片资源放置进去了。问题搞定,谢谢,点赞,关注!!!!!!
题目来源与C程序设计课后习题:
输入三个数字,按由从小到大输出并利用指针的方法实现,
代码如下
#include <stdio.h> int main() { void swap(int *p1,int *p2); int n1,n2,n3; printf("请输入三个数字\n"); int *p1,*p2,*p3; scanf("%d%d%d",&n1,&n2,&n3); p1=&n1; p2=&n2; p3=&n3; if(n1>n2) swap(p1,p2); if(n1>n3) swap(p1,p3); if(n2>n3) swap(p2,p3); printf("现在输出已经完成了比较的数字序列\n"); printf("%d\n%d\n%d\n",n1,n2,n3); return 0; } void swap(int *p1,int *p2) { int p; p=*p1; *p1=*p2; *p2=p; } 这里我介绍一下我们学校的校园判题系统哦,不喜别喷,喜欢就进入这个网站学习吧,我是使用它一步一步学习C语言,逐渐学会了C语言。使用这个网站最好使用谷歌浏览器吧,广东技术师范大学在线判题网站http://www.gpnuacm.com/#/home
低版本的antd table组件 官网文档上有可伸缩列功能,但是用起来有很明显的bug,无法直接拿来用;接下来给大家提供一个手写的拖拽方案:
1.首先,写好v-table组件,这里最重要的就是table组件中的‘components’属性,官方对component的描述是"覆盖默认的 table 元素",意思就是对table进行重写
<a-table :components="components" @change="handleTableChange" :columns="columns" :data-source="tableData" :rowKey="(record, index) => index" :pagination="false"> </table> 2.然后用计算属性去定义这个components,这里的“ResizeHeader”就是重写table组件的一个方法,这里面还引入了‘customHeaderCell, ResizeColumnProvide’这两个方法后面会介绍
import ResizeHeader, { customHeaderCell, ResizeColumnProvide } from './header' computed: { components() { return { header: { cell: ResizeHeader, }, } }, } mixins: [ResizeColumnProvide], 3.我们创建一个header.js 文件 用来放ResizeHeader方法
//重构table组件的核心渲染函数 const ResizeHeader = (h, props, children) => { const { key, column, ...restProps } = props; let content = [].concat(children); if (column?.resizable) { const handlerVNode = h(DragHandler, { props: { width: column.
当使用elementUIDateTimePicker 日期时间选择器组件的时候,想要显示当前时间 和 禁用当前时间之前的日期
显示当前时间
可以通过选项default-time可以控制选中起始与结束日期时所使用的具体时刻。default-time接受一个数组,数组每项值为字符串,形如12:00:00,其中第一项控制起始日期的具体时刻,第二项控制结束日期的具体时刻。
使用moment插件
设置需要显示的开始时间和结束时间
//前提需要下载moment插件 npm i moment //引入import moment from 'moment' data(){ retuen:{ defaultTime: [moment().format('HH:mm:ss'), '00:00:00'], } } //然后在el-date-picker组件中添加 :default-time="defaultTime" 即可 禁用当前时间之前的日期
参照element ui的官方文档可以使用里面的picker-options属性和disabledDate(设置禁用状态,参数为当前日期,要求返回 Boolean)
JavaScript getTime()方法
返回距 1970 年 1 月 1 日之间的毫秒数: var d = new Date(); var n = d.getTime(); // 输出结果:1661489029980 使用:
<el-date-picker type="datetime" :picker-options="forbiddenTime" value-format="yyyy-MM-dd HH:mm:ss" v-model.trim="data.time" style="width: 100%;"/> data() { return { forbiddenTime:{ //禁用当前日期之前的日期 disabledDate(time) { //Date.now()是javascript中的内置函数,它返回自1970年1月1日00:00:00 UTC以来经过的毫秒数。 return time.
文章目录 Hive的迁移涉及两个技术点:1.仅迁移元数据2.元数据及Hive数据全量迁移2.1 全表迁移2.1.1 旧集群2.1.2 新集群 2.2 仅部分分区迁移(主要步骤)2.1.1 旧集群2.1.2 新集群 2.3 beeline连接hive并进行数据迁移 Hive的迁移涉及两个技术点: 1.仅迁移元数据 参考:网易元数据管理 - hive 元数据迁移与合并
2.元数据及Hive数据全量迁移 主要流程
1.将旧集群的hive数据导出至其hdfs中
2.将旧集群hdfs中的导出数据下载到本地中
3.将本地的导出数据上传至新的集群hdfs中
4.将新集群hdfs中的数据导入至新集群中的hive中
2.1 全表迁移 2.1.1 旧集群 设置hive默认数据库 vim ~/.hiverc use export_db; hdfs上创建导出目录 hdfs dfs -mkdir -p /tmp/export_db_export 生成、执行导出脚本 hive -e "show tables;" | awk '{printf "export table %s to |/tmp/export_db_export/%s|;\n",$1,$1}' | sed "s/|/'/g" | grep -v tab_name > ~/export.hql hive -f ~/export.hql 发送数据 sudo scp -r export_db_export/ hr@192.168.1.xx:/opt/lzx 2.
关键概念 该控制器会确保每一个节点上部署一个相同的副本,且只部署一个副本。
应用场景 在集群的每个节点上运行存储,比如:glusterd 或 ceph。
在每个节点上运行日志收集组件,比如:flunentd 、 logstash、filebeat 等。
在每个节点上运行监控组件,比如:Prometheus、 Node Exporter 、collectd 等。
了解工作原理:如何管理 Pod daemonset 的控制器会监听 kuberntes 的 daemonset 对象、pod 对象、node 对象,这些被监听的对象之变动,就会触发 syncLoop 循环让 kubernetes 集群朝着 daemonset 对象描述的状态进行演进。
资源清单解释 # kubectl explain ds.spec 没有replicas字段 minReadySeconds <integer> #当新的 pod 启动几秒种后,再 kill 掉旧的pod。 revisionHistoryLimit <integer> #历史版本 selector <Object> -required- #用于匹配 pod 的标签选择器 template <Object> -required- #定义 Pod 的模板,基于这个模板定义的所有 pod 是一样的 updateStrategy <Object> #daemonset 的升级策略 # kubectl explain ds.spec.updateStrategy rollingUpdate <Object> # 只支持RollingUpdate Rolling update config params.
工业类 产品型号描述分辨率有效像素靶面长宽比像素大小 [um]帧率 [fps]接口色彩类型技术及快门IMX411ALR/AQRRolling Shutter CMOS, 151M, 4.2"151 M14208 x 106564.24:33.766SLVS-ECMonochrome, RGBRolling shutterIMX661-AAMR/AAQRGlobal Shutter CMOS 127M, 3.6"127 M13472 x 95683.64:33.4519SLVS
SLVS-ECMonochrome, RGBPregius
Global shutterIMX461ALR/AQRRolling Shutter CMOS, 102M, 3.4"102 M11664 x 87503.44:33.768SLVS-ECMonochrome, RGBRolling shutterIMX455ALK-K/AQK-KRolling Shutter CMOS, 61.1M, 2.7"61.1 M9576 x 63882.73:23.7621SLVS-ECMonochrome, RGBRolling shutterIMX492LLJ/LQJGlobal Shutter CMOS, 47.0M, 1.4"47.0 M8336 x 56481.44:32.31524MIPI CSI-2, SLVS-ECMonochrome, RGBRolling ShutterIMX342LLA/LQARolling Shutter CMOS, 31.4M, APS-C31.4 M6480 x 4860APS-C4:33.4535SLVS, SLVS-ECMonochrome, RGBGlobal shutterIMX571BLR/BQR-JRolling Shutter CMOS, 26.1M, 1.8"26.1 M6252 x 41761.
springboot2.7.3整合nacos2.0.1在拉取配置文件的时候出现了死循环。
看了很多教程说是springboot2.6.X之后的默认禁用了循环依赖。
我拍查完,后来想想粘贴了配置文件,估计是格式问题。
果断清空空格,重新排列格式,完美解决问题。
有时候我们从其他地方复制的,空格格式不对,会出现此问题。
首先从向日葵的官网下载最新的向日葵安装包
下载后,打开个人目录,下载,该目录下空白处右击在终端打开输入命令
rpm -ivh SunloginClient_11.0.1.44968_amd64.rpm
报如上依赖错误,此时因为麒麟源中没有webkitgtk3相关包,所以使用其他源中的相关包,相关依赖包已经打包为webkitgtk3.tar
将该包放置/root/目录下,使用
cd /root #切换到/root目录
tar -xvf webkitgtk3.tar
解压后进行安装
rpm -ivh /root/repo/babse/Packages/webkit*.rpm --nodeps
再执行yum -y install libappindicator-gtk3 此时向日葵所需依赖已经安装完成,重新回到下载目录,空白处右击打开终端。执行
rpm -ivh SunloginClient_11.0.1.44968_amd64.rpm
此时已经安装完成,从开始菜单找到向日葵打开
打开向日葵后,点击如下位置,修改本机验证码。修改后,即可使用其他电脑对齐进行远程
分析入口:@EnableCircuitBreaker注解激活了熔断功能,那么该注解就是Hystrix源码追踪的入口
@EnableCircuitBreaker注解激活熔断器
查看EnableCircuitBreakerImportSelector类 继续关注父类 SpringFactoryImportSelector spring.factories文件内容如下 会注入org.springframework.cloud.netflix.hystrix.HystrixCircuitBreakerConfiguration 关注切面:com.netflix.hystrix.contrib.javanica.aop.aspectj.HystrixCommandAspect 重点分析环绕通知方法 GenericCommand中根据元数据信息重写了两个很核心的方法,一个是run方法封装了对原始目标方法的调用,另外一个是getFallBack方法它封装了对回退方法的调用另外,在GenericCommand的上层类构造函数中会完成资源的初始化,比如线程池
GenericCommand —>AbstractHystrixCommand—>HystrixCommand—>AbstractCommand 接下来回到环绕通知方法那张截图 进入execute执行这里 另外,我们观察,GenericCommand方法中根据元数据信息等重写了run方法(对目标方法的调用),getFallback方法(对回退方法的调用),在RxJava处理过程中会完成对这两个方法的调用。
安装tomcat之前得先安装jdk,jdk在麒麟系统一般是已经安装好了得。
2,从官网下载tomcat源码包
地址:https://tomcat.apache.org/
3,解压
tar -xvf apache-tomcat-10.0.tar.gz
4,移动到java目录下
mv apache-tomcat-10.0 /usr/local/java/tomcat
5,启动服务
1.计算阶乘相加 1!+2!+……+10! 如果你不会n的阶乘计算方法 先了解n的阶乘的计算 n的阶乘计算代码介绍
观看完n的阶乘计算方法,那么开始入手正题 效率低,但好理解的代码 #include<stdio.h> int main() { int ret=0; for(int n=0;n<=10;n++) { int sum=1; //将sum放在循环的里面,每次计算阶乘都 //要初始化为1; for(int a=1;a<=n;a++) { //计算单个数的阶乘 sum *=a; } ret=ret+sum; //将所有计算的单个数的阶乘相加 } printf("%d",ret); return 0; } 两次for循环,内层for循环算单个数的阶乘,外层for循环将所得到的阶乘相加 ;切记,这里的sum要放在循环里面,要保证sum每次都初始化为1.
效率高的代码 思想:
1!=1
2!=2 * 1 =2 * 1!
3!=3 * 2 * 1 = 3 *2!
每一个数乘前一个数的阶乘就是自己本身的阶乘
#include<stdio.h> int main() { int sum=1; int ret=0; for(int a=1;a<=10;a++) { sum *= a; ret +=sum ; } printf("
git上有develop分支,branch查看分支看不到develop,checkout切换分支报错
一、问题 git上有develop分支,branch查看分支看不到develop,checkout切换分支报错
(一)branch查看分支 git branch -a 结果:看不到develop分支。
(二)checkout切换分支 git checkout develop 结果:报错error: pathspec 'develop' did not match any file(s) known to git.
二、解决方案 先fetch更新分支再checkout切换分支(由于远程分支是新建的,本地没有更新)
(二)fetch更新远程分支 git fetch (二)checkout切换分支- git checkout develop
目录
Input输入事件绑定
轴映射与动作映射:SetupPlayerInputComponent
编辑器设置对应名称、代码设置响应事件,实现具体动作
C++设置添加轴和动作映射
碰撞检测事件绑定
碰撞对象通道与预设
碰撞响应设置:是否模拟物理碰撞以及触发Overlap事件
碰撞响应类型:Blokc、Overlap、Ignore
C++实现
定时器Timer与事件绑定
设置定时器:SetTimer
清空定时器:ClearTimer
暂停和恢复:PauseTimer和UnPauseTimer
判断是否活跃且未暂停:IsTimerActive
获取定时器速率:GetTImerRate
获取经过时间和剩余时间:GetTimerElapsed & GetTimerRemaining
虚幻引擎中的碰撞响应参考 | 虚幻引擎5.0文档 (unrealengine.com)
变量、定时器和事件 | 虚幻引擎5.0文档 (unrealengine.com) 虚幻引擎中的Gameplay定时器 | 虚幻引擎5.0文档 (unrealengine.com)
Input输入事件绑定 轴映射与动作映射:SetupPlayerInputComponent 编辑器设置对应名称、代码设置响应事件,实现具体动作 绑定名称及事件,Action还需绑定按键 void AMyCharacter::SetupPlayerInputComponent(UInputComponent* PlayerInputComponent) { Super::SetupPlayerInputComponent(PlayerInputComponent); PlayerInputComponent->BindAction("DropItem", EInputEvent::IE_Pressed, this, &AMyCharacter::DropItem); PlayerInputComponent->BindAction("Jump", IE_Pressed, this, &AMyCharacter::Jump); PlayerInputComponent->BindAxis("MoveForward", this, &AMyCharacter::MoveForward); PlayerInputComponent->BindAxis("MoveRight", this, &AMyCharacter::MoveRight); PlayerInputComponent->BindAxis("PitchCamera", this, &AMyCharacter::PitchCamera); PlayerInputComponent->BindAxis("YawCamera", this, &AMyCharacter::YawCamera); } 事件:
void AMyCharacter::MoveForward(float AxisValue) { MovementInput.X = FMath::Clamp<float>(AxisValue, -1.
C#虚拟键盘的实现 前言一、通过Keybd_event实现1.keybd_event函数 简介2.虚拟键码对照表3.函数使用4.代码实例 二、使用winio模拟键盘硬件扫描码(暂未复现)三、使用钩子(Hook)(暂未复现) 前言 在工作中,使用到触摸屏外接键盘不方便的情况,需要上位机调用虚拟键盘完成输入操作,在此做记录分享。网上有很多种方法,我将再实践后陆续更新在这里。
一、通过Keybd_event实现 1.keybd_event函数 简介 微软官方文档地址
合成击键。系统可以使用这种合成的击键来生成WM_KEYUP或WM_KEYDOWN消息。键盘驱动程序的中断处理程序调用keybd_event函数。
原型如下:
void keybd_event( [in] BYTE bVk, [in] BYTE bScan, [in] DWORD dwFlags, [in] ULONG_PTR dwExtraInfo ); 参数:
bvk : 虚拟钥匙代码。代码必须是介于 1 到 254 之间的值。完整列表虚拟键代码。
bScan:定义该键的硬件扫描码;
dwFlags:控制功能操作的各个方面。此参数可以是以下一个或多个值;
定义数值意义KEYEVENTF_KEYDOWN0x0000键被按下KEYEVENTF_EXTENDEDKEY0x0001指示这个键是否是扩展键KEYEVENTF_KEYUP0x0002键被释放 dwExtraInfo: 与击键关联的附加值。(暂时不知道用处,一般常为0)
PS:
微软键接受结构与扩展标志
硬件扫描码:当用户按下某个键时,
’ 1.键盘会检测到这个动作,并通过键盘控制器把扫描码(scan code)传送到计算机;
’ 键盘扫描码跟具体的硬件有关的,不同厂商对同一个键的扫描码有可能不同。
’ 2.计算机接收到扫描码后,将其交给键盘驱动程序;
’ 3.键盘驱动程序把这个扫描码转换为键盘虚拟码;
’ 虚拟码与具体硬件无关,不同厂商的键盘,同一个键的虚拟码总是相同的。
’ 3.然后,键盘驱动程序把该键盘操作的扫描码和虚拟码以及其它信息传递给操作系统;
’ 4.操作系统将获得的信息封装在一个键盘消息中,并把该键盘消息插入到消息列队。
’ 5.通过Windows的消息系统,该键盘消息被送到某个窗口中;
’ 6.窗口所在的应用程序接收到消息后,可以了解到有关键盘操作的信息,然后决定作出一定的响应
扩展键:扩展键标志指示击键消息是否源自增强型 101/102 键键盘上的附加键之一。 扩展键由键盘右侧的 Alt 和 Ctrl 键组成:数字键盘左侧的 INS、DEL、HOME、END、PAGE UP、PAGE DOWN 和箭头键;NUM LOCK 键;BREAK (CTRL+PAUSE) 键;PRINT SCRN 键;和数字键盘中的除号 (/) 和 ENTER 键。 右侧 SHIFT 键不被视为扩展键,而是具有单独的扫描代码。
微信公众号:运维开发故事,作者:乔克
在Kubernetes中,Pod是最小的管理单元,是一组紧密关联的容器组合。
但是,单独的Pod并不能保障总是可用,比如我们创建一个nginx的Pod,因为某些原因,该Pod被意外删除,我们希望其能够自动新建一个同属性的Pod。很遗憾,单纯的Pod并不能满足需求。
为此,Kubernetes实现了一系列控制器来管理Pod,使Pod的期望状态和实际状态保持一致。目前常用的控制器有:
Deployment
StatefulSet
DaemonSet
Job/CronJob
这里只介绍Deployment、DaemonSet、Job/CronJob。StatefulSet留到后面Kubernetes有状态应用管理章节再来介绍,因为它涉及到很多其他的知识点,比如Service、PV/PVC,等这些知识点介绍完成过后再来说StatefulSet要好一点。
Deployment 在说Deployment之前,先来了解一下ReplicaSet(RS)。
在Kubernetes初期,是使用RC(Replication Controller)来控制Pod,保证其能够按照用户的期望运行,但是后面因为各种原因淘汰了RC,转而使用RS来替代它。从功能上看RC和RS没多大的变化,唯一的区别RS支持集合的Selector,可以方便定义更复杂的条件。
我们可以定义一个简单的ReplicaSet来感受一下:
apiVersion: apps/v1 kind: ReplicaSet metadata: name: nginx-set labels: app: nginx spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: name: nginx labels: app: nginx spec: containers: - name: nginx image: nginx 创建结果如下:
$ kubectl get po NAME READY STATUS RESTARTS AGE nginx-set-hmtq4 0/1 ContainerCreating 0 2s nginx-set-j2jpr 0/1 ContainerCreating 0 2s $ kubectl get rs NAME DESIRED CURRENT READY AGE nginx-set 2 2 0 5s 可以看到我们期望replicas: 2创建2个Pod,所以通过kubectl get pod的时候可以看到有2两个Pod正在创建,这时候如果我们删除一个Pod,RS会立马给我们重新拉一个Pod,以满足我们的期望。
在官方博客 Registration and Login (Authentication) with Vue.js and Strapi 中演示如何实现注册与登录。实际重点部分是 Strapi 的角色和权限插件,可以说这个插件让开发者不用再为项目考虑的用户登录注册与鉴权相关。
创建 Strapi 项目 这里省略创建 strapi 项目创建过程,具体可到 Quick Start Guide 中查看。创建完项目,并注册管理员账号后,打开管理面板,根据自己需求创建数据。下面会介绍下管理面板的一些操作(以下针对中文面板)
角色列表 打开 设置 => 用户及权限插件 => 角色列表
默认有两个角色 Authenticated 与 Pubilc,都不可删除,其中还有一个 Admin 是我自己创建的角色,用于分配管理员的权限。
Authenticated 对应的也就是登录后的角色,即携带 Authorization 协议头携带 jwt 的用户。
另一个 Pubilc 则是未授权用户,默认权限如下
权限分配 双击角色可以到权限分配页面,比方说我想给 Authenticated 角色分配 Restaurant 表中查询数据,就可以按照如下选项中勾选,并且勾选其中一个权限(增删改查)可以在右侧看到对应的请求 api 接口(路由)
默认角色 可以在 设置 => 用户及权限插件 => 高级设置 中分配默认角色,此外这里还可以配置注册,重置密码等操作。对于这些功能而言,传统开发就需要编写相当多的代码了,而 Strapi 的 角色和权限 插件能省去开发这一部分功能的时间。
管理员权限 在 设置 => 管理员权限 也可以看到角色列表与用户列表,不过这个只针对登录 strapi 仪表盘的用户,与实际业务的用户毫不相干。通俗点说就是数据库系统的用户与后台管理系统用户的区别。
收到的cookie头包含无效的cookie tomcat
我正在将服务器从 Tomcat-6* 迁移 到 Tomcat-9 。我的网站是为HTTP /
1.1协议设计的。server.xml文件包含 org.apache.coyote.http11.Http11NioProtocol
的连接器协议。服务器正常启动,不会产生任何错误。但是,当我尝试使用localhost访问我的网站时,出现以下错误:- *
INFO [https-nio-8445-exec-3]
org.apache.tomcat.util.http.parser.Cookie.logInvalidHeader 收到Cookie标头[
2,3,4,5,6,7,8,9,10 ,11,12,21,22,23]; userId =
53136]包含无效的cookie。该cookie将被忽略。注意:此错误的进一步发生将在DEBUG级别记录。
处理方式: 要消除警告,必须LegacyCookieProcessor在tomcat
config(conf/context.xml)中更新cookie处理器()
cat /usr/local/apache-tomcat-8.5.12/conf/context.xml <?xml version="1.0" encoding="UTF-8"?> <!-- The contents of this file will be loaded for each web application --> <Context> <WatchedResource>WEB-INF/web.xml</WatchedResource> <WatchedResource>${catalina.base}/conf/web.xml</WatchedResource> <!-- <CookieProcessor className="org.apache.tomcat.util.http.Rfc6265CookieProcessor" /> --> <CookieProcessor className="org.apache.tomcat.util.http.LegacyCookieProcessor" /> </Context>
安装使用以下命令: 安装:brew install redis 安装后的目录是:/usr/local/bin 启动redis:redis-server 停止redis:redis-cli shutdown 设置后台运行 sudo vim /usr/local/etc/redis.conf 搜索文件找到:daemonize no这一行,修改为:daemonize yes 启动redis并查看启动进程 #后台方式启动 redis-server /usr/local/etc/redis.conf 查看启动进程 ps aux | grep redis 进入客户端调用 redis-cli
LE Audio进入商用阶段,TWS耳机要变天了-36氪
蓝牙协议十年来的最大更新,LE Audio进入商用测试阶段。
全球最畅销的IoT设备是什么?我很轻松就能告诉你答案:AirPods。作为开启新时代的一款产品,AirPods诞生后的短短数年里,TWS(True Wireless Stereo 真正的无线立体声)耳机迅速占领了个人音频市场,成为最受欢迎耳机类产品。
相关统计数据显示,2022年的第一季度全球的TWS耳机出货量达6820万台,对比2021年增长了17%,其中苹果的市场份额占比为31.8%,出货量2170万台。在数码消费市场大多数品类都陷入增长停滞甚至倒退的情况下,TWS耳机市场仍然表现出了惊人的潜力。
图片来源:网络
目前的TWS耳机并不算完善,因为传统的蓝牙通讯协议在信息传输密度、速率、延迟和稳定性等方面都有不少的缺陷,这些基于基础通讯协议所遗留的问题也导致TWS耳机的体验一直受到约束。
而蓝牙音频协议的救星在经过两年多的酝酿后,终于要与大家见面了,它就是LE Audio。
Bluetooth LE Audio是什么? Bluetooth LE Audio最早在2019年的蓝牙5.2版本上就作为核心协议登场,大家可以注意到从2021年开始就有不少支持蓝牙5.2协议的TWS耳机开始上市,并且均宣传自己拥有极低的延迟(对比蓝牙5.1),可以实现“电竞级”的延迟参数。
相较于上一代协议普遍在100-200ms间的延迟,蓝牙5.2的延迟可以达到100ms以下,确实是可以满足游戏玩家对延迟的要求。让蓝牙5.2的延迟表现得到极大提升的核心因素就是Bluetooth LE Audio协议,虽然蓝牙5.2仅仅是应用了Bluetooth LE Audio中关于蓝牙LE链路层的传输Audio方式,却也直观的改变了延迟上的表现。
作为全新的无线传输协议,LE Audio对比现在的通用协议SBC在各方面都有显著的升级,主要的升级在三个方面。
首先是功耗方面,LE Audio有着更低的功耗要求,降低对电池等硬件的需要,让TWS耳机可以做到更小的体积,而在其它硬件不变的情况下,采用LE Audio协议的TWS耳机续航则会得到明显提升。
其次是更高质量、高效率的LC3音频解码器,在相同传输速率的情况下可以传输比SBC更多的数据,在相关机构发布的测试结果中,LE Audio仅用192Kbps的传输速率就在音频质量得分上超过了SBC以345Kbps速率传输的成绩。
图片来源:蓝牙技术联盟
在传输速率方面,虽然LE Audio与aptX、LDAC等安卓主流无损传输协议还有一定差距,但是传输质量也会明显领先SBC及AAC两种通用协议。同时也是得益于更高的编码效率和多音频流的优化,LE Audio能够实现最低20ms的无线延迟,该数据已经优于LDAC和aptX在最佳状态下的表现。
最后是广播音频扫描服务,这个服务是LE Audio的特色,让用户可以将蓝牙音频信号进行大范围广播,在接受范围内且耳机支持LE Audio协议的用户,都可以通过手机接入音频传输服务中,获得主机提供的音频信息。
图片来源:官网
对,某种程度上与我们日常接入WiFi时的情景十分相似,当LE Audio普及后,我们在诸如图书馆、博物馆等场所中,可以通过这个功能直接接受到来自演讲者或讲解员的语音信息,得到更清晰的语音服务。
此外,在机场等交通枢纽中,LE Audio的音频广播同样有着不错的未来,用户可以让耳机分别接入手机等移动设备和交通场所的音频广播信道,在听歌解闷的同时也不用担心会错过关键信息,比如登机时间、检票时间等。
LE Audio对比上一代的蓝牙协议,在许多用户痛点上都做出了改善,针对一些未来的应用场景也提前进行了相关的部署。从用户体验来说,即使不考虑LE Audio在音频质量上的提升,其它功能的体验提升也一样会给用户带来明显的感知。
LE Audio什么时候上市? 实际上,在前段时间发布的红米Note 10 Pro上,Redmi就开放了LE Audio协议的支持,只需要搭配Redmi AirDots 3 Pro即可启用,算是业内首个采用LE Audio音频方案的成熟产品,虽然这套搭配依然不是完全体,依然能够提供69ms的低延迟效果。
当然,从安卓阵营的角度来看,LE Audio带来的改变并不算大,毕竟不管是LDAC还是aptX都拥有超越LE Audio的传输速率,能够更好的满足无损音乐播放要求。至于延迟方面,对于大多数用户来说感知并不大,主要影响的还是FPS手游玩家的体验。
不过对于苹果用户来说,LE Audio就是救星般的存在,根据相关信息人士的爆料,苹果已经验证并决定将LE Audio协议应用到下一代的H2芯片上,而H2芯片据悉将与AirPods Pro(第二代)一起发布。
对于AirPods用户来说,长达六年的“有损音乐”体验,终于要告一段落了。
虽然AirPods是TWS耳机市场的开创者,但是在技术进步上却一直处于停滞状态,不提空间音频这些计算音频领域的升级,单就硬件来说,AirPods使用的芯片已经5年没有进行更新,从AirPods(第一代)到后续的AirPods Pro、AirPods(第二代)和AirPods(第三代)均采用H1芯片。
图片来源:官网
硬件层面的限制以及一些客观原因的影响下,AirPods系列一直都无法支持无损音频传输协议,以至于Apple Music虽然拥有最高码率的在线音乐播放服务,但是AirPods却无法体验,即使在软件中选择了高解析度无损,实际传输到AirPods的依然是有损格式,徒增网络流量消耗。
首先看官网解释:
resetFields对整个表单进行重置,将所有字段值重置为初始值并移除校验结果 解决方案:
编辑打开弹窗时,在$nextTick中给model赋值,此时Dialog已经初始化(已经mounted), 会慢一步赋值,所以form表单的初始值全部为data中的空值
this.$nextTick(() => {
this.curItem = JSON.parse(JSON.stringify(row))
}
弹性布局
要布局的子元素的父元素称之为容器,容器中写
display:flex //将块级元素变为容器 display:inline-flex //将行内元素变为容器 弹性容器的样式属性
flex-direction:row //默认值,主轴是X轴,主轴起点在左端 flex-direction:row-reverse //主轴是X轴,主轴起点在右端 flex-direction:column //主轴是Y轴,主轴起点在顶端 flex-direction:column-reverse //主轴是Y轴,主轴起点在底部 当一个主轴排列不下所以项目时,项目的显示方式
flex-wrap:nowrap //默认值,空间不够,不换行,项目会自动压缩 flex-wrap:wrap //空间不够,就换行,项目不压缩 flex-wrap:wrap-reverse //换行,反转 定义项目在主轴上的对齐方式
justify-content:space-between //两端对齐 justify-content:space-around //每个间距相同 justify-content:flex-start //默认值,在主轴起点对齐 justify-content:flex-end //在主轴的终点对齐 justify-content:center //在主轴上居中对齐 定义项目在交叉轴的对齐方式
align-items:flex-start //交叉轴起点对齐 align-items:flex-end //交叉轴终点对齐 align-items:center //交叉轴居中对齐 align-items:baseline //交叉轴基线对齐 align-items:stretch //如果项目未设置高度,在交叉轴上充满容器 全局滚动条样式
<style> #nprogress .bar{ background-color: #f4f4f4!important; height: 3px!important; } ::-webkit-scrollbar{ //滚动条整体部分,其中的属性有width,height,background,border等 width: 4px; height: 6px; } ::-webkit-scrollbar-corner{ //边角,两个滚动条交汇处 display: block; } ::-webkit-scrollbar-thumb{ //滚动条里面可以拖动的那部分 border-radius: 8px; background-color: rgba(0, 0, 0, 0.
想在windows安装docker的时候,需要windows电脑开启Hyper-V的功能,可是我打开电脑的程序与功能无法找到Hyper-V的选项,就很奇怪:
后来找到一种方法即可解决该问题:
首先打开电脑的powershell,输入:systeminfo查看电脑是否支持Hyper-V:
可以看到该电脑支持Hyper-V,随后我们在桌面新建一个文本文档,输入此段代码:
pushd "%~dp0" dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txt for /f %%i in ('findstr /i . hyper-v.txt 2^>nul') do dism /online /norestart /add-package:"%SystemRoot%\servicing\Packages\%%i" del hyper-v.txt Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALL 然后将文本文档后缀改成.bat,用管理员程序运行即可安装Hyper-V:注意bat的命名不要中文,英文即可:
随后等待安装完成,大概5分钟,提示重启电脑即可完成:
-----------------金鳞岂是池中物,一遇成风变化龙
Ts初次学习并使用node运行TS文件 node.js直接运行js,在运行ts时会报错。
//使用 ts-node包,“直接”在Node.js中执行 TS 代码,ts-node并不会生成 JS 文件 //全局安装ts-node //安装命令:npm i -g ts-node(ts-node包提供了ts-node命令)。 //查看版本:ts-node -v //运行ts文件 ts-node helloword.ts
1、问题 数据库中字段
新建一个项目,拷贝之前的,测试实体类字段不一致的情况
package com.gt.pojo; public class User { private int id; private String name; private String password; public User() { } public User(int id, String name, String password) { this.id = id; this.name = name; this.password = password; } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getPassword() { return password; } public void setPassword(String password) { this.
本文有配套视频教程
项目面核心问题回答思路 说说你最近的项目 记叙文的六要素:时间、人物、地点、起因、经过、结果;时间:研发周期;人物:团队成员、分工、我负责哪几个模块;起因:项目背景、项目的用户是谁、用户能用这个App干啥、基本业务逻辑描述;经过:我负责哪几个模块,主用的技术栈是…,结果:1.0耗时多久上线、目前处于何种状态;项目亮点:最好有并且输出10分钟; 你负责哪些模块? 先下载一个业务极其相近的App在自己的手机上;对着该蓝本App玩烂、充分脑补,而不要对着空气脑补;该蓝本App的各种菜单、导航、页面跳转按钮…就是所谓【模块】;信手一划拉就有十几个模块备选(不要来来回回就是登录、网络通信、路由跳转…)从以上模块中找几个你最能脑补出东西的模块来,号称是自己做的; 讲讲XX模块的实现细节 业务功能是什么?事先玩透、脑补透;静态组件布局 + 网络通信获取数据 + 动态渲染 + 事件交互 + 后期优化;静态布局部分:核心组件,给核心组件传递的主要props与callback(组件与通信)网络通信:axios三层封装 + vuex/redux的数据缓存;事件交互:可能有基于antd/elementPlus的二次封装(初中级)、自定义组件库(中高级);后期优化:性能优化 + 复用提取(Vue和React如何复用逻辑) 为每个模块事先准备一些物料:
二次封装的组件若干(有明确的名字与逻辑)自定义Hook若干自定义指令若干HOC/RenderProp若干; 有什么亮点? 性能方面:性能优化25条复用方面:mixin,自定义指令,自定义hook,HOC,RenderProp,自定义组件(二次封装/自定义组件库) 有什么难点? 不一而足,请为最近的两个项目各自准备一个难点;(至少能输出20分钟) 怎么做的优化? 性能方面:性能优化25条(简单:至少输出30分钟)复用方面:mixin,自定义指令,自定义hook,HOC,RenderProp,自定义组件(二次封装/自定义组件库)(略难:尽量准备) @之前团队的工作流程 立项阶段 老板+产品+技术总监一起论证某产品的可行性产品出《需求文档》+《需求原型》 *PS:需求原型的形态通常是网页上的简单交互与跳转,或手机App上的简单交互与跳转,产品使用的原型制作工具(Axure/墨刀等)能自动生成一个临时的App二维码,扫码即可安装
开发阶段 美术按照需求原型设计界面,生成《效果图》与此同时前后端共同协商,生成前后端通信的《接口文档》前后端根据《接口文档》分头开发前端组长创建工程并推送远程,添加开发者账号,组员克隆项目组员在各自的分支上开发不同功能(通常按页面分工最容易衡量各自的责权利)前端根据《效果图》制作静态页面前端将静态页拆分为组件化结构前端自己部署mock数据(json/json-server/fast-mock等皆可)前端与自己的mock-server进行网络通信,完成数据交互与其它业务功能后端的接口开发完成后,前端将网络框架中的BASE_URL由mock-server改为真实后端服务器地址前后端共同联调直至前后端功能开发完毕 测试阶段 各功能分支合并到dev分支,再基于dev分支拉出一个test分支,打包到测试环境服务器,提交测试测试人员提交BUG到【禅道/Jira】等BUG管理平台上组长将BUG分配给不同的个人进行修复持续修复BUG并提交测试【致命】+【严重】+【一般】级别的BUG确认修复完毕后(测试人员需要签字),可以考虑上线 上线阶段 手动上线流程:master分支合并dev分支,打包并上传到生产服务器上的Nginx部署目录下,上线完成持续集成(CI/CD)上线流程:master分支只要一提交,即自动触发运维脚本(运维同学所写),该脚本执行npm run build并将产出目录上传覆盖到Nginx的部署目录,上线完成 升级/维护阶段 重复上述流程,即:产出新需求 + 产出新界面 + 产出新接口 + 产出新代码 + 测试通过 + 再次上线 @项目上线后出现bug怎么去解决? 更新master分支 git checkout master git fetch git merge origin/master 从master分支拉出修复BUG的分支 git checkout -b hotfix-bugid 在该分支上修复BUG并提交 git add .
一、CentOS上查找IP连接Linux客户端 下载好虚拟机上并安装Linux之后输入指令查找IP地址:
# 查看ip地址 ip a ip addr 当查不到IP地址时,输入以下指令查找到对应的 ens33网卡配置:
输入vi /etc/sysconfig/network-scripts/ifcfg-ens33(vi后加空格) 将NOBOOT的权限改为yes, 再按住ESC退出,之后再次输入:wq,再按Enter。
输入指令重启网络服务,看到[ok]即配置成功:
sudo service network restart 下载好mobaxterm创建session的ssh连接:
输入IP地址和用户名称创建连接:
输入密码连接:
本文介绍记录在web api中实现 上传和下载。
编程环境:VS2022
框架:NET6.0
1、创建.net6 web api 项目
IFileService.cs
namespace WebApplication1.service { public interface IFileService { void UploadFile(List<IFormFile> files, string subDirectory); (string fileType, byte[] archiveData, string archiveName) DownloadFiles(string subDirectory); string SizeConverter(long bytes); } } FileService.cs
using System.IO.Compression; namespace WebApplication1.service; public class FileService : IFileService { #region Property private readonly IWebHostEnvironment _webHostEnvironment; #endregion #region Constructor public FileService(IWebHostEnvironment webHostEnvironment) { _webHostEnvironment = webHostEnvironment; } #endregion #region Upload File public void UploadFile(List<IFormFile> files, string subDirectory) { subDirectory = subDirectory ?
在这里给大家总结一下c语言常见的占位符。
%d 整型int
%ld 长整型long (int)//long是long int的简写方式
%lld 长长整型long long (int)
%hd 短整型short int
%u 无符号整型unsigned int
%hu 无符号短整型unsigned short int
%lu 无符号长整形unsigned long int
%llu 无符号长长整型unsigned long long
%f 浮点型float
double比较特殊,它的输入占位符是%lf,输出只能是%f
%e(E) 以指数形式表示的浮点型
%m.nf 可控制输出小数位数,具体见此博客目录中最后一条(因为这个也是我自己的博客所以在这里不要在意版权问题)
http://t.csdn.cn/PCr0X
//浮点型也有长短型,可以参考整型
%c 字符型char
%s 字符串
%o 以八进制输出
%x 以16进制输出
%p 变量地址
%i 结构体输出
涉及的数据比较多,写一个过滤器,将所有的数据都过滤一下,挂载到全局,不需要每个页面引用了。
创建一个js文件,实现数字千位分隔符
export function numberToCurrencyNo(value) { if (!value) return 0 // 获取整数部分 const intPart = Math.trunc(value) // 整数部分处理,增加, const intPartFormat = intPart.toString().replace(/(\d)(?=(?:\d{3})+$)/g, '$1,') // 预定义小数部分 let floatPart = '' // 将数值截取为小数部分和整数部分 const valueArray = value.toString().split('.') if (valueArray.length === 2) { // 有小数部分 floatPart = valueArray[1].toString() // 取得小数部分 return intPartFormat + '.' + floatPart } return intPartFormat + floatPart } 引用挂载到全局
在 main.js 文件中引入
import { numberToCurrencyNo } from '@/utils/numberToCurrency' // 配置全局过滤器,实现数字千分位格式 Vue.
Connect the console to enter the settings
Enter view mode
system-view
Set switch name
system hostname
Exit view mode
quit
Set telnet login
system-view
Enable telnet
telnet server enable
View of incoming vty subscriber line
line class vty
Enter one or more vty subscriber line views
line vty 1 50
Set the authentication mode of the login user as password login
authentication-mode password
Set password for password authentication ⽂ password "
Redis持久化方案 Redis有两种数据持久化方案
RDB持久化AOF持久化 1、RDB持久化 RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。快照文件称为RDB文件,默认是保存在当前运行目录。
1.1、执行时机 执行save命令执行bgsave命令Redis停机时触发RDB条件时 (1)save命令
执行save命令,redis会立即执行一次RDB。save命令会导致主进程执行,因为redis执行是单线程,所以这个过程其他所有命令都会被阻塞。只有在数据迁移时可能用到。
(2)bgsave命令
执行这个命令会异步执行RDB。这个命令会开启独立进程(子进程)完成RDB,主进程可以继续处理用户请求,不受影响。
(3)停机时
Redis停机时会执行一次save命令,实现RDB持久化。
(4)触发RDB条件
Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:
# 第一条命令意思为900秒内,如果至少有1个key被修改,则执行bgsave ,( 如果是 save "", 则表示禁用RDB) save 900 1 save 300 10 save 60 10000 关于RDB的其它配置也可以在redis.conf文件中设置:
# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱 rdbcompression yes # RDB文件名称 (即记录数据的文件) dbfilename dump.rdb # 文件保存的路径目录 dir ./ 1.2、RDB原理 bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。
fork采用的是copy-on-write技术:
当主进程执行读操作时,访问共享内存;当主进程执行写操作时,则会拷贝一份数据,执行写操作。
注:子进程复制的是父进程的页表从而通过页表去映射实际的物理内存来操作数据,而当fork的过程中,物理内存的数据是只读状态(read-only),主进程想要写操作时,对应的则是copy-on-wirte技术,即复制一份要操作的数据,在操作,后续的读同样读当前操作后的数据。
1.3、RDB总结 RDB方式bgsave的基本流程?
fork主进程得到一个子进程,共享内存空间子进程读取内存数据并写入新的RDB文件用新RDB文件替换旧的RDB文件 RDB会在什么时候执行?save 60 1000代表什么含义?
默认是服务停止时代表60秒内至少执行1000次修改则触发RDB RDB的缺点?
RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险fork子进程、压缩、写出RDB文件都比较耗时 2、AOF持久化 2.1、AOF原理 AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。 类似于MySQL的二进制文件
内容简介 Windows10 系统安装 MySQL 8.0,建议安装Zip压缩包版,这样配置过程熟悉了之后,后续更新升级会比较方便。 本文以 Windows 10 举例,Windows 11 同样适用。
如果是 Windows 2012 或者 Windows 2016/2019/2022 等 Windows Server 服务器操作系统,方法是一样的,区别只是在 Path 设置稍有不同。
1.下载 MySQL
首先在官网下载 MySQL 8.0.30,下载网址是:MySQL :: Download MySQL Community Server
在页面里找到 Windows (x86, 64-bit), ZIP Archive,点击后面的 Download。
会弹出登陆页面,其实无需登陆的,直接点击下面的 No thanks, just start my download. 就可以。
下载下来,是一个名字类似于 mysql-8.0.30-winx64.zip 的 Zip压缩包。
2.将 mysql-8.0.30-winx64.zip 压缩包解压出来
这里我在D盘新建了一个 Web-Soft 文件夹,解压到 D:\Web-Soft\mysql-8.0.30-winx64 文件夹里。
3.设置 Path 环境变量
选中 此电脑→右键→属性→高级系统设置→环境变量。(Win10 21H2为例)
在 环境变量 对话框,从 系统变量 栏里找到 变量 Path,然后点编辑,打开 编辑环境变量 对话框。
准备工作
1、将需要转换的工程下载到本地
2、配置qmake环境变量,确认对应的qt版本。找到qt目录下qmake.exe的绝对路径,将其添加到系统变量中。
3、生成命令 qmake [mode] [options] [files]
注:具体命令使用方法可以通过 命令行输入qmake -h
默认生成VS版本
默认情况下,即环境变量qmakespec为你装的qt for vs的版本,默认生成的为该版本的vs工程文件。例如,你装的是QT for vs2010,环境变量qmakespec=win32-msvc2010,默认情况下生成的是vc2010的工程文件。
1)如果项目.pro文件中 TEMPLATE = subdirs时,
qmake -r -tp -vc ***.pro 2)如果项目.pro文件中 TEMPLATE 值为其他时,
qmake -tp -vc ***.pro 指定生成vs 版本 qmake -spec win32-msvc2017 -tp vc ***.pro 开始编译
1、在项目pro文件同级目录下,按下shift+鼠标右键,选择命令行打开
2、命令行输入qmake -tp -vc ***.pro
注:报错:找到cl.exe 设置环境变量 3、重新打开命令行输入编译命令
转自:
Java Math.sqrt()具有什么功能呢?
下文笔者将讲述Math.sqrt()方法的功能简介说明,如下所示:
Math.sqrt()方法的功能: 用于返回参数的算数平方根 -------------------------------- Math.sqrt()语法 double sqrt(double d) 参数说明 d:待求平方根的double数值 返回值说明 返回参数的算术平方根 例
public class TestClass{ public static void main(String args[]){ double x = 89.22; double y = 6.43; System.out.printf("e 的值为 %.4f%n", Math.E); System.out.printf("sqrt(%.3f) 为 %.3f%n", x, Math.sqrt(x)); } } -----运行以上代码,将输出以下信息----- e 的值为 2.7183 sqrt(89.220) 为 9.446
NVMe 【参考资料】1、NVMe扫盲;2、NVME协议解读(一);3、NVMe协议SSD 控制器端实现浅析(一);4、NVMe解读
目录
文章目录 NVMe一、概述1.1 什么是NVMe1.2 高性能&低延迟1.3 名词&术语 二、NVMe命令2.1 命令通用格式2.2 两类命令2.2.1 Admin Command2.2.2 IO Command(NVM Command) 2.3 SQ、CQ、DB2.4 命令的执行过程 三、多命令队列与仲裁机制3.1 NVMe多命令队列3.2 多命令队列的仲裁机制3.2.1 RR3.2.2 带有优先权的RR 四、内存寻址4.1 PRP方法4.2 SGL方法4.3 PRP 与 SGL 的比较 五、NVMe SSD Controller 物理架构(了解)5.1 概念模型5.2 子模块5.3 NVMe主机接口控制器 一、概述 1.1 什么是NVMe Non-Volatile Memory Express(非易失性存储器标准)NVMe是面向PCIe SSD制定的标准接口协议,用于访问通过PCIe总线附加的SSD(可适用于各种支持PCIe总线的物理插槽上)定义了NVMe协议的使用范围、指令集、寄存器配置规范等具有良好的可拓展性、低延迟,低能耗,高性能等优点 PCle:Peripheral Component Interconnect Express,周边设备高速连接标准。是一种端对端的互连协议,提供了高速传输带宽的解决方案。其协议内容主要是物理层和数据链路层的。
另一个常用的相关协议是AHCI,AHCI主要是针对高延时的SATA接口的机械硬盘而设计的
1.2 高性能&低延迟 面向PCIe SSD产品的NVMe标准能有效降低控制器和软件接口部分的延迟,是因为:
能让SSD走PCI-E通道直连CPU,有效降低了数据延迟NVMe执行命令时则不需要读取寄存器 NVMe还能大大提高SSD的IOPS性能。理论上,IOPS=队列深度/ IO延迟,所以增加队列深度,就可以有效提升SSD的IOPS。
传统的ACHI标准下队列深度最多能达到32在NVMe标准下,这一数值可以达到64000 此外NVMe还加入了自动功耗状态切换、动态能耗管理、免驱等功能,驱动适应性广,低功耗
1.3 名词&术语 1、Namespace
Namespace是一定数量逻辑块(LB)的集合其属性在Identify Controller中的数据结构中定义 逻辑块:NVMe定义的最小的读写单元,2KB、4KB……,用LBA来标识块地址
LBA range:表示物理上连续的逻辑块集合
2、Fused Operations
目录
1.Filter概念
2.Filter 快速入门
3.Filter 执行流程 4. Filter 拦截路径配置
4.1过滤器链(执行顺序)
5.登录验证 5.1创建文件
5.2代码 6.Listener 6.1代码 1.Filter概念 概念:Filter 表示过滤器,是 JavaWeb 三大组件(Servlet、Filter、Listener)之一。
过滤器可以把对资源的请求拦截下来,从而实现一些特殊的功能。
过滤器一般完成一些通用的操作,比如:权限控制、统一编码处理、敏感字符处理等等…
2.Filter 快速入门 3.Filter 执行流程 4. Filter 拦截路径配置 Filter 可以根据需求,配置不同的拦截资源路径
拦截具体的资源:/index.jsp:只有访问index.jsp时才会被拦截。目录拦截:/user/*:访问/user下的所有资源,都会被拦截后缀名拦截:*.jsp:访问后缀名为jsp的资源,都会被拦截拦截所有:/*:访问所有资源,都会被拦截 4.1过滤器链(执行顺序) 5.登录验证 5.1创建文件 注意
问题 解决
//获取request 将ServletRequest强转成HttpServletRequest HttpServletRequest req = (HttpServletRequest) request; //判断访问资源路径是否和登录注册相关 String[] urls = {"/login.jsp","/imgs/","/css/","/loginServlet","register.jsp","/registerServlet","/checkCodeServlet"}; //获取当前访问的资源路径 String url = req.getRequestURL().toString(); //循环判断 for (String u : urls) { if (url.contains(u)){ //找到了 //放行 chain.doFilter(request, response); //放行后,后面的代码就不用执行了 return结束方法 return; } } 5.
如何提交 Pull Request 这里以 Gitee为例
在个人本地创建放置项目代码的目录,然后右键选择 git bash,首次使用时需要对 git 进行配置:使用 git config --global user.name "用户名" 配置用户名 (即 Gitee 上的用户名),使用 git config --global user.email "电子邮箱地址" 配置邮箱 (即 Gitee 上绑定的邮箱)将公共仓库的项目代码 fork 到自己的个人仓库
将个人仓库的代码克隆到本地 (第一步创建的目录),克隆使用 git clone 项目代码的地址 进行操作,克隆完就可以在本地看到相应的项目目录建议在开发时切换到开发分支,使用 git checkout -b 新分支名 创建并切换到新的分支 (当然只是建议)对本地项目代码进行需要的修改继续在 bash 窗口中操作。使用 git commit -s -a 将所做的修改 commit。-s 表示添加部分额外信息;-a 表示将刚刚做的所有修改全部添加到 commit 中。信息通常包含三部分内容,title,message,作者信息,-s 可以自动添加作者信息。commit 回车后出现的是提交信息的编辑界面,使用 vim 编辑器,可以进行修改之后再 commit。完成了 commit 就可以推送到远端分支 (指的是个人仓库) 了使用 git push 命令进行推送,由于提交的分支为远端的 master 分支,所以如果在第 4 步选择切换了其它分支 (如 dev),即远端仓库上没有的分支,那么就会 push 失败,git 会提示使用一个 --set-upstream 选项,跟着它的提示进行操作就可以;而如果没有切换到其它分支还是使用本地的 master 的话,直接 push 就会成功push 后就可以在远端的个人仓库看到刚才的提交在个人远端仓库选择 pull request,可以看到该 PR 的源分支以及目的分支的信息。添加 标题,说明 等内容后,点击创建 PR,就可以在公共主仓下面我们创建的新的 PR,至此 PR 提交成功,等待管理员进行审核即可
目录
1.AJAX
1.AJAX作用:
2.同步与异步
AJAX 快速入门
2.案例
代码
java--后端实现
html--前端
3.Axios 异步框架
Axios 请求方式别名
4.JSON
JSON 基础语法
JSON 数据和Java对象转换
5.查询和新增的案例 1.查询所有
代码
2.新增
1.AJAX 概念:AJAX(Asynchronous JavaScript And XML):异步的 JavaScript 和 XML
1.AJAX作用: 1.与服务器进行数据交换:通过AJAX可以给服务器发送请求,并获取服务器响应的数据
使用了AJAX和服务器进行通信,就可以使用 HTML+AJAX来替换JSP页面了
2.异步交互:可以在不重新加载整个页面的情况下,与服务器交换数据并更新部分网页的技术,如:搜索联想、用户名是否可用校验,等等…
2.同步与异步 在网页中异步请求
AJAX 快速入门 在代码中分析:
2.案例 需求:在完成用户注册时,当用户名输入框失去焦点时,校验用户名是否在数据库已存在
代码 java--后端实现 package com.itheima.web.servlet; import javax.servlet.*; import javax.servlet.http.*; import javax.servlet.annotation.*; import java.io.IOException; @WebServlet("/ajaxServlet") public class AjaxServlet extends HttpServlet { @Override protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { //1.
这个地方网巨慢,在安装numoy时,出现pip安装软件时:raise ReadTimeoutError(self._pool, None, ‘Read timed out.‘) pip._vendor.urllib3.exceptions.错误。
解决方法:
1、在C:\Users\Admin\pip路径下,新建pip.txt文档,拷贝以下
[global] index-url = http://mirrors.aliyun.com/pypi/simple/ [install] trusted-host=mirrors.aliyun.com 2、将文件后缀名改为ini后保存再执行pip
众所周知,在使用夏冰加密软件时,可以为软件设置密码,也就是我们常说的“管理员密码”,那么如果忘记管理密码该怎么办呢?
软件管理员密码 软件管理员密码简单的来说就是进入软件时需要输入的密码,但不光如此,它还有找回文件夹加密密码、个人密盘密码的功能。
注意:只有正式版拥有设置管理员密码的功能哦,试用版软件若有默认密码,在登录时则会进行提示。
管理员密码找回方法 1、双击运行软件,在密码输入框中输入“SOS”,不区分大小写,点击“确定”。
2、在弹窗中输入软件激活码,点击“确定”。
3、这时软件就会显示管理员密码,点击“OK”,即可进入软件。
进入软件后,我们可以根据提示密码,重新设置软件密码,以便更好的记忆。
更多精彩内容,尽在夏冰加密软件:文件加密-文件夹加密-U盘移动硬盘加密-夏冰加密软件
前言 Docker Engine提供RestFul API, Docker Cli通过Restful API和Docker Daemon进行交互,默认情况下,docker cli通过unix通道文件和Daemon进程进行交互,也可以通过docker cli里的--host参数指定,需要通信的Docker远端机器进行交互, --host参数指定,需要进行连接的Docker daemon的监听端口。
默认情况下,Docker的socket tcp端口是没有打开的,只提供本地的unix的通道文件的通信方式。
今天给大家介绍的就是,如何打开Docker的socket通信方式。 在爱上开源之DockerUI系列视频里,给大家介绍DockerUI来进行Docker管理的时候也提到过,这样的启动方式。
修改启动文件 找到启动文件,修改启动文件的运行参数,使其支持TCP通信方式;Docker Daemon应用的方式不同,启动的途径也各不相同,
在Centos7或者以上的Docker环境里
在这个环境下,Docker是通过Systemclt里的服务进行启动的, 在这个环境下,我们就需要修改Docker的启动的service。 [root@CENTOS-01 ~]# systemctl status docker ● docker.service - Docker Application Container Engine Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2022-03-25 05:30:16 CST; 3h 7min ago Docs: https://docs.docker.com Main PID: 315761 (dockerd) Tasks: 47 Memory: 75.8M CGroup: /system.slice/docker.service └─315761 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock -H tcp://0.
python的popen函数的使用,主要是用来执行linux命令。
这种调用方式是通过管道的方式来实现,函数返回一个file-like的对象,里面的内容是脚本输出的内容(可简单理解为echo输出的内容)
使用介绍
import os cmd="ls -la" result_list=os.popen(cmd)#查看当前目录下文件列表 print result_list read() 读取整个文件,并将整个文件放入一个字符串变量中
readline() 每次读取一行,返回一个字符串对象并保留当前行的内存
readlines() 读取整个文件,并将整个文件按行解析成列表
复杂的命令往往需要通过解析获取的数据来得到需要的部分值。通常使用正则匹配,字符过滤等方式。下面介绍几种常用方法:
""" 去除空字符串 """ def not_empty(s): return s and s.strip() """ 在shell终端每行数据中查找固定的字符返回行号 """ def shellfindstrline(cmd,starval): lineNum = 0 try: x = os.popen(cmd).readlines() if x == "" or x == " " or x.isspace() != False: print("popen read is null") return lineNum result = [] for i in range(0, len(x) - 1):# 由于原始结果需要转换编码,所以循环转为utf8编码并且去除\n换行 res = x[i].
SignalR SignalR是一个.NET Core/.NET Framework的开源实时框架. SignalR的可使用Web Socket, Server Sent Events 和 Long Polling作为底层传输方式.
SignalR基于这三种技术构建, 抽象于它们之上, 它让你更好的关注业务问题而不是底层传输技术问题.
SignalR这个框架分服务器端和客户端, 服务器端支持ASP.NET Core 和 ASP.NET; 而客户端除了支持浏览器里的javascript以外, 也支持其它类型的客户端, 例如桌面应用.
三种通信方式 long polling(长轮询) 长轮询是客户端发起请求到服务端,服务器有数据就会直接返回。如果没有数据就保持连接并且等待,一直到有新的数据返回。如果请求保持到一段时间仍然没有返回,这时候就会超时,然后客户端再次发起请求。
这种方式优点就是简单,缺点就是资源消耗太多,基本是不考虑的。
server sent events(sse) 如果使用了sse,服务器就拥有了向客户端推送的能力,这些信息和流信息差不多,期间会保持连接。
这种方式优点还是简单,也支持自动重连,综合来讲比long polling好用。缺点也很明显,不支持旧的浏览器不说,还只能发送本文信息,而且浏览器对sse还有连接数量的限制(6个)。
web socket web socket允许客户端和服务端同时向对方发送消息(也就是双工通信),而且不限制信息类型。虽然浏览器同样有连接数量限制(可能是50个),但比sse强得多。理论上最优先使用。
回落机制 在Web Socket, Server Sent Events 和 Long Polling中
Web Socket仅支持比较现代的浏览器, Web服务器也不能太老.
而Server Sent Events 情况可能好一点, 但是也存在同样的问题.
所以SignalR采用了回落机制, SignalR有能力去协商支持的传输类型.
RPC RPC (Remote Procedure Call). 它的优点就是可以像调用本地方法一样调用远程服务.
SignalR采用RPC范式来进行客户端与服务器端之间的通信.
SignalR利用底层传输来让服务器可以调用客户端的方法, 反之亦然, 这些方法可以带参数, 参数也可以是复杂对象, SignalR负责序列化和反序列化.
1:材质和shader Shader 是一种給GPU执行的代码,GPU的渲染流水线,为了方便开发人员定制效果,开放出接口給程序员编写代码来控制,这种程序叫作shader, shader开发语言,cocos采用的是GLSL编程语言。开发人员可以在下图顶点Shader和着色Shader来插入代码。
材质是一种配置文件,选择好一个Shader(算法), 并給这个Shader提供必要的参数,当游戏引擎绘制物体的时候,先读取材质,根据材质, 給GPU配置shader和shader要的参数, 这样管道流水线就可以完成的绘制出来这个物体。
2: 准备工作 准备一个子弹头模型(子弹列车^_^)
准备一个加速特效的火焰与透明渐变的贴图:
3: 实现的效果:
4: 上代码:
Shader "Custom/additiveTex_2" { Properties { _TintColor ("Tint Color", Color) = (0.5, 0.5, 0.5, 0.5) _Intensity ("Intensity", Float) = 1.0 _MainTexture ("Base (RGB) Alpha(A)", 2D) = "white" {} _Mask ("Mask (ARGB or Grayscale)", 2D) = "white" {} _speed("speed",Float)=5 } Category { Tags { "Queue"="Transparent" "IgnoreProjector"="True" "RenderType"="Transparent" } Blend SrcAlpha One AlphaTest Greater 0.01 ColorMask RGB Cull Off Lighting Off ZWrite Off // Fog { Color (0,0,0,0) } /*BindChannels { Bind "
基本常识 串口通信:指串口按位(bit)发送和接收字节。尽管比按字节(byte)的并行通信慢,但是串口可以使用一根线发送数据的同时接收数据。在串口通信中,常用的协议包括RS232、RS-422和RS-485。
在Android开发中,对串口数据的读取和写入,实际上是是通过I/O流读取、写入文件数据。
串口用完记得关闭(文件关闭)。 串口关闭,即是文件流关闭。
一、准备so库以及相关SDK 用到开源库serialPort-api
下载其中相关so库资源导入到项目中
其中libs文件夹中的armeabi、armeabi-v7a代表不同的cpu架构,可以根据自己app运行环境自动加载,通常只需要armeabi就可以了。android_serialport_api包下的两个文件则是用来加载so库以及提供相关接口的封装SDK;
注意:这里的包名不可以修改,必须跟so库中的保持一致(这同样在以后对接其他外设SDK时,在加载so库方法经常会遇到方法名加载不到的原因)
在拷贝完相关so库之后我们仍然需要在gradle中指定我们支持的cpu架构,保持libs包中一致即可:
defaultConfig { ndk { abiFilters "armeabi","armeabi-v7a" // "armeabi", "x86", "arm64-v8a" } } SerialPort类:
/* * Copyright 2009 Cedric Priscal * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "
最近做一些项目,综合考虑到一些问题,所以,决定将项目建立在gitee上,下面就写一下主要的流程,方便自己也方便有需要的小伙伴参考。
1、建立仓库名称,具体是开源还是公开,自行选择即可。
2、在idea上创建项目,在菜单上选择VCS,具体如下图:
选择项目所在文件夹,作为gitee的仓库目录。
3、选择remotes,将你要提交的仓库地址填入进去。
4、点击项目右键,此时会出现一个git选项,如果没有出现,重复上一步操作再试试看
5、将缓冲区的项目添加至本地仓库
6、将项目文件提交至git
7、将项目push到git仓库
8、点击push后选择提交到git仓库
注:1、如果是新建项目或者是将本地项目提交到已有仓库中,提交之前记得解决冲突,如果出现以下提示,
基本上就是代码冲突的问题,请按照以下步骤解决:
①.切换到自己项目所在的目录,右键选择GIT BASH Here,Idea中可使用Alt+F12
②.在terminl窗口中依次输入命令:
git pull
git pull origin master
git pull origin master --allow-unrelated-histories
③.在idea中重新push自己的项目,成功!!!
如果还不行: git push -u origin master -f
2、如果是首次提交,需要输入gitee的账号和密码,如果需要修改你的本地凭据,win7下,控制面板\所有控制面板项\凭据管理器,参考下图:
然后,前往gitee仓库地址查看代码是否提交成功。
“两客一危一重货”车辆运输安全是当前道路运输安全管理工作的重中之重,相应的车辆GPS定位监控平台是监控“两客一危一重货”车辆运输安全的重要平台。本系统结合交通部JT808、JT1078等协议标准,提供Java开发车载视频定位监控系统的开发思路。
一:JT808协议解析和服务器搭建。
JT808协议分为2011版、2013版、2019版本。市面上大多是2013版,少数2019版。2013和2019版本的最大区别是报文固定头部把手机号从原来的6字节BCD码改成了10字节BCD码。
2013版报文头:
2019版报文头:
对于TCP报文的解析,消息头可以使用公共组件,通过版本标记解析不同版本的消息头。消息体用每个消息自定义的解析格式。
public abstract class JTMessage { protected String msgId;//消息编号 protected String tid;//终端ID protected String msgNo;//消息流水 protected int version;//版本号 protected int isPack;//分包 解析报文头:
//解析报文头 ReadByteFromHex reader = new ReadByteFromHex(msg); //=============解析消息头开始============= reader.readByte(1);// 7E String msgId = reader.readByte(2);// 消息id String msgBodyAttr = reader.readByte(2);// 消息体属性 int msgBodyInt = Integer.parseInt(msgBodyAttr, 16); boolean isVersion = (msgBodyInt & 0x4000) > 0;// 是否有版本号 取第13位是否为1 0x4000二进制是0100000000000000 int version = 0; //2019版本开始从1递增 if (isVersion) { version = Integer.
1:类和结构体有些相似 是由不同数据类型组成的集合体 但类比结构体增加了操作数据的行为 这个行为就是函数
类的声明
class 类名{ public: 数据成员声明 成员函数声明 private:... protected:... }; 类的实现 类的成员函数可以在类体内实现 也可以在类体外实现,在外面实现要用到域运算符::
2:对象的声明(是object 不是boy or gril friend)
定义一个新类后就可以通过类名来声明一个对象 语法如下
类名 对象名;
person p1,p2; 3:对象的引用
(1) 成员引用方式 成员变量引用表示如下
成员变量 对象名.成员名 成员函数 对象名.成员名(参数表) (2) 对象指针方式 引用成员用->运算符 与 . 运算符意义相同
person *p; 引用成员 p->index; 4:构造函数和析构函数
构造函数和类同名 简而言之它的主要作用就是给类中的变量进行赋值、初始化
析构函数也和类同名,但前面要加个~ 其主要作用是用来清理内存 如手动释放delete等等
5:友元 顾名思义用friend关键字定义 可以读写类中受保护的成员 如protected 和private
6:命名空间
用namespace 关键字定义 可以防止全局变量名字重复 消除命名冲突
namespace m1{ int value=10; }; namespace m2{ int value=20; }; m1::value m2:::value //用域运算符确定是哪个命名空间的变量
需求 在访问线上项目,从访问的电脑本地获取资源。
真正需求就是要访问本地多个视频已打包好的项目中播放并循环播放
实现 环境 项目打包上线 对于项目如何打包上线,这里笔者就不多说啦,因为会遇到这个需求的肯定会布署项目
前后端分离:前端项目布署到服务器
nginx部署vue项目:多个项目、相同的端口下
nginx部署多个vue项目,不同端口号下
给需要访问的电脑安装nginx 下载nginx http://nginx.org/en/download.html
2. 安装这里就不说了
安装完成后,创建一个video文件夹,创建一个num.txt,写入视频的数量就可以了,其和视频资源都在video文件夹中 listen 8888; server_name localhost; #charset koi8-r; #access_log logs/host.access.log main; location /video/ { add_header 'Access-Control-Allow-Origin' '*'; add_header 'Access-Control-Allow-Credentials' 'true'; add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS'; add_header Access-Control-Allow-Headers 'DNT,X-Mx-ReqToken,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Authorization'; if ($request_method = 'OPTIONS') { return 204; } alias D:/nginx/video/; #视频资源存放的路径 autoindex on; } location / { root html; index index.html index.htm; } 代码 video_url是为了动态获取访问地址;
autoplay表示视频准备好就播放;
controls 视频控制按钮;