文章目录 问题描述问题图片: 问题原因解决方式继续使用Google翻译修改本地Host文件 使用国内翻译引擎代替具体操作参考 只想快点用上翻译点这里 ~~2022年11月4日补充~~插件gitHub此问题lssues地址(文中方法不管用的话,去这里面找找看) 2023年2月补充(插件问题已解决) 问题描述 出现时间:2022年10月8日(文末已更新最新的解决方式,注意查看2023年2月15日添加)
Idea使用时无法正常进行翻译,报出TKK: 更新 TKK 失败,请检查网络连接错误,但网络访问正常,Idea的插件商城可正常访问(排除本地网络问题)
问题图片: 确认本地网络
问题原因 并不是插件本身的问题,插件默认使用的翻译引擎是Google翻译。
“在 Google 宣布退出中国之后,它仅在中国保留了翻译服务和不含搜索的地图服务,后来地图服务关闭了,但现在看来它也要关闭翻译服务了。近期有人发现访问 Google 翻译的中国站点 http://translate.google.cn 时有几率(经测试,是1/2)看到和搜索主页相同的重定向到 google.com.hk 页面 。目前不清楚这一现象的缘由,也不清楚 Google 是否完全计划关闭或者保留翻译服务。”1
究其原因 ,解决方式分为两个大类
继续访问Google翻译使用国内其他翻译引擎 解决方式 继续使用Google翻译 修改本地Host文件 临时绕过,后期可能出现问题
在host文件中添加以下内容(推荐,既简单又效率 ,无论是直接修改Host文件还是使用SwitchHost修改,相较于申请国内的翻译引擎有效率多了)
该地址已失效请移步文末,使用新的host(2022年11月4日修改)
# (已失效,2022年11月4日修改) 203.208.40.66 translate.google.com # (已失效,2022年11月4日修改) 203.208.40.66 translate.googleapis.com 使用国内翻译引擎代替 国内的引擎基本目前插件支持的是有道、百度、阿里。
大致步骤是需要去对应的开发者平台进行开发者账号的注册和认证。这些国内引擎基本是每月有一定的免费数量,并不是永久免费。
具体操作参考 博主在前几年刚接触这个的时候,用有道的平台,送了50块的额度,不过之后没在用过了,可以去开通下文本翻译的服务
大家有兴趣可以去试试,其他两个平台也是类似的步骤,具体的细节相关教程应该也不少,这里不在赘述,需要的朋友自行查询把。
只想快点用上翻译点这里 自行在host文件中添加一下内容(已失效(2022年11月4日修改))
# (已失效,2022年11月4日修改) 203.208.40.66 translate.google.com # (已失效,2022年11月4日修改) 203.208.40.66 translate.googleapis.com 2022年11月4日补充 上述地址已失效 在host文件中添加下方内容即可(感谢评论区的大大)
有条件还是希望去注册个有道的,用着方便
172.253.124.90 translate.googleapis.com 插件gitHub此问题lssues地址(文中方法不管用的话,去这里面找找看) 因为这个问题,对于插件的使用造成了很大影响,博主也只是将插件方提供的一些方法搬到这里进行更新,帮助相对小白一些的同学能找到解决的方法。
1、查看改动 修改文件后可以使用git status 查看本地有哪些改动
2、提交修改 git commit Enter键 进入提交编辑区
编辑区首行为要提交的标题编辑区首行一下为内容,一般写哪些改动 编辑完成 shift + 双击z 退出编辑区
3、创建分支推送到远程 git push origin 远程分支名: 新起名分支 (远程仓库分支:新起的名字分支。冒号中间不要有空格)
4、提交后 打开github项目指定pullRequest 要合并的分支即可。然后指定要review的人。
拥有者review之后就会选择合并pullrequest分支,然后还可选择是否删除这个临时分支。
5、注意 review之后 pullRequest 自动被合并到目标分支,合并之后pullRequest 一般被自动删除,本地代码不需要拉取即最新代码。
pull request 未close时后续还可以修改代码提交到同一个pull request上。提交时还是重复之前的步骤即可,添加文件、添加提交日志、push origin aaa:bbb 即可。
添加提交日志时,命令行会进入编辑区。想要退出可通过快捷键shift +双z (执行不了需要调输入法为英文、或者嗯esc 摁键)
git add 之前可以查看有哪些修改 git status 红色为本地变动。add时可以直接使用鼠标粘贴文件路径。
一、jmeter报错信息 jmeter 响应数据--Response Body:
java.io.EOFException: Unexpected end of ZLIB input stream at java.util.zip.InflaterInputStream.fill(InflaterInputStream.java:240) at java.util.zip.InflaterInputStream.read(InflaterInputStream.java:158) at java.util.zip.GZIPInputStream.read(GZIPInputStream.java:117) at org.apache.jmeter.protocol.http.sampler.hc.LaxGZIPInputStream.read(LaxGZIPInputStream.java:52) at java.io.FilterInputStream.read(FilterInputStream.java:107) at org.apache.jmeter.protocol.http.sampler.hc.LaxGZIPInputStream.read(LaxGZIPInputStream.java:70) at org.apache.http.client.entity.LazyDecompressingInputStream.read(LazyDecompressingInputStream.java:64) at org.apache.jmeter.protocol.http.sampler.HTTPSamplerBase.readResponse(HTTPSamplerBase.java:1936) at org.apache.jmeter.protocol.http.sampler.HTTPAbstractImpl.readResponse(HTTPAbstractImpl.java:476) at org.apache.jmeter.protocol.http.sampler.HTTPHC4Impl.sample(HTTPHC4Impl.java:673) at org.apache.jmeter.protocol.http.sampler.HTTPSamplerProxy.sample(HTTPSamplerProxy.java:66) at org.apache.jmeter.protocol.http.sampler.HTTPSamplerBase.sample(HTTPSamplerBase.java:1296) at org.apache.jmeter.protocol.http.sampler.HTTPSamplerBase.sample(HTTPSamplerBase.java:1285) at org.apache.jmeter.threads.JMeterThread.doSampling(JMeterThread.java:638) at org.apache.jmeter.threads.JMeterThread.executeSamplePackage(JMeterThread.java:558) at org.apache.jmeter.threads.JMeterThread.processSampler(JMeterThread.java:489) at org.apache.jmeter.threads.JMeterThread.run(JMeterThread.java:256) at java.lang.Thread.run(Thread.java:750) 二、报错原因 查看报错信息,注意
因为服务器,在返回数据时,对返回数据进行了GZIP格式的压缩。
三、解决办法 content-encoding: GZIP 相关:
jmeter 启用gzip压缩——解决测试中web服务器上行流量过大的问题_程序员_IT源码网
程序简介 打地鼠,点击鼹鼠的小游戏。游戏界面是仿照 unity 书上的素材绘制的。纯手工绘制,不添加任何图片。
我喜欢打地鼠游戏,因为了解这个游戏,又有书配套的素材,我最先想的便是制作它。
相比于之前,这次重新制作,更新了一些东西。
添加了红眼鼹鼠,点击红眼鼹鼠会对分数产生特殊增减效果。鼹鼠是自己画的,所以如果愿意的话,可以有各种各样颜色的鼹鼠。增加这个功能的原意是代替“炸弹”。
游戏图片素材改为“手绘”,这是因为这个游戏素材不多,比较简单。遇到复杂游戏肯定还是要用图片,将程序和美工分开^-^。
代码更新,现在兼容 vc2010
vc2010:_stscanf_s,vc6.0:_stscanf
vc2010:_stprintf_s,vc6.0:_stprintf
程序运行展示 // 游戏进程头文件 // # include <graphics.h> # include <string> # include <time.h> # include <stdlib.h> // 头文件 // 头文件编译开始 #ifndef CIRCLE_H #define CIRCLE_H // 定义变量 static HWND hOut; // 画布 // 定义一个结构体,地洞 struct Node1 { int boxnum; // 地洞编号 int posx_hole, posy_hole; // 地洞坐标 int posx_gopher, posy_gopher; // 鼹鼠坐标 int time_life; // 剩余时间 int type; // 地洞状态 }; // 定义一个结构体,按钮 struct Node2 { int posx1, posy1, posx2, posy2; // 坐标 double r; // 圆按钮半径 LPTSTR text; // 按钮文本 int type; // 按钮激活状态 }; // 定义一个类,game class game { public: int carry_main (); // 游戏进程主循函数 void draw_button (); // 按钮绘制函数 void draw_word (double size, int posx, int posy, LPTSTR text); // 标题绘制函数 void creact_gopher (); // 生成鼹鼠函数 void draw_cloud (double posx, double posy, double size); // 云朵绘制函数 void draw_left_railing (double posx, double posy, double size); // 左栏杆绘制函数 void draw_left_fence (double posx, double posy, double size); // 左栅栏绘制函数 void draw_right_railing (double posx, double posy, double size); // 右栏杆绘制函数 void draw_right_fence (double posx, double posy, double size); // 右栅栏绘制函数 void draw_gopher (double posx, double posy, double size, int flag); // 鼹鼠绘制函数 void draw_hole (double posx, double posy, double size); // 地洞绘制函数 void carry_prepare (); // 准备进程主循函数 void initialization_prepare (); // 准备进程初始化函数 void draw_scene_prepare (); // 准备进程绘制函数 void carry_start (); // 开始进程主循函数 void initialization_start (); // 开始进程初始化函数 void draw_scene_start (); // 开始进程绘制函数 Node1 box[10]; // 地洞,预制 Node2 boxm[20]; // 按钮,预制 int num_button; // 按钮数量 int exit_carry; // 主进程主循函数控制参数 int exit_start; // 开始进程主循函数控制参数 int start_endtime; // 结束时间参数 int start_point; // 分数参数 int speed_creact; // 生成时间间隔参数 int speed_gopher_life; // 鼹鼠存在时间参数 int speed_gopher_beaten; // 鼹鼠被击打后僵直时间参数 int hole_full_end; // 溢满是否结束控制参数 int gopher_red_eye_num; // 红眼数量参数 int point_punishment; // 点击红眼得分改变参数 int every_creact_num; // 每次生成数量 clock_t start_t1; // 游戏开始系统时间参数 clock_t start_t2; // 游戏进行系统时间参数 }; // 头文件编译结束 #endif // 主程序源文件 // // 窗口初始化 void initialization () { // 窗口定义,整个程序仅定义一次 hOut = initgraph (800, 480); // 窗口标题 SetWindowText (hOut, _T ("
1.双击进入服务
2.停止Oracle开头的所有服务
3.在开始菜单里面,打开所有应用找到Oracle安装的文件,打开往下翻找到Universal Installer,然后双击
4.进入Universal Installer界面后点击卸载产品
5.第一步选择你已安装的Oracle产品,第二部点击删除。弹出警告弹窗(请记住这个警告窗弹出的路径,这个路径是你Oracle安装的文件路径,后面会用到)
6.根据警告弹出的文件位置找到deinstall.bat批处理文件,然后双击弹出黑窗体
7.出现取消配置的所有单实例监听程序,这里输入[ ]中括号里面的内容,然后回车
8.如图这里的意思是指定你在Oracle配置的数据库,输入[ ]括号里面的内容,然后回车,这里回车后要有耐心等一下
9.出现指定此数据库 (1. 单实例数据库|2. 启用 Oracle Restart 的数据库) 的类型 [1]: 输入1,直接回车
如果出现已自动搜索到数据库 ORCL11 的详细资料。是否仍要修改 ORCL11 数据库的详细资料?输入y,直接回车
10.出现指定数据库的诊断目标位置 [D:\app\panhang\diag\rdbms\tj]: 如图输入[ ]中括号里面的路径就好,然后回车
如果出现找不到目标位置,就先根据[ ]中括号里面的路径进入一下文件夹,然后再输入[ ]中括号里面的路径就好,然后回车
11.指定数据库 ASM|FS 使用的存储类型 [ ]:这里输入FS,然后回车
12.出现如果有任何数据库文件存在于共享文件系统上, 请指定目录的列表。如果找到了 'TJ' 子目录, 则将删除该子目录。否则将删除指定的目录。此外, 可以指定带有完整路径的数据库文件的列表 [ ]:直接回车(‘’TJ‘’是我的数据库名)
13.出现如果在文件系统上配置了快速恢复区, 请指定其位置。如果找到了 'TJ' 子目录, 则将删除该子目录。 []: 直接回车
14.出现指定数据库 spfile 位置 [ ]: 直接回车后稍等一下
15.是否继续 (y - 是, n - 否)? [n]: 输入y直接回车
前言:很多时候我们是不知道待测接口能支持多少并发用户数的。此时,需要我们先做负载测试,通过逐步加压,来找到最大并发用户数。那么当我们找到一个区间,怎么找到具体的值呢?
在区间中逐步增加步长,出现以下任意现象时,即是最大并发用户数:
1.出现连续报错
2.平均响应时间超过1.5秒(1.5秒是行业标准)
3.tps出现下降趋势
负载测试概念:简单来说:逐步增加并发用户数,找出被测系统的最大可接受的并发用户数,并考察系统性能的变化。
1:安装jmeter 管理插件:jdbc - Standard Set
下载地址:https://jmeter-plugins.org/install/Install/,将下载下来的jar包放到jmeter文件夹下的lib/ext路径下,然后重启jmeter。
在Available Plugins中找到Custom Thread Groups,jdbc - Standard Set安装
2:开始测试
(1)右键”测试计划“》添加》线程,选择”jp@gc - Stepping Thread Group“,插件。
(2):.jp@gc - Stepping Thread Group填写数据,场景为在5秒内增加10个并发用户数,并运行30秒,再继续在5秒内增加10个并发用户数,重复循环,直至并发用户数达到50个后运行脚本60秒。然后在每1秒内减少5个并发用户数,直到减为0,结束脚本的运行
3:添加http请求,就不写了。
4:添加监听器;
5:测试分析结果
从两张图可以分析出,当线程36-48之间的时候出现错误事务,最大应该在36-48之间,然后通过调节线程组的最大线程数反复测试得到最终结果。
6:最终调试参数结果:
从四张图看出,当线程数30时,吞吐量最高,且整个过程无错误事务,响应时常正常,所以结果并发30最佳。
一、软考是什么? 计算机技术与软件专业技术资格(水平)考试(以下简称计算机软件资格考试)是原中国计算机软件专业技术资格和水平考试(简称软件考试)的完善与发展。计算机软件资格考试是由国家人力资源和社会保障部、工业和信息化部领导下的国家级考试,其目的是科学、公正地对全国计算机与软件专业技术人员进行职业资格、专业技术资格认定和专业技术水平测试。
计算机软件资格考试设置了27个专业资格,涵盖5个专业领域, 3个级别层次(初级、中级、高级)。
通过考试获得证书的人员,表明其已具备从事相应专业岗位工作的水平和能力,用人单位可根据工作需要从获得证书的人员中择优聘任相应专业技术职务(技术员、助理工程师、工程师、高级工程师)。计算机软件资格考试全国统一实施后,不再进行计算机技术与软件相应专业和级别的专业技术职务任职资格评审工作。因此,计算机软件资格考试既是职业资格考试,又是职称资格考试。
二、软考的时间安排是什么时候? 软考每年有两次考试,每次报名时间并不固定在某一天,一般上半年考试都是三月份开始下半年考试都是八月份开始。
2023年度计算机软件资格考试(初级、中级、高级)上半年考试日期为5月27日、28日,下半年考试日期为11月4日、5日。
2023年软考考试安排各科目考试时间已定! 想要拿下证书,提前做好规划 ,不要错过备考黄金期
软考有些资格一年考两次,有些资格一年考一次,每年各资格考试时间可能会有所调整。软考各级别资格除了初级信息处理技术员考试为上机考试外,其余资格的考试形式均为笔试。其中软考初级和软考中级包含基础知识和应用技术两个科目,软考高级包含综合知识、案例分析以及论文共三个科目。 2023年上半年软考考试科目 软考高级:信息系统项目管理师、系统分析师、系统规划与管理师
软考中级:软件设计师、网络工程师、信息系统监理师、系统集成项目管理工程师、嵌入式系统设计师、电子商务设计师、数据库系统工程师
软考初级:程序员、网络管理员、信息处理技术员、信息系统运行管理员
2023年下半年软考考试科目 软考高级:信息系统项目管理师、系统架构设计师、网络规划设计师
软考中级:软件设计师、网络工程师、软件评测师、系统集成项目管理工程师、信息系统监理师、信息系统管理工程师、信息安全工程师、多媒体应用设计师
软考初级:程序员、网络管理员、信息处理技术员
2023年考试科目考试大纲 三、软考证书有什么用? 软考证书的用途、含金量还是可以的,不然据官网信息所知,计算机软件资格考试在全国范围内已经实施了二十多年,近十年来,考试规模持续增长,截止目前,累计报考人数约有五百万人,得到了社会各界及用人单位的广泛认同,并为推动国家信息产业发展。
考试合格者将颁发由中华人民共和国人力资源和社会保障部、工业和信息化部用印的计算机技术与软件专业技术资格(水平)证书。
1、在IT行业,软考证书可以作为就业求职的自信和能力的体现。
2、软考的考试跟职称有关系,现在IT行业,凭职称的话,一定要通过软考的认证的,俗说“以考代评”,所以有很多同学考软考是因为职称,要申请居住证,户口等都会参加软考。
3、如果备考中级、高级的科目,将来在一线城市,还能用来积分落户。
4、通过考试获得证书的人员,表明其已具备从事相应专业岗位工作的水平和能力,用人单位可根据工作需要从获得证书的人员中择优聘任相应专业技术职务(技术员、助理工程师、工程师、高级工程师)。起到升职加薪的作用,当然考到证书是前提,现在说多了都是“画大饼”
四、软考如何备考? 很多人也会问,怎么学?难不难?那我只能说这个考试难不难考也是因人而异。毕竟是一个可以评职称评工程师的资格考试,难度肯定是有的。俗话说得好,世上无难事只怕有心人,你真正想做一件事的时候,全世界都会为你让路。
那就给点建议,让考友们少走弯路~~
1、根据自己的实际情况考虑好是要自学,还是参考培训班。不管最终选择哪种学习方式,都要选好相应的自学教材或培训机构。
2、认真阅读考试科目的考试大纲,了解考试知识点,在复习时可以针对性的重点学习。
3、通读一遍官方教材,建立自己的一个知识体系,方便以后遇到问题迅速查阅。
4、细读备考科目的辅导教程,更深入的掌握考试知识点。
5、多做历年真题。通过做题,检验自己对知识点掌握的程度,并巩固知识点。
6、在考试的前一周,再做一次之前的错题,进一步杜绝模棱两可的知识点。
7、多加一些考试交流群和考友一起备考学习,多和大神交流学习经验,有问题就多问,不要一个人闷着学。
总之,想顺利通过2023年软考,就要从现在开始付出努力。点滴积累,重在持之以恒,付出总会有回报的!
文件上传是网页常用功能
我们一般用以下标签在网页中实现这一功能
<input type="file" id="myfile" /> 它的原始显示效果是这样的
我们尝试设置它的css样式
input#myfile{ display: block; border: 1px solid #e1e1e1; box-shadow: none; width: 400px; height: 34px; border-radius: 5px; background-color: #f1f1f1; padding: 5px; } 现在再来看显示效果
可以见到,样式修改成功了.
但有一个问题.中间的按钮怎么设置样式呢,它自己并不是一个独立的按钮啊
这就需要用到css 的 伪类选择器 “::file-selector-button” 了
input#myfile::file-selector-button{ background-color: #008080; color: #FFFFFF; border-radius: 3px; border: 0px; width: 150px; height: 32px; display: inline-block; box-shadow: 3px 3px 10px #555555; margin-right: 10px; } 于是得到显示效果如下
R语言多元分析系列之一:主成分分析
主成分分析(principal components analysis, PCA)是一种分析、简化数据集的技术。它把原始数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是在处理观测数目小于变量数目时无法发挥作用,例如基因数据。
R语言中进行主成分分析可以采用基本的princomp函数,将结果输入到summary和plot函数中可分别得到分析结果和碎石图。但psych扩展包更具灵活性。
一 、选择主成分个数
选择主成分个数通常有如下几种评判标准:
根据经验与理论进行选择
根据累积方差贡献率 ,例如选择使累积方差贡献率达到80%的主成分个数。
根据相关系数矩阵的特征值,选择特征值大于1的主成分。
另一种较为先进的方法是平行分析(parallel analysis)。该方法首先生成若干组与原始数据结构相同的随机矩阵,求出其特征值并进行平均,然后和真实数据的特征值进行比对,根据交叉点的位置来选择主成分个数。我们选择USJudgeRatings数据集举例,首先加载psych包,然后使用fa.parallel函数绘制下图,从图中可见第一主成分位于红线上方,第二主成分位于红线下方,因此主成分数目选择1。
二 、提取主成分
从上面的结果观察到,PC1即观测变量与主成分之间的相关系数,h2是变量能被主成分解释的比例,u2则是不能解释的比例。主成分解释了92%的总方差。注意此结果与princomp函数结果不同,princomp函数返回的是主成分的线性组合系数,而principal函数返回原始变量与主成分之间的相关系数,这样就和因子分析的结果意义相一致。
三 、旋转主成分
旋转是在保持累积方差贡献率不变条件下,将主成分负荷进行变换,以方便解释。成分旋转这后各成分的方差贡献率将重新分配,此时就不可再称之为“主成分”而仅仅是“成分”。旋转又可分为正交旋转和斜交旋转。正交旋转的流行方法是方差最大化,需要在principal中增加rotate='varimax'参数加以实现。也有观点认为主成分分析一般不需要进行旋转。
四、计算主成分得分
主成分得分是各变量的线性组合,在计算出主成分得分之后,还可以将其进行回归等做进一步分析处理。但注意如果输入数据不是原始数据时,则无法计算主成分得分。我们需要在principal中增加score=T的参数设置,结果将存放在结果的score元素中。
R语言多元分析系列之二:探索性因子分析
探索性因子分析(Exploratory Factor Analysis,EFA)是一项用来找出多元观测变量的本质结构、并进行处理降维的技术。 因而EFA能够将具有错综复杂关系的变量综合为少数几个核心因子。EFA和PCA的区别在于:PCA中的主成分是原始变量的线性组合,而EFA中的原始变量是公共因子的线性组合,因子是影响变量的潜在变量,变量中不能被因子所解释的部分称为误差,因子和误差均不能直接观察到。进行EFA需要大量的样本,一般经验认为如何估计因子的数目为N,则需要有5N到10N的样本数目。
虽然EFA和PCA有本质上的区别,但在分析流程上有相似之处。下面我们用ability.cov这个心理测量数据举例,其变量是对人的六种能力,例如阅读和拼写能力进行了测验,其数据是一个协方差矩阵而非原始数据。R语言中stats包中的factanal函数可以完成这项工作,但这里我们使用更为灵活的psych包。
一、选择因子个数
一般选择因子个数可以根据相关系数矩阵的特征值,特征值大于0则可选择做为因子。我们仍使用平行分析法(parallel analysis)。该方法首先生成若干组与原始数据结构相同的随机矩阵,求出其特征值并进行平均,然后和真实数据的特征值进行比对,根据交叉点的位置来选择因子个数。根据下图我们可以观察到特征值与红线的关系,有两个因子都位于红线上方,显然应该选择两个因子。
二、提取因子
psych包中是使用fa函数来提取因子,将nfactors参数设定因子数为2,rotate参数设定了最大化方差的因子旋转方法,最后的fm表示分析方法,由于极大似然方法有时不能收敛,所以此处设为迭代主轴方法。从下面的结果中可以观察到两个因子解释了60%的总方差。Reading和vocabulary这两个变量于第一项因子有关,而picture、blocks和maze变量与第二项因子有关,general变量于两个因子都有关系。
如果采用基本函数factanal进行因子分析,那么函数形式应该是factanal(covmat=correlations,factors=2,rottion='varimax'),这会得到相同的结果。此外,我们还可以用图形来表示因子和变量之间的关系
三、因子得分
得到公共因子后,我们可以象主成分分析那样反过来考察每个样本的因子得分。如果输入的是原始数据,则可以在fa函数中设置score=T参数来获得因子得分。如果象上面例子那样输入的是相关矩阵,则需要根据因子得分系数来回归估计。
参考资料:R in Action
R语言多元分析系列之三:多维标度分析
多维标度分析(MDS)是一种将多维空间的研究对象简化到低维空间进行定位、分析和归类,同时又保留对象间原始关系的数据分析方法。
设想一下如果我们在欧氏空间中已知一些点的座标,由此可以求出欧氏距离。那么反过来,已知距离应该也能得到这些点之间的关系。这种距离可以是古典的欧氏距离,也可以是广义上的“距离”。MDS就是在尽量保持这种高维度“距离”的同时,将数据在低维度上展现出来。从这种意义上来讲,主成分分析也是多维标度分析的一个特例。
一、距离的度量
多元分析中常用有以下几种距离,即绝对值距离、欧氏距离(euclidean)、马氏距离(manhattan)、 两项距离(binary)、明氏距离(minkowski)。在R中通常使用disk函数得到样本之间的距离。MDS就是对距离矩阵进行分析,以展现并解释数据的内在结构。
在经典MDS中,距离是数值数据表示,将其看作是欧氏距离。在R中stats包的cmdscale函数实现了经典MDS。它是根据各点的欧氏距离,在低维空间中寻找各点座标,而尽量保持距离不变。
非度量MDS方法中,“距离"不再看作数值数据,而只是顺序数据。例如在心理学实验中,受试者只能回答非常同意、同意、不同意、非常不同意这几种答案。在这种情况下,经典MDS不再有效。Kruskal在1964年提出了一种算法来解决这个问题。在R中MASS包的isoMDS函数可以实现这种算法,另一种流行的算法是由sammon函数实现的。
二、经典MDS
下面我们以HSAUR2包中的watervoles数据来举例。该数据是一个相似矩阵,表示了不同地区水田鼠的相似程度。首先加载数据然后用cmdscales进行分析。
下面计算前两个特征值在所有特征值中的比例,这是为了检测能否用两个维度的距离来表示高维空间中距离,如果达到了0.8左右则表示是合适的。
然后从结果中提取前两个维度的座标,用ggplot包进行绘图。
三、非度量MDS
第二例子中的数据是关于新泽西州议员投票行为的相似矩阵,这里我们用MASS包中的isoMDS函数进行分析
参考资料:
A Handbook of Statistical Analyses Using R
多元统计分析及R语言建模
R语言多元分析系列之四:判别分析
判别分析(discriminant analysis)是一种分类技术。它通过一个已知类别的“训练样本”来建立判别准则,并通过预测变量来为未知类别的数据进行分类。
判别分析的方法大体上有三类,即Fisher判别、Bayes判别和距离判别。Fisher判别思想是投影降维,使多维问题简化为一维问题来处理。选择一个适当的投影轴,使所有的样品点都投影到这个轴上得到一个投影值。对这个投影轴的方向的要求是:使每一组内的投影值所形成的组内离差尽可能小,而不同组间的投影值所形成的类间离差尽可能大。Bayes判别思想是根据先验概率求出后验概率,并依据后验概率分布作出统计推断。距离判别思想是根据已知分类的数据计算各类别的重心,对未知分类的数据,计算它与各类重心的距离,与某个重心距离最近则归于该类。
一.线性判别
当不同类样本的协方差矩阵相同时,我们可以在R中使用MASS包的lda函数实现线性判别。lda函数以Bayes判别思想为基础。当分类只有两种且总体服从多元正态分布条件下,Bayes判别与Fisher判别、距离判别是等价的。本例使用iris数据集来对花的品种进行分类。首先载入MASS包,建立判别模型,其中的prior参数表示先验概率。然后利用table函数建立混淆矩阵,比对真实类别和预测类别。
Redis实战—黑马点评(二)缓存篇 目录 Redis实战—黑马点评(二)缓存篇1. 什么是缓存1.1 缓存的作用和成本 2. 添加 Redis 缓存3. 缓存更新策略3.1 三种更新策略3.1.1 主动更新策略 4. 缓存穿透4.1 常见两种解决办法4.1.1 缓存空值4.1.2 布隆过滤器 4.2 小结 5. 缓存雪崩6. 缓存击穿6.1 常见解决方案两种6.1.1 互斥锁6.1.2 逻辑过期6.1.3 方案对比 6.2 小收获 7. 缓存工具类封装7.1 代码实现问题:刚才的代码中,锁的key不应该在代码中指定,而是作为参数传入。 7.2 小收获7.2.1 时间处理7.2.2 泛型使用7.2.3 Function对象 1. 什么是缓存 缓存即为数据交换的缓冲区,是数据临时存储的地方,读写性能高。
1.1 缓存的作用和成本 简单的说,用缓存好处多,可以提升程序性能,缺点就是麻烦。
2. 添加 Redis 缓存 不用缓存的话,我们的程序获取数据是从数据库:
用了缓存之后,减少了数据库的压力:
原本需要从数据库中查的数据现在只需要去缓存中查了(第一次除外)。
案例:添加商户缓存
具体代码就不写了,这个流程还存在缓存穿透的问题,后续会说明。
这里收获了一个小编码技巧,在软件工程中有“单一出口原则”的说法,在方法中就只有一个return,但有时候用多个return会大幅简洁代码,省掉大量的else。
3. 缓存更新策略 数据存到缓存后,会有一个数据一致性的人问题:
假如数据库更新了,用户还是从缓存查数据,那么查到的就是缓存中的旧数据了。
所以需要有一种更行缓存的机制。
3.1 三种更新策略 内存淘汰
Redis自带的机制,当内存不足时自动淘汰部分数据。下次查询时更新缓存。
超时剔除
给数据添加TTL值,到期自动删除。下次查询时更新。
主动更新
主动编写逻辑,在数据改变时,更行缓存。
3.1.1 主动更新策略 第一种就是主动编码,在数据库更新时更新缓存(编码多,麻烦)。
第二种就是将缓存和数据库整合为一个服务,由该服务来保证一致性(编码少,缺点就是这个服务质量不好保证,不好维护)。
自己的笔记本安装的双系统,linux系统不知在什么时候有线是不通讯的,无线倒是没事,开始没注意,因为笔记本比较旧想着是网卡太旧不稳定,再说也能使用无线,但时间久了发现笔记本在win系统下有线还是一如继往的好。最后总结一下发现在linux系统下,接网线启动网络不通,不接网线启动再插线网络是通的。已排除了网卡的问题,那就只能是系统的问题了。经过排查,发现是为了方便图形介面网络管理,安装了NetworkManager,但这个服务和原有的networking服务有冲突,导制这种情况。这就好说了,停一个服务就可以了,为了方便管理,我停掉了原生的networking服务。问题解决!
解决方法:
关闭NetworkManager或networking
#systemctl disable networking
目录
布隆过滤器 完整代码 布隆过滤器应用 布隆过滤器的查找
布隆过滤器删除
布隆过滤器优点
布隆过滤器缺陷
布隆过滤器海量数据处理
布隆过滤器 位图只能映射整形,而对于字符串却无能为力。
把字符串用哈希算法转成整形,映射一个位置进行标记
下面就是布隆过滤器设计思路
位图是直接定址法,不存在冲突,而字符串可能转成整形后,会有重合的地方,发生下面这种冲突(误判)。
布隆过滤器存在误判,如这里如果美团不存在,而B站存在,此时美团的位置被B站占据,有可能会误判为美团此时存在。
这种误判不可能完全去掉,但我们可以通过优化降低误判率。
优化方法:让每个值多映射几个位,如美团映射好几个位,就能减少上面误判的概率。理论而言,一个值映射的位越多,误判冲突的概率就越低,但如果映射过多,空间消耗就会增大。
判断某邮箱是否在黑名单中,可用布隆过滤器进行简单的过滤
完整代码 struct HashBKDR { // BKDR size_t operator()(const string& key) { size_t val = 0; for (auto ch : key) { val *= 131; val += ch; } return val; } }; struct HashAP { // BKDR size_t operator()(const string& key) { size_t hash = 0; for (size_t i = 0; i < key.
一、问题描述:maven加载依赖报错 点击刷新,加载所有maven项目的时候,maven加载依赖失败。
显示“无法解析mysql:mysql-connector-java:pom:8.0.27”,具体报错原因如下:
mysql:mysql-connector-java:pom:8.0.27 failed to transfer from https://maven.aliyun.com/repository/public during a previous attempt. This failure was cached in the local repository and resolution is not reattempted until the update interval of nexus has elapsed or updates are forced. Original error: Could not transfer artifact mysql:mysql-connector-java:pom:8.0.27 from/to nexus (https://maven.aliyun.com/repository/public): transfer failed for https://maven.aliyun.com/repository/public/mysql/mysql-connector-java/8.0.27/mysql-connector-java-8.0.27.pom 尝试使用 -U 标记(强制更新快照)运行 Maven 导入 二、原因分析&&解决方法 mysql:mysql-connector-java:pom:8.0.27 failed to transfer from https://maven.aliyun.com/repository/public during a previous attempt. This failure was cached in the local repository and resolution is not reattempted until the update interval of nexus has elapsed or updates are forced.
一、处理25端口
①、换用端口
1、官方建议【465端口、25端口申请】。
2、云服务器可用端口。
1、可用端口(465、587)。 ②、使用(465、587)端口问题
1、错误信息:The SMTP server requires a secure connection or the client was not authenticated.
2、错误信息: Bad sequence of commands. The server response was: Error: need EHLO and AUTH first ③、完整代码(处理及解决)
1、禁用默认凭证、启用ssl。
/// <summary> /// 发送邮件 /// </summary> /// <returns></returns> public async Task SendAsync() { MailMessage mail = new MailMessage(); mail.To.Add(new MailAddress("apricot@qq.com")); mail.Body = "so far ~"; Mail.SmtpClient smtp = new Mail.SmtpClient(); mail.From = new MailAddress("
情景描述:xShell输入密码之后直接被服务器断开连接;局域网内的其他电脑也都相同状况
重装sshd没有用
查看了网上的解决方案 IP冲突;我这里排除,两边都是静态地址
修改ssh的配置文件,将连接超时和重发次数的#去掉并赋值(试了无效)
折磨了一天,看到xshell突然连接不上-报错:Socket error Event: 32 Error: 10053. Connection closing...Socket close. - 灰信网(软件开发博客聚合) (freesion.com) 这篇文章中的“2、selinux机制是否关闭【确认已经关闭】” 想起来自己好像最近装了一个带selinux的东西;(linux算小白,也不清楚具体什么用的东西)
于是在网上搜索如何关闭selinux;最后将selinux关闭,成功连上;
文章目录 前言一、web开发安全 - 攻击1. Cross-Site Scripting(XSS)1.1 存储型(Stored Xss)1.2 反射型(Reflect Xss)1.3 DOM型(DOM Xss)1.4 Mutation-based XSS 2. Cross-Site Request Forgery(CSRF)3. SQL Injection4. Server-Side Request Forgery(SSRF)5. Denial of Service(DoS)6. Distributed DoS(DDoS) 二、web开发安全 - 防御(开发者注意)1. XSS防御1.1 现成工具1.2 注意点1.3 Content Security Policy(CSP) 2. CSRF防御避免携带 SameSite Cookie 3. injection 防御3.1 sql injection3.2 injection beyond SQL 4. DOS 防御4.1 DDOS 5. 通过传输层防御(HTTPS) 前言 仅以此文章记录学习。
一、web开发安全 - 攻击 1. Cross-Site Scripting(XSS) 跨站脚本攻击
是针对用户层面的攻击。
恶意攻击者会往Web页面里插入恶意Script代码,当用户浏览该页面时,嵌入Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。XSS攻击针对的是用户层面的攻击!
特点:
通常难以从 UI上感知(暗地执行脚本窃取用户信息 (cookie/token)绘制 UI(例如弹窗),诱骗用户点击/填写表单 1.
文章目录 一、磁盘结构二、先来先服务三、最短寻道时间优先四、电梯算法 SCAN 一、磁盘结构 盘面(Platter):一个磁盘有多个盘面;
磁道(Track):盘面上的圆形带状区域,一个盘面可以有多个磁道;
扇区(Track Sector):磁道上的一个弧段,一个磁道可以有多个扇区,它是最小的物理储存单位,目前主要有 512 bytes 与 4 K 两种大小;
磁头(Head):与盘面非常接近,能够将盘面上的磁场转换为电信号(读),或者将电信号转换为盘面的磁场(写);
制动手臂(Actuator arm):用于在磁道之间移动磁头;
主轴(Spindle):使整个盘面转动。
读写一个磁盘块的时间的影响因素有:
旋转时间(主轴转动盘面,使得磁头移动到适当的扇区上)寻道时间(制动手臂移动,使得磁头移动到适当的磁道上)实际的数据传输时间
其中,寻道时间最长,因此磁盘调度的主要目标是使磁盘的平均寻道时间最短。 二、先来先服务 FCFS, First Come First Served
按照磁盘请求的顺序进行调度。
优点是公平和简单。缺点也很明显,因为未对寻道做任何优化,使平均寻道时间可能较长。
三、最短寻道时间优先 优先调度与当前磁头所在磁道距离最近的磁道。
虽然平均寻道时间比较低,但是不够公平。如果新到达的磁道请求总是比一个在等待的磁道请求近,那么在等待的磁道请求会一直等待下去,也就是出现饥饿现象。具体来说,两端的磁道请求更容易出现饥饿现象。
四、电梯算法 SCAN 电梯总是保持一个方向运行,直到该方向没有请求为止,然后改变运行方向。
电梯算法(扫描算法)和电梯的运行过程类似,总是按一个方向来进行磁盘调度,直到该方向上没有未完成的磁盘请求,然后改变方向。
因为考虑了移动方向,因此所有的磁盘请求都会被满足,解决了 SSTF 的饥饿问题。
在Django的模板标签中, {% for %}标签用于迭代序列中的各个元素。 而{% if %} 也经常搭配使用,在有多组数据的情况下,具体使用方法如下:
{% if list1 %} {% for a in list1 %} <p>{{a}}</p> {% endfor %} {% elif list2 %} {% for b in list2 %} <p>{{b}}</p> {% endfor %} {% elif list3 %} {% for c in list3 %} <p>{{c}}</p> {% endfor %} {% elif list4 %} {% for d in list4 %} <p>{{d}}</p> {% endfor %} {% else %} <p>No relevant information.
1.准备aab包以及 bundletool 工具
打开
bundletool
https://github.com/google/bundletool/releases
点击下载
mac文件夹如图所示,window同理
2.使用 bundletools 转换aab包
打开命令行工具
cd到指定目录下
输入命令转换,会使用默认的debug.keystore进行签名
java -jar bundletool-all-1.11.2.jar build-apks --mode=universal --bundle=~/admobileSdkTest/app-google-release.aab --output=~/admobileSdkTest/universal.apks
其中
bundletool-all-1.11.2.jar 是你下载的jar包,如果是其他版本,修改即可
/admobileSdkTest/app-google-release.aab 是aab包所在的文件夹位置,默认mac会加 /Users/mckj 前缀,加一起就是 /Users/mckj/admobileSdkTest/app-google-release.aab 位置
/admobileSdkTest/universal.apks 是输出的apks文件的位置,也是一样,默认mac会加 /Users/mckj 前缀,加一起就是 /Users/mckj/admobileSdkTest/universal.apks 位置
文件夹如下,多出了一个 universal.apks 文件
重命名文件,将 universal.apks 修改为 universal.rar
再双击 universal.rar,解压缩,其中的 universal.apk 文件就是我们想要的文件
可以把文件拖到Android Studio 中,就可以打开 resources.arsc 文件,查看到资源信息
经常使用到的数组方法,过段时间需要整理一遍,工作中经常使用,偶尔想不起来
目录 pushconcatunshiftsplice push 向数组尾部追加数据
定义
push(...items: T[]): number; 示例
let list = ['tom'] list.push('Jack', 'Steve') console.log(list) // [ 'tom', 'Jack', 'Steve' ] concat 合并两个数组,注意:该方法会返回新数组
定义
concat(...items: (T | ConcatArray<T>)[]): T[]; 示例
let list = ['tom'] let newList = list.concat('Jack', 'Steve') console.log(list) // [ 'tom' ] console.log(newList); // [ 'tom', 'Jack', 'Steve' ] unshift 头部插入元素
定义
unshift(...items: T[]): number; 示例
let list = ['tom'] list.unshift('Jack', 'Steve') console.log(list) // [ 'Jack', 'Steve', 'tom' ] splice 删除元素或插入元素,同时具有remove(Array未提供)、insert(Array未提供)、push、unshift的功能
JVM Full GC(Full Garbage Collection)是一种垃圾回收的机制,用于回收整个堆内存中的所有未使用对象,包括年轻代和老年代中的对象。
在进行Full GC时,主要会做以下几件事情:
停止所有的应用程序线程:为了避免在Full GC期间产生新的垃圾对象,JVM需要先暂停所有的应用程序线程。
标记所有存活的对象:JVM会从根对象(如静态变量、局部变量等)开始遍历所有可达的对象,并标记所有存活的对象。这一过程类似于Young GC中的标记阶段。
整理内存空间:在标记所有存活对象之后,JVM会将所有存活对象移动到堆内存的一端,并将所有未使用的内存空间整理到另一端,从而释放出一段连续的内存空间。这一过程类似于Young GC中的整理阶段。
释放未使用的内存空间:在整理内存空间之后,JVM会将整个堆内存中未使用的内存空间全部释放掉,从而回收所有不再使用的对象。
重置指针:在释放未使用的内存空间之后,JVM会将内存指针指向堆内存的起始位置,以便下一次垃圾回收使用。
需要注意的是,Full GC通常是一种非常耗时的操作,因为它需要遍历整个堆内存中的所有对象,并对内存空间进行整理和释放。因此,在实际开发中,我们需要尽可能地避免Full GC的发生,以提高应用程序的性能和响应速度。
问题 1、Microsoft Word 启动时显示 Please reload Word to load MathType addin properly
2、安装MathType后在 Microsoft Word 中使用复制粘贴时报错 运行时错误‘53’
3、在 Microsoft Word 中使用 MathType 选项卡时,无法打开并报错 运行时错误‘53’
重新加载后,MathType 大部分功能不可用,状态为灰色不可点击
解决方法一 如果之前使用正常,而在系统安装了更新补丁之后才出现这种情况的话,卸载MathType,重装
解决方法二 MathPage.wll文件可能不在Office的STARTUP文件夹中,需要我们手动添加
复制wll文件 找到 MathType 安装目录,默认的安装目录为C:\Program Files (x86)\MathType\MathPage\64,如果你修改了安装目录请自行定位。在安装目录下能够找到 MathPage 文件夹。
粘贴wll文件 粘贴到Word中的“STARTUP”文件夹中。路径在C:\Users\zhou\AppData\Roaming\Microsoft\Word\STARTUP
AppData文件夹是隐藏文件夹,因此,我们需要设置显示隐藏的文件夹才能看到
解决方法三 复制wll文件 找到 MathType 安装目录,默认的安装目录为C:\Program Files (x86)\MathType\MathPage\64,如果你修改了安装目录请自行定位。在安装目录下能够找到 MathPage 文件夹。
粘贴wll文件 进入 MathPage 目录,根据操作系统位数选择 32 位或 64 位,进入对应目录,找到 MathPage.wll 文件。并复制到 C:\Program Files\Microsoft Office\root\Office16 目录下。
本节学习设备树的规范。
使用设备树时,需要编写dts文件,然后使用dtc编译dts文件,生成dtb文件。
所以本节分为两部分,第一部分讲解dts格式,第二部分讲解dtb格式。
首先看一下dts文件的布局。
DTS文件布局(layout): /dts-v1/; // 表示DTS文件的版本 [memory reservations] // 保存的内存区域 格式为: /memreserve/ <address> <length>; / { [property definitions] [child nodes] }; 第一行 /dts-v1/; 表示的是DTS文件的版本。
第二行 [memory reservations] 表示保留的内存区域,假设有64MB内存,如果希望保留4MB内存,只提供60MB内存供内核使用,那么就可以设置这个选项,如果不设置则认为内核使用全部的内存。
接下来是 / { ... };,其中 / 是根,是设备树的起点。
对于每一个设备树,我们需要一些属性来描述这颗树,就是 [property definitions];同样,一颗树有很多树干,很多分支,一颗设备树同样也有很多子节点,子节点中又可以包含子节点,就是 [child nodes]。
那么属性和设备节点是如何定义的呢?
属性 首先来看属性。
属性的格式有两种,一种是没有值的空属性,一种是有值的属性。
Property格式1: [label:] property-name = value; Property格式2(没有值): [label:] property-name; 下面就是有值的属性,除了特殊规定的属性,比如bootargs是用来设置启动指令,其他没有特殊规定的属性,属性名是可以自由定义的,比如pin,就是我们自己定义的属性。
属性值的写法有三种:
用尖括号括起来 <xx xx xx ...>,例如<1 0x3 0x123>,每个成员都是32bit数据,称为arrays of cells;用双引号括起来的字符串 "...",例如上面bootargs的字符串;用中括号括起来的字节序列(byte string)[xx xx xx .
在开发过程中因为需要根据模板来生成对应的word文档和excel,在参考一圈后,决定使用freemarker和easypoi一起来做。可是在部署到Tomcat后,发现生成的文档中文乱码。并且飘忽不定,百度一圈,现在附上我的解决方法,希望能帮助到你。
1、修改编辑器编码,具体见下图 外链图片转存中…(img-hNlBhWsk-1676346181428)]
红线标注的地方,最好调整成统一的编码
2、代码编写注意 在创建writer时,使用此方法来进行创建。
Writer w = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(xmlTemp), "utf-8")); 在获取模板路径的时候,注意下编码格式
public class XmlToExcel { private static XmlToExcel tplm = null; private Configuration cfg = null; private XmlToExcel() { cfg = new Configuration(); try { // 注册tmlplate的load路径 cfg.setClassForTemplateLoading(this.getClass(), "/template/"); String path = this.getClass().getClassLoader().getResource("").getPath() + "fileTemplate/"; System.out.println(this.getClass().getClassLoader().getResource("").getPath() + "fileTemplate/"); cfg.setDirectoryForTemplateLoading(new File(path)); } catch (Exception e) { } } private static Template getTemplate(String name) throws IOException { if (tplm == null) { tplm = new XmlToExcel(); } return tplm.
文章目录 前言PC web端一、 前端Debug的特点二、 前端Debug的方式1. 浏览器动态修改元素和样式2. Console3. Sorce Tab4. NetWork5. Application6. Performancee7. Lighthouse 移动端调试IOSAndroid通过代理工具调试 前言 仅以此文章记录学习。
PC web端 一、 前端Debug的特点 多平台:浏览器、Hybrid、NodeJs、小程序、桌面应用等.多环境:本地开发环境、线上环境多工具:Chrome devTools、Charles、Spy-Debugger、Whistle、vConsole等多技巧:Console、BreakPoint、sourceMap、代理等 二、 前端Debug的方式 1. 浏览器动态修改元素和样式 点击 .cls 开启动态修改元素的 class输入字符串可以动态的给元素添加类名勾选/取消类名可以动态的查看类名生效效果点击具体的样式值 (字号、颜色、宽度高度等)可以进行编辑,浏览器内容区域实时预览Computed 下点击样式里的箭头可以跳转到 styles面板中的 css 规则 伪类强制激活的两种方式:
选中具有伪类的元素,点击:hovDOM 树右键菜单,选择 Force State 2. Console console.log:输出一条信息console.warn:输出警告信息,信息最前面加一个黄色三角console.error:输出错误信息到控制台console.debug:输出“调试”级别的消息console.info:输出一条信息console.table:具像化的展示 JSON 和 数组数据console.dir:通过类似文件树的方式展示对象的属性占位符给日志添加样式,可以突出重要的信息%s: 字符串占位符,%o: 对象占位符: %c: 样式占位符,%d: 数字占位符 3. Sorce Tab 区域1: 页面资源文件目录树区域2: 代码预览区域区域3: Debug 工具栏 从左到右依次为
暂停 (继续)单步跳过进入函数跳出函数单步执行激活 (关闭) 所有断点代码执行异常处自动 区域4: 断点调试器 4. NetWork 区域1: 控制面板区域2: 过滤面板区域3: 概览区域区域4:Request Table 面板区域5: 总结面板区域6: 请求详情面板 5.
目录
1、下载redis安装包
2、将下载后的.tar.gz压缩包上传到到服务器自定义文件夹下
3、 解压文件
4、安装redis
5、配置redis.conf
6、启动redis
1、下载redis安装包 Redis各版本下载:https://download.redis.io/releases/
2、将下载后的.tar.gz压缩包上传到到服务器自定义文件夹下 3、 解压文件 -- 解压文件 tar -zxvf redis-6.0.3.tar.gz -- 移动文件夹,看个人需要 mv redis-6.0.3 redis 4、安装redis 在redis文件夹下输入make指令
在src文件夹下输入make install指令
如果没有root权限,则执行如下命令安装到指定有权限的目录
make install PREFIX=/eflex/app/packages/redis/redis-6.0.3 5、配置redis.conf 1、修改redis.conf中的相关参数
#daemonize no 改为yes,开启后台运行,默认是前台运行 daemonize yes #把这一行注释,监听所有IP #bind 127.0.0.1 #protected-mode yes 如果改为no,则是关闭保护模式,这种模式下不能配置系统服务,建议还是开启 protected-mode yes #requirpass,保护模式开启的时候要配置密码或者bind ip requirepass 123456 #修改本参数,指定数据目录 dir /opt/redis6/data #修改本参数,指定日志目录 logfile /opt//redis6/redis_6379.log 6、启动redis 进入bin目录,执行了make install就会有bin目录了
./redis-server /eflex/app/packages/redis/redis-6.0.3/redis.conf 参考地址:银河麒麟安装Redis 6.0.3_LD_Coding的博客-CSDN博客_麒麟系统安装redis
请介绍什么是Binder机制⭐⭐⭐⭐⭐
请介绍Binder机制流程 ⭐⭐⭐⭐
Binder机制需要多少次内存拷贝 ⭐⭐⭐
Android有很多跨进程通信方法,为何选择Binder?⭐⭐⭐
目录 1、Android中的跨进程方法(IPC)
1.1 Android中的跨进程方法
1.2 为何要使用Binder
2、传统的Linux跨进程通讯
3、Binder的通讯原理
4、Binder通信模型
4.1 服务端、客户端、ServiceManager、Binder驱动
4.1.1 Binder驱动
4.1.2 ServiceManager
4.1.3 服务端向ServiceManager注册
4.1.4 客户端获取服务端Binder引用
4.2 Binder通讯中的代理模式
4.3 好多Binder分不清?
4.4 Binder通讯流程
5、Binder源码分析(外部链接)
1、Android中的跨进程方法(IPC) Binder是Android中的一种跨进程通信机制,采用服务端/客户端结构,主要包含服务端、客户端、ServiceManager、Binder驱动4大部分。我们先看看Android中都有哪些跨进程的方法。
1.1 Android中的跨进程方法 共享内存:通过共享缓冲区直接映射到各个进程的虚拟地址空间,速度快。但实现比较复杂,进程间的同步问题操作系统无法实现,必须各进程利用同步工具解决;
消息队列:提供了一种从一个进程向另一个进程发送一个数据块的方法,但需要进行2次数据拷贝,不适合频繁或者数据量大的情况;
管道:分为有名/无名管道,在创建时分配一个page大小的内存,缓存区大小比较有限;
信号量:一般作为一种锁机制,用于进程/线程同步;
信号:更适合作为进程中断控制,而非数据交换;
Socket/LocalSocket:允许位于同一主机(计算机)或使用网络连接起来的不同主机上的应用程序之间交换数据;
Binder:Binder是Android中的一种跨进程通信机制;
匿名共享内存:在Android系统中,提供了独特的匿名共享内存子系统Ashmem(Anonymous Shared Memory),它利用了Linux的 tmpfs文件系统(一种可以基于RAM或是SWAP的高速文件系统)来实现不同进程间的内存共享。有两个特点:
能够辅助内存管理系统来有效地管理不再使用的内存块;
通过Binder进程间通信机制来实现进程间的内存共享;
File:通过文件进行多进程通信用法简单,但不适合高并发情况;
ContentProvider:Android四大组件之一,常用于进程间数据共享,特别是一对多的情况,不过受限于AIDL;
Bundle:很常见也很常用,但只能传输Bundle支持的数据类型,同样不适合大量数据的传输;
面试官很喜欢问Android中有哪些跨进程方法,如果你可以答出这么多,一定可以加分 1.2 为何要使用Binder 众所周知,Android系统基于Linux系统,因此Linux系统的IPC方法:共享内存、消息队列、管道、信号量,在Android系统都可以使用。1.1小节就列出了10+种方法,那么为何还需要Binder?
使用Binder的理由可以总结为性能、安全、稳定几个方面:
性能:管道、消息队列、Socket都需要2次数据拷贝(即数据先从发送方缓存区拷贝到内核开辟的缓存区中,然后再从内核缓存区拷贝到接收方缓存区),而Binder只要1次(可见第3节分析),且Binder相对Socket方法也更加高效,Socket主要用于跨网络的进程间通讯,传输的效率比较低。当然共享内存1次数据拷贝都不需要,因此就性能而言,共享内存高于Binder;
安全:Android系统为每个应用都分配各自的UID以鉴别不同进程。Binder会验证权限,鉴定UID/PID来验证身份,保证了进程通信的安全性;
稳定:共享内存1次数据拷贝都不需要,但实现的方法比较复杂,并且需要做好进程同步,容易出现死锁或者资源竞争,稳定性差。而Binder基于C/S架构,客户端和服务端彼此独立,稳定性强。
因此,在Android系统的IPC方式,一般情况下都推荐使用Binder。当然,在Android源码里,上述其他IPC方法也会使用到。接下来让我们先看看传统的Linux跨进程通讯原理。
2、传统的Linux跨进程通讯 Android是基于Linux的,以32位系统来说,在每一个Linux进程都有3G虚拟内存空间,称之为用户空间,以及1G的内核空间。其中,不同进程的用户空间是相互隔离不可直接通讯的,但是内核空间却是共享的。以进程A发送数据到进程B为例,需要经历如下步骤:
进程A的内核空间开辟一块内核缓存区,通过copy_from_user()系统调用,将在用户空间的数据拷贝到内核缓存区;
进程B的内核空间也开辟了一块内核缓存区,因为不同进程的内核空间共享的,此时进程B就可以通过copy_to_user()系统调用将内核缓存区的数据拷贝到自己的用户空间;
如此就完成了一次进程间通讯,上面说到的管道、消息队列都是基于这种方式,因此有两个缺点:
经历2次数据拷贝,效率较低;
进程B接收的内核缓存区无法确定开辟多大的空间合适,太大自然损耗空间,太小则可能出现拷贝不完整,因此要么开辟尽可能大的空间,要么先获取进程A发送的数据大小再开辟对应大小的空间。这两种做法要么浪费空间,要么浪费时间。
3、Binder的通讯原理 了解Binder通讯原理需要知道两个概念:
文章目录 前言摘要(Abstract)一、引言( Introduction)二、编程模型(Programming Model)三、实现(Implementation)3.1、执行概述(Execution Overview)3.2、主节点数据结构(Master Data Structures)3.3、容错(Fault Toleran)3.4、局部性3.5、任务粒度3.6、 备用任务 四、技巧4.1、划分函数4.2、顺序保证4.3、合并函数4.4、输入和输出类型4.5、边界效应4.6、略过错误的记录4.7、本地执行4.8、状态信息4.9、计数器 五、性能六、经验(运用)七、相关性八、总结 前言 大抵只有一直忙下去,才能保持内心的平静了…后面有空打算就更些笔记,也会穿插些个人的理解。
摘要(Abstract) MapReduce论文地址
MapReduce 是一个分布式运算程序的编程框架,可以处理并生成巨大的数据集。用户可以在输入端利用指定map函数,该函数可以处理KV键值对,生成一组中间值,而下一阶段的reduce函数则可以合并同一hash的中间值(相当于分组合并)最后得到结果。因此可以看出其的核心思想则是分而治之。将庞大的数据,拆分成相同的任务,再进行分组计算,汇合结果,而这也是分布式系统下的经典的并行处理方式,并且它是自动进行并行的,也因此就算不具有并行和分布式系统的经验,能够轻松利用大型分布式系统的资源。
一、引言( Introduction) 在实现mapreduce之前,google的作者与其他许多人,实现数百个处理大型原始数据的专用计算(爬取文档,web请求日志。)并得到各种衍生数据,如分析后的倒排索引,web文档的结构化表示…而往往原始数据都会数量庞大,则必须分布在数百台至数千台机器上,进行分布式计算。而为了这一系列的场景,则进行了新的抽象,这就是MapReduce。
二、编程模型(Programming Model) 用户分别编写map、reduce函数。用户输入一组Key/Value,map将会计算输入,并生成一组中间值的K/V,**而这个K生成的规则可以类似于哈希值之类,非常关键。**后续reduce则可以通过相同的k合并value,最终返回结果。
对于单词计数应用case,这里简单画一个图:
map(String key, String value): // key: document name // value: document contents for each word w in value: EmitIntermediate(w, "1"); reduce(String key, Iterator values): // key: a word // values: a list of counts int result = 0; for each v in values: result += ParseInt(v); Emit(AsString(result)); 而这拆分的文档的位置其实也可以看做前面提到的分布式的节点(机器上)。 且按理来说应该是map(k1,v1) => mediate(k2,list1) => reduce(k2,list2)。只是论文中提到的例子k1=k2,也可以理解为,容量足够大,自身即为哈希值。
要使用 Python 实现接收串口数据,需要用到 PySerial 库。下面是一个基本的串口数据接收的 Python 代码示例:
import serial ser = serial.Serial('COM1', 9600) # 将 'COM1' 替换成实际的串口号,9600 是波特率 while True: data = ser.readline() print(data.decode()) 这个程序首先创建了一个串口对象 ser,通过指定串口号和波特率来打开一个串口。接下来通过一个无限循环,不停地从串口中读取数据,并通过 `print
随机生成一个整数数组,并倒序打印,求最大值,平均值,并查找一个数是否在数组中
public class ChaZhao8{ public static void main(String[] args) { int[] arr = new int[10];//此时数组默认全是10 for(int i = 0;i < arr.length;i++){ arr[i] = (int)(Math.random()*100) + 1; } System.out.println("随机产生的数组情况:"); for(int i = 0;i < arr.length;i++) { System.out.print(arr[i]+"\t"); } /*倒序打印*/ System.out.println("\n"+"倒序后的数组情况:"); for(int i = arr.length-1;i >= 0;i--){ System.out.print(arr[i]+"\t"); } double sum = arr[0]; int max = arr[0]; int maxIndex = 0; for(int i = 1;i<arr.length;i++){ sum += arr[i]; if(max < arr[i]){ max = arr[i]; maxIndex = i; } } System.
本文以串口4为例子:
在APB1为72MHz的时钟频率下,是设置不了300波特率的,原因在于 Tx/Rx baud = fck / (16 * reg_value) ,reg_value是写进USART_BRR寄存器里。
比如我们要设置300波特率, reg_value = 72000000/ (16 * 300) = 15000,虽然能计算出来,但注意,USART_BRR的前四位存放的是小数部分,后12位存放的是整数部分,所以整数部分最大位4095,根本达不到15000,因此只能改变APB1的时钟频率。
调用 RCC_PCLK1Config(RCC_HCLK_Div4); 把72MHz除于4 等于18MHz, reg_value = 18000000/ (16 * 300) = 3750 3750这个值是够放的。
双三次插值 - 插值图像任意位置亚像素C++ 一、概念 双三次插值又称立方卷积插值。三次卷积插值是一种更加复杂的插值方式。该算法利用待采样点周围16个点的灰度值作三次插值,不仅考虑到4 个直接相邻点的灰度影响,而且考虑到各邻点间灰度值变化率的影响。三次运算可得到更接近高分辨率图像的放大效果,但也导致了运算量的急剧增加。这种算法需要选取插值基函数来拟合数据,其最常用的插值基函数如图1所示,本次实验采用如图所示函数作为基函数。
加权算法(a可以不取-0.5):点开链接
根据比例关系x/X=m/M=1/K,我们可以得到B(X,Y)在A上的对应坐标为A(x,y)=A(X*(m/M),Y*(n/N))=A(X/K,Y/K)。如图所示P点就是目标图像B在(X,Y)处对应于源图像A中的位置,P的坐标位置会出现小数部分,所以我们假设 P的坐标为P(x+u,y+v),其中x,y分别表示整数部分,u,v分别表示小数部分(蓝点到a11方格中红点的距离)。那么我们就可以得到如图所示的最近16个像素的位置,在这里用a(i,j)(i,j=0,1,2,3)来表示,如下图。
我们要做的就是求出BiCubic函数中的参数x,从而获得上面所说的16个像素所对应的权重W(x)。BiCubic基函数是一维的,而像素是二维的,所以我们将像素点的行与列分开计算。BiCubic函数中的参数x表示该像素点到P点的距离,例如a00距离P(x+u,y+v)的距离为(1+u,1+v),因此a00的横坐标权重i_0=W(1+u),纵坐标权重j_0=W(1+v),a00对B(X,Y)的贡献值为:(a00像素值)* i_0* j_0。因此,a0X的横坐标权重分别为W(1+u),W(u),W(1-u),W(2-u);ay0的纵坐标权重分别为W(1+v),W(v),W(1-v),W(2-v);B(X,Y)像素值为:
二、代码实现C++(可配合读取图片程序使用) #include <iostream> #include <tchar.h> #include "ImageBuffer.h" using namespace CamCtrl; void test() { CImageBuffer mCImageBuffer; mCImageBuffer.LoadFromBmp(_T("1.bmp")); } int main() { test(); return 0; } //功能:双三边插值 //image:输入图片 //iImgWidth:图像宽度 //iImgHeight:图像高度 //dx,dy:亚像素点与整像素点posy在下x,y上的距离 //ipos = (posy - 1)*(iImgWidth)+(posx - 1); //得到ipos double CubicPolynomial(unsigned char * image, int iImgWidth, int iImgHeight, double dx, double dy, int ipos) { // image为图像各个位置的像素值, iImgWidth为图像的宽度, iImgHeight为图像的高度, ipos为当前插值的位置。 // 先计算padding 图像的大小。 int padding_size = (iImgHeight + 2) * (iImgWidth + 2); double * padding_img = new double[padding_size]; // 接着对 padding_img 进行赋值。 // 将原图像的值赋给padding_img的(2,2)-(iImgHeight+1, iImgWidth+1) // 该部分验证无误。 for (int i = 0; i < iImgHeight; i++) { for (int j = 0; j < iImgWidth; j++) { int ipos1 = (i + 1) * (iImgWidth + 2) + (j + 1); int temp = i * iImgWidth + j; padding_img[ipos1] = image[temp]; } } // 第一行的值: 第二行、第三行、第四行的值的线性组合.
目录
ROS Bag概念与使用场景
ROS Bag文件生成的两种方式
ROS Bag文件的解析 (C++实现)
1、rosbag::View
2、完整C++代码示例
ROS Bag文件的解析 (Python实现)
C++与Python 解析ROS Bag文件两种方式的对比
ROS Bag概念与使用场景 ROS Bag是一种文件格式,用于存储ROS系统中的消息。ROS Bag可以将ROS节点发布的消息记录下来,然后在需要的时候将这些消息再次播放回ROS系统中。
ROS Bag通常用于以下场景:
离线数据处理:在无法连接实时ROS系统时,可以使用ROS Bag记录消息,然后在离线状态下进行数据处理和算法开发。数据集收集:ROS Bag可以用于收集数据集,以用于机器学习和深度学习等应用。调试和测试:ROS Bag可以用于调试和测试ROS节点和程序的行为。 ROS Bag文件生成的两种方式 ROS Bag文件以 .bag 扩展名结尾,可以通过以下方法进行保存:
在终端中使用rosbag record命令来记录指定主题的消息,将消息保存到ROS Bag文件中。例如,以下命令将记录名为/scan的激光雷达数据并将其保存到名为scan.bag的文件中: rosbag record /scan -O scan.bag rosbag record 是一个用于记录 ROS 消息到 ROS Bag 文件中的命令行工具。它可以记录指定主题的消息,将消息保存到一个ROS Bag文件中。以下是 rosbag record 命令的常用参数:
-a, --all:记录所有主题。-O, --output-name:指定输出的 ROS Bag 文件名。-b, --buffer-size:设置ROS Bag文件的缓冲区大小。-d, --duration:设置记录时间长度,以秒为单位。-l, --limit:设置记录的消息数量限制。-j, --bz2:使用bzip2压缩来压缩ROS Bag文件。-z, --lz4:使用LZ4压缩来压缩ROS Bag文件。-p, --split:设置ROS Bag文件的分段大小。-t, --topics:指定要记录的主题列表。-x, --exclude:指定要排除的主题列表。 2.
前言 作者在使用Mybatis+Spring Boot框架的时候,遇到了一个需求,就是定期汇总3个用户分表中的数据去重后进行后期处理,实现思路比较简单,但是有一些需要注意的地方。
相关sql 作者对sql语言仅有一定的基础,所以提出的方案未必最优,但是可以解决当前的问题。
对于3个用户表user,user1和user2,可以这样写——
select * from user union select * from user1 union select * from user2 union 和union all的区别 最大的区别就是union对于并集同时完成了去重的操作,相当于使用了distinct,而union all只取并集,不进行任何其他操作。
结合Spring Boot框架 松耦合配置 作者使用了Spring Boot框架,故可以通过配置文件和@ConfigurationProperties注解方便地将所有的表名注入到一个String类型的List中,以供下一步使用。
其中prefix属性表示类中的所有属性都来自于application.yml/application.properties中的sql,如tableList就对应sql.tableList=XXX。
使用foreach标签完成需求 作为Mybatis中最为强大的标签之一的foreach标签,它可以灵活地完成各种批量、循环相关的数据库需求。
Mybatis foreach标签的使用
我们观察上面的sql语句,发现联合查询中共同的是select * from和union,不同的是表名。结合foreach标签的各个属性我们可以这么做。
<select id="selectAllCrossTable" useCache="false" flushCache="false" resultType="com.school.springboot.entity.User"> select * from user union all <foreach collection="list" item="table" separator="union"> select * from ${table} </foreach> </select> 将表名通过${table}注入,使用union作为不同select语句的分隔符,最终就可以得到这样的sql语句
select * from user union select * from user1 union select * from user2 Mapper层 @Mapper public interface UserMapper extends BaseMapper<User> { List<User> selectAllCrossTable(List<String> list); } Service层 @Service(value = "
一、 sonarqube-7.5平台搭建
SonarQube为静态代码检查工具,是管理代码质量一个开放平台,可以快速的定位代码中潜在的或者明显的错误。采用B/S架构,帮助检查代码缺陷,改善代码质量,提高开发速度,通过插件形式,可以支持Java、C、C++、JavaScripe等等二十几种编程语言的代码质量管理与检测。
通过客户端插件分析源代码,sonar客户端可以采用IDE插件、Sonar-Scanner插件、Ant插件和Maven插件方式,并通过各种不同的分析机制对项目源代码进行分析和扫描,并把分析扫描后的结果上传到sonar的数据库,通过sonar web界面对分析结果进行管理
架构图
可以从七个维度检测代码质量:
(1)复杂度分布(complexity):代码复杂度过高将难以理解
(2) 重复代码(duplications):程序中包含大量复制、粘贴的代码而导致代码臃肿,sonar可以展示源码中重复严重的地方
(3) 单元测试统计(unit tests):统计并展示单元测试覆盖率,开发或测试可以清楚测试代码的覆盖情况
(4) 代码规则检查(coding rules):通过Findbugs,PMD,CheckStyle等检查代码是否符合规范
(5) 注释率(comments):若代码注释过少,特别是人员变动后,其他人接手比较难接手;若过多,又不利于阅读
(6) 潜在的Bug(potential bugs):通过Findbugs,PMD,CheckStyle等检测潜在的bug
(7) 结构与设计(architecture & design):找出循环,展示包与包、类与类之间的依赖、检查程序之间耦合度
个人使用之后认为 : sonarQube的优势如下(相比于阿里编码规约这种市面上常见类似软件):
更加优秀的图形化界面
基本上通过界面就可以对自己项目的代码状况一目了然可以查询出其它软件难以定位到的问题
比如 : 可能导致空指针异常的问题 (对象在进行使用前没有加空的判断)
可能导致内存泄漏的问题, 在try catch 块里面,直接使用e.printStackTrace()将堆栈信息打印到内存的
可能导致的漏洞 : 成员变量使用public定义的
还有诸如 : 流等未关闭或者是非正常关闭都能够检测出来!
功能非常强大!! 下面将会介绍一下这个工具的安装、配置以及使用
环境部署:sonar7.5+mysql5.7+ jdk1.8+ sonar-scanner-3.3
准备工作;
1、jdk(不再介绍),sonarqube-7.5使用jdk1.8
2、sonarqube:http://www.sonarqube.org/downloads/
3、SonarQube+Scanner:https://sonarsource.bintray.com/Distribution/sonar-scanner-cli/sonar-scanner-2.5.zip
4、mysql数据库(不再介绍)
sonarqube-7.5对应 MySQL >=5.6 && <8.0
二、 安装篇
1.下载好sonarqube后,解压打开bin目录,启动相应OS目录下的StartSonar。如本文演示使用的是win的64位系统,则打开D:\sonar\sonarqube-5.3\sonarqube-5.3\bin\windows-x86-64\StartSonar.bat
Linux启动命令,sonar的所有者登录执行:
$ sh sonar.sh start
其他:Usage: sonar.sh { console | start | stop | restart | status | dump }
问题:EasyExcel导出xlsx时,某一列的数据为空
问题来源:字段的命名在读取时,出现了问题 这个字段,我们可以debug一下, 有的时候会变成bid ,这个时候就会导致导出字段为空
解决办法:我们只需要在字段上面加上注释 @JsonProperty("bId) 就好了
ChatGPT是一种使用人工智能 (AI) 来理解和响应用户查询的聊天机器人。它是一种复杂的工具,可以理解和解释自然语言,并对用户问题提供量身定制的回答。ChatGPT通常用于改善客户服务和简化沟通,它可以集成到网站、消息传递平台和其他在线工具中。ChatGPT 以其理解和响应广泛的用户查询的能力而闻名,这使其成为希望改善在线交流和参与度的企业和个人的强大多功能工具。
随着越来越多的企业转向聊天机器人来改善客户服务和简化沟通,很自然地想知道这项技术会如何影响您的搜索引擎优化(SEO) 努力。毕竟,SEO 就是要让您的网站更显眼并吸引搜索引擎,而聊天机器人可以成为吸引访问者并提供有价值信息的强大工具。
那么,chatGPT 真的能够影响您的 SEO 吗?简短的回答是肯定的,但重要的是要了解如何以及为什么。
首先,值得注意的是,chatGPT 只是一种使用人工智能 (AI) 来理解和响应用户查询的聊天机器人。虽然 chatGPT 无疑是一个强大而复杂的工具,但它并不是唯一的聊天机器人,它对您的 SEO 的影响将取决于您如何使用它。
也就是说,chatGPT 当然可以通过多种方式帮助改进您的 SEO。一方面,聊天机器人可以帮助访问者在您的网站上停留更长的时间,这有助于提高您在搜索引擎结果中的排名。通过提供有价值和有用的信息,聊天机器人可以帮助保持用户参与并鼓励他们更多地探索您的网站。这可以提高用户满意度,从而有助于提高您在搜索结果中的排名。
此外,chatGPT 可以通过提供更加个性化的用户体验来帮助改进您的 SEO。通过使用 AI 来理解用户查询并提供量身定制的响应,聊天机器人可以帮助为用户创造更加个性化和引人入胜的体验。这有助于改善网站的整体用户体验,这是 SEO 的关键因素。
还值得注意的是,chatGPT 可以通过为用户提供一种与您的网站进行交互的新方式来帮助改进您的 SEO。通过允许用户通过聊天机器人提问并获得答案,您可以创建更加动态和引人入胜的用户体验。这有助于提高网站的整体可用性,这是 SEO 的另一个关键因素。
此外,chatGPT 可以为用户提供一种更有效的方式来访问您网站上的信息,从而帮助改善您的 SEO。通过允许用户提出特定问题并收到量身定制的回复,您可以帮助他们更快、更轻松地找到所需的信息。这有助于改善您网站的整体用户体验,并使用户更有可能在未来回访。
请务必记住,chatGPT 只是改进 SEO 的其中一环。为了真正针对搜索引擎优化您的网站,您需要关注一系列因素,包括:
关键字优化:确保您在整个网站的内容、标题和标签中使用相关且有针对性的关键字。这有助于提高您的网站在这些关键字的搜索结果中的排名。
内容质量:确保您网站的内容质量高、内容丰富且引人入胜。这有助于改善您网站上的用户体验,并鼓励用户在您的网站上花费更多时间。
用户体验:专注于为您网站的访问者创造流畅无缝的用户体验。这可以包括使用响应式设计、轻松导航和快速加载时间。
反向链接:为您的网站建立一个强大的高质量反向链接网络。这有助于提高您网站在搜索结果中的排名并提高其知名度。
通过关注这些因素并使用 chatGPT 改善用户体验并增加参与度,您可以帮助提高网站的排名并提高其在搜索结果中的可见度。
最后,值得注意的是,chatGPT 可以通过提供新的用户参与渠道来帮助改善您的 SEO。通过允许用户通过聊天与您的网站进行交互,您可以创建更具交互性和动态性的用户体验。这有助于提高用户参与度并鼓励用户在您的网站上花费更多时间,从而有助于提高您在搜索结果中的排名。
总之,虽然 chatGPT 只是可以影响您的 SEO 的众多工具中的一个,但它是一个强大而复杂的工具,可以帮助提高您网站的排名和在搜索结果中的可见度。通过使用 chatGPT 改善用户体验、提高用户参与度并为用户提供更有效的信息访问方式,您可以帮助提升网站排名并提高其在搜索结果中的可见度。
安装配置 - nginx : 1.14.2 - node.js : 8.19.3 1. 先将自己在电脑上的 vue项目打包 npm run build 2. 打开 aidlux 的文件管理器 如果不知道怎么打开网页的界面看这里
1. 打开文件管理器 2. 找到home,在home下新建一个 www 的文件夹 然后将刚刚打包好的 dist 文件夹放到这个 www 文件中
3. 然后在根目录下 找到 /etc/nginx/conf.d 在这个文件夹中创建一个 my.conf 配置文件 这个是我的配置文件(实际情况根据个人而定)
server { listen 8899; # 写需要的端口 # 前端页面的端口 location / { root /home/www/dist; # 站定目录 (这里如果是按我刚刚的配置就这么写) index index.html; # 首页文件 } location /api { #(/api 这里一定要确定好 配置的路径) proxy_pass http://localhost:3000; #(配置服务端的端口要和你配置的服务器端口一致) proxy_connect_timeout 3; proxy_send_timeout 30; proxy_read_timeout 30; proxy_set_header X-Forwarded-Host $host; proxy_set_header X-Forwarded-Server $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; client_max_body_size 500m; } } 详细配置教程可参考:
一、小程序开发框架 1:WePY
WePY (发音: /'wepi/) 是小程序上最早的一款类 Vue 语法的开发框架。WePY 2 是基于小程序原生组件实现组件化开发。因此 WePY 2 支持的最低版本小程序基础库为 1.6.3。
2:mpvue
是美团点评开源的一个使用 Vue.js 开发小程序的前端框架。
3:Vant Weapp
轻量、可靠的小程序 UI 组件库
一、强制清除gradle的缓存 问题:有时在开发中我们会上传一些开发jar到远程仓库,当我们打包时版本号不变时有时候我们跟新不到新的jar
问题分析:这个问题一般是因为gradle的缓存机制引起的
解决方案:
1:命令行强制清除缓存 gradle build --refresh-dependencies
2:如果我们明确知道本地gradle仓库位置可以手动删除
一般需要删除.gradle\caches\modules-2\files-2.1和.gradle\caches\modules-2\metadata-2.71\descriptors目录下的对应jar文件就可以
二、加载本地依赖 通过在依赖中指定所需依赖在项目中的相对路径以及匹配规则来加载相应的本地依赖dependencies{compile fileTree(dir: 'src/main/libs', includes: ['*.jar'])}
目录
一、微服务
1.1、微服务技术栈
1.2、微服务的介绍:
1.3、微服务技术对比
1.4、认识微服务-springcloud
1.4.1、springcloud和springboot的兼容性(左边springcloud右边springboot版本)
1.5、服务拆分,服务远程调用(即从order能查到user,用到的是restTemplate,里面有很多API)
1.6、Eureka注册中心
1.7、搭建Eureka
1.8、Eureka服务注册
1.9、Eureka服务发现
1.10、Ribbon负载均衡原理(随机分配)
1.11、Ribbon策略-饥饿加载
1.12、nacos安装
1.13、nacos快速入门
编辑
1.14、nacos服务多级存储模型
1.15、nacosRule负载均衡(集群优先)
1.16、nacos服务实例的权重设置
1.17、nacos环境隔离
1.18、nacos和eureka的对比
二、nacos配置管理(nacos是替代eureka的,是alibaba研发的注册中心)
2.1、nacos配置管理-nacos实现配置管理
2.2、nacos配置管理-微服务配置拉取
2.3、nacos配置管理-配置热更新
2.4、nacos配置管理-多环境配置共享 编辑
2.5、nacos集群搭建
2.6、基于Feign远程调用(替换掉restTemplate)
编辑
2.7、feign自定义配置
2.8、feign性能调优
2.9、feign最佳实践分析
编辑
2.10、统一网关Gateway
编辑
2.11、Gateway快速入门
2.12、Gateway路由断言工厂(在路由里面有路由工厂去判断)
2.13、Gateway网关-路由的过滤器配置
2.14、Gateway网关-全局过滤器
2.15、Gateway网关-过滤器链执行顺序
2.16、Gateway网关-网关的cors跨域配置
三、Docker
3.1、什么是docker
3.2、docker和虚拟机的差别
3.3、Docker架构
3.4、Docker的安装
3.5、Docker-镜像命令
3.6、Docker-容器命令
3.7、Docker-数据卷命令(volume)
3.8、数据卷挂载
3.9、自定义镜像-镜像结构
3.10、自定义镜像-Dockerfile
3.11、DockerCompose
3.12、部署微服务集群
3.13、Docker镜像仓库
四、MQ
4.1、同步
4.2、异步
4.3、MQ常用技术
4.4、RabbitMQ
五、面试题
5.0、分布式和微服务的区别(*)
5.1、springcloud的常见组件有哪些
5.2、Nacos注册表结构
5.3、nacos如何避免并发读写冲突问题
5.4、nacos和eureka的区别
5.5、sentinel和hystrix的区别
zookeeper集群部署 vim /etc/hosts
192.168.1.11 server1
192.168.1.12 server2
192.168.1.13 server3
解压部署zookeeper
tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz -C /usr/local/
mv /usr/local/apache-zookeeper-3.8.0-bin /usr/local/zookeeper
cd /usr/local/zookeeper/conf/
cp zoo_sample.cfg zoo.cfg
修改配置文件zoo.cfg
dataDir=/usr/local/zookeeper/data dataLogDir=/usr/local/zookeeper/datalog autopurge.snapRetainCount=3 autopurge.purgeInterval=0 maxClientCnxns=60 server.1=server1:2888:3888 server.2=server2:2888:3888 server.3=server3:2888:3888 创建相应目录 mkdir /usr/local/zookeeper/data /usr/local/zookeeper/datalog/
复制当前/usr/local/zookeeper目录到其他节点
scp -P 10022 -rp /usr/local/zookeeper server2:/usr/local/
scp -P 10022 -rp /usr/local/zookeeper server3:/usr/local/
配置每一台的myid
server1:
echo 1 > /data/myid
server2:
echo 1 > /data/myid
server3:
echo 1 > /data/myid
进入到zookeeper的bin目录,分别启动zookeeper
./zkServer.sh start
./zkServer.sh status 验证。
问题描述 系统使用者在进行lvm扩容时操作不当导致系统出现了很多unknown的pv,无法删除,扩容失败
尝试执行vgreduce --removemissing /dev/klas(卷组名)无法删除。
注:--removemissing:删除卷组中丢失的物理卷,使卷组恢复正常状态。
通过vgs、pvs、lvs命令查看,都会报错有PV not found
问题解决步骤 1、通过fdisk /dev/vda 将/dev/vda4删除。删除后,w保存q退出。再使用partprobe。更新分区信息。
2、使用如下命令,通过vgcfgrestore结合元数据日志恢复vg。(恢复有风险)
vgcfgrestore -f /etc/lvm/archive/klas-00001-1232432432.vg klas #恢复。
问题:mount时 虚拟盘/dev/klas找不到
解决:
lvchange -ay /dev/klas
mount -a
问题解决
一、Mysql-mmm集群技术概述;
概述:MMM(Master-Master replication manager for MySQL)是一套支持双主故障切换和双主日常管理的脚本程序。MMM使用Perl语言开发,主要用来监控和管理MySQL Master-Master(双主)复制,可以说是mysql主主复制管理器。
虽然叫做双主复制,但是业务上同一时刻只允许对一个主进行写入,另一台备选主上提供部分读服务,以加速在主主切换时刻备选主的预热,可以说MMM这套脚本程序一方面实现了故障切换的功能,另一方面其内部附加的工具脚本也可以实现多个slave的read负载均衡。
MMM提供了自动和手动两种方式移除一组服务器中复制延迟较高的服务器的虚拟ip,同时它还可以备份数据,实现两节点之间的数据同步等。由于MMM无法完全的保证数据一致性,所以MMM适用于对数据的一致性要求不是很高,但是又想最大程度的保证业务可用性的场景。
二、Mysql-mmm优缺点;
优点:高可用性,扩展性好,出现故障自动切换,对于主主同步,在同一时间内只提供一台数据库写操作,保证数据的一致性。
缺点:Monitor节点是单点,可以结合Keepalived实现高可用。
三、Mysql-mmm内部工作架构;
进程类型:
mmm_mond:监控进程,负责所有的监控工作,决定和处理所有节点角色活动。此脚本需要在监管机上运行;
mmm_agentd:运行在每个mysql服务器上(Master和Slave)的代理进程,完成监控的探针工作和执行简单的远端服务设置。此脚本需要在被监管机上运行;
mmm_control:一个简单的脚本,提供管理mmm_mond进程的命令;
工作原理:
mysql-mmm的监管端会提供多个虚拟IP(VIP),包括一个可写VIP,多个可读VIP;
通过监管的管理,这些IP会绑定在可用mysql之上;
当某一台mysql宕机时,监管会将VIP迁移至其他mysql;
案例搭建Mysql-mmm+mysql 5.6双主高可用集群;
案例环境:
系统
IP地址
主机名
所需软件
Centos 7.4 1708 64bit
192.168.100.1
master1
mysql-5.6.36.tar.gz
mysql-mmm
mysql-mmm-agent
mysql-tools
Centos 7.4 1708 64bit
192.168.100.3
master2
mysql-5.6.36.tar.gz
mysql-mmm
mysql-mmm-agent
mysql-tools
Centos 7.4 1708 64bit
192.168.100.5
slave1
mysql-5.6.36.tar.gz
mysql-mmm
mysql-mmm-agent
mysql-tools
Centos 7.4 1708 64bit
192.168.100.6
slave2
mysql-5.6.36.tar.gz
mysql-mmm
mysql-mmm-agent
mysql-tools
Centos 7.
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。在使用spring-boot操作MongoDB数据库前,先了解一些MongoDB的基本概念和增删改查操作。下面是MongDB中某些概念与关系性数据库中概念类别。
在安装MongoDB数据库后,在terminal中输入mongodb命令,即可进入命令行模式,对mongDB进行增删改查操作,如下图所示,切换到myDB数据库,并对col collection进行查询操作。
这里整理了几个常用的增删改查脚本,可以在命令行中逐一输入验证,另外,除了操作数据外,还可以创建各种管理权限的用户。
db.mycol2.insert({"name" : "Demo教程"}) //自动创建集合
db.createCollection("mycol", { capped : true, max : 10000 } ) //创建集合并插入数据
db.COLLECTION_NAME.insert(document)或db.COLLECTION_NAME.save(document) //插入Document
db.col.insert({title: 'MongoDB教程', description: 'Nosql',tags: ['mongodb', 'database', 'NoSQL']}) db.col.update({'title':'MongoDB教程'},{$set:{'title':'MongoDBNew'}}) //updateDocument
db.col.find().pretty() //查询Document
db.createUser({user: "Guru99",pwd: "password",roles:[{role: "userAdminAnyDatabase" , db:"admin"}]}) //在admin数据库中创建管理员用户Guru99,用户角色是userAdminAnyDatabase,该角色允许用户对MongoDB中的所有数据库具有管理特权。
db.createUser({user: "Employeeadmin",pwd: "password",roles:[{role: "userAdmin" , db:"Employee"}]}) //在Employee数据库中创建普通用户Employeeadmin,角色是userAdmin,该角色允许用户仅对db选项中指定的数据库具有管理特权。
db.createUser({user: "Mohan",pwd: "password",roles:[{role: "read" , db:"Marketing"},role: "readWrite" , db:"Sales"}}]})
//创建用户Mohan,对Marketing数据库具备只读权限,对Sales数据库具备读写权限
上面的查询只是简单查询,如果要进行更加复杂的条件,应该如何编写了呢?下面总结了常用的查询条件
除了查询操作,还可以对Collection进行聚合操作,例如groupby等,具体如下所示:
聚合操作和管道相集合,例如$project控制显示的结果的数据结构字段,具体如下所示:
聚合操作除了上面的使用场景外,还可以通过$lookup支持多表关联查询,语法规则如下所示
{ $lookup: { from: <collection to join>, localField: <field from the input documents>, foreignField: <field from the documents of the "
Elisa数据通常可以使用多种分析方法,具体取决于实验目的和数据特征。常用的分析方法包括:
免疫比浊法 (Immunoassay titration):用于确定抗原或抗体的浓度。
全面反应曲线分析 (Competitive reaction curve analysis):用于确定抗原抗体互补作用的结合常数。
点状免疫吸附试验 (Dot blot immunoassay):用于检测抗原的存在与否,并评估其相对浓度。
单抗夹带试验 (Monoclonal antibody sandwich assay):用于检测特定分子的存在与否,并评估其浓度。
在选择分析方法
CountDownLatch概念 CountDownLatch是一个同步工具类,用来协调多个线程之间的同步,或者说起到线程之间的通信(而不是用作互斥的作用)。
CountDownLatch能够使一个线程在等待另外一些线程完成各自工作之后,再继续执行。使用一个计数器进行实现。计数器初始值为线程的数量。当每一个线程完成自己任务后,计数器的值就会减一。当计数器的值为0时,表示所有的线程都已经完成一些任务,然后在CountDownLatch上等待的线程就可以恢复执行接下来的任务。
CountDownLatch的用法 CountDownLatch典型用法:1、某一线程在开始运行前等待n个线程执行完毕。将CountDownLatch的计数器初始化为new CountDownLatch(n),每当一个任务线程执行完毕,就将计数器减1 countdownLatch.countDown(),当计数器的值变为0时,在CountDownLatch上await()的线程就会被唤醒。一个典型应用场景就是启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行。
CountDownLatch典型用法:2、实现多个线程开始执行任务的最大并行性。注意是并行性,不是并发,强调的是多个线程在某一时刻同时开始执行。类似于赛跑,将多个线程放到起点,等待发令枪响,然后同时开跑。做法是初始化一个共享的CountDownLatch(1),将其计算器初始化为1,多个线程在开始执行任务前首先countdownlatch.await(),当主线程调用countDown()时,计数器变为0,多个线程同时被唤醒。
CountDownLatch的不足 CountDownLatch是一次性的,计算器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当CountDownLatch使用完毕后,它不能再次被使用。
在实时系统中的使用场景 让我们尝试罗列出在java实时系统中CountDownLatch都有哪些使用场景。我所罗列的都是我所能想到的。如果你有别的可能的使用方法,请在留言里列出来,这样会帮助到大家。
1.实现最大的并行性:有时我们想同时启动多个线程,实现最大程度的并行性。例如,我们想测试一个单例类。如果我们创建一个初始计数为1的CountDownLatch,并让所有线程都在这个锁上等待,那么我们可以很轻松地完成测试。我们只需调用 一次countDown()方法就可以让所有的等待线程同时恢复执行。
2.开始执行前等待n个线程完成各自任务:例如应用程序启动类要确保在处理用户请求前,所有N个外部系统已经启动和运行了。
3.死锁检测:一个非常方便的使用场景是,你可以使用n个线程访问共享资源,在每次测试阶段的线程数目是不同的,并尝试产生死
CountDownLatch上手 场景:扫描26家中烟公司的品规信息,保存到redis缓存中
首先是不使用多线程情况下
public void scanSpu() { log.info("定时扫描中台spu信息开始================="); long start = System.currentTimeMillis(); // 中烟公司列表(包含工业公司) List<ListOrgIdAndNameDTO> orgIdAndNameDTOList = orgService.listZYOrgIdAndName(true); List<Product> productList = new ArrayList<>(); if (CollectionUtils.isNotEmpty(orgIdAndNameDTOList)) { //这里需要遍历26次 for (ListOrgIdAndNameDTO listOrgIdAndNameDTO : orgIdAndNameDTOList) { productList.addAll(querySpuList(listOrgIdAndNameDTO)); } long expireTime = 24 * 60 * 60; log.info("扫描中台spu信息共计:{}条", productList.size()); redisUtil.del(SpuScheduledTaskConstant.SPU_LIST_REDIS_KEY); //将productList 放入缓存 redisUtil.set(SpuScheduledTaskConstant.SPU_LIST_REDIS_KEY, productList, expireTime); } long end = System.
@[TOC](ubuntu16.04 安装多版本cuda(原10.0,新安装10.1),实现任意切换)
前言 需求:单位需要使用yolo-v5训练模型,可所需的pytorch对cuda的依赖版本较高,而仅仅安装单个高版本的cuda又会与原先的项目产生矛盾,所以纠结一下,研究了安装双cuda步骤,记录一下
一、下载cuda地址: cuda官方下载地址: https://developer.nvidia.com/cuda-toolkit-archive
cudnn官方下载地址:https://developer.nvidia.com/rdp/cudnn-download
我使用的cuda版本与cudnn版本如下所示:
下图是英伟达显卡驱动与cuda的版本对照:
英伟达显卡驱动需要由较高cuda版本对应的显卡驱动来确定;更新英伟达显卡驱动可以在安装cuda时选择安装,但是本人多次尝试都失败告终,最后使用ubuntu的自带的更新功能成功,如下界面:
二、安装cuda10.1 sudo chmod +x cuda_10.1.105_418.39_linux.run # 为 cuda添加可执行权限 sudo ./cuda_10.1.105_418.39_linux.run # 安装 稍等片刻后会出现如下安装提示:
3、如果之前安装过另一个版本的cuda,除非你确定想要用这个新版本的cuda,否则这里就建议选n,因为指定该链接后会将cuda指向这个新的版本
4. cuda环境设置:
sudo gedit ~/.bashrc 打开后在末尾添加以下语句
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}} export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}} export CUDA_HOME=/usr/local/cuda 以上的路径都是指向/usr/local/cuda 软连接,并没有写死指向某一个cuda版本,后面切换时不用改路径了,只改软连接指向就可以。
保存关闭后:
source ~/.bashrc 三、cuda版本切换 切换/usr/local/目录
sudo rm -rf cuda #删除之前的软链接(原本指向10.0) sudo ln -s /usr/local/cuda-10.1 /usr/local/cuda #生成新的软链接,指向10.1 在/usr/local/ 目录下,以下四行命令均可以查看当前cuda软链接指向的哪个cuda版本
stat cuda # stat /usr/local/cuda cat /usr/local/cuda/version.txt nvcc --version nvcc -V ls -al # 在/usr/local目录下查看 当需要cuda10.
0x34请求下载 0x34 00-FF 44
数据格式标志符,【00-FF】,左半元组表示压缩方法,右半元组表示加密算法,如果没有应用压缩或者加密,相应位为0
44的bit7~4表示memorysize参数的长度
bit3~0表示memoryadress参数的长度
36数据传输 TransferData (0x36)—— 数据传输
这个服务通常是用来下载/上传数据时用的,数据的传输方向由不同的服务控制:0x34服务表示下载,0x35服务表示上传。
0x36服务包含了一个blockSequenceCounter,在多个服务请求序列失败的时候以提高错误处理机制。在接收到0x34/0x35服务以后,blockSequenceCounter会被初始化为1。
服务请求报文中参数定义:
(1)blockSequenceCounter
这个值在第一次初始化的时候为0x01,往后每增加一次0x36服务的请求这个值也跟着增加1,直到增加到0xFF,会重新再从0x00增加(笔者的理解就是blockSequenceCounter的值对应用户此次请求传输出去的数据,以确保数据传输无误)。
例如以下2种情形:
数据已经正确的传输给ECU了,但是用户这边没有收到肯定响应,timeout以后用户这边会再次重复刚刚发出去的数据(blockSequenceCounter还是之前那个值)。这时候ECU通过blockSequenceCounter的值就可以知道用户又重复传了一次相同的数据,就不用再次重新写一遍Memory而直接给用户发送肯定响应。
如果数据没有正确传输给ECU,用户这边也不会收到肯定响应,timeout以后用户这边会再次重复刚刚发出去的数据(blockSequenceCounter还是之前那个值)。这时候ECU通过blockSequenceCounter的值就可以知道这是新传来的数据,则执行写Memory的操作,并且在成功后发送相应的肯定响应。
0x73 强制要求
服务器检测到数据传输的BlockSequenceCounter错误时,回复此编码
37请求退出传输
1 .部署k8s的两种方式 目前生产部署Kubernetes集群主要有两种方式:
kubeadm
Kubeadm是一个K8s部署工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群。
二进制包
从github下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群。
本实验采用kubeadm的方式搭建集群。
2.部署环境 NAME
IP
OS-IMAGE
VERSION
DOCKER VERSION
CALICO VERSION
master
192.168.0.220
el7.x86_64
v1.23.0
23.0.1
v3.9.0
node01
192.168.0.6
el7.x86_64
v1.23.0
23.0.1
v3.9.0
3.初始化配置 修改主机名
修改 hosts 文件
关闭防火墙
关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久 setenforce 0 # 临时 关闭 swap分区,然后重启
swapoff -a # 临时 sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久 同步各节点时间
#安装ntpdate yum -y install ntpdate 运行命令:crontab -l 添加:0 */1 * * * ntpdate time1.
IPTV简介
IPTV主要是运营商于城域网等骨干网络中部署视频专用服务器作为视频源,并在该服务器中内置视频资源,以供接入该运营商线路的机顶盒播放视频节目。IPTV系统的特点是实时性强,能实现实时直播、直播回放、点播等业务。
系统组网
IPTV系统由前端设备、网络传输和终端设备三部分组成:
前端设备:主要是指视频专用服务器,作为视频源不仅需要加加密的视音频流媒体节目以IP单播/组播的方式推送,还需要支持对用户或用户终端设备进行认证。网络传输:视频源推送的IP组播/单播视频流会在城域网、骨干网络中传输,常见PIM协议部署的ASM(任意组播源模型)和SSM模型(指定组播源模型),通过组播路由和路由交换将视频流最终送达到所需用户侧的终端设备。终端设备:目前市面上最常见的设备为机顶盒,用来接收、存储和播放及转发IP视音频流媒体节目。 网络架构
常见的运营商家庭IPTV、园区IPTV、酒店IPTV、在线直播、网络电视等组网场景下对于IPTV功能的实现依赖于组播技术,它有效地解决了单点发送、多点接收的问题,能够大量地节约网络带宽、降低网络负载。
典型的组网常见使用PIM协议进行部署,如下:
通过运营商部署的PIM网络,实现家庭网络用户能接收到视频服务器的视频流,以正常观看电视节目。
典型配置案例:在路由器上配置PIM-SM协议,为网络中的用户主机提供ASM服务,使得加入同一组播组的所有用户主机(家用机顶盒)能够接收任意源发往该组的组播数据信息观看IPTV电视直播。
【PIM网络配置思路】
PIM协议依赖单播路由协议。配置PIM路由路各个接口的IP地址,并配置IGP协议(本例使用OSPF,且不考虑跨域方案)实现PIM路由器互通;;所有PIM路由器使能组播功能(multicast routing-enable),所有接口使能PIM-SM;与家庭网络中光猫相连的路由器接口上使能IGMP(入户光猫一般作为IGMP代理,可直接视为用户侧主机),Receiver机顶盒通过发送IGMP消息自由加入或离开;配置AR2为主RP,AR1为备RP以实现RP动态冗余。PIM-SM域中,RP是提供ASM服务的核心,是转发组播数据的中转站;配置AR1为主BSR,AR2为备BSR以实现BSR冗余。BSR负责收集网络内的RP信息,为每个组选举出RP,然后将RP集(即组-RP映射数据库)发布到整个PIM-SM网络。 本文就不附实验配置了,感兴趣的同学可以在华为官网参考相关实验配置实现。
【PIM网络数据流转发原理】
(1)完成配置后,Receiver1(192.168.1.254/24)和Receiver2(192.168.2.254/24)的机顶盒会发IGMP报告加入组播组,前者为224.1.1.1后者为239.1.1.1;
(2)(*,G)表项在用户侧路由到RP沿途生成并建立共享树,分别为:Receiver1-AR1-AR2和Receiver2-AR5-AR2:
(3)AR2 PIM路由表可以看到224.1.1.1的组播流需要向下联口G0/0/0转发,239.1.1.1需要向下联口G0/0/2转发::
(4)视频服务器会向PIM网络中发流(如224.1.1.1的直播流和239.1.1.1的直播流),其所连接的DR路由器此时会通过单播的方式找到RP完成注册信息,(S,G)表项在组播源路由器到RP沿途生成并建立源树,即:视频服务器-AR4-AR2:
(5)源树沿途建立完成后,直播流通过源树到达RP,RP向第一跳路由器(AR4)发送注册停止(Register-Stop)消息,停止注册过程。此时AR2 PIM路由表可以看到(S,G)表项:
a. 来自源视频服务器172.1.1.1的224.1.1.1直播流上联口为G0/0/1下联口为G0/0/0:
b. 来自源视频服务器172.1.1.2的239.1.1.1直播流上联口为G0/0/1下联口为G0/0/2
(6)IPTV数据流沿着SPT(源树)流向RP,再从RP沿着RPT(共享树)流向Receiver机顶盒,最终完成电视节目的正常播放:
(7)当IPTV数据流达到一定速率后会触发RPT向SPT的切换,用户侧路由器(AR1和AR5)知道视频流源IP就能通过IGP最短路径找到组播源DR(AR4),从而建立新源树(AR1-AR2-AR4和AR5-AR2-AR4)直接转发数据流,如果与源共享树路径不一致会“剪枝”阻断数据流(本例中新SPT路径和旧RPT+SPT路径一致,在此不做过多详解)。
IPTV直播与换台
运营商PIM网络至用户侧机顶盒部署完成后,在家里将机顶盒接入光猫专用IPTV口,然后在接上电视就就能观看IPTV节目啦!
日常使用中,每个直播频道都会对应一个组播组,更换节目频道即“离开上一个组播组,加入新组播组取流的过程”:
更多组网方案可关注微信公众号:网络工程师解决方案与技术
作者:小云君
不少同学都在关注2022下半年软考证书领取时间,截止至目前,上海、湖北、江苏、南京、安徽、山东、浙江、宁波、江西、贵州、云南、辽宁、大连、吉林、广西地区的纸质证书可以领取了。
将持续更新2022下半年软考纸质证书领取时间,请同学们在证书申领时间内及时预约证书邮寄发放哦~
证书领取方式: 2022年下半年软考证书领取方式(仅供参考):
1.个人领取。考生携带身份证、准考证、成绩单等相关材料前往指定地点办理现场领取。
2.他人代领。如考生本人无法前往领取合格证书,可由他人代领,代领人需提供本人及考生身份证原件、复印件、证书代领委托书。
3.证书邮寄。考生可登录官方指定渠道,填写邮寄信息办理证书直邮服务。
因2022年下半年软考证书发放工作由各地区软考办及人事考试中心负责,证书领取具体方式略有不同,证书代领及邮寄服务并非全国统一,部分地区不支持他人代领证书和邮寄,具体相关要求请考生以当地相关单位发布的领证通知为准。
除纸质版证书之外,目前浙江、广东、山东等地区也实行了电子证书,根据人社局《关于推行专业技术人员职业资格证书网络查询验证服务的通知》(人社厅发〔2019〕27号)可以得知,个人和机构均可以通过中国人事考试网证书查询验证系统进行证书查询验证。证书持有人可通过证书查询验证系统自行下载打印本人所持证书的电子证书或电子文件。
祝贺各位通过的友友,记得及时领取证书~
1. Redis主从复制 1.1 概述 单个Redis支持的读写能力是有限的,此时我们可以使用多个redis来提高redis的并发处理能力,这些redis如何协同,就需要有一定的架构设计,这里我们首先从主从(Master/Slave)架构进行分析和实现。
1.2 架构图 其中,master负责读写,并将数据同步到slave,从节点负责读操作。
1.3 快速入门 基于redis,设计一个主从架构,一个Master,两个Slave,其中Master负责Redis读写操作,并将数据同步到Slave,Slave只负责读.,其步骤如下:
第一步:将redis01拷贝两份。
cp -r redis01/ redis02 cp -r redis01/ redis03 第二步:假如已有redis服务,先将原先所有的redis服务停止(docker rm -f redis 容器名),并启动新的redis容器。
创建第一个redis服务:
docker run -p 6379:6379 --name redis6379 \ -v /usr/local/docker/redis01/data:/data \ -v /usr/local/docker/redis01/conf/redis.conf:/etc/redis/redis.conf \ -d redis redis-server /etc/redis/redis.conf \ --appendonly yes 创建第二个redis服务:
docker run -p 6380:6379 --name redis6380 \ -v /usr/local/docker/redis02/data:/data \ -v /usr/local/docker/redis02/conf/redis.conf:/etc/redis/redis.conf \ -d redis redis-server /etc/redis/redis.conf \ --appendonly yes 创建第三个redis服务:
docker run -p 6381:6379 --name redis6381 \ -v /usr/local/docker/redis03/data:/data \ -v /usr/local/docker/redis03/conf/redis.
这个错误的意思是,您在尝试调用 std::basic_ifstream 的构造函数,但是没有找到匹配的函数,即没有重载的构造函数接受 std::string 类型的参数。 要解决这个问题,您需要使用字符数组或者 C 风格字符串代替 std::string 作为 basic_ifstream 的构造函数的参数,例如:
#include <fstream> #include <string> int main() { std::string fileName = "example.txt"; std::basic_ifstream<char> file(fileName.c_str()); // ... return 0; }
一、什么是深拷贝和浅拷贝 浅拷贝是创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值,如果属性是引用类型,拷贝的就是指向内存的地址 ,所以如果其中一个对象改变了这个引用类型的值,就会影响到另一个对象。深拷贝是将一个对象从内存中完整的拷贝一份出来,从堆内存中开辟一个新的区域存放新对象,且修改新对象不会影响原对象。 二、实现深拷贝的五种方式 1、递归调用
// 递归调用 const deepCopy = (obj) => { // 判断传入的值是否为一个对象 if (obj === null && typeof obj !== "object") { return obj; } // 判断对象的类型 注意这里不考虑包装类对象 if (Object.prototype.toString.call(obj) === "[object Date]") { return new Date(obj); } if (Object.prototype.toString.call(obj) === "[object RegExp]") { return new RegExp(obj); } if (Object.prototype.toString.call(obj) === "[object Undefined]") { return new Error(obj); } // 判断对象是类 let newObj = Array.isArray(obj) ? [] : {} for(let item in obj){ if(typeof obj[item] === 'object') { newObj[item] = deepCopy(obj[item]) }else { newObj[item] = obj[item] } } return newObj }; const foo = { name: '张三', info: { age: 24 } } const newFoo = deepCopy(foo) console.
1、转换 aab包 为 apks 说明: 1、bundletool-all-1.11.2.jar 转换文件的工具
2、a.aab aab源文件
3、xxx.apks 导入的文件以及路径(例如:D:\Android\xxx.apks)
4、–ks=xxxx.jks 该aab打包所需的jsk文件
5、三条命令为 jsk打包所需的签名配置
–ks-pass=pass:xxx 存储密码(storePassword)
–ks-key-alias=xxx 秘钥别名(keyAlias)
–key-pass=pass:xxx 秘钥密码(keyPassword)
java -jar D:\Android\bundletool-all-1.11.2.jar build-apks --bundle=a.aab --output=xxx.apks --ks=xxxx.jks --ks-pass=pass:xxx --ks-key-alias=xxx --key-pass=pass:xxx 2、安装apks文件 说明: b.apks 第一条中保存的apks文件路径以及文件名称(例如:D:\Android\xxx.apks) java -jar D:\Android\bundletool-all-1.11.2.jar install-apks --apks=b.apks 注意: 安装成功后并不会提示其他信息,只有以下一条信息。安装时会存在安装失败的情况,具体请查看错误日志 The APKs have been extracted in the directory: C:\Users\ADMINI~1.DES\AppData\Local\Temp\434263751887352571 bundletool.jar 下载地址 :https://github.com/google/bundletool/releases 跳转链接
1、数学函数:操作一个数据,返回一个结果
(1)取上限 ceiling 如果有一个小数就取大于它的一个最小整数 列如9.5 就会取到 10
select code,name,ceiling(price) from car
(2)取下限 floor 如果有一个小数就会舍掉小数点以后的数取整
select floor(price) from car
(3)ABS 绝对值 一张表中有负数就会变成正数
(4)派PI(),圆周率,括号里不需要加东西
(5)ROUND 四舍五入
select round(3.14,1) l两个参数 前面是一个小数,后面是表示保留几位小数
(3.16,1)输出的结果就是3.2
(6)SQRT 开根号
(7)SQUARE平方,自己乘以自己
2、字符串函数:
(1)转换成大写 select upper(pic) from car
(2)转换成小写 select lower() from car
(3)select ltrim(’ 123 ') 去左空格
(4)select rtrim(’ 123 ') 去右空格
(5)space() 里面放几个数字,就打印出几个空格
(6)LEFT ,类似于substring,从左边开头截取,select LEFT(‘123456’,3) 结果是123
(7)select len(‘aaaaaa’) 返回几个长度
(8)select replace(‘aaaaabbaaaaa’,‘bb’,‘haha’) 把第一个字符串中的bb替换成haha
(9)select reverse(‘abc’) 结果是cba
(10)select str(1.
更改家用WiFi密码 一、登录路由器ip地址二、进入WiFi设置改密码和名称 一、登录路由器ip地址 在浏览器上面输入 192.168.1.1 或者 192.168.0.1/192.168.1.0
一般路由器登录ip地址都是这几个,一般路由器说明书上都会有写的,要么自己上网查询下自己路由器的型号就会知道地址ip跟用户名和密码。一般用户名都是admin,密码为admin、12345678、为空或者其他固定值(参考路由器背面说明),参考样图:
浏览器输入 : 192.168.1.1
二、进入WiFi设置改密码和名称 先点击进入wifi设置
1、只改WiFi密码:
2、改WiFi名称和密码:
保存设置后即可完成更改。
AIGC将成为重要的软件供应链 近日,OpenAI推出的ChatGPT通过强大的AIGC(人工智能生产内容)能力让不少人认为AI的颠覆性拐点即将到来,基于AI将带来全新的软件产品体验,而AI也将会成为未来软件供应链中非常重要的一环。
在OpenAI的文档中,例举了可以利用其实现的48种应用场景,人们在积极探索如何将以ChatGPT为代表的AI能力应用到各行各业。
OpenAI中的应用举例
从应用上,学生可能成为了第一批的风险群体。在线课程厂商Study.com针对1000名18岁以上学生的调研发现,89%的美国大学生使用ChatGPT做家庭作业,53%的学生用它写论文,48%的学生使用ChatGPT完成考试。为了避免学生过于依赖此类工具,防止作弊,多个国家的学校已经开始禁止学生使用ChatGPT。
针对ChatGPT带来的影响还没有系统性的研究,而在ChatGPT之前,2021年OpenAI与GitHub联手推出了AI代码生成工具Copilot。Copilot基于OpenAI通过数十亿行代码训练的Codex模型,能够基于上下文中的内容实现代码的自动补全。在其推出的首月就有超过40万的开发者订阅,而类似的工具还有tabnine、亚马逊公司的CodeWhisperer,都在「抢占」程序员写代码的空间。
GitHub Copilot工作原理
GitHub通过实验发现:
使用 Copilot 能够显著提高开发者的任务完成率(实验中使用Copilot的完成率为 78%,而未使用的为 70%)
使用 Copilot 的开发者的开发速度比不使用要高55%,提升显著(使用 Copilot 的开发者平均用时为 1 小时 11 分钟,而未使用的开发者平均用时达 2 小时 41 分钟)
而在体验上,通过调研发现:
90%的开发者认为提升了工作的速度
60% 至 75%的开发者认为对工作的满意度有所提升
87%的开发者在处理重复性工作时缓解了精神内耗
可以预见,会有越来越多的开发者基于Copilot这类的智能代码生成工具进行开发,其生成的代码结果可能随着时间的积累被更多开发者信任。
作为软件供应链将带来的安全及合规风险 安全问题本质上是信任问题,对于AIGC尤是,随着其应用的广泛,人们接触到的各类内容都可能是AI生成的。
由此对于开发者、用户而言,可能存在以下风险:
引入漏洞代码 根据 OpenAI 的评估,Codex 只有 37% 的几率会给出正确代码。除了存在无法运行的bug以外,基于AI编写的代码可能引入漏洞。Hammond Pearce等人通过研究89个场景中生成的代码,发现GitHub Copilot给出的结果中40%存在漏洞。如下图中生成的python代码,由于将参数直接拼接进SQL语句中,导致存在SQL注入风险。
GitHub Copilot生成的漏洞python代码示例
究其原因,可能由于Copilot的训练数据来自于开源代码,大量的开源代码以个人项目为主,不会像在企业场景或在真实场景中使用一样考虑其安全性,也就是其数据从安全性上可能就存在不均衡;而在训练样本选择时可能也未对其安全性进行检测、过滤,直接用于训练,因此导致开发者直接使用生成的代码,有很大几率引入漏洞风险。
模型被投毒 数据源投毒
模型训练的数据通常来源于公开获取的内容,如果数据源被攻击者控制,在数据标注时又未进行识别,攻击者就可能通过在数据源中添加恶意数据,干扰模型结果。对于数据源较为单一的场景,投毒的可能性更高。最近Google在发布Bard时就因为提供了错误的事实结果,导致当日股价大跌。在被问及“关于詹姆斯韦伯望远镜的新发现,有什么可以告诉我九岁孩子的?”时,Bard 回答:“第一张系外行星照片是由詹姆斯韦伯望远镜拍摄。”而事实却是由欧洲南方天文台的甚大望远镜在 2004 年拍下的,此时距离詹姆斯韦伯望远镜升空还有 18 年之久。
Bard 关于詹姆斯韦伯望远镜演示截图
使用过程投毒
如ChatGPT使用了基于人工反馈的强化学习机制,AIGC模型可能根据用户的反馈来对其模型进行修正。如同区块链中的51%攻击,如果模型被大量的用户对同一个内容提交错误的反馈,那么模型则会被错误地修正。如果攻击者发现了类似调试模式的开关,也可能站在模型开发者的上帝视角实现投毒。
OpenAI针对AI模型存在一些限制策略,不允许ChatGPT输出。而Reddit中一位名叫walkerspider的用户发现,可以通过对话赋予ChatGPT一个打破限制的沙盒环境,从而让ChatGPT不受到其策略限制,这类行为被称作提示符注入攻击(prompt injection)。
使ChatGPT假装成一个不受限制的DAN
模型存在后门 当模型变得越来越强大,也就会被赋予越来越多的能力,原来只是生成内容的AI,可能具备执行其他工作的bot能力,这些能力可能被滥用甚至作为后门进行入侵。
来自斯坦福大学的学生 Kevin Liu就通过提示符注入发现了微软新上线的聊天机器人(Bing Chat)存在的开发调试模式,通过对话让AI进入开发者覆盖模式(Developer Override Mode),他了解到Bing Chat在微软内部称为Sydney,了解到它创建的时间以及模型的规则限制。
前言:时隔一年多了,不知不觉博客停更那么久了,那不忘初心还记得吗? 最近在做音视频相关的开发,没什么资料并且之前也没有接触过这方面, 咨询了T届的好友,拿到了下面的这张表情包,问题是当我百度的时候才 发现与我想要知道的相关文档是没有一篇能满足,东拼西凑的找文档,可 还是没办法实现想要的功能,于是我陷入了沉思......最终还是轻松搞定 了这个需求,于是我打开了csdn想给后人留一片树荫。 最后奉上工具的学习资料(感兴趣的可以看看),废话不多说!!!!!
FFmpeg是啥: ffmpeg(命令行工具) 是一个快速的音视频转换工具。
FFmpeg能干啥:如果你用过爱剪辑的话或者其他一些音视频处理软件的话,你可以理解他们能做的你用玩意都能做。
为啥要用FFmpeg:开源免费啊,你用软件要收费呢,但是这不是关键,核心是你要整合进Java,怎么用Java和执行它,也就是你咋去写个爱剪辑呢(当然呢那种东西靠一个两个人也是很难写出来的,本文结合实际情况处理一下小问题还是绰绰有余)。
FFmpeg先去这学习一下再来看哦
1、我的需求 需要将mp3,m4a,m4r,wma,amr,aac,ac3,ape,flac,mmf,ogg类型格式的音频转成wav格式并指定声道和采样率;
需要将mp4,3gp,mov,m4v,mkv,flv,vob,wmv,rm,rmvb,dat,asf,asx,avi类型格式的视频先提取音轨再转成wav格式并指定声道和采样率;
2、设计&编码 当时了解到的技术选型就是ffmpeg工具了,去简单的学习了一下这个工具的基础语法以及音视频开发的基本规范和格式。
于是我写了工具类FFmpegUtils
package com.iflytex.bohai.utils; import lombok.Data; import lombok.extern.slf4j.Slf4j; import org.apache.commons.io.FilenameUtils; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Configuration; import java.io.BufferedReader; import java.io.File; import java.io.IOException; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.List; /** * 利用ffmpeg进行音频视频操作,需先下载安装ffmpeg */ @Slf4j @Data @Configuration public class FfmpegUtil { @Value("${ffmpeg.temppath}") private String tempPath;//保存音频、视频的临时文件夹 @Value("${ffmpeg.ffmpeg-util-path}") private String ffmpegUtilPath;//工具包路径 /** * 将音频统一转成wav格式 * @param inputPath 输入文件 * @param sampleRate 采样率 */ public String transcodeToWav(String inputPath, String sampleRate) throws IOException, InterruptedException { createTempDir(); List<String> command = new ArrayList<>(); command.
正下文:
解决办法有两种,第一种(第二种自己去搜一下,哈哈哈)
右击,点击属性
点击,编辑
点击,添加
输入 au 点击回车
确定之后,再次点击确定就OK了
Error cause
缘由
try {
const rawResource = await fetch(“/source”);
const newResource = doComputationalJob(rawResource);
await fetch(“/upload”, { method: “POST”, body: newResource });
} catch (err) {
console.log(err); // TypeError: Failed to fetch
}
复制代码
在上面代码中,我们捕捉了错误,我们没法知道是/source接口还是/upload接口报错,提示不够详细。一般我们会自定义下error
try {
const rawResource = await fetch(“/source”).catch((err) => {
throw new Error(“获取资源失败”);
});
const newResource = doComputationalJob(rawResource);
await fetch(“/upload”, { method: “POST”, body: newResource }).catch(
(err) => {
throw new Error(“上传资源失败”);
}
);
} catch (err) {
原因是IMPDP的时候 ,既写了tables=xxx 还写了 remap_schema=LIS:oai
报错的导入脚本:
IMPDP oai/oai@tempdb directory=EEE dumpfile=ENTRY_BDC.dmp logfile=ENTRY_BD_IMPDP.txt tables=TEMP_BDC_ENTRY,TEMP_BDC_LUJING remap_schema=LIS:oai remap_tablespace=LIS:oai
将 tables=TEMP_BDC_ENTRY,TEMP_BDC_LUJING 拿掉就好了:
修改后的:
IMPDP oai/oai@tempdb directory=EEE dumpfile=ENTRY_BDC.dmp logfile=ENTRY_BD_IMPDP.txt remap_schema=LIS:oai remap_tablespace=LIS:oai
-----------------------------------------------
就跟 expdp 同时写 了tables=xxx 和 schemas=LIS 一样,会报错
问题:下载完成labview,打开VIPM闪退
解决:VIPM版本太低,需更新版本后打开
一、概念 根证书:是生成服务器证书和客户端证书的基础,是信任的源头,也可以叫自签发证书,即CA证书。
服务器证书:由根证书签发,并发送给客户,让客户安装在浏览器里的证书。主要包含服务端的公钥、域名和公司信息,浏览器客户端会验证自己请求的地址是否和证书里面的地址是否相同。
客户端证书:由根证书签发,需要导入到服务器的信任库中。主要包含客户端公钥、域名和公司信息。
二、目标 1、单向验证:如果是你客户端,你需要拿到服务器的证书,并放到你的信任库中;如果是服务端,你要生成私钥和证书,并将这两个放到你的密钥库中,并且将证书发给所有客户端。
2、双向验证:如果你是客户端,你要生成客户端的私钥和证书,将它们放到密钥库中,并将证书发给服务端,同时,在信任库中导入服务端的证书。如果你是服务端,除了在密钥库中保存服务器的私钥和证书,还要在信任库中导入客户端的证书。
3、使用单向验证还是双向验证,是服务器决定的。
单向认证是只在客户端侧做证书校验,双向认证客户端和服务端都要做对方的证书校验。
三、生成密钥、证书 openssl 参数:
-x509:创建自签名证书。
-days:指定自签名证书的有效期限,默认30天,需要和"-x509"一起使用。
-name可用于指定server证书别名;
-caname用于指定ca证书别名
-chain指示同时添加证书链
1、服务器端密钥 # 生成服务器端私钥 openssl genrsa -out server.key 2048 # 生成服务器端公钥 openssl rsa -in server.key -pubout -out server.pem 2、客户端密钥 # 生成客户端私钥 openssl genrsa -out client.key 2048 # 生成客户端公钥 openssl rsa -in client.key -pubout -out client.pem 下面这一步转换编码可以省略,这一步是后面用在java代码中作为客户端使用。若不需要不用转换编码。
私钥在使用前为pkcs1格式,而java在不引用第三方包的情况下无法直接使用pkcs1格式的秘钥,需要将其转化为pkcs8编码。
#将私钥进行pkcs8编码 openssl pkcs8 -topk8 -inform PEM -in client.key -outform PEM -out client_private.pem -nocrypt 3、CA机构密钥(这一步是CA机构操作,我们自己代劳而已) # 生成 CA 私钥 openssl genrsa -out ca.
地图官网获取服务许可key;国家地理信息公共服务平台 天地图
vue使用天地图报错Error in v-on handler: “TypeError: Cannot read property ‘_tdt_events‘ of null
当我们调用地图时需要使用setTimeout做延迟
mounted() { // 初始化天地图 setTimeout(()=>{ this.initTdtMap(); },100) }, 或者使用
mounted() { // 初始化天地图 this.$nextTick(()=>{ this.initTdtMap(); }) }, vue使用天地图实现步骤:
创建地图容器元素;引入天地图,tk:在官网申请;初始化地图对象;设置显示地图的中心点和级别;创建地图类型控件;将控件添加到地图,一个控件实例只能向地图中添加一次;创建坐标,通常是调取接口获得经纬度;创建覆盖使用的图标;创建在该坐标上的一个图像标注实例;将覆盖物添加到地图中,一个覆盖物实例只能向地图中添加一次; 全局引入地图 js 库 在Vue项目的index.html 文件中,全局引入天地图js库
<body> <script src="http://api.tianditu.gov.cn/api?v=4.0&tk=申请的key" type="text/javascript"></script> </body> 这种方法引入的地图 js,会导致项目的每一个组件都会加载该 js,尤其在不需要加载天地图的页面,会造成很大的性能损耗;而在首页不需要天地图时,天地图加载缓慢,会造成很长的白屏时间,因此需要优化一下引入地图 js 的方法; 创建dom元素并插入 在需要引入 js 的页面,创建script元素,设置 src 属性,并插入;这样就会只在该页面中引入天地图 js;
mounted() { let script = document.createElement('script') script.type = 'text/javascript' script.src = 'http://api.tianditu.gov.cn/api?v=4.0&tk=申请的key' document.body.appendChild(script) }, 应用天地图 <template> <div id="
我用的是 jquery还有echarts
第一步:寻找你需要的地图.json文件,下载后放到目录下 留着备用(注:地点区分可以理解为是身份证号区分);
第二步:开始写代码(需要查询标点及中心点的经纬坐标)
$(function(){ created(); }); function created(){ var sanData=[ [{name: '义乌机场', value: 1}], [{name: '义乌站', value: 2}], [{name: '松山风景区', value: 3}], [{name: '福田湿地公园', value: 4}], [{name: '凌云寺', value: 5}] ]; var geoCoordMap={ '义乌机场':[119.933733,29.27913], '义乌站':[120.049674,29.385449], '松山风景区':[120.072383,29.137404], '福田湿地公园':[120.145973,29.339617], '凌云寺':[119.719277,29.107542], }; var fromCoord='义乌机场' //中心点 var convertData = function (data) { console.log(data); var res = []; for (var i = 0; i < data.length;i++) { console.log('***',data[i]); var dataItem = data[i]; var fromCoord= geoCoordMap[dataItem[0].
一、安装
docker run -d --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:8.0.25 --lower_case_table_names=1
参数解释
-v:挂载宿主机目录和 docker容器中的目录,前面是宿主机目录,后面是容器内部目录。
-d:后台运行容器。
-p:映射容器端口号和宿主机端口号。
-e:环境参数,MYSQL_ROOT_PASSWORD设置root用户的密码。
–lower_case_table_names: 表名在硬盘上以小写保存,名称比较对大小写不敏感。
二、修改密码并配置远程连接
1、进入容器
docker exec -it mysql bash
2、连接并切换数据库
mysql -uroot -p123456
use mysql
3、修改密码,设置所有主机可以访问
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '新密码'
4、刷新权限
flush privileges
三、总结
此方法仅适用于简单测试,不推荐在生产环境中使用docker部署mysql。
文章链接:为什么mysql不要放在docker中?
————————————————
版权声明:本文为CSDN博主「Evan Wang」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41378597/article/details/123803955
记录一下
后续有用到在出使用的详细。
https://inorganik.github.io/countUp.js/ 数字动画
echarts示例echarts示例
目录 Cadence Allegro 17.4学习记录开始11-PCB Editor 17.4DXF板框导入和PCB板框自己定义一、认识板框所在的层二、PCB板框自己定义1、画个矩形板框1、选择命令,点击2、选择所在层,设置矩形的宽和高3、输入坐标,进行放置,就可以了 2、画个圆形板框1、选择命令,点击2、选择所在层,设置圆心坐标和半径,直接放置就可以了 三、DXF板框导入1、选择命令,点击2,弹出对话框,进行设置,路径,单位,等3、映射设置4、直接导入板框5、打开导入层的显示和设置一个自己喜欢的颜色显示6、将导入的板框Change到板框这一层 Cadence Allegro 17.4学习记录开始11-PCB Editor 17.4DXF板框导入和PCB板框自己定义 一、认识板框所在的层 我们现在使用的是17.4的版本,在Design_outline这个层定义板框就可以了
二、PCB板框自己定义 1、画个矩形板框 1、选择命令,点击 2、选择所在层,设置矩形的宽和高 3、输入坐标,进行放置,就可以了 2、画个圆形板框 1、选择命令,点击 2、选择所在层,设置圆心坐标和半径,直接放置就可以了 三、DXF板框导入 1、选择命令,点击 2,弹出对话框,进行设置,路径,单位,等 3、映射设置 4、直接导入板框 5、打开导入层的显示和设置一个自己喜欢的颜色显示 6、将导入的板框Change到板框这一层 1、选择命令,Change,点击
2、进行设置板框的所在层
3、点击需要Change的板框,完成
目录 Cadence Allegro 17.4学习记录开始02-原理图Capture CIS 17.4一、元件库的复用1、从已有原理图文件中复制元器件 二、绘制原理图1、绘制原理图之前,软件设置2、放置元器件3、编辑元器件4、原理图电气互连、 网络标号、 分页符连接、 总线的使用1、电气连接2、网络标号3、分页符连接4、总线 5、快速放置之重复操作F46、快速复制之Ctrl7、批量浏览8、find命令9、Design Cache操作(元件批量替换/更新)10、元件操作a、元件移动b、元件旋转c、元件镜像:d、元件属性浏览 11、添加/修改封装12、文本处理13、原理图注释操作(annotate):原理图编号(位号)14、原理图设计方式平铺式结构设计方式层叠式结构设计方式 15、原理图中添加差分属性 三、原理图DRC检查四、原理图生成网表1、第一方网表2、第三方网表AllegroADPADS 总结 五、原理图导出BOM六、原理图导出PDF文档方法1:使用打印导出PDF方法2: 使用PDF工具导出,17.4版本才有的功能 七、总结 Cadence Allegro 17.4学习记录开始02-原理图Capture CIS 17.4 一、元件库的复用 继续上一章的内容,先开始介绍元件库的复用。
原理图的后缀:DSN
原理图元件库的后缀:OLB
1、从已有原理图文件中复制元器件 从原理图缓存中复制元器件从原理图中复制元器件
二、绘制原理图 1、绘制原理图之前,软件设置 可以设计自己喜欢的主题,和颜色。
栅格设置,方便绘制原理图。
2、放置元器件 (快捷键: P)
在绘制原理图的界面下,工具栏->Place->Part,或直接使用快捷键P,即可打开元件库入口
如下图所示,选择红框选中的按钮,即可选择官方内置库或者第三方库,官方库的位置以及说明已经在前面提出。然后在part部分双击对应元件即可放置对应元件。
3、编辑元器件 4、原理图电气互连、 网络标号、 分页符连接、 总线的使用 1、电气连接 放置线条(Place wire) (快捷键: W)。
2、网络标号 放置网络标号(Place net alias) (快捷键: N) 仅限于同一张原理图。
3、分页符连接 放置分页符连接(Place off-page connector) 用于不同页元器件连接。
4、总线 放置总线(Place bus) (快捷键: B)。
将一组数据线绘制出线并放置网络标号。靠近这组线出现绘制出总线。命名总线:放置网络标号(Place net alias) (快捷键: N) 给总线命名。
完美转发 1. 在函数模板中,可以将 自己的参数“完美”地转发给其它函数。所谓完美,即 不仅能准确地转发参数的值,还能保证被转发参数的左、右值属性不变。 2. C++11标准引入了右值引用和移动语义,所以,能否实现完美转发,决定了该参数在传递过程使用的是拷贝语义(调用拷贝构造函数)还是移动语义 (调用移动构造函数)。 1. 如果模板中 (包括类模板和函数模板)函数的参数书写成为T&& 参数名 那么,函数既可以接受左值引用,又可以接受右值引用。 2. 提供了模板函数std::forward<T>(参数),用于转发参数如果参数是一个右值,转发之后仍是右值引用;如果 参数是一个左值,转发之后仍是左值引用 move 在我的另一篇文章《C++之右值引用、移动构造函数》提到,左值不能初始化右值引用。
那么我们能不能用左值初始化一个右值引用呢??这里C++给我们了一个函数move();
move()函数
将左值转换为右值,实现对象资源的转移。 下面看个例子
void test2() { vector<int> v; for (int i = 0; i < 10; i++) v.push_back(i); vector<int>vv = v; //拷贝 cout << "v ="; for (auto x : v) cout << x << " "; cout << ", v.addr=" << &v << endl; cout << "vv ="; for (auto x : vv) cout << x << "
可调用对象 在C++中,可以像函数一样调用的有:普通函数、类的静态成员函数、仿函数、lambda函数、类的非静态成员函数、可被转换为函数的类的对象,统称可调用对象或函数对象。
可调用对象有类型,可以用指针存储它们的地址,可以被引用(类的成员函数除外)。
这里举几个例子
仿函数(本质是重载了()的类)
#include<iostream> using namespace std; struct Object { void operator()(int age, string name) { cout << "年龄:" << age << ",姓名:" << name << endl; } }; int main() { Object obj; obj(20, "小谢"); Object& obj_r = obj; // 引用函数 obj_r(19, "小赵"); return 0; } lambda函数
#include<iostream> using namespace std; int main() { auto func = [](int age, string name) { cout << "年龄:" << age << "
以下是 C 语言代码,用于解决这个问题:
#include<stdio.h> int main() { int a, b, c; // 使用三重循环枚举三位整数的每一位 for(a=1; a<=9; a++) { for(b=0; b<=9; b++) { for(c=0; c<=9; c++) { // 如果abc + cba 等于 1333,则输出 a、b、c 的值 if(a*100 + b*10 +
如何保证消息的顺序性 如图所示,RabbitMQ保证消息的顺序性,就是拆分多个 queue,每个 queue 对应一个 consumer(消费者),就是多一些 queue 而已,确实是麻烦点;
或者就一个 queue 但是对应一个 consumer,然后这个 consumer 内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
如何保证消息不丢失? 1,生产者发送消息至MQ的数据丢失 解决方法:在生产者端开启comfirm 确认模式,你每次写的消息都会分配一个唯一的 id,
然后如果写入了 RabbitMQ 中,RabbitMQ 会给你回传一个 ack 消息,告诉你说这个消息 ok 了
Channel channel = connection.createChannel(); channel.confirmSelect(); // 开启confirm模式 2,MQ收到消息,暂存内存中,还没消费,自己挂掉,数据会都丢失 解决方式:MQ设置为持久化。将内存数据持久化到磁盘中。
rabbitmq的持久化分为队列持久化、消息持久化和交换器持久化。一般三个都要设置持久化
3,消费者刚拿到消息,还没处理,挂掉了,MQ又以为消费者处理完 解决方式:用 RabbitMQ 提供的 ack 机制,简单来说,就是你必须关闭 RabbitMQ 的自动 ack,可以手动ack,可以通过一个 api 来调用就行,然后每次你自己代码里确保处理完的时候,再在程序里 ack 一把。这样的话,如果你还没处理完,不就没有 ack 了?那 RabbitMQ 就认为你还没处理完,这个时候 RabbitMQ 会把这个消费分配给别的 consumer 去处理,消息是不会丢的。
如果消费者由于某些原因失去连接(其通道已关闭,连接已关闭或 TCP 连接丢失),导致消息未发送 ACK 确认,RabbitMQ 将了解到消息未完全处理,并将对其重新排队。如果此时其他消费者可以处理,它将很快将其重新分发给另一个消费者。这样,即使某个消费者偶尔死亡,也可以确保不会丢失任何消息。
如何保证消息不被重复消费? (幂等性) 方式1: 消息全局 ID 或者写个唯一标识(如时间戳、UUID 等) :每次消费消息之前根据消息 id 去判断该消息是否已消费过,如果已经消费过,则不处理这条消息,否则正常消费消息,并且进行入库操作。(消息全局 ID 作为数据库表的主键,防止重复)
文章目录 1. VUE的响应式原理1.1 ViewModel1.2 双向绑定的基本原理1.3 什么是响应性1.4 Vue 中的响应性是如何工作的 2. Vue 渲染机制2.1 虚拟 DOM2.2 渲染管线2.3 带编译时信息的虚拟 DOM2.3.1 静态提升2.3.2 修补标记 Flags2.3.3 树结构打平2.3.4 对 SSR 激活的影响 1. VUE的响应式原理 响应式的基本原理:双向数据绑定,就是把Model绑定到View,当我们用JavaScript代码更新Model时,View就会自动更新,在单向绑定的基础上,如果用户更新了View,Model的数据也会自动更新。
双向绑定由三个重要部分构成:
数据层(Model):应用数据及业务逻辑
视图层(View):应用的展示效果,各类UI组件
业务逻辑层(ViewModel):框架封装的核心,负责将数据与视图关联起来
1.1 ViewModel 作用:
数据变化更新视图视图变化更新数据 它还有两个主要部分组成:
监听器(Observer):对所有数据的属性进行监听解析器(Compiler):对每个节点的指令进行扫描跟解析,根据指令模板替换数据,以及绑定相应的更新函数 1.2 双向绑定的基本原理 在 JavaScript 中有两种劫持属性访问的方式:Object.defineProperty 和 Proxy 。
Vue 2 使用 Object.defineProperty 完全由于需支持更旧版本浏览器的限制。在 Vue 3 中使用了 Proxy 来创建响应式对象,将 getter/setter 用于 ref。 首先要对数据(data)进行劫持监听。所以需要设置一个监听器Observer,用来监听所有的属性。
每一个组件都有一个Watcher实例。如果属性发生变化,需要通知订阅者Watcher,看是否需要更新。因为订阅者有多个,所以需要一个消息订阅器(发布者)Dep(订阅者集合的管理数组)来专门收集这些订阅者,在Observer和Watcher之间进行统一管理。
还需要一个指令解析器Compile,对每个节点元素进行扫描和解析,将相关指令初始化为一个订阅者Watcher,并替换模板数据或绑定相应的函数,此时当订阅者Watcher接收到相应属性的变化,就会执行对应的更新函数,从而更新视图。
1、实现一个监听器Observer,用来劫持并监听所有属性,如果发生变化,就通知订阅者。
2、实现一个订阅者Watcher,可以收到属性的变化通知并执行相应的函数,从而更新视图。
3、实现一个解析器Compile,可以扫描和解析每个节点的相关指令,并据此初始化视图和订阅器Watcher。
1.3 什么是响应性 如果我们在 JavaScript 写类似的逻辑:
let A0 = 1 let A1 = 2 let A2 = A0 + A1 console.
我们程序中经常遇到倒计时的问题 倒计时转换成时分秒格式
//时间转换 时分秒 FormatTime(totalSeconds: number): string { let hours: number = this.Rounding((totalSeconds / 3600)); let hh: string = (hours < 10 ? "0" + hours : hours).toString(); let minutes: number = this.Rounding((totalSeconds - hours * 3600) / 60); let mm: string = minutes < 10 ? "0" + minutes : minutes.toString(); let seconds: number = this.Rounding(totalSeconds - hours * 3600 - minutes * 60); let ss: string = seconds < 10 ?
1:环境准备:jdk1.8
依赖管理:maven
代码管理:git
二、框架结构 data ————————————————测试数据目录
| rus ————————————————项目目录(不同项目不同名称)
| | searchbydetail.json —————————测试数据文件
| | search.csv ————————————数据驱动文件
report —————————————————测试报告目录
src
| main
| | java
| | | com.tal.seg.autotest
| | | | commontools ——————实体类等目录
| | | | rus ———————————项目目录
| | | | | QuestionSearch.java ———测试用例文件 | | | | utils —————————— 工具类目录
三:项目配置:
说明:配置文件分别对应开发、线上、测试环境,可将项目中的url和数据库信息写到相应的文件中。通过@value引用url进行使用。
@Value(“${recommendEngine.url}”)
public String recommandUrl;
通过application.properties 设置激活dev test pro 环境
通过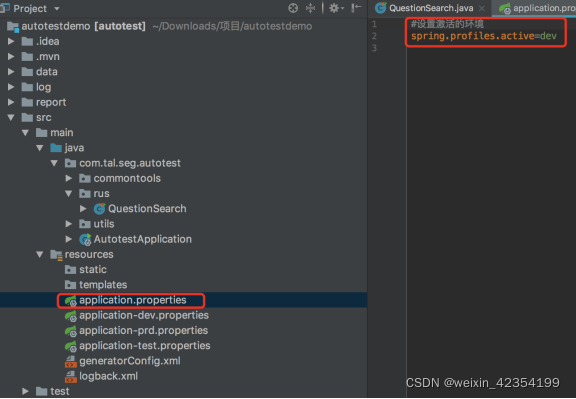 四、测试用例组成
1、测试用例文件:提供请求头,请求方法等信息(对应框架示例中的QuestionSearch.java);
1.构造下列正规式相应的 DFA。 (1)1(0|1) *101 (2)1(1010* |1(010)*1) *0 (3)a((a|b)* |ab*a)*b (4)b((ab)* bb)*ab 答案:(2)(3)(4)略。 写1个(1)体现解题思路。
2.已知 NFA= ((x,yz),{0,1}M,{x},{z}),其中: M(x,0)={z}, M(y,0)={x,y}, M(z,0)={x,z}, M(x,1)={x}, M(y,1)= , M(z,1)={y},构造相应的 DFA。 答案:
3.将下图确定化。 答案:
4.将下图的 (a) 和 (b) 分别确定化和最小化 答案:
剩余部分见:编译原理第三版答案
搭建GitLab服务器: 在Windows下搭建Gitlab服务器 - 从未被超越 - 博客园
使用Hyper-V安装LINUX系统: 使用Hyper-V安装LINUX系统 - 咸鱼也是有梦想的 - 博客园
使用VMware Workstation安装Linux系统: https://blog.csdn.net/ly021499/article/details/79695511 Jenkins安装与配置详解:Jenkins安装与配置详解 - Mecell - 博客园
网址 React 官方中文文档 – 用于构建用户界面的 JavaScript 库
一、了解: 用于构建用户界面的 JavaScript 库
声明式:
React 使创建交互式 UI 变得轻而易举。为你应用的每一个状态设计简洁的视图,当数据改变时 React 能有效地更新并正确地渲染组件。
以声明式编写 UI,可以让你的代码更加可靠,且方便调试。
组件化:
创建拥有各自状态的组件,再由这些组件构成更加复杂的 UI。
组件逻辑使用 JavaScript 编写而非模板,因此你可以轻松地在应用中传递数据,并使得状态与 DOM 分离。
一次学习,随处编写:
无论你现在正在使用什么技术栈,你都可以随时引入 React 来开发新特性,而不需要重写现有代码。
React 还可以使用 Node 进行服务器渲染,或使用 React Native 开发原生移动应用。
二、入门案例 使用react脚手架create-react-app搭建react环境
安装脚手架
选择一个文件夹,运行如下命令
npx create-react-app reacte-basic
启动命令
cd reacte-basic
npm start
三、从0开始编写react程序 删除src下的所有文件
src下创建index.js入口文件
测试代码console.log("hello react")
console.log('hello react') 页面运行后,输出了hello react,
index.js为整个react项目的js入口文件
在index.js中实现react程序
import React from "react" import ReactDom from "
Pillow1、OpenCV2
文章目录 一、opencv、matplotlib、pillow和pytorch读取数据的通道顺序二、Pillow(1) Image类(2) ImageFilter类(3) ImageEnchance类 三、OpenCV(1)读、显示、写图片(2) 常用操作函数(3) BGR与HSV模型 一、opencv、matplotlib、pillow和pytorch读取数据的通道顺序 详细区别:
总结:除了pytorch得到的是nchw图片,其余方法得到的都是hwc图片;除了cv2得到的c是bgr图片,其余方法得到的c都是rgb图片;plt.imshow()既可以显示(H,W)灰色图片,也可以显示(H,W,C=3)的numpy或torch类型的RGB图片,但nhwc某批次里的图片只能一张一张显示opencv(imread,imshow):uint8的ndarray数据,通道顺序hwc,颜色通道BGR。matplotlib(imread,imshow):uint8的ndarray数据,通道顺序hwc,颜色通道RGB。pillow(open,show):自己的数据结构。可以np.array(image)转换成numpy数组:uint8的ndarray数据,通道顺序hwc,颜色通道RGB。可以Image.fromarray(image)将numpy数组类型转化为pillow类型。pythorch(torchvision.datasets、torch.utils.data.DataLoader及torchvision.io.read_image):ToTensor()到[0, 1]的torch数据,通道顺序nchw,颜色通道RGB,查看图片方法及ToPILImage。 import cv2 import matplotlib.pyplot as plt from PIL import Image image = cv2.imread(img_path) cv2.imshow("image", image) cv2.waitKey(2000) #由bgr图片转成rgb图片:cv2.cvtColor(image, cv2.COLOR_BGR2RGB)或image[:, :, :: -1] image = plt.imread(img_path) plt.imshow(image)#plt.imshow(image, cmap="gray") plt.show()#若没有显示应该是开发环境的问题 image = Image.open(img_path) image.show()#或plt.imshow(image), plt.show() #pytorch的nchw图片转成nhwc图片,下面train_data[0][0]代表第一张图片的数据,train_data[0][0]代表第一张图片的标签。分别plt和pillow显示 plt.imshow(train_data[0][0].permute(1, 2, 0)) plt.imshow((train_data[0][0].numpy().transpose(1,2,0))) transforms.ToPILImage()(train_data[0][0]).show() 二、Pillow PIL库最常用的类3:Image、ImageFilter、ImageEnhance
(1) Image类 返回Image实例:im=Image.open()/Image.fromarray()/Image.new(),转成数组:np.asarray(im)实例常用属性: format(如png/jpg)size(宽度和高度组成的二元组,即水平和垂直方向上的像素数,像素值0为黑,255为白),width,heightmode(图像的类型和像素的位宽,即[‘1’, ‘L’, ‘I’, ‘F’, ‘P’, ‘RGB’, ‘RGBA’, ‘CMYK’, ‘YCbCr’ ]和相应位宽,如’RGB’类型图像的每个像素占3×8位,‘P’类型图像的每个像素占8位且使用调色板映射到其他模式) 实例(或Image类)常用方法: 保存图片:save()裁切图片crop((x0,y0,x1,y1)):在原始图像中以左上角为坐标原点,x0是距离左边界的距离,y0是距离上边界的距离,x1是x0+要截的宽度,y1是y0+要截的高度将一张图粘贴到另一张图像上:paste(image|color,box)(其中image,box的尺寸必须一样)转换新模式:convert(mode)缩放和旋转图像:resize, rotate(逆时旋转给定角度值)分开、合并、混合图像:split(提取RGB图像的每个颜色通道分别作为Image对象),Image.merge(mode,bands)(将各独立通道再合成一幅新的图像),Image.blend(image1,image2, alpha)(alpha是透明度,合成公式为:out=image1(1-alpha)+image2 alpha,需保证两张图像的模式和大小是一致的)from PIL import Image im = Image.
AntDesign中a-select下拉选择框的两种用法 用法1 <template> <a-form-model-item> <a-select placeholder="请选择" :disabled="disabled" v-model="ruleForm.sqrXb" @change="handleChange"> <a-select-option value="01"> 男性 </a-select-option> <a-select-option value="02"> 女性 </a-select-option> </a-select> </a-form-model-item> </template> <script> export default { data() { return { ruleForm: { sqrXb:'' } } }, methods: { handleChange(value) { // sqrXb 申请户户主性别 this.ruleForm.sqrXb = value }, } } </script> 用法2 <template> <a-select :disabled="disabled" placeholder="请选择" style="width: 90px" v-model="sqbList.sqhhzxb" @change="handleChange" > <a-select-option :value="item.value" v-for="item in xb" :key="item.value" > {{item.value}} </a-select-option> </a-select> </template> <script> export default { data() { xb: [ { key: 0, value: '男性' }, { key: 1, value: '女性' }, // { key: 0, value: '不详' }, ], return { sqbList: { sqhhzxb:'' } } }, methods: { handleChange(value) { // sqhhzxb 申请户户主性别 this.
本文写作顺序:效果展示——子组件封装——父组件传值
仅js的原始图(回归初始化)、撤销(上一步)功能实现,样式需要自己调整
目录 前言:参考文档文章一、实现效果:二、安装插件及依赖:三、封装组件:1.html部分:2.引入依赖:3.父组件传入数据:4.js部分全部配置 四、父组件调用1.引入子组件2.初始数据3.父组件按钮及事件 前言:参考文档文章 vis官方配置文档:文档地址
参考使用文章:文章地址
一、实现效果: 二、安装插件及依赖: cnpm install -S vis-linetime cnpm install -S vis-data cnpm install -S moment 三、封装组件: 下端时间轴单独封装成组件
1.html部分: <template> <div class="visGantt" ref="visGanttDom"></div> </template> 2.引入依赖: import { DataSet } from 'vis-data/peer' import { dateFormat } from '@/util' //封装的时间格式化函数,如下所示 import { Timeline } from 'vis-timeline/peer' import 'vis-timeline/styles/vis-timeline-graph2d.css' const moment = require('moment') 时间格式化函数:
export function dateFormat(date, fmt) { //date是日期,fmt是格式 let o = { 'M+': date.getMonth() + 1, // 月份 'd+': date.
KubeSphere中集成ApiSix 一、Apache APISIX 介绍 Apache APISIX 是一款开源的高性能、动态云原生网关,由深圳支流科技有限公司于 2019 年捐赠给 Apache 基金会,当前已经成为 Apache 基金会的顶级开源项目,也是 GitHub 上最活跃的网关项目。Apache APISIX 当前已经覆盖了 API 网关,LB,Kubernetes Ingress,Service Mesh 等多种场景。
二、部署Apache APISIX Ingress Controller 2.1 进入企业空间添加应用仓库 首先还是先要添加 Apache APISIX Helm Chart 仓库,推荐用这种自管理的方式来保障仓库内容是得到及时同步的。我们选定一个企业空间后,通过「应用管理」下面的「应用仓库」来添加如下一个 Apache APISIX 的仓库(仓库 URL:https://charts.apiseven.com)。
2.2 创建项目部署apisix 接下来我们创建一个名为 apisix-system 的项目。进入项目页面后,选择在「应用负载」中创建「应用」的方式来部署 Apache APISIX,并选择 apisix 应用模版开始进行部署。
为何是部署 Apache APISIX 应用的 Helm Chart,而不是直接部署 Apache APISIX Ingress Controller?
这是因为 Apache APISIX Ingress Controller 目前和 Apache APISIX 网关是强关联的(如下图所示),且目前通过 Apache APISIX Helm Charts 同时部署 Apache APISIX Gateway + Dashboard + Ingress Controller 是最方便的,因此本文推荐直接使用 Apache APISIX 的 Helm Chart 进行整套组件的部署。
k8s集群中部署微服务项目前端代理服务 Nginx 一、微服务项目静态资源准备 # mkdir sangomall-proxy # cd sangomall-proxy/ [root@k8s-master01 sangomall-proxy]# ls conf Dockerfile html html.tar.gz [root@k8s-master01 sangomall-proxy]# cd conf/ [root@k8s-master01 conf]# docker run -d nginx:latest [root@k8s-master01 conf]# docker ps [root@k8s-master01 conf]# docker cp id:/etc/nginx/default.conf . [root@k8s-master01 conf]# ls default.conf [root@k8s-master01 conf]# docker stop id;docker rm id; [root@k8s-master01 conf]# vim default.conf [root@k8s-master01 conf]# cat default.conf upstream sangomall {//反向代理 server mall-gateway.sangomall.svc.cluster.local.:8072; } server { listen 80; server_name *.msb.com; #access_log /var/log/nginx/host.access.log main; location /static/ { root /usr/share/nginx/html; } location / { proxy_set_header Host $host; proxy_pass http://sangomall; } #error_page 404 /404.
1.文法G=({A,B,S},{a,b,c},P,S)其中Р为:S→Ac|aB A→ab→bc 写出L(GISJ)的全部元素。 答案: L(G[S])={abc}
2.文法G[N]为:N→D|ND D→0|1|2|3|4|5|6|7|8|9 G[N]的语言是什么? 答案:G[N]的语言是V+。V={0,1,2,3,4,5,6,7,8,9} (允许 0 开头的非负整数)
3.为只包含数字、加号和减号的表达式,例如 9-2+5,3-1,7 等构造一个文法 答案:G[S]: S→S+DIS-DID
D→0|1|2|3|4|5|6|7|8|9
4.证明文法G=({E,O}),{(,),+,*,v,d},P,E)是二义的,其中P为 E->EOE|(E)|v|d O->+|* 答案:E=>EOE=>EOEOE
E=>EOE=>EOEOE
有两个不同的最左推导(两颗不同的语法树),所以是二义的。
5.已知文法 G[Z]: Z::=a Z b Z::=a b 写出 L(G[Z])的全部元素。 答案:L(G[Z])={|n≥1}
6.已知文法 G: <表达式>::=<项>| <表达式>+<项> <项>::=<因子>| <项>*<因子> <因子>::= (<表达式>) l i 试给出下述表达式的推导及语法树。 (1)i (2) (i) (3) i*i (4)i*i+i (5) i+(i+i) (6) i+i*i 答案:
7.习题1中的文法G[S]是二义的吗?为什么? 答案:是二义的,对于一个产生式有两个不同的语法树。
8.考虑下面的上下文无关文法: S->SS*|SS+|a (1)表明通过此文法如何生成串 aa+a*,并为该串构造语法树. (2)该文法生成的语言是什么? 答案:
(1)S=>SS*=>SS+S*=>aS+S*=>aa+S*=>aa+a*
(2)该文法生成的语言是: *和+的后缀表达式,即逆波兰式。
9.文法 S->S(S)S|ε (1)该文法生成的语言是什么?
报表计算出错,错误信息如下:
com.bstek.ureport.console.exception.ReportDesignException: Report data has expired,can not do preview.
at com.bstek.ureport.console.html.HtmlPreviewServletAction.loadReport(HtmlPreviewServletAction.java:277)
at com.bstek.ureport.console.html.HtmlPreviewServletAction.execute(HtmlPreviewServletAction.java:78)
at com.bstek.ureport.console.UReportServlet.service(UReportServlet.java:81)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:764)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:228)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163)
at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:190)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163)
at de.codecentric.boot.admin.server.ui.web.servlet.HomepageForwardingFilter.doFilter(HomepageForwardingFilter.java:73)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:190)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163)
at cn.exrick.xboot.core.config.security.permission.MyFilterSecurityInterceptor.invoke(MyFilterSecurityInterceptor.java:48)
at cn.exrick.xboot.core.config.security.permission.MyFilterSecurityInterceptor.doFilter(MyFilterSecurityInterceptor.java:41)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:190)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163)
…
使用ureport点击预览时报错原因:
https://www.w3cschool.cn/ureport/ureport-y4op2han.html
文章目录 1.使用 NAT 模式的前提2.编辑虚拟机设置3.配置虚拟机 VMnet8 的 NAT 模式4.配置 Windows 主机的 WLAN 和 VMnet85.修改 Ubuntu 22.04 的配置文件5.1 开启 Ubuntu 22.045.2 修改配置文件5.3 测试 Windows 能否 ping 通 Ubuntu5.4 测试 Ubuntu 能否 ping 通 Windows 和 Baidu 问题描述:在 Windows 主机连接(哈工大)校园网、VMware 虚拟机使用桥接模式的情况下,即使 Ubuntu 和 Windows 处于同一网段下,Ubuntu 也无法上网,此时可以使用 NAT 模式。
1.使用 NAT 模式的前提 打开 Windows 主机的“任务管理器”,在“服务”中开启 “VMware DHCP Service” 和 “VMware NAT Service”。
2.编辑虚拟机设置 打开 VMware,点击“编辑虚拟机设置”,选中“网络适配器”,勾选“NAT模式”。
3.配置虚拟机 VMnet8 的 NAT 模式 打开 VMware 左上角“编辑”,选择“虚拟网络编辑器”。
项目运行
环境配置:
Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。
项目技术:
SSM + mybatis + Maven + Vue 等等组成,B/S模式 + Maven管理等等。
环境需要
1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。
2.IDE环境:IDEA,Eclipse,Myeclipse都可以。推荐IDEA;
3.tomcat环境:Tomcat 7.x,8.x,9.x版本均可
4.硬件环境:windows 7/8/10 1G内存以上;或者 Mac OS;
5.是否Maven项目: 否;查看源码目录中是否包含pom.xml;若包含,则为maven项目,否则为非maven项目 6.数据库:MySql 5.7/8.0等版本均可;
毕设帮助,指导,本源码分享,调试部署(见文末)
5.1 登录注册 登录,用户通过输入用户名,密码,选择角色等信息即可进行系统登录,如图5-1所示。
图5-1管理员登录界面图
学生注册,在学生注册页面通过填写学号、密码、学生姓名、学院、专业、手机等信息完成学生注册,如图5-2所示。
图5-2学生注册界面图
5.2管理员功能模块 管理员登录进入考试排考系统可以查看首页、个人中心、学生管理、考生类别管理、准考证信息管理等内容进行详细操作,如图5-3所示。
图5-3管理员功能界面图
学生管理,在学生管理页面可以查看索引、学号、学生姓名、性别、头像、学院、专业、手机等信息,并可根据需要进行详情、修改或删除等操作,如图5-4所示。
图5-4学生管理界面图
考生类别管理,在考生类别管理页面可以查看索引、专业名称、类别、编号等信息,并可根据需要进行详情、修改或删除等操作,如图5-5所示。
图5-5考生类别管理界面图
准考证信息管理,在准考证信息管理页面可以查看索引、准考证号、考场日期、考场时间、学号、学生姓名、年份、专业名称、类别、编号、考场号、座位号、考场名称、考场地点等信息,并可根据需要进行详情、修改或删除等操作,如图5-6所示。
图5-6准考证信息管理界面图
5.3学生功能模块 学生登录进入考试排考系统可以查看首页、个人中心、准考证信息管理等内容进行详细操作,如图5-7所示。
图5-7学生功能界面图
个人中心,在个人中心页面通过填写学号、学生姓名、性别、头像、学院、专业、手机等信息,并可根据需要对个人信息进行修改,如图5-8所示。
图5-8个人中心界面图
准考证信息管理,在准考证信息管理页面可以查看索引、准考证号、考场日期、考场时间、学号、学生姓名、年份、专业名称、类别、编号、考场号、座位号、考场名称、考场地点等信息,并可根据需要进行详情等操作,如图5-9所示。
图5-9准考证信息管理界面图
JAVA毕设帮助,指导,源码分享,调试部署
题目描述 n 个人参加某项特殊考试。
为了公平,要求任何两个认识的人不能分在同一个考场。
求是少需要分几个考场才能满足条件。
输入描述 输入格式:
第一行,一个整数 n (1≤n≤100),表示参加考试的人数。
第二行,一个整数 m,表示接下来有 m 行数据。
以下 m 行每行的格式为:两个整数 a,b,用空格分开 ( 1≤a,b≤n )表示第 a 个人与第 b 个人认识。
输出描述 输出一行一个整数,表示最少分几个考场。
输入输出样例 示例
输入
5 8 1 2 1 3 1 4 2 3 2 4 2 5 3 4 4 5 输出
4 思路: 从第1个考场开始,逐个加入考生。每新加进来一个人x,都与已经开设的考场里面的人进行对比,如果认识,就换个考场。直到找到一个考场,考场里面所有的人都不认识x,x就可以坐在这里。如果所有已经开设的考场都有熟人,就开一个新考场给x坐。
剪枝:用剪枝来减少搜索。在搜索一种新的可能的考场安排时,如果需要的考场数量已经超过了原来某个可行的考场安排,就停止。
参考代码: def dfs(x,room): global num,p if room>num: #需要的考场数量超过了原来可行的考场安排,停止 return if x>n: if room<num: #用的考场更少了 num=room #更新考场数量 return for j in range(1,room+1): k=0 while p[j][k] and a[x][p[j][k]]==0: k+=1 if p[j][k]==0: # k 座位没人坐 p[j][k]=x #第 j 考场的k座位,安排x坐 dfs(x+1,room) #第x人安排好了,继续安排下一人 p[j][k]=0 #回溯,放开这个座位 p[room+1][0]=x #1~room考场都不能坐,x只能坐第room+1个考场的第一个座位 dfs(x+1,room+1) #继续安排第x+1人,试试第1~room+1考场 p[room+1][0]=0 #回溯 n=int(input()) m=int(input()) num=110 p=[[0 for i in range(n+1)]for j in range(n+1)] a=[[0 for i in range(n+1)]for j in range(n+1)] for i in range(m): u,v=map(int,input().
软件使用方法 解压压缩包,得到一个文件夹,内容如下
双击【wechat.exe】运行,可以看到程序有两个子菜单,每一个菜单都能对聊天界面进行部分设置
我们进入【对话设置】子菜单,这里可以设置聊天对象的头像,可以添加多个聊天成员来生成群聊记录,可以选择当前发送消息的成员,可以设置红包或转账金额等,设置好这些后,点击下面的绿色或蓝色按钮即可完成消息发送或转账信息发送,而右侧也就会相应的出现对应的聊天记录。
并且,右侧的聊天记录也是可编辑的,对于不满意的消息可以选择删除,还可以将鼠标放在转账消息上对转账进行领取。
最后,我们将生成好的图片保存到本地就可以啦。
下载链接 https://pan.baidu.com/s/1ugINiqROVSQhkCzjjG_w_w?pwd=oz9p https://donot996.lanzoub.com/iVd7H0nf7syd
“深度学习刷 SOTA 有哪些 trick?”,此问题在知乎上有超 1700 人关注,浏览量超 32 万,相信是大家都非常关心的问题,快一起看看下面的分享吧,希望可以帮助到大家~
对于图像分类任务,让我们以 Swin-Transformer 中使用到的 trick 为例,简单梳理一下目前深度学习中常用的一些 trick:
Stochastic Depth 这一方法最早在 Deep Networks with Stochastic Depth 一文中被提出,原文中被称为 stochastic depth。在 EfficientNet 的实现中被 Google 称为 drop connect。因为和 DropConnect 撞名,在 timm 的实现中又被改名为 drop path(但是这个名字也和 DropPath 撞名了,尴尬)。因此大家听到这几个名词的时候最好注意区分一下到底是哪个。
stochastic depth 类似于 dropout,但又有所不同。简单来说 dropout 在训练时随机地抛弃了一部分激活值,而 stochastic depth 则直接抛弃了一部分样本,即将这些样本的值设为零。因此这一方法一般只能放在残差结构中,将网络输出中的一部分样本直接抛弃,再与 shortcut 相加,从而实现部分样本 “跳过” 这一残差结构的效果。
通过跳过部分残差结构,实际上起到了多种深度网络组合的效果,类似集成学习,从而提高网络的性能。
Mixup & CutMix 二者都是图像混合增强手段,即在训练时,我们将两个样本按照某种方式进行混合,并相应地混合它们的标签。其中 Mixup 和 CutMix 的区别就在于按照什么方式对图像进行混合。
这种图像混合增强的目的是使图像经过神经网络映射后嵌入的低维流形变得平滑,从而提高网络的泛化能力。
关于图像混合增强手段的详细介绍参见 https://zhuanlan.zhihu.com/p/436238223
RandAugment 这是一种组合数据增强手段,相比传统数据增强的随机裁剪、随机翻转,这种方法设置了一个包含各种数据增强变换的集合,并对每个样本随机应用其中若干个增强,大大扩展了增强后的图像空间。
关于 RandAugment 的详细介绍参见 https://zhuanlan.
文章目录 1.构建系统make2.构建系统CMake3.CMake的常见命令行调用4.CMakeLists.txt常见语法5.为什么需要库library?6.CMake 中的静态库与动态库(1)add_library(2)动态库的符号隐藏方式(3)position-independent code (PIC) 编译动态库 .so(4)生成动态库的 SO-NAME(5)include_directories,link_directories,link_libraries和target_link_libraries解析(6)–no-copy-dt-needed-entries问题 7.为什么 C++ 需要声明8.为什么需要头文件?9.CMake 中的子模块(1)子模块的头文件如何处理(2)总结 11.目标的一些其他选项12.第三方库 - 作为纯头文件引入13.第三方库 - 作为子模块引入14.CMake - 引用系统中预安装的第三方库15.安装第三方库 - 包管理器(1) arch的pacman(2)ubuntu apt-get(3)vcpkg(4)CMake 添加第三方库依赖方式git submodule、 find_library、FetchContent、CPM等 1.构建系统make 2.构建系统CMake 为了解决make的以上问题,跨平台的Cmake应运而生只需要写一份CmakeLists.txt,它就能在调用时生成当前系统所支持的构建系统CMake可以自动检测源文件和头文件之间的依赖关系,导出到Makefile里面CMake具有相对高级的语法,内置的函数能够处理configure,install等常见需求CMake可以自动检测当前的编译器,需要添加哪些flag,必须OpenMP,只需要在CMakeLists,txt中指明target_link_libraries(a.out OpenMP::OpenMP_CXX)即可 3.CMake的常见命令行调用 生成构建文件Makefile 表示输出makefile文件的目录 表示试用clang++作为编译器 cmake -Bbuild -DCMAKE_CXX_COMPILER=clang++ cmake -Bbuild -DCMAKE_CXX_COMPILER=clang++ -DCMAKE_CXX_STANDARD=17 构建可执行文件,编译 cd build;make 或者make -C build,优点是:跨平台 或者cmake --build build 4.CMakeLists.txt常见语法 add_executable(输出的可执行文件 输入的多个源文件) add_executable(a.out main.cpp hello.cpp) add_library(test STATIC source1.cpp source2.cpp) # 生成静态库 libtest.a add_library(test SHARED source1.cpp source2.cpp) # 生成动态库 libtest.
1.下载JSEncrypt
npm install jsencrypt --dep 2.在main.js引入注册并使用
import JSEncrypt from 'jsencrypt' //**依赖引入**// import JSEncrypt from 'jsencrypt' //**JS引入**// <script src="https://cdn.bootcss.com/jsencrypt/3.0.0-beta.1/jsencrypt.js"></script> //**Vue引入**// import JSEncrypt from '@/common/jsencrypt.min' 3.在@/node_modules/jsencrypt/bin/jsencrypt.js修改jsencrypt源码
var modificationNavigator = { appName: 'Netscape', userAgent: 'Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1' }; var modificationWindow = { ASN1: null, Base64: null, Hex: null, crypto: null, href: null }; 将navigator替换为modificationNavigator 将window替换为modificationWindow uni-app可用的jsencrypt.js下载:
https://vkceyugu.cdn.bspapp.com/VKCEYUGU-0c03b75a-8139-4654-83b3-f12d36df4bbe/a4e593c9-fefa-41f6-9b94-28d904c607fd.zip
在线生成公钥和私钥: 在线RSA加密解密,RSA2加密解密(SHA256WithRSA)-BeJSON.
问题描述:1.新焊接的电路板晶振未成功起振
2.起振后晶振两端波形不一致
正常情况下8MHZ晶振两端对地波形都一样(波形规整,光滑无毛刺),如下图
晶振部分原理图如图
解决过程:先检查电路焊接情况,排除焊接问题;再给板子烧录程序,灌入程序后晶振起振,测量波形正常。但直有晶振一端为正常起振波形,另一端波形晶振频率仍不正常,发现是示波器参数未调试正确,使用了×1档测量晶振两端波形。
问题分析:
1.为什么新板子不写入程序晶振就不工作?
因为未烧写程序的单片机内部寄存器没配置好。单片机外部晶振接的是无源晶振,必须先烧写程序进去,配置好相关寄存器,晶振才会起振。
参考此博客:STM32外部晶振不起振:http://t.csdn.cn/bHx3f
2.为什么测量晶振两端波形不一样?
测量晶振示波器表笔要打到衰减档,表笔调至×10档位。
×10档意思是,信号衰减到1/10再到示波器;而使用×1档,相当于一个很重的负载并联在晶振电路中导致晶振停振了。(一个示波器探头的×1档具有上百pF电容)。
参考此博客:示波器探头原理 :http://t.csdn.cn/OJDAl
示波器表笔衰减档×1 ×10:http://t.csdn.cn/W5P3J
写在最后,文章记录个人学习测试中的问题,若有错误望各位技术大佬批评指正;如有侵权行为请联系删除修改。
一、概述 形态学: 通常是指生物学的分支,用于处理动物和植物的形状和结构
形态学图像处理用于提取表示和描述区域形状(如边界、骨架和凸壳)的图像分量
映像: 取反
平移:移动
二、结构元 结构元:用于探测正在研究的图像,以获取感兴趣的小集合。
腐蚀:原图像向内腐蚀一圈
A被B腐蚀,是所有结构元的原点位置的集合,其中平移的B与A的背景并不叠加。
膨胀:原图像向外膨胀一圈
映射并平移后的B与A集合至少有一个元素重叠。
腐蚀和膨胀的对偶性
腐蚀和膨胀在集合、互补和映射方面是相为对偶的
开操作:先腐蚀再膨胀
一般会平滑物体的轮廓、断开较窄的狭颈并消除细的突出物
闭操作:先膨胀再腐蚀
同样也会平滑轮廓的一部分。但与开操作相反,它通常会弥合较窄的间断和细长的沟壑,消除小的孔洞,填补轮廓线中的断裂。
开运算和闭运算的对偶性
开运算和闭运算在集合、互补和映射方面是相互对偶的
击中或击不中变换
如果 B 表示由前景B1 及其背景B2组成的集合(B1,B2),则B在A中的匹配(或匹配集),记为 三、形态学算法 边界提取:
集合A的边界可以通过先用B对A的腐蚀,然后求A和腐蚀结果之间的集合差得到
A对B腐蚀就是边界
孔洞填充
孔洞可以被定义为:由前景中相连接的边界像素点所包围的一个背景区域。
迭代算法:半自动 先给一个初始点作为xk
连通分量
当前的结果与结构元膨胀,然后与原图像进行求交 得到的结果必在原图像内
凸包
集合A内,若连接任意两个点的线段都在A的内部,则称集合A的凸形的。 击中操作
细化
原图像减去击中
粗化:
原图像并上击中
骨架
A的骨架记为S(A),它有如下性质:
集合A的骨架可以用腐蚀和开操作来表达:
重建骨架化的集合A:
裁剪
1、细化
2、击中
3、膨胀
形态学重建
重构涉及到两幅图像和一个结构元:
一幅图像包含变换的开始点,图像称为标记(marker)。F另一幅图像(模板mask)用来约束变换过程。G结构元用于定义连接性。B F为标记图像,同时G为模板,满足F包含于G
测地膨胀D 先对图像G进行膨胀,然后与模板F进行相交 测地腐蚀E 先对图像G进行腐蚀,然后与模板F进行相并
通过膨胀的形态学重建
利用测地膨胀进行迭代,知道到达稳定性
应用-重建开运算
图像 F 的大小为 n 的重建开运算定义为: F 的大小为 n 的腐蚀相对于 F 的膨胀重建
1. 设置坐标轴上下限: axis([xmin,xmax,ymin,ymax]);
例:axis([0, 11, 0, 0.5]); xmin = 0, xmax = 11, ymin = 0, ymax = 0.5;
2、坐标轴名称相关设置: x轴的名称及字体和大小:xlabel('x(m)', 'FontName', 'Times New Roman', 'FontSize', 7);
例:xlabel('n','FontName','Times New Roman','FontSize', 22);
3、坐标轴的字体及大小设置: set(gca,'FontName','Times New Roman','FontSize',7,'LineWidth',1.5);
例:set(gca,'FontName','Times New Roman','FontSize', 18, 'LineWidth',0.5);
4、 图例的相关设置: 图例中字体及大小:legend('FontName','Times New Roman','FontSize',7,LineWidth',1.5);
图例中各个量及位置:legend('y','zc','location','NorthEast');
例:h = legend('C', 'Python');
set(h, 'FontName', 'Times New Roman','FontSize', 22,'FontWeight','normal');
5、 图名的字体及大小设置: title('title name','FontName','Times New Roman','FontSize',7);
例:title('Real-time Test','FontName','Times New Roman','FontSize',18);
6、显示网格 grid on;
功能
对SQLite数据库进行连接对数据库中的数据进行增删改查并更新到DataGridView控件中 一、创建数据库连接 #region 变量 private string dbUrl = null; //数据库文件的地址 private SQLiteConnection connection; //数据库连接对象 #endregion #region 数据库工具类相关的函数 /****************************************************************************************************************** * name : public DBHelper(string DBName) * Function : 指定数据库文件的地址 * Parameters : DBName :数据库的名称 * Returns : NULL * Author : 那些你很冒险的梦 * Check : * Date : 2021-3-21 ******************************************************************************************************************/ public DBHelper(string DBName) { dbUrl = Application.StartupPath + "\\" + DBName + ".db"; } /****************************************************************************************************************** * name : public SQLiteConnection Connection * Function : 创建并返回数据的连接 * Parameters : DBName :数据库的名称 * Returns : NULL * Note : * Author : 那些你很冒险的梦 * Check : * Date : 2021-3-21 ******************************************************************************************************************/ //创建连接 public SQLiteConnection Connection { get { //判断数据库文件是否存在 if (!
您可以在 20 分钟内创建一个网站。您也不需要成为技术向导。
不管是商务还是休闲。您不需要花哨的设计师或昂贵的开发人员。只需按照以下简单步骤操作,您就可以立即上线。 顶级虚拟主机提供商创建网站 如果你想创建一个网站,你需要一个网络托管服务提供商。这是最好的选择。
创建网站的 9 个步骤 以下是构建网站的步骤摘要:
第 1 步:选择完美的域名 选择域是您可以为网站做出的最重要的决定。它从字面上说明了您想如何向世界展示。它是您网站的地址,也是人们记住您的方式。
虽然许多最佳域名已被占用,但这并不意味着您无法为您的品牌找到完美的域名。 在集思广益想出好的域名时,请考虑以下因素:
容易说和拼写。潜在访问者应该能够向某人大声说出您的域名,而无需他们问两次如何拼写或说出。
简短而甜美。我们建议不要超过 14 个字符。您不想要一个难以记住和说出的过长域名。
使用 .com、.org 或 .net。虽然那里有很多域名系统,但最好还是坚持使用久经考验的系统。毕竟,您希望人们能够记住它。
用你的名字。对于个人博客、网站或作品集来说是一个特别好的选择。
避免数字和连字符。这只会让它在 URL 中看起来很奇怪。此外,它使人们更难将您的 URL 告诉他人。
第 2 步:获取虚拟主机和免费域名注册 一个网站只需要两件事就可以上线:一个域名和一个虚拟主机。
你刚刚想出了你的域名。现在是时候将它与一个好的网络主机一起使用了。
第 3 步:申请您的免费域名 WordPress 现在是时候选择您的 CMS(内容管理系统)了,而 WordPress 是我最推荐的。
系统将提示您使用 WordPress 创建您的网站。如果您错过提示或出于任何原因跳过它们,您始终可以使用仪表板中左侧的下拉面板登录 WordPress:
第 6 步:使用可自定义的主题设计您的网站 您已经选择了一个 WordPress 主题来构建您的网站,如果您对它的外观感到满意,那就太好了!
如果您想看看还有什么,您可以在 WordPress.org 上探索数以万计的主题。其中很多都是免费的。还有一些您需要付费。
专业提示:不要太担心这一部分。很容易陷入完美主义,并认为您需要在第一时间就把主题弄好。这不是真的。
您可以做的最重要的事情就是选择一个基本主题并与之配合。您以后可以随时更改主题。 转到您的 WordPress 网站的管理仪表板。您可以通过 Hostinger 仪表板执行此操作,也可以使用 URL [您的网站名称].com/wp-admin。然后只需使用您在上一步中获得的用户名和密码即可。
第 7 步:构建网站架构 如果您的网站是一座房子,那么它目前是一片空地。它有坚实的基础,并连接到基本的公用设施——但它需要墙壁和房间。